新颖训练方法——用迭代投影算法训练神经网络
作者介绍:Jesse Clark

研究相位恢复的物理学家、数据科学家,有着丰富的建设网站与设计手机应用的经验,在创业公司有着丰富的经验,对创业有着极大的热情。
Github: https://github.com/jn2clark
Linkedin: http://www.linkedin.com/in/j3ss3cl4rk
相位恢复(PR)关心的是在给定幅度信息以及受到实空间限制下,找到复值函数(通常在傅立叶空间中)的相位[1]。
PR是一个非凸优化问题,已经成为大量工作[1,2,3,4,5,6,9]的主题,并且成为结晶学的支柱,是结构生物学的中坚力量。
下面显示的是PR重建过程的一个例子,展示了3D弥散数据(傅里叶幅度)重构实空间3D密度的纳米晶体[15]。
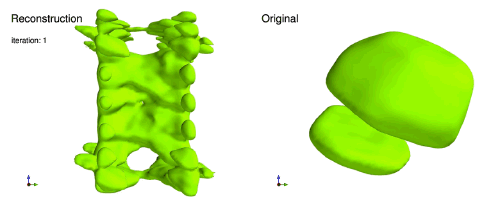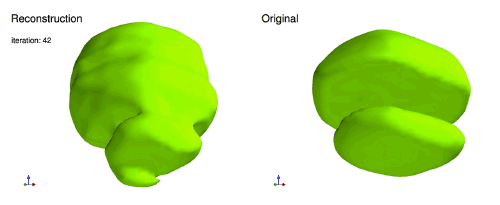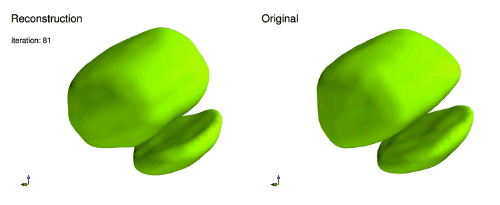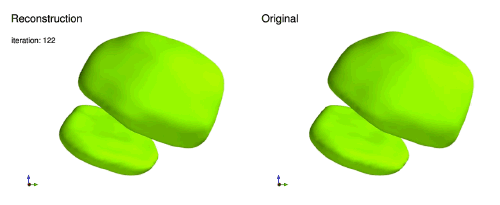
大多PR问题的成功算法是基于投影的方法,这是受到了凸优化投影到凸集上的启发[10]。由于基于投影的方法在PR上取得了成功,探索能否使用类似的方法训练神经网络。
交替投影

凸集投影(POCS)是找到凸集之间交点的有用方法。上面显示了一个简单的例子,其中两个凸约束集C1(红色)和C2(蓝色)。通过简单的迭代映射连续地投影每个集合来找到交集:
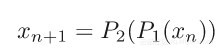
其中P是各自的集合上的投影。投影是幂等PP=P,并且是距离最小化;
P(x)=y以至于![]() 最小;
最小;
当满足下式的时候,能够发现解决方案:
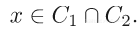
当约束集为非凸时,很少能得出一般结论。因此,使用简单的交替投影可能会导致局部最小值的停滞。下面展示一个例子,其中集合被设置为非凸,找到交集(全局极小值)的能力高度依赖于初始猜测值。

尽管集合在不为凸的情况下失去了保障,但投影方法被证明是寻找非凸优化问题解决方案的一种有效方法。例子包括数独、n皇后问题、图形着色和相位检索等[4,10]。
差异图
最成功的非凸投影算法之一是差分图(DM)[4,8],可以写成
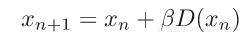
其中

其中y1和y2被称为估计。一旦达到定点:
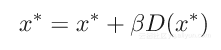
这意味着两个估计等价于解决方案;
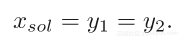
差异图通过作为泛化或等价特定超参数,关联了PR文献中许多的不同算法[1,3,6],不于上述形式,简单版本的差异图经常被使用:
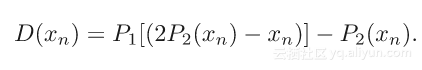
这种更简单的版本通常表现良好,并减少每次迭代所需的投影数量(投影的顺序也可以切换)。公式中的2P2-I项也被称为反射操作,出现在许多投影算法中[9]。
同样的非凸问题如下图所示,但使用差分映射算法后不会被困在局部最小值中,而是能够逃脱并搜索更多的解空间,最后收敛于一个解决方案。

差异图先前被定义为两个投影,那么当有两个以上时会发生什么呢?在这种情况下,定义一个新的迭代X,它是n个重复连接[10]:
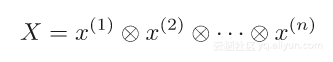
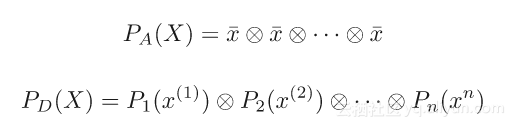
其中Pl为第l个投影,x是加权和;
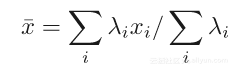
那么许多预测的差异图为
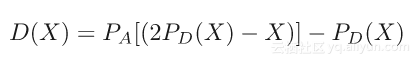
更新X:
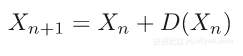
这种方法被称为“分治算法”。下面是一个数独拼图的迭代例子,其收敛使用了差异图与分治算法。

数独有4个约束:每行的数字为1到9,每列的数字为1到9,3x3子方格的数字为1到9,最后数字与部分填充的模板一致。该代码实现这个例子。
用于训练神经网络的投影
对差异图、投影及其在非凸优化中的应用有了解后,下一步是对神经网络的训练进行预测。下例仅考虑一个分类任务,基本思想是寻找一个能正确分类数据的权重向量,将数据分解成K个子集:
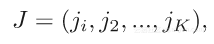
定义一个“投影”权重的投影,使得子集中的所有训练数据被正确分类(或者损失为0)。实际上,使用的是子集的梯度下降来实现投影(基本上是过度拟合的点)。目标是获得能正确分类每个数据子集的权重,并且要查找这些集合的交集。
结果
为了测试训练方案(代码),使用标准方法[13]训练了一个小型网络,并将其与基于投影的方法进行比较。小型网络使用非常简单的层,大约包含22000个参数; 1个卷积层,8个3x3滤波器;2个子采样;1个全连接层(激活函数为ReLU),有16个节点;最后softmax有10个输出(MNIST的10类)。使用Glorot uniform[11]初始化权重。
下图显示其平均训练和测试损失曲线:
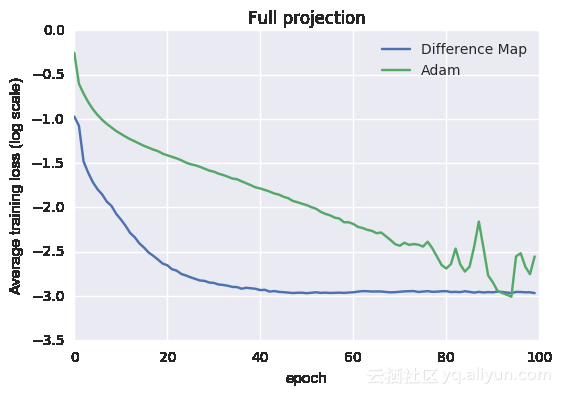
训练损失曲线
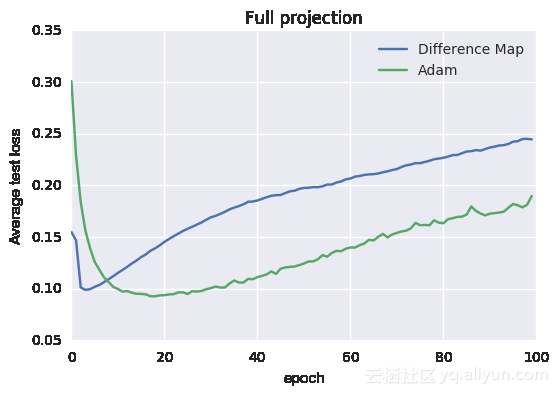
测试损失函数
从图中可以看出效果不错。训练数据被分为大小相同的3组,都被用于投影约束。对于投影而言,需要找到一组最新的权重,使其与先前一组权重的距离最小。另外使用梯度下降法进行训练,一旦训练数据的准确度达到99%就终止投影。更新后的权重投影到3组上产生3个新的权重集合,这些集合连接在一起以形成
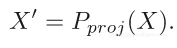
平均投影可以通过将权重平均得到,之后进行复制并连接后形成新的向量:
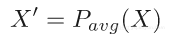
根据差异图将这两个投影步骤组合以获得权重的更新方案。除了常规度量外,还可以监视差异图误差来寻找收敛。差异映射误差由下式定义:
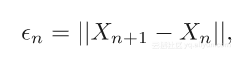
上式值越低,表明解决方案越好。差异图错误达到稳定表明已经找到了一个近似的解决方案。差异图错误通常在稳定前会突然下降[4],表明找到合适的解决方案。
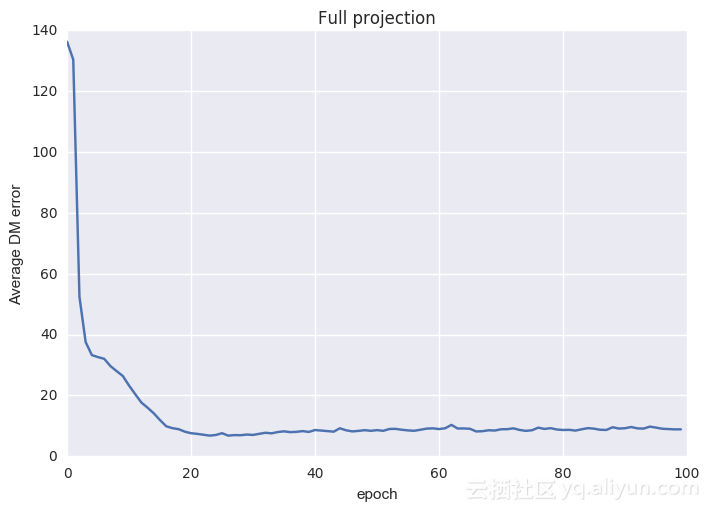
在上例中,投影是通过训练数据子集上的反复梯度变化定义,本质上是过度拟合的点。在下例中,遍历完一次训练数据后就终止投影。
下面显示的是平均cv测试和训练误差(与上述相同的常规训练相比)
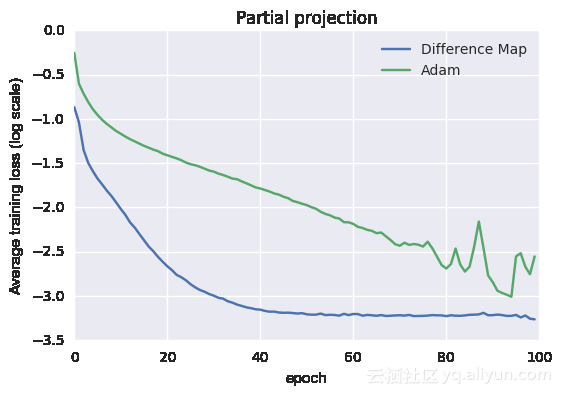
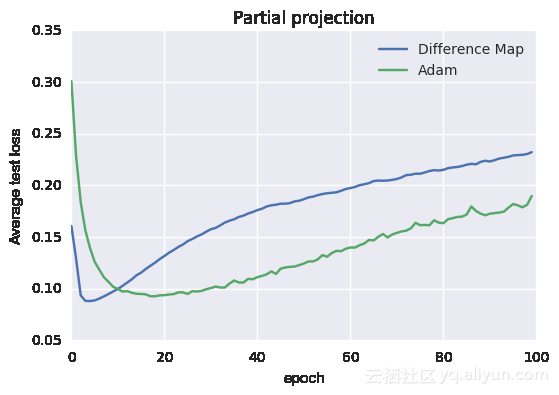
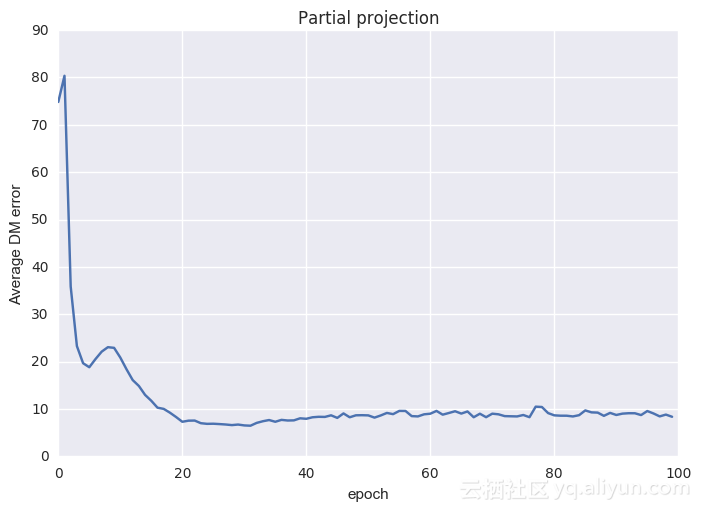
从图中可以看到这种方法仍然可行,为什么会这样呢?如果投影操作提前终止,那么能想到的一点就是简单地将该投影视为一个松弛投影或非最佳投影。凸优化和PR的结果[4,5,7,14]仍然表明,松弛投影或非最佳投影趋于好的解决方案。另外,在单遍历投影限制中,可以通过交替投影来恢复传统的基于梯度下降的训练方案(以3组为例):
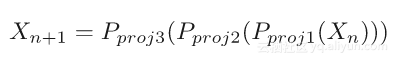
最后,常规训练中的参数设置会对网络的结果产生很大的影响,具体参数设置可以查看原文。训练这样的网络并执行提前终止,传统训练方法的最终损失和准确度分别为0.0724和97.5%,而使用差异图方法的结果分别为0.0628和97.9%。
投影方法的扩展
关于投影方法的好处之一是可以轻松实现额外的约束。对于L1正则化而言,可以定义收缩或软阈值操作,如
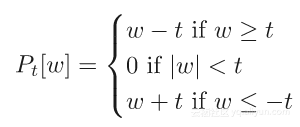
其他投影可以是卷积核的对称性或权重的直方图约束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号