R语言实战学习笔记-基本数据管理
本文主要介绍基本的数据处理,设计以下内容:1.变量的创建 2.缺失值处理 3.日期处理 4.数据的类型转换 5.数据排序、合并、取子集 6.SQL中取数据框
1.变量创建
#创建数据框
manager<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","UK","UK","US","UK")
gender<-c("M","F","F","M","F")
age<-c(32,45,25,39,99)
q1<-c(5,3,3,3,2)
q2<-c(4,5,5,3,2)
q3<-c(5,2,5,4,1)
q4<-c(5,5,5,NA,2)
q5<-c(5,5,2,NA,1)
leadership<-data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors=FALSE)
print(leadership)
#数据结果
manager date country gender age q1 q2 q3 q4 q5
1 1 10/24/08 US M 32 5 4 5 5 5
2 2 10/28/08 UK F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 US M 39 3 3 4 NA NA
5 5 5/1/09 UK F 99 2 2 1 2 1
创建变量的方式:
变量<-表达式
#例子:
a<-c(1,2,4)
变量的运算符:

#数据计算
mydata<-data.frame(x1<-c(2,2,6,4),x2<-c(3,4,2,8))
print(mydata)
#方法1
mydata$sumx<-mydata$x1+mydata$x2
mydata$meanx<-(mydata$x1+mydata$x2)/2
#方法2
attach(mydata)
mydata$sumx<-x1+x2
mydata$meanx<-(x1+x2)/2
print(mydata)
detach(mydata)
#方法3
mydata<-transform(mydata,sumx=x1+x2,meanx=(x1+x2)/2)
#原始数据
x1....c.2..2..6..4. x2....c.3..4..2..8.
1 2 3
2 2 4
3 6 2
4 4 8
#处理后数据
x1....c.2..2..6..4. x2....c.3..4..2..8. sumx meanx
1 2 3 5 2.5
2 2 4 6 3.0
3 6 2 8 4.0
4 4 8 12 6.0
变量的重编码
例如:
- 将一个连续型变量修正为一组类别值
- 将误编码的值替换为正确值
- 基于一个分数线创建一个及格、不及格的变量
逻辑运算符号:
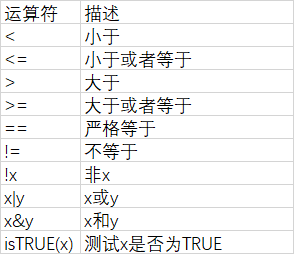
#重编码
manager<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","UK","UK","US","UK")
gender<-c("M","F","F","M","F")
age<-c(32,45,25,39,99)
q1<-c(5,3,3,3,2)
q2<-c(4,5,5,3,2)
q3<-c(5,2,5,4,1)
q4<-c(5,5,5,NA,2)
q5<-c(5,5,2,NA,1)
leadership<-data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors=FALSE)
#将99重编码为缺失值
leadership$age[leadership$age==99]<-NA
#分年龄阶段
leadership$agecat[leadership$age>75] <-"Elder"
leadership$agecat[leadership$age>55&leadership$age<=75]<-"Middle Aged"
leadership$agecat[leadership$age<=55]<-"Young"
#输出结果
manager date country gender age q1 q2 q3 q4 q5 agecat
1 1 10/24/08 US M 32 5 4 5 5 5 Young
2 2 10/28/08 UK F 45 3 5 2 5 5 Young
3 3 10/1/08 UK F 25 3 5 5 5 2 Young
4 4 10/12/08 US M 39 3 3 4 NA NA Young
5 5 5/1/09 UK F NA 2 2 1 2 1 <NA>
变量的重命名
#方法1
fix(leadership)
#方法2
names(leadership)[2]<-"TestData"
#方法3
#加载plyr
rename(dataframe,c(oldname1="newname1",oldname2="newname2",……)
2.缺失值处理
#检查是否为缺失值
is.na()
y<-c(1,2,3,NA)
print(is.na(y))
#输出结果
[1] FALSE FALSE FALSE FALSE TRUE
#确定是否为无穷大
is.infinite(Inf)
[1] TRUE
#判断是否为非数
is.nan()
is.nan(NaN)
[1] TRUE
#重编码缺失值
leadership$age[leadership$age==99]<-NA
#排除缺失值
x<-c(1,2,3,NA)
y<-sum(x)
print(y)
[1] NA
#排除了缺失值
y1<-sum(x,na.rm=TRUE)
print(y1)
[1] 6
3.日期处理
将数值转换成日期格式的方式:
#将数值型变量转换成日期变量
mydates<-as.Date(c("2017-06-22","2004-02-13"))
print(mydates)
#读取系统时间
print(Sys.Date())
[1] "2018-04-17"
print(date())
[1] "Tue Apr 17 21:16:18 2018"
#指定日期输入格式
today<-Sys.Date()
format(today,format="%B %d %Y")
#计算日期之间天数间隔
startDate<-as.Date("2004-02-13")
endDate<-as.Date("2011-01-22")
days<-endDate-startDate
print(days)
#输出结果
Time difference of 2535 days
#as.Date()格式化读入日期的格式,format()格式化输出日期格式
4.字符串的类型转换
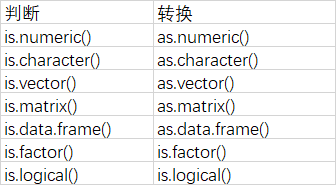
a<-c(1,2,3)
print(a)
[1] 1 2 3
#判断数据类型
is.numeric(a)
[1] TRUE
is.vector(a)
[1] TRUE
#转换成字符串
a<-as.character(a)
[1] "1" "2" "3"
#判断类型
is.numeric(a)
[1] FALSE
is.vector(a)
[1] TRUE
is.character(a)
[1] TRUE
5.数据排序、合并、取子集
manager<-c(1,2,3,4,5)
date<-c("10/24/08","10/28/08","10/1/08","10/12/08","5/1/09")
country<-c("US","UK","UK","US","UK")
gender<-c("M","F","F","M","F")
age<-c(32,45,25,39,99)
q1<-c(5,3,3,3,2)
q2<-c(4,5,5,3,2)
q3<-c(5,2,5,4,1)
q4<-c(5,5,5,NA,2)
q5<-c(5,5,2,NA,1)
leadership<-data.frame(manager,date,country,gender,age,q1,q2,q3,q4,q5,stringsAsFactors=FALSE)
#按照年纪升序排序
newdata<-leadership[order(leadership$age),]
print(newdata)
#按照女性到男性、年纪升序排列
attach(leadership)
newdata<-leadership[order(gender,age),]
print(newdata)
#输出结果
manager date country gender age q1 q2 q3 q4 q5
3 3 10/1/08 UK F 25 3 5 5 5 2
2 2 10/28/08 UK F 45 3 5 2 5 5
5 5 5/1/09 UK F 99 2 2 1 2 1
1 1 10/24/08 US M 32 5 4 5 5 5
4 4 10/12/08 US M 39 3 3 4 NA NA
#按照女性到男性、年纪降序排列
attach(leadership)
newdata<-leadership[order(gender,-age),]
print(newdata)
5 5 5/1/09 UK F 99 2 2 1 2 1
2 2 10/28/08 UK F 45 3 5 2 5 5
3 3 10/1/08 UK F 25 3 5 5 5 2
4 4 10/12/08 US M 39 3 3 4 NA NA
1 1 10/24/08 US M 32 5 4 5 5 5
数据的合并:数据框中增加列(变量)和行(观测)的方法
#两个数据框通过一个或者多个变量进行联结(inner join)
total<-merge(dataframeA,dataframeB,by="ID")
total<-merge(dataframeA,dataframeB,by=c("ID","Country"))
#横向合并,不需要一个公共索引
total<-cbind(A,B)
#数据框中添加行
#必须有相同的变量
#合并有两种处理方式
#1.删除dataframeA中多余的变量
#2.在dataframeB中创建追加的变量并将其设置为NA(缺失)
total<-rbind(dataframeA,dataframeB)
#取数据子集
newdata<-leadership[,c(6:10)]
#从数据框中取,q1,q2,q3,q4,q5,并将他们保存在newdata中。(,)表示默认选择所有的行
myvars<-c("q1","q2","q3","q4","q5")
newdata<-leadership[myvars]
#用paste()函数取值
myvars<-paste("q",1:5,sep="")
newdata<-leadership[myvars]
删除数据
#删除变量
myvars<-names(leadership) %in% c("q3","q4")
newdata<-leadership[!myvars]
#names(leadership)生成了一个包含所有变量名的字符串逻辑变量,c("managerID","testData","country","gender","age","q1","q2","q3","q4","q5")
#names(leadership) %in% c("q3","q4")返回一个逻辑型向量,names(leadership)中每一个匹配q3或者q4元素的值为TRUE,反之为FALSE
#运算!将逻辑值反转:c(TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,FALSE,FALSE,TRUE)
#leadership[c(TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,FALSE,FALSE,TRUE)]选择逻辑值为TRUE的,删除q3,q4的
#如果知道要删除的变量的位置,可以用如下函数:
newdata<-leadership[c(-8,-9)]
选取观测值
#选择前三行
newdata<-leadership[1:3,]
#选择性别为男,年纪大于30的
newdata<-leadership[leadership$gender=="M"&leadership$age>30,]
#选择时间区间的变量
leadership$date<-as.Date(leadership$date,"%m/%d/%y")
startdate<-as.Date("2009-01-01")
enddate<-as.Date("2009-10-31")
newdata<-leadership[which(leadership$date>=startdate&leadership$date<=enddate),]
快速选择观测值方法
#选择所有age大于等于35或者小于24的行,保留了变量q1到q4的值
newdate<-subset(leadership,age>=35|age<24,selct=c(q1,q2,q3,q4))
#选择所有25以上的男性,并保留了变量gender到q4的所有列
newdate<-suset(leadership,gender=="M"&age>25,select=gender:q4)
#随机抽样
mysample<-leadership[sample(1:nrow(leadership),3,replace=FALSE),]
#第一个参数,1到数据框中观测的数量,第二个是选取的元素数量,第三个表示是无放回抽样
6.利用SQL获取数据框
library('RODBC')
#建立连接
channel<-odbcConnect("ODBC名称",uid="用户名",pwd="密码")
mydate<-sqlQuery(channel,"select * from datajobinfo")
is.data.frame(mydate)
[1] TRUE
#关闭连接
odbcClose(channel)
以上为基本数据管理方法介绍,下一篇文章学习高级管理方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号