Linux Redis集群搭建与集群客户端实现
redis集群实现方案:
关于redis的集群化方案 目前有三种
(1)Twitter开发的twemproxy
(2)豌豆荚开发的codis
(3)redis官方的redis-cluster
简介:twemproxy架构简单 就是用proxy对后端redis server进行代理 但是由于代理层的消耗性能很低 而且通常涉及多个key的操作都是不支持的 而且本身不支持动态扩容和透明的数据迁移 而且也失去维护 Twitter内部已经不使用了。
redis-cluster是三个里性能最强大的 因为他使用去中心化的思想 使用hash slot方式 将16348个hash slot 覆盖到所有节点上 对于存储的每个key值 使用CRC16(KEY)&16348=slot 得到他对应的hash slot 并在访问key时就去找他的hash slot在哪一个节点上 然后由当前访问节点从实际被分配了这个hash slot的节点去取数据 节点之间使用轻量协议通信 减少带宽占用 性能很高 自动实现负载均衡与高可用 自动实现failover 并且支持动态扩展 官方已经玩到可以1000个节点 实现的复杂度低 总之个人比较喜欢这个架构 因为他的去中心化思想免去了proxy的消耗 是全新的思路。
但是它也有一些不足 例如官方没有提供图形化管理工具 运维体验差 全手工数据迁移 并且自己对自己本身的redis命令支持也不完全等 但是这些问题 我觉得不能掩盖他关键的新思想所带来的的优势 随着官方的推进 这些问题应该都能在一定时间内得到解决 那么这时候去中心化思想带来的高性能就会表现出他巨大的优势。
Codis使用的也是proxy思路 但是做的比较好 是这两种之间的一个中间级 而且支持redis命令是最多的 有图形化GUI管理和监控工具 运维友好 这个过段时间会详细另外写出来原理 工作机制和搭建实现。
基本介绍:
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施installation。
Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动数据, 并且在高负载的情况下, 这些命令将降低Redis集群的性能, 并导致不可预测的行为。
Redis 集群通过分区partition来提供一定程度的可用性availability: 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Redis集群提供了以下两个好处:
- 将数据自动切分split到多个节点的能力。
- 当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力。
集群原理:
redis-cluster架构图:
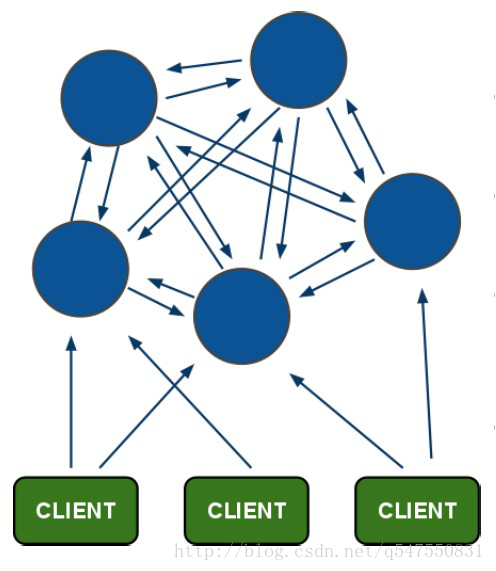
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的fail是通过集群中超过半数的节点检测失效时才生效。
- 客户端与redis节点直连,不需要中间proxy层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
- redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
redis-cluster投票:容错
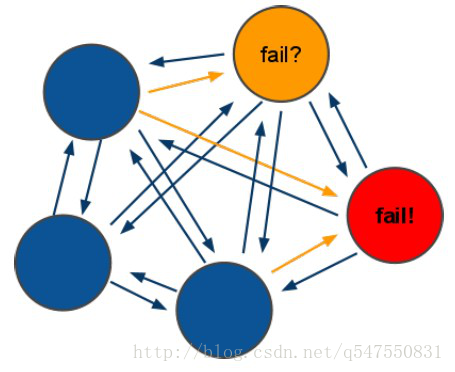
1. 投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超时(cluster-node-timeout),认为当前master节点挂掉。
2. 什么时候整个集群不可用(cluster_state:fail)?
① 如果集群任意master挂掉,且当前master没有slave,集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完整时进入fail状态。
redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败。
② 如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态。
redis集群的搭建
完全分布式:redis集群的节点个数是奇数个,最少有三个节点,为了保证集群的高可用性,对每台redis节点需要进行备份,因此redis集群需要6台服务器。
伪分布式:可以再一台服务器上面同时运行6个redis实例,模拟完全分布式集群。需要修改每个redis实例中的端口号,同时设置cluster-enabled的值为yes。
硬件环境
本文适用的硬件环境如下:
Linux版本:CentOS release 6.7 (Final) Redis版本:3.2.1
Redis已经成功安装,安装路径为/home/idata/axing/local/redis-3.2.1。
我们要在单台机器上搭建Redis集群,方式是通过不同的TCP端口启动多个实例,然后组成集群。
1、启动Redis多个实例
我们在Redis安装目录下创建目录cluster,并编写7000.conf~7005.conf 6个配置文件,这6个配置文件用来启动6个实例,后面将使用这6个实例组成集群。
以7000.conf为例,配置文件需要填写如下几项:
port 7000 //端口7000,7002,7003 bind 10.93.84.53 //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群 daemonize yes //redis后台运行 pidfile ./redis_7000.pid //pidfile文件对应7000,7001,7002 cluster-enabled yes //开启集群 把注释#去掉 cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002 cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置 appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志
分别启动6个实例:
./bin/redis-server cluster/conf/7000.conf ./bin/redis-server cluster/conf/7001.conf ./bin/redis-server cluster/conf/7002.conf ./bin/redis-server cluster/conf/7003.conf ./bin/redis-server cluster/conf/7004.conf ./bin/redis-server cluster/conf/7005.conf
启动成功后,看一下进程:
# ps -ef | grep redis | grep cluster idata 15711 22329 0 18:40 pts/10 00:00:00 ./bin/redis-server 10.93.84.53:7000 [cluster] idata 15740 22329 0 18:40 pts/10 00:00:00 ./bin/redis-server 10.93.84.53:7001 [cluster] idata 15810 22329 0 18:40 pts/10 00:00:00 ./bin/redis-server 10.93.84.53:7002 [cluster] idata 17023 22329 0 18:42 pts/10 00:00:00 ./bin/redis-server 10.93.84.53:7003 [cluster] idata 17030 22329 0 18:42 pts/10 00:00:00 ./bin/redis-server 10.93.84.53:7004 [cluster] idata 17035 22329 0 18:42 pts/10 00:00:00 ./bin/redis-server 10.93.84.53:7005 [cluster]
至此,ip=10.93.84.53机器上创建了6个实例,端口号为port=7000~7005。
Redis 3.0以上的集群方式是通过Redis安装目录下的bin/redis-trib.rb脚本搭建。
这个脚本是用Ruby编写的,尝试运行,如果打印如下,你可以跳过本文的第二部分。
idata@qa-f1502-xg01.xg01:~/yangfan/local/redis-3.2.1/bin$ ruby redis-trib.rb Usage: redis-trib <command> <options> <arguments ...> create host1:port1 ... hostN:portN --replicas <arg> check host:port info host:port fix host:port --timeout <arg> reshard host:port --from <arg> --to <arg> --slots <arg> --yes --timeout <arg> --pipeline <arg> rebalance host:port --weight <arg> --auto-weights --use-empty-masters --timeout <arg> --simulate --pipeline <arg> --threshold <arg> add-node new_host:new_port existing_host:existing_port --slave --master-id <arg> del-node host:port node_id set-timeout host:port milliseconds call host:port command arg arg .. arg import host:port --from <arg> --copy --replace help (show this help) For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
2、安装ruby
下面的过程都是在root权限下完成的。
1)yum安装ruby和依赖的包。
2)使用gem这个命令来安装redis接口
3)升级Ruby的版本
4)安装gem redis接口
5)安装rubygems
至此,我们的Ruby和运行redis-trib.rb需要的环境安装完成了。
3、Redis集群搭建
有了Ruby执行环境,可以开始将之前的6个实例组建成集群了。
命令方式:
ruby ./bin/redis-trib.rb create --replicas 1 10.93.84.53:7000 10.93.84.53:7001 10.93.84.53:7002 10.93.84.53:7003 10.93.84.53:7004 10.93.84.53:7005
--replicas 1表示为集群的master节点创建1个副本。那么6个实例里,有三个master,有三个是slave。
后面跟上6个实例就好了,形式就是ip:port
执行情况:
# ruby ./bin/redis-trib.rb create --replicas 1 10.93.84.53:7000 10.93.84.53:7001 10.93.84.53:7002 10.93.84.53:7003 10.93.84.53:7004 10.93.84.53:7005 >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 10.93.84.53:7000 10.93.84.53:7001 10.93.84.53:7002 Adding replica 10.93.84.53:7003 to 10.93.84.53:7000 Adding replica 10.93.84.53:7004 to 10.93.84.53:7001 Adding replica 10.93.84.53:7005 to 10.93.84.53:7002 M: 6346ae8c7af7949658619fcf4021cc7aca454819 10.93.84.53:7000 slots:0-5460 (5461 slots) master M: 5ac973bceab0d486c497345fe884ff54d1bb225a 10.93.84.53:7001 slots:5461-10922 (5462 slots) master M: cc46a4a1c0ec3f621b6b5405c6c10b7cffe73932 10.93.84.53:7002 slots:10923-16383 (5461 slots) master S: 92f62ec93a0550d962f81213ca7e9b3c9c996afd 10.93.84.53:7003 replicates 6346ae8c7af7949658619fcf4021cc7aca454819 S: 942c9f97dc68198c39f425d13df0d8e3c40c5a58 10.93.84.53:7004 replicates 5ac973bceab0d486c497345fe884ff54d1bb225a S: a92a81532b63652bbd862be6f19a9bd8832e5e05 10.93.84.53:7005 replicates cc46a4a1c0ec3f621b6b5405c6c10b7cffe73932 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join... >>> Performing Cluster Check (using node 10.93.84.53:7000) M: 6346ae8c7af7949658619fcf4021cc7aca454819 10.93.84.53:7000 slots:0-5460 (5461 slots) master 1 additional replica(s) S: a92a81532b63652bbd862be6f19a9bd8832e5e05 10.93.84.53:7005 slots: (0 slots) slave replicates cc46a4a1c0ec3f621b6b5405c6c10b7cffe73932 M: 5ac973bceab0d486c497345fe884ff54d1bb225a 10.93.84.53:7001 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: 942c9f97dc68198c39f425d13df0d8e3c40c5a58 10.93.84.53:7004 slots: (0 slots) slave replicates 5ac973bceab0d486c497345fe884ff54d1bb225a S: 92f62ec93a0550d962f81213ca7e9b3c9c996afd 10.93.84.53:7003 slots: (0 slots) slave replicates 6346ae8c7af7949658619fcf4021cc7aca454819 M: cc46a4a1c0ec3f621b6b5405c6c10b7cffe73932 10.93.84.53:7002 slots:10923-16383 (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
可以看到16384个slot都已经创建完成,并且建立了3个master和对应的replica:
Using 3 masters: 10.93.84.53:7000 10.93.84.53:7001 10.93.84.53:7002 Adding replica 10.93.84.53:7003 to 10.93.84.53:7000 Adding replica 10.93.84.53:7004 to 10.93.84.53:7001 Adding replica 10.93.84.53:7005 to 10.93.84.53:7002 。。。 [OK] All 16384 slots covered.
4、验证集群状态
登录集群客户端,-c标识以集群方式登录:
./bin/redis-cli -h 10.93.84.53 -p 7000 -c
查看集群状态:
10.93.84.53:7000> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:8 cluster_my_epoch:8 cluster_stats_messages_sent:215 cluster_stats_messages_received:215 10.93.84.53:7000> cluster nodes 942c9f97dc68198c39f425d13df0d8e3c40c5a58 10.93.84.53:7004 slave 5ac973bceab0d486c497345fe884ff54d1bb225a 0 1507806791940 5 connected 5ac973bceab0d486c497345fe884ff54d1bb225a 10.93.84.53:7001 master - 0 1507806788937 2 connected 5461-10922 a92a81532b63652bbd862be6f19a9bd8832e5e05 10.93.84.53:7005 slave cc46a4a1c0ec3f621b6b5405c6c10b7cffe73932 0 1507806790939 6 connected cc46a4a1c0ec3f621b6b5405c6c10b7cffe73932 10.93.84.53:7002 master - 0 1507806789937 3 connected 10923-16383 6346ae8c7af7949658619fcf4021cc7aca454819 10.93.84.53:7000 myself,slave 92f62ec93a0550d962f81213ca7e9b3c9c996afd 0 0 1 connected 92f62ec93a0550d962f81213ca7e9b3c9c996afd 10.93.84.53:7003 master - 0 1507806792941 8 connected 0-5460
原理总结:
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽(hash slot)的方式来分配的,一致性哈希对向集群中新增和删除实例的支持很好,但是哈希槽对向集群新增实例或者删除实例的话,需要额外的操作,需要手动的将slot重新平均的分配到新集群的实例中。
redis cluster 默认分配了 16384 个slot,当我们set一个key时,会用CRC16算法来取模得到所属的slot,然后将这个key分到哈希槽区间的节点上,具体算法就是:CRC16(key)%16384。 Redis 集群会把数据存在一个master节点,然后在这个master和其对应的salve之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的master节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的salve节点,充当master。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号