zookeeper原理
什么是一致性:
要站在集群的角度去思考问题:
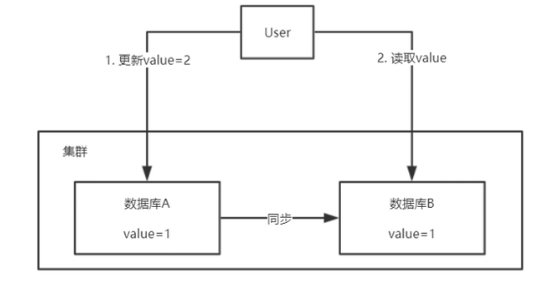
一致性的分类:
强一致性:它要求系统写入什么,读出来的
弱一致性:不承诺立即可以读到写入的值,也不久承诺多久之后数据能够达到一致,但会尽可能地保证
到某个时间级别(比如秒级别)后,数据能够达到一致状态。
最终一致性:
系统会保证在一定时间内,能够达到一个数据一致的状态。
它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型。
注意:zookeeper尽量达到强一致性,但是实际上只实现了最终一致性
什么是2pc
二阶段提交(Two-phaseCommit)
2PC是一个非常经典的强一致、中心化的原子提交协议
先由一方进行提议(propose)并收集其他节点的反馈(vote),再根据反馈决定提交(commit)或中止(abort)事务。
我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts)
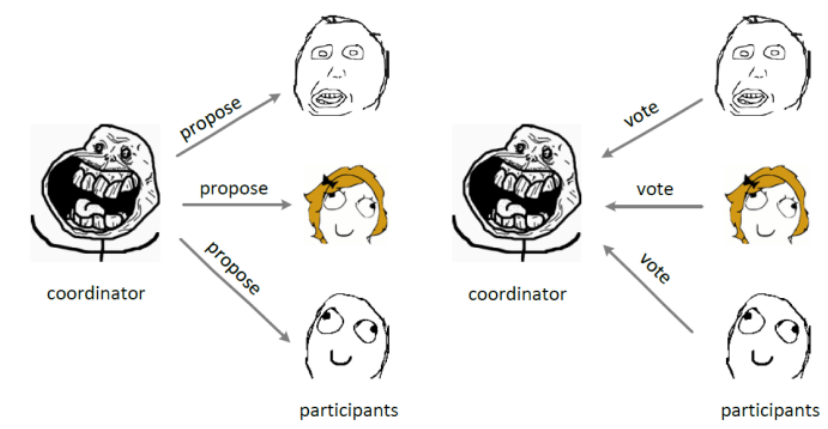
第一阶段:
coordinator发起一个提议,分别问询各participant是否接受。
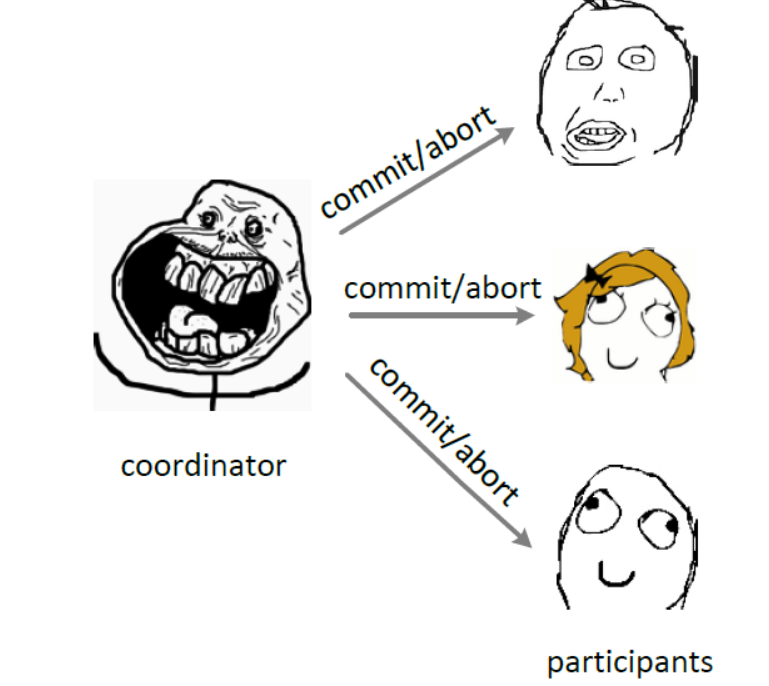
第二个阶段
coordinator根据participant的反馈,提交或中止事务,如果participant全部同意则提交,只要有一个participant不同意就中止。
zookeeper中的一致性:------Zab协议
Zookeeper Atomic Broadcast (Zookeeper原子广播)。
Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性。
1:Leader-------选举过程
2:2pc---------------过程
3:过半机制-验证是不是超过一半
4:同步过程-----------发生机制
Leader领导者选举
至少要两台zk,才会有选举
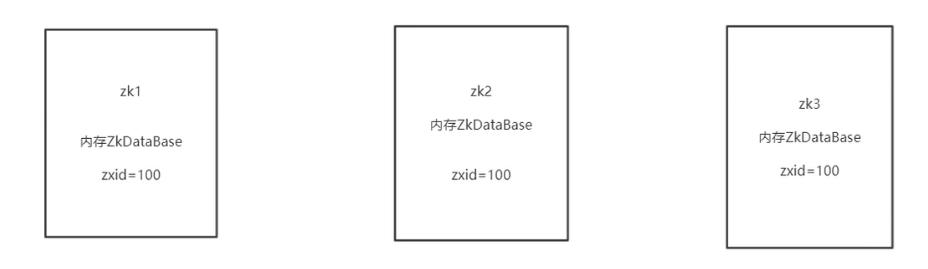
zookeeper的数据存储:
内存---每个zk都有一个ZkDatabase对象,
磁盘----Database对象持久化到磁盘
请求的过程:
1收到一个create /quan 123请求后 2会先生成一个日志------持久化到磁盘 (使用的是追加模式,速度快) 3指定操作内存中的数据----DataBase
注意,我们很多数据库都是靠日志来恢复数据的
create /quan 123
set /quan 234
set /quan 345
这样子其实有些日志是不需要追加的,导致日志越来越大
解决:
zk有有个单独的线程,去定时将内存中的数据进行快照
快照就是将内存中的DataBase存到DataBase文件里面去
就在这个时候,会把日志删除掉
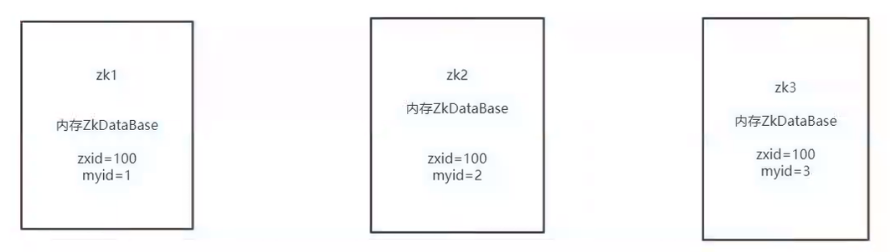
Leader的特征:
1-数据最新
因为上面我们知道处理数据之前,我们都是先进行日志追加,而日志追加的内容
有一个zxid,是一个自增的id,
这就意味着zxid越大,表示处理的数据是越多的,那集群里面应该是最新的
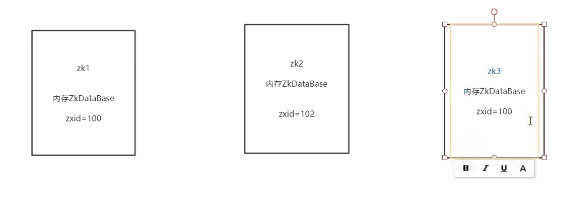
第二种情况:
当zxid都是一致的时候,比较myid,最大的选为leader
zk的投票过程:
11111
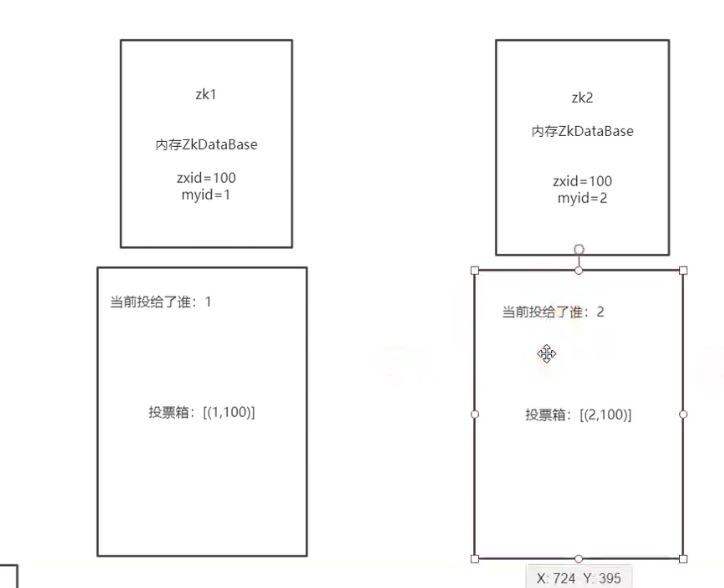
服务器刚刚启动的时候,投的票都是自己
zookeeper里面存在一个hash表,存储的是投票信息zxid,myid
所以一开始都是写自己的信息
222222,发送自己的投票信息,
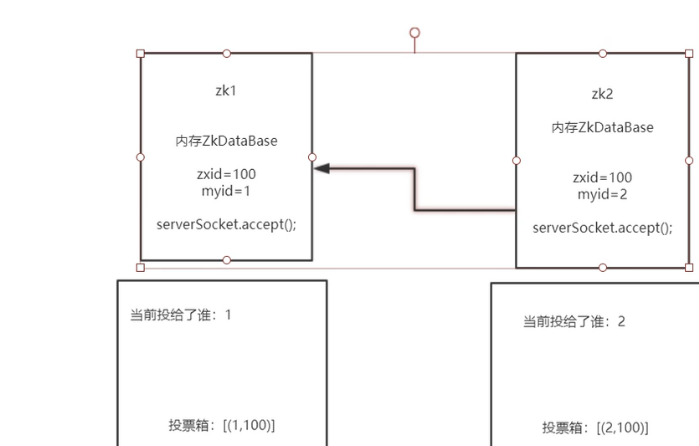
当投票完自己之后,需要进行集群之间的交流,服务器之间要建立socket连接
zookeeper的源码里面定义了我去连的zk的myid必须要比自己的小才能建立socket连接
这样子避免了建立多条连接
3333比较收到的投票信息
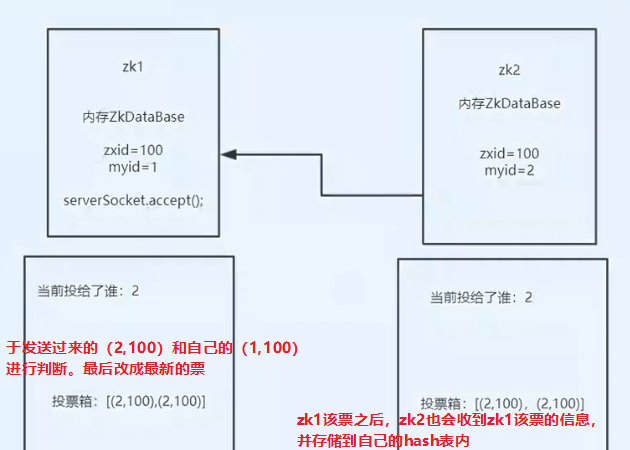
4444
我们如果只有3台zk,那么现在就可以知道leader是谁了,因为zk有一个过半机制
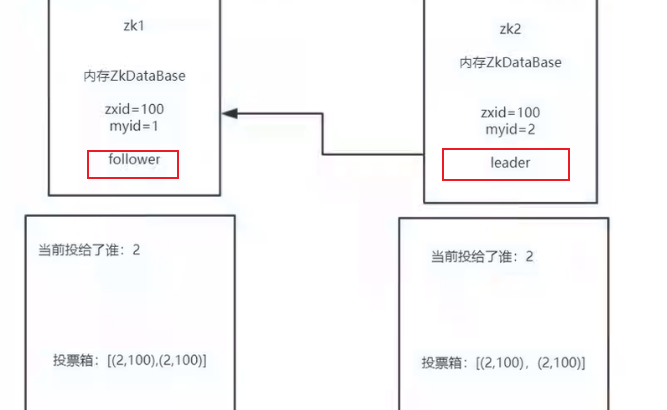
555如果这个时候zk3启动
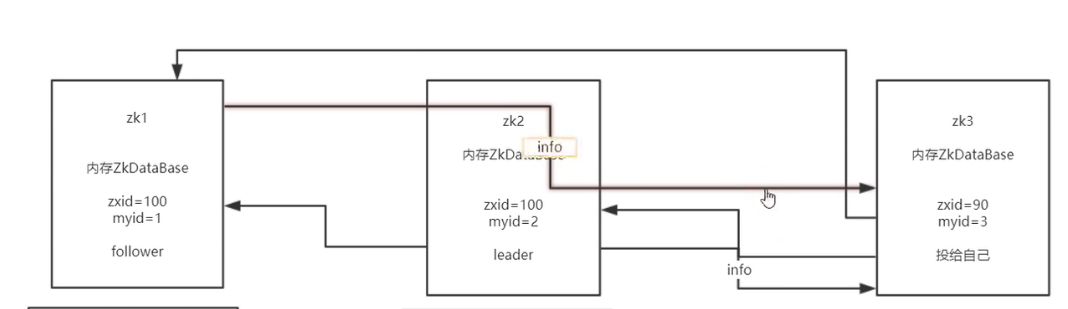
zk3也会先投票给自己
然后想zk1 zk2其他服务器发送自己的投票信息,
而其他服务器已经知道自己的角色了,所以直接都返回leader是谁的信息给zk3
最后其实zk3可以直接知道自己的角色是follower.
6666zk3知道自己是follower后,会和leader建立一个数据同步的socket连接
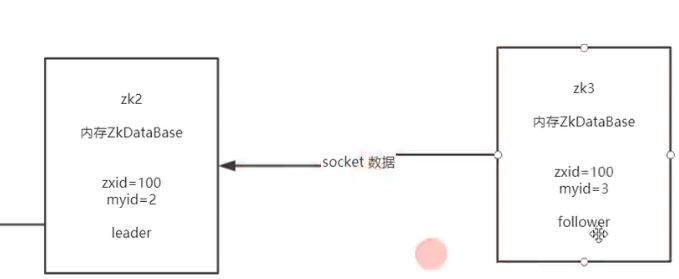
所以可以知道其实每一台zk都会启动三个端口,一个是leader选举端口,一个是数据同步+心跳端口
最后一个是zk客户端连接端口
注意:即使zk3的zxid为200,也不会是leader,而zk里面会直接将zk3进行回滚(可以这么理解),其实就是数据同步
出现这个情况的场景就是,leader处理完一个数据之后,还没来得及通知其他zk,就已经dea掉了。所以这个数据应该
当重新启动的时候,其他在线的zk可能处理了其他请求,所以zk里面原则就是后来则follower
领导者选举发送的场景:
刚开始启动集群的时候 leader-down的时候 超过一半的集群内的机器挂掉的时候
注意:leader可以通过socket连接进行心跳检测,知道多少台follower在线,炒股一半的时候,会自发shutdown
特殊场景11

这时候其实zk2还是在选举的过程,
所以会新建socket连接去继续选举
2-处理数据
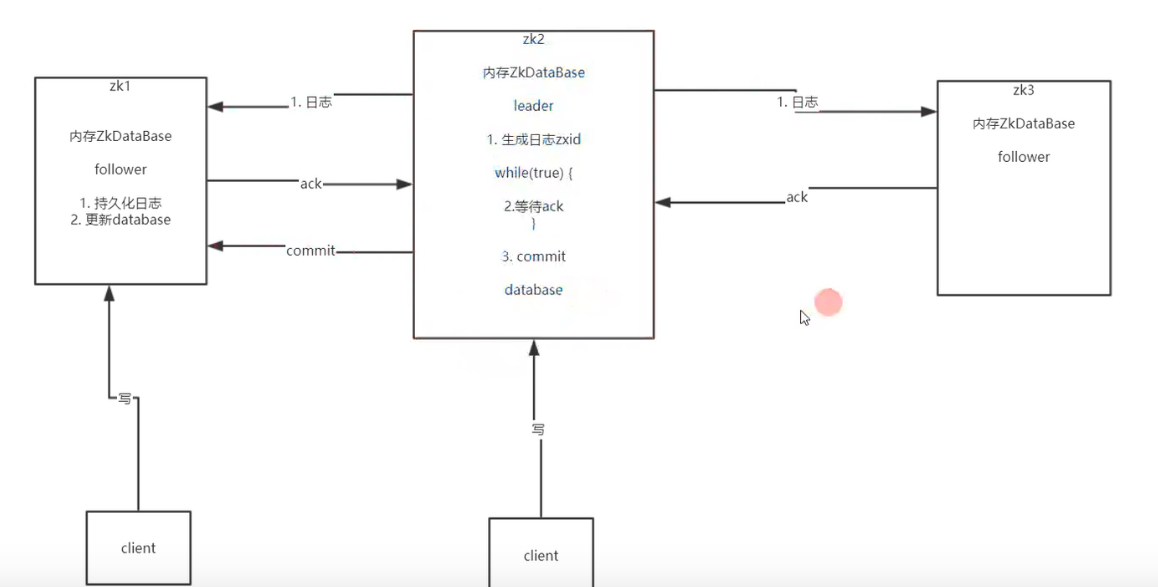
1客户端发送处理数据请求给leader
2leader会生成日志,并将日志发送给follower,同时开启一个死循环
3死循环的内容就是接收所有follower响应回来的ack数量,一旦数量
超过集群的一半(过半机制),leader就认为整个集群都可以处理整个请求了
4follower接收到这个日志之后,进行持久化,并返回ack给leader
5当leader接收到的ack数量过半,leader就进行数据的处理commit
6发送commit的请求给follower,
7follower接收到请求后,更新自己的database
特殊情况:
1当ack发送失败
leader会一直在等待,因为在源码里面,有一个laenerHandler线程会一直在等
不会报什么异常,但是因为客户端和leader的连接有timeout,所以客户端会超时
注意:
follower发送心跳的时候,会携带自己的zxid,leader会返回给follower当前你的zxid是大了还是小了还是相等
小了就进行同步
异步模式
发送commit的时候,其实是想将消息发送添加到一个队列里面,然后开启一个新的线程去从队列里面
取出消息并发送
并不会取关心follower是否commit成功,因为可以看看上面的注意,是一个补偿机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号