mapreduce数据清洗-第一阶段
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
package test;
import java.lang.String;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class sjqx {
static Dao dao=new Dao();
public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); //原时间格式
public static final SimpleDateFormat dateformat1 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//现时间格式
private static Date parseDateFormat(String string) { //转换时间格式
Date parse = null;
try {
parse = FORMAT.parse(string);
} catch (Exception e) {
e.printStackTrace();
}
return parse;
}
public static class MyMapper extends Mapper<LongWritable, Text, Text/*map对应键类型*/, Text/*map对应值类型*/>
{
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException
{
String[] strNlist = value.toString().split(",");//如何分隔
//LongWritable,IntWritable,Text等
Date date = parseDateFormat(strNlist[1]);
context.write(new Text(strNlist[0])/*map对应键类型*/,new Text(dateformat1.format(date)+","+strNlist[2]+","+strNlist[3]+","+strNlist[4]+","+strNlist[5])/*map对应值类型*/);
}
}
public static class MyReducer extends Reducer<Text/*map对应键类型*/, Text/*map对应值类型*/, Text/*reduce对应键类型*/, Text/*reduce对应值类型*/>
{
// static No1Info info=new No1Info();
protected void reduce(Text key, Iterable<Text/*map对应值类型*/> values,Context context)throws IOException, InterruptedException
{
for (/*map对应值类型*/Text init : values)
{
// String[] strNlist = init.toString().split(",");
// dao.add("data", strNlist);
context.write( key/*reduce对应键类型*/, new Text(init)/*reduce对应值类型*/);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//将命令行中的参数自动设置到变量conf中
// String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
// if (otherArgs.length != 2) {
// System.err.println("Usage: wordcount <in> <out>");
// System.exit(2);
// }
Job job = Job.getInstance();
//job.setJar("MapReduceDriver.jar");
job.setJarByClass(sjqx.class);
// TODO: specify a mapper
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(/*map对应键类型*/Text.class);
job.setMapOutputValueClass( /*map对应值类型*/Text.class);
// TODO: specify a reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(/*reduce对应键类型*/Text.class);
job.setOutputValueClass(/*reduce对应值类型*/Text.class);
// TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/test/in/result"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/test/out"));
boolean flag = job.waitForCompletion(true);
System.out.println("SUCCEED!"+flag); //任务完成提示
System.exit(flag ? 0 : 1);
System.out.println();
}
}
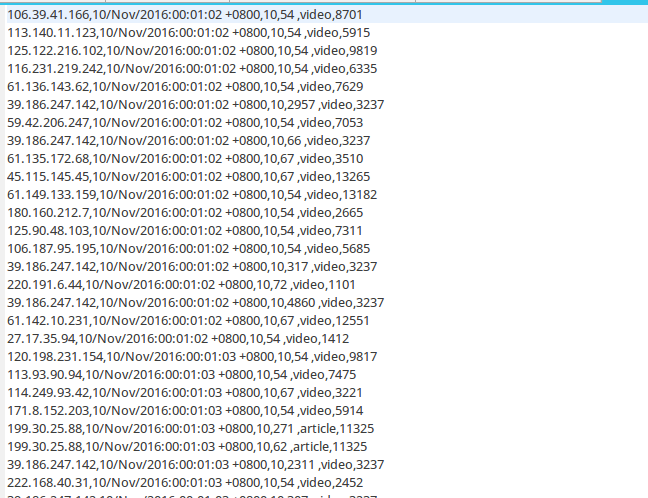 (清洗之前)
(清洗之前) (清洗之后)
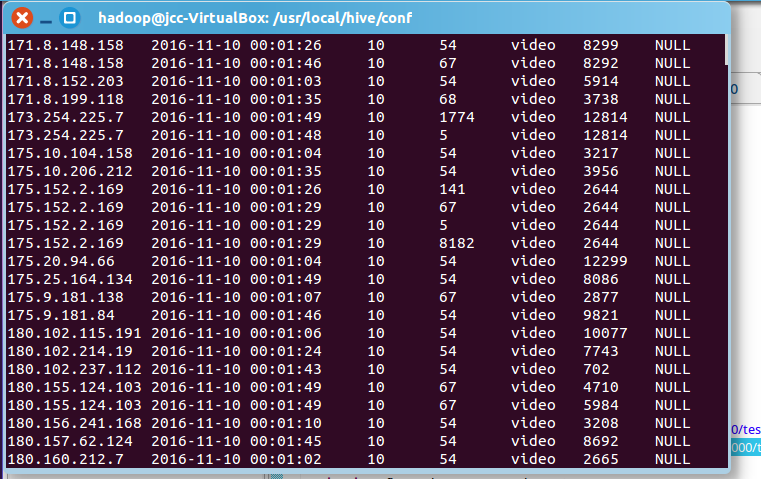
(清洗之后)
在hive中创建表data
运行
load data inpath 'hdfs://localhost:9000/test/out/part-r-00000' overwrite into table data;
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号