

kubernetes日志收集
kubernetes的日志收集
日志收集在本篇文章中主要分2种方案
需要明确的是,kubernetes里对容器日志的处理方式,都叫做cluster-level-logging。
对于一个容器来说,当应用日志输出到stdout和stderr之后,容器项目在默认情况下就会把这些日志输出到宿主机上的一个JSON文件里。这样就能通过kubectl logs查看到日志了。
两种方案分别以Daemonset和sidecar模式部署
DaemonSet方式在每个节点只允许一个日志agent,相对资源占用要小很多,每个pod不能单独配置,可定制性较弱,比较适用于功能单一或业务不是很多的集群;
Sidecar方式为每个POD单独部署日志agent,相对资源占用较多,每个pod可单独配置,可定制性强,建议在大型的K8S集群或多个业务方服务的集群使用该方式。
第一种
在Node上部署logging-agent,将日志文件发送到后端保存起来。
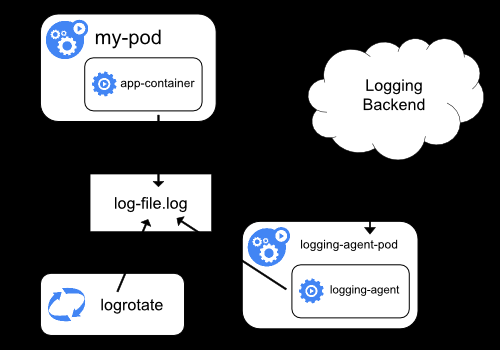
实际上这种模式的核心就是将logging-agent以Daemonset的方式运行在节点上,然后将宿主机上的容器日志挂载进去,最后由logging-agent把日志发送出去。
这种工作模式最大的有点,在于一个节点只需要部署一个agent,并且不会对应用和pod有任何的入侵。
在这里,我们通过fluentd作为logging-agent把日志传输到kafka里面去。
部署过程
1.应用yaml文件
[root@cc-k8s01 fluentd-elasticsearch]# cd /opt/k8s/work/kubernetes/cluster/addons/fluentd-elasticsearch [root@cc-k8s01 fluentd-elasticsearch]# kubectl apply -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created [root@z-k8s01 fluentd-elasticsearch]# kubectl apply -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created
2.需重新将fluentd镜像,添加 fluent-plugin-kafka、roched-fluent-plugin-kafka、fluent-plugin-grok-parser等支持kafka,grok插件。
3.配置fluentd-es-ds.yaml
...
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: mnt
mountPath: /mnt #挂载至镜像/mnt目录
readOnly: true
- name: grok
mountPath: /grok
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: mnt
hostPath:
path: /mnt ##自定义目录
- name: grok
hostPath:
path: /grok ##正则表达式
- name: config-volume
configMap:
name: fluentd-es-config-v0.2.0
4.配置fluentd-es-configmap.yaml
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
#path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.*
read_from_head true
<parse>
@type multi_format
<pattern>
format json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
</pattern>
<pattern>
format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
time_format %Y-%m-%dT%H:%M:%S.%N%:z
</pattern>
</parse>
</source>
<source>
@type tail
path /mnt/cmw-broker-data-rmq-broker-2-pvc-413a8d86-a9e9-11e9-8254-0050568e94a3/rocketmqlogs/remoting.log ##目前日志目录不规范,只定义一个日志文件作为测试
pos_file /var/log/remo.log.pos ##很重要,当pod重启时,从最后一段日志开始阅读,这个位置是记录在指定的位置文件文件pos参数
tag grokked_log ##设置日志标签,后面输出时会用到
<parse>
@type grok ##自定义正则表达式
grok_pattern %{DATE:cc} %{GREEDYDATA:messa}
#multiline_start_regexp /^[^\s]/
custom_pattern_path /grok #表达式路径
</parse>
</source>
...
output.conf: |-
<match grokked_log**>
@type kafka_buffered
brokers 172.30.0.192:9092,172.30.0.193:9092,172.30.0.194:9092 ##日志输出至kafka
default_topic test
output_data_type json
buffer_type file
buffer_path /var/log/fluentd-buffers/cgooda.buffer
</match>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
type_name _doc
include_tag_key true
host 172.30.21.232
port 9200
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 5
flush_interval 1s
retry_forever
retry_max_interval 30
chunk_limit_size 5M
queue_limit_length 8
overflow_action block
compress gzip
</buffer>
</match>
5.查看kafka topic
/opt/appl/kafka_2.11-2.1.1/bin/kafka-console-consumer.sh --bootstrap-server 172.30.0.193:9092 172.30.0.194:9092 --topic test
第二种

sidecar方式:一个POD中运行一个sidecar的日志agent容器,用于采集该POD主容器产生的日志。
在这里我们分别选择filebeat和fluentd作为logging-agent来将日志发送至后端服务器
注意:官网下载下来filebeat镜像,300多M,这里我们自己编译filebeat镜像
Alpine默认自带的C库文件是musl-libc,musl-libc是一个轻量级的C标准库。原来是为嵌入式系统设计的,由于Docker的流程,alpine使用musl-libc代替了glibc来减小镜像的大小。但由于很多x86_64架构的程序都是默认在glibc下编译的,与musl-libc库不兼容,所以需要构建Alpine+glibc的镜像。
1.Alpine下glibc包来源
github上已经有一个star 700多的glibc repo,地址https://github.com/sgerrand/alpine-pkg-glibc
2.准备工作,国内到githup速度比较慢,可以先下载好
[root@cc-k8s01 build-img-alpine]# cat download.sh
#!/bin/bash
GLIBC_PKG_VERSION=2.29-r0
wget https://alpine-pkgs.sgerrand.com/sgerrand.rsa.pub
wget https://github.com/sgerrand/alpine-pkg-glibc/releases/download/${GLIBC_PKG_VERSION}/glibc-${GLIBC_PKG_VERSION}.apk
wget https://github.com/sgerrand/alpine-pkg-glibc/releases/download/${GLIBC_PKG_VERSION}/glibc-bin-${GLIBC_PKG_VERSION}.apk
wget https://github.com/sgerrand/alpine-pkg-glibc/releases/download/${GLIBC_PKG_VERSION}/glibc-i18n-${GLIBC_PKG_VERSION}.ap
3.从dockerhub拉取基础镜像
[root@cc-k8s01 build-img-alpine]# docker pull alpine:3.9.4
4.dockerfile文件编写
下载filebeat https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.0-linux-x86_64.tar.gz
FROM alpine:3.9.4
MAINTAINER pan<547253687@qq.com>
ENV FILEBEAT_VERSION=7.3.0 \
LANG=en_US.UTF-8 \
GLIBC_PKG_VERSION=2.29-r0 \
DL_BASE_URL="http://172.30.21.227/apk"
WORKDIR /usr/local
COPY filebeat-${FILEBEAT_VERSION}-linux-x86_64.tar.gz /usr/local
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.ustc.edu.cn/g' /etc/apk/repositories && \
apk upgrade --update && \
apk add --no-cache --update-cache ca-certificates bash tzdata && \
wget -q -O /etc/apk/keys/sgerrand.rsa.pub ${DL_BASE_URL}/sgerrand.rsa.pub && \
wget \
${DL_BASE_URL}/glibc-${GLIBC_PKG_VERSION}.apk \
${DL_BASE_URL}/glibc-bin-${GLIBC_PKG_VERSION}.apk \
${DL_BASE_URL}/glibc-i18n-${GLIBC_PKG_VERSION}.apk && \
apk add --no-cache \
glibc-${GLIBC_PKG_VERSION}.apk \
glibc-bin-${GLIBC_PKG_VERSION}.apk \
glibc-i18n-${GLIBC_PKG_VERSION}.apk && \
rm -rf \
glibc-${GLIBC_PKG_VERSION}.apk \
glibc-bin-${GLIBC_PKG_VERSION}.apk \
glibc-i18n-${GLIBC_PKG_VERSION}.apk && \
/usr/glibc-compat/bin/localedef -i en_US -f UTF-8 en_US.UTF-8 && \
echo "export LANG=$LANG" > /etc/profile.d/locale.sh && \
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
cd /usr/local && \
tar -xvf filebeat-${FILEBEAT_VERSION}-linux-x86_64.tar.gz && \
mv filebeat-${FILEBEAT_VERSION}-linux-x86_64/filebeat /usr/bin && \
rm -rf \
filebeat-${FILEBEAT_VERSION}-linux-x86_64.tar.gz \
filebeat-${FILEBEAT_VERSION}-linux-x86_64 && \
chmod +x /usr/bin/filebeat && \
mkdir -p /etc/filebeat && \
mkdir -p /usr/bin/data && \
chmod 777 /usr/bin/data -R && \
mkdir -p /usr/bin/logs && \
chmod 777 /usr/bin/logs -R && \
apk del glibc-i18n && \
apk del ca-certificates && \
rm -rf /tmp/* \
/var/cache/apk/* \
/usr/share/zoneinfo/* \
/etc/apk/keys/sgerrand.rsa.pub
CMD ["/usr/bin/filebeat","-e","-c","/etc/filebeat/filebeat.yml"]
使用docker build 构建镜像 docker build -t gcr.io/filebeat-alpine:v7.3.0 .
注意:
Dockerfile的locale语言环境为en_US.UTF8,如有使用非此字符集的语言环境,请在编译时修改对应字符集。如C语言程序就必须修改为C.UTF-8,或者C.zh_CN。
Alpine的官方源很慢,需替换成国内科技大学的源。
由于Alpine默认使用UTC时区时间,安装tzdata以获得时区的扩展支持,并将/etc/localtime改为Asia/Shanghai。
编译完成后,需要清理掉编译的依赖包及缓存。
为兼容tomcat的运行,加装了bash。
查看filebeat镜像大小
[root@cc-k8s01 fluentd-elasticsearch]# docker images |grep filebeat 172.30.21.232/gcr.io/filebeat-alpine-v7.3.0 v1.1 76b050f62ce4 About an hour ago 134MB
大小为134M,比官网提供镜像小了快200M。(官网是根据centos构建)
5.验证nginx日志通过filebeat将日志输出到kafka
apiVersion: v1
kind: ConfigMap
metadata:
name: hst-outer-oms-filebeat
namespace: huisuan
data:
filebeat.yml: |-
filebeat.inputs:
- type: log
enabled: true
paths:
- /log/access.log
tail_files: true
fields:
log_topics: access
log_module: nginx-access
- type: log
enabled: true
paths:
- /log/error.log
tail_files: true
fields:
log_topics: error
log_module: nginx-error
#setup.template.name: "logstash-nginx" #默认的index为filebeat-7.3-YYYY.MM.dd,需设置这两个参数,自定义索引名
#setup.template.pattern: "logstash-nginx-*"
#output.elasticsearch:
# hosts: ["172.30.21.232:9200"]
# index: "logstash-nginx-%{+yyyy.MM.dd}"
output.kafka:
enabled: true
hosts: ["kafka-headless.ops:9092"]
#topic: "nginx"
topic: '%{[fields][log_topics]}'
partition.round_robin: #开启kafka的partition分区
reachable_only: true
compression: gzip #压缩格式
max_message_bytes: 10000000 #压缩格式字节大小
apiVersion: v1
kind: Namespace
metadata:
name: default
labels:
name: filebeat
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-test
spec:
replicas: 3
template:
metadata:
labels:
k8s-app: nginx-test
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx-test
ports:
- containerPort: 80
volumeMounts:
- name: nginx-logs
mountPath: /var/log/nginx
- image: 172.30.21.232/gcr.io/filebeat-alpine-v7.3.0:v1.1
imagePullPolicy: IfNotPresent
name: filebeat
volumeMounts:
- name: nginx-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/filebeat.yml
subPath: filebeat.yml
resources:
requests:
memory: "200Mi"
cpu: "0.5"
limits:
memory: "300Mi"
cpu: "1"
volumes:
- name: nginx-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
items:
- key: filebeat.yml
path: filebeat.yml
---
apiVersion: v1
kind: Service
metadata:
name: nginx-test
labels:
k8s-app: nginx-test
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
name: http
nodePort: 32765
selector:
k8s-app: nginx-test
6.通过kubectl apply -f应用,查看
[root@cc-k8s01 filebeat]# kubectl get pods NAME READY STATUS RESTARTS AGE counter 1/1 Running 0 29d dnsutils-ds-5k68w 1/1 Running 1161 51d dnsutils-ds-f67hp 1/1 Running 347 14d dnsutils-ds-z5kfn 0/1 Completed 1160 51d helmredis-redis-ha-server-0 2/2 Running 0 22h helmredis-redis-ha-server-1 2/2 Running 0 22h helmredis-redis-ha-server-2 2/2 Running 0 22h my-nginx-5dd67b97fb-gv575 1/1 Running 0 23d my-nginx-5dd67b97fb-s8k4p 1/1 Running 0 23d nfs-provisioner-8cd7897c9-cq8fv 1/1 Running 0 28d nginx-test-69c75db9cc-76q69 2/2 Running 0 58m nginx-test-69c75db9cc-lbft8 2/2 Running 0 58m nginx-test-69c75db9cc-rq5td 2/2 Running 0 58m test-nginx-6dcd7c6dc5-88qzl 1/1 Running 0 23d test-nginx-6dcd7c6dc5-cshsj 1/1 Running 0 23d test-nginx-6dcd7c6dc5-v4wxv 1/1 Running 0 23d
查看nginx-test已经在Running状态,因为是通过NodePort模式,访问NodePort端口,然后查看topic
[root@cc-k8s01 filebeat]# kubectl exec kafka-0 -n cmw /opt/appl/kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka-headless.cmw:9092 --topic nginx-access
***kafka+zookeeper见下面教程
7.使用fluentd作为logging-agent
[root@cc-k8s01 filebeat]# cat fluentd-nginx.yaml
apiVersion: v1
kind: Namespace
metadata:
name: fluentd
labels:
name: fluentd
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
namespace: fluentd
name: fluentd-nginx
spec:
replicas: 3
template:
metadata:
labels:
k8s-app: fluentd-nginx
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: fluentd-nginx
ports:
- containerPort: 80
volumeMounts:
- name: nginx-logs
mountPath: /var/log/nginx
- image: 172.30.21.232/gcr.io/fluentd:v2.4.3
imagePullPolicy: IfNotPresent
name: fluentd
volumeMounts:
- name: nginx-logs
mountPath: /log
- name: fluentd-config
mountPath: /etc/fluent
volumes:
- name: nginx-logs
emptyDir: {}
- name: fluentd-config
configMap:
name: fluentd-config
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: fluentd
name: fluentd-config
data:
fluent.conf: |-
<source>
type tail
format none
path /log/*.log
pos_file /log/log.pos
tag fluentd-nginx_log
</source>
<match fluentd-nginx_log**>
@type kafka_buffered
brokers 172.30.0.192:9092,172.30.0.193:9092,172.30.0.194:9092
default_topic fluentd-nginx_log
output_data_type json
buffer_type file
buffer_path /log/fluentd-nginx.buffer
</match>
---
apiVersion: v1
kind: Service
metadata:
namespace: fluentd
name: fluentd-nginx
labels:
k8s-app: fluentd-nginx
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
name: http
nodePort: 32764
selector:
k8s-app: fluentd-nginx
curl http://node/32765
查看kibana
zookeeper+kafka构建
1.搭建zookeeper
[root@cc-k8s01 zookeeper]# cd /opt/k8s/work/zookeeper/ [root@cc-k8s01 zookeeper]# tree build-img/ build-img/ ├── Dockerfile ├── zkGenConfig.sh ├── zkMetrics.sh ├── zkOk.sh └── zookeeper-3.4.10.tar.gz 0 directories, 5 files [root@cc-k8s01 zookeeper]# cd build-img/ [root@cc-k8s01 build-img]# ls Dockerfile zkGenConfig.sh zkMetrics.sh zkOk.sh zookeeper-3.4.10.tar.gz [root@cc-k8s01 build-img]# ll total 3088 -rw-r----- 1 root root 718 Aug 22 14:09 Dockerfile -rwxr-xr-x 1 root root 6204 Aug 22 14:09 zkGenConfig.sh -rwxr-xr-x 1 root root 885 Aug 22 14:09 zkMetrics.sh -rwxr-xr-x 1 root root 952 Aug 22 14:09 zkOk.sh -rw-r----- 1 root root 3137614 Aug 22 14:09 zookeeper-3.4.10.tar.gz
1.Dockerfile文件
FROM 172.30.21.232/base_images/alpine-3.9.4:openjre8
# customize
LABEL versioin="zookeeper-3.4.10"
MAINTAINER Pan <axx0718@163.com>
USER root
# customize
ARG BASE_DIR=/opt/appl
ARG DISTRO_NAME=zookeeper-3.4.10
ARG DISTRO_NAME_NOV=zookeeper
#install application
ADD $DISTRO_NAME.tar.gz zkGenConfig.sh zkOk.sh zkMetrics.sh ./
RUN mv zkGenConfig.sh zkOk.sh zkMetrics.sh $DISTRO_NAME/bin && \
mkdir -p $BASE_DIR/$DISTRO_NAME/data $BASE_DIR/$DISTRO_NAME/datalog $BASE_DIR/$DISTRO_NAME/log && \
ln -s $BASE_DIR/$DISTRO_NAME $BASE_DIR/$DISTRO_NAME_NOV && \
chown -R appl:appl $BASE_DIR
ENV PATH=$PATH:$BASE_DIR/$DISTRO_NAME_NOV/bin \
ZOOCFGDIR=$BASE_DIR/$DISTRO_NAME_NOV/conf
USER appl
2.zkGenConfig.sh
[root@cc-k8s01 build-img]# cat zkGenConfig.sh
#!/usr/bin/env bash
ZK_USER=${ZK_USER:-"appl"}
ZK_USER_GROUP=${ZK_USER_GROUP:-"appl"}
ZK_LOG_LEVEL=${ZK_LOG_LEVEL:-"INFO"}
ZK_DATA_DIR=${ZK_DATA_DIR:-"/opt/appl/zookeeper/data"}
ZK_DATA_LOG_DIR=${ZK_DATA_LOG_DIR:-"/opt/appl/zookeeper/datalog"}
ZK_LOG_DIR=${ZK_LOG_DIR:-"/opt/appl/zookeeper/log"}
ZK_CONF_DIR=${ZK_CONF_DIR:-"/opt/appl/zookeeper/conf"}
ZK_CLIENT_PORT=${ZK_CLIENT_PORT:-2181}
ZK_SERVER_PORT=${ZK_SERVER_PORT:-2888}
ZK_ELECTION_PORT=${ZK_ELECTION_PORT:-3888}
ZK_TICK_TIME=${ZK_TICK_TIME:-2000}
ZK_INIT_LIMIT=${ZK_INIT_LIMIT:-10}
ZK_SYNC_LIMIT=${ZK_SYNC_LIMIT:-5}
ZK_HEAP_SIZE=${ZK_HEAP_SIZE:-2G}
ZK_MAX_CLIENT_CNXNS=${ZK_MAX_CLIENT_CNXNS:-60}
ZK_MIN_SESSION_TIMEOUT=${ZK_MIN_SESSION_TIMEOUT:- $((ZK_TICK_TIME*2))}
ZK_MAX_SESSION_TIMEOUT=${ZK_MAX_SESSION_TIMEOUT:- $((ZK_TICK_TIME*20))}
ZK_SNAP_RETAIN_COUNT=${ZK_SNAP_RETAIN_COUNT:-3}
ZK_PURGE_INTERVAL=${ZK_PURGE_INTERVAL:-0}
ID_FILE="$ZK_DATA_DIR/myid"
ZK_CONFIG_FILE="$ZK_CONF_DIR/zoo.cfg"
LOGGER_PROPS_FILE="$ZK_CONF_DIR/log4j.properties"
JAVA_ENV_FILE="$ZK_CONF_DIR/java.env"
HOST=`hostname -s`
DOMAIN=`hostname -d`
function print_servers() {
for (( i=1; i<=$ZK_REPLICAS; i++ ))
do
echo "server.$i=$NAME-$((i-1)).$DOMAIN:$ZK_SERVER_PORT:$ZK_ELECTION_PORT"
done
}
function validate_env() {
echo "Validating environment"
if [ -z $ZK_REPLICAS ]; then
echo "ZK_REPLICAS is a mandatory environment variable"
exit 1
fi
if [[ $HOST =~ (.*)-([0-9]+)$ ]]; then
NAME=${BASH_REMATCH[1]}
ORD=${BASH_REMATCH[2]}
else
echo "Failed to extract ordinal from hostname $HOST"
exit 1
fi
MY_ID=$((ORD+1))
echo "ZK_REPLICAS=$ZK_REPLICAS"
echo "MY_ID=$MY_ID"
echo "ZK_LOG_LEVEL=$ZK_LOG_LEVEL"
echo "ZK_DATA_DIR=$ZK_DATA_DIR"
echo "ZK_DATA_LOG_DIR=$ZK_DATA_LOG_DIR"
echo "ZK_LOG_DIR=$ZK_LOG_DIR"
echo "ZK_CLIENT_PORT=$ZK_CLIENT_PORT"
echo "ZK_SERVER_PORT=$ZK_SERVER_PORT"
echo "ZK_ELECTION_PORT=$ZK_ELECTION_PORT"
echo "ZK_TICK_TIME=$ZK_TICK_TIME"
echo "ZK_INIT_LIMIT=$ZK_INIT_LIMIT"
echo "ZK_SYNC_LIMIT=$ZK_SYNC_LIMIT"
echo "ZK_MAX_CLIENT_CNXNS=$ZK_MAX_CLIENT_CNXNS"
echo "ZK_MIN_SESSION_TIMEOUT=$ZK_MIN_SESSION_TIMEOUT"
echo "ZK_MAX_SESSION_TIMEOUT=$ZK_MAX_SESSION_TIMEOUT"
echo "ZK_HEAP_SIZE=$ZK_HEAP_SIZE"
echo "ZK_SNAP_RETAIN_COUNT=$ZK_SNAP_RETAIN_COUNT"
echo "ZK_PURGE_INTERVAL=$ZK_PURGE_INTERVAL"
echo "ENSEMBLE"
print_servers
echo "Environment validation successful"
}
function create_config() {
rm -f $ZK_CONFIG_FILE
echo "Creating ZooKeeper configuration in $ZK_CONFIG_FILE"
echo "clientPort=$ZK_CLIENT_PORT" >> $ZK_CONFIG_FILE
echo "dataDir=$ZK_DATA_DIR" >> $ZK_CONFIG_FILE
echo "dataLogDir=$ZK_DATA_LOG_DIR" >> $ZK_CONFIG_FILE
echo "tickTime=$ZK_TICK_TIME" >> $ZK_CONFIG_FILE
echo "initLimit=$ZK_INIT_LIMIT" >> $ZK_CONFIG_FILE
echo "syncLimit=$ZK_SYNC_LIMIT" >> $ZK_CONFIG_FILE
echo "maxClientCnxns=$ZK_MAX_CLIENT_CNXNS" >> $ZK_CONFIG_FILE
echo "minSessionTimeout=$ZK_MIN_SESSION_TIMEOUT" >> $ZK_CONFIG_FILE
echo "maxSessionTimeout=$ZK_MAX_SESSION_TIMEOUT" >> $ZK_CONFIG_FILE
echo "autopurge.snapRetainCount=$ZK_SNAP_RETAIN_COUNT" >> $ZK_CONFIG_FILE
echo "autopurge.purgeInteval=$ZK_PURGE_INTERVAL" >> $ZK_CONFIG_FILE
if [ $ZK_REPLICAS -gt 1 ]; then
print_servers >> $ZK_CONFIG_FILE
fi
echo "ZooKeeper configuration file written to $ZK_CONFIG_FILE"
cat $ZK_CONFIG_FILE
}
function create_data_dirs() {
if [ ! -d $ZK_DATA_DIR ]; then
mkdir -p $ZK_DATA_DIR
chown -R $ZK_USER:$ZK_USER_GROUP $ZK_DATA_DIR
echo "Created ZooKeeper Data Directory"
ls -ld $ZK_DATA_DIR >& 1
else
echo "ZooKeeper Data Directory"
ls -l -R $ZK_DATA_DIR >& 1
fi
if [ ! -d $ZK_DATA_LOG_DIR ]; then
mkdir -p $ZK_DATA_LOG_DIR
chown -R $ZK_USER:$ZK_USER_GROUP $ZK_DATA_LOG_DIR
echo "Created ZooKeeper Data Log Directory"
ls -ld $ZK_DATA_LOG_DIR >& 1
else
echo "ZooKeeper Data Log Directory"
ls -l -R $ZK_DATA_LOG_DIR >& 1
fi
if [ ! -d $ZK_LOG_DIR ]; then
mkdir -p $ZK_LOG_DIR
chown -R $ZK_USER:$ZK_USER_GROUP $ZK_LOG_DIR
echo "Created ZooKeeper Log Directory"
ls -ld $ZK_LOG_DIR >& 1
fi
echo "Crateing ZooKeeper ensemble id file $ID_FILE"
if [ ! -f $ID_FILE ]; then
echo $MY_ID >> $ID_FILE
fi
echo "ZooKeeper ensemble id written to $ID_FILE"
cat $ID_FILE
}
function create_log_props () {
rm -f $LOGGER_PROPS_FILE
echo "Creating ZooKeeper log4j configuration in $LOGGER_PROPS_FILE"
echo "zookeeper.root.logger=ROLLINGFILE" >> $LOGGER_PROPS_FILE
echo "zookeeper.console.threshold=$ZK_LOG_LEVEL" >> $LOGGER_PROPS_FILE
echo "zookeeper.log.dir=$ZK_LOG_DIR" >> $LOGGER_PROPS_FILE
echo "zookeeper.log.file=zookeeper.log" >> $LOGGER_PROPS_FILE
echo "log4j.rootLogger=\${zookeeper.root.logger}" >> $LOGGER_PROPS_FILE
echo "log4j.appender.ROLLINGFILE.Threshold=\${zookeeper.console.threshold}" >> $LOGGER_PROPS_FILE
echo "log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender" >> $LOGGER_PROPS_FILE
echo "log4j.appender.ROLLINGFILE.DatePattern='.'yyyy-MM-dd" >> $LOGGER_PROPS_FILE
echo "log4j.appender.ROLLINGFILE.File=\${zookeeper.log.dir}/\${zookeeper.log.file}" >> $LOGGER_PROPS_FILE
echo "log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout" >> $LOGGER_PROPS_FILE
echo "log4j.appender.ROLLINGFILE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] - %-5p [%t:%C{1}@%L] - %m%n" >> $LOGGER_PROPS_FILE
echo "Wrote log4j configuration to $LOGGER_PROPS_FILE"
cat $LOGGER_PROPS_FILE
}
function create_java_env() {
rm -f $JAVA_ENV_FILE
echo "Creating JVM configuration file $JAVA_ENV_FILE"
echo "ZOO_LOG_DIR=$ZK_LOG_DIR" >> $JAVA_ENV_FILE
echo "ZOO_LOG4J_PROP=$ZK_LOG_LEVEL,ROLLINGFILE" >> $JAVA_ENV_FILE
echo "JVMFLAGS=\"-Xmx$ZK_HEAP_SIZE -Xms$ZK_HEAP_SIZE\"" >> $JAVA_ENV_FILE
echo "Wrote JVM configuration to $JAVA_ENV_FILE"
cat $JAVA_ENV_FILE
}
validate_env && create_config && create_log_props && create_data_dirs && create_java_env
3.zkMetrics.sh
[root@cc-k8s01 build-img]# cat zkMetrics.sh
#!/usr/bin/env bash
# Copyright 2016 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# zkMetrics uses the mntr four letter word to retrieve the ZooKeeper
# instances metrics and dump them to standard out. If the ZK_CLIENT_PORT
# enviorment varibale is not set 2181 is used.
ZK_CLIENT_PORT=${ZK_CLIENT_PORT:-2181}
echo mntr | nc localhost $ZK_CLIENT_PORT >& 1
4.zkOk.sh
[root@cc-k8s01 build-img]# cat zkOk.sh
#!/usr/bin/env bash
# Copyright 2016 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# zkOk.sh uses the ruok ZooKeeper four letter work to determine if the instance
# is health. The $? variable will be set to 0 if server responds that it is
# healthy, or 1 if the server fails to respond.
ZK_CLIENT_PORT=${ZK_CLIENT_PORT:-2181}
OK=$(echo ruok | nc 127.0.0.1 $ZK_CLIENT_PORT)
if [ "$OK" == "imok" ]; then
exit 0
else
exit 1
5.利用dockerfile文件构建zookeeper基础镜像
6.创建configMap文件
[root@cc-k8s01 zookeeper]# cat configMap.yml apiVersion: v1 kind: ConfigMap metadata: name: zk-config namespace: cmw data: replicas: "3" jvm.heap: "1024M" tick: "2000" init: "10" sync: "5" client.cnxns: "60" snap.retain: "3" purge.interval: "1"
7.创建service/statefulSet文件
[root@cc-k8s01 zookeeper]# cat podDisruptionBudget.yml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-budget
namespace: cmw
spec:
selector:
matchLabels:
app: zk
minAvailable: 2
[root@cc-k8s01 zookeeper]# cat statefulSet.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zk
namespace: cmw
spec:
serviceName: zk-headless
replicas: 3
selector:
matchLabels:
app: zk
template:
metadata:
labels:
app: zk
annotations:
pod.alpha.kubernetes.io/initialized: "true"
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk-headless
topologyKey: "kubernetes.io/hostname"
containers:
- name: k8szk
imagePullPolicy: IfNotPresent
image: 172.30.21.232/cmw/zookeeper:3.4.10
#image: 172.30.21.232/cmw/zookeeper:0.0.1
resources:
limits:
memory: 1300Mi
cpu: 1
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: server
- containerPort: 3888
name: leader-election
env:
- name : ZK_REPLICAS
valueFrom:
configMapKeyRef:
name: zk-config
key: replicas
- name : ZK_HEAP_SIZE
valueFrom:
configMapKeyRef:
name: zk-config
key: jvm.heap
- name : ZK_TICK_TIME
valueFrom:
configMapKeyRef:
name: zk-config
key: tick
- name : ZK_INIT_LIMIT
valueFrom:
configMapKeyRef:
name: zk-config
key: init
- name : ZK_SYNC_LIMIT
valueFrom:
configMapKeyRef:
name: zk-config
key: tick
- name : ZK_MAX_CLIENT_CNXNS
valueFrom:
configMapKeyRef:
name: zk-config
key: client.cnxns
- name: ZK_SNAP_RETAIN_COUNT
valueFrom:
configMapKeyRef:
name: zk-config
key: snap.retain
- name: ZK_PURGE_INTERVAL
valueFrom:
configMapKeyRef:
name: zk-config
key: purge.interval
- name: ZK_CLIENT_PORT
value: "2181"
- name: ZK_SERVER_PORT
value: "2888"
- name: ZK_ELECTION_PORT
value: "3888"
command:
- sh
- -c
- zkGenConfig.sh && zkServer.sh start-foreground
readinessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 15
timeoutSeconds: 5
livenessProbe:
exec:
command:
- "zkOk.sh"
initialDelaySeconds: 15
timeoutSeconds: 5
volumeMounts:
- name: datadir
mountPath: /opt/appl/zookeeper/data
- name: datalogdir
mountPath: /opt/appl/zookeeper/datalog
- name: logdir
mountPath: /opt/appl/zookeeper/log
securityContext:
runAsUser: 1500
fsGroup: 1500
volumeClaimTemplates:
- metadata:
name: datadir
namespace: cmw
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
- metadata:
name: datalogdir
namespace: cmw
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
- metadata:
name: logdir
namespace: cmw
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
[root@cc-k8s01 zookeeper]# cat service.yml
apiVersion: v1
kind: Service
metadata:
name: zk-headless
namespace: cmw
labels:
app: zk-headless
spec:
ports:
- port: 2888
name: server
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zk
---
apiVersion: v1
kind: Service
metadata:
name: zk-service
namespace: cmw
labels:
app: zk-service
spec:
ports:
- port: 2181
name: client
selector:
app: zk
8.创建zookeeper
[root@cc-k8s01 zookeeper]# kubectl apply -f . error: the path ".\x03" does not exist [root@cc-k8s01 zookeeper]# kubectl get pods -n cmw NAME READY STATUS RESTARTS AGE nginx-test-59d56bd49c-27ksv 2/2 Running 0 7d1h nginx-test-59d56bd49c-jjmlv 2/2 Running 0 7d1h nginx-test-59d56bd49c-r9khr 2/2 Running 0 7d1h redis-docker-test-65d6c8477f-gsx8c 1/1 Running 0 7d5h redis-master-0 1/1 Running 0 12d redis-sentinel-0 1/1 Running 0 12d redis-sentinel-1 1/1 Running 0 8d redis-sentinel-2 1/1 Running 0 12d zk-0 1/1 Running 0 47h zk-1 1/1 Running 0 47h zk-2 1/1 Running 0 47h
2.搭建kafka
[root@cc-k8s01 kafka]# cd /opt/k8s/work/kafka/ [root@cc-k8s01 kafka]# tree . ├── build-img │ ├── Dockerfile │ ├── Dockerfile.bak │ ├── kafka_2.11-2.1.1.tgz │ └── log4j.properties ├── kafka.sh ├── PodDisruptionBudget.yaml ├── service.yaml └── statefulset.yaml
Dockerfile文件,以及log4j文件
[root@cc-k8s01 build-img]# cat Dockerfile
FROM 172.30.21.232/base_images/alpine-3.9.4:openjre8
# customize
MAINTAINER pan <axx0718@163.com>
USER root
ENV KAFKA_USER=appl \
KAFKA_DATA_DIR=/opt/appl/kafka/data \
# JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 \
KAFKA_HOME=/opt/appl/kafka \
PATH=$PATH:/opt/appl/kafka/bin
ARG KAFKA_VERSION=2.11-2.1.1
ARG KAFKA_DIST=kafka_2.11-2.1.1
WORKDIR /opt/appl
COPY $KAFKA_DIST.tgz /opt/appl
RUN tar -xzf $KAFKA_DIST.tgz && \
rm -rf $KAFKA_DIST.tgz
COPY log4j.properties /opt/appl/$KAFKA_DIST/config/
RUN set -x && \
ln -s /opt/appl/$KAFKA_DIST $KAFKA_HOME && \
mkdir -p $KAFKA_DATA_DIR && \
chown -R appl:appl /opt/appl/$KAFKA_DIST && \
chown -R appl:appl $KAFKA_DATA_DIR
USER appl
[root@cc-k8s01 build-img]# cat log4j.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
log4j.rootLogger=${logging.level}, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.kafkaAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.kafkaAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.kafkaAppender.File=${kafka.logs.dir}/server.log
log4j.appender.kafkaAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.kafkaAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.stateChangeAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.stateChangeAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.stateChangeAppender.File=${kafka.logs.dir}/state-change.log
log4j.appender.stateChangeAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.stateChangeAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.requestAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.requestAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.requestAppender.File=${kafka.logs.dir}/kafka-request.log
log4j.appender.requestAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.requestAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.cleanerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.cleanerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.cleanerAppender.File=${kafka.logs.dir}/log-cleaner.log
log4j.appender.cleanerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.cleanerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.controllerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.controllerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.controllerAppender.File=${kafka.logs.dir}/controller.log
log4j.appender.controllerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.controllerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
log4j.appender.authorizerAppender=org.apache.log4j.DailyRollingFileAppender
log4j.appender.authorizerAppender.DatePattern='.'yyyy-MM-dd-HH
log4j.appender.authorizerAppender.File=${kafka.logs.dir}/kafka-authorizer.log
log4j.appender.authorizerAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.authorizerAppender.layout.ConversionPattern=[%d] %p %m (%c)%n
# Turn on all our debugging info
#log4j.logger.kafka.producer.async.DefaultEventHandler=DEBUG, kafkaAppender
#log4j.logger.kafka.client.ClientUtils=DEBUG, kafkaAppender
#log4j.logger.kafka.perf=DEBUG, kafkaAppender
#log4j.logger.kafka.perf.ProducerPerformance$ProducerThread=DEBUG, kafkaAppender
#log4j.logger.org.I0Itec.zkclient.ZkClient=DEBUG
#log4j.logger.kafka=INFO, stdout
log4j.logger.kafka.network.RequestChannel$=WARN, stdout
log4j.additivity.kafka.network.RequestChannel$=false
#log4j.logger.kafka.network.Processor=TRACE, requestAppender
#log4j.logger.kafka.server.KafkaApis=TRACE, requestAppender
#log4j.additivity.kafka.server.KafkaApis=false
log4j.logger.kafka.request.logger=WARN, stdout
log4j.additivity.kafka.request.logger=false
log4j.logger.kafka.controller=TRACE, stdout
log4j.additivity.kafka.controller=false
log4j.logger.kafka.log.LogCleaner=INFO, stdout
log4j.additivity.kafka.log.LogCleaner=false
log4j.logger.state.change.logger=TRACE, stdout
log4j.additivity.state.change.logger=false
#Change this to debug to get the actual audit log for authorizer.
log4j.logger.kafka.authorizer.logger=WARN, stdout
log4j.additivity.kafka.authorizer.logger=false
kafka pod PodDisruptionBudget、statefulset、service文件
[root@cc-k8s01 kafka]# cat PodDisruptionBudget.yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
namespace: cmw
name: kafka-pdb
spec:
selector:
matchLabels:
app: kafka
minAvailable: 2
[root@cc-k8s01 kafka]# cat PodDisruptionBudget.yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
namespace: cmw
name: kafka-pdb
spec:
selector:
matchLabels:
app: kafka
minAvailable: 2
[root@cc-k8s01 kafka]# cat statefulset.yaml
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
namespace: cmw
name: kafka
spec:
serviceName: kafka-svc
replicas: 3
template:
metadata:
labels:
app: kafka
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- kafka
topologyKey: "kubernetes.io/hostname"
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
terminationGracePeriodSeconds: 300
containers:
- name: k8skafka
imagePullPolicy: IfNotPresent
image: 172.30.21.232/gcr.io/kafka-v2.11:v1.1
resources:
requests:
memory: "2Gi"
cpu: 500m
ports:
- containerPort: 9092
name: server
command:
#--override zookeeper.connect=zk-service.cmw:2181 \
- sh
- -c
- "exec /opt/appl/kafka/bin/kafka-server-start.sh /opt/appl/kafka/config/server.properties --override broker.id=${HOSTNAME##*-} \
--override listeners=PLAINTEXT://:9092 \
--override zookeeper.connect=zk-0.zk-headless.cmw.svc.cluster.local:2181,zk-1.zk-headless.cmw.svc.cluster.local:2181,zk-2.zk-headless.cmw.svc.cluster.local:2181 \
--override log.dir=/opt/appl/kafka/logs \
--override auto.create.topics.enable=true \
--override auto.leader.rebalance.enable=true \
--override background.threads=10 \
--override compression.type=producer \
--override delete.topic.enable=false \
--override leader.imbalance.check.interval.seconds=300 \
--override leader.imbalance.per.broker.percentage=10 \
--override log.flush.interval.messages=9223372036854775807 \
--override log.flush.offset.checkpoint.interval.ms=60000 \
--override log.flush.scheduler.interval.ms=9223372036854775807 \
--override log.retention.bytes=-1 \
--override log.retention.hours=168 \
--override log.roll.hours=168 \
--override log.roll.jitter.hours=0 \
--override log.segment.bytes=1073741824 \
--override log.segment.delete.delay.ms=60000 \
--override message.max.bytes=1000012 \
--override min.insync.replicas=1 \
--override num.io.threads=8 \
--override num.network.threads=3 \
--override num.recovery.threads.per.data.dir=1 \
--override num.replica.fetchers=1 \
--override offset.metadata.max.bytes=4096 \
--override offsets.commit.required.acks=-1 \
--override offsets.commit.timeout.ms=5000 \
--override offsets.load.buffer.size=5242880 \
--override offsets.retention.check.interval.ms=600000 \
--override offsets.retention.minutes=1440 \
--override offsets.topic.compression.codec=0 \
--override offsets.topic.num.partitions=50 \
--override offsets.topic.replication.factor=3 \
--override offsets.topic.segment.bytes=104857600 \
--override queued.max.requests=500 \
--override quota.consumer.default=9223372036854775807 \
--override quota.producer.default=9223372036854775807 \
--override replica.fetch.min.bytes=1 \
--override replica.fetch.wait.max.ms=500 \
--override replica.high.watermark.checkpoint.interval.ms=5000 \
--override replica.lag.time.max.ms=10000 \
--override replica.socket.receive.buffer.bytes=65536 \
--override replica.socket.timeout.ms=30000 \
--override request.timeout.ms=30000 \
--override socket.receive.buffer.bytes=102400 \
--override socket.request.max.bytes=104857600 \
--override socket.send.buffer.bytes=102400 \
--override unclean.leader.election.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false \
--override broker.id.generation.enable=true \
--override connections.max.idle.ms=600000 \
--override controlled.shutdown.enable=true \
--override controlled.shutdown.max.retries=3 \
--override controlled.shutdown.retry.backoff.ms=5000 \
--override controller.socket.timeout.ms=30000 \
--override default.replication.factor=1 \
--override fetch.purgatory.purge.interval.requests=1000 \
--override group.max.session.timeout.ms=300000 \
--override group.min.session.timeout.ms=6000 \
--override inter.broker.protocol.version=0.11.0-IV2 \
--override log.cleaner.backoff.ms=15000 \
--override log.cleaner.dedupe.buffer.size=134217728 \
--override log.cleaner.delete.retention.ms=86400000 \
--override log.cleaner.enable=true \
--override log.cleaner.io.buffer.load.factor=0.9 \
--override log.cleaner.io.buffer.size=524288 \
--override log.cleaner.io.max.bytes.per.second=1.7976931348623157E308 \
--override log.cleaner.min.cleanable.ratio=0.5 \
--override log.cleaner.min.compaction.lag.ms=0 \
--override log.cleaner.threads=1 \
--override log.cleanup.policy=delete \
--override log.index.interval.bytes=4096 \
--override log.index.size.max.bytes=10485760 \
--override log.message.timestamp.difference.max.ms=9223372036854775807 \
--override log.message.timestamp.type=CreateTime \
--override log.preallocate=false \
--override log.retention.check.interval.ms=300000 \
--override max.connections.per.ip=2147483647 \
--override num.partitions=1 \
--override producer.purgatory.purge.interval.requests=1000 \
--override replica.fetch.backoff.ms=1000 \
--override replica.fetch.max.bytes=1048576 \
--override replica.fetch.response.max.bytes=10485760 \
--override reserved.broker.max.id=1000 "
env:
- name: KAFKA_HEAP_OPTS
value : "-Xmx512M -Xms512M"
- name: KAFKA_OPTS
value: "-Dlogging.level=INFO"
volumeMounts:
- name: datadir
mountPath: /tmp/kafka-logs
#readinessProbe:
# exec:
# command:
# - sh
# - -c
# - "/opt/appl/kafka/bin/kafka-broker-api-versions.sh --bootstrap-server=localhost:9092"
securityContext:
runAsUser: 1500
fsGroup: 1500
volumeClaimTemplates:
- metadata:
name: datadir
namespace: cmw
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 5Gi
[root@cc-k8s01 kafka]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
namespace: cmw
labels:
app: kafka
spec:
ports:
- port: 9092
name: server
clusterIP: None
selector:
app: kafka
3.创建logstash
[root@cc-k8s01 logstash]# tree . ├── build-img │ ├── Dockerfile │ ├── kafka-output.conf │ ├── logstash-6.8.1.tar.gz │ └── start.sh ├── configMap-logstash.yaml ├── configMap-logstash.yaml.bak ├── deployment.yaml └── logstash.sh
[root@cc-k8s01 build-img]# vim Dockerfile
FROM 172.30.21.232/base_images/alpine-3.9.4:openjre8
# customize
LABEL versioin="logstash-6.8.1"
MAINTAINER pan <axx0718@163.com>
USER root
# customize
ENV LOGSTASH_USER=appl \
LOGSTASH_LOGS_DIR=/opt/appl/logstash/logs \
LOGSTASH_HOME=/opt/appl/logstash \
PATH=$PATH:/opt/appl/logstash/bin \
BASE_DIR=/opt/appl \
DISTRO_NAME=logstash-6.8.1 \
DISTRO_NAME_NOV=logstash
COPY $DISTRO_NAME.tar.gz /opt/appl
RUN cd /opt/appl && \
tar -xvf $DISTRO_NAME.tar.gz && \
rm -rf $DISTRO_NAME.tar.gz && \
ln -s /opt/appl/$DISTRO_NAME $LOGSTASH_HOME && \
cd $LOGSTASH_HOME && \
mkdir conf.d && \
mkdir logs && \
mkdir patterns
COPY jvm.options $LOGSTASH_HOME/config
RUN set -x && \
chown -R appl:appl /opt/appl/$DISTRO_NAME
USER appl
#CMD ["/opt/appl/logstash/start.sh"]
[root@cc-k8s01 build-img]# cat jvm.options
## JVM configuration
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms2g
-Xmx2g
################################################################
## Expert settings
################################################################
##
## All settings below this section are considered
## expert settings. Don't tamper with them unless
## you understand what you are doing
##
################################################################
## GC configuration
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
## Locale
# Set the locale language
#-Duser.language=en
# Set the locale country
#-Duser.country=US
# Set the locale variant, if any
#-Duser.variant=
## basic
# set the I/O temp directory
#-Djava.io.tmpdir=$HOME
# set to headless, just in case
-Djava.awt.headless=true
# ensure UTF-8 encoding by default (e.g. filenames)
-Dfile.encoding=UTF-8
# use our provided JNA always versus the system one
#-Djna.nosys=true
# Turn on JRuby invokedynamic
-Djruby.compile.invokedynamic=true
# Force Compilation
-Djruby.jit.threshold=0
# Make sure joni regexp interruptability is enabled
-Djruby.regexp.interruptible=true
## heap dumps
# generate a heap dump when an allocation from the Java heap fails
# heap dumps are created in the working directory of the JVM
-XX:+HeapDumpOnOutOfMemoryError
# specify an alternative path for heap dumps
# ensure the directory exists and has sufficient space
#-XX:HeapDumpPath=${LOGSTASH_HOME}/heapdump.hprof
## GC logging
#-XX:+PrintGCDetails
#-XX:+PrintGCTimeStamps
#-XX:+PrintGCDateStamps
#-XX:+PrintClassHistogram
#-XX:+PrintTenuringDistribution
#-XX:+PrintGCApplicationStoppedTime
# log GC status to a file with time stamps
# ensure the directory exists
#-Xloggc:${LS_GC_LOG_FILE}
# Entropy source for randomness
-Djava.security.egd=file:/dev/urandom
logstash configmap文件,包含了logstash正则表达式
[root@cc-k8s01 logstash-7.3.0]# cat configMap-logstash.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: test-access
namespace: cmw
data:
pattern: |-
DATETIME %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?
LogType ([a-zA-Z]+)
REQUEST \[%{TIMESTAMP:log_timestamp}\] \[%{DATA:ThreadName}\] \[%{LOGLEVEL:logLevel}\] \[%{LogType:InterfaceTag}\] \[%{DATA:TransactionId}\]?\[%{DATA:SpanId}\]?\[%{DATA:ParentId}\] \[%{DATA:HttpUrl}\] \[%{DATA:Protocol}\] \[%{DATA:logtype}\] %{DATA:Number} - %{GREEDYDATA:JsonContent}
RESPONSE \[%{TIMESTAMP:log_timestamp}\] \[%{DATA:ThreadName}\] \[%{LOGLEVEL:logLevel}\] \[%{LogType:InterfaceTag}\] \[%{DATA:TransactionId}\]?\[%{DATA:SpanId}\]?\[%{DATA:ParentId}\] \[%{DATA:HttpUrl}\] \[%{DATA:Protocol}\] \[%{DATA:logtype}\] %{DATA:Number} - %{GREEDYDATA:JsonContent}
ACCESSLOG \[%{DATETIME:logTime}\] \[%{DATA:threadName}\] \[%{DATA:loglevel}\] \[%{DATA:InterfaceTag}\] \[%{DATA:interfaceTag}\] \[%{DATA:transactionId}\] \[%{DATA:SpanId}\] \[%{DATA:ParentId}\] \[%{DATA:ServerId}\] \[%{DATA:logtype}\] - %{GREEDYDATA:AccessJson}
INTERFACELOG \[%{DATETIME:log_timestamp}\] \[%{DATA:ThreadName}\] \[%{LOGLEVEL:logLevel}\] \[%{DATA:InterfaceTag}\] \[%{DATA:TransactionId}\] \[%{DATA:SpanId}\] \[%{DATA:ParentId}\] \[%{DATA:HttpUrl}\] \[%{DATA:Protocol}\]?\[%{DATA:logtype}\] - %{GREEDYDATA:JsonContent}
kafka-output.conf: |-
input {
kafka {
bootstrap_servers => "kafka-svc.cmw.svc.cluster.local:9092"
topics => ["nginx-access"]
codec => "json"
}
}
filter {
if [fields][log_topics] =~ "\w+-access" {
if [message] =~ '^{\w*' {
json {
source => "message"
add_field => ["type", "%{[fields][log_topics]}"]
}
}
else {
grok {
patterns_dir => [ "/opt/appl/logstash/patterns" ]
match => { "message" => "%{ACCESSLOG}" }
}
json {
source => "AccessJson"
remove_field => "AccessJson"
add_field => ["type", "%{[fields][log_topics]}"]
}
}
}
ruby {
code => "event.timestamp.time.localtime"
}
#if [startTime] {
# date {
# match => [ "startTime", "YYYY-MM-dd HH:mm:ss.SSS" ]
# timezone => "Asia/Shanghai"
# target => "@timestamp"
# }
#}
if [timeDiff] {
mutate {
add_field => [ "timeDiff_int", "%{timeDiff}" ]
}
mutate {
convert => [ "timeDiff_int", "integer" ]
remove_field => "timeDiff"
}
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch.cmw:9200" ]
index => "logstash-k8s-%{[fields][log_topics]}-%{+YYYY.MM.dd}"
template_overwrite => true
#user => "elastic"
#password => "xri&h2azaj"
#document_type => "%{[type]}"
}
}
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash-test-access
namespace: ops
labels:
app: logstash-test
spec:
replicas: 1
selector:
matchLabels:
app: logstash-test
template:
metadata:
labels:
app: logstash-test
spec:
containers:
- name: test-access
imagePullPolicy: IfNotPresent
image: harbor.iboxpay.com/ops/logstash:6.8.1
volumeMounts:
- name: test-access
mountPath: /opt/appl/logstash/conf.d/kafka-output.conf
subPath: kafka-output.conf
- name: test-access
mountPath: /opt/appl/logstash/patterns/pattern
subPath: pattern
resources:
requests:
memory: "2Gi"
cpu: "1"
limits:
memory: "3Gi"
cpu: "2"
command:
- sh
- -c
#- "/opt/appl/logstash/start.sh"
- "/opt/appl/logstash/bin/logstash -f /opt/appl/logstash/conf.d"
volumes:
- name: test-access
configMap:
name: test-access
items:
- key: kafka-output.conf
path: kafka-output.conf
- key: pattern
path: pattern
securityContext:
runAsUser: 1500
fsGroup: 1500
4.将外部服务elasticsearch,提供一个endpoint、service供集群使用
[root@cc-k8s01 es]# cd /opt/k8s/work/es/
[root@cc-k8s01 es]# cat *
kind: Endpoints apiVersion: v1 metadata: name: elasticsearch namespace: cmw subsets: - addresses: - ip: 172.30.21.232
- ip: 172.30.21.233
- ip: 172.30.21.234
ports: - port: 9200 apiVersion: v1 kind: Service metadata: name: elasticsearch namespace: cmw spec: ports: - port: 9200

 浙公网安备 33010602011771号
浙公网安备 33010602011771号