鄢宇航--第一次个人编程作业
| 这个作业属于哪个课程 | <软件工程综合实践> |
|---|---|
| 这个作业要求在哪里 | <作业要求> |
| 这个作业的目标 | 独立完成数据采集、分析处理和可视化的三大步骤 |
| 作业源代码 | first-personal-work |
| 学号 | 211805249 |
作业完成记录:
| 代码行数:200+ | 需求分析:1~2h | 数据采集与处理:2~3h | 可视化:n |
|---|
前言(第一次编程作业)
由于上学期学了爬虫,所以选择第一题,顺便回顾一下上学期的爬虫知识。前期比较顺利的爬取到了数据,并使用jieba第三方库做了分词处理。本想用刚学的JavaWeb基础搭一个后端服务,对comments.json做异步处理交由页面渲染。于此同时存在跨域问题,弄了很久还是没弄好。为了提前完成作业,找了一个捷径,把所有资源放在tomcat的同一个项目目录下,使用XMLHttpRequest对象请求即可获得数据,所以异步请求留着自己慢慢做。
一、爬取腾讯视频《在一起》评论数据
- 视频评论信息是异步加载的形式,使用chrome控制台中的Filter可以过滤出javascript传过来的一条数据。在借鉴网上的经验发现,请求数据中暗藏的玄机。
- 每次点击【查看更多评论】会换一个数据地址,但只有cursor字段的值和最后尾部的数据会发生改变
- cursor的值隐藏在上一层数据的last字段中,而尾部数值每次自增1
- 每次数据地址发送变化后,客户端会请求信息的评论信息,根据这一规律可以不断获取评论数据

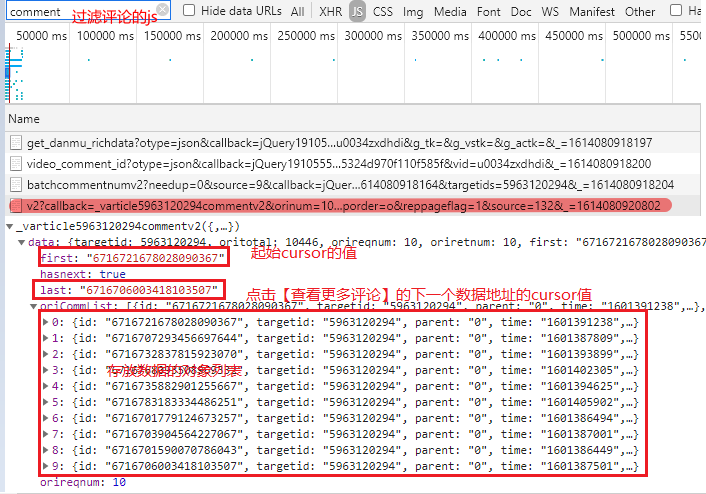
- 了解到异步请求评论信息的规律后就可以开始爬
- 没有使用urllib构造请求地址,就直接字符串拼接出地址,然后用requests库请求获取源码
- 在源码字符串中使用正则提取json格式的字符串 _varticlexxxxxxxxcommentv2([json格式字符串])
- 提取出的字符串转成python数据类型,直接获取评论信息,并保持到文件
def parse_page(source): # 解析构造出来的json页面
# 提取中间符合json格式的字符串
string_json = re.search('.*?\((.*)\)', source, re.S).group(1)
source_json = json.loads(string_json) # 将网页源码字符串转成json格式
items = source_json.get("data").get("oriCommList") # 获取包含评论的部分
buff_list = list()
for item in items:
buff_list.append(item.get("content"))
write_to_local(buff_list)
return source_json.get("data").get("last")
def main():
base_url = 'https://video.coral.qq.com/varticle/5963120294/comment/v2?' \
'callback=_varticle5963120294commentv2&orinum=10&oriorder=o&pageflag=1' \
'&cursor={}&scorecursor=0&orirepnum=2&reporder=o&' \
'reppageflag=1&source=132&_={}'
cursor = 6716721678028090367
tail = 1613808784355
while True:
source = get_page(base_url, cursor, tail)
cursor = parse_page(source)
tail += 1
time.sleep(2) # 为确保程序安全运行,选择爬取一页后延时2秒
二、对评论信息做分词处理
- 使用jieba第三方库对句子做精确的分词处理,用字典数据类型临时存储,统计数量
- 根据value值的大小,对字典做一个降序处理,把个数大于30的保存到 comments.json 文件
def word_counter(read_buff):
words_dict = dict()
for word in read_buff: # 统计字典中key相同的词
words_dict[word] = words_dict.get(word, 0) + 1
# get()方法,如果key存在返回对应value值,否则返回默认值0
# 对字典排序
return sorted(words_dict.items(), key=lambda item: item[1], reverse=True)
def breakup_sentence(sentence, read_buff):
msg_list = jieba.cut(sentence)
for msg in msg_list:
if len(msg) > 1: # 去除空字符和单个字符的
read_buff.append(msg)
def main():
read_buff = list()
load_data(read_buff)
words_dict = word_counter(read_buff)
write_to_file(words_dict)
三、加载json数据,生成词云图
- 本想封装api调用数据,奈何自己还没学透,存在各种问题,这里使用XMLHttpRequest请求
- 把所有需要用到的文件和资源放在tomcat的一个webapp上跑,不需要做各种请求和跨域处理,简单无脑
- echarts没有支持词云图,要生成词云图还需要引入echarts-wordcloud.js
<script>
// 初始化echarts到展示的div节点
var chart = echarts.init(document.getElementById('content'));
// 页面加载完毕后 处理数据和生成云图的逻辑
window.onload = function () {
var url = "data/comments.json" // tomcat服务器json文件的资源地址
// 实例化XMLHttpRequest 对象,用于浏览器在后台与服务器交换数据。
var request = new XMLHttpRequest();
request.open("get", url); // 初始化http请求参数
// 发送请求,但不发送数据给服务器
request.send(null);
/*XHR对象获取到返回信息后执行*/
request.onload = function () {
/*返回状态为200 或者readyState等于4,即为数据获取成功*/
if (request.status == 200 || request.readyState == 4) {
// 使用JSON对象解析返回的信息
var arraylist = JSON.parse(request.responseText).data;
console.log(arraylist); // 打印数组,验证数据格式是否正确
// 设置云图的配置参数列表
chart.setOption({
series: [ {
type: 'wordCloud', // 类型
//数据是一个数组。每个数组项必须具有name和value属性。
data: arraylist // 渲染的数据
}]
});
}
}
}
window.onresize = chart.resize; // 自适应画布
</script>
- 词云图展示(本来是个五角星形状,可能数据比较多变形了)

问题与自我总结:
- 作业比较早就开始着手,途中遇到各种问题都需要动手去调试、解决
- 信心满满的写个后端服务,结果各种状况。后面慢慢改吧
- 总之需要不断的积累和尝试,才能检验自己的成果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号