浅析b-树 b+树 以及Mysql的Innodb,Myisam引擎
B-树性质
B-树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
1根节点至少有两个子节点
2每个节点有M-1个key,并且以升序排列
3位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
其它节点至少有M/2个子节点
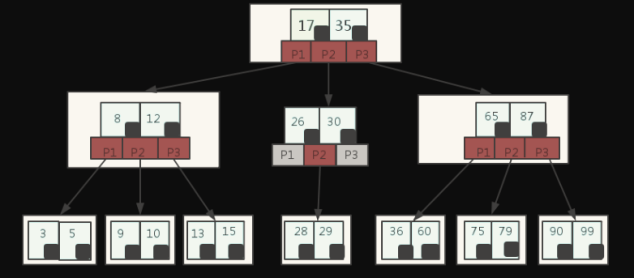
下图是一个M=3 阶的B树
这里简单说明下
图中的小黑方块表示对应关键字所代表的文件的存储位置,实际上可以看做是一个地址,比如根节点中17旁边的小黑块表示的就是关键字17所对应的文件在硬盘中的存储地址。
P是指针,
需要注意的是:指针(P),关键字(17),以及关键字所代表的文件地址这三样东西合起来构成了B树的一个节点,这个节点存储在一个磁盘块上
查找过程
下面,看看搜索关键字的29的文件的过程:
从根节点开始,读取根节点信息,根节点有2个关键字:17和35。因为17 < 29 < 35,所以找到指针P2指向的子树,也就是磁盘块3(第1次I/0操作)
读取当前节点信息,当前节点有2个关键字:26和30。26 < 29 < 30,找到指针P2指向的子树,也就是磁盘块8(第2次I/0操作)
读取当前节点信息,当前节点有2个关键字:28和29。比较找到了!(第3次I/0操作)
B+树性质
B+树是对B树的一种变形树,它与B树的差异在于:
非叶子结点的子树指针与关键字个数相同
非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
所有分支节点的关键字都是对应子树中关键字的最大值(或最小值)
树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
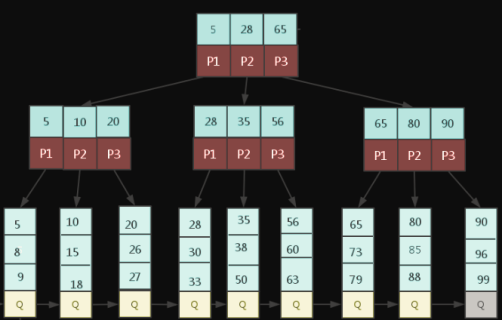
查找过程与b树类似,这里就不再描述了。
为什么mysql数据库采用b+树而不是b树?
B树在提高了IO性能的同时并没有解决遍历元素的效率比较低的问题,
而由于b+树的特点,只需要去遍历叶子节点就可以实现整棵树的遍历.
而且在实际开发中,基于范围的查询是非常频繁的,
而B树不支持这样的操作(或者说效率太低)
关于B树和B+树相关应用拓展
B树一般用于数据库索引或者文件系统,这里我们讨论mysql的两种不同 引擎
Myisam Innodb
1 MyISAM

MyISAM中有两种索引,分别是主索引和辅助索引, 他们的数据都是那列的指针
在这里面的主索引使用主键进行创建,
而二级(辅助)索引中键值则是其他索引列。
MyISAM分别会存一个索引文件和数据文件。它的主索引是非聚集索引。
当我们查询的时候我们找到叶子节点中保存的地址,然后通过地址我们找到所对应的信息
Innodb

InnoDB索引和MyISAM最大的区别是它只有一个数据文件,并且在辅助索引中不存储那列的指针,而是存储主键。
在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,
这棵树的叶子节点数据域保存了完整的数据记录。
我们把它的主索引叫做聚集索引。
而它的辅助索引和MyISAM也会有所不同,它的辅助索引都是将主键作为数据域。而它的辅助索引和MyISAM也会有所不同,它的辅助索引都是将主键作为数据域。
因为MySQL重建聚簇索引,重建完后,原数据所有的page都发生了变动,这个时候你一定希望非聚簇索引记录的都是PK,而非page指针了
(由于每个辅助索引都包含主键索引,因此,为了减小辅助索引所占空间,我们通常希望 InnoDB 表中的主键索引尽量定义得小一些)
当我们查找的时候通过辅助索引要先找到主键,然后通过主索引再找到对于的主键,得到信息。
注意一下两点:
1聚集索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。聚簇索引要比非聚簇索引查询效率高很多。
例如,如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能
2聚集索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是数据具体的物理地址。
那实际情况,我们一般选用哪种引擎?
我们一般使用Innodb,从mysql-5.5.5开始的版本 默认都是innodb引擎。他支持事务,支持行锁,并发度高。尽量不要混用引擎。
posted on 2017-09-25 21:09 一只小蜗牛12138 阅读(383) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号