
Memcache详解
Memcache详解
参考链接
https://blog.51cto.com/freeloda/1289806
https://acecodeinterview.com/memcached/
https://hoverzheng.github.io/post/technology-blog/architect/memcached架构分析/
https://segmentfault.com/a/1190000016173095
https://blog.csdn.net/xin93/article/details/80712527
https://zhuanlan.zhihu.com/p/87810822
什么是memcache
- 官方的描述,Memcached是一个高性能分布式的内存对象缓存系统。
- 它将数据以key-value形式存储的存储在内存中,极大的提高了效率。
- 但是Memcached的缺点在于不支持持久化(不支持写入磁盘),所以一旦断电,内存中的全部数据都会丢失。
- 而Redis弥补了这个缺点,既在内存中存取数据,又支持持久化,所以Memcached可以理解为是Redis的前身
应用场景
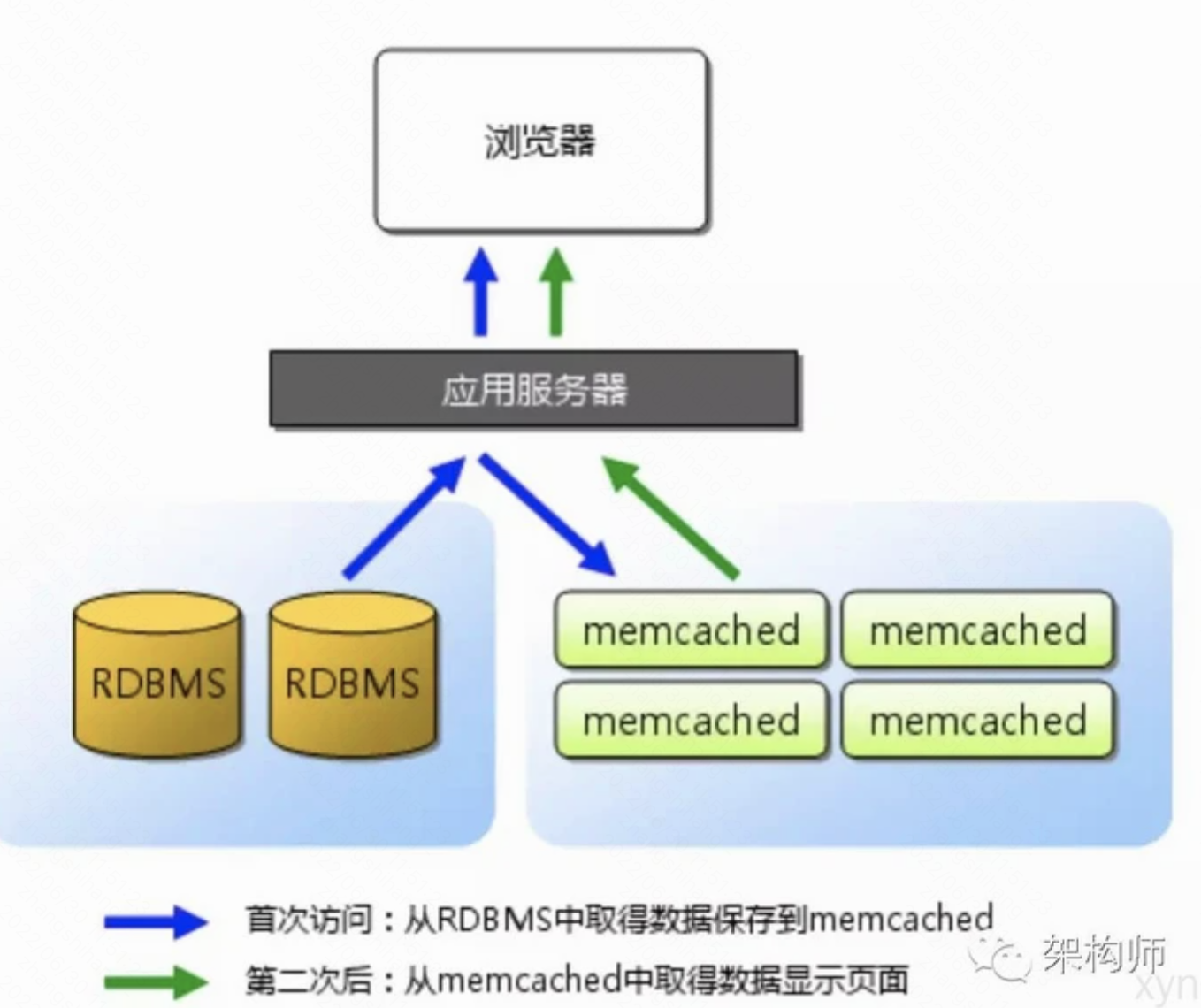
- 在高并发的场景下, 大量的读/写请求涌向数据库, 此时磁盘IO将成为瓶颈, 从而导致过高的响应延迟
特点
| 特点 | 描述 |
|---|---|
| 协议简单 | 它是基于文本行的协议,可以直接通过telnet在memcached服务器上可进行存取数据操作 |
| 基于libevent事件处理 | 异步I/O, 基于事件的单进程和单线程, 使用libevent作为事件处理机制; |
| 内置内存存储方式, 非持久性存储 | 所有数据都保存在内存中,存取数据比硬盘快,当内存满后,通过LRU算法自动删除不使用的缓存,但没有考虑数据的容灾问题,重启服务,所有数据会丢失。 |
| 分布式 | 各个memcached服务器之间互不通信,各自独立存取数据,不共享任何信息。服务器并不具有分布式功能,分布式部署取决于memcache客户端。 |
架构
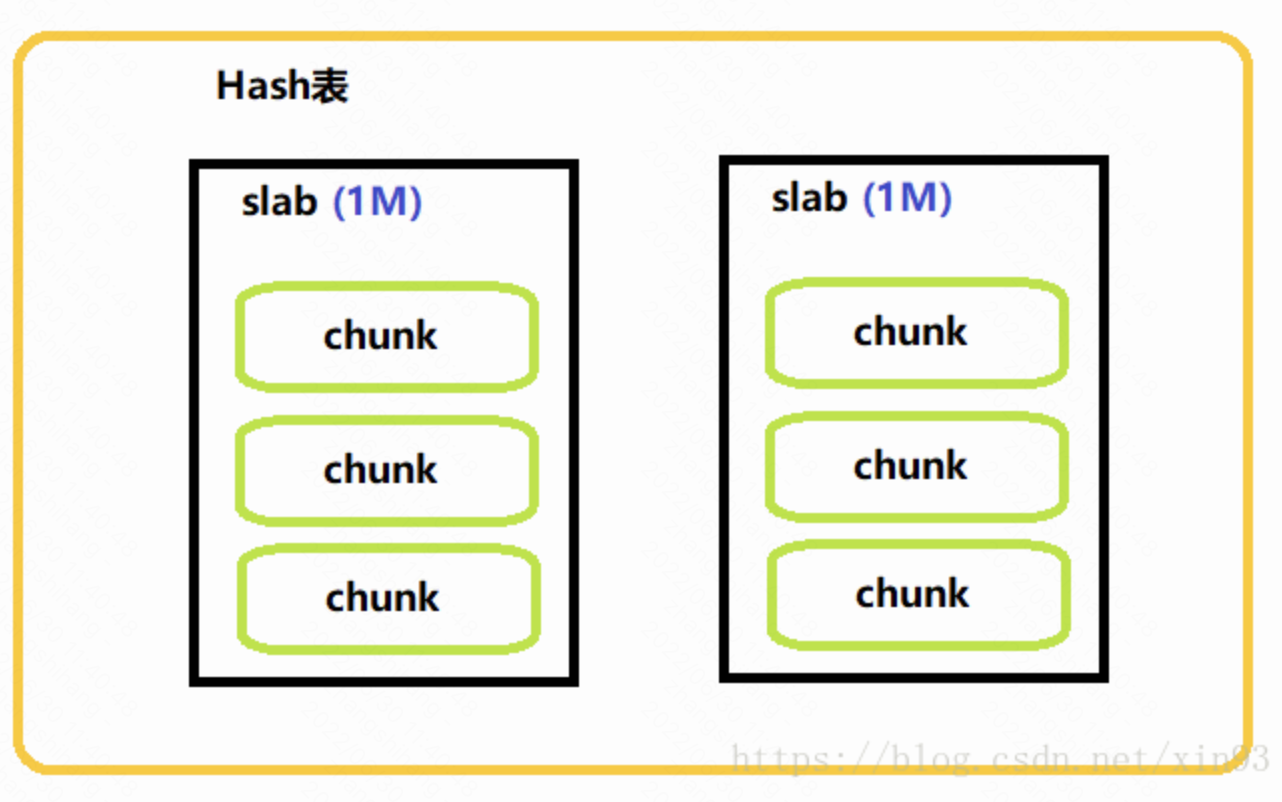
- Memcached是在内存中维护一张巨大的Hash表。
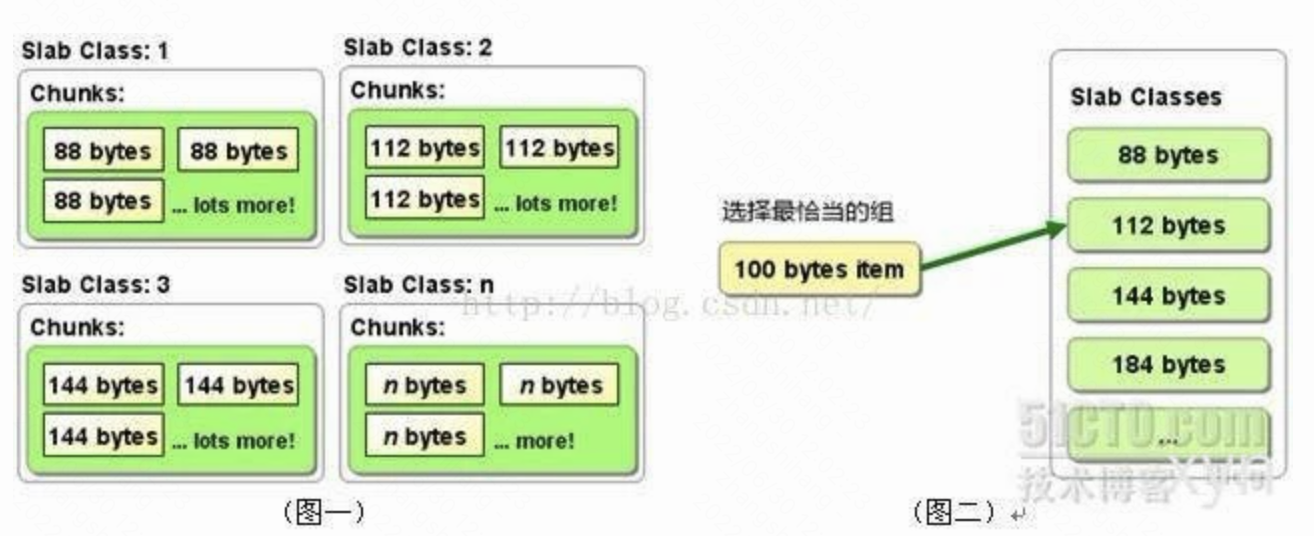
- 这张Hash表的结构是由多个slab组成,每个slab的大小是1M;每个slab中存在多个chunk,chunk是数据最终存储的单位。
- chunk采用预分配的方式提高性能,在保存数据之前,需要制定chunk的大小来分配内存。
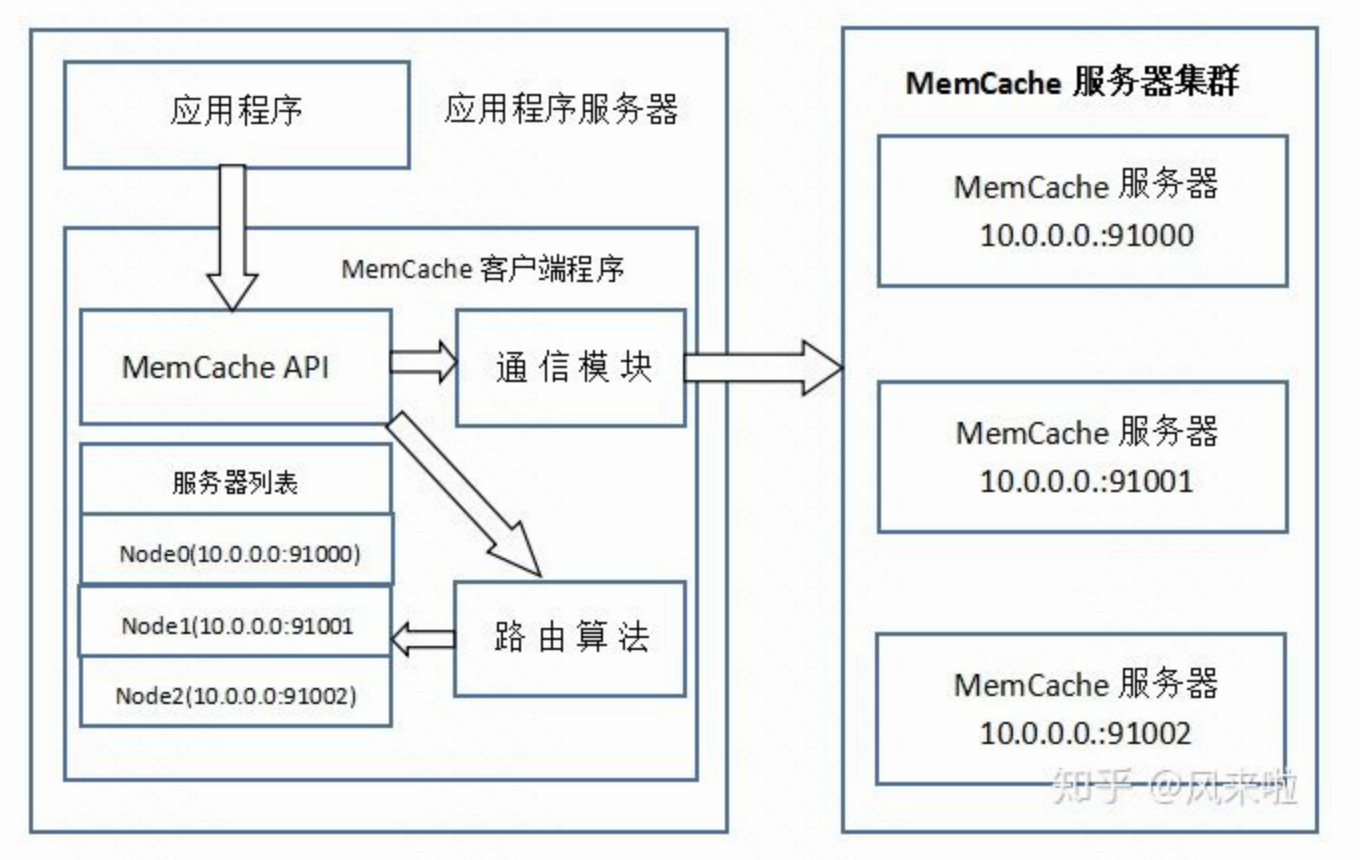
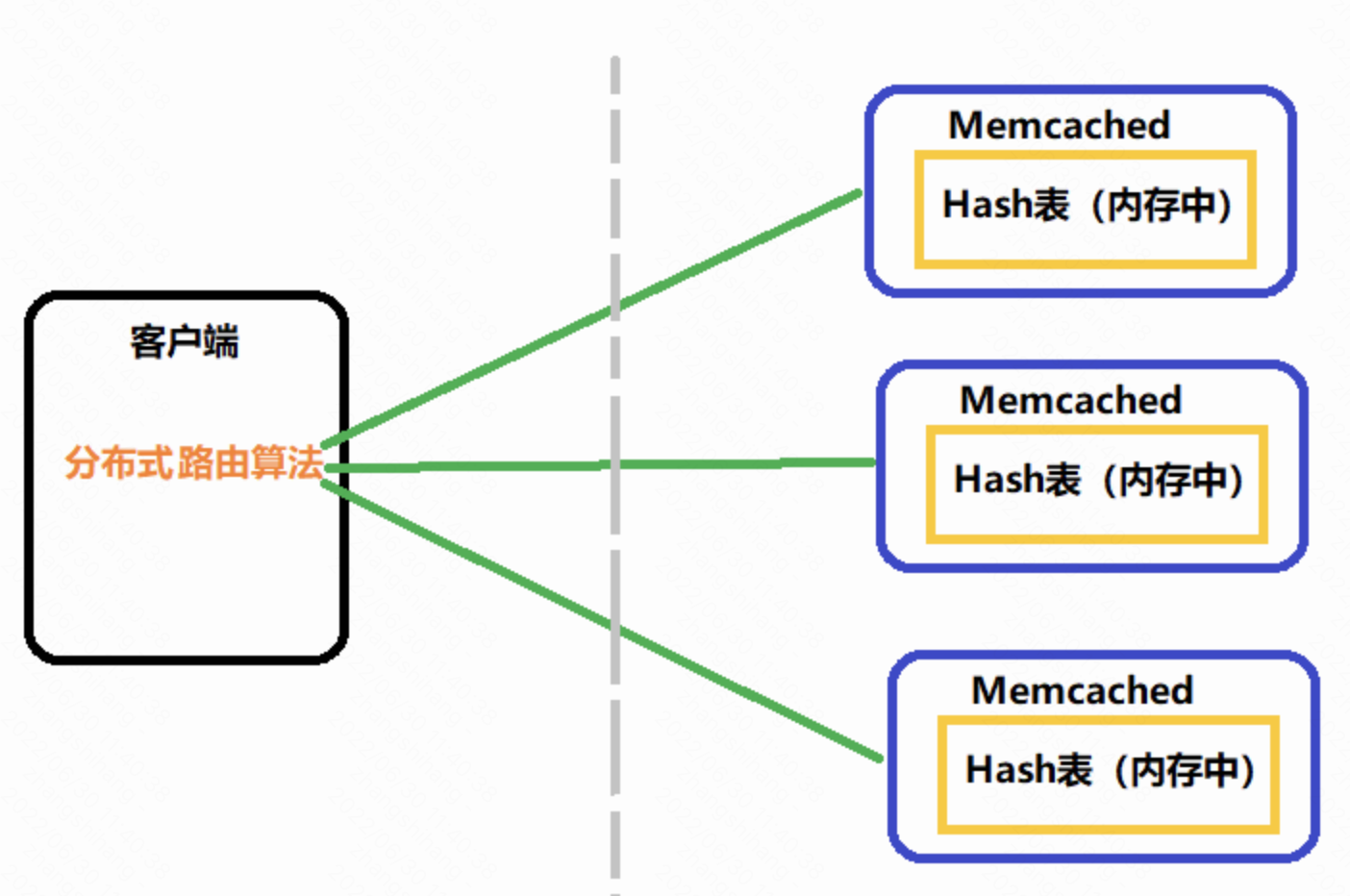
- Memcached官方版本不支持集群搭建,Memcached彼此之间不进行通信,也就是把一个数据存到一个Memcached上,一旦这个Memcached宕掉了,不能从其它Memcached上读取这些数据,会造成数据丢失。
写流程
-
应用程序输入需要写缓存的数据
-
API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
-
由服务器编号得到MemCache及其的ip地址和端口号
-
API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
-
读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,只要应用程序查询的是相同的Key,
-
MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
-
这种MemCache集群的方式也是从分区容错性的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
接口
| 分类 | 方法 | 描述 |
|---|---|---|
| 存 | set | 添加一个新条目到memcached或是用新的数据替换替换掉已存在的条目 |
| 存 | add | 当KEY不存在的情况下,它向memcached存数据,否则,返回NOT_STORED响应 |
| 存 | replace | 当KEY存在的情况下,它才会向memcached存数据,否则返回NOT_STORED响应 |
| 存 | cas | 改变一个存在的KEY值 ,但它还带了检查的功能 |
| 存 | append | 在这个值后面插入新值 |
| 存 | prepend | 在这个值前面插入新值 |
| 取 | get | 取单个值 ,从缓存中返回数据时,将在第一行得到KEY的名字,flag的值和返回的value长度,真正的数据在第二行,最后返回END,如KEY不存在,第一行就直接返回END |
| 取 | get_multi | 一次性取多个值 |
| 删 | delete |
| 命令 | 描述 |
|---|---|
| stats | 统计memcached的各种信息 |
| stats reset | 重新统计数据 |
| stats slabs | 显示slabs信息,可以详细看到数据的分段存储情况 |
| stats items | 显示slab中的item数目 |
| stats cachedump 1 0 | 列出slabs第一段里存的KEY值 |
| set/get | 保存/获取数据 |
| STAT evictions 0 | 表示要腾出新空间给新的item而移动的合法item数目 |
- 不能够遍历MemCache中所有的item,因为这个操作的速度相对缓慢且会阻塞其他的操作
内存设计
-
Memcached利用slab allocation机制来分配和管理内存,它按照预先规定的大小,将分配的内存分割成特定长度的内存块,再把尺寸相同的内存块分成组,数据在存放时,根据键值 大小去匹配slab大小,找就近的slab存放,所以存在空间浪费现象。
-
传统的内存管理方式是,使用完通过malloc分配的内存后通过free来回收内存,这种方式容易产生内存碎片并降低操作系统对内存的管理效率。
-
Memcached的内存管理制效率高,而且不会造成内存碎片,但是它最大的缺点就是会导致空间浪费。因为每个 Chunk都分配了特定长度的内存空间,所以变长数据无法充分利用这些空间。如图二所示,将100个字节的数据缓存到128个字节的Chunk中,剩余的28个字节就浪费掉了。
-
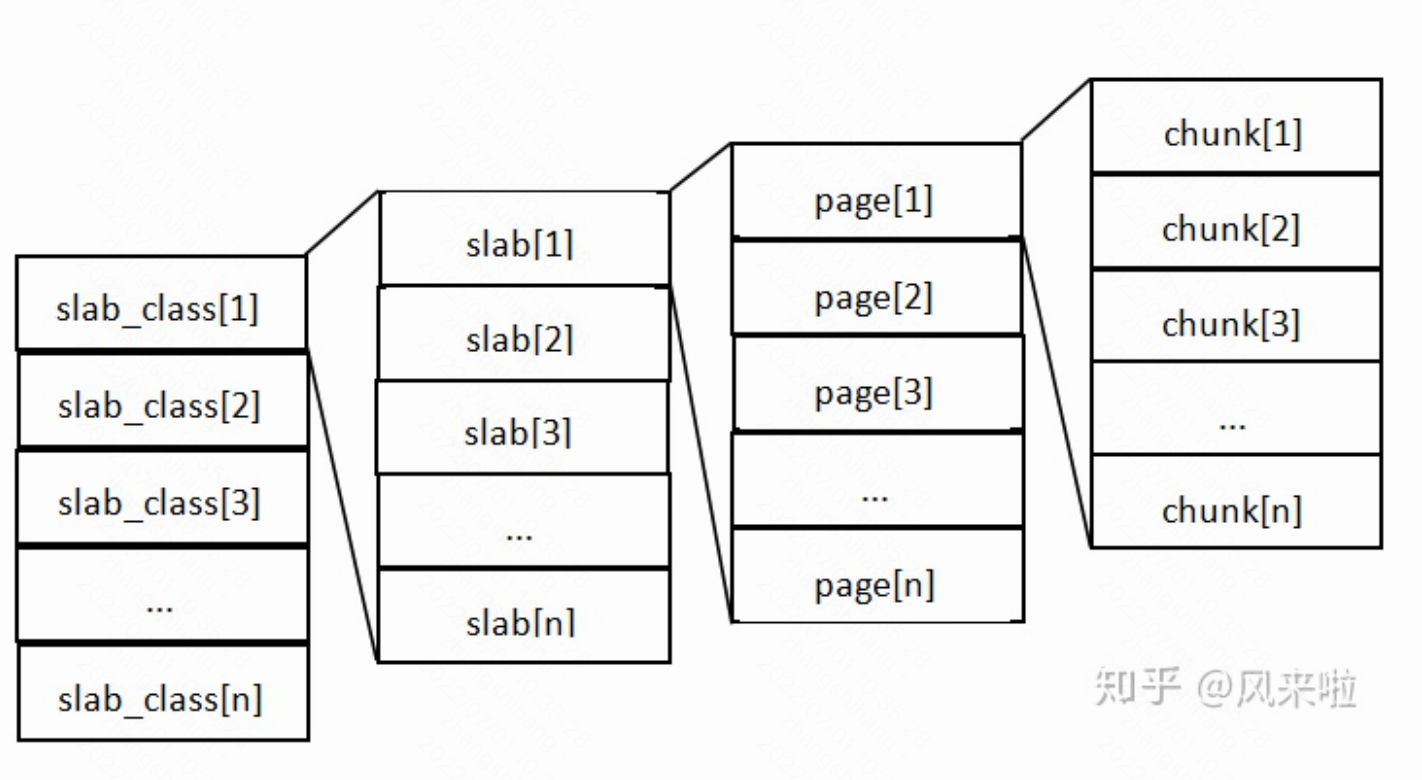
MemCache将内存空间分为一组slab
-
每个slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page
-
每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的
-
有相同大小chunk的slab被组织在一起,称为slab_class
-
MemCache内存分配的方式称为allocator,slab的数量是有限的,几个、十几个或者几十个,这个和启动参数的配置相关。
-
MemCache中的value过来存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中
-
MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节(紧接着大的用)的chunk中,就损失了30字节,但是这也避免了管理内存碎片的问题
-
MemCache存放的value大小是限制的,因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了
如何避免内存浪费
- 预先计算出应用存入的数据大小,或把同一业务类型的数据存入一个Memcached服务器中,确保存入的数据大小相对均匀,这样就可以减少对内存的浪费
- 在启动时指定“-f"参数,能在某种程度上控制内存组之间的大小差异
- 在应用中使用Memcached时,通常可以不重新设置这个参数,使用默认值1.25进行部署
- 如果想优化Memcached对内存的使用,可以考虑重新计算数据的预期平均长度,调整这个参数来获得合适的设置值
删除机制(缓存策略)
-
Memcached的缓存策略是LRU(最近最少使用)加上到期失效策略。
-
MemCache的LRU算法不是针对全局的,是针对slab的
-
当你在memcached内存储数据项时,你有可能会指定它在缓存的失效时间,默认为永久。当memcached服务器用完分配的内时,失效的数据被首先替换,然后也是最近未使用的数据。
-
在LRU中,memcached使用的是一种Lazy Expiration策略,自己不会监控存入的key/vlue对是否过期,而是在获取key值时查看记录的时间戳,检查key/value对空间是否过期,这样可减轻服务器的负载。
-
当空间占满时
- 使用LRU算法来分配空间,删除最近最少使用的key/value对
- 如果不使用LRU的话, 在启动参数上加入”-M”, 内存耗尽时,会返回报错信息
内存回收机制
目标
- 防止常被访问的 Key 被踢出
- 降低延迟 - 减少 LRU Lock 的使用
- 合理协调各 class 的内存
Segmented LRU (分段式LRU)
对于单个数据会维护两个状态。
- Fetched 当数据被访问时,设置为1。
- Active 当数据被访问第二次时设置为1。被往前提 (Bump) 或移动时设置为0。
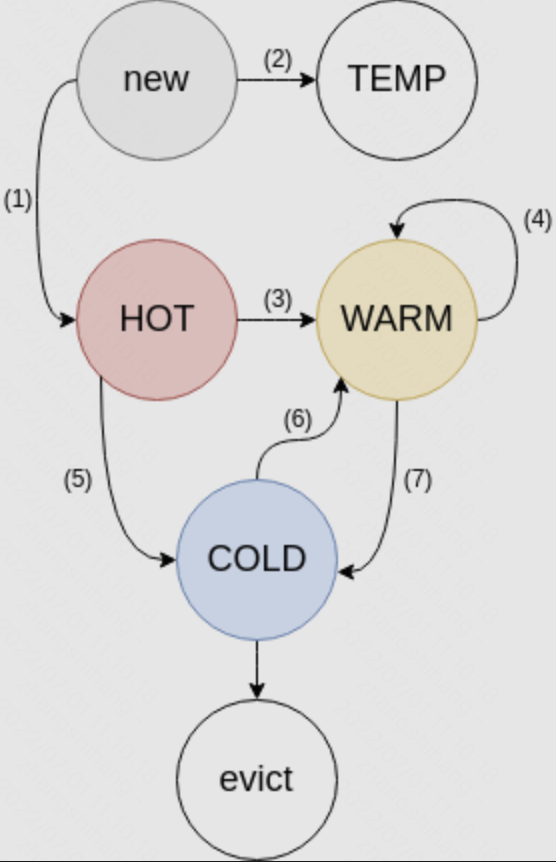
LRU 被分成四个子 LRU。
- HOT
- 新的数据从这里进来
- 数据在这里排成队列,一旦到了队尾,如果 Active,放入 WARM;如果不是,放入 COLD
- 数据即使被访问了,顺序也始终不变
- 此 LRU 占用内存的大小主要会被限制在全部内存的一定百分比
- 队尾数据的年龄会相对 COLD 队尾数据的年龄被限制
- WARM
- 只有当数据被访问至少两次时,才会被放到 WARM
- 如果队尾数据是 Active,放到队头;如果不是,放入 COLD
- 此 LRU 占用内存的大小主要会被限制在全部内存的一定百分比 (与 HOT 相同)
- 队尾数据的年龄会相对 COLD 队尾数据的年龄被限制 (与 HOT 相同)
- COLD
- 内存满之后,COLD 的队尾数据会被踢出
- 当 COLD 队列里的数据变得 Active,该数据会被异步放入 WARM。
- 这个异步放入 WARM 的操作可能不及时,甚至在过载情况下变得在部分时候随机发生。
- TEMP
- 默认不使用
- 用于超短 TTL 数据
- 数据即使被访问了,顺序也始终不变,也不会移到其他地方
以上四个子 LRU 规则的维护是由称为 LRU Maintainer 的后台线程实现的。
- 遍历所有的子 LRU,看一下队尾
- 保证每个子 LRU 在大小范围以及队尾在年龄范围内,如果不满足,移动一些数据。
- 回收过期数据内存
- 异步将 COLD 队列里的 Active 数据放入 WARM
- 如果特定 class 已经没有 COLD 数据可以踢了,那么普通的 worker 线程会 block SET 指令,将数据踢出 HOT 和 WARM,而不是依赖后台线程处理。
这个机制很巧妙地做到了以下几个点
- LRU 维护不会在取数据时发生,也就不会有 LRU lock
- LRU 维护绝大多数情况下是异步发生的
- 多个子 LRU 各自维护自己的 LRU lock,使得一个子 LRU lock 时,别的依旧可以写
- 每个数据的状态仅 2 bit
LRU Crawler
如何保证 class 之间的内存分配是合理的呢,要准确了解内存情况就得先处理掉内存中的过期数据
- 从每个 class 的每个子 LRU 的队尾同步开始向队头方向寻找,回收过期数据。
- 这里同步的意思是排好队齐步走,这样较短的 class 会很快完成,不至于要一直等到较长的 class 完成后被处理。
- Crawler 边走边维护一个 TTL 直方图,并根据直方图决定多久以后再重新扫描该LRU。
- 如果一个 class 有很多马上就要过期的数据,那么 Crawler 就会在短时间内重新扫描,反之,则可以等等。
这里的设计目标是尽快地回收最大量的内存。
上述的规则会自然地反复快速地回收序号较大的 class 来回收尽可能多的内存,也会根据使用特征来在不同 class 之间平衡数据回收的频率。
Slab Rebalance
-
这是一个可选的功能。
-
随着信息结构的变化,信息的大小会有起伏,使得某一些 class 的大小不再合适。Slab Automove 和 Slab Reassign 功能使得一个 class 的内存可以重新分配到别的class里。
-
Slab Automove 会根据每个 class 里一定时间内内存被提出的次数来找到需要更多内存的class
-
Slab Automove 会根据每个 class 里空余的内存来找到可以减少内存的 class
-
Slab Reassign 实现将一个 page 从 class A 移交到 class B 的交接工作,使用一个后台进程将这个 page 内所有的数据全部提出并且完成移交。
路由算法
- Memcached路由算法,由它来决定数据最终存储在哪个Memcached上。
- Memcached路由算法是由客户端实现的。
hash算法取余
- 将key做hash运算,对memcached数量进行求余数,根据余数来决定存储到哪个Memcached实例。
- 这样根据余数路由的优点在于,能够使数据均匀分布在每个Memcached上,但是也有很大的缺点,一旦某个Memcached宕机,或有新的memcached加入就会找不到数据,出现*严重的数据丢失*。
- 假设服务器由3台扩容到20+的台数,只有前三个HashCode对应的Key是命中的,也就是15%。不仅仅是无法命中,那些大量的无法命中的数据还在原缓存中在被移除前占据着内存。这个结果显然是无法接受的。当大部分被缓存了的数据因为服务器扩容而不能正确读取时,这些数据访问的压力就落在了数据库的身上,这将大大超过数据库的负载能力,严重的可能会导致数据库宕机。
一致性hash
- 一致性hash能够将丢失的数据减小到最小,但不能完全解决宕机造成的数据丢失。
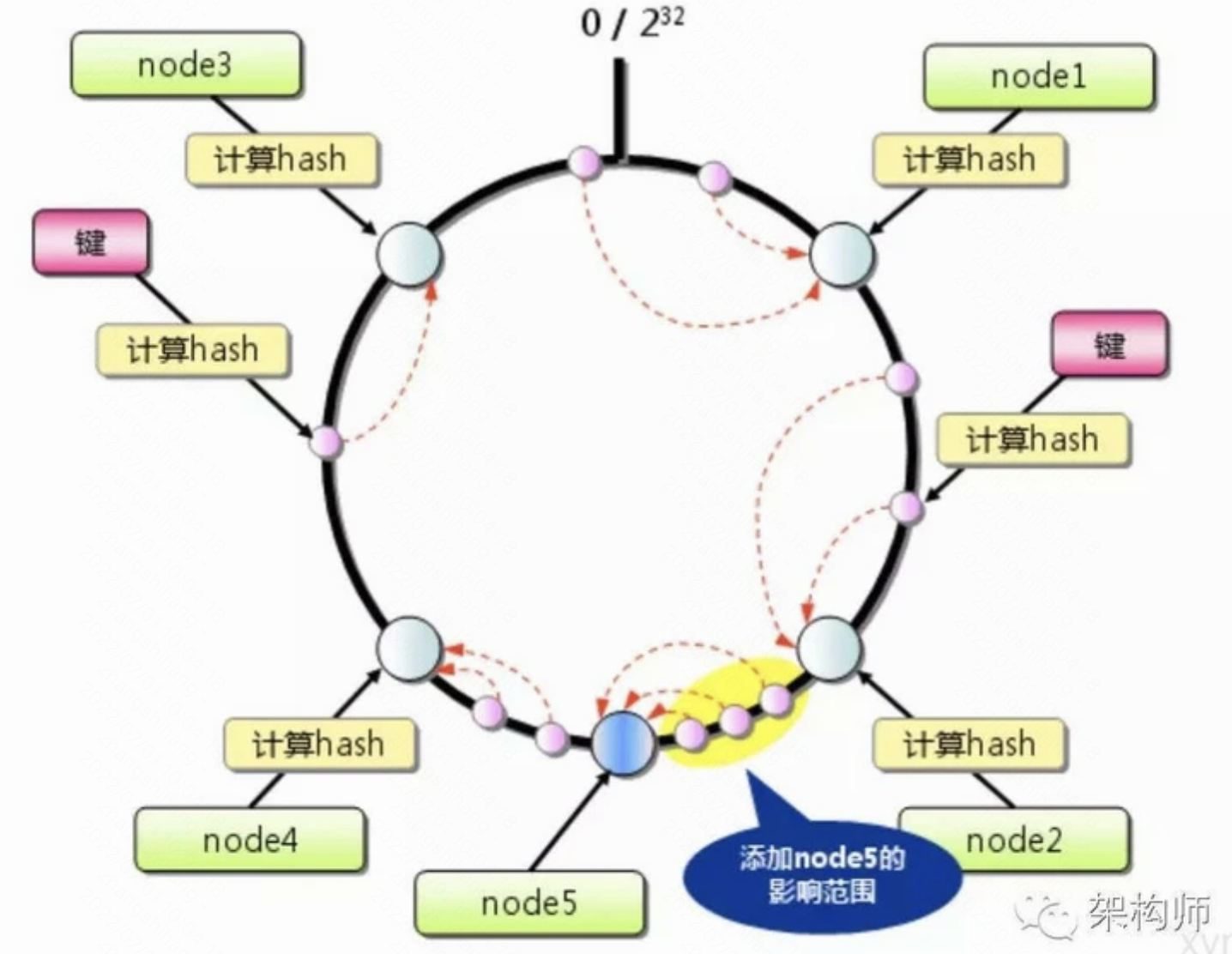
- 一般的一致性hash算法最大限度的抑制了键的重新分配, 并且有的实现方式还采用了虚拟节点的思想
- 服务器的映射地点的分布非常的不均匀, 导致数据访问倾斜, 大量的key被映射到同一台服务器上.
- 虚拟节点: 每台机器计算出多个hash值, 每个值对应环上的一个节点位置
- key的映射方式不变, 就多了层从虚拟节点到再映射到物理机的过程
memcache和redis的区别
| 对比点 | memcached | redis |
|---|---|---|
| 数据结构 | 单一(存储数据的类型都是String字符串类型) | 丰富(String、List、Set、Sortedset、Hash) |
| 内存使用率 | 使用简单的key-value存储,Memcached的内存利用率更高 | Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached |
| 持久化 | 不可以 | 可以(可以把数据随时存储在磁盘上) |
| 数据同步 | 不可以 | 可以 |
| 多核 | 可以使用多核(多线程) | 单核 |
| 数据大小 | 单个key(变量)存放的数据有1M的限制 | 单个key(变量)存放的数据有1GB的限制 |
| 计算能力 | 无 | 本身有一定的计算功能 |
- Redis在存储小数据时比Memcached性能更高
- 在100k以上的数据中,Memcached性能要高于Redis
- memcached增加了网络IO的次数和数据体积
memcached和redis对过期数据的处理
Redis是lazy处理,对有有效期的数据会做有效期的标识,在指定时间会对有过期时间的数据做处理。
随机取出一部分数据,检查是否有过期数据,如果过期数据超过25/100,则反复此过程
服务端设计
在memcached中,可以大致把线程分为两种:
- 一种是分发线程(主线程)
- 一种是worker线程,也就是进行后续命令处理的线程。
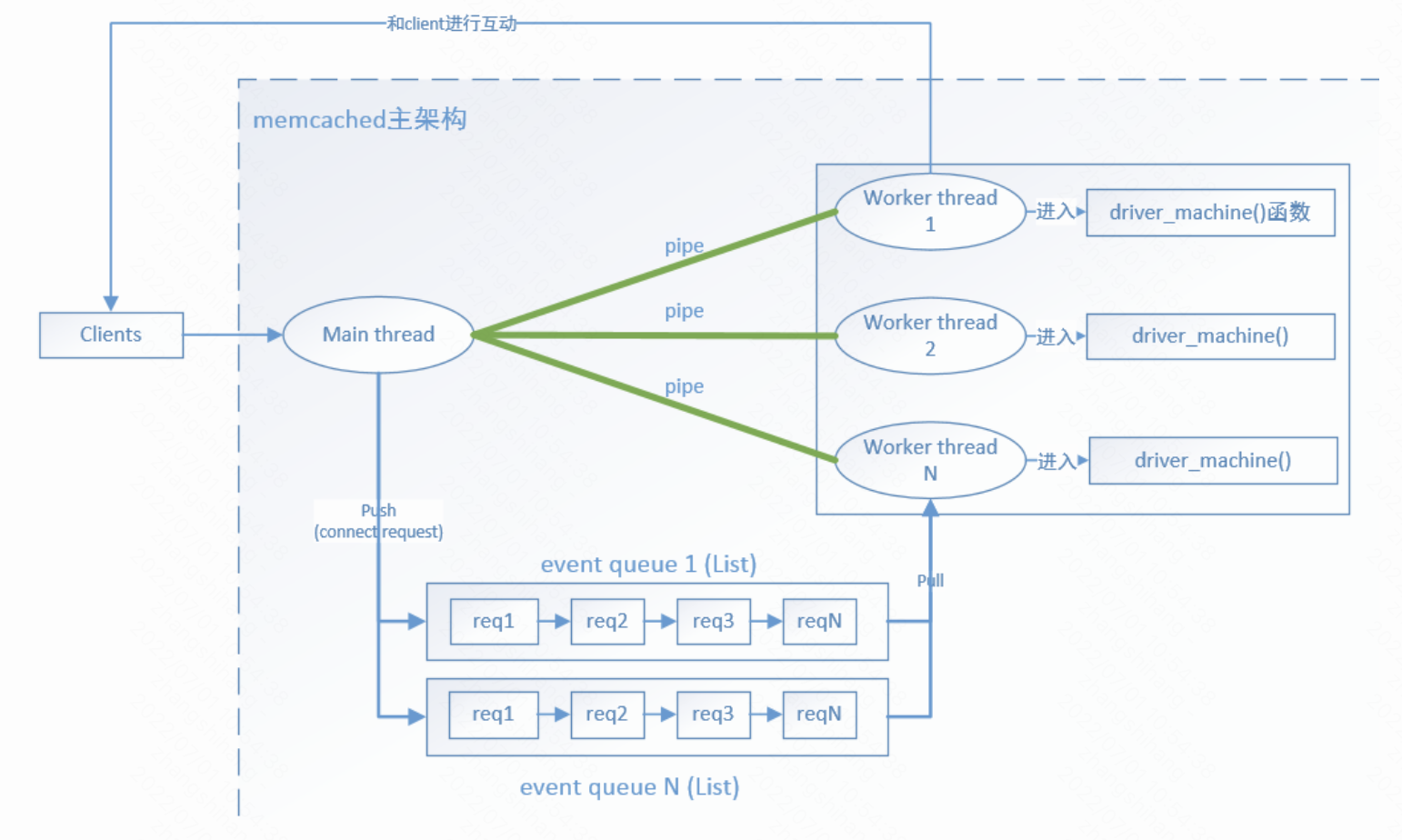
- 主线程(main thread)会和每个worker线程都建立一个管道(pipe)
- 当client连接memcached时,会先把连接请求发送给主线程,并和主线程完成连接的建立,让后主线程会选择一个管道,也就是选择了一个worker thread发送一个字符: ‘c’,并把创建一个新的连接实体放到连接队列中,
- 此时阻塞在管道读区端的worker线程被唤醒,worker线程从连接队列中取出连接实体,并对完成连接的socket注册读事件处理函数,最后进入命令处理流程来处理client端的发送命令和各种连接异常的事件。
主线程
- 在memcached中主线程负责监听client端的连接请求,接收并创建和client的tcp连接。
- 并选择一个worker线程来处理该client端的后续请求。
主线程初始化
- 初始化时memcached的主线程主要完成以下几项工作:
- 创建N个worker线程,并和每个线程创建一个双向管道(pipe)
- 为每个woker线程创建保存conn_queue_item对象的队列:new_conn_queue
- 为管道的读端fd(代码中的变量是:notify_receive_fd),注册读事件处理函数:thread_libevent_process
- 创建conn实体,并初始化状态为conn_listening
- 创建绑定(bind)的socket:sfd,并为该socket注册读事件处理函数:event_handler
worker线程
- worker线程负责处理client端发送的命令,连接超时等。
worker线程初始化
- worker线程的初始化完成的工作如下:
- 为管道的读fd:notify_receive_fd,注册读事件监听函数thread_libevent_process 该函数会阻塞在管道的notify_receive_fd描述符上进行读取。
事件处理
处理流程概要
- 处理客户端创建连接请求的处理流程如下:
- 主线程和客户端完成tcp连接的建立
- 主线程创建conn对象,并把该对象放到连接队列中
- 主线程向worker线程的管道中发送字符:’c’
- worker线程从管道中读取命令’c’,并从连接队列中取出一个conn实体
- worker线程创建一个新的conn实体,并把最新的sfd(已完成tcp连接的socket)读事件注册到event_handler
- event_handler会调用drive_machine处理客户端的各种命令和事件
详细说明
-
当客户端向memcached发送连接请求时会触发sfd的读事件处理函数event_handler的执行。
-
该函数会调用drive_machine函数,在该函数中完成与client端的tcp连接建立。
-
当主线程接收到客户端的连接请求时,会选择一个worker线程的管道,选择哪一个worker线程呢,规则如下:
int tid = (last_thread + 1) % settings.num_threads;
-
其实是按轮训的方式来选择worker线程。这样可以保证每个worker线程服务的client的数量基本相同。
-
通过以上方式,选择好一个线程的管道后,创建一个conn_queue_item对象,并把该对象放到连接队列new_conn_queue中,然后向该管道发送’c’字符,该字符表示客户端要创建连接了。
-
此时会触发worker线程的管道读事件处理函数thread_libevent_process的执行,当worker线程的从管道中接收到该字符时,会从事件队列中取出conn_queue_item对象,根据该实体的信息创建一个新的conn实体,并为已经完成连接的socket描述,注册event_handler读事件处理函数。
-
此时已经由worker线程接管了client的连接,后续的客户端发送的命令都会由event_handler事件处理函数进行处理。
-
event_handler函数会最终调用driver_machine()函数来处理客户端所有的请求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号