[2019.04]四月和五月练习 -- 正则表达式 65 篇解释
鸽子说每天都更新。下列表达式来自:https://www.jb51.net/article/77687.htm,作者:lijiao
练习推荐使用正则表达式测试网站:https://regex101.com/
忘记表达式某些字符含义可参考速查表:https://www.jb51.net/shouce/jquery1.82/regexp.html
感谢诸位大大的帮助!
一、校验数字的表达式
1 ^[0-9]*$
字符解释:^ 代表字符串开头,[0-9]规定匹配中可接受的字符范围,*表示0-任意个字符,$代表字符串结尾。
含义:只包含0~9的一个字符串。
2 ^\d{n}$
字符解释:\d == [0-9],{n}中的n应该替换成用户需要的值,代表匹配n次。
含义:n位数字。
3 ^\d{n,}$
字符解释:{n,m}中,缺少n表示不多于m个,缺少m表示不少于n个。
含义:n位以上数字。
4 ^\d{m,n}$
同上
5 ^(0|[1-9][0-9]*)$
字符解释:| 竖线表示或,[A][B]表示第一位用A规则匹配,第二位用B规则匹配。
含义:0或是任意长度非0开头的数字,换言之,≥0的整数。
6 ^([1-9][0-9]*)+(.[0-9]{1,2})?$ || ^([1-9][0-9]*)+(\.[0-9]{1,2})?$
警告:本例原帖可能有误,"."是匹配任意字符的关键字,应该用"\"转义!
字符解释:\. 匹配英文句点".",?是非贪婪匹配前面字符串匹配一次或零次(有没有都行)。
含义:正整数或正一位、两位小数。
备注:?只有在表示数量的修饰符后面紧跟着才表示非贪婪,比如此处如果要懒惰匹配应该用 "(\.[0-9]{1,2})??"
7 ^(\-)?\d+(\.\d{1,2})?$ || ^-?\d+(\.\d{1,2})?
警告:本例原帖可能不够简洁,常用语言中 "-" 短横线/减号 并不是需要转义的字符(除非在方括号中。如[1-2])
字符解释:\d 表示全体数字,相当于 [0-9];.原点一定要转义不然就变成匹配全字符了
含义:小数位数不多于2的一个正负数
8 ^(\-|\+)?\d+(\.\d+)?$ || ^(-|\+)?\d+(\.\d+)?$
字符解释:| -> “或”
含义:全体实数
9 ^[0-9]+(.[0-9]{2})?$ || ^\d+(\.\d{1,3})
警告:原帖没有转义"."并且不够简洁。
字符解释:略
含义: 有1-3位小数的正实数
10 ^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
警告: ^([1-9][0-9]*){1,3}$ 中的{1,3}没有意义 ^([1-9]\d*)$ 就可以。 ^\+?[1-9][0-9]*$ 是比较好的解决方案,不会因为多了 + 导致匹配失败。
字符解释:略
含义: 正整数
========
都是一样的内容,略过。
========
二、校验字符的表达式
1 ^[\u4e00-\u9fa5]{0,}$
字符解释:\u???? 使用UTF-8 编码格式,{0,}使用*可以更简单一些
含义: 全体汉字
2 ^[A-Za-z0-9]+$
字符解释:[...]方括号里面可以连着放很多东西,但是如果想要匹配方括号请使用 \ 转义字符!
含义: 一个以上的大小写字母和数字组成的字符串
3 ^.{3,20}$
字符解释:略
含义:长度为3-20的所有符号
4 ^\w+$ 或 ^\w{3,20}$
字符解释:\w 等同于 [A-Za-z0-9_]
含义:长度为3-20的由数字字母和下划线组成的字符串
5 [^%&',;=?$\x22]+
字符解释:\x 表示下面使用16进制的UTF编码,其实\x22就是",它并不需要转义或者利用UTF编码。^表示取补集,即指定的范围是不能匹配的范围。
含义:匹配不含有方括号内特殊字符[ ^%&',;=?$\" ]的字符串
三、特殊需求表达式
1 ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
建议修改:^[A-Za-z0-9]+([.\-_][A-Za-z0-9]+)*@[A-Za-z0-9\-]+(\.[A-Za-z0-9]+)+$
修改原因:原表达式在匹配 _开头或有连续特殊字符(-_.)的邮件地址时会出现误判。而且貌似修改后的版本匹配效率得到了提升。
设计理念:
①分段式设计:利用特殊字符划分区域,不要妄图使用一个匹配集合就匹配掉所有的内容,这样不仅导致出现误判,而且有可能造成灾难性回溯。这一条用黄色标注。
②避免范围过大的集合:避免出现一个判断集合能够判断太多字符,并且不要在同一组判断(指在同一个括号内的判断)里面出现重复的判断集,这样几乎100%产生灾难性回溯。这一条用红色标注
示例:判断“ADU5dX-532.dx_aerx@gcre..com.cn”的输入合法性
| ^[A-Za-z0-9]+([.\-_][A-Za-z0-9]+)*@[A-Za-z0-9\-]+(\.[A-Za-z0-9]+)+ 使用39次判断得出结论
| ^[A-Za-z0-9]+([\w.-][A-Za-z0-9]+)*@[A-Za-z0-9\-]+(\.[A-Za-z0-9]+)+ 使用930次判断得出结论,加粗部分重复了
| ^([A-Za-z0-9]+([\w.-]?[A-Za-z0-9]+)*)+@([\w-]+\.)+([A-Za-z0-9]+) 灾难性回溯,红色部分反复回溯
>什么是灾难性回溯:https://www.cnblogs.com/jackablack/p/10751914.html
2 [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.*?
解析:[域名必须用字母或数字开头] [后面可以用连字符]{最大长度62+1 = 63字符} ( \.匹配“.” [ 和前面意思 ] [一定不要忘记域名后面可能带着的东西,在 / 之后匹配任意内容]
在域名前面添加 http[s]?:// 可以匹配URL,当然也可以改造来匹配其他协议的URL
4 ^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
解析:没什么好解析的,就是 或 字符值得注意!
含义:电话号码
5 ^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
解析:
# 正向肯定预查:当字符串满足预查条件,从首个满足条件的字符处开始执行匹配。
上面给出的表达式的意思是:字符串从左到右来看需要包含至少一个数字和大小写字母,且长度在8~10之间。
分解来看:
①(?=.*\d):在任意个(包括零个)字符之后有一个数字;
②.{8,10}:任意个字符,8-10个。
含义:8~10个字符长度的,包含大小写字母、数字各至少一个的字符串
# 原文本来想要表达的是这是一个密码匹配逻辑,然而这样写只要有大小写字母加数字各一个的字符串都能匹配,比如:“1我是Ab字符串¿”
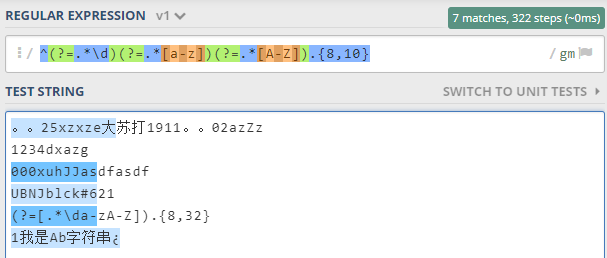
证据表明不是瞎说
所以我觉得可以改进成这样子:^(?=.*\d{3,})(?=.*[a-z])(?=.*[A-Z])(?=.*[.\-#*%$])[\w.\-#*%$]{8,32}$
含义是一个包含三个以上数字,大小写字母、特殊符号各一个,长度在8-32之间的由英文字母、数字和特殊符号构成的字符串
另外值得注意的是预查不可以合起来写哦,分开写时预查三次必须每次都通过才开始匹配,合起来写预查只进行一次,要么无法保证范围的限制,要么无法保证格式足够宽松,如下图所示:
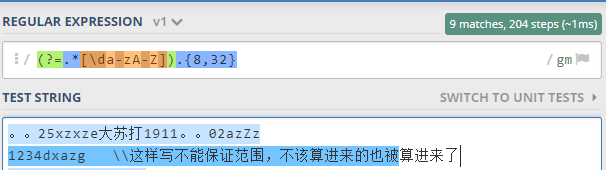
所谓的不能保证范围
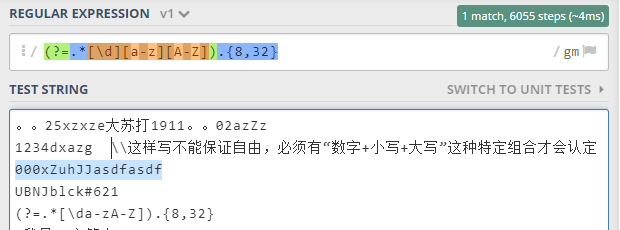
所谓的不能保证自由度
6 ^\d{4}-\d{1,2}-\d{1,2}
含义:日期,YYYY-MM-DD,由于日期具有特殊的进制,所以还是要用脚本来算一下是否真的时合法的
改进:^\d{4}-(0?[1-9]|1[0-2])-(([1-2][0-9])|30|31|(0?[1-9]))
上面的表达式就有一定的限制作用了,然而针对每个月究竟有几天还是没法做限制的,不然正则表达式就太长了。
值得注意的是,有底色的部分的顺序不可以颠倒,如果把(0?[1-9])这一部分提前到前面,就会导致优先匹配一位数, 1997-11-11 的匹配结果会变成 1997-11-11,最后一位1匹配不到,这一点也是原帖中14条的错误。
7 钱的输入格式:
原文絮絮叨叨说了一万行,其实只需要:
^[$¥]?[1-9]\d{0,2}(,?\d{3})*(\.\d{1,4})?$
含义:
1.可以不写货币类型,必须用1开头,后面跟着0-2个数字,然后用逗号分隔,剩下的是每三个数字一个逗号;
2.只要加了逗号必须完整加满所有逗号,否则就会出现某个逗号后面跟着大于3数字而无法通过表达式;
8. [\u4e00-\u9fa5]
含义:中文字符的范围,可用于数据统计等事项;
9 [^\x00-\xff]
含义:\x 对应的是UTF-8编码,\x??指的是??编码对应的字符。
解释:包括汉字在内的双字节字符。其实因为使用UTF8,所有字符都用的双字节编码,故这个表达式其实可以用来查找任意字符(包括 .正常情况下不匹配的 \n)
10 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
含义:\n 匹配掉换行符,一个空行至少要包括一个换行符和一个回车符(CRLF,Win)或者一个换行符(LF,Linux)或者一个回车符(CR,OSX)所以其实这个表达式应该按照使用系统的不同稍作调整。
11 ^\s*|\s*$或(^\s*)|(\s*$)
含义:首尾空白字符的正则表达式,灵活的应用空格符!
作用:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
12. \d+\.\d+\.\d+\.\d+
含义:IP地址
改进:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号