
(一)
选题背景:此数据分析能根据视频播放量、评论数、弹幕数等清晰观察到观众的喜好,还有视频博主喜欢做的视频主题,分析一段时期的网络热度、关注点在哪。(其实一开始只是想爬喜欢的UP的数据)
预期目标:通过程序得到一些视频的相关数据,并能直观看出数据的大小、随时间变化这些数据的起伏,以及它们之间的关系。
(二)
主题式网络爬虫名称:B站视频弹幕爬虫
主题式网络爬虫爬取的内容与数据特征分析:
视频有title标题,aid,bvid,comment-评论数,created_time-发布时间,length-视频长度,play-播放量,cid,弹幕就只有cid,和content-内容
主要是分析博主视频播放量和时长有没有关系,播放量和评论数有没有关系,博主一般怎样命名自己的视频主题。
设计思路:
采集的逻辑是从视频页将每个视频的信息和地址采集下来,再请求地址采集视频的弹幕。进入视频页,https://space.bilibili.com/11684516/video

查看源码并没有视频的信息,所以可能是用异步加载的方式加载数据的,那么用谷歌浏览器的检查模式,很容易发现视频的数据都在下面那个请求的响应体中,返回的是json数据。


视频的信息都在里面了,所以可以直接请求这个接口就可以获取到信息了,而该接口的请求参数也比较容易分析。
mid是up主的id,ps返回的视频数量,tid在后面的请求都不变,所以可以直接赋为0,pn是页数,后面的参数也直接复制即可。
下面就是爬取弹幕了,弹幕的话本人并没有在检查模式里面找到,然后通过百度,弹幕数据都在这一个接口中。很明显cid就是用于标识视频的,那么获取到cid就可以了。后来我才发现,这里最多只能获取1000条弹幕。
http://comment.bilibili.com/{cid}.xml
然后在视频信息里面并没有cid的信息,所以先从从视频播放页里面找。可以看到下面这一个接口返回的数据就有cid。
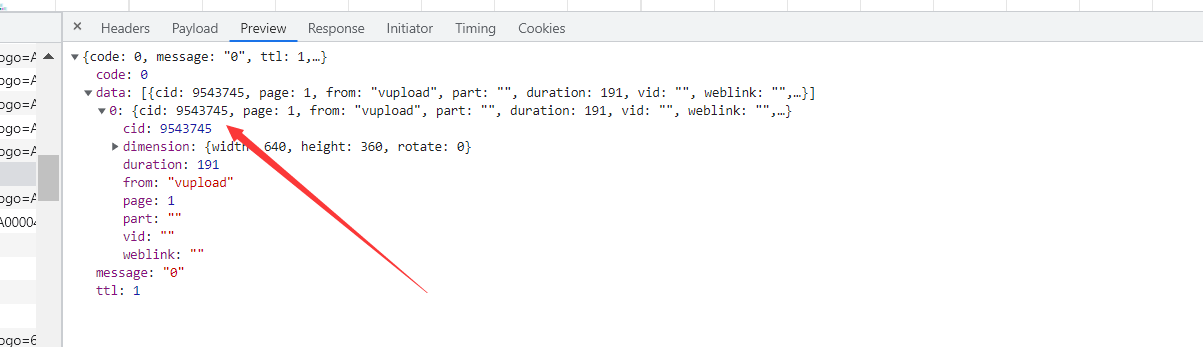
然后看该接口的请求参数,只需要bvid就可以了,而bvid在视频信息里面就可以提取到,那么分析到此结束了,开始爬虫。
这里我使用scrapy框架,首先编写items,主要分为两个视频的和弹幕的,视频有title标题,aid,bvid,comment-评论数,created_time-发布时间,length-视频长度,play-播放量,cid。
技术难点:因为该爬虫数据是异步获取的,所以寻找数据接口比较麻烦,因为b站异步接口众多,想找到所需接口还是挺麻烦的,构思整个scrapy框架我也花了不少时间。
(三)页面结构与特征分析
由于该网站采用前后端分离架构,页面数据是异步获取,因此没有对页面结构去分析,而是对数据接口返回数据分析。
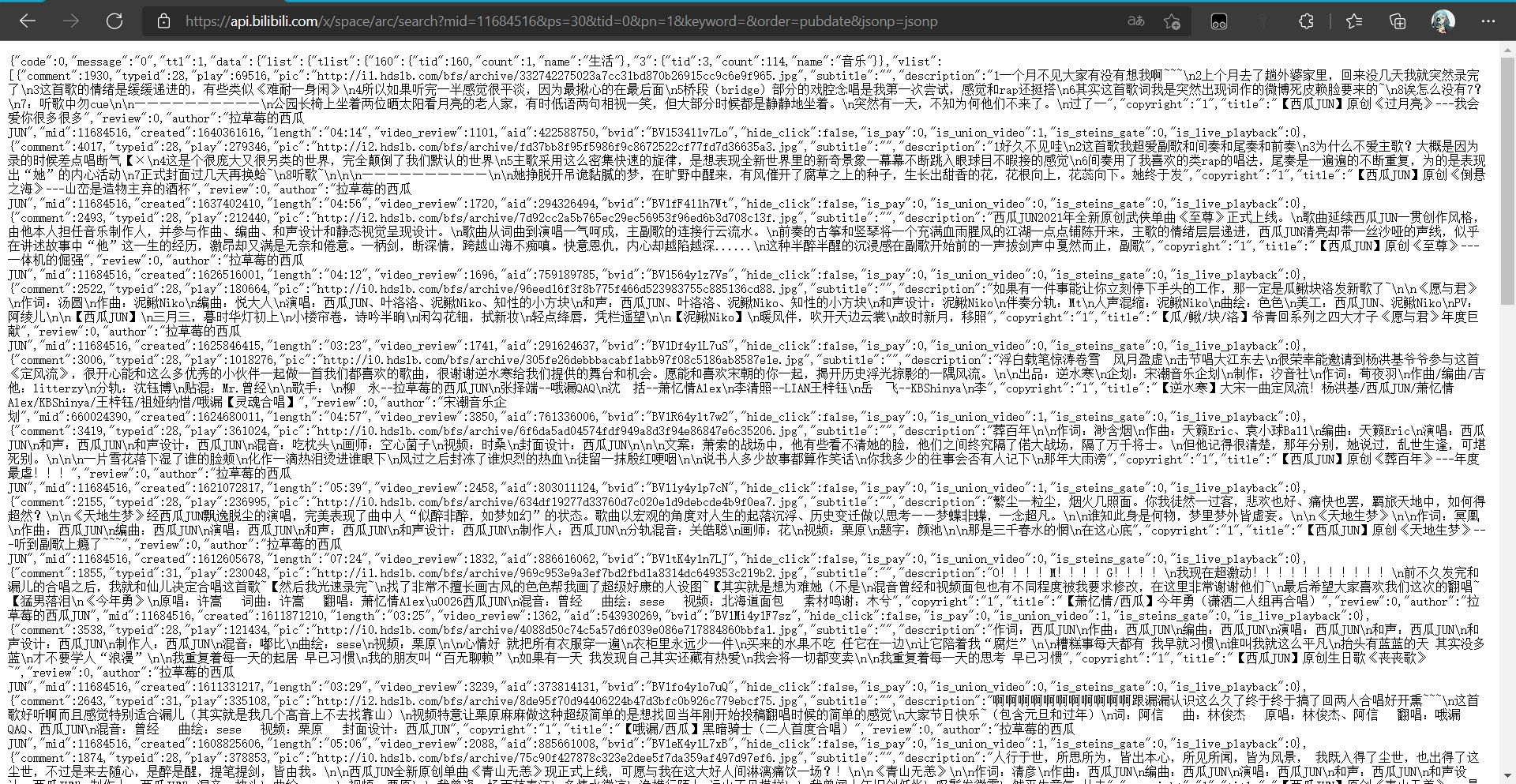
对应的数据为json格式,所以可以直接利用json库提取数据,而不要bs4,正则等解析库。
(四)爬虫程序设计
1.数据爬取与采集(scrapy+json)核心代码
Items文件
1 import scrapy 2 class BilibiliErniuItem(scrapy.Item): 3 title = scrapy.Field() 4 aid = scrapy.Field() 5 bvid = scrapy.Field() 6 comment = scrapy.Field() 7 created_time = scrapy.Field() 8 length = scrapy.Field() 9 play = scrapy.Field() 10 cid = scrapy.Field() 11 12 class ErniuBulletChatItem(scrapy.Item): 13 cid = scrapy.Field() 14 content = scrapy.Field()
crawl_spider文件
1 import json 2 3 import scrapy 4 5 from my_crawler.items import BilibiliErniuItem, ErniuBulletChatItem 6 class MaoyanSpider(scrapy.Spider): 7 name="my_crawler" 8 def start_requests(self): 9 base_url = 'https://api.bilibili.com/x/space/arc/search?mid=11684516&ps=30&tid=0&pn={}&keyword=&order=pubdate&jsonp=jsonp' 10 headers = self.settings.get('DEFAULT_REQUEST_HEADERS') 11 for pn in range(1, 10): 12 url = base_url.format(pn) 13 yield scrapy.Request(url=url, headers=headers, callback=self.parse_video_info) 14 15 16 def parse_video_info(self, response): 17 detail = json.loads(response.text) 18 headers = self.settings.get('DEFAULT_REQUEST_HEADERS') 19 for info in detail.get('data').get('list').get('vlist'): 20 item = BilibiliErniuItem() 21 item['title'] = info.get('title') 22 item['aid'] = info.get('aid') 23 item['bvid'] = info.get('bvid') 24 item['comment'] = info.get('comment') 25 item['created_time'] = info.get('created') 26 item['length'] = info.get('length') 27 item['play'] = info.get('play') 28 cid_url = 'https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp'.format(item['bvid']) 29 yield scrapy.Request(url=cid_url, headers=headers, meta={'item': item}, callback=self.get_bullet_chat_url) 30 31 32 def get_bullet_chat_url(self, response): 33 detail = json.loads(response.text) 34 headers = self.settings.get('DEFAULT_REQUEST_HEADERS') 35 item = response.meta['item'] 36 cid = detail.get('data')[0].get('cid') 37 item['cid'] = cid 38 bullet_chat_url = 'http://comment.bilibili.com/{}.xml'.format(cid) 39 yield scrapy.Request(url=bullet_chat_url, headers=headers, meta={'cid': cid}, callback=self.parse_bullet_chat) 40 yield item 41 42 43 def parse_bullet_chat(self, response): 44 sel = scrapy.Selector(response) 45 item = ErniuBulletChatItem() 46 item['cid'] = response.meta['cid'] 47 item['content'] = sel.xpath('//d//text()').extract() 48 yield item
pipline文件
1 import os 2 3 from my_crawler.items import BilibiliErniuItem 4 5 6 class MyCrawlerPipeline(object): 7 def __init__(self): 8 self.dirs = 'E:\\video.csv' 9 if not os.path.exists(self.dirs): 10 with open(self.dirs, 'w', encoding='utf-8')as fp: 11 fp.write('title|aid|bvid|comment|created_time|length|play|cid\n') 12 self.buttet_chat_dir = 'E:\\buttet_chat' 13 if not os.path.exists(self.buttet_chat_dir): 14 os.makedirs(self.buttet_chat_dir) 15 16 def process_item(self, item, spider): 17 if isinstance(item, BilibiliErniuItem): 18 with open(self.dirs, 'a', encoding='utf-8') as fp: 19 fp.write(item['title'] + '|' + str(item['aid']) + '|' + item['bvid'] + '|' + str( 20 item['comment']) + '|' + str(item['created_time']) + '|' + item['length'] + '|' + str( 21 item['play']) + '|' + str(item['cid']) + '\n') 22 return item 23 else: 24 filename = str(item['cid']) + '.csv' 25 if not os.path.exists(self.buttet_chat_dir + '\\' + filename): 26 with open(self.buttet_chat_dir + '\\' + filename, 'w', encoding='utf-8')as fp: 27 fp.write('content' + '\n') 28 for content in item['content']: 29 fp.write(content + '\n') 30 return item
setting配置文件
1 DEFAULT_REQUEST_HEADERS = { 2 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 3 'Accept-Language': 'en', 4 } 5 ITEM_PIPELINES = { 6 'my_crawler.pipelines.MyCrawlerPipeline': 300, 7 } 8 LOG_LEVEL = 'WARNING' 9 BOT_NAME = 'my_crawler' 10 11 SPIDER_MODULES = ['my_crawler.spiders'] 12 NEWSPIDER_MODULE = 'my_crawler.spiders' 13 ROBOTSTXT_OBEY = True
启动爬虫命令
scrapy crawl my_crawler
开始截图

爬虫结束截图
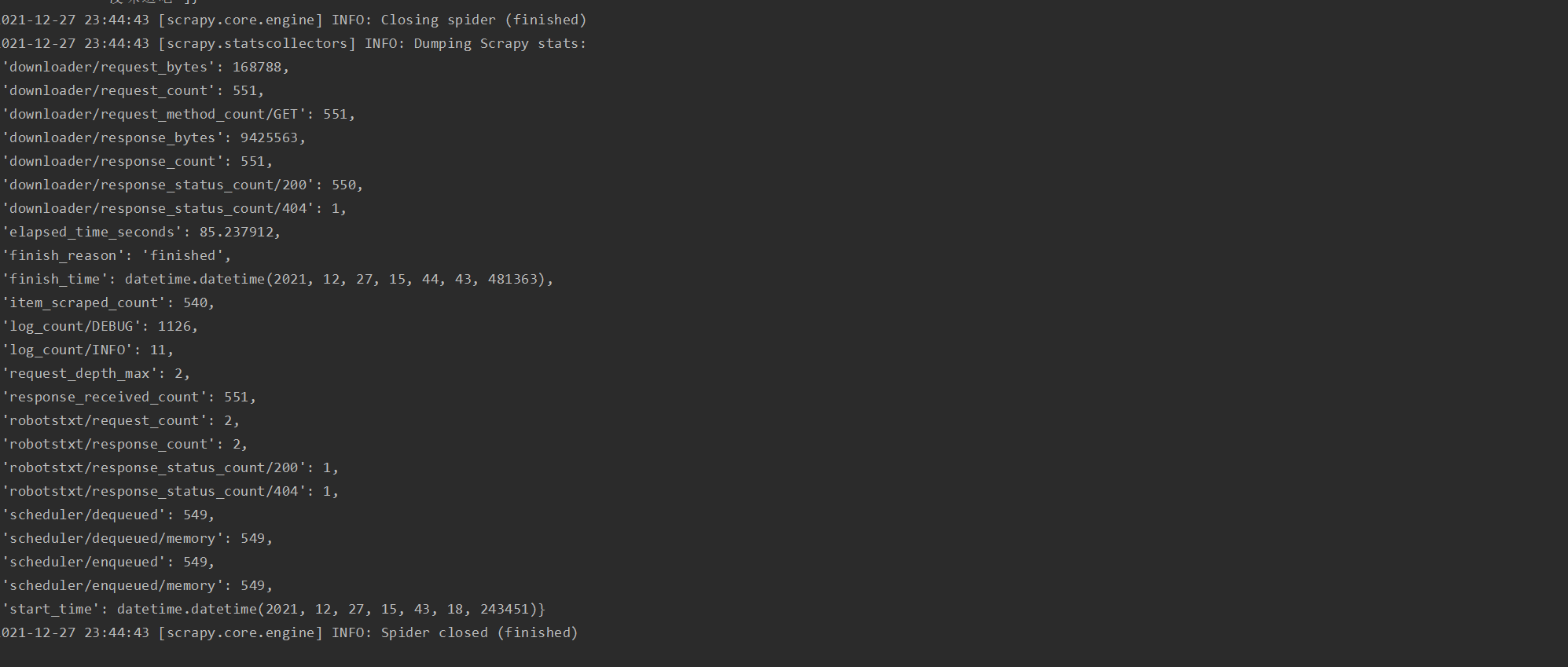
成果
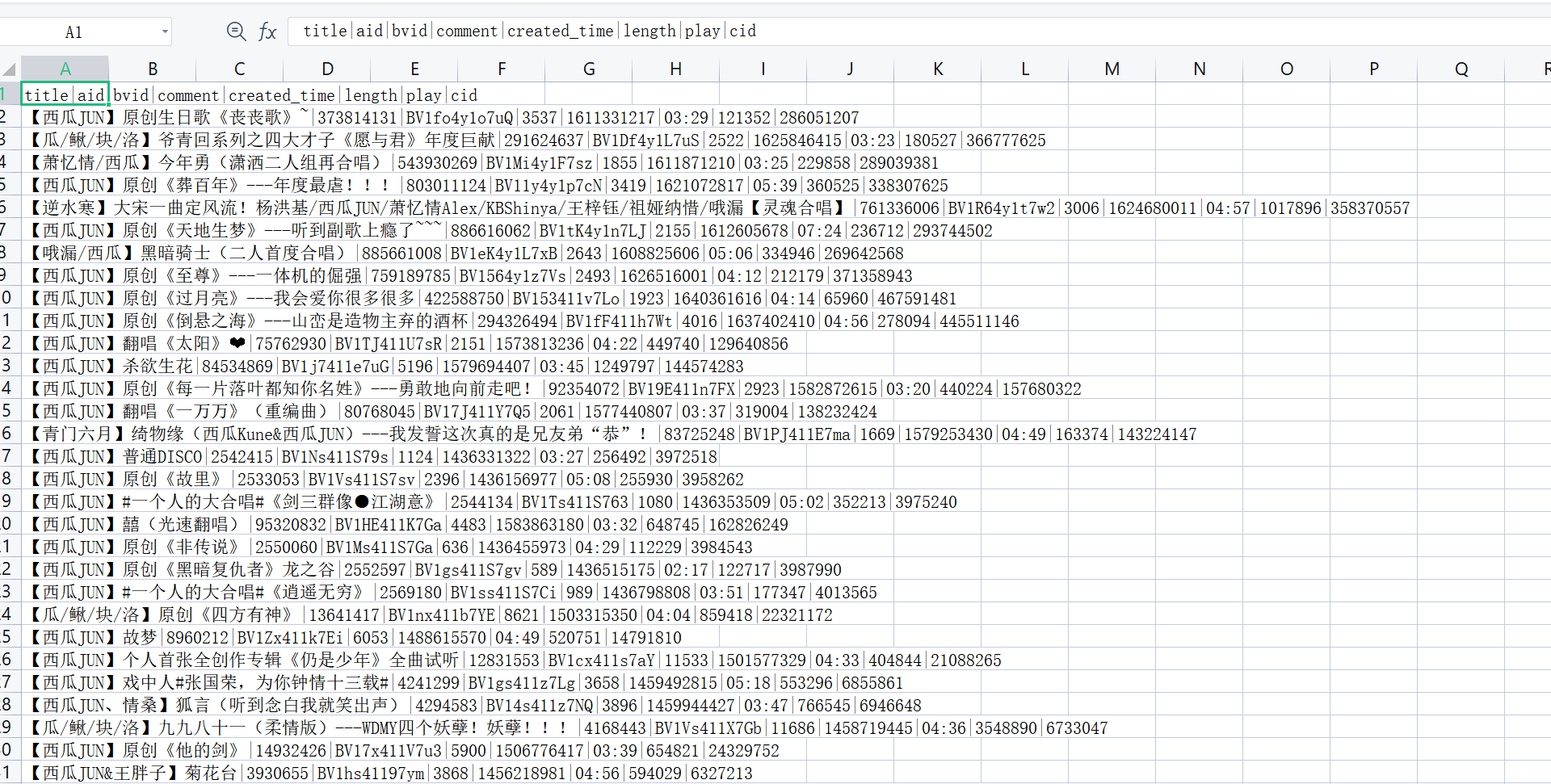

2.数据清洗和处理
(1)查看是否有空值
1 import pandas as pd 2 3 videos=pd.read_csv("E:\\video.csv",sep="|") 4 print(videos.isnull().any())
运行结果

表明无空值,无需清洗。
(2)将created_time转换为日期
1 videos['time'] = videos.created_time.apply(change_time) # 时间戳转为年月日时分 2 videos['date'] = videos.time.apply(split_date) # 分出日期 3 videos['hour_min'] = videos.time.apply(split_hour_min) # 分出时间 4 videos[["year","month","day"]] =videos.date.str.split('-',expand=True)
处理后结果
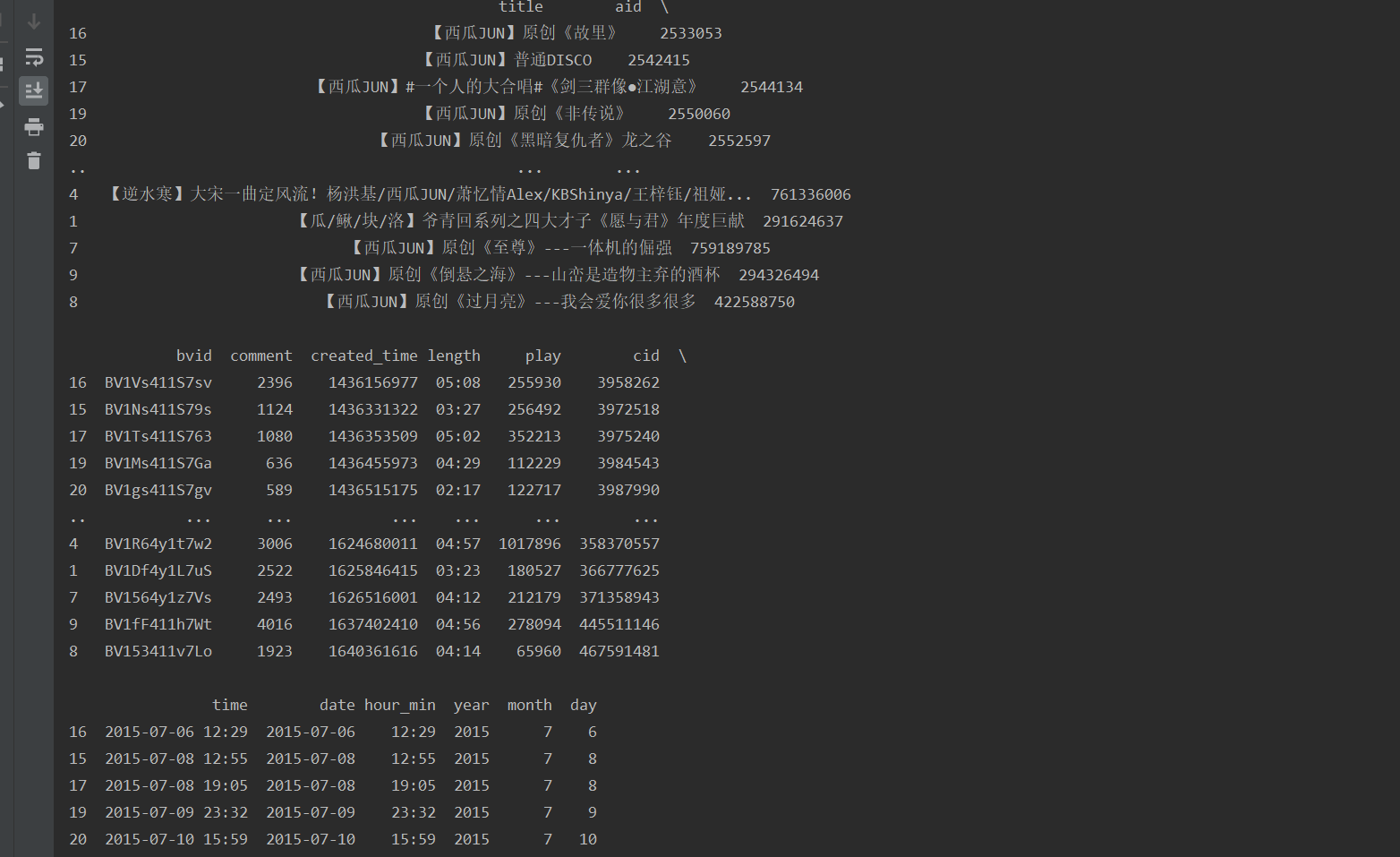
(3)将年月日的数据从字符串转换为整型,方便后面的数据可视化,并对这三列进行排序。
1 videos.year = videos.year.astype('int') 2 videos.month = videos.month.astype('int') 3 videos.day = videos.day.astype('int') 4 videos.sort_values(['year', 'month', 'day'], inplace=True)
先取出了年和月的数据,方便可视化时添加时间轴。
1 years = set(videos.year) 2 months = [] 3 for year in years: 4 months.append(set(videos[videos['year'].isin([year])].month))
3. 数据分析可视化(pandas+pyechats)
pyecharts库进行可视化,这里展示的数据是播放量和评论数随时间变化的柱状图。
1 #可视化 2 from pyecharts import options as opts 3 from pyecharts.charts import Bar, Timeline, WordCloud 4 5 timeline_2021 = Timeline() 6 for m in months[2]: 7 bar = ( 8 Bar() 9 .add_xaxis(list(videos[videos.year.isin([2021])][videos.month.isin([m])].day)) 10 .add_yaxis("播放量", list(videos[videos.year.isin([2021])][videos.month.isin([m])].play), yaxis_index=0, ) 11 .add_yaxis("评论数", list(videos[videos.year.isin([2021])][videos.month.isin([m])].comment), yaxis_index=1) 12 .extend_axis( 13 yaxis=opts.AxisOpts( 14 name="评论数", 15 type_="value", 16 position="right", 17 axislabel_opts=opts.LabelOpts(formatter="{value}"), 18 ) 19 ) 20 .set_global_opts(title_opts=opts.TitleOpts("拉草莓的西瓜JUN{}年{}月视频播放量和评论数".format(2021, m))) 21 ) 22 timeline_2021.add(bar, '{}月'.format(m)) 23 timeline_2021.render("view.html")
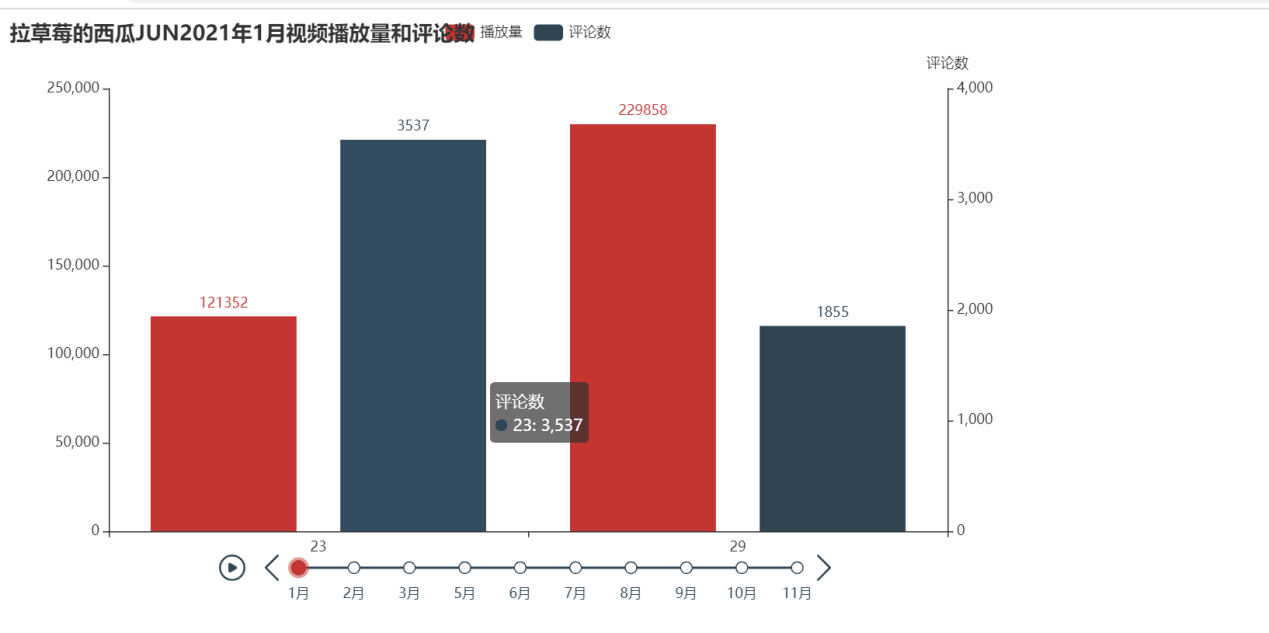
仅展示了2021年的,但是这样并不能看出博主视频的播放量波动情况,所以再使用折线图展示。
1 #可视化2 2 from pyecharts.charts import Line 3 4 line = ( 5 Line() 6 .set_global_opts( 7 tooltip_opts=opts.TooltipOpts(is_show=True), 8 xaxis_opts=opts.AxisOpts(type_="category"), 9 yaxis_opts=opts.AxisOpts( 10 type_="value", 11 axistick_opts=opts.AxisTickOpts(is_show=True), 12 splitline_opts=opts.SplitLineOpts(is_show=True), 13 ), 14 title_opts=opts.TitleOpts("拉草莓的西瓜JUN视频播放量和评论数折线图"), 15 datazoom_opts=[opts.DataZoomOpts()], 16 ) 17 .add_xaxis(xaxis_data=list(videos.time)) 18 .add_yaxis( 19 series_name="播放量", 20 y_axis=list(videos.play), 21 symbol="emptyCircle", 22 is_symbol_show=True, 23 label_opts=opts.LabelOpts(is_show=False), 24 yaxis_index=0, 25 ) 26 .add_yaxis( 27 series_name="评论数", 28 y_axis=list(videos.comment), 29 symbol="emptyCircle", 30 is_symbol_show=True, 31 label_opts=opts.LabelOpts(is_show=False), 32 yaxis_index=1, 33 ) 34 .extend_axis( 35 yaxis=opts.AxisOpts( 36 name="评论数", 37 type_="value", 38 position="right", 39 axislabel_opts=opts.LabelOpts(formatter="{value}"), 40 ) 41 ) 42 ) 43 line.render("view2.html")
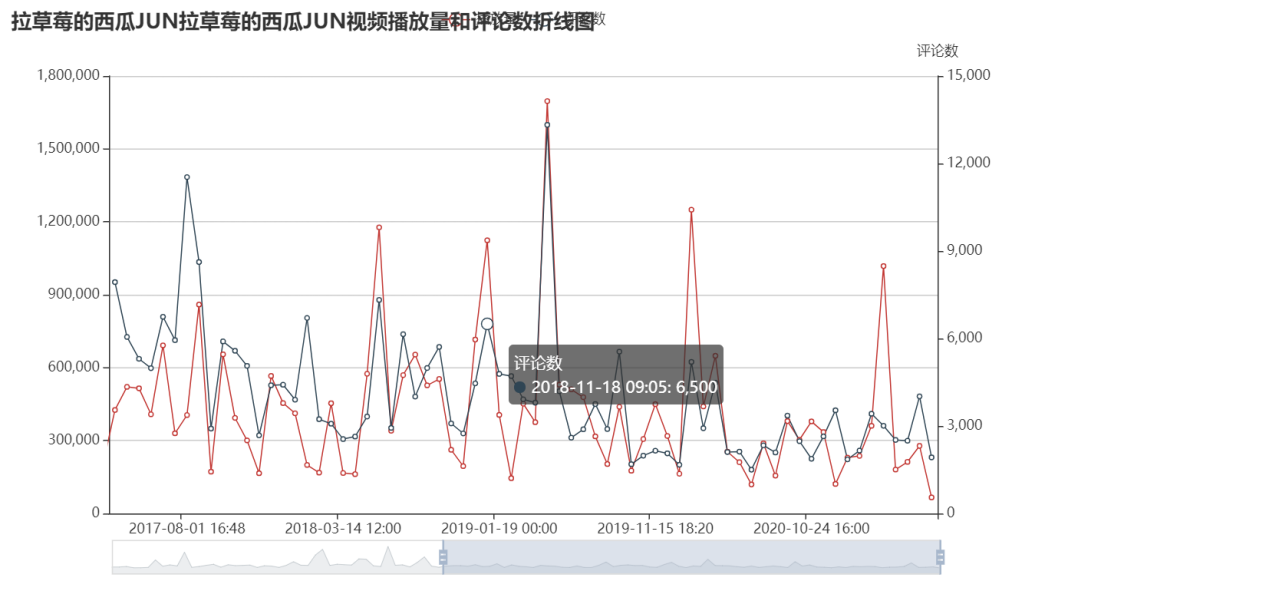
从该图可以看出,博主视频的播放量和评论数波动不大,中间的最高点我去找了一下那个视频,是与其他12个唱见一起合作的高考应援歌,怪不得那么多播放量。
接下来对视频长度和播放量使用了散点图可视化。
1 #可视化三 2 from pyecharts.charts import Scatter 3 4 c = ( 5 Scatter() 6 .add_xaxis(list(videos.length)) 7 .add_yaxis("播放量", list(videos.play)) 8 .set_global_opts( 9 title_opts=opts.TitleOpts(title="拉草莓的西瓜JUN视频时长-播放量散点图"), 10 visualmap_opts=opts.VisualMapOpts(type_="size", max_=1000000, min_=27000), 11 ) 12 ) 13 c.render("view3.html")
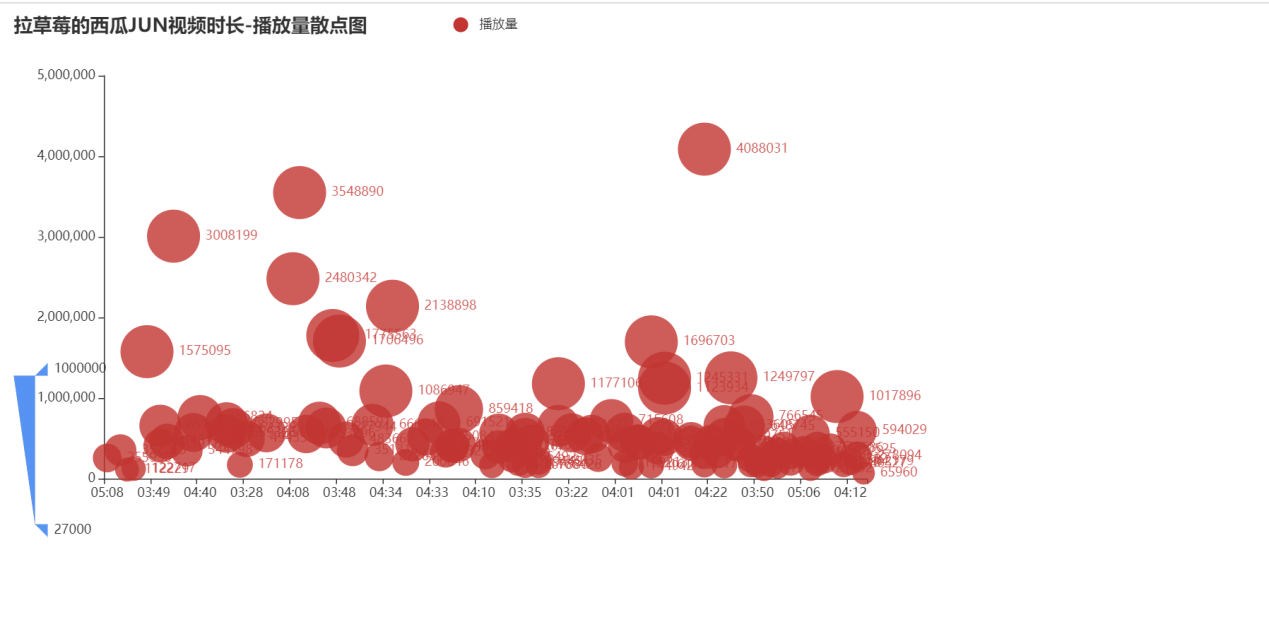
从这个图看出博主的视频播放量和时长无关,播放量大概集中在50万左右。
接下来将标题做成词云图,看看博主最喜欢用什么标题。
这里我使用的是jieba库进行分词,用正则简单处理了一下文本,并没有加入停用词。
1 #可视化四 2 import jieba 3 import re 4 from pyecharts.charts import WordCloud 5 from collections import Counter 6 7 title_cut = [] 8 9 10 def tokenizer(title): 11 return jieba.lcut(title) 12 13 14 for t in videos.title: 15 t = re.sub(r"[0-9,,。?!?!【】]+", "", t) 16 title_cut += tokenizer(t) 17 18 title_count = [] 19 for key, value in Counter(title_cut).items(): 20 title_count.append((key, value)) 21 22 w = ( 23 WordCloud() 24 .add(series_name="标题词云", data_pair=title_count, word_size_range=[10, 100]) 25 .set_global_opts( 26 title_opts=opts.TitleOpts( 27 title="标题词云", title_textstyle_opts=opts.TextStyleOpts(font_size=23) 28 ), 29 tooltip_opts=opts.TooltipOpts(is_show=True), 30 ) 31 ) 32 w.render("view4.html")
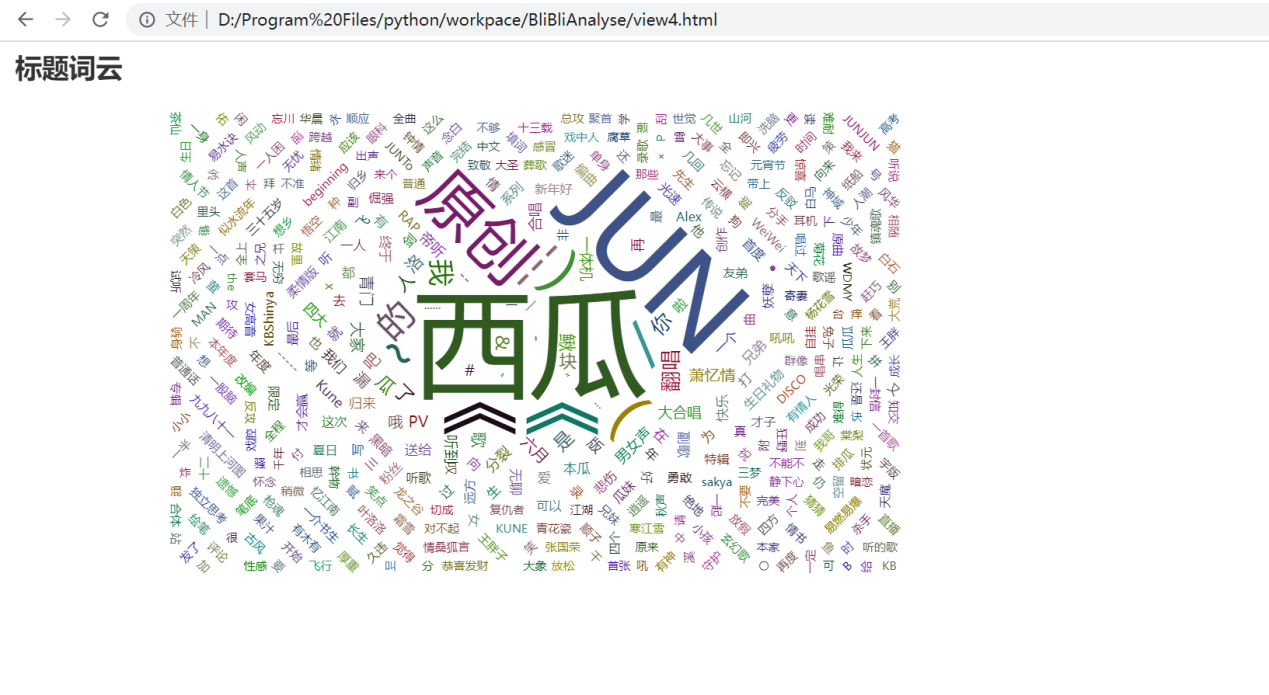
从词云图看出,博主的标题一般都会注上自己名字,合唱作品也会注上其他唱见的名字,有一小部分翻唱作品,但更多的是原创。
最后,用上了一直没用的弹幕做成词云图,因为弹幕最多只有1000多条,所以就不做折线图这些的可视化了。
弹幕词云
1 import jieba 2 buttet_chat = [] 3 path = 'E:\\buttet_chat' 4 dirs = os.listdir(path) 5 for file in dirs: 6 with open(os.path.join(path, file), 'r', encoding='utf-8')as fp: 7 content = fp.readlines() 8 buttet_chat += content[1:-1] 9 10 buttet_chat_cut = [] 11 def tokenizer(title): 12 return jieba.lcut(title) 13 for b in buttet_chat: 14 b = b.strip() 15 b = re.sub(r"[0-9,,。?!?!【】]+", "", b) 16 buttet_chat_cut += tokenizer(b) 17 18 buttet_chat_count = [] 19 for key, value in Counter(buttet_chat_cut).items(): 20 buttet_chat_count.append((key, value)) 21 22 w = ( 23 WordCloud() 24 .add(series_name="弹幕词云", data_pair=buttet_chat_count, word_size_range=[10, 100]) 25 .set_global_opts( 26 title_opts=opts.TitleOpts( 27 title="弹幕词云", title_textstyle_opts=opts.TextStyleOpts(font_size=23) 28 ), 29 tooltip_opts=opts.TooltipOpts(is_show=True), 30 ) 31 ) 32 w.render("view5.html")

从词云图可以看出,大家一般喜欢发的弹幕的是‘瓜瓜’,‘我’,‘表白’等,从小点的词可以看出也是有很多祝福的内容,例如:‘生日快乐’,‘圣诞快乐’,‘幸福’,‘愿’等,当然还有很多夸赞(吹)的话。
5.构建回归模型(sk-learn+matplotlib)
探究评论数和播放量相关性
1 #回归 2 import matplotlib.pyplot as plt 3 from sklearn.linear_model import LinearRegression as LR 4 reg=LR().fit(videos[['comment']],videos['play']) 5 print(reg.intercept_) 6 7 comment=videos["comment"].values 8 play=videos["play"].values 9 a,b=reg.coef_,reg.intercept_ 10 plt.rcParams['font.sans-serif']=['SimHei'] 11 plt.scatter(comment,play) 12 plt.xlabel("评论数") 13 plt.ylabel("播放量") 14 plt.plot(comment,a*comment+b) 15 plt.show()
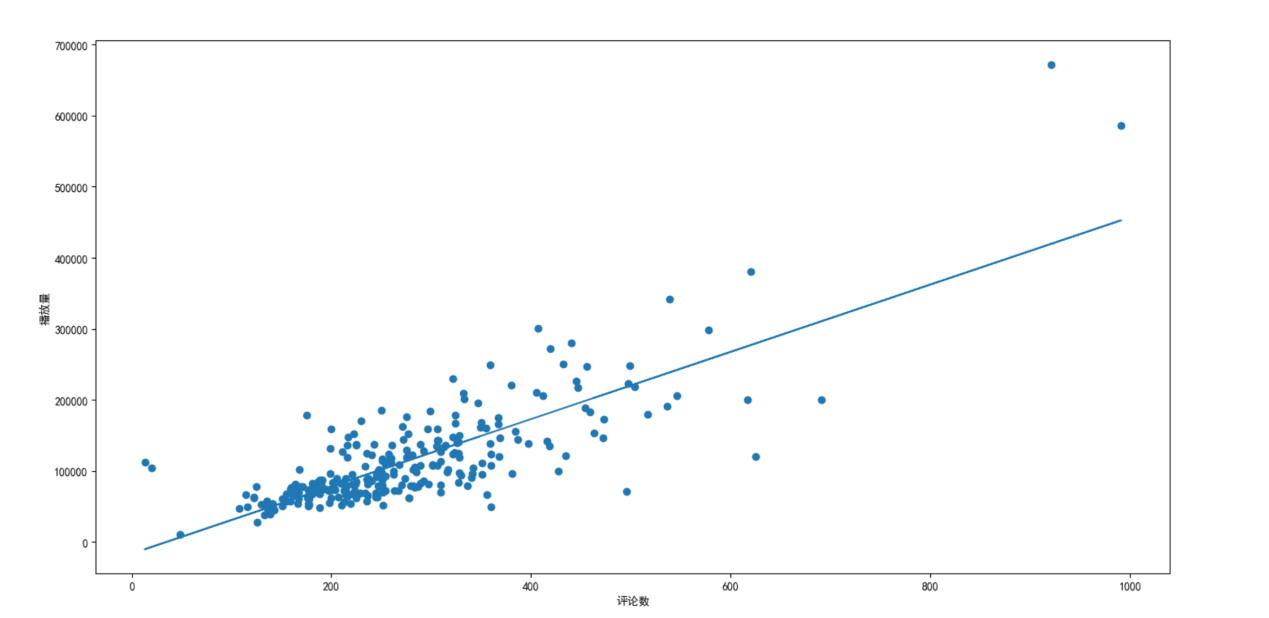
从图中来看,播放量和评论数成正比。
6.数据持久化
(1)标题

(2)115个视频的弹幕
7.代码总汇
1 import scrapy 2 class BilibiliErniuItem(scrapy.Item): 3 title = scrapy.Field() 4 aid = scrapy.Field() 5 bvid = scrapy.Field() 6 comment = scrapy.Field() 7 created_time = scrapy.Field() 8 length = scrapy.Field() 9 play = scrapy.Field() 10 cid = scrapy.Field() 11 12 class ErniuBulletChatItem(scrapy.Item): 13 cid = scrapy.Field() 14 content = scrapy.Field() 15 16 import json 17 18 import scrapy 19 20 from my_crawler.items import BilibiliErniuItem, ErniuBulletChatItem 21 class MaoyanSpider(scrapy.Spider): 22 name="my_crawler" 23 def start_requests(self): 24 base_url = 'https://api.bilibili.com/x/space/arc/search?mid=11684516&ps=30&tid=0&pn={}&keyword=&order=pubdate&jsonp=jsonp' 25 headers = self.settings.get('DEFAULT_REQUEST_HEADERS') 26 for pn in range(1, 10): 27 url = base_url.format(pn) 28 yield scrapy.Request(url=url, headers=headers, callback=self.parse_video_info) 29 30 31 def parse_video_info(self, response): 32 detail = json.loads(response.text) 33 headers = self.settings.get('DEFAULT_REQUEST_HEADERS') 34 for info in detail.get('data').get('list').get('vlist'): 35 item = BilibiliErniuItem() 36 item['title'] = info.get('title') 37 item['aid'] = info.get('aid') 38 item['bvid'] = info.get('bvid') 39 item['comment'] = info.get('comment') 40 item['created_time'] = info.get('created') 41 item['length'] = info.get('length') 42 item['play'] = info.get('play') 43 cid_url = 'https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp'.format(item['bvid']) 44 yield scrapy.Request(url=cid_url, headers=headers, meta={'item': item}, callback=self.get_bullet_chat_url) 45 46 47 def get_bullet_chat_url(self, response): 48 detail = json.loads(response.text) 49 headers = self.settings.get('DEFAULT_REQUEST_HEADERS') 50 item = response.meta['item'] 51 cid = detail.get('data')[0].get('cid') 52 item['cid'] = cid 53 bullet_chat_url = 'http://comment.bilibili.com/{}.xml'.format(cid) 54 yield scrapy.Request(url=bullet_chat_url, headers=headers, meta={'cid': cid}, callback=self.parse_bullet_chat) 55 yield item 56 57 58 def parse_bullet_chat(self, response): 59 sel = scrapy.Selector(response) 60 item = ErniuBulletChatItem() 61 item['cid'] = response.meta['cid'] 62 item['content'] = sel.xpath('//d//text()').extract() 63 yield item 64 65 import os 66 67 from my_crawler.items import BilibiliErniuItem 68 69 70 class MyCrawlerPipeline(object): 71 def __init__(self): 72 self.dirs = 'E:\\video.csv' 73 if not os.path.exists(self.dirs): 74 with open(self.dirs, 'w', encoding='utf-8')as fp: 75 fp.write('title|aid|bvid|comment|created_time|length|play|cid\n') 76 self.buttet_chat_dir = 'E:\\buttet_chat' 77 if not os.path.exists(self.buttet_chat_dir): 78 os.makedirs(self.buttet_chat_dir) 79 80 def process_item(self, item, spider): 81 if isinstance(item, BilibiliErniuItem): 82 with open(self.dirs, 'a', encoding='utf-8') as fp: 83 fp.write(item['title'] + '|' + str(item['aid']) + '|' + item['bvid'] + '|' + str( 84 item['comment']) + '|' + str(item['created_time']) + '|' + item['length'] + '|' + str( 85 item['play']) + '|' + str(item['cid']) + '\n') 86 return item 87 else: 88 filename = str(item['cid']) + '.csv' 89 if not os.path.exists(self.buttet_chat_dir + '\\' + filename): 90 with open(self.buttet_chat_dir + '\\' + filename, 'w', encoding='utf-8')as fp: 91 fp.write('content' + '\n') 92 for content in item['content']: 93 fp.write(content + '\n') 94 return item 95 96 DEFAULT_REQUEST_HEADERS = { 97 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 98 'Accept-Language': 'en', 99 } 100 ITEM_PIPELINES = { 101 'my_crawler.pipelines.MyCrawlerPipeline': 300, 102 } 103 LOG_LEVEL = 'WARNING' 104 BOT_NAME = 'my_crawler' 105 106 SPIDER_MODULES = ['my_crawler.spiders'] 107 NEWSPIDER_MODULE = 'my_crawler.spiders' 108 ROBOTSTXT_OBEY = True 109 110 import pandas as pd 111 112 videos=pd.read_csv("E:\\video.csv",sep="|") 113 print(videos.isnull().any()) 114 115 videos['time'] = videos.created_time.apply(change_time) # 时间戳转为年月日时分 116 videos['date'] = videos.time.apply(split_date) # 分出日期 117 videos['hour_min'] = videos.time.apply(split_hour_min) # 分出时间 118 videos[["year","month","day"]] =videos.date.str.split('-',expand=True) 119 120 videos.year = videos.year.astype('int') 121 videos.month = videos.month.astype('int') 122 videos.day = videos.day.astype('int') 123 videos.sort_values(['year', 'month', 'day'], inplace=True) 124 125 years = set(videos.year) 126 months = [] 127 for year in years: 128 months.append(set(videos[videos['year'].isin([year])].month)) 129 130 #可视化 131 from pyecharts import options as opts 132 from pyecharts.charts import Bar, Timeline, WordCloud 133 134 timeline_2021 = Timeline() 135 for m in months[2]: 136 bar = ( 137 Bar() 138 .add_xaxis(list(videos[videos.year.isin([2021])][videos.month.isin([m])].day)) 139 .add_yaxis("播放量", list(videos[videos.year.isin([2021])][videos.month.isin([m])].play), yaxis_index=0, ) 140 .add_yaxis("评论数", list(videos[videos.year.isin([2021])][videos.month.isin([m])].comment), yaxis_index=1) 141 .extend_axis( 142 yaxis=opts.AxisOpts( 143 name="评论数", 144 type_="value", 145 position="right", 146 axislabel_opts=opts.LabelOpts(formatter="{value}"), 147 ) 148 ) 149 .set_global_opts(title_opts=opts.TitleOpts("拉草莓的西瓜JUN{}年{}月视频播放量和评论数".format(2021, m))) 150 ) 151 timeline_2021.add(bar, '{}月'.format(m)) 152 timeline_2021.render("view.html") 153 154 #可视化2 155 from pyecharts.charts import Line 156 157 line = ( 158 Line() 159 .set_global_opts( 160 tooltip_opts=opts.TooltipOpts(is_show=True), 161 xaxis_opts=opts.AxisOpts(type_="category"), 162 yaxis_opts=opts.AxisOpts( 163 type_="value", 164 axistick_opts=opts.AxisTickOpts(is_show=True), 165 splitline_opts=opts.SplitLineOpts(is_show=True), 166 ), 167 title_opts=opts.TitleOpts("拉草莓的西瓜JUN视频播放量和评论数折线图"), 168 datazoom_opts=[opts.DataZoomOpts()], 169 ) 170 .add_xaxis(xaxis_data=list(videos.time)) 171 .add_yaxis( 172 series_name="播放量", 173 y_axis=list(videos.play), 174 symbol="emptyCircle", 175 is_symbol_show=True, 176 label_opts=opts.LabelOpts(is_show=False), 177 yaxis_index=0, 178 ) 179 .add_yaxis( 180 series_name="评论数", 181 y_axis=list(videos.comment), 182 symbol="emptyCircle", 183 is_symbol_show=True, 184 label_opts=opts.LabelOpts(is_show=False), 185 yaxis_index=1, 186 ) 187 .extend_axis( 188 yaxis=opts.AxisOpts( 189 name="评论数", 190 type_="value", 191 position="right", 192 axislabel_opts=opts.LabelOpts(formatter="{value}"), 193 ) 194 ) 195 ) 196 line.render("view2.html") 197 198 #可视化三 199 from pyecharts.charts import Scatter 200 201 c = ( 202 Scatter() 203 .add_xaxis(list(videos.length)) 204 .add_yaxis("播放量", list(videos.play)) 205 .set_global_opts( 206 title_opts=opts.TitleOpts(title="拉草莓的西瓜JUN视频时长-播放量散点图"), 207 visualmap_opts=opts.VisualMapOpts(type_="size", max_=1000000, min_=27000), 208 ) 209 ) 210 c.render("view3.html") 211 212 #可视化四 213 import jieba 214 import re 215 from pyecharts.charts import WordCloud 216 from collections import Counter 217 218 title_cut = [] 219 220 221 def tokenizer(title): 222 return jieba.lcut(title) 223 224 225 for t in videos.title: 226 t = re.sub(r"[0-9,,。?!?!【】]+", "", t) 227 title_cut += tokenizer(t) 228 229 title_count = [] 230 for key, value in Counter(title_cut).items(): 231 title_count.append((key, value)) 232 233 w = ( 234 WordCloud() 235 .add(series_name="标题词云", data_pair=title_count, word_size_range=[10, 100]) 236 .set_global_opts( 237 title_opts=opts.TitleOpts( 238 title="标题词云", title_textstyle_opts=opts.TextStyleOpts(font_size=23) 239 ), 240 tooltip_opts=opts.TooltipOpts(is_show=True), 241 ) 242 ) 243 w.render("view4.html") 244 245 import jieba 246 buttet_chat = [] 247 path = 'E:\\buttet_chat' 248 dirs = os.listdir(path) 249 for file in dirs: 250 with open(os.path.join(path, file), 'r', encoding='utf-8')as fp: 251 content = fp.readlines() 252 buttet_chat += content[1:-1] 253 254 buttet_chat_cut = [] 255 def tokenizer(title): 256 return jieba.lcut(title) 257 for b in buttet_chat: 258 b = b.strip() 259 b = re.sub(r"[0-9,,。?!?!【】]+", "", b) 260 buttet_chat_cut += tokenizer(b) 261 262 buttet_chat_count = [] 263 for key, value in Counter(buttet_chat_cut).items(): 264 buttet_chat_count.append((key, value)) 265 266 w = ( 267 WordCloud() 268 .add(series_name="弹幕词云", data_pair=buttet_chat_count, word_size_range=[10, 100]) 269 .set_global_opts( 270 title_opts=opts.TitleOpts( 271 title="弹幕词云", title_textstyle_opts=opts.TextStyleOpts(font_size=23) 272 ), 273 tooltip_opts=opts.TooltipOpts(is_show=True), 274 ) 275 ) 276 w.render("view5.html") 277 278 #回归 279 import matplotlib.pyplot as plt 280 from sklearn.linear_model import LinearRegression as LR 281 reg=LR().fit(videos[['comment']],videos['play']) 282 print(reg.intercept_) 283 284 comment=videos["comment"].values 285 play=videos["play"].values 286 a,b=reg.coef_,reg.intercept_ 287 plt.rcParams['font.sans-serif']=['SimHei'] 288 plt.scatter(comment,play) 289 plt.xlabel("评论数") 290 plt.ylabel("播放量") 291 plt.plot(comment,a*comment+b) 292 plt.show()
五、总结
1、每个分析与可视化的结论已附于图片下方。已达到预期目标。
2、收获:重新复习了一遍scrapy框架,明白了更多知识点。无改进建议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号