User-Agent和Cookie反爬虫以及如何绕过
一、前言
今天是1024程序员节,大家节日快乐。听说今天发博客会得一枚1024勋章,一年一次呢,真是稀有。写篇博客顺便把这几天学习的相关知识总结一下。
二、为什么要学习反爬虫
从暑假算起到现在,我也接触了4个月的爬虫,期间做过不少测试和实战,越往后学,越是难学。倒不是难在设计爬虫,编写Python代码上,而是大部分时间都花在了绕过上,费尽心思绕过网站的反爬措施。从最开始伪造User-Agent和Cookies,到后来的提交Post请求破解登录,再到后来的逆向破解JavaScript加密算法。这部分所花费的时间已经超过了写爬虫的时间。这对没有前端基础的我来说,绕过过程真是让我苦不堪言。
所以我决定有必要系统的学习绕过和JavaScript逆向分析,从原理上弄清楚网站是怎么实现反爬虫的,针对这样的方法改怎么绕过等。
今天我总结的是User-Agent和Cookie反爬虫。初级爬虫都知道User-Agent是客户端标识,不同浏览器有不同的User-Agent,Cookie是保存在客户端用于记录客户端身份的一种措施,同时Web工程师还可以利用它们实现网站的反爬虫。我还是初学者的时候已经了解了这些东西,但完全不知道它们是如何实现的。经过最近几天的学习,我已经了解了,大概有nginx和JavaScript两种方式。
三、User-Agent反爬虫
反爬
在nginx配置文件下的conf.d目录下创建一个conf文件,也可以修改default.conf
server {
listen 83;
server_name localhost;
charset utf-8;
location /verify/uas/ {
if ($http_user_agent ~* (python)) {
return 403;
}
root /home/pineapple/Code/WebProject/www;
index index.html;
}
}
改完之后别忘记重载一下配置
pineapple@Mars:~$ sudo nginx -s reload
/verify/uas/index.html里只写一个标签
<h1>This is uas/index.html</h1>
利用正则表达式匹配,如果请求头中的User-Agent带有python,则返回状态码403。
写个python代码测试一下,设置代理端口为8888,方便Charles抓到请求
'''
@Date : 2020-10-24 09:05:48
@LastEditors : Pineapple
@LastEditTime : 2020-10-24 09:42:28
@FilePath : /www/spider.py
@Blog : https://blog.csdn.net/pineapple_C
@Github : https://github.com/Pineapple666
'''
import requests
from pyquery.pyquery import PyQuery as pq
proxies = {
"http": "http://127.0.0.1:8888",
"https": "https: // 127.0.0.1: 8888",
}
url = 'http://localhost:83/verify/uas/'
response = requests.get(url=url, proxies=proxies)
doc = pq(response.text)
print(doc('h1'))
输出结果为:<h1>403 Forbidden</h1>
抓包结果如下:
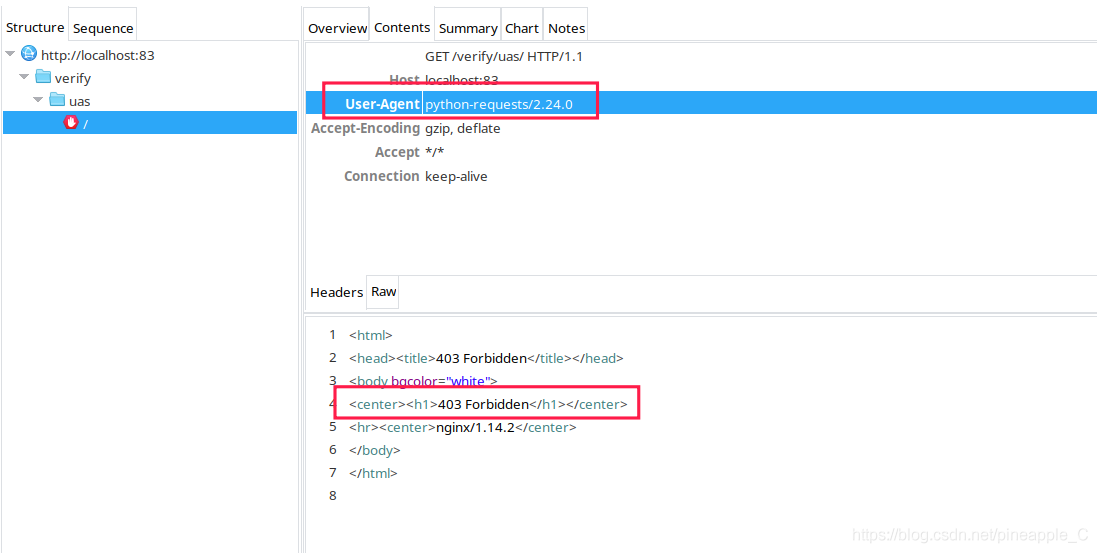
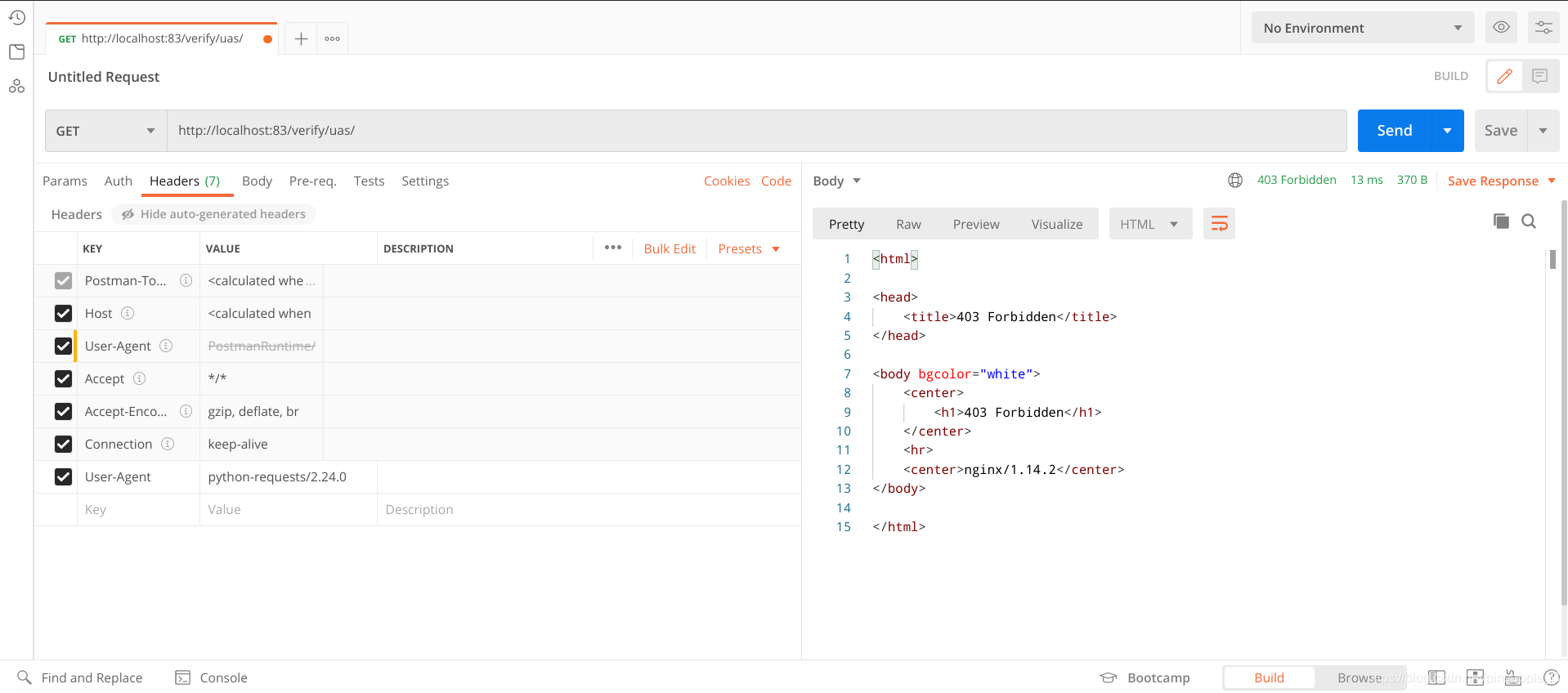
已知python的UA是python-requests/2.24.0,Postman测试如下:
绕过
这就是User-Agent反爬的简单实现,想要绕过也很简单,学爬虫的都知道,伪造个浏览器的UA就行了。
四、Cookie反爬虫
假设访问网站/verify/cookie/content.html必须携带一个符合规定的cookie,如果cookie不符合规定,则会被重定向到/verify/cookie/index.html去设置一个cookie,有了cookie后才能继续访问content.html。这种方法很常见,就好比淘宝,在访问其商品列表页面前,必须登录且信息无误后才能继续访问,这种方法不仅能增加用户数,还能实现反爬,真是一举两得!
反爬
我起初猜测它可能是这样实现的:在content.html加入一段JavaScript代码,使其能获取请求头中的cookie并判断是否符合规定,如果不符合则重定向到index.html,然后在index.html内插入一些JavaScript算法来生成cookie。
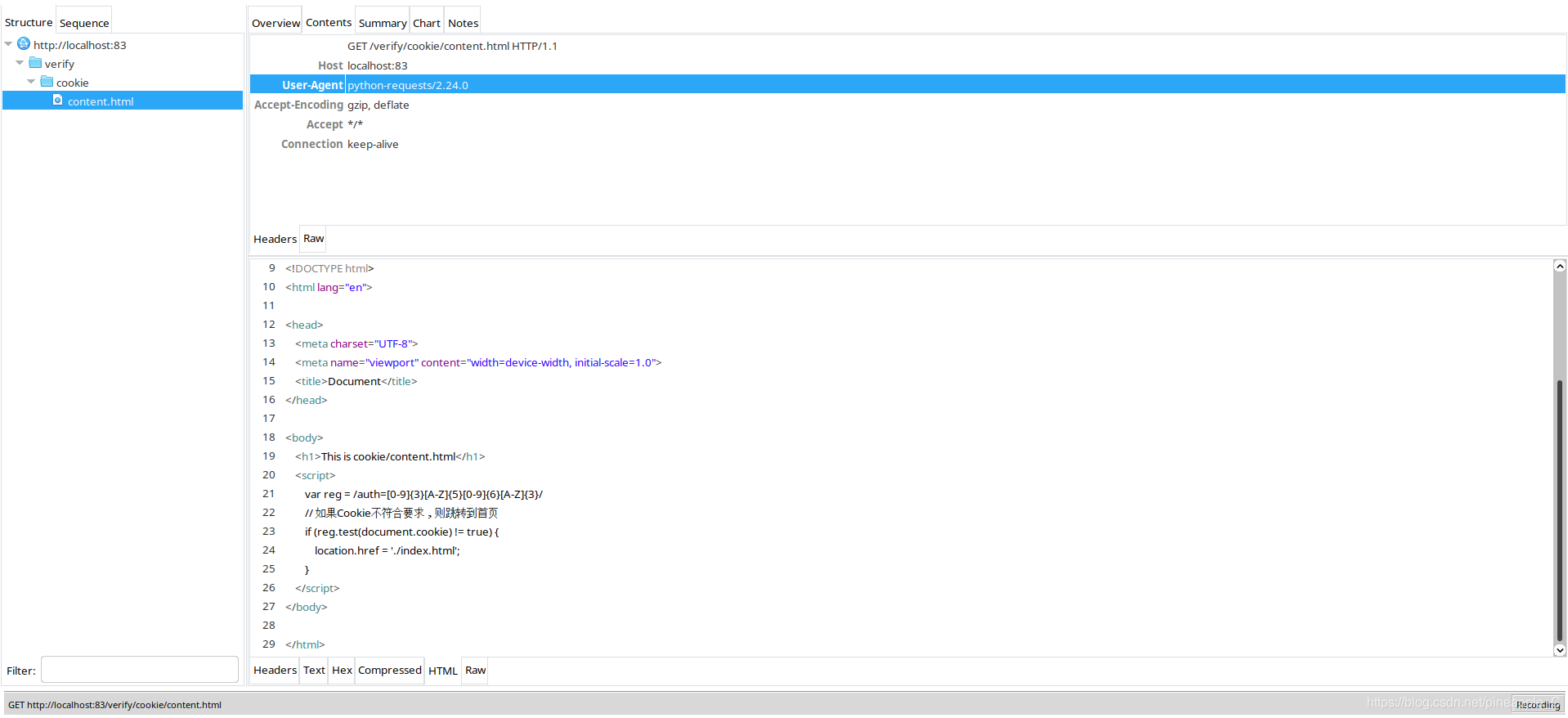
编辑content.html:
<body>
<h1>This is cookie/content.html</h1>
<script>
var reg = /auth=[0-9]{3}[A-Z]{5}[0-9]{6}[A-Z]{3}/
// 如果Cookie不符合要求,则跳转到首页
if (reg.test(document.cookie) != true) {
location.href = './index.html';
}
</script>
</body>
变量reg是一个正则表达式,它可以匹配auth= + 3位小于9的随机整数 + 5位随机大写字母 + 6位小于9的随机整数 + 3位随机大写字母
用浏览器测试了一下,确实可以实现重定向的操作,但是还是会先访问content.html。这种做法只能起到增长用户的目的,并不能实现反爬虫,因为python是没有JavaScript解释器的,它不会解析js代码,对于这种页面还是照爬无误。
所以还是得靠nginx,继续修改一下配置
location /verify/cookie/index.html {
root /home/pineapple/Code/WebProject/www;
index index.html;
}
location /verify/cookie/content.html {
if ($http_cookie !~* "auth=[0-9]{3}[A-Z]{5}[0-9]{6}[A-Z]{3}") {
rewrite content.html ./index.html redirect;
}
root /home/pineapple/Code/WebProject/www;
index content.html;
}
通过这样的方法,把重定向的工作放到服务器端,而不是客户端,这样在客户端就不会先看到content.html再重定向到index.html,而是直接执行重定向
为了在重定向后给客户端设置cookie,需要在index.html里加入JavaScript代码
<!--
* @Date : 2020-10-22 22:38:37
* @LastEditors : Pineapple
* @LastEditTime : 2020-10-23 17:30:20
* @FilePath : /www/verify/cookie/index.html
* @Blog : https://blog.csdn.net/pineapple_C
* @Github : https://github.com/Pineapple666
-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>This is cookie/index.html</h1>
<h1><a href="./content.html">Go to cookie/content.html</a></h1>
<script id="random cookie">
function randcookie() {
// 生成随机字符串用作cookie值
var header = randints(9, 3, 0);
var middle = randstrs(5);
var footer = randints(9, 6, 0);
var pp = randstrs(3);
var res = header + middle + footer + pp
return res;
}
function randints(r, n, tof) {
/* 生成随机数字,tof决定返回number类型或者字符串类型
r 代表数字范围 n 代表数量
*/
var result = [];
if (tof) {
return Math.floor(Math.random() * r);
}
for (var i = 0; i < n; i++) {
s = Math.floor(Math.random() * r);
result.push(s);
}
return result.join('');
}
function randstrs(n) {
// 生成随机字母,n为随机字母的数量
var result = [];
for (var i = 0; i < n; i++) {
s = String.fromCharCode(65 + randints(25, 1, 1));
result.push(s);
}
return result.join('');
}
// 设置Cookie
document.cookie = 'auth=' + randcookie();
</script>
</body>
</html>
接下来进行测试
打开Chrome浏览器,选择Preserver log持续记录,访问http://localhost:83/verify/cookie/content.html
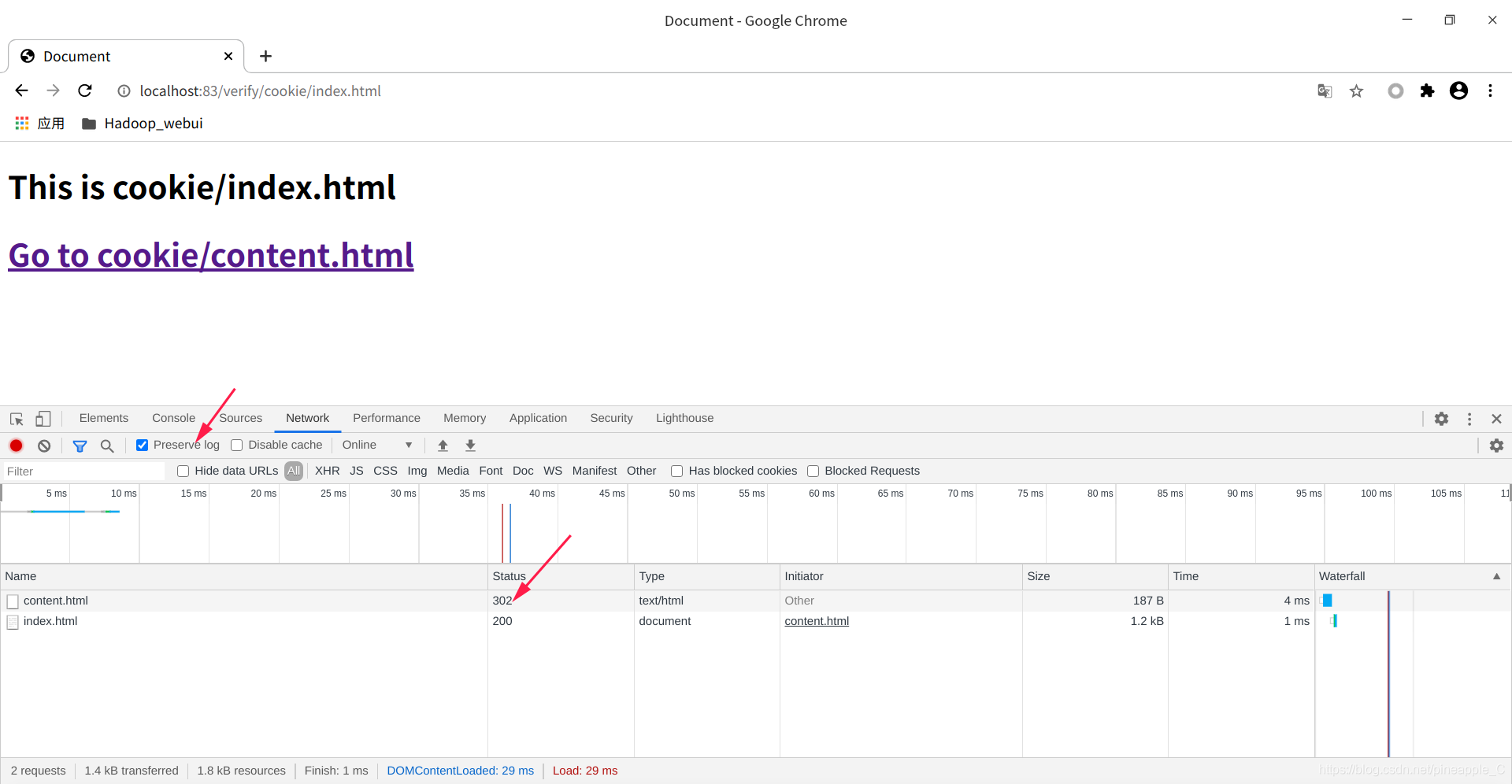
可以看到content.html的状态码是302,意思就是重定向。既然成功的重定向了,访问了index.html页面,那么cookie也应该设置好了,接下来再访问一次content.html,或者直接点击页面链接。
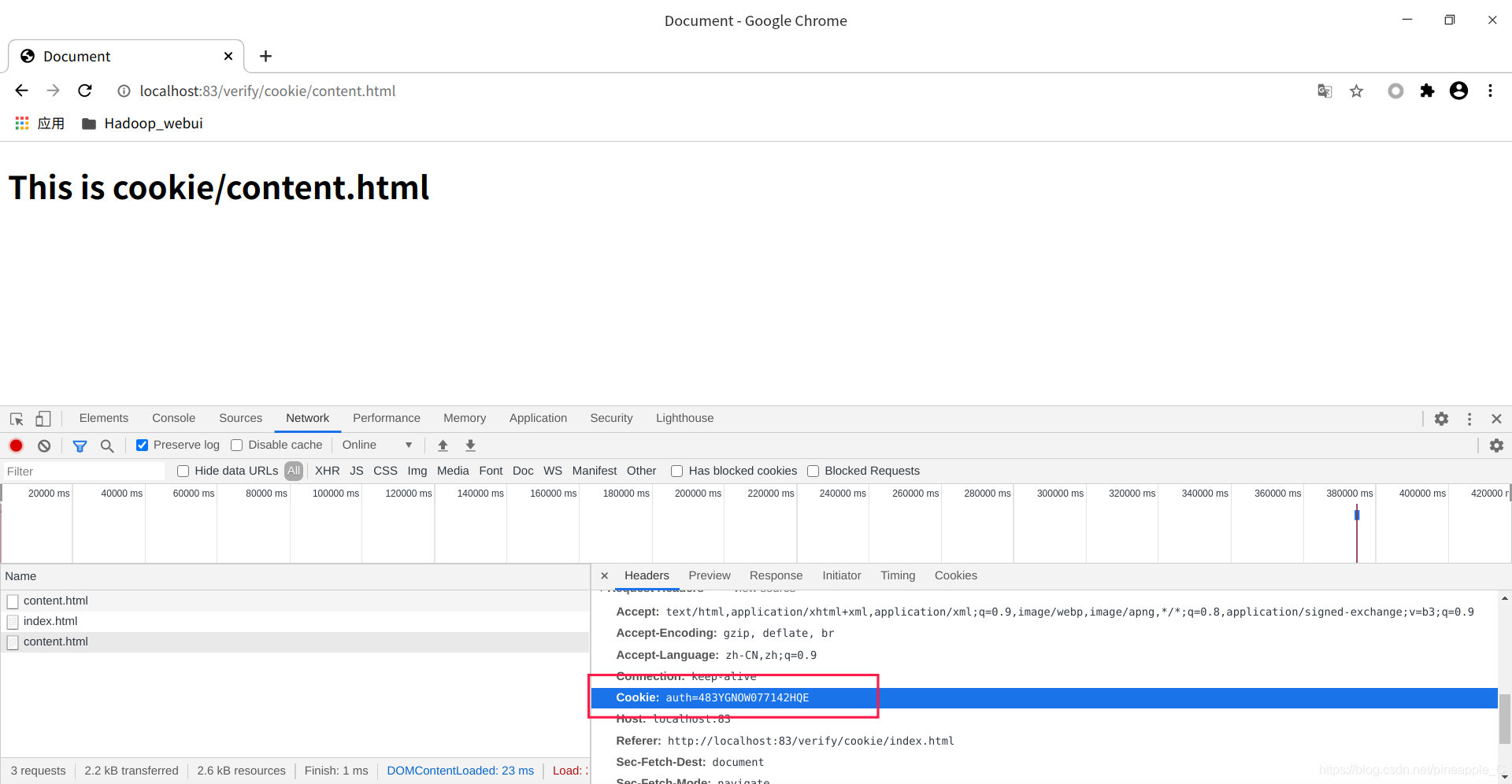 测试成功!
测试成功!
那么怎么编写爬虫进行绕过呢?
绕过
这个绕过也比较简单,分析一下JavaScript代码,很快就能找到cookie的规律,自己编一个cookie或者直接复制一个就完事了
'''
@Date : 2020-10-24 09:05:48
@LastEditors : Pineapple
@LastEditTime : 2020-10-24 11:13:04
@FilePath : /www/spider.py
@Blog : https://blog.csdn.net/pineapple_C
@Github : https://github.com/Pineapple666
'''
import requests
from pyquery.pyquery import PyQuery as pq
proxies = {
"http": "http://127.0.0.1:8888",
"https": "https: // 127.0.0.1:8888",
}
url = 'http://localhost:83/verify/cookie/content.html'
headers = {
"cookie": "auth=483YGNOW077142HQE"
}
response = requests.get(url=url, proxies=proxies, headers=headers)
doc = pq(response.text)
print(doc('h1'))
Charles抓包,绕过成功。

五、结语
因为用作测试的JavaScript算法比较简单,分析一下或者前后对比一下就能找到规律。可是如果加上时间戳的计算就不那么好办了,得用python重写相关JavaScript算法,获取时间戳。
推荐大家看一本书:《Python3反爬虫原理与绕过实战》,讲的很好,弥补了我在Web方面的不足,非常适合Web工程师和爬虫工程师看。
具体的重写相关JavaScript算法,获取时间戳的方法我也是边看书边总结的,下一篇再详细介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号