Redis中篇--应用
Redis中篇--应用
上篇看这里:Redis上篇
csdn地址:https://blog.csdn.net/okok__TXF/article/details/148538138
微信公众号:https://mp.weixin.qq.com/s/aQUfCQ6OEEdF27V285A2LA
本文示例代码见GITEE仓库中的【redis-analysis】
地址:https://gitee.com/quercus-sp204/new-technology/tree/master/redis-analysis
1. 缓存问题
Redis作为缓存的时候,会发生一些经典问题。下面就来分析一下:
1.1 缓存击穿
缓存击穿是指一个访问量非常大(热点)的缓存 Key,在它过期失效(Expire)的瞬间,大量并发的请求同时发现缓存失效(Cache Miss),这些请求会击穿缓存层,直接去查询底层数据库(如 MySQL)。这会导致数据库在极短时间内承受巨大的、远超其处理能力的请求压力,可能导致数据库响应变慢、连接耗尽甚至崩溃,进而引发整个系统的连锁故障。
举个例子,就比如仓库门口堆放的一件特别抢手的热门商品刚好卖完(缓存失效),一大群等着买它的人瞬间冲进仓库抢购,把仓库管理员(DB)累垮了。
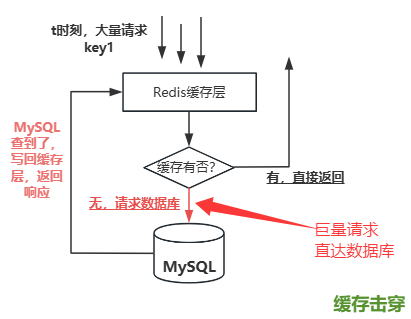
那么,我们可以总结出这个缓存问题的特征:
首先,它是针对单个 Key 问题集中在某一个特定的热点 Key 上, 这个 Key 对应的数据访问频率非常高;
然后呢,时机发生在在过期瞬间,在该 Key 设置的过期时间刚好到达的那一刻,这个时刻有高并发请求,同时这个时刻请求全打到数据库了;
我们就要防止在缓存失效瞬间,大量请求同时访问数据库。那么我们该怎么解决呢?
- 方法一:互斥锁
该方法的核心思想:既然是大量请求都直接访问数据库了,那我就在数据库那一层加锁,保证同一时刻只有一个线程访问,这样就减轻数据库的压力。
双检锁
// 缓存击穿,解决方式1---双检锁
public Goods getGoodsDetailById(String goodsId) {
// 1.先从缓存里面查
Goods goodsObj = (Goods) valueOperations.get(RedisKey.GOODS_KEY + goodsId);
// 2.缓存没有再查数据库
if (goodsObj == null) {
synchronized ( goodsId.intern() ) {
goodsObj = (Goods) valueOperations.get(RedisKey.GOODS_KEY + goodsId);
}
if (goodsObj != null) {
return goodsObj;
}
Goods goods = getDbGoodsById(goodsId);
if (goods != null) {
valueOperations.set(RedisKey.GOODS_KEY + goodsId, goods);
return goods;
}
return null;
}
return goodsObj;
}
加锁检查缓存(第一次检查):当用户请求数据时,首先检查缓存中是否存在该数据。
加锁:如果缓存中没有数据,那么走DB。但是,在尝试从数据库查询数据之前,使用本地锁(或者分布式锁)来确保只有一个请求能够执行数据库查询操作。
数据库查询:如果成功获取到锁,那么第二次检查缓存,如果确实缓存中没有数据, 执行数据库查询操作,获取最新的数据。
更新缓存:将查询到的数据写入缓存,并设置一个合理的过期时间。
释放锁:完成缓存更新后,释放分布式锁,以便其他请求可以继续执行。
返回数据:将查询到的数据返回给用户。
处理其他请求:对于在等待锁释放期间到达的请求,它们可以直接从缓存中获取数据,而不需要再次查询数据库。
上面的问题也很明显,那就是假如查数据库,写入缓存这俩步骤,如果耗时过长,前面的请求会被一直阻塞住的。治标不治本哪
- 方法二:key不过期
【永不过期】设置key的时候,不让其过期,由于是永不过期的,故需要考虑更新这个key的值;
【逻辑过期】缓存 Key 不设置过期时间(或设置一个很长的过期时间),让其“永不过期”。但是我们可以在缓存 Value 中,额外存储一个逻辑过期时间戳(例如 {value: obj, expireTime: 12345678910}),当应用读取缓存时,检查 Value 中的逻辑过期时间戳,如果未过期,直接返回数据;如果已过期,触发一个异步任务(如放入消息队列、启动一个线程池任务都可以)去更新缓存。当前请求可以直接返回已过期的旧数据(业务允许短暂不一致)或尝试获取互斥锁进行同步更新(类似方法 1)。
此方法缓存 Key 永不失效,彻底避免“失效瞬间”的问题,用户请求基本不受缓存更新影响,延迟低(直接返回旧数据或触发异步更新)。
但是问题也是非常的明显:首先就是业务要容忍数据的不一致性;需要实现异步更新机制(消息队列、线程池),增加了设计的复杂性;其次呢,如果异步更新失败或延迟过大,用户可能长时间读到旧数据;
- 方法三:热点key探测,提前刷新
在缓存热点 Key 即将过期之前(比如还剩 1 分钟时),主动触发一个后台任务(定时任务、监控线程)去查询数据库并更新缓存,重置其 TTL。这种方式看起来算是完美的,但是丢给了我们一个致命问题,那就是哪些key是热点key?
1.1.1 hotKey问题
首先我们要明白一点,HotKey是什么,如何定义HotKey?
HotKey指的是 Redis 缓存中被高频访问的键,这类键的访问量远高于其他普通键。这类键称之为“热键”。
比如说,秒杀模块中,可能会将商品信息缓存在Redis中,那么,某些商品的skuId可能作为key,在秒杀这段时间里面,这类key的访问量可能会明显高于其他键;此外呢,如果有人恶意访问缓存,发送大量请求到指定key,也可能导致该key变成热键;还有像新闻网站上的突发新闻、论坛的热点文章帖子等等.......
如果这个时候这个热键过期了,就会造成缓存击穿的问题,巨量请求直接到达了MySQL数据库层,很有可能会造成服务的不可用。
如何去监测这些热key呢,出现了热key问题,该怎么办?或者说,我们要如何去预防这类问题的出现?
我认为可以由以下几步结合起来,给他来一套组合拳:
- 系统功能设计之初,凭借经验判断可能的热key:
我丢?这种方法是可以说的吗?肯定可以啊,就好比说烂了的秒杀系统,肯定就可以比较容易判断出哪些key可能变成热key了吧,电商系统中的商品详情页、或者是新上的活动促销、社交平台上的热门帖子等数据通常容易成为热点Key。
- Redis客户端代码层面增加访问次数记录:
在Redis客户端层面,我们手动记录key的访问次数、或者是xxx时间间隔的访问频率,如果有监控系统,我们可以将这类数据定时或者实时上报的监控系统,然后就可以在监控系统看到了;
- 在Redis服务端:
它本身提供了相应的功能:执行一些相关命令(如MONITOR、redis-cli --hotkeys等),通过分析这些命令,可以观察到哪些Key被频繁访问,识别出热点Key。
MONITOR 命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。由于该命令对 Redis 性能的影响比较大,被逼到墙角的时候,我们可以暂时使用这个命令,得到其输出之后,关闭它,然后对其输出归类分析。
同理,--hotkeys也会增加 Redis 实例的 CPU 和内存消耗(全局扫描),因此需要谨慎使用
- 【无意之间,我在GITEE上看asyncTool的时候,在其主页翻到了京东零售的热点数据监测】
它的hotKey项目:这个就交给读者自行查看了。
上面好像说的都是监测key,检测到了能怎么办呢?
在单服务器承受范围之内,我们可以结合本节开始前的方法三,如果设置了过期时间,可以刷新其过期时间,可以避免缓存击穿的问题了哇。
在单个服务器承受范围之外: 这就涉及到Redis主从架构等等问题了,本文不做探讨。
- 如果是用 : redis 主从架构,可以通过增加Redis集群中的从节点,增加 多个读的副本。通过对读流量进行 负载均衡, 将读流量 分散到更多的从节点 上,减轻单个节点的压力。【节选一下参考1的话】
- 通过改变Key的结构(如添加随机前缀),将同一个热点Key拆分成多个Key,使其分布在不同的Redis节点上,从而避免所有流量集中在一个节点上。【节选一下参考1的话】
1.2 缓存穿透
缓存穿透是指查询的数据既不在缓存中,也不在数据库中,但恶意或异常请求持续访问,导致每次请求都直接穿透到数据库的现象。这会显著增加数据库压力,甚至引发系统崩溃。

这种缓存问题和缓存击穿有点像,但是它的特征是请求的Key在缓存和数据库中均不存在(如恶意构造的非法ID:id=-1或id=99999999)。
缓存穿透:数据根本不存在(缓存和数据库均无)。
缓存击穿:数据存在但缓存失效(数据库中有数据)。【热点key问题】
那么,缓存穿透我们该怎么解决呢?
- 方法一:缓存空值
这个很容易就想到了,但是为了避免缓存被长时间占用,需要给这个空值加一个比较短的过期时间,例如几分钟。
假如有大量无效请求穿透过来时,缓存内就会有 大量的空值缓存。
所以,我们针对这种接口,我认为可以在查询缓存之前,判断那种必定无效参数,直接将无效参数的请求给过滤掉,比如说:数据库中id都是正数,但是传过来的id是个负数,我们就可以将这种请求直接过滤掉了,等等。但是,这个措施也仅仅能起到一丢丢作用罢了。【请求层拦截过滤一下】
那么有什么办法可以避免缓存大量的空value呢?
- 方法二:布隆过滤器
布隆过滤器的介绍见这篇文章:【分分钟搞懂布隆过滤器】
地址:https://mp.weixin.qq.com/s/PmJ8nMFbxJ1qI3hGt8s9lw
我们可以在查询缓存前,先走一遍布隆过滤器,如果布隆过滤器说不存在该key,则一定不存在;反之,则可能存在。
但是,我们需要预先将数据库中的key加载到布隆过滤器中去。这就引出了另一个问题:那就是数据库中key和布隆过滤器中的一致性问题。
下面给出布隆过滤器的简单例子:
// 首先使用Redisson创建一个商品goods的布隆过滤器
@Bean("goodsBloomFilter")
public RBloomFilter<Object> bloomFilter() {
RBloomFilter<Object> goodsBloomFilter = redissonClient.getBloomFilter("goodsBloomFilter");
goodsBloomFilter.tryInit(expectedInsertions, fpp);
// 初始化布隆过滤器
List<Goods> goods = Goods.goods;
for (Goods good : goods) {
goodsBloomFilter.add(good.getGoodsId());
}
return goodsBloomFilter;
}
// 2.缓存穿透,解决方式 -- 布隆过滤器【本方法只用于解决缓存穿透的问题】
// 实际肯定也要考虑缓存击穿的。
public Goods getGoodsDetailById_cacheThrough(String goodsId) {
boolean contains = goodsBloomFilter.contains(goodsId);
if (contains) {
// 先到缓存里面找
Goods goodsObj = (Goods) valueOperations.get(RedisKey.GOODS_KEY + goodsId);
if (goodsObj != null) return goodsObj;
// 如果找不到
Goods goods = getDbGoodsById(goodsId);
if (goods != null) {
valueOperations.set(RedisKey.GOODS_KEY + goodsId, goods);
return goods;
}
return null;
} else {
return null;
}
}
看过上面给的链接里面的文章,想必大家也知道问题所在:那就是其存在误判率(可通过增加哈希函数降低),同时呢需要我们定期更新合法Key集;
现在,我们来对比一下:
| 方案 | 适用场景 | 注意事项 |
|---|---|---|
| 缓存空值 | 动态生成的Key或临时数据 | 设置短TTL,避免内存浪费 |
| 请求层拦截 | 所有场景的初级防御 | 结合参数校验与限流机制 |
| 布隆过滤器 | 海量合法Key已知的场景(如商品ID) | 需定期更新Key集合,控制误判率 |
综上呢,我们可以组合一下这些方案,形成一个比较有效的解决方案

如果误判了,怎么办呢?
1.3 缓存雪崩
缓存雪崩是指因大量缓存数据在同一时间集中失效或缓存服务崩溃,导致海量请求直接涌向数据库,引发数据库瞬时压力激增、系统性能骤降甚至崩溃的现象。这些 Key 的大量并发请求,瞬间全部穿透缓存层,直接涌向底层数据库(如 MySQL)。
与前两个问题比对一下,可以发现其特征:涉及大量缓存 Key(可能是几十、几百、甚至成千上万),而非单个 Key;这些 Key 的失效时间点非常集中(例如,在同一秒、同一分钟内);在失效发生的时刻,恰好有对这些 Key 的正常业务请求(通常量很大)。主要还是同一时间过期key的数量太多了。
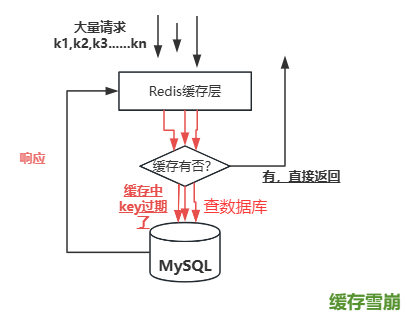
它的成因:
【设置相同的过期时间(TTL)】: 这是最常见的原因。在初始化缓存数据或在批量更新缓存时,为大量 Key 设置了完全相同的 TTL(例如,都设为 24 小时)。当 24 小时后,这些 Key 同时失效。又或者是在每天凌晨执行批量缓存刷新任务,刷新后新 Key 的 TTL 相同。
【缓存服务灾难性故障:】Redis 集群宕机: 主节点宕机且未成功切换从节点,或哨兵/集群模式本身出现故障。网络分区: 导致应用服务器无法连接 Redis 集群。大范围重启/升级: 运维操作导致整个 Redis 集群或大部分节点不可用。
问题不能完全解决,我们只能尽可能的去预防这些问题的产生:
首先在key层面,采用过期时间随机化:这个例子就不举了吧,设置缓存的时候,将TTL给它Random,如果想要更随机,可以网上找一些均匀的随机算法,然后自己diy一下就好了。对相当核心、容易预测的key数据可采用 永不过期+异步刷新。
其次呢,可以在Redis层面,搭建高可用的集群,来预防基础设施故障;
在缓存层面,我们可以构建多级缓存来提升韧性: 对于性能要求极高、存在极端热点的系统,考虑引入本地缓存(caffeine)构建多级缓存,能有效抵御 Redis 层雪崩对数据库的冲击。但是需解决一致性问题。
最后可以来一个兜底措施:比如说熔断降级 ,来防止数据库崩溃和雪崩扩散;服务限流 来控制流量洪峰、从而也可以保护数据库。
综合比较一下上面所说的/缓存三个主要的问题:
- 缓存击穿: 单个热点 Key 失效瞬间遭遇 高并发。关键:单个热点 Key 失效 + 高并发。仓库门口堆放的一件特别抢手的热门商品刚好卖完(缓存失效),一大群等着买它的人瞬间冲进仓库抢购,把仓库管理员(DB)累垮了。其他商品还能正常在门口买。
- 缓存穿透: 查询 数据库中根本不存在 的数据。关键:数据不存在。 请求必定穿透缓存访问 DB。你要找的东西压根不存在于仓库(DB)里,每次都得翻遍仓库确认没有。仓库管理员(DB)每次都得白忙活一趟。不管门口有没有货架(缓存),都得进仓库。
- 缓存雪崩: 大量 Key 同时失效 或 Redis 集群整体不可用。关键:大规模失效 + 高并发。仓库门口堆放的很多常用物品(缓存)在同一时间被清空了(同时失效),所有人(请求)涌进仓库(数据库)找东西,把仓库挤爆了,并且因为仓库瘫痪,导致整个商场(系统)停摆。
雪崩就像一场雪,击穿就像这场雪里面的一片雪花。
2. 其他实战
2.1 排行榜
Redis 的 ZSET 天然支持按分值(Score)排序,完美契合排行榜需求,下面我们来模拟一下文章阅读量前十排行榜,结合Redis实现的:
Key 设计:article_ranking(存储文章阅读量排行)
成员(Member):文章标题(如 article:钢铁是怎样炼成的!),也可以放文章ID,查出前十文章ID之后,然后通过id查询文章。
分值(Score):文章阅读量(整数类型)
见如下代码:
@RequestMapping("/other")
@RestController
public class OtherController {
@Resource
private ZSetOperations<String, Object> zSetOperations;
// 1.访问文章
@GetMapping("/accessArticle")
public R accessArticle() {
// 假设有30篇文章
List<Integer> list = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30);
// 模拟100个用户访问文章
Random random = new Random();
for ( int i = 0; i < 100; ++i ) {
// 生成1-30随机数
int index = random.nextInt(list.size());
// 文章访问数加一
zSetOperations.incrementScore(RedisKey.ARTICLE_RANK_KEY, list.get(index), 1);
}
return R.success("访问ok!");
}
}
// 1.排行榜
@GetMapping("/rankingList")
public R rankingList() {
// 获取前十
Set<Object> range = zSetOperations.range(RedisKey.ARTICLE_RANK_KEY, 0, 9);
if (range == null) {
return R.fail("没有数据!");
}
String str;
for (Object o : range) {
str = o.toString();
String[] split = str.split(":");
System.out.println("文章ID或者标题:" + split[1]); // 这里可以根据id去数据库查具体文章
}
return R.success().setData("rankingList", range);
}
优化点:如果文章过多的话,比如说member达到了数以万计乃至十万计,我们可以选择仅保留 Top N 文章:定期清理非热门文章(如只保留前 1000 名)
ZREMRANGEBYRANK article_ranking 1000 -1 # 删除1000名后的成员
2.2 附近商家
Redis实现附近的商家功能。这个问题在LBS(基于位置的服务)应用中非常常见,比如外卖、打车、社交等场景都需要查找附近的服务点。Redis的GEO模块是解决这类问题的核心工具,它在3.2版本后被引入。我们可以将商家的经纬度实现导入Redis,然后就可以实现这个功能了。
如下代码:读者们可以去这里转换经纬度:http://jingweidu.757dy.com/
鄂州市经纬度: 114.895003, 30.390893
石家庄:114.515000,38.042401
public class Shop {
private String shopId;
private String shopName;
private Double longitude; // 经度
private Double latitude; // 纬度
public static final List<Shop> shops = new ArrayList<>();
static {
// 模拟导入11个城市的经纬度
shops.add(new Shop("1", "上海乡村基", 121.48, 31.22));
shops.add(new Shop("2", "北京乡村基", 116.46, 39.92));
shops.add(new Shop("3", "广州乡村基", 113.27, 23.13));
shops.add(new Shop("4", "深圳乡村基", 114.07, 22.62));
shops.add(new Shop("5", "杭州乡村基", 120.19, 30.26));
shops.add(new Shop("6", "南京乡村基", 118.78, 32.04));
shops.add(new Shop("7", "西安乡村基", 108.95, 34.27));
shops.add(new Shop("8", "武汉乡村基", 114.31, 30.52));
shops.add(new Shop("9", "长沙乡村基", 113.01, 28.21));
shops.add(new Shop("10", "苏州店肯德基", 120.62, 31.32));
shops.add(new Shop("11", "天津店肯德基", 117.2, 39.13));
}
}
@GetMapping("/importLAL")
public R importLAL() {
List<Shop> shops = Shop.shops;
for (Shop shop : shops) {
redisTemplate.opsForGeo().add(RedisKey.SHOP_KEY, new Point(shop.getLongitude(), shop.getLatitude()), shop.getShopName());
}
return R.success("导入成功!");
}
// 查询附近
@GetMapping("/nearbyShop")
public R nearbyShop(@RequestParam("longitude") Double longitude, @RequestParam("latitude") Double latitude) {
// =========1.获取指定成员的地理位置
//List<Point> position = redisTemplate.opsForGeo().position(RedisKey.SHOP_KEY, "上海乡村基");
// =========2.distance:计算两个成员之间的距离(默认以米为单位)
//Distance distance = redisTemplate.opsForGeo().distance(RedisKey.SHOP_KEY, "上海乡村基", "北京乡村基");
//double distanceInKm = distance.getValue() / 1000;
// =========3.radiusByMember:根据给定的成员,返回与该成员距离在指定范围内的其他成员(按距离由近到远排序)
// =========4.radius:根据给定的中心点,返回与中心点距离在指定范围内的成员(按距离由近到远排序)
// 构建中心点
Point center = new Point(longitude, latitude);
// 构建圆形搜索区域
Circle circle = new Circle(center, new Distance(1000, Metrics.KILOMETERS));
// 构建搜索参数
RedisGeoCommands.GeoRadiusCommandArgs args = RedisGeoCommands.GeoRadiusCommandArgs
.newGeoRadiusArgs()
.includeDistance() // 返回距离
.includeCoordinates() // 返回坐标
.sortAscending() // 按距离升序
.limit(15); // 限制数量
// 执行搜索
GeoResults<RedisGeoCommands.GeoLocation<Object>> results = redisTemplate.opsForGeo().radius(RedisKey.SHOP_KEY, circle, args);
if (results == null) return R.fail("没有!");
List<NearbyPlace> places = results.getContent().stream()
.map(result -> {
RedisGeoCommands.GeoLocation<Object> location = result.getContent();
Distance dist = result.getDistance();
Point pos = location.getPoint();
return new NearbyPlace(
location.getName().toString(),
pos.getX(), pos.getY(),
dist.getValue(),
dist.getUnit()
);
}).toList();
// 可以在这里对结果处理一下,比如说从数据库查一下该店铺的评分、评价之类的,等等
return R.success().setData("places", places);
}
优化点:同理哦,如果商家巨多,都在同一个key里面可能会出现大key问题,我们可以考虑给商家按照区域划分到不同的key,这算是一种优化方案。
2.3 签到
Redis实现签到功能的核心是使用位图(BitMap)数据结构。用户签到记录可以按用户ID+月份作为Key,日期作为偏移量,签到状态用0/1表示,这种设计非常节省空间,100万用户一年的签到数据才43MB左右。
具体实现上,签到操作使用SETBIT命令,查询是否签到用GETBIT,统计当月签到次数用BITCOUNT,获取连续签到天数则通过BITFIELD获取位图数据后做位运算。
具体代码如下:
// 模拟用户签到
@PostMapping("/mockSign")
public R signIn() {
// 这里以六月举例子,模拟6月1日-6月30日
// 有十个用户
for (int i = 1; i <= 10; ++i ) {
String key = RedisKey.SIGN_IN_KEY + ":" + i + ":202506";
// 30天中随机20天签到
for (int j = 0; j < 20; ++j) {
int day = (int) (Math.random() * 30) + 1;
redisTemplate.opsForValue().setBit(key, day, true);
}
}
return R.success();
}
// 获取用户的签到日历
@GetMapping("/signInCalendar")
public R signInCalendar() {
// 获取当前日期
LocalDate now = LocalDate.now();
// 当前月有多少天
int daysInMonth = now.lengthOfMonth();
// 获取用户的签到日历
List<SignCalendar> calendars = new ArrayList<>();
for (int i = 1; i <= 10; ++i) { // 遍历这十位用户
String key = RedisKey.SIGN_IN_KEY + ":" + i + ":202506"; // key
SignCalendar calendar = new SignCalendar(i, new ArrayList<>());
for (int j = 1; j <= daysInMonth; ++j) { // 判断每一天
SignCalendarDay day = new SignCalendarDay(2025, now.getMonthValue(), j, false);
int offset = j - 1;
Boolean sign = redisTemplate.opsForValue().getBit(key, offset);
day.setSign(sign);
calendar.addDaySign(day);
}
calendars.add(calendar);
}
System.out.println(calendars);
return R.success().setData("calendars", calendars);
}
具体详情请看仓库项目。
2.4 网站uv统计
独立用户访问量Unique Visitor。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
示例请看如下代码:
@GetMapping("/mockAccess")
public R webUv() {
String[] keys = buildKey();
// 记录访问-- 模拟1000个用户访问
List<Integer> uids = new ArrayList<>();
for (int i = 0; i < 1000000; ++i) uids.add( i);
// uids.forEach(uid -> {
// redisTemplate.opsForHyperLogLog().add(keys[0], uid);
// redisTemplate.opsForHyperLogLog().add(keys[1], uid);
// redisTemplate.opsForHyperLogLog().add(keys[2], uid);
// });
redisTemplate.opsForHyperLogLog().add(keys[0], uids.toArray());
redisTemplate.opsForHyperLogLog().add(keys[1], uids.toArray());
redisTemplate.opsForHyperLogLog().add(keys[2], uids.toArray());
return R.success();
}
@GetMapping("/webUv")
public R webUv() {
String[] keys = buildKey();
Long day = redisTemplate.opsForHyperLogLog().size(keys[0]);
Long month = redisTemplate.opsForHyperLogLog().size(keys[1]);
Long year = redisTemplate.opsForHyperLogLog().size(keys[2]);
return R.success().setData("day", day)
.setData("month", month)
.setData("year", year);
}
我这里访问量测试了
{
"code": 200,
"data": {
"msg": "响应成功!",
"month": 1009972,
"year": 1009972,
"day": 1009972
}
}
占用内存连0.5MB都不到. 虽然访问量可能不是精准的,但是大差不差了。实际情况地话,这些key肯定是要定期清零的,比如说,月访问量,一个月过去了,肯定是需要重新统计的。
2.5 社交关系
利用Redis的集合(Set)数据结构来存储关注关系,每个用户用两个集合分别存储关注列表(following)和粉丝列表(followers),当用户A关注用户B时,系统会执行两条原子操作——把A加入B的粉丝集合,同时把B加入A的关注集合。
比如要查A和B的共同关注,只需对A的关注集合和B的关注集合取交集(SINTER命令),Redis集合运算的时间复杂度是O(N),百万级关系数据也能毫秒级响应,这种性能对社交场景至关重要。
但社交关系不只是关注功能,搜索结果还展示了更丰富的可能性:比如用有序集合(Sorted Set)存储关注时间,可以实现"最近关注"排序;用发布订阅(Pub/Sub)实现实时动态推送——当用户发帖时,系统会向所有粉丝的推送频道发布消息等等。
同时需要注意的是,如果网站中有大V,比如说有十万百万粉丝,同理又会出现大key问题,这个时候就要注意了,可以用粉丝ID的哈希值分桶,比如把1亿粉丝分散到100个分片集合中。
本文仅给出简单例子:
// 举例子
# 用户123 关注用户456
SADD following:123 456 # 123的关注列表加入456
SADD followers:456 123 # 456的粉丝列表加入123
具体情况见代码。
2.6 限流计数
见这篇文章:限流算法
地址:https://blog.csdn.net/okok__TXF/article/details/148048960
end. 参考
- https://mp.weixin.qq.com/s/d_JJuTGiN6Lspn0oyYxKFA 【阿里面试:缓存击穿、缓存穿透、缓存雪崩 3大问题,如何彻底解决?】
- https://mp.weixin.qq.com/s/Bt8yVVZ-F4H7KzJnZlwJMQ 【hotKey】
- https://mp.weixin.qq.com/s/PmJ8nMFbxJ1qI3hGt8s9lw 【布隆过滤器】
- https://mp.weixin.qq.com/s/HSQVnPW4aRdLP2jnTOFr4A 【分布式锁】
- https://www.runoob.com/redis/redis-hyperloglog.html 【菜鸟教程】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号