Python网络爬虫
第20章 网络爬虫开发
-
网络爬虫是一种按照一定的规则,自动抓取互联网信息的程序或脚本,目的是抓取网页中的内容为己用,减轻手动录入信息。
-
网络爬虫抓取的是html标签的内容,通过分析和过滤html代码,实现对图片和文字等资源的获取。
20.1 BeautifulSoup模块
爬虫项目的实际应用中,通常使用Beautiful Soup获取网页数据,其功能是从HTML或XML文件中提取数据。
20.1.1 环境搭建
- 用pip工具安装Beautiful Soup模块:
pip install beautifulsoup4(本文当前版本为4.10) - 安装XML文本的解析器:
pip install lxml - 安装html文本的解析器:
pip install html5lib(解析方式与浏览器相同)
20.1.2 BeautifulSoup的使用
-
用BeautifulSoup解析html代码:
from bs4 import BeautifulSoup # 编写一段html代码 html_doc = """ <html><head><title>解析html演示</title></head> <body> <p class="title"><b>小标题</b></P> <p class="content">内容1........................ <a href="http://example.com/content01" class="link" id="link1">链接1</a>、 <a href="http://example.com/content02" class="link" id="link2">链接2</a>、 <a href="http://example.com/content03" class="link" id="link3">链接3</a>, 内容2.............................</p> """ soup = BeautifulSoup(markup=html_doc) # 用构造器创建实例,解析代码。 print(soup.prettify()) # 修饰并输出实例中的html标签。// 输出内容如下,可见它自动缩进、自动补全结束标签。 <html> <head> <title> 解析html演示 </title> </head> <body> <p class="title"> <b> 小标题 </b> </p> <p class="content"> 内容1........................ <a class="link" href="http://example.com/content01" id="link1"> 链接1 </a> 、 <a class="link" href="http://example.com/content02" id="link2"> 链接2 </a> 、 <a class="link" href="http://example.com/content03" id="link3"> 链接3 </a> , 内容2............................. </p> </body> </html> -
用BeautifulSoup解析网页:
from bs4 import BeautifulSoup # 引入beautifulsoup模块 import urllib.request # 引入url工具 url = "http://www.baidu.com" html_page = urllib.request.urlopen(url) # 打开并创建网页对象 soup = BeautifulSoup(markup=html_page,features="html.parser") # 解析html代码,创建解析后的对象 print(soup) # 输出解析后的对象(不自动缩进修饰)。 -
用BeautifulSoup解析网页并抓取网页数据:
from bs4 import BeautifulSoup from urllib.request import urlopen url = "http://www.cmpedu.com/so.htm?&KEY=python" # 1. 打开网页,获取网页对象 html_page = urlopen(url) # 2. 解析html网页,获取解析对象 soup = BeautifulSoup(markup=html_page,features="html.parser") # 3. 用标准选择器findall()爬取所有书籍标题的标签 book_list = soup.findAll(name="div",attrs={"class":"ts_solgcont_title"}) # 4. 用css选择器select()爬取所有书籍价格的标签 books_price = soup.select(".ts_solgcont_bot .fl") # 5. 同时遍历两个列表,输出便签中的文本 for book_name, price in zip(book_list, books_price): print(book_name.get_text(), price.get_text())![image-20211026113432874]()

20.1.3 BeautifulSoup的三种选择器
-
标签选择器
print(soup.title) #将title标签里的代码,含title print(soup.head) #获取head标签内代码,含head print(soup.p) #获取第一个p标签代码,含p print(soup.title.name) #获取标签的名称,如这个显示为title标签 print(soup.p.attrs['name']) #获取p标签的name属性的值 print(soup.p['name']) #等同与上一条指令 print(soup.p.string) #获取标签p内的内容,不含p print(soup.head.title.string) #层层迭代,获取head标签里的title标签里的文本 # 其他详情请查看文档 -
标准选择器
# 参数表:标签名、特征字典、文本等。 book_list = soup.findAll(name="div",attrs={"class":"ts_solgcont_title"}) # 其他标准选择器,参数详情查看文档。 find(name,attrs,recursive,text,**kwargs) # 返回单个标签代码 find_parents() # 返回直接父节点。 find_next_siblings() # 返回后面第一个兄弟节点。 find_previous_siblings() # 返回前面第一个兄弟节点。 find_all_next() # 返回第一个符合条件的节点 find_all_previous() # 返回第一个符合条件的节点 -
CSS选择器
# 基本选择 print(soup.select('.panel .panel-heading')) #选择class的类型 print(soup.select('ul li')) #直接选择标签 print(soup.select('#list-2 .element')) #选择id的类型 print(type(soup.select('ul')[0])) # 层层迭代选择 for ul in soup.select('ul'): print(ul.select('li')) # 获取标签属性 for ul in soup.select('ul'): print(ul['id']) #这两种方法都能获取标签的属性(id或其他) print(ul.attrs['id']) # 获取标签文本 for li in soup.select('li'): print(li.get_text()) #输出li里的内容
20.2 XPath模块
XPath是一门在XML文件中查找信息的语言,可以根据DOM模型的元素树结构,遍历并提取XML文档中的元素和属性,提供了非常简明的路径选择表达式,和上百个用于处理字符串、数值、时间、节点、序列的内置函数。
20.2.1 环境搭建
XPath是一门语言表达,安装xml文档的解析模块lxml.py,其中的etree子模块,可以使用XPath。
- 安装lxml模块:
pip install lxml - 引入etree子模块:
from lxml import etree
20.2.2 XPath的使用
-
使用XPath解析HTML代码并定位指定标签:
from lxml import etree # 一段html代码 html_code = """ <div> <ul> <li class="item"><a href="link1.html"> item-1</a></li> <li class="item"><a href="link2.html"> item-2</a></li> <li class="item"><a href="link3.html"> item-3</a></li> <li class="item"><a href="link4.html"> item-4</a></li> <li class="item"><a href="link5.html"> item-5</a></li> </ul> </div> """ # 解析html并获取对象,会自动补全缺少的标签 html = etree.HTML(html_code) # 从对象中获取html代码,默认为ASCII字符 code = etree.tostring(html) # 转为utf-8字符并输出 print(code.decode("utf-8")) # 用XPath收集指定标签并输出便签中的文本 messages = html.xpath("/html/body/div/ul/li/a") for mess in messages: print(mess.text) -
用XPath爬取网页数据:
from lxml import etree # 指定url url = "http://www.cmpedu.com/so.htm?&KEY=python" # 解析网页html并返回对象(该parse()方法需要实例化一个html解析器作参数。 html = etree.parse(url, etree.HTMLParser()) # 用XPath根据标签属性定位到指定标签,只收集文本,生成数据集 dataset = html.xpath("//div[@class='ts_solgcont_title']/a/text()") # 输出数据集 for data in dataset: print(data)
20.3 Scrapy爬虫框架
Scrapy是一个提取结构性数据而编写的爬虫项目框架,可以用于数据挖掘、数据监测、自动化测试等工作。
20.3.1 Scrapy框架说明
-
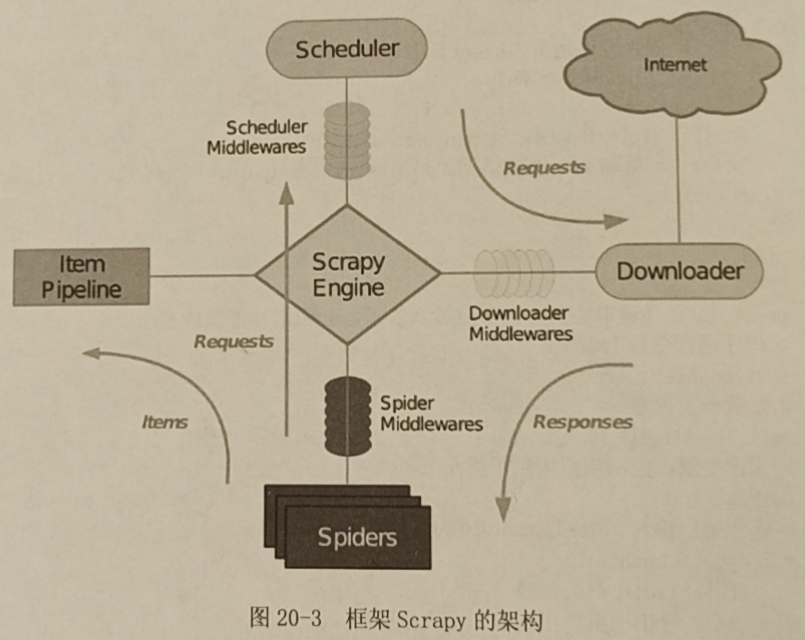
Scrapy框架使用了Twisted异步网络库处理网络通信,框架的组件和整体架构如下:
-
Scrapy Engine引擎:用来处理整个系统的数据流和事务,是框架的核心。
-
Scheduler调度器:用来接收引擎发过来的请求,压入url队列,由此组件决定下一个抓取的网址是什么,并去除重复的网址。
-
Downloader下载器:用于下载网页内容,返回给Spider去处理。
-
Spider爬取器:用于从特定网页提取需要的信息项(Item)。
-
Item Pipeline项管道:负责处理爬出的信息项,如持久化、验证有效性、清除无效信息。页面被爬虫解析后发送到管道处理。
-
Downloader Middlewares:下载器中间件,介于引擎和下载器之间的框架,用于处理它们之间的请求和响应。
-
Spider Middlewares:爬取器中间件,介于引擎和爬取器之间的框架,用于处理之间的请求和响应。
-
Scheduler Middlewares:调度器中间件,介于引擎和调度器之间,处理之间的请求和响应。
![image]()
-
-
工作流程:
- 引擎从调度器取出一个链接。
- 引擎吧链接封装成请求对象(request)传给下载器。
- 下载器下载资源,封装成响应对象(response)传给爬取器。
- 爬取器解析response对象。
- 若解析出信息项(Item),交给项管道处理。
- 若解析出链接(URL),交给调度器等待抓取。
20.3.2 环境搭建
-
用pip工具安装Scrapy模块:
pip install scrapy -
用pip工具安装pywin32模块,功能是方便python开发者快速调用windows系统的API,同时pywin32也是大部分windows上第三方python模块库的前提,一些第三方模块没有安装pywin32是无法正常使用。
pip install pywin32
20.3.3 实现一个Scrapy项目
-
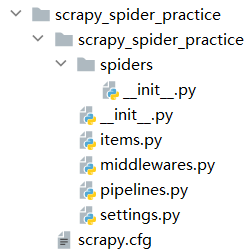
创建项目,终端进入创建位置,执行
scrapy startproject project_name,会出现以下项目目录,【scrapy.cfg】是项目的配置文件,其他 Python模块对应着上述scrapy框架的组件,【settings.py】是项目的设置文件。![image]()
-
定义Item
-
Item是保存爬取数据的容器,与字典类似,可以自定义内容。
-
打开【items.py】文件,继承scrapy.Item类定义一个子类,用scrapy.Field类创建3个实例作为类属性:
import scrapy # 继承Item类 class DataItem(scrapy.Item): # 实例化Field类作为成员对象。 title = scrapy.Field() link = scrapy.Field() description = scrapy.Field()
-
-
编写第一个爬虫程序
-
即定义一个用于爬取数据的类,包含了下载初始URL、跟进网页链接、解析网页内容、提取生成信息项Item等方法。
-
在【spiders】目录下新建【first_spider.py】文件,继承scrapy.Spider类,并重写几个方法:
import scrapy class FirstSpider(scrapy.Spider): # 定义名字,用于区分spider,必须唯一。 name = "first-spider" # 设置过滤,不在此允许范围内的域名就会被过滤,不爬取。 allowed_domains = ["dmoz-odp.org"] # 这里将网页目录索引网站作为爬取的域名。 # 设置起始地址,后续的URL将从起始地址获取的url列表中提取。 start_urls = [ "https://www.dmoz-odp.org/Computers/Programming/Languages/Python/Books/", "https://www.dmoz-odp.org/Computers/Programming/Languages/Python/Resources/" ] # 处理方法,url的响应消息将传给该方法,负责解析和提取数据,生成下一个url的请求消息。 def parse(self, response): # 取url倒数第二个目录作文件名。 filename = response.url.split("/")[-2] # 以二进制写入的方式创建一个文本,返回给f,并写入响应消息。 with open(file=filename, mode="wb") as f: # with关键字是简化的异常处理模式。 f.write(response.body)
-
-
爬取url数据
-
终端进入项目根目录,执行
scrapy crawl first-spider,可见窗口在输出执行信息。 -
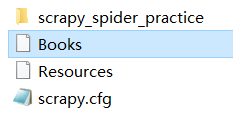
执行完毕后,可见项目生成了两个保存url的文本。
![image]()
-
-
提取Item
- 当爬取完毕后,可以载入scrapy自带的shell查看保存到本地的url响应消息的对象。
- 在项目根目录执行
scrapy shell "https://www.dmoz-odp.org/Computers/Programming/Languages/Python/Books/",载入了该URL的shell,并输出Item信息。 - 再执行
response.headers,会输出响应消息头。 - 执行
response.body,会输出响应消息体。 - 执行
response.selector,会获取查询数据的选择器,可以以 XPath 或 CSS 的选择方式进行匹配。
-
提取数据
-
在shell中执行
response.xpath("expression"),以XPath方式搜索并返回节点列表。 -
response.css("expression"),以css选择器方式搜索并返回节点列表。 -
response.re("expression"),以正则表达式匹配并返回Unicode字符的节点列表。 -
extract()方法,序列号节点为Unicode字符并返回列表。
response.xpath("//ul/li/a/") // 获取标签的列表 response.xpath("//ul/li/a/text()") // 获取标签中文本列表 response.xpath("//ul/li/a/text()").extract() // 获取文本列表并转为Unicode。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号