

Python 异步编程,挑战单线程的极限,爬取LOL皮肤(1385次get请求和图片下载,用时29.4s)
承接上一篇博客,直接上代码,解析请看上篇。----<<<<传送门
完整代码
# -*- coding: utf-8 -*-
"""
@author :Pineapple
@Blog :https://blog.csdn.net/pineapple_C
@contact :cppjavapython@foxmail.com
@time :2020/8/13 13:33
@file :lol.py
@desc :fetch lol hero's skins
"""
from aiohttp.client_exceptions import ClientConnectionError
from time import perf_counter
from loguru import logger
import requests
import asyncio
import aiohttp
import os
start = perf_counter()
# global variable
ROOT_DIR = os.path.dirname(__file__)
IMG_DIR = f'{ROOT_DIR}/image'
if not os.path.exists(IMG_DIR):
os.mkdir(IMG_DIR)
RIGHT = 0 # counts of right image
ERROR = 0 # counts of error image
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
# target url
hero_url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
# skin's url, will completed with hero's id.
base_url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/'
loop = asyncio.get_event_loop()
tasks = []
def get_hero_id(url):
"""
get hero's id, to complete base_url.
:param url: target url
:return: hero's id
"""
response = requests.get(url=url, headers=headers)
info = response.json()
items = info.get('hero')
for item in items:
yield item.get('heroId')
async def fetch_hero_url(url):
"""
fetch hero url, to get skin's info
:param url: hero url
:return: None
"""
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False)) as session:
async with session.get(url=url, headers=headers) as response:
if response.status == 200:
response = await response.json(content_type='application/x-javascript')
# skin's list
skins = response.get('skins')
for skin in skins:
info = {}
info['hero_name'] = skin.get('heroName') + '_' + skin.get('heroTitle')
info['skin_name'] = skin.get('name')
info['skin_url'] = skin.get('mainImg')
await fetch_skin_url(info, session)
async def fetch_skin_url(info, session):
"""
fetch image, save it to jpg.
:param info: skin's info
:param session: session
:return: None
"""
global RIGHT, ERROR
path = f'{IMG_DIR}/{info["hero_name"]}'
make_dir(path)
name = info['skin_name']
url = info['skin_url']
if name.count('/'):
name.replace('/', '//')
elif url == '':
ERROR += 1
else:
try:
async with session.get(url=url, headers=headers) as response:
if response.status == 200:
RIGHT += 1
with open(f'{path}/{name}.jpg', 'wb') as file:
chunk = await response.content.read()
logger.success(f'Downloading {name}...')
file.write(chunk)
else:
ERROR += 1
logger.error(f'{name},{url} status error')
except (OSError, ClientConnectionError) as e:
logger.error(f'{info} except error {e.args}')
def make_dir(path):
"""
make dir with hero's name
:param path: path
:return: None
"""
if not os.path.exists(path):
os.mkdir(path)
if __name__ == '__main__':
for hero_id in get_hero_id(hero_url):
url = base_url + str(hero_id) + '.js'
tasks.append(fetch_hero_url(url))
loop.run_until_complete(asyncio.wait(tasks))
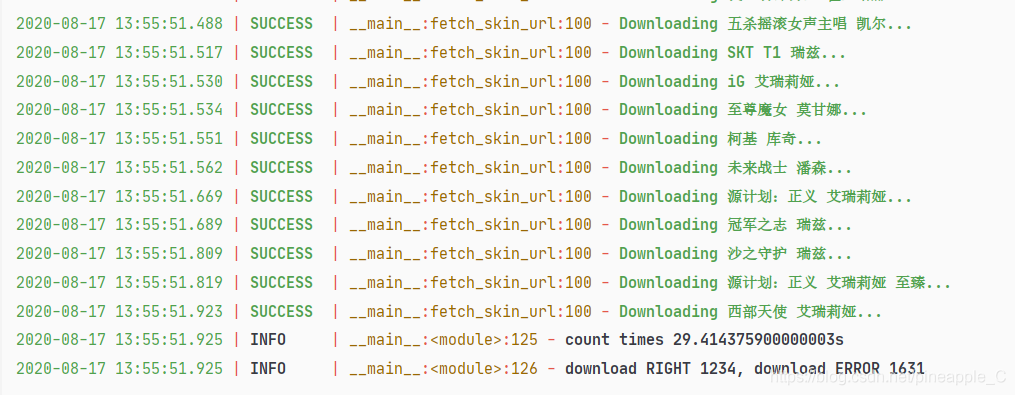
logger.info(f'count times {perf_counter() - start}s')
logger.info(f'download RIGHT {RIGHT}, download ERROR {ERROR}')
改动说明
1、事先判断./image目录是否存在
2、之前的url都是http协议,主要是避免SSL验证问题,现在在session里设置了SSL为False。
3、fetch_skin_url()函数接收一个session,由一张图片一个session变为一个英雄一个session,避免来回切换session的消耗。
4、去掉不必要的信息提示。
5、except (OSError, ClientConnectionError)捕捉信号灯超时等未知异常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号