

这款模型将加剧AI冷战。原因在这里。
这款模型将加剧AI冷战。原因在这里。
计算力、数据和胜利

来源:作者使用GPT-4o
美国和中国都认为,AI对于决定谁将成为最终的超级大国至关重要。而中国最新的前沿模型则发出了明确的信息:
你们无法阻止我们,我们正在追赶上来。
对于美国来说,这是一个坏消息,特别是在它渴望保持全球最强大国家的雄心下。
直到最近,美国被认为在计算能力上相对于中国占有重要优势。然而,DeepSeek发布的v3模型实际上使这一优势归于无效,标志着AI冷战的一个重要转折点,并可能导致未来几个月紧张局势的加剧,美国最近在1月13日的报复使NVIDIA陷入恐慌状态。
那么,为什么这个模型改变了一切呢?让我们深入探讨一下。
理解这场战斗
目前,美国在四个关键领域中领先,尽管我将解释为什么这个领先地位很快可能会改变。
四大优势
• 首先,他们在知识产权(IP)方面处于领先地位。
世界上最好的模型都在美国训练,包括OpenAI的o1和o3,Anthropic的Claude 3.5 Sonnet和Opus,Google的Gemini 2.0,以及xAI的Grok-3(目前正在测试发布)。
• 他们在数据方面也占据领先地位。
虽然大规模语言模型(LLM)的预训练数据主要是公开的、广泛可用的,但对于大型推理模型(LRM),比如o1、o3或Gemini 2.0 Flash Thinking,情况就不同了。这些模型需要推理数据,其中问题和答案还包括推理过程,这个过程是通向答案的中间步骤。大部分互联网内容都是人们发布的结论性思维和解决方案,而不是他们为得出结论所进行的内部对话和思考过程。因此,这些数据必须从零开始构建,需要顶级人才和雄厚资金。没有任何公司能像OpenAI或Anthropic那样在这方面与美国竞争,因此世界上最好的数据也都掌握在美国。
• 他们在人才方面也占优势。
尽管大部分人才来自印度,且有趣的是,很多人来自中国,但美国的深厚资金使得全球许多有前途的研究人员加入了美国公司。
• 最重要的是,他们在计算能力上占据领先地位。
毫无疑问,美国目前最大的优势是在硬件方面,顶级的GPU由美国公司设计,并由美国盟友台湾的TSMC制造。
美国如何保持其领先地位?
AI冷战的主要战斗
保护知识产权是不可能的;最终,即便是那些没有正式发布的突破性研究,背后的顶级研究人员也会泄露出来。但如果不能训练或运行模型,知识产权也毫无用处。为此,你需要获得计算资源。因此,到目前为止,美国的主要武器就是计算限制,防止中国公司或中共获得顶级GPU。例如,NVIDIA不能将其最顶级的产品出售给中国公司,TSMC也不能为中国的公司(如华为)生产芯片来采用他们的顶级封装方法。
长话短说,中国公司在GPU的可获取性方面受到了严重的“欠缺”,而仅有少数通过马来西亚的GPU走私来缓解这一问题。
但正如我在开头所说,DeepSeek v3的发布意味着这一问题很快将不再存在。
为什么?
一场资金较量
在常规的从零开始的程序中,训练一个最先进的模型是一项八位数的投资,甚至在某些情况下需要九位数。而接下来的数字会让你目眩。
没有现金,你就是垃圾
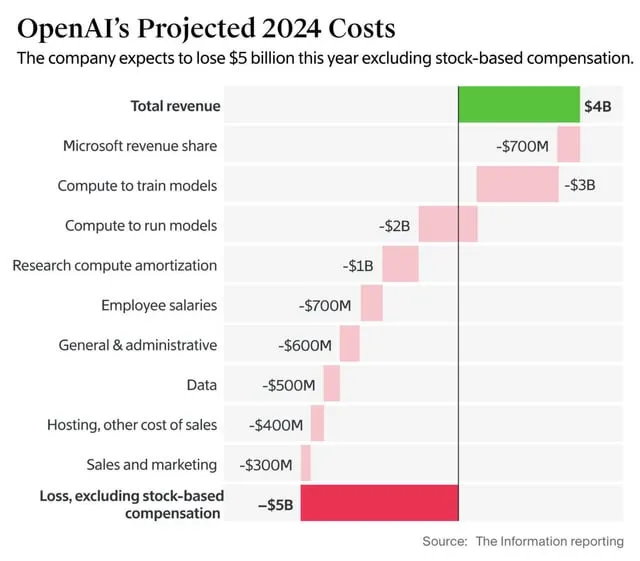
以GPT-4为例,2022年时,训练成本大约在8000万到1亿美元之间。
而o3(Orion)的价值据称已经增长到5亿美元。这些数字可能没有计算完全的TCO(总拥有成本),因为薪资和硬件资本支出可能被忽略了。
然而,根据《The Information》的报道,OpenAI在2024年花费了大约30亿美元用于训练计算。
为什么这么贵?
训练的四个阶段
之所以如此昂贵,是因为它需要完整执行四个阶段:
- 预训练:
需要汇集大量数据并输入模型。该模型必须处理数万亿个单词,Llama 3.1模型达到大约12万亿个单词,这是一个人如果每天工作8小时需要20万年才能读完的数量。
最近发布的训练运行使用了大约10到100百万艾克福洛普(Exaflops),即10到100万万万次数学运算(或1至10×10²⁵次运算)。
为了让这个数字有个概念,全球沙粒的数量估计为7.5×10¹⁸。因此,这个模型所需的运算次数是地球上沙粒数量的660万倍。
这一阶段还包括广泛的数据整理和去重,试图最大化训练数据的质量。如今,这一阶段还涉及大量的合成数据生成。
- 监督微调:
在下一个阶段,我们会整理出{问题:答案}类型的结构化数据集,也就是指令数据集,模型在此学习如何作为对话者,尤其是如何回答收到的问题。
这些数据主要是从零开始构建的,尽管你可以在像HuggingFace这样的地方找到这些数据集的免费示例。虽然这个数据集比第一个小得多,但从零开始构建仍然是昂贵的。
- RLHF(基于人类反馈的强化学习):
接下来,我们进入RLHF阶段,这是一种较弱的强化学习形式(但仍然非常有用),帮助模型在回答问题时做出更好的决策。
同样,这一阶段的数据集必须从零开始构建,并需要像博士这样的人类专家来整理,博士的聘用费用非常高。
- 推理训练:
在最后阶段,我们有推理训练,在这一阶段,模型接受新的数据进行广泛训练,教会它们以逐步的方式解决问题,忽略时间(模型不会被激励迅速作答,而是更长时间思考)。
这一阶段对计算资源的要求非常高。
结论
OpenAI在2024年花费了30亿美元训练自己的模型,但现在,中国的DeepSeek却用仅600万美元的投入,训练出了一个与世界顶尖模型相媲美的生成模型,彻底打破了训练一个最先进模型需要上亿资金的传统观念。
这一切是如何做到的呢?
答案就是:蒸馏(Distillation)。
通过这一方法,DeepSeek能够以较低的成本训练出性能接近美国顶级模型的模型,而这也意味着中国公司正在利用美国的技术限制来迅速赶超,甚至有可能超越美国。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号