数据采集与融合技术第一次作业
实验一
实验源代码见:https://gitee.com/jie-zheng/crawl_project/tree/master/作业1
作业一
作业内容:
-
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
-
输出信息:
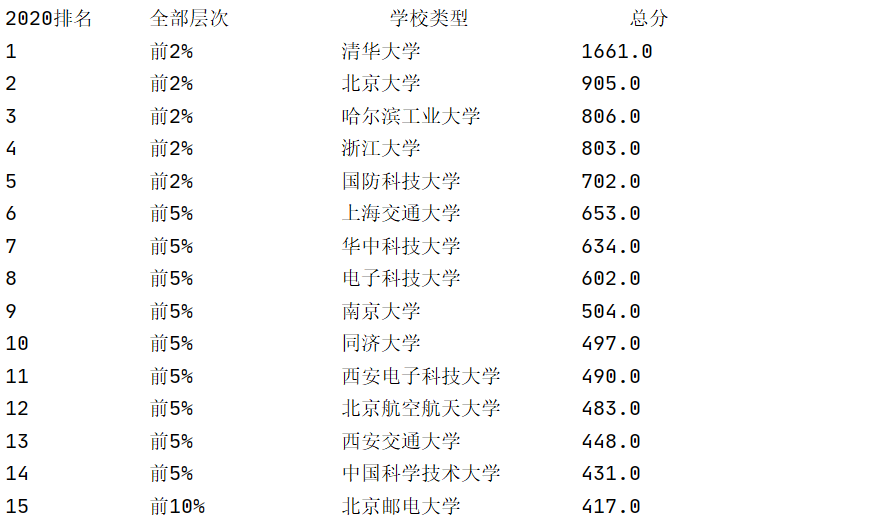
2020排名 全部层次 学校类型 总分 1 前2% 中国人民大学 1069.0 2......
解题思路:
-
查看网页源代码可发现,每个学校的信息集合位于
<tr>标签中,信息内容位于每个<tr>标签中的<td>标签
-
先利用re获取每个
<tr>标签起始位置m = re.search(r'<tr.*?>', html) n = re.search(r'<\/tr>', html) row = html[m.end():n.start()] -
再截取每个
<td>标签内容sort = re.findall(r'<td.*?>(.*?)<\/td>', row) -
对
<td>标签内容进行提取# 提取排名 rank = eval(re.search(r'>(.*?)<', sort[0]).group().replace(">", "").replace("<", "").replace(" ", "")) # 提取所占比例 num = re.search(r'(.*)<', sort[2]).group().replace(" ", "").replace("<", "") # 提取学校名称 name = re.search(r'<img alt="(.*?)"', sort[3]).group(1).strip() # 提取得分 score = eval(sort[4].strip())
运行结果:
心得体会
-
如果对获取的html文件进行单纯正则表达式匹配,可以先将其进行预处理,删除空格与换行符,避免表达式过于复杂。
html = html.replace("\n", "").strip() -
特别是在匹配标签时,要注意选择非贪婪匹配,不然匹配出的字符串会包含许多无用的标签信息。
作业二
作业内容
-
要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报
-
输出信息:
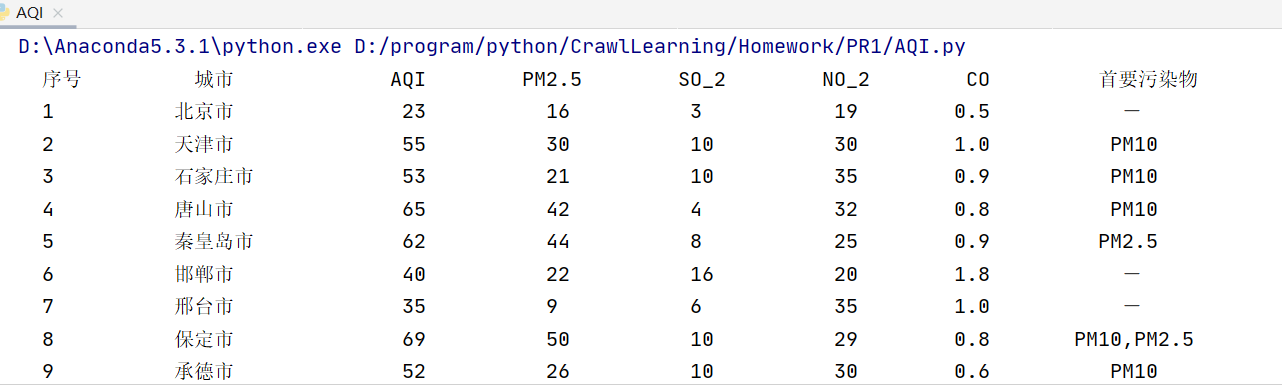
序号 城市 AQI PM2.5 SO2 No2 Co 首要污染物 1 北京 55 6 5 1.0 225 — 2......
解题思路
-
由于网页是动态页面,所以使用检查不容易看清结构,选择直接查看网页源代码。
-
所需内容位于
<tbody id="legend_01_table">下的`````标签块中
-
网页结构较为清晰,使用BeautifulSoup库进行遍历即可
- 先遍历
<tbody id="legend_01_table">的儿子节点<tr> - 再对每个
<tr>寻找所有<td>
for tr in soup.find('tbody', attrs={"id": "legend_01_table"}).children: if isinstance(tr, element.Tag): # 查找tr下的td标签 sorts = tr.find_all('td') - 先遍历
运行结果
心得体会
- 在选择内容提取方式上,若爬取内容遵循网页标签树的规律,可利用bs4库层层遍历获取数据,或者利用bs4库遍历使查询范围缩小后,再使用正则表达式进行匹配。直接使用正则表达式需要考虑表达式普适性与非贪婪性等问题,提取信息步骤不够直观。
作业三
作业内容
- 要求:使用urllib和requests和re爬取一个给定网页(http://news.fzu.edu.cn/ )爬取该网站下的所有图片
- 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
解题思路
-
提取内容方式选择上:
本题要求下载所有照片,故直接利用正则表达式匹配出所有图片链接即可达成目的,由于设计到的模块众多,使用bs4反而不好遍历。
-
提取图片正则表达式:
imgurl = re.findall(r'<imgsrc="([^<]*?\.(jpe?g|gif|png))".*?/>', html)可匹配jpg、jpeg、gif、png四种格式的图片链接
-
对获得的图片链接拼接成可直接访问的链接
true_url = 'http://news.fzu.edu.cn' + url[0] -
图片下载至本地
for pic in urls: # 遍历图片 file_name = pic.split('/')[-1] # 以/为分隔符,取最后一段作为文件名 response = requests.get(pic) with open("photo/" + file_name, 'wb') as f: # 文件写入 f.write(response.content)
运行结果
心得体会
- 总结出匹配图片链接的正则表达式,日后可直接使用。
- 本题很好的体现了正则表达式在网页信息提取中可突破标签结构进行查找这一优势,在对特定要求的项目中有快速的提取效果。
