
mapreduce数据清洗-第二阶段
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
1、
package test4;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class quchong {
public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException {
Job job = Job.getInstance();
job.setJobName("paixu");
job.setJarByClass(quchong.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://localhost:9000/test/in/result");
Path out = new Path("hdfs://localhost:9000/test/stage3/out1");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
////
if(job.waitForCompletion(true)){
Job job2 = Job.getInstance();
job2.setJobName("paixu");
job2.setJarByClass(quchong.class);
job2.setMapperClass(doMapper2.class);
job2.setReducerClass(doReduce2.class);
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
job2.setSortComparatorClass(IntWritableDecreasingComparator.class);
job2.setInputFormatClass(TextInputFormat.class);
job2.setOutputFormatClass(TextOutputFormat.class);
Path in2=new Path("hdfs://localhost:9000/test/stage3/out1/part-r-00000");
Path out2=new Path("hdfs://localhost:9000/test/stage3/out2");
FileInputFormat.addInputPath(job2,in2);
FileOutputFormat.setOutputPath(job2,out2);
System.exit(job2.waitForCompletion(true) ? 0 : 1);
}
}
public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException,InterruptedException {
//StringTokenizer tokenizer = new StringTokenizer(value.toString()," ");
String[] strNlist = value.toString().split(",");
// String str=strNlist[3].trim();
String str2=strNlist[4]+strNlist[5];
// Integer temp= Integer.valueOf(str);
word.set(str2);
//IntWritable abc = new IntWritable(temp);
context.write(word,one);
}
}
public static class doReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key,Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException{
int sum = 0;
for (IntWritable value : values){
sum += value.get();
}
result.set(sum);
context.write(key,result);
}
}
/////////////////
public static class doMapper2 extends Mapper<Object , Text , IntWritable,Text>{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
@Override
protected void map(Object key, Text value, Context context)
throws IOException,InterruptedException {
String line=value.toString();
String arr[]=line.split(" ");
num.set(Integer.parseInt(arr[1]));
goods.set(arr[0]);
context.write(num,goods);
}
}
public static class doReduce2 extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
int i=0;
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text val:values){
if(i<10)
{
context.write(key,val);
i++;
}
}
}
}
private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
}
 (去重,并输出访问次数)
(去重,并输出访问次数)
 (排序,输出Top10)
(排序,输出Top10)
2、
package test3;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import test4.quchong.doMapper2;
import test4.quchong.doReduce2;
public class quchong {
public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException {
Job job = Job.getInstance();
job.setJobName("paixu");
job.setJarByClass(quchong.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://localhost:9000/test/in/result");
Path out = new Path("hdfs://localhost:9000/test/stage2/out1");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
if(job.waitForCompletion(true)){
Job job2 = Job.getInstance();
job2.setJobName("paixu");
job2.setJarByClass(quchong.class);
job2.setMapperClass(doMapper2.class);
job2.setReducerClass(doReduce2.class);
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
job2.setSortComparatorClass(IntWritableDecreasingComparator.class);
job2.setInputFormatClass(TextInputFormat.class);
job2.setOutputFormatClass(TextOutputFormat.class);
Path in2=new Path("hdfs://localhost:9000/test/stage2/out1/part-r-00000");
Path out2=new Path("hdfs://localhost:9000/test/stage2/out2");
FileInputFormat.addInputPath(job2,in2);
FileOutputFormat.setOutputPath(job2,out2);
System.exit(job2.waitForCompletion(true) ? 0 : 1);
}
}
public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException,InterruptedException {
//StringTokenizer tokenizer = new StringTokenizer(value.toString()," ");
String[] strNlist = value.toString().split(",");
// String str=strNlist[3].trim();
String str2=strNlist[0];
// Integer temp= Integer.valueOf(str);
word.set(str2);
//IntWritable abc = new IntWritable(temp);
context.write(word,one);
}
}
public static class doReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key,Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException{
int sum = 0;
for (IntWritable value : values){
sum += value.get();
}
result.set(sum);
context.write(key,result);
}
}
////////////////
public static class doMapper2 extends Mapper<Object , Text , IntWritable,Text>{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
@Override
protected void map(Object key, Text value, Context context)
throws IOException,InterruptedException {
String line=value.toString();
String arr[]=line.split(" ");
num.set(Integer.parseInt(arr[1]));
goods.set(arr[0]);
context.write(num,goods);
}
}
public static class doReduce2 extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
int i=0;
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text val:values){
if(i<10)
{
context.write(key,val);
i++;
}
}
}
}
private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
}
 (去重,显示ip次数)
(去重,显示ip次数)
 (排序,输出Top10)
(排序,输出Top10)
3、
package test2;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import test3.quchong;
import test3.quchong.doMapper2;
import test3.quchong.doReduce2;
public class paixu {
public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException {
Job job = Job.getInstance();
job.setJobName("paixu");
job.setJarByClass(paixu.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://localhost:9000/test/in/result");
Path out = new Path("hdfs://localhost:9000/test/stage1/out1");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
if(job.waitForCompletion(true)){
Job job2 = Job.getInstance();
job2.setJobName("paixu");
job2.setJarByClass(quchong.class);
job2.setMapperClass(doMapper2.class);
job2.setReducerClass(doReduce2.class);
job2.setOutputKeyClass(IntWritable.class);
job2.setOutputValueClass(Text.class);
job2.setSortComparatorClass(IntWritableDecreasingComparator.class);
job2.setInputFormatClass(TextInputFormat.class);
job2.setOutputFormatClass(TextOutputFormat.class);
Path in2=new Path("hdfs://localhost:9000/test/stage1/out1/part-r-00000");
Path out2=new Path("hdfs://localhost:9000/test/stage1/out2");
FileInputFormat.addInputPath(job2,in2);
FileOutputFormat.setOutputPath(job2,out2);
System.exit(job2.waitForCompletion(true) ? 0 : 1);
}
}
public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException,InterruptedException {
//StringTokenizer tokenizer = new StringTokenizer(value.toString()," ");
String[] strNlist = value.toString().split(",");
String str=strNlist[3].trim();
String str2=strNlist[4]+strNlist[5];
Integer temp= Integer.valueOf(str);
word.set(str2);
IntWritable abc = new IntWritable(temp);
context.write(word,abc);
}
}
public static class doReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key,Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException{
int sum = 0;
for (IntWritable value : values){
sum += value.get();
}
result.set(sum);
context.write(key,result);
}
}
/////////////
public static class doMapper2 extends Mapper<Object , Text , IntWritable,Text>{
private static Text goods=new Text();
private static IntWritable num=new IntWritable();
@Override
protected void map(Object key, Text value, Context context)
throws IOException,InterruptedException {
String line=value.toString();
String arr[]=line.split(" ");
num.set(Integer.parseInt(arr[1]));
goods.set(arr[0]);
context.write(num,goods);
}
}
public static class doReduce2 extends Reducer< IntWritable, Text, IntWritable, Text>{
private static IntWritable result= new IntWritable();
int i=0;
public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
for(Text val:values){
if(i<10)
{
context.write(key,val);
i++;
}
}
}
}
private static class IntWritableDecreasingComparator extends IntWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
}
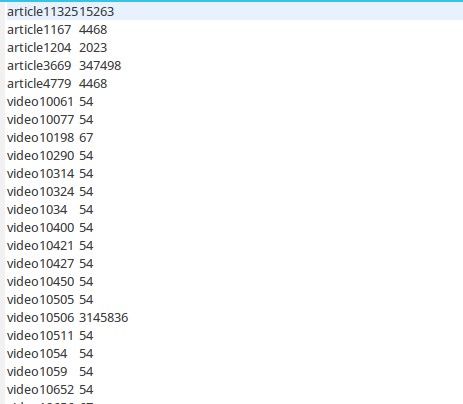 (去重、显示流量总量)
(去重、显示流量总量)
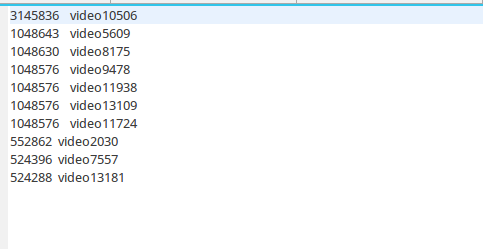 (排序,输出Top10)
(排序,输出Top10)
总结:
本来我是通过两个类来实现的,后来我发现在一个类中可以进行多个job,我就定义两个job,job1进行去重,输出总数。job2进行排序,输出Top10。
在for(Intwritable val:values)遍历时,根据主键升序遍历,但我们需要的结果是降序,那么在这里我们需要引入一个比较器。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号