原文链接: http://www.cnblogs.com/jacklu/p/8379726.html
博士一年级选了这门课 SEEM 5680 Text Mining Models and Applications,记下来以便以后查阅。
1. 信息检索的布尔模型
用0和1表示某个词是否出现在文档中。如下图例子,要回答“Brutus AND Caesar but NOT Calpurnia”,我们需要对词的向量做布尔运算,即110100 AND 110111 AND 101111=100100 对应的文档是Antony and Cleopatra和Hamlet

然而这种方法随着数据的增大是非常耗费空间的。比如我们有100万个文档,每个文档平均有1000字,总共有50万个不同的词语,那么矩阵将是500 000 x 1 000 000。这个矩阵是稀疏的,1的个数一般不会超过1亿个。
2. 倒排索引
倒排索引是为了解决上述布尔模型的问题。具体来说,每个词用链表顺序存储文档编号。如下图所示:
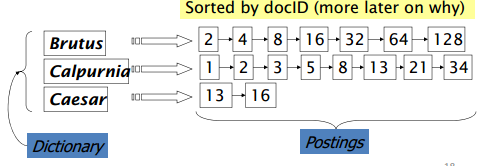
建立索引的核心是将词按字母顺序排列,合并重复词,但是要记录词频。
3. 倒排索引模型中对查询语句(AND)的处理
1、求Brutus AND Calpurnia,即求两个链表的交集。

算法思路是如果文档号不同就移动较小的指针,伪代码 INTERSECTION(p1, p2):
answer<-() while p1 != NIL and p2 != NIL do if docID(p1) = docID(p2) then ADD(answer, docID(p1)) p1 <-next(p1) p2 <-next(p2) else if docID(p1) < docID(p2) p1 <-next(p1) else p2<-next(p2) return answer
思考题,有两个词项A,B,其文档编号链表长度分别为3和5,那么对A,B求交集,最少的访问次数和最多的访问次数分别是多少?各举一个例子
最少访问次数是4,比如A:1-2-3,B:3-4-5-6-7;最多访问次数是8,比如A:1-7-8, B:3-4-5-7-9
2、思考题:求Brutus OR Calpurnia,即求两个链表的并集。伪代码 UNION(p1,p2):
answer<-() while p1 != NIL and p2 != NIL do if docID(p1) = docID(p2) then ADD(answer, docID(p1)) p1 <-next(p1) p2 <-next(p2) else if docID(p1) < docID(p2) then ADD(answer, docID(p1)) p1<-next(p1) else ADD(answer, docID(p2)) p2<-next(p2) return answer
3、思考题:求Brutus AND NOT Calpurnia。伪代码 INTERSECTION(p1,p2, AND NOT):
answer<-() while p1 != NIL and p2 != NIL do if docID(p1) = docID(p2) p1 <-next(p1) p2 <-next(p2) else if docID(p1) < docID(p2) then ADD(answer, docID(p1)) p1<-next(p1) else p2<-next(p2) if p1 != NIL and P2 = NIL then ADD(answer, docID(p1)) p1<-next(p1) return answer
参考资料:http://www1.se.cuhk.edu.hk/~seem5680/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号