数据采集与融合技术第四次作业
数据挖掘第四次实践
作业一
当当图书爬取实验
作业内容
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法; Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生自由选择
实践过程
-
确定需要爬取的信息位置,需要注意的是,纸质书与电子书的价格标签位置不同,需要分别寻找;对可以有可能取空值的信息用.extract_first()方法,当信息为空时,返回NULL
代码实现:
item['title'] = info.xpath('./a/@title').extract()[0] # 书名 # 纸质书与电子书价格标签位置不同 if(info.xpath('./p[@class="price"]')): price = info.xpath('./p[@class="price"]/span[@class="search_now_price"]/text()').extract() else: price = info.xpath('./div/p[2]/span/text()') item['price'] = price[0] detail = info.xpath('./p[@class="detail"]/text()').extract_first() # 书本详情介绍 item['detail'] = detail item['date'] = info.xpath('./p[@class="search_book_author"]/span[2]/text()').extract_first() # 上市时间 item['author'] = info.xpath('./p[@class="search_book_author"]/span[1]/a[1]/@title').extract_first() # 作者 item['publisher'] = info.xpath('./p[@class="search_book_author"]/span[3]/a/text()').extract_first() # 出版商 -
写入数据库Pipeline编写
class DangdangPipeline: def __init__(self): # 数据库连接 self.connect = pyodbc.connect( 'DRIVER={SQL Server};' 'SERVER=(local);DATABASE=test;' 'Trusted_Connection=yes') self.cur = self.connect.cursor() def process_item(self, item, spider): # 信息写入 self.cur.execute( 'insert into book([bTitle],[bAuthor], [bPublisher],[bData],[bPrice],[bDetail]) values(?,?,?,?,?,?)', (item['title'], item['author'], item['publisher'], item['date'], item['price'], item['detail']) ) self.connect.commit() return item def close_spider(self, spider): # 关闭数据库 self.connect.close(); -
Setting设置
from fake_useragent import UserAgent BOT_NAME = 'dangdang' SPIDER_MODULES = ['dangdang.spiders'] NEWSPIDER_MODULE = 'dangdang.spiders' IMAGES_STORE = 'D:\\program\\python\\CrawlLearning\\Homework\\PR3\\imgs' USER_AGENT = UserAgent(path="D:\\program\\python\\CrawlLearning\\fake_useragent_0.1.11.json").random DEFAULT_REQUEST_HEADERS = { 'User-Agent':USER_AGENT } ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'dangdang.pipelines.DangdangPipeline': 300, }
作业结果
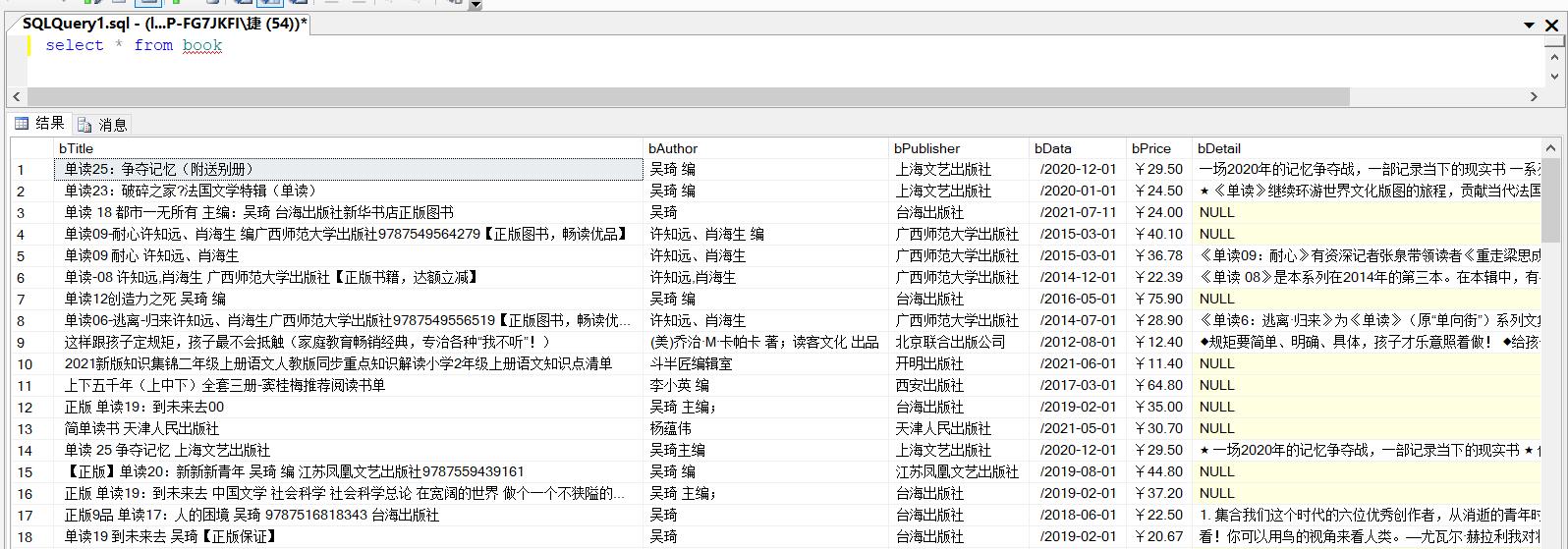
数据库存储结果:
心得体会
通过本实验,进一步巩固了scrapy用法,还有对网页元素寻找更加熟练。
作业二
银行汇率爬取实验
作业内容
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
实践过程
-
依然是查看各元素位置,因为网站元素比较简单,所以选择直接用xpath提取出某一列的所有信息,最后再拼接为item
money = response.xpath('//div[@id="realRateInfo"]/table/tr/td[1]/text()').extract() # 交易币 tsps = response.xpath('//div[@id="realRateInfo"]/table/tr/td[4]/text()').extract() # TSP csps = response.xpath('//div[@id="realRateInfo"]/table/tr/td[5]/text()').extract() # CSP tbps = response.xpath('//div[@id="realRateInfo"]/table/tr/td[6]/text()').extract() # TBP cbps = response.xpath('//div[@id="realRateInfo"]/table/tr/td[7]/text()').extract() # CBP stime = response.xpath('//div[@id="realRateInfo"]/table/tr/td[8]/text()').extract() # 时间 -
爬下来的数据有很多符号,需要对字符串进行处理
item['current'] = money[i].replace(" ","").replace("\n","").replace("\r","") -
Pipeline与Setting与上题相似,不再展示
作业结果
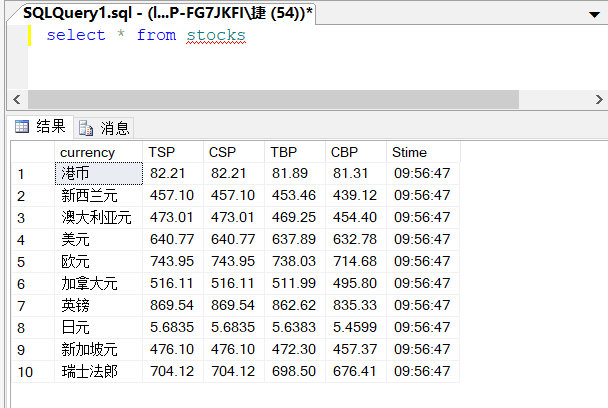
数据库存储结果:
心得体会
对于网页元素较少,且信息比较完整的网页,可以直接一次性获取所有元素列表,再进行拼接。
tbody标签是无法通过xpath找到的,之间跳过这一层即可。
作业三
股票信息爬取实验
作业内容
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
实践过程
-
定位各信息位置 所需信息都在tr标签的td标签内
-
代码实现
trs = driver.find_elements_by_xpath("//tr") flag = 0 for tr in trs: if flag==0: flag=1 continue id = tr.find_element_by_xpath("./td[2]/a").text # 代码 name = tr.find_element_by_xpath("./td[3]").text # 名称 cmoney = tr.find_element_by_xpath("./td[5]").text # 最新价 up = tr.find_element_by_xpath("./td[6]").text # 涨跌幅 upnum = tr.find_element_by_xpath("./td[7]").text # 涨跌额 success = tr.find_element_by_xpath("./td[8]").text # 成交量 snum = tr.find_element_by_xpath("./td[9]").text # 成交额 f = tr.find_element_by_xpath("./td[10]").text # 振幅 max = tr.find_element_by_xpath("./td[11]").text # 最高 min = tr.find_element_by_xpath("./td[12]").text # 最低 today = tr.find_element_by_xpath("./td[13]").text # 今开 yesterday = tr.find_element_by_xpath("./td[14]").text # 昨收 -
定位版块切换按钮位置,实现版块切换
def nextSort(driver,num): # 版块切换 try: driver.find_element_by_xpath('//ul[@class="tab-list clearfix"]/li['+str(num)+']').click() except: print("不存在该版块") -
构造webdriver
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board" ua = UserAgent(path="D:\\program\\python\\CrawlLearning\\fake_useragent_0.1.11.json").random chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') chrome_options.add_argument("user-agent=" + ua) driver = webdriver.Chrome(chrome_options=chrome_options) driver.get(url)
作业结果
数据库结果:
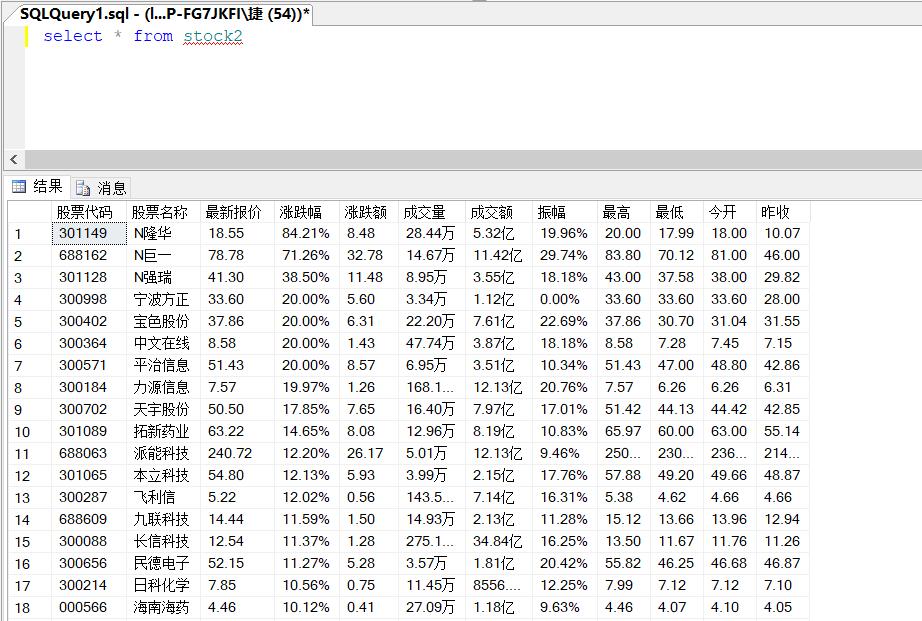
心得体会
熟悉了selenium的使用,而且通过scrapy与selenium对于xpath使用的对比,对不同框架下的xpath使用有了更深的理解。
