cs231n学习笔记——Lecture11 Detection and Segmentation
该博客主要用于个人学习记录,部分内容参考自:CS231n笔记九:图像目标检测和图像分割、2017CS231n笔记_S11分割,定位,检测
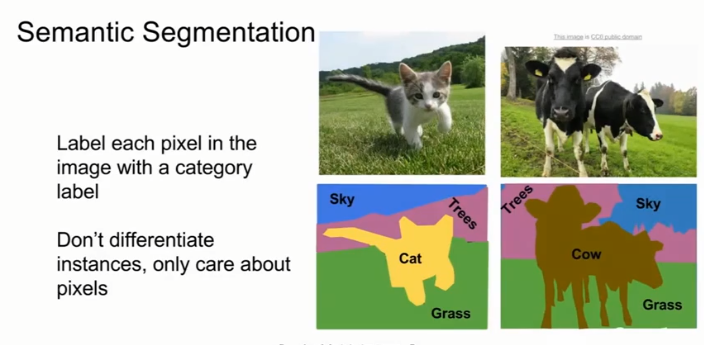
一、语义分割Semantic Segmentation
目标:输入图像,并对图像中的每个像素分类
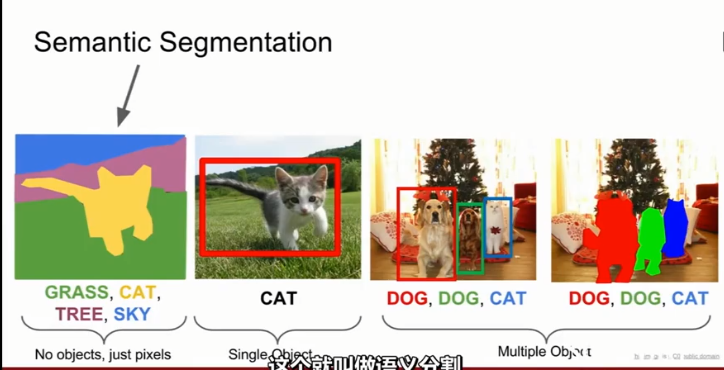
不足之处:将图像的每个像素分到一个类别中,不区分instances。如在右边的两头牛无法区分开,只会把这堆像素都标记为牛
1、滑动窗口实现语义分割 sliding window
将整张图片分解成若干小碎片,然后对每个小碎片进行分类。但是这样做的计算复杂度很高,因为我们希望为图中的每一个像素点都做label,这就需要我们为每个像素都准备单独的小碎片。且对于有重叠区域的两个碎片来说,它们的重叠区域的卷积计算都是一样的,但是却要计算两遍,没有办法共享计算过程。
2、全卷积Fully Convolutional
有一个很深的卷积网络,我们直接把整个图像(大小为H×W)输入到网络中,然后经过卷积层的输出结果是对每一个像素都做一个分类,也就是C × H × W,其中C是总共的类别数目。
但是这种方法有一个问题,就是我的每一个卷积层都要保持原始图像的尺寸,也就是假设我的通道数选了P,那么我这一层的输出数据量就是P × H × W(因为我要对每个像素都做分类,所以一定是通道数×H×W),那么如果我的输入图像清晰度很高,也就是H×W很大,那我的计算量就会非常非常大。
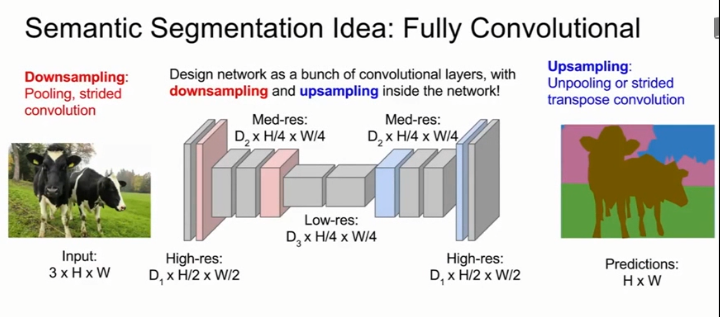
3、下采样和上采样结合的卷积网络
卷积结合下采样,如最大池化(Max Pooling)或跨步卷积(Strided Convolutions)来减少输入图像的尺寸,加上上采样,先把图像清晰度降下来,结合一系列卷积处理,最后再通过上采样层把清晰度恢复回输入图像的清晰度,作为输出结果。
下采样通过跨步卷积或池化实现,上采样通过转置卷积或各种去池化实现,用反向传播端对端训练这个网络,用交叉熵损失衡量表现。
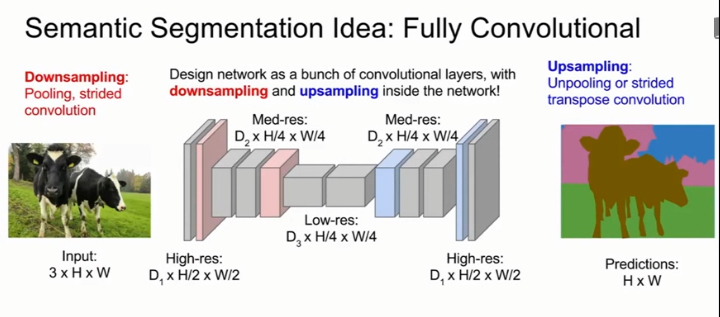
在下采样Downsample中,我们讨论过平均池化、最大池化。在上采样Upsample中,分为Unpooling和Transpose Convolution两种方法。
(1)去池化Unooling
- 最近距离去池化 Nearest Neighbor Unpooling:在输出中对像素进行重复。
- 钉床函数去池化 Bed of Nails Unpooling:在输出区域左上角的值为对应的输入像素值,输出区域的其他值为0。
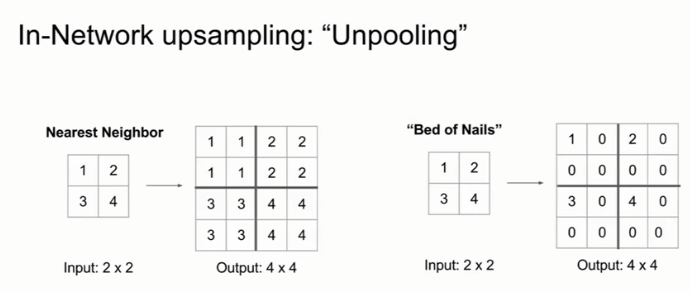
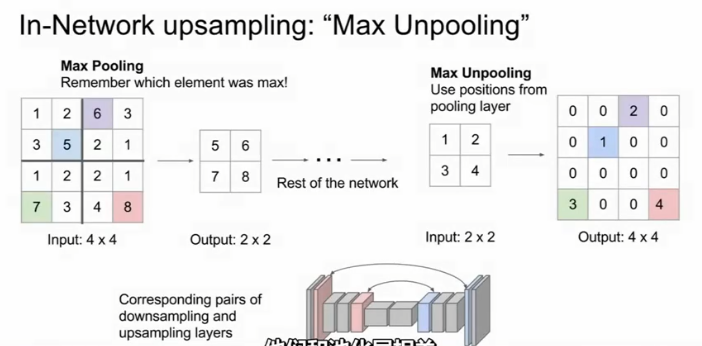
- 最大去池化 Max Unpooling:最大去池化和最大池化层是对称的,我们在下采样的时候会做一次最大池化,然后要记住那些最大值出现的位置,在上采样对应的最大去池化层中,会把那些最大值的位置赋值,其它位置都取零。这种方法保留了空间信息。
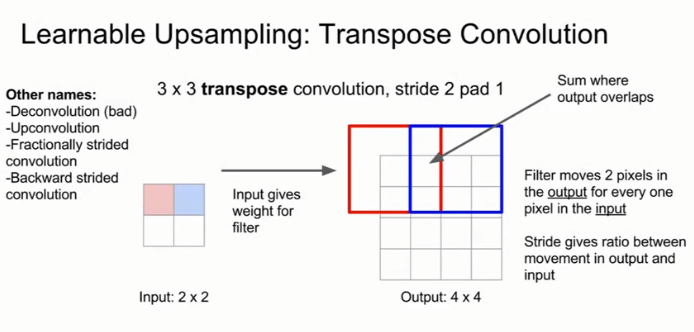
(2)Learnable Upsampling:卷积转置Transpose Convolution
以上方法其实都是固定采样,没有学习过程。类似于步长较大的卷积层可以用来做下采样,我们提出了卷积转置层来做可学习的上采样层。
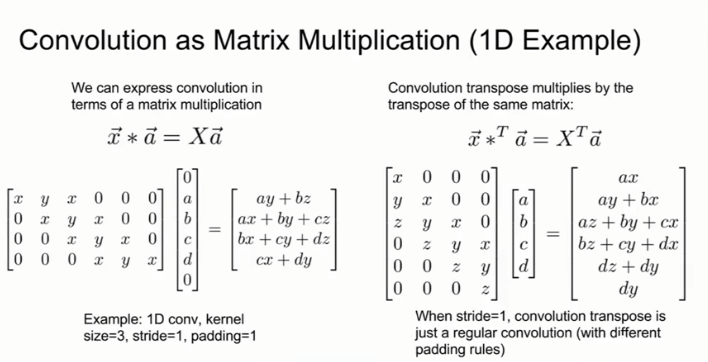
将输入矩阵的每个值都分别与卷积核矩阵的所有元素相乘,作为输出矩阵中对应位置的结果,重叠部分的值为每个矩阵中该位置值之和。 其他名称,如Deconvolution,Upconvolution,fractionally strided convolution,Backward strided convolution。

二、分类Classification + 定位Localization
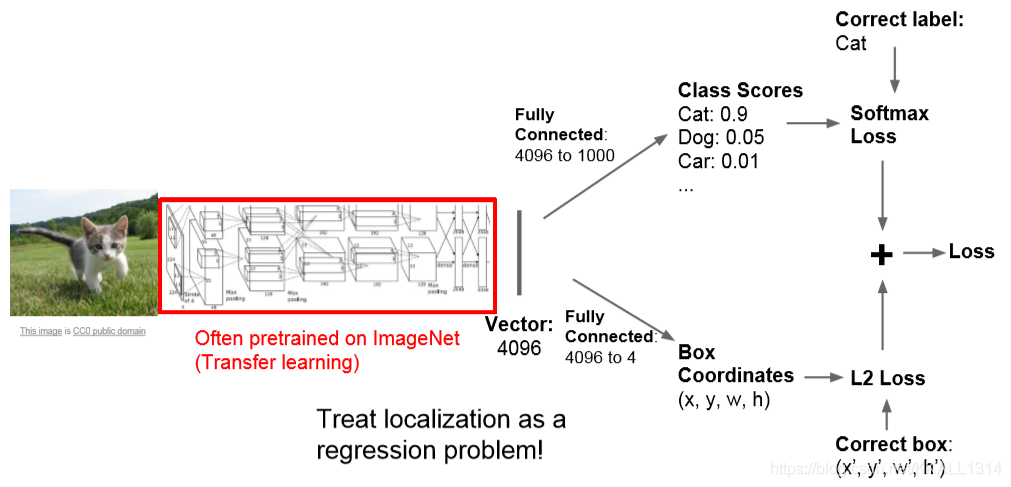
对于一幅含有猫的图片,除了判别该图像是猫,还想判断猫在哪里。这就是分类定位问题。提前知道有一个物体或多个物体是需要定位的。我们需要画出一个框来包括整个猫咪。解决该任务的一个模型如下所示。首先,在一个预训练的CNN网络上生成图像表示向量。然后用两个全连接层。第一个全连接层用于图像的分类。使用Softmax,交叉熵等损失函数来计算分类损失。第二个全连接层用于输出位置值(x,y,w,h)。使用L1损失,平滑L1损失,L2等损失韩式来计算回归损失。回归和分类的区别在于,回归的值是一个连续值,分类的值是一个离散值。网络的整体损失是分类损失和回归损失的加权和,需要手动设置加权参数。网络的训练方法可以是网络整体一起训练,这种效果会好。但实际中有一个训练技巧,首先冻结卷积网络,分别训练来优化两个全连接部分网络的参数,直到两个网络收敛,最后再对整体网络进行训练/联合调试。
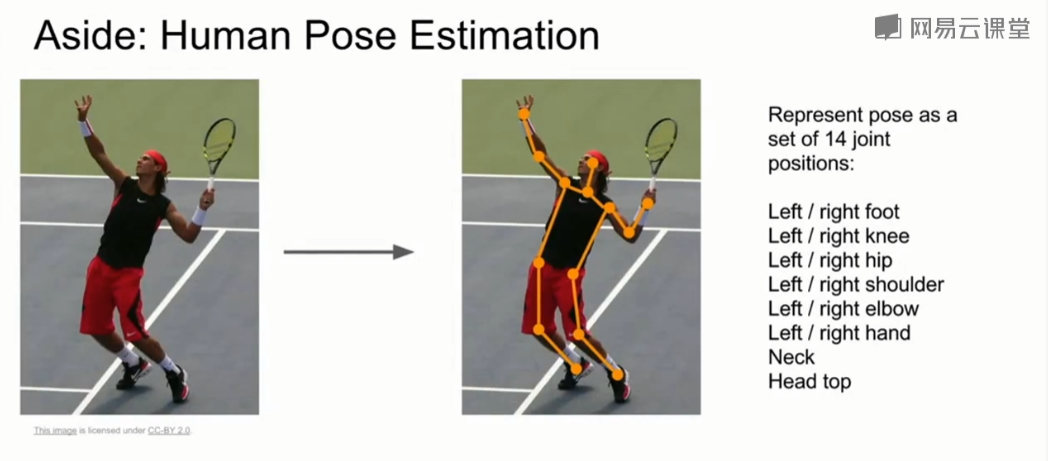
在图片中预测固定点的位置的想法可以应用到姿态估计。姿态估计的任务是,输入左边的图,输出人的关节/点位(右边的图)。这样网络就能预测出这个人的姿态。一般在深度学习中,使用14个关节点的位置来定义人的姿态。
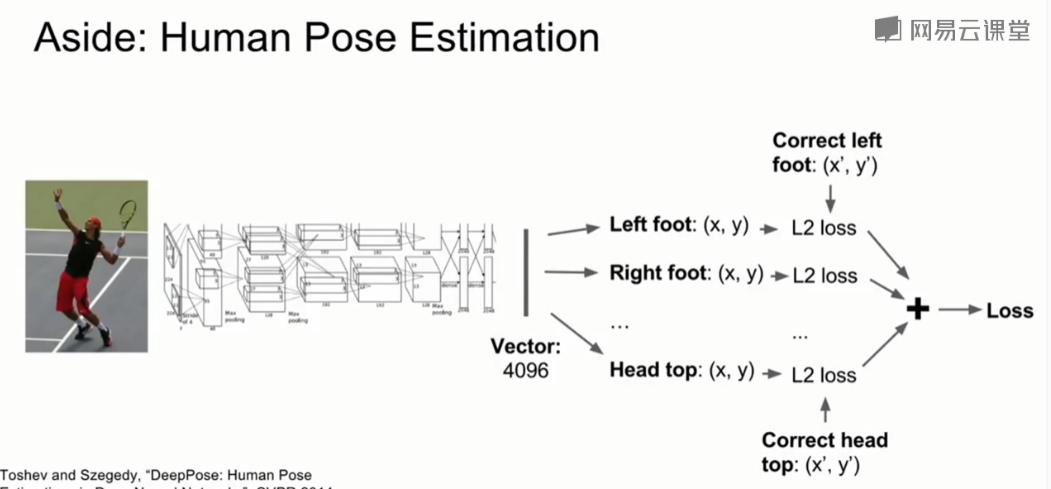
人体姿势估计模型如下所示。模型接收图片,然后使用使用CNN网络来得到图像表示向量,然后输出14个关节点的坐标值。分别计算14个关节点的回归损失,这里使用L2损失。然后对所有损失求和。
三、目标检测Object Detection
目标检测研究的是,根据输入图像,每当图像中出现一类对象时围绕对象画一个框并预测该对象从属的类别。目标检测与分类+定位的不同点在于我们无法提前得知图像中有多少个目标物体,因此将目标检测作为回归任务会非常棘手。
1、滑动窗口算法 object detection as classification:Sliding Window
将输入图像切分为小块,将图像块输入到CNN网络中,进行分类决策。当网络没有见过的范围之外的其他对象时,就会将其识别为背景Background。
这里有个大问题是如何选择图像块,图像中对象的数量、出现的位置、尺寸、比例都是不定的,这要测试成千上万次才能解决,并且每一块都要丢到CNN中计算,计算复杂度非常高,所以实际一般不这么做。

2、候选区域算法 Region Proposals
使用候选区域(Region Proposals)方法来进行目标检测。该方法在深度学习中并不常见,更像传统的计算机视觉方法。候选区域网络采用信号处理,图像处理等方法建立候选的区域。一般会在对象周围给出上千个框,如下图所示。使用候选区域的方法有Selective Search,R-CNN,Fast R-CNN,Faster R-CNN等。

R-CNN
给定输入图像,首先运行区域选择网络,找到大约2000个兴趣区域(Regionis of Interest,RoI),并会边界框进行修正;接着由于兴趣区域可能有不同尺寸,但都要输入到CNN中进行分类,因此,需要对兴趣区域进行切分,使得区域尺寸一致;最后将兴趣区域输入到CNN中进行分类。
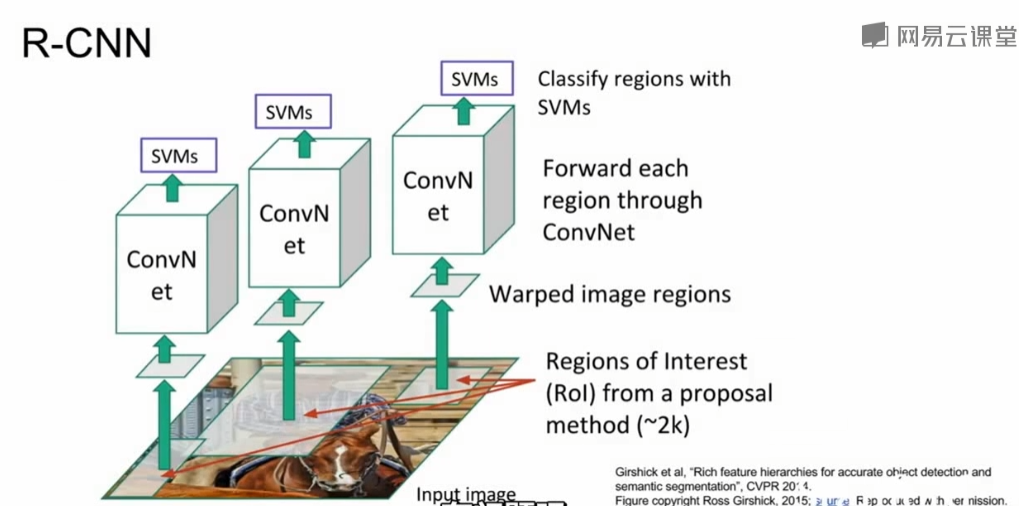
但该算法的实现需要许多计算力;训练时间慢(84h);占用很多磁盘空间;区域选择模型是固定的,并不学习参数。

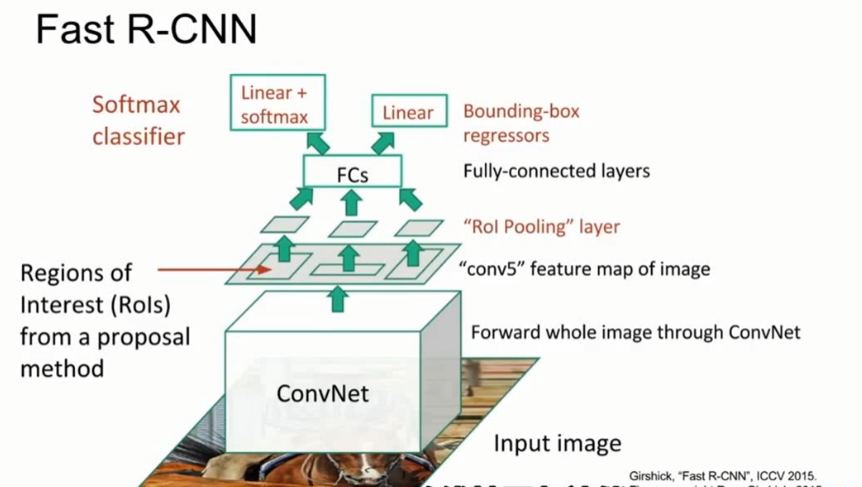
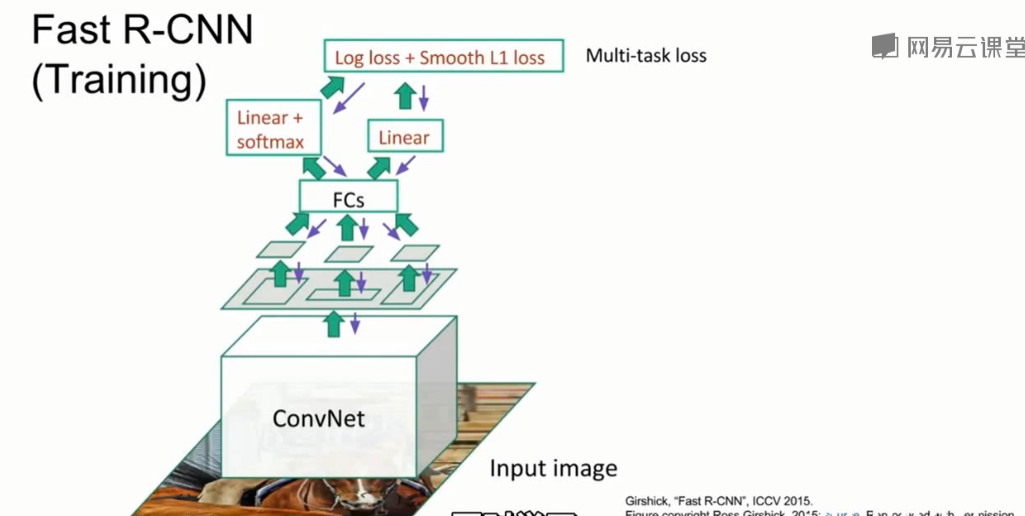
Fast R-CNN
Faster R-CNN
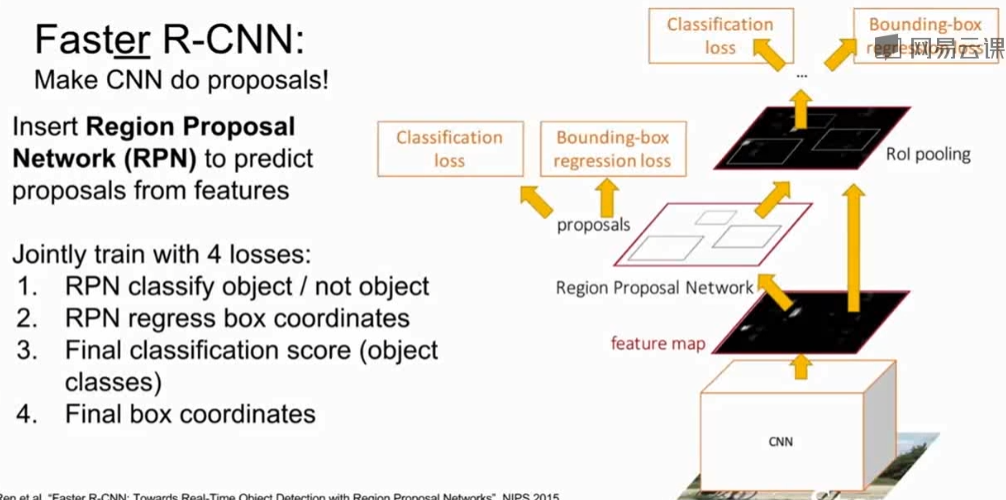
3、Detection without Proposals
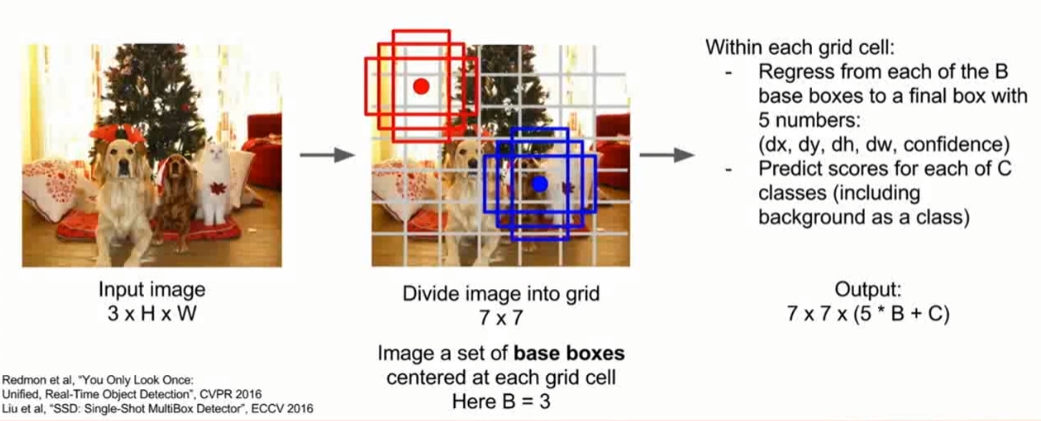
用于目标检测的另一种方法,是一种前馈模型,有两种模型:YOLO(You Only Look Once)和SSD(Single Shot Detection)。该类模型不对候选区域分别进行处理,而是尝试将其作为回归问题处理。借助于大型网络,所有的预测一次完成。下图是SSD模型方法。给定输入图像,将输入图像分成网格,例如7×7。以每个单元格为中心,分别画一些基本边界框,例如长的,宽的,正方形的三个基本边界框。模型要预测边界框与对象位置的偏移量;预测对象对应类别的分数。
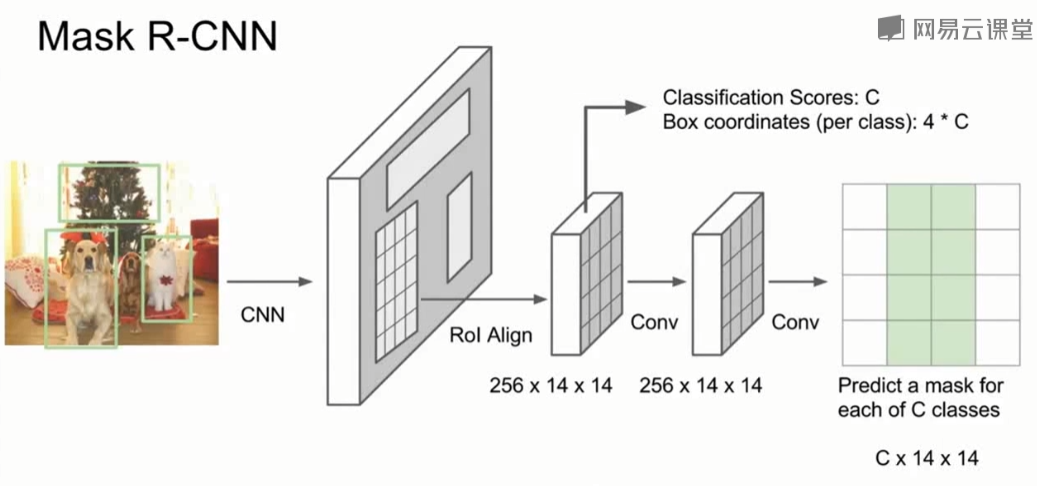
四、实例分割 Instance Segmentation
实例分割相当于是语义分割和目标检测的结合,我们需要检测出不同的实例,同时提供一个像素级别精度的分割。
Mask R-CNN模型是解决该问题的一个模型,如下所示。模型有两个分支,上面的分支用于预测对象的类别和框,下面的分支对输入候选框的像素进行分类,确定该像素是不是属于某个对象。它还可以做姿态估计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号