
跟浩哥学自动化测试Selenium -- 浏览器的基本操作与元素定位(3)
浏览器的基本操作与元素定位
通过上一章学习,我们已经学会了如何设置驱动路径,如何创建浏览器对象,如何打开一个网站,接下来我们要进行一些复杂的操作比如先打开百度首页,在打开博客园,网页后退,前进等等,甚至可以获取一些浏览器信息等等。
首先看一个基本的例子,流程如下:
- 打开百度的网站
- 获取到百度首页的Title
- 获取当前页面的URL
- 获取页面的html信息
对应的代码如下:
public class SeleniumTest { public static void main(String... args){ System.setProperty("webdriver.gecko.driver","c:\\geckodriver.exe"); WebDriver webDriver = new FirefoxDriver(); webDriver.get("http://www.baidu.com"); System.out.println(webDriver.getTitle());//获取首页的Title System.out.println(webDriver.getCurrentUrl());//获取当前url System.out.println(webDriver.getPageSource());//获取页面的html信息 } }
再来看一个例子,操作流程如下:
- 打开百度首页
- 打开我的博客页面
- 后退到百度页面
- 前进到博客页面
- 刷新页面
- 关闭页面
对应的代码如下:
public class SeleniumTest { public static void main(String... args){ System.setProperty("webdriver.gecko.driver","c:\\geckodriver.exe"); WebDriver webDriver = new FirefoxDriver(); webDriver.navigate().to("http://www.baidu.com"); webDriver.navigate().to("https://www.cnblogs.com/jacktest"); webDriver.navigate().back();//后退 webDriver.navigate().forward();//前进 webDriver.navigate().refresh();//刷新 webDriver.close();//关闭浏览器 webDriver.quit();//关闭浏览器以及驱动 } }
close 和 quit区别:close 只会关闭当前浏览器,而quit不仅会关闭浏览器也会杀掉驱动进程。close的问题在于你多次进行调试时,进程中会残留多个驱动进程,这种情况有可能会引起一些其他的问题,建议使用quit。
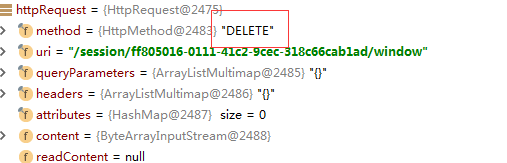
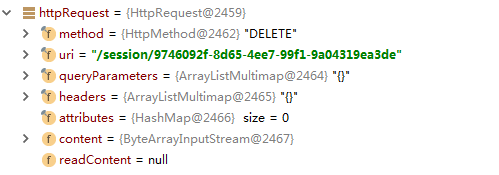
源码分析,close和quit在发送 HttpRequest 请求时,method 都是DELETE ,但uri不同,如下:
close的HttpRequest
quit 的HttpRequest
最后看一个例子,基础元素定位,流程如下:
- 打开百度首页
- 点击登录链接
- 输入用户名、密码
- 点击登录
对应的代码如下:
public class SeleniumTest { public static void main(String... args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", "C:\\driver\\geckodriver.exe"); WebDriver webDriver = new FirefoxDriver(); webDriver.manage().window().maximize();//浏览器最大化 webDriver.get("https://www.baidu.com"); webDriver.findElement(By.xpath("//div[@id='u1']/a[@name='tj_login']")).click();//点击登录链接 Thread.sleep(1000); webDriver.findElement(By.id("TANGRAM__PSP_10__footerULoginBtn")).click();//点击用户名登录 webDriver.findElement(By.id("TANGRAM__PSP_10__userName")).sendKeys("jacktest");//输入用户名 webDriver.findElement(By.id("TANGRAM__PSP_10__password")).sendKeys("123456");//输入密码 webDriver.findElement(By.id("TANGRAM__PSP_10__submit")).click();//点击登录 } }
运行该脚本,我们发现打开了火狐浏览器,打开百度首页,点击了登录链接,输入了用户名、密码并成功进行了登录。什么登录失败,哈哈,当然,账号换成你自己的就ok 了。
代码分析,在该脚本中,我们看到了Thread.sleep(1000),它的作用是让脚本执行时暂停1秒,有的同学会问,为什么要暂停呢?因为我的脚本在执行完webDriver.findElement(By.xpath("//div[@id='u1']/a[@name='tj_login']")).click()这条语句后,弹出窗口不会马上弹出来,大概需要 0.5-1秒的时间,如果在窗口未弹出的情况下执行下一条语句时,就会发生错误(org.openqa.selenium.NoSuchElementException异常---找不到元素),所以,我要等待一下,等窗口出现以及页面上的元素出现就不会出现以上错误了。有的同学会问,难道所有的窗口以及元素或页面都得等待吗,我们都需要加sleep吗,浩哥的回答是当然不需要。在脚本调试过程中,只有极个别的情况需要加等待,当然我们也有更好的方式去解决这个问题,比如显示等待,隐式等待,自定义等待等等。
接下来,我们再来看几个常用的方法:
public class SeleniumTest { public static void main(String... args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", "C:\\driver\\geckodriver.exe"); WebDriver webDriver = new FirefoxDriver(); webDriver.manage().window().fullscreen();//浏览器全屏,相当于F11 Point point = new Point(50, 100); webDriver.manage().window().setPosition(point);//指定窗口出现的位置 Dimension dimension = new Dimension(500, 600); webDriver.manage().window().setSize(dimension);//指定窗口大小 WebDriver.ImeHandler imeHandler = webDriver.manage().ime(); System.out.println(imeHandler.isActivated());//输入法相关的API,查了一些资料好像只支持linux,有兴趣可以自己试试 } }
日志相关的API,指的是Selenium原生的日志支持,并不是指比如像 log4j 这样的外部提供的日志支持。
public class SeleniumTest {
public static void main(String... args) throws InterruptedException {
System.setProperty("webdriver.gecko.driver", "C:\\driver\\geckodriver.exe");
DesiredCapabilities desiredCapabilities = DesiredCapabilities.firefox();
LoggingPreferences loggingPreferences = new LoggingPreferences();
loggingPreferences.enable(LogType.BROWSER, Level.ALL);
loggingPreferences.enable(LogType.CLIENT, Level.ALL);
loggingPreferences.enable(LogType.DRIVER, Level.ALL);
desiredCapabilities.setCapability(CapabilityType.LOGGING_PREFS, loggingPreferences);
WebDriver webDriver = new FirefoxDriver(desiredCapabilities);
LogEntries logEntries = webDriver.manage().logs().get(LogType.BROWSER);
for (LogEntry logEntry : logEntries) {
System.out.println(logEntry.getMessage()+"--");
}
webDriver.get("https://www.baidu.com");
}
}
自己试验了一下上述代码,在Selenium 3.0 之前的版本中可以支持,在之后无法支持,提示org.openqa.selenium.UnsupportedCommandException: POST /session/419bca1f-d33d-46ff-8979-10e88901cd12/log did not match a known command。好像是由于logs 并不支持 W3C 规范,大家也可以试试其他的方法是否支持。如果想关闭运行Selenium的日志输出,可把loggingPreferences.enable(LogType.BROWSER, Level.OFF)设置成off即可。
接下来,我们再看一个有关 Session id 相关的 API:
public class SeleniumTest { public static void main(String... args) throws InterruptedException { System.setProperty("webdriver.gecko.driver", "C:\\driver\\geckodriver.exe"); WebDriver webDriver = new FirefoxDriver(); webDriver.get("https://www.baidu.com"); Set<String> strings = ((FirefoxDriver) webDriver).getLocalStorage().keySet(); for (String s : strings) { System.out.println(s); //输出结果为BIDUPSID } System.out.println(((FirefoxDriver) webDriver).getLocalStorage().getItem("BIDUPSID"));//获取值 } }
有的同学问,输出结果为什么是BIDUPSID呢,代表什么意思呢,看完后面的内容大家就明白了。
首先我们先看一下api,根据 Selenium3 官方文档 LocalStorage 的表示当前在浏览器中打开站点的本地存储,每个站点都有自己的独立的存储区域,也就是打开不同的网站 LocalStorage 各不相同,大家可以自行试验。有的同学会问,那这和 Session id 有什么关系呢,接下来,我们来普及一下 Session 的一些知识。
Session id 主要是用来维持会话状态的通信秘钥,在请求过程中,默认名字SESSIONID,当然也可以自定义命名(百度的Sessionid是自定义命名)。以百度为例,用户第一次访问www.baidu.com的时候,由于请求头(Request Header)中没有带BIDUPSID,百度服务器认为这是一个新的会话,会在服务端给这次会话生成一个唯一标识的 Session id,同时会在http请求的(Response header)中将这个 Session id 带给浏览器,反应在请求的Response header,如下:
Set-Cookie:BIDUPSID=EEAE958FDBA12D0BECDA19585965F6E8; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
这个Session id 就是 key=BIDUPSID,value=EEAE958FDBA12D0BECDA19585965F6E8 这样一个结构,浏览器接收到 response 中Set-Cookie命令之后,会在浏览器设置cookie 值 BIDUPSID=EEAE958FDBA12D0BECDA19585965F6E8,并在以后请求 baidu.com 这类域名时带上cookie值,既 Request Header 中带上Cookie:BAIDUID=EEAE958FDBA12D0BECDA19585965F6E8,这样服务器就可以通过这个秘钥来识别请求来自哪个用户了。
继续验证上述问题,打开google浏览器,清除百度页面相关的所有缓存,打开开发者模式,切换到 Network 页,在浏览器中输入https://www.baidu.com,其中部分请求页面如下:
点击第一个请求,在Header中进行查看,
General
Request URL:https://www.baidu.com/
Request Method:GET
Status Code:200 OK
Remote Address:111.13.100.92:443
Referrer Policy:no-referrer-when-downgrade
Response Headers
Connection:Keep-Alive
Content-Length:225
Content-Type:text/html
Date:Mon, 09 Jul 2018 07:20:43 GMT
Location:https://www.baidu.com/
P3p:CP=" OTI DSP COR IVA OUR IND COM "
Server:BWS/1.1
Set-Cookie:BD_LAST_QID=10490791214885359030; path=/; Max-Age=1
Set-Cookie:BAIDUID=813A9265BC68AC521C003B3ABEFDB222:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie:BIDUPSID=D09FD09E7F46EBE0242500D6844DEE1D; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie:PSTM=1531120843; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
X-Ua-Compatible:IE=Edge,chrome=1
Request Header
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.9
Connection:keep-alive
Host:www.baidu.com
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
分析如下:由于第一次请求时未存在 BIDUPSID,所以百度服务器认为这是一次新的会话,接着在服务端生成唯一标识Sessionid,既Set-Cookie:BAIDUID命令,下次请求baidu.com的网页时会带上这个信息。
打开另一个Tab页面,输入百度首页,查看 Request Header,信息如下:
General
Request URL:https://www.baidu.com/
Request Method:GET
Status Code:200 OK
Remote Address:111.13.100.91:443
Referrer Policy:no-referrer-when-downgrade
Response Headers
Bdpagetype:1
Bdqid:0xa07b1f01000072b3
Cache-Control:private
Connection:Keep-Alive
Content-Encoding:gzip
Content-Type:text/html
Cxy_all:baidu+7fa1ff7e20dcb627a29697a5f962bcc8
Date:Mon, 09 Jul 2018 07:43:37 GMT
Expires:Mon, 09 Jul 2018 07:43:22 GMT
Server:BWS/1.1
Set-Cookie:BDSVRTM=0; path=/
Set-Cookie:BD_HOME=0; path=/
Set-Cookie:H_PS_PSSID=1425_25810_21083_20719; path=/; domain=.baidu.com
Strict-Transport-Security:max-age=172800
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Ua-Compatible:IE=Edge,chrome=1
Request Header
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9
Connection:keep-alive
Cookie:BAIDUID=813A9265BC68AC521C003B3ABEFDB222:FG=1; BIDUPSID=813A9265BC68AC521C003B3ABEFDB222; PSTM=1531121867; BD_HOME=0; H_PS_PSSID=1425_25810_21083_20719; BD_UPN=12314353; SL_GWPT_Show_Hide_tmp=1; SL_wptGlobTipTmp=1
Host:www.baidu.com
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
因为在第一次请求时服务器已经返回了BIDUPSID,所以下一次请求时候直接在request header 中加上了BIDUPSID(Sessionid),既验证了上述内容。
关于 Selenium cookie 操作的 API,我们会在之后的API 进行分析,此处先略过。
通过本章的学习的,我们学会了几个操作,如何操作浏览器,怎么点击元素(click),怎么输入数据(sendKeys),元素定位(id的方式),元素定位(xpath的方式)。是不是感觉很简单,其实 Selenium 的API 中常用方法只有十几个,使用起来还是蛮简单的。
在下一篇 《常用定位模式分析》中,我们会一一介绍所有的元素定位模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号