

数据采集第二次作业
一、在中国气象网爬取指定城市的 7 日天气预报并入库数据库
1. 作业实现过程与展示
本实验采用 requests + BeautifulSoup 进行页面解析,提取天气预报数据,并存入 SQLite 数据库。
数据库设计
| 字段 | 说明 |
|---|---|
| id | 主键,自增 |
| city | 城市名称 |
| date | 日期 |
| weather | 天气描述 |
| temperature | 温度范围 |
核心代码示例(weather_crawler.py)
import requests
import sqlite3
from bs4 import BeautifulSoup
def create_database():
conn = sqlite3.connect('weather_forecast.db')
conn.execute('''
CREATE TABLE IF NOT EXISTS weather_forecast (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city TEXT,
date TEXT,
weather TEXT,
temperature TEXT
)
''')
return conn
def get_weather_data(city_code):
url = f'http://www.weather.com.cn/weather/{city_code}.shtml'
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
forecast_items = soup.select('ul.t.clearfix > li')
weather_data = []
for item in forecast_items:
date = item.find('h1').get_text(strip=True)
weather = item.find('p', class_='wea').get_text(strip=True)
high = item.find('span').get_text(strip=True) if item.find('span') else ''
low = item.find('i').get_text(strip=True)
temperature = f"{high}/{low}"
weather_data.append((date, weather, temperature))
return weather_data
def save_to_db(conn, city, weather_data):
conn.executemany(
"INSERT INTO weather_forecast (city, date, weather, temperature) VALUES (?, ?, ?, ?)",
[(city, *w) for w in weather_data]
)
conn.commit()
源代码仓库
🔗 https://gitee.com/jadevoice/data-collection-tas/blob/main/weather_crawler.py


二、定向爬取股票信息并入库数据库
1. 作业实现展示
使用 requests 抓取股票信息页面,提取股票代码、名称、当前价格等内容存入数据库。
def fetch_stock_data(cmd: str, page: int = 1, page_size: int = 50) -> List[dict]:
""" 拉取单页股票数据 """
url = (
"https://push2.eastmoney.com/api/qt/clist/get?"
f"pn={page}&pz={page_size}&po=1&np=1&fltt=2&invt=2&fid=f3"
f"&fs=b:MK0021&fields=f12,f14,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f18,f15,f16,f17,f23"
f"&cmd={cmd}"
)
headers = {
"User-Agent": "Mozilla/5.0"
}
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
data = json.loads(resp.text)
if data.get("data") and data["data"].get("diff"):
return data["data"]["diff"]
return []
def save_to_database(stock_list: List[dict], conn):
""" 保存数据进数据库,避免重复 """
cursor = conn.cursor()
for stock in stock_list:
cursor.execute('''
INSERT OR REPLACE INTO stock_info
(stock_code, stock_name, latest_price, change_percent, change_amount, volume, turnover, amplitude, high, low, open_price, yesterday_close)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
stock.get("f12"), stock.get("f14"), stock.get("f2"), stock.get("f3"),
stock.get("f4"), stock.get("f5"), stock.get("f6"), stock.get("f7"),
stock.get("f15"), stock.get("f16"), stock.get("f17"), stock.get("f18")
))
conn.commit()
源代码仓库
🔗 https://gitee.com/jadevoice/data-collection-tas/blob/main/eastmoney_crawler.py


2. 实验心得
本任务加强了我对网页结构分析和选择器定位的理解,尤其是表格类页面数据提取,同时熟悉了批量入库操作。
使用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
三、爬取中国大学排名信息(2021 主榜),并分析数据加载方式
1. 作业展示与关键分析
在分析网站的数据结构和请求方式后,发现无法像普通分页网页那样简单地循环请求分页数据,原因主要是:
数据是通过前端 JS 动态生成的
- 网站使用 Nuxt.js(或类似 SPA 框架)渲染页面内容。
- 页面里的数据(大学排名、详细信息等)并不是直接在 HTML 里,而是存储在一个 JS 对象里,例如:
__NUXT_JSONP__("/rankings/bcur/2020", function(...) { return { data: [...], fetch: {...} }})

- 也就是说 每页的数据都在 JS 文件里预加载,浏览器解析 JS 后才渲染到页面。
- 对于爬虫而言,直接请求 HTML 无法获取 JS 渲染后的内容。
因此要爬取到全部大学排名信息无法使用urllib.request和BeautifulSoup这种传统做法
网络抓包分析后发现有一个payload.js文件拥有全部的数据
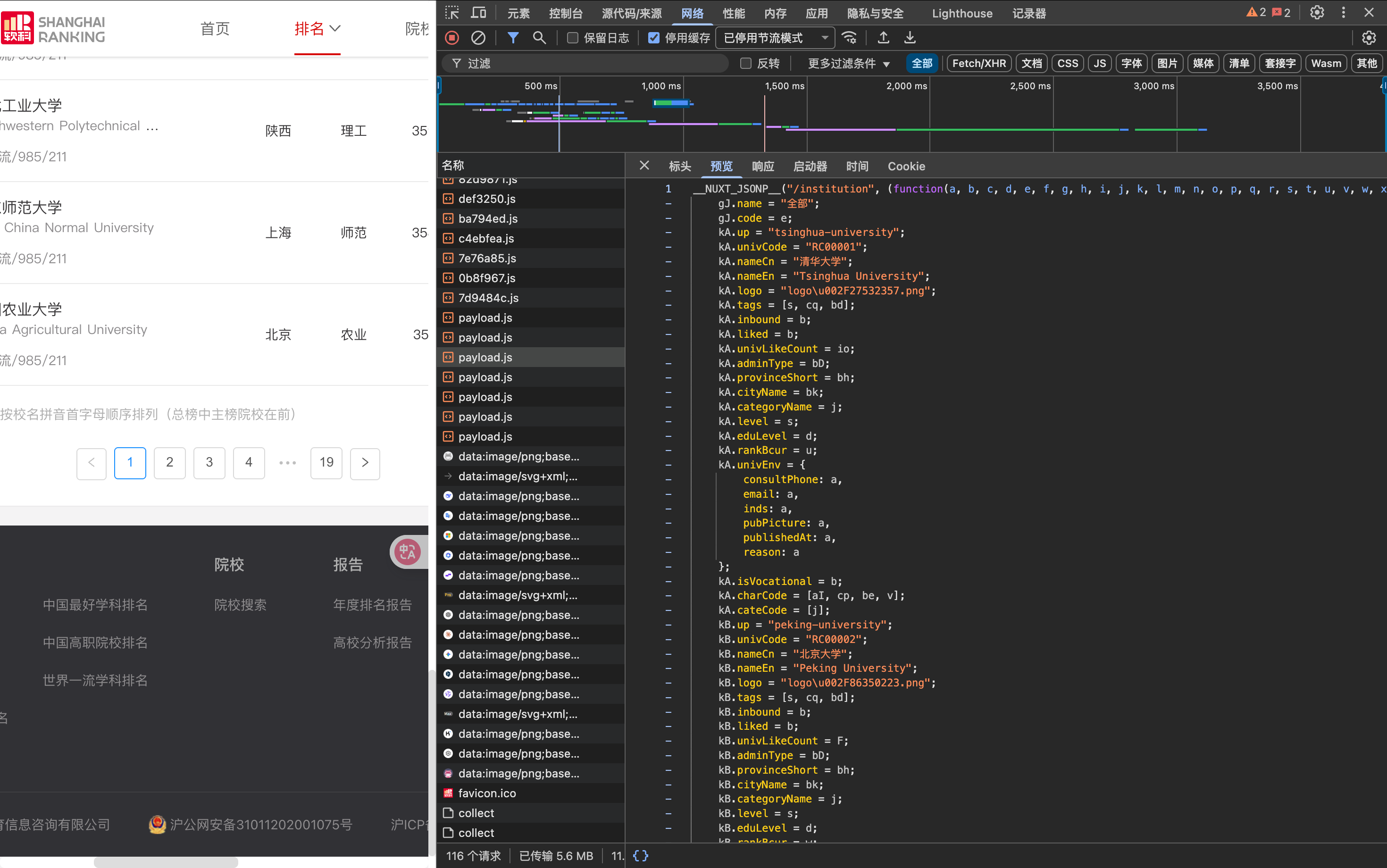
使用console查看
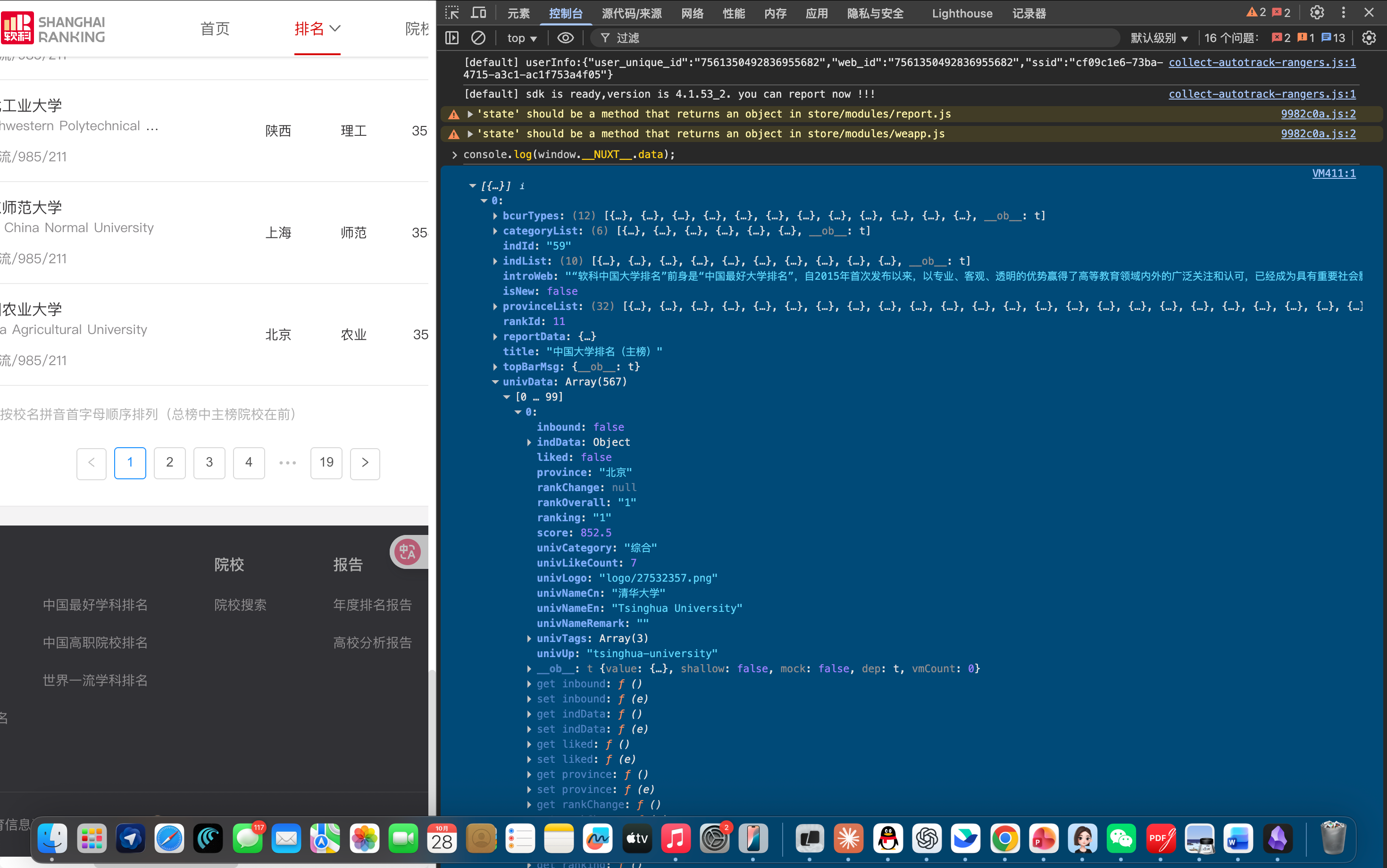
可以使用这一个console命令下载到数据
源代码仓库
🔗 https://gitee.com/jadevoice/data-collection-tas/blob/main/rank.py


2. 实验心得
本次任务让我理解到:
• 现代网页大量使用前端框架渲染
• 爬虫必须分析:数据是否 AJAX/JS 动态生成
• 可通过抓包、Vue/Nuxt/React 结构解析定位数据源
• 必要时使用浏览器自动化工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号