elasticsearch--知识点
中文社区
https://elasticsearch.cn/
spring data es
Spring Data Elasticsearch 官方文档
一、elasticsearch
Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
基于lucene
lucene基于倒序索引
1、倒排索引
进行分词处理,记录该词的出现次数,出现位置,根据词定位到文档,根据文档信息检索内容
2、正排索引
传统方式,从前往后一个一个进行匹配
document:文档 对象
属性 size 、path、content、time
二、集群
每个节点分别存放倒排索引,document
主、从
主:增删改,从分担主的查询,主、从不能放到一台机器
三、安装
值允许普通用户操作,不允许root用户
因为elasticsearch 有远程执行脚本的功能所以容易中木马病毒
es需要安装JDK,由java开发
tar -zxvf elasticsearch-6.6.0.tar.gz
es比较耗内存,默认占用1G内存
进入es conf目录
1、修改内存大小
jvm.options
-Xms512m
-Xmx512m
2、修改配置文件
进入el目录中,进入conf目录,修改配置文件
elasticsearch.yml
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
network.host: 0.0.0.0
http.port: 9200
说明
#配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。 cluster.name: my-es #节点名称 node.name: node-1 #设置索引数据的存储路径 path.data: /usr/local/elasticsearch/data #设置日志的存储路径 path.logs: /usr/local/elasticsearch/logs #设置当前的ip地址,通过指定相同网段的其他节点会加入该集群中 network.host: 0.0.0.0 #设置对外服务的http端口 http.port: 9200 #设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点 discovery.zen.ping.unicast.hosts: ["127.0.0.1","10.10.10.34:9200"]
9300内部端口号
3、创建用户
因为安全问题elasticsearch 不让用root用户直接运行,所以要创建新用户。
具体操作如下:
useradd testuser
passwd testuser
再输入两次密码(自定义)
为用户赋权限
chown -R testuser:testuser /usr/local/elasticsearch
chown -R elk:elk /opt/soft/elasticsearch-6.6.0
修改配置文件
vim /etc/sysctl.conf 添加(限制一个进程可以拥有的虚拟内存的数量)
vm.max_map_count=655360
保存后执行(配置生效)
sysctl -p
vim /etc/security/limits.conf 添加以下字段(因为允许外网访问,必须的系统调优)
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
修改后需要重启
vim /etc/security/limits.d/90-nproc.conf 修改 ( 解决线程不够的异常 )
* soft nproc 1024 把 1024 改成 4096
启动es命令:bin/elasticsearch
systemctl status firewalld
然后使用es用户启动 :su testuser
启动es命令:bin/elasticsearch
cd /usr/local/elasticsearch
/opt/soft/elasticsearch-6.6.0/bin/elasticsearch
之后切换回到 我们自己的账户下,启动es: ./elasticsearch 或者加上 -d, 已守护线程方式启动,
查看进程是否启动: ps -ef|grep elasticsearch
关闭es和关闭他的线程方式一样: kill -9 '进程号'
http://192.168.1.136:9200/
四、kibana 安装
修改配置文件
server.port: 5601
server.host: "http://192.168.233.100:5601"
elasticsearch.hosts: ["http://http://192.168.233.100:5601:9200"]
切换到bin 目录
./kibana --allow-root
{ "query": { "match": { "infoall": { "query": "如果有理数 a、b 满足 | a b - 2 | + \\left( 1 - b \\right) ^ { 2 } = 0 , ,试求- \\frac { 1 } { a b } + \\frac { 1 } { \\left( a + 1 \\right) \\left( b + 1 \\right) } + \\frac { 1 } { \\left( a + 2 \right) \\left( b + 2 \right) } + \\cdots \frac { 1 } { \\left( a + 2 0 1 7 \\right) \\left( b + 2 0 1 7 \\right) } 的值. ", "fuzzy_transpositions":false, "minimum_should_match":"75%" } } } }
1、创建索引
put /myindex
获取索引
get /myindex
创建文档 必须有ID
/索引/类型/id
put /myindex/user/1
{
"name":"张三",
"age":20,
"sex":0
}
delete /myindex
id不可以重复
会自动生成ID
post /myindex/user/
{
"name":"张三",
"age":20,
"sex":0
}
查询所有
get /myindex/user/_search
查询指定ID
get /myindex/user/_search
{
"ids":["1","2"]
}
查询指定条件
get /myindex/user/_search?q=age:21
复杂条件查询
get /myindex/user/_search?q=age[30 TO 60]
排序
get /myindex/user/_search?q=age[30 TO 60]&sort=age:desc&from=0&size=2
Dsl语言查询
post已json格式发送进行查询
term精确匹配,不会分词
GET /myindex/user/_search
{
"query":{
"term":{
"name":"aaa"
}
}
}
match
分词查询
{
"query":{
"from":0,
"size":2,
"match":{
"name":"aaa"
}
}
}
查询文档映射类型
GET /myindex/_mapping
在postman中传json查看分词效果
http://192.168.136.110:9200/_analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
DSL语言查询,用的比较多
五、es版本控制
cas 乐观锁
悲观锁:假设会发生并发冲突,屏蔽一切可能违反数据准确性的操作
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性
9200:暴露 es restful接口端口号, 通过restful可进行增删改查
9300:tcp协议端口号,ES集群之间通讯端口号
六、中文分词器 es-ik插件 ,版本要和es版本一致
es中默认的分词器对中文拆词不是很好,会拆成一个一个的字
https://github.com/medcl/elasticsearch-analysis-ik
下载对应版本的zip解压后放到es的pluge中
plugins/analysis-ik
unzip -d /analysis-ik elasticsearch-analysis-ik-6.6.0.zip
创建自己的dic 把路径配置到IKAnalyzer.cfg.xml
测试:
curl -XGET -H 'Content-Type: application/json' 'http://localhost:9200/_analyze?pretty' -d '{
"analyzer" : "ik_max_word",
"text": "中华人民共和国国歌"
}'
七、文档映射
1、动态映射(默认)
数值默认long
String分为text和keyword
text 会分词
keyword 不会分词
2、静态映射
之前如果该索引已经指定类型
不可以再post 修改,要删除后再操作
post /myindex/_mapping/user
{
"user":{
"properties":{
"age":{
"type":"integer"
},
"name":{
"type":"text",
"analyzer":"ik_smart" //指定分词器es-ik
},
"sex":{
"type":"keyword"
}
}
}
}
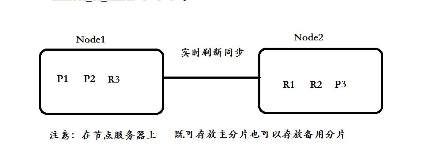
八、集群 分片,集群后访问那个几点都能得到数据
将单台服务器节点的索引文件使用分片进行拆分,分布式存在多个不同的物理机(节点)进行存放
1、主分片(primary) 默认5个分片,定义好数量就不能更改
为什么??
2、副分片(replicas 备份分片) 副分片可以改
分片定义好就不能更改
主分片对应的副分片不能放在一台机器
单台服务器没有备用分片
分片是均摊存放到各个节点
主分片实时同步信息到备份分片
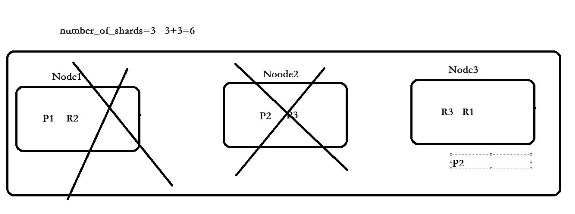
如果两台挂了会丢失 p2分片
主分片对应的备用分片不能1个 要对应多个 才能做到都都挂了,只剩一个的时候能够存在完整的索引
分片最好是节点的平方
分片位置 =文档 ID%主分片数量
查询索引信息
http://192.168.136.110:9200/myindex/_settings
3、集群
名称要相同
配置节点名称
cluster.name: my-application
node.name: node-1
node.name: node-2
node.name: node-3
验证集群
http://192.168.136.110:9200_cat/nodes?pretty
集群要把data下的nodes数据清除,否则同步不了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号