从disable_cost到disabled_nodes,最小代价预估质的飞跃
在HOW2025大会优化专场,老杨分享了修改disable_cost为GUC结合pg_hint_plan实现精准执行计划控制的实践。
主要是举例了一个极端case,在17版本依然需要disable_cost的动态调整来实现hint精准指定索引。
对于disable_cost的讨论早在2019年就开始了,一直持续到现在,可参考社区邮件。邮件前期主要是讨论disable_cost默认常量值不足,往往导致set guc to off不能达到预期,执行计划跑偏。期间也有人提交patch意图调整这里的逻辑。最近老杨再去看最新进展时发现disable_cost基本要退出历史舞台了,18版本有了更优的逻辑来控制代价。
再实测这个极端case,获得了意外之喜,直呼PG牛X!!! 18版本优化器代价预估逻辑优化后,hint已经能够精准指定索引了。当然18版本带来的惊喜可不止这个,大家敬请期待吧!
本文较长,希望大家能感兴趣耐心看完。
1 问题回顾
颠覆认知的limit
本质上是优化器limit算子代价预估模型缺陷,没有考虑数据分布,导致ordering index的代价预估存在偏差。
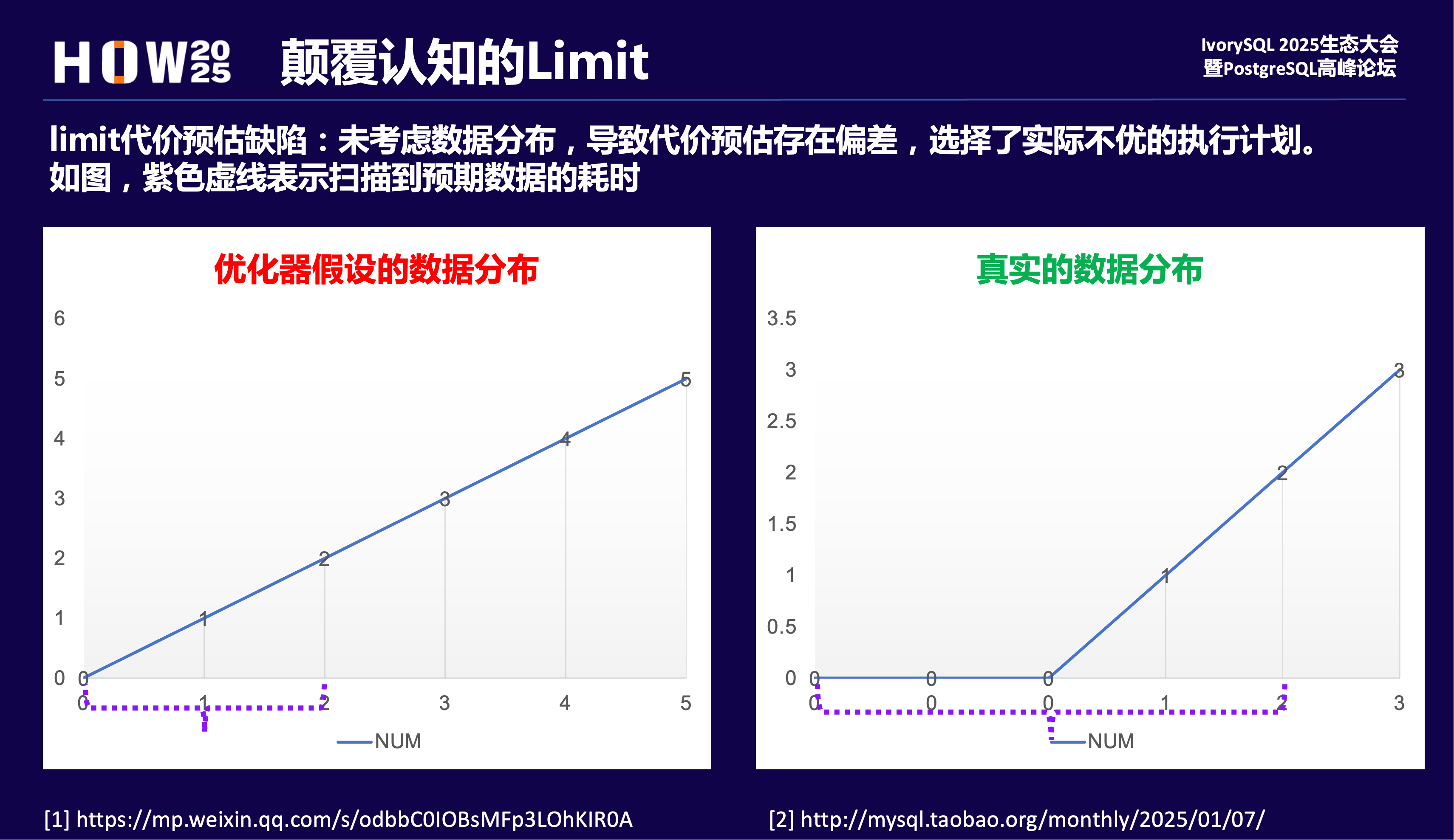
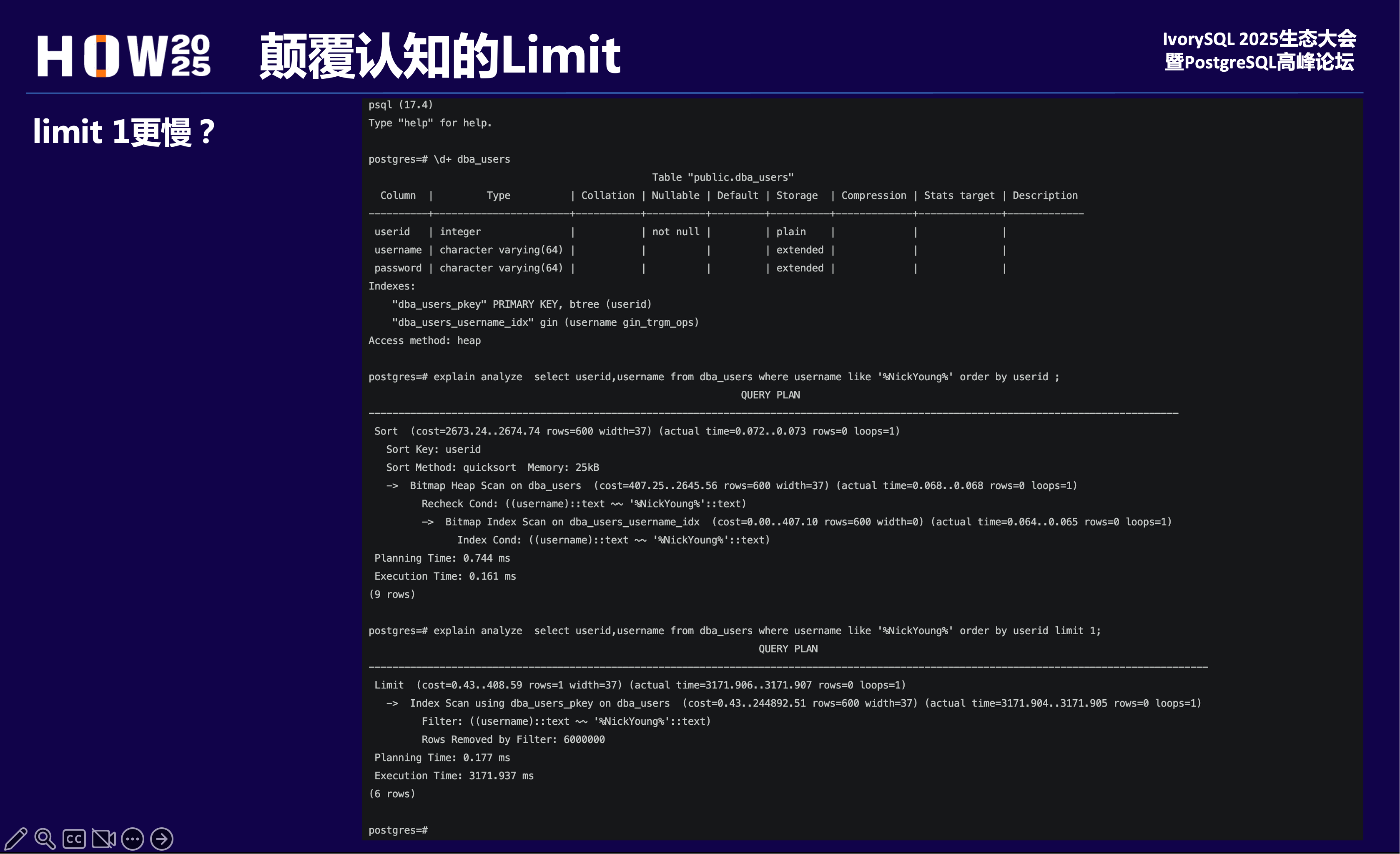
limit 1居然慢了数万倍,是代价预估偏差,走了不优的计划。可以看到走了“错误的”索引,导致回表检索全表数据,耗时久。
对于这个问题,老杨也曾尝试修改过limit代价预估的逻辑,虽然是草台班子玩法,但效果还是杠杠的。感兴趣的老铁可以看下这篇。
当然更推荐大家去看下专业开发者的方案。
不过到目前为止,社区还没有做相关优化,这个问题可能短期内会一直存在。
所以,当遇到这个场景,我们会使用pg_hint_plan来指定索引。但在17版本及以下实际效果不尽人意。
指定走某个索引,却走了顺序扫描,有种“这把枪弹道偏左”的感觉。
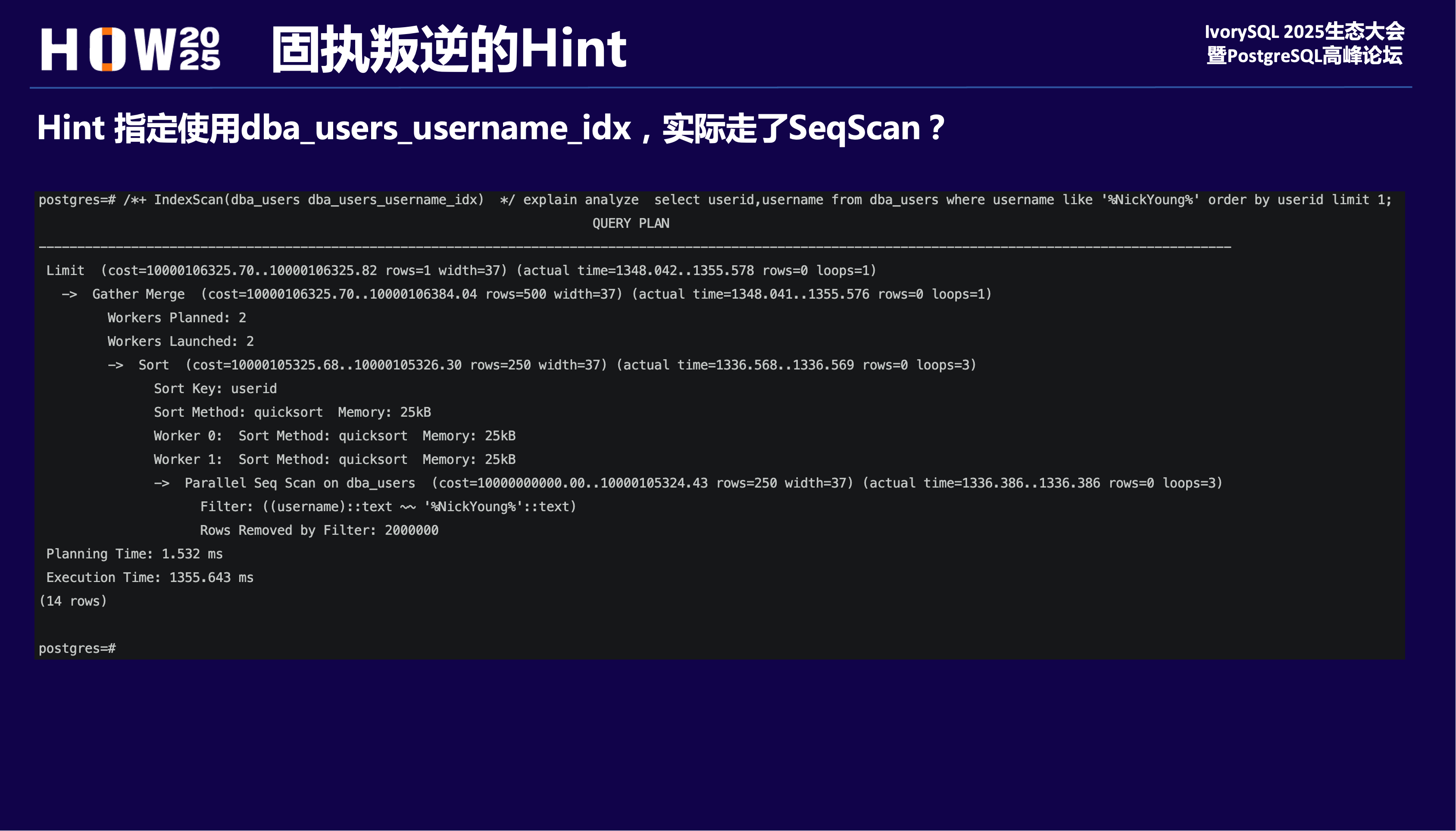
固执叛逆的hint
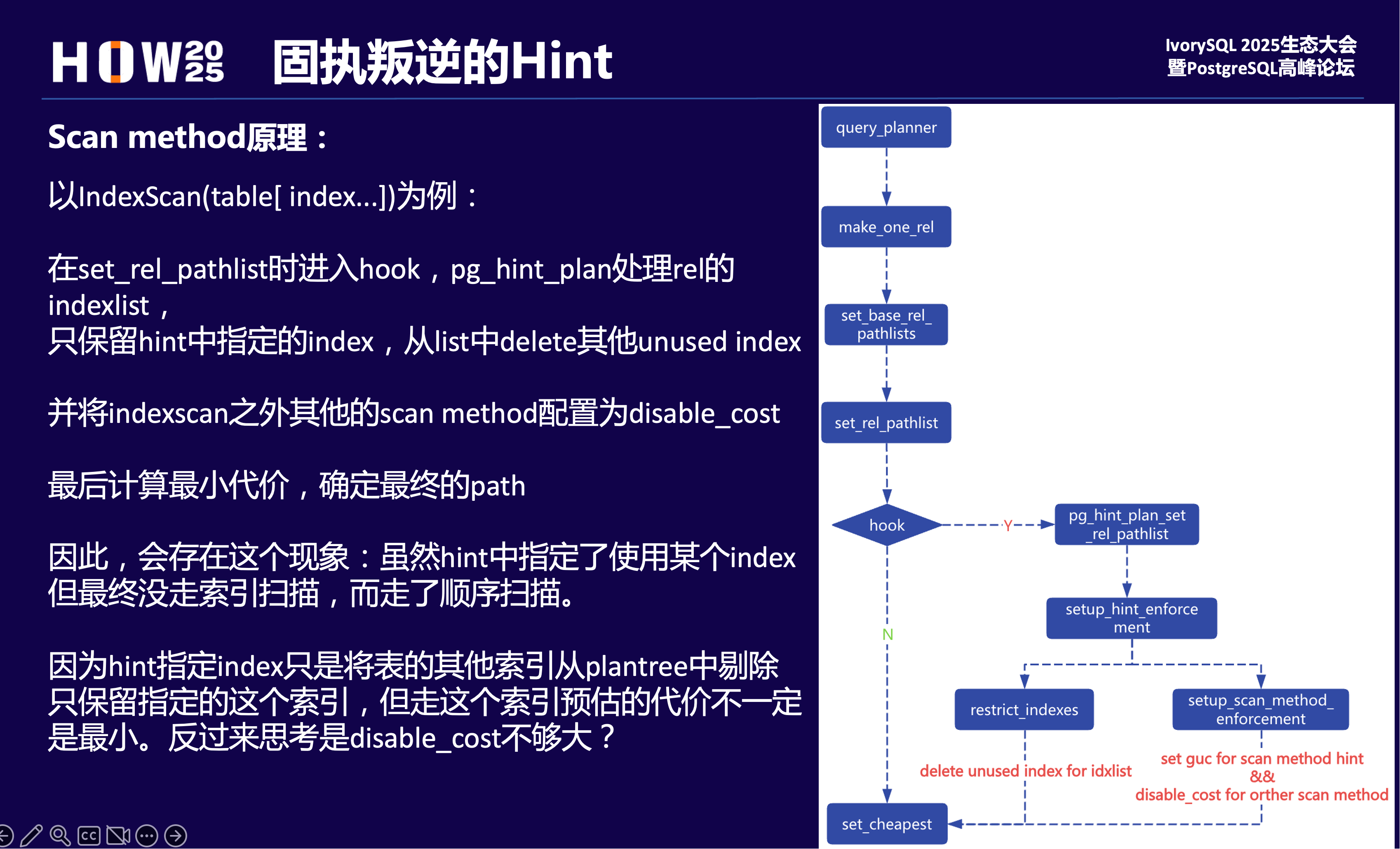
这个和hint原理相关: IndexScan指定走某个索引,主要在创建rel pathlist环节做两件事:
- 将hint之外的索引从IndexList中剔除,对于Indexscan的path只保留了预期的index;
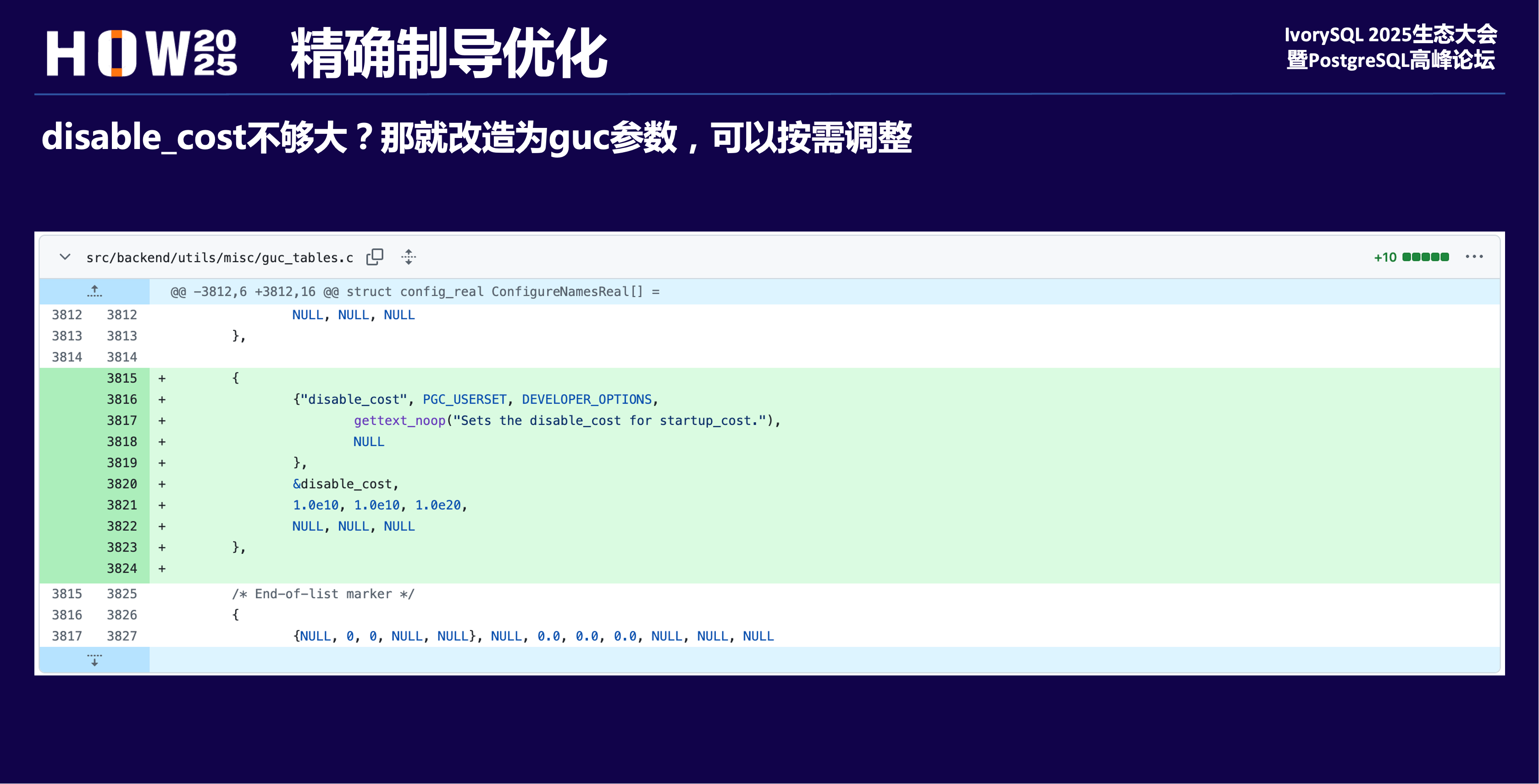
- 设置enable_indexscan=on,设置enable_seqscan、enable_bitmapscan、enable_tidscan为off,其实就是给这几种ScanMethod的startup_cost加上disable_cost (1e+10)
看起来似乎可以按预期走指定的索引扫描。事实上即使增加其他了扫描方式的cost,但有可能cost的值不够大,这样在优化器计算最小代价时,还是其他执行路径代价更小,所以就不会走索引扫描。
精确制导优化
disable_cost不够大,那将其改造为guc参数可动态调整,就可以和hint一起精准打击。
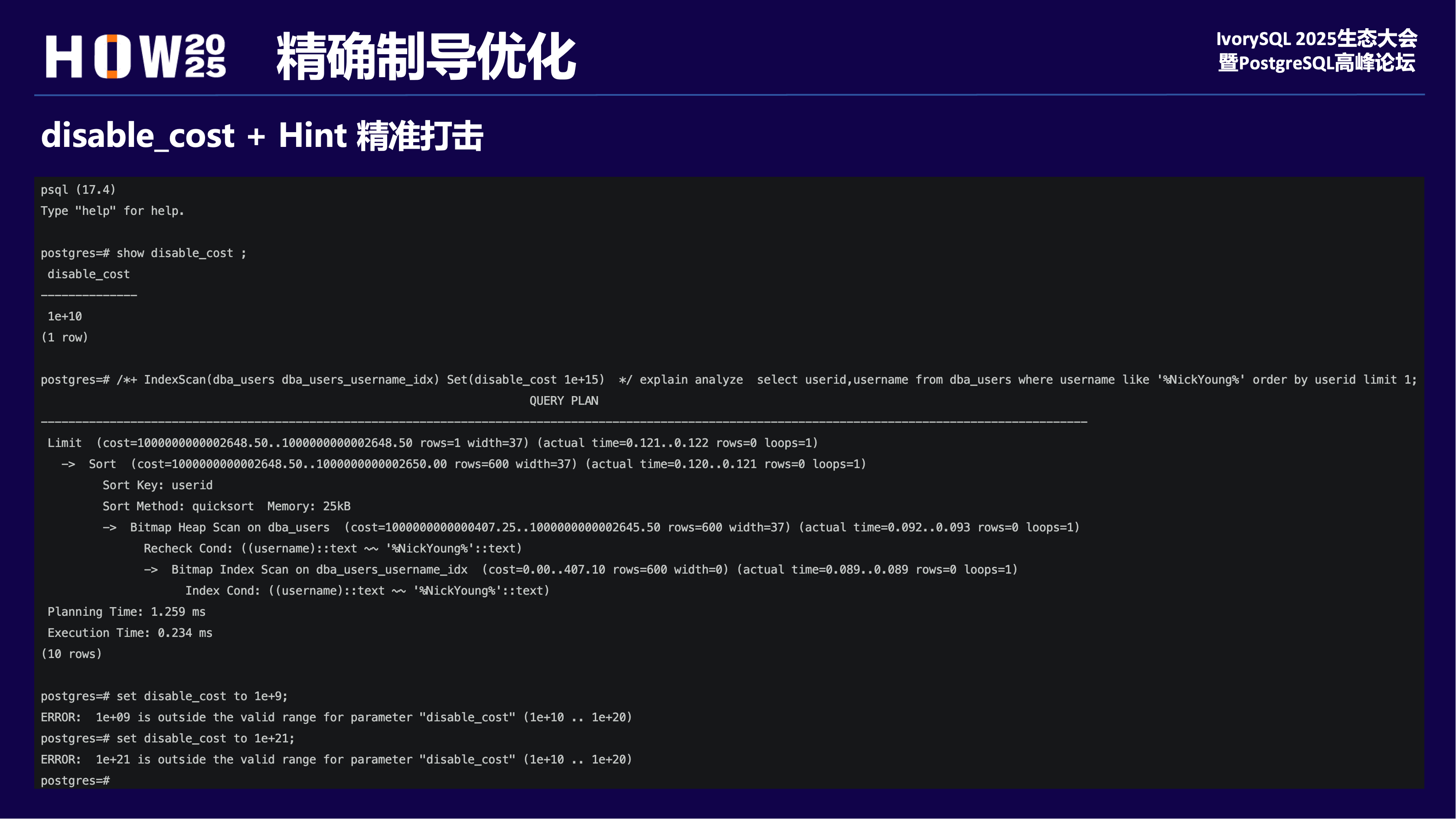
2 意外之喜
看到社区对disable_cost讨论的最新进展后,再测这个case,发现18版本hint已经可以精确指定索引。
至于为什么是Bitmap Index Scan,那是因为gin索引本来就是这样设计的。
[postgres@Nick ~]$ psql
psql (18beta2)
Type "help"forhelp.
postgres=# /*+ IndexScan(dba_users dba_users_username_idx) */ explain analyze select username from dba_users where username like '%NickYoung%' order by userid limit 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2618.81..2618.81 rows=1 width=37) (actual time=0.100..0.101 rows=0.00 loops=1)
Buffers: shared hit=18
-> Sort (cost=2618.81..2620.31 rows=600 width=37) (actual time=0.098..0.099 rows=0.00 loops=1)
Sort Key: userid
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=18
-> Bitmap Heap Scan on dba_users (cost=377.50..2615.81 rows=600 width=37) (actual time=0.055..0.055 rows=0.00 loops=1)
Disabled: true
Recheck Cond: ((username)::text ~~ '%NickYoung%'::text)
Buffers: shared hit=15
-> Bitmap Index Scan on dba_users_username_idx (cost=0.00..377.35 rows=600 width=0) (actual time=0.048..0.048 rows=0.00 loops=1)
Index Cond: ((username)::text ~~ '%NickYoung%'::text)
Index Searches: 1
Buffers: shared hit=15
Planning:
Buffers: shared hit=133
Planning Time: 1.711 ms
Execution Time: 0.287 ms
(18 rows)
postgres=#
不过从执行计划limit节点的cost来看,代价很小,已经看不到disable_cost的影子了。
3 原理分析
具体的变化来自这个commit。
简单来说,就是disable_cost的玩法,在很多场景下表现都很糟糕。这个巨大的cost本身就不够优雅,会导致两条路径的模糊成本一致,导致代价预估偏差大。
因此Robert Haas大师,提出并实现了“禁用路径,而不是增加cost”的方案。
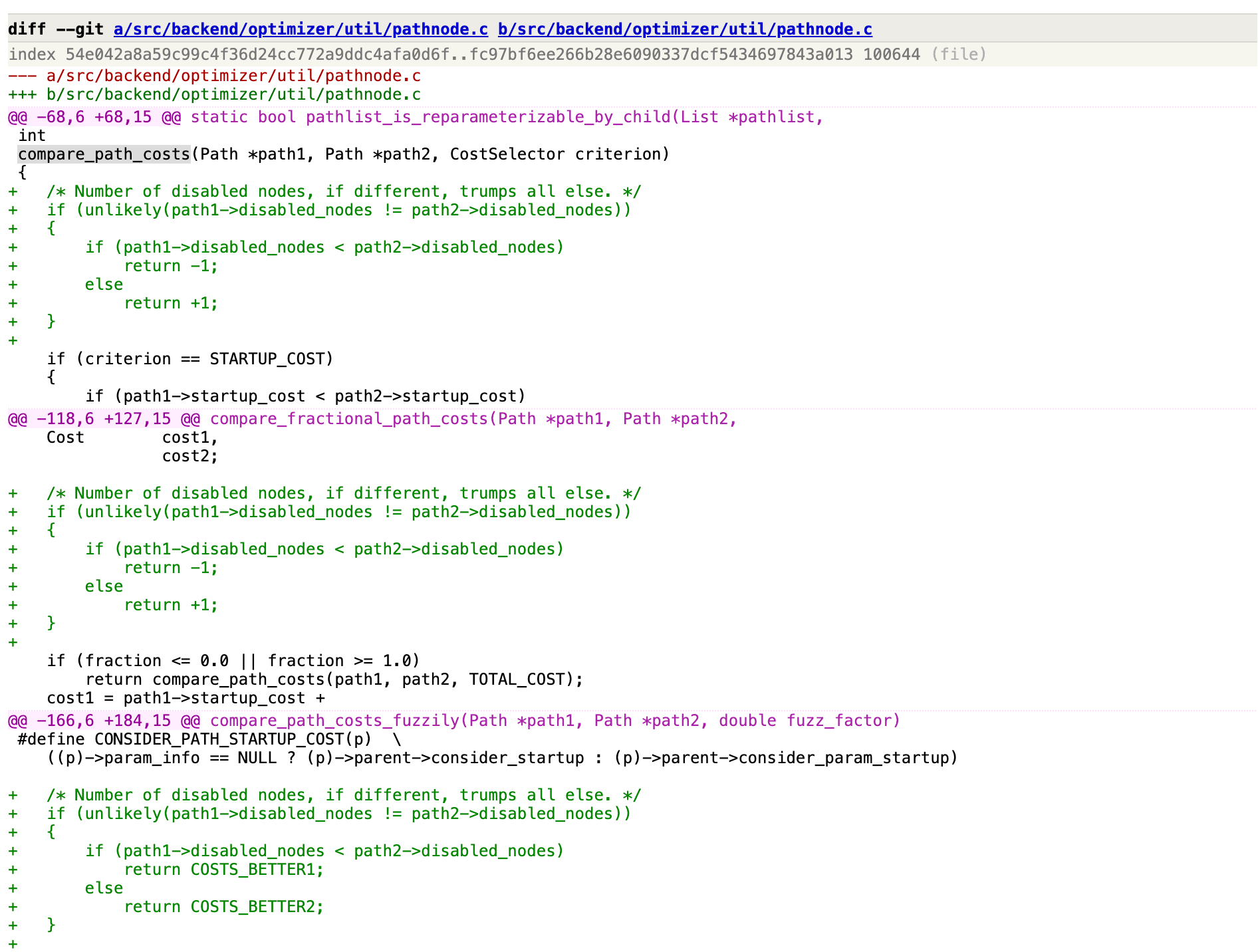
在cost预估中,去除了几乎所有disable_cost逻辑,Path结构体新增int类型变量disabled_nodes,在各node里初始值为0。
比如当set enable_seqscan to off时会执行disabled_nodes++ ,这个时候值为1,这个变量值会继续传递到后续的计划节点。后续join的时候,如果set enable_nestloop to off,先将当前节点的disabled_nodes++为1,再将inner和outer的disabled_nodes值传递过来, 这样整体路径的disabled_nodes为4, disabled_nodes一直会传递到最终节点。
void
initial_cost_nestloop(PlannerInfo *root, JoinCostWorkspace *workspace,
JoinType jointype,
Path *outer_path, Path *inner_path,
JoinPathExtraData *extra)
{
int disabled_nodes;
Cost startup_cost = 0;
Cost run_cost = 0;
double outer_path_rows = outer_path->rows;
Cost inner_rescan_start_cost;
Cost inner_rescan_total_cost;
Cost inner_run_cost;
Cost inner_rescan_run_cost;
/* Count up disabled nodes. */
disabled_nodes = enable_nestloop ? 0 : 1;
disabled_nodes += inner_path->disabled_nodes;
disabled_nodes += outer_path->disabled_nodes;
/* estimate costs to rescan the inner relation */
cost_rescan(root, inner_path,
&inner_rescan_start_cost,
&inner_rescan_total_cost);
/* 省略 */
}
在代价比较时,逻辑也与之前不同,优先比较两条路径的disabled_nodes的值,小的为更优路径。
在disabled_nodes一致的情况下,再比较total_cost,然后再比较startup_cost。
所以最小代价计算的逻辑也不同了,优先考虑比较禁用路径数量,这样要比仅比较cost稳妥的多。
compare_path_costs_fuzzily(模糊比较)、compare_path_costs(精确比较)、compare_fractional_path_costs(折衷比较)都是先比较disabled_nodes。
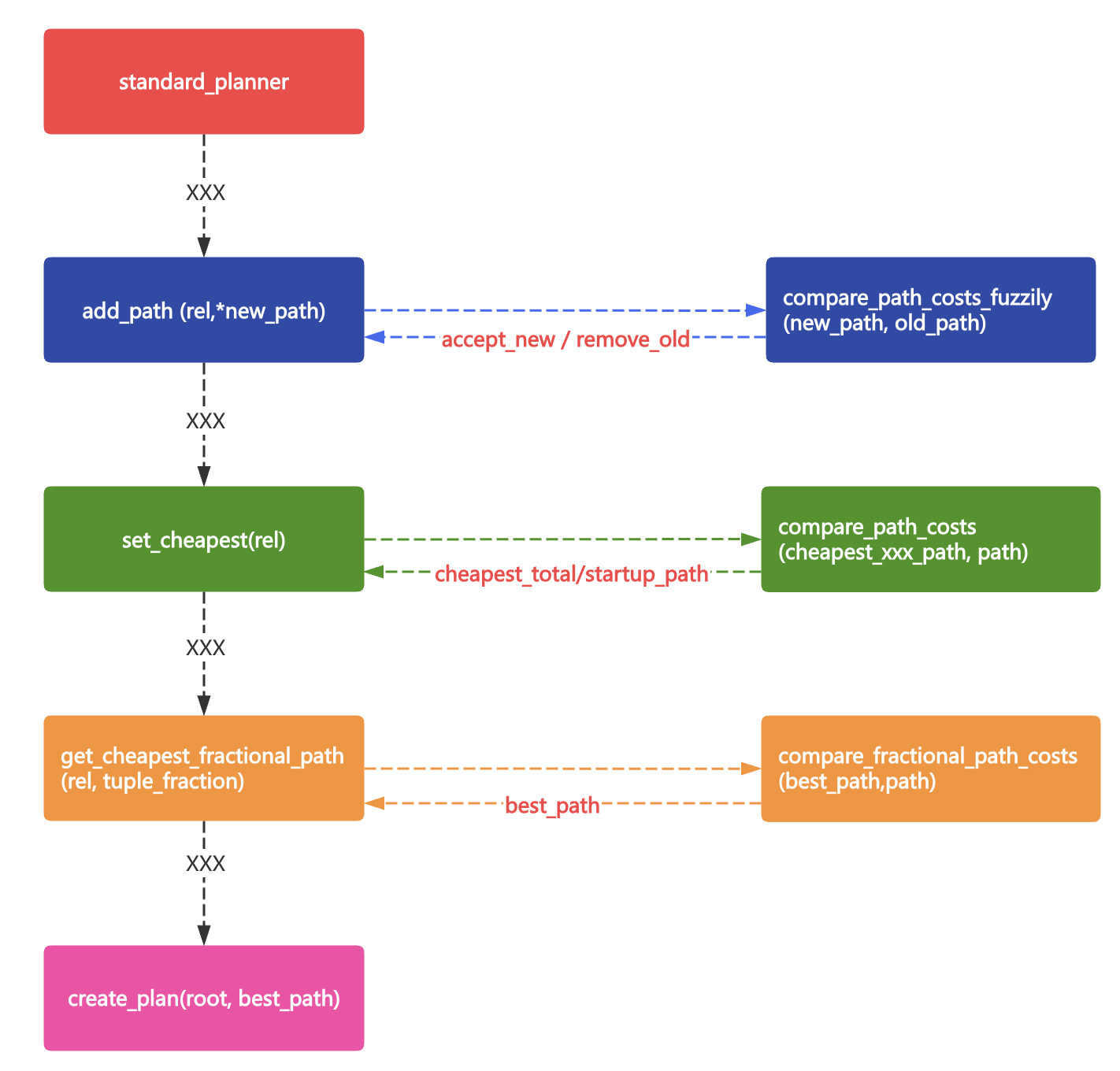
用框图简单描述下最优代价预估的过程。
另外,disable_cost的逻辑是全部剔除了吗? 纵览代码,只剩一处了。在final_cost_hashjoin中,用来评估work_mem是否足够inner_path_row * mcv 生成hash。 如果预估需要的hash_mem大于work_mem,则给startup_cost加disable_cost。
void
final_cost_hashjoin(PlannerInfo *root, HashPath *path,
JoinCostWorkspace *workspace,
JoinPathExtraData *extra)
{
/* 省略 */
/*
* If the bucket holding the inner MCV would exceed hash_mem, we don't
* want to hash unless there is really no other alternative, so apply
* disable_cost. (The executor normally copes with excessive memory usage
* by splitting batches, but obviously it cannot separate equal values
* that way, so it will be unable to drive the batch size below hash_mem
* when this is true.)
*/
if (relation_byte_size(clamp_row_est(inner_path_rows * innermcvfreq),
inner_path->pathtarget->width) > get_hash_memory_limit())
startup_cost += disable_cost;
/* 省略 */
}
size_t
get_hash_memory_limit(void)
{
double mem_limit;
/* Do initial calculation in double arithmetic */
mem_limit = (double) work_mem * hash_mem_multiplier * 1024.0;
/* Clamp in case it doesn't fit in size_t */
mem_limit = Min(mem_limit, (double) SIZE_MAX);
return (size_t) mem_limit;
}
4 测试验证
默认走dba_users_pkey索引,实际性能差,耗时3s+。
psql (18beta2)
Type "help"forhelp.
postgres=# explain analyze select username from dba_users where username like '%NickYoung%' order by userid limit 1;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.43..408.59 rows=1 width=37) (actual time=3490.601..3490.603 rows=0.00 loops=1)
Buffers: shared hit=90471
-> Index Scan using dba_users_pkey on dba_users (cost=0.43..244894.43 rows=600 width=37) (actual time=3490.599..3490.599 rows=0.00 loops=1)
Filter: ((username)::text ~~ '%NickYoung%'::text)
Rows Removed by Filter: 6000000
Index Searches: 1
Buffers: shared hit=90471
Planning:
Buffers: shared hit=126
Planning Time: 1.674 ms
Execution Time: 3490.653 ms
(11 rows)
postgres=#
使用hint指定走dba_users_username_idx,耗时1ms。
postgres=# /*+ IndexScan(dba_users dba_users_username_idx) */ explain analyze select username from dba_users where username like '%NickYoung%' order by userid limit 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2618.81..2618.81 rows=1 width=37) (actual time=0.069..0.070 rows=0.00 loops=1)
Buffers: shared hit=15
-> Sort (cost=2618.81..2620.31 rows=600 width=37) (actual time=0.067..0.068 rows=0.00 loops=1)
Sort Key: userid
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=15
-> Bitmap Heap Scan on dba_users (cost=377.50..2615.81 rows=600 width=37) (actual time=0.060..0.061 rows=0.00 loops=1)
Disabled: true
Recheck Cond: ((username)::text ~~ '%NickYoung%'::text)
Buffers: shared hit=15
-> Bitmap Index Scan on dba_users_username_idx (cost=0.00..377.35 rows=600 width=0) (actual time=0.048..0.048 rows=0.00 loops=1)
Index Cond: ((username)::text ~~ '%NickYoung%'::text)
Index Searches: 1
Buffers: shared hit=15
Planning:
Buffers: shared hit=2
Planning Time: 1.234 ms
Execution Time: 0.123 ms
(18 rows)
postgres=#
debug这个SQL最优路径选取以及hint生效的过程。
dba_users表有两个index:
"dba_users_pkey" PRIMARY KEY, btree (userid)
"dba_users_username_idx" gin (username gin_trgm_ops)
1、set_rel_pathlist创建表的扫描路径,我们先关注下所有index路径的创建。
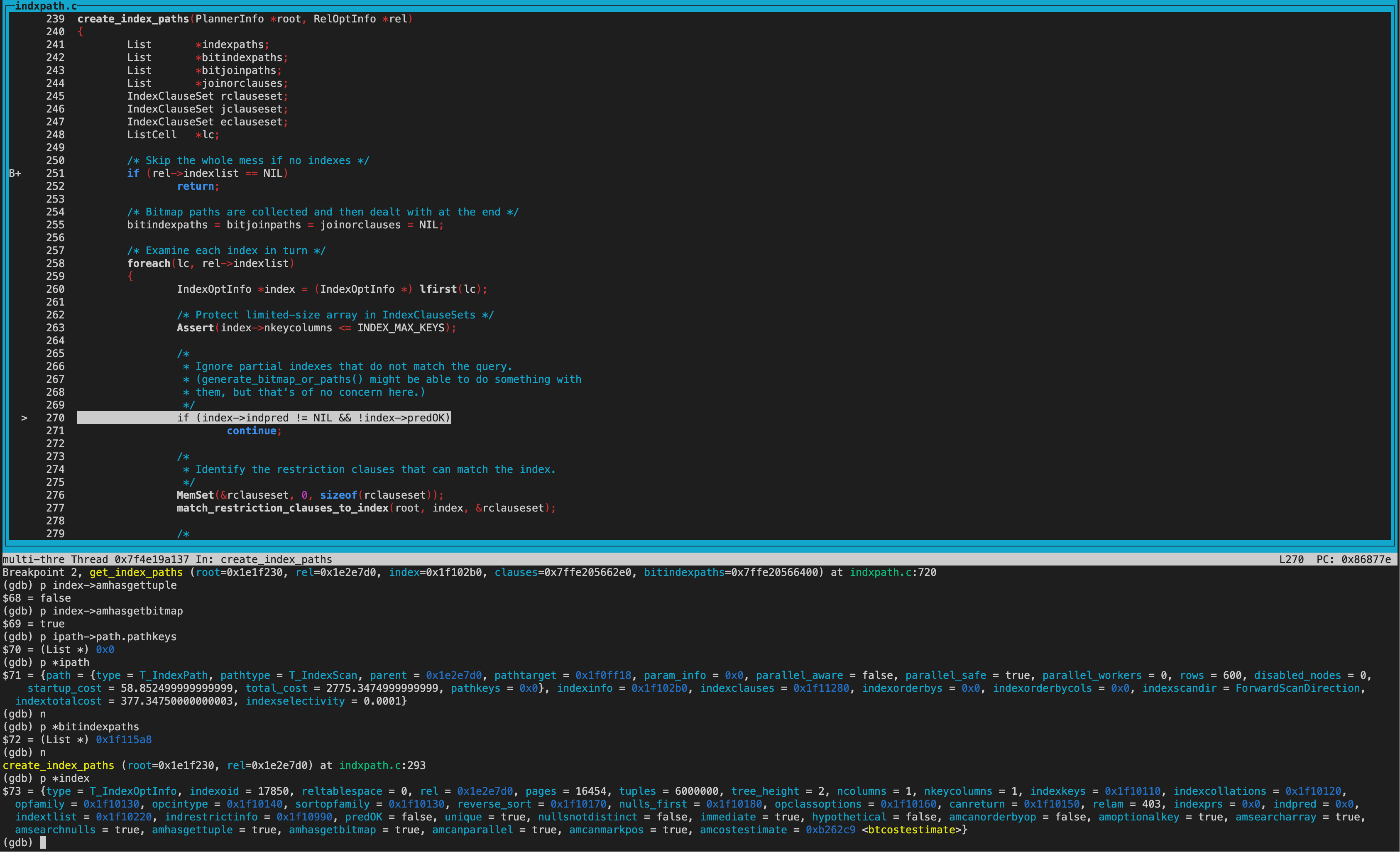
create_index_paths函数里,可以看到rel->indexlist长度为2,遍历list获取到的第一个index为gin索引。
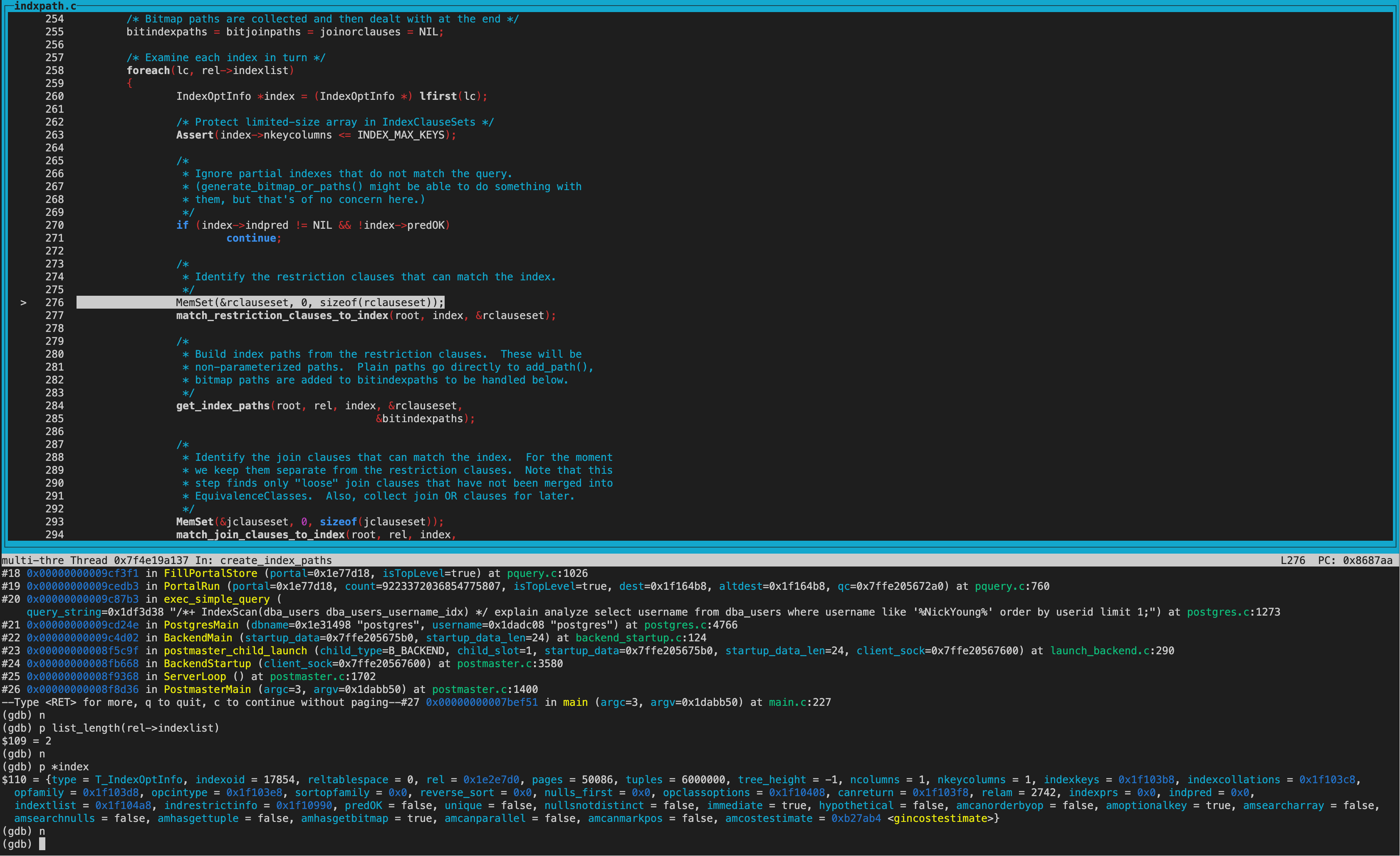
调用get_index_paths函数给gin索引生成路径。 gin索引amhasgettuple为NULL(ginhandler中初始化),所以gin索引不创建IndexScan Path。
而amhasgetbitmap为true(ginhandler中初始化),也就是可以生成Bitmap Index scan路径,不过同时还要满足pathkey为NULL。从打印的结果看确实都满足,所以给gin索引创建了bitindexpaths即Bitmap Index scan path。
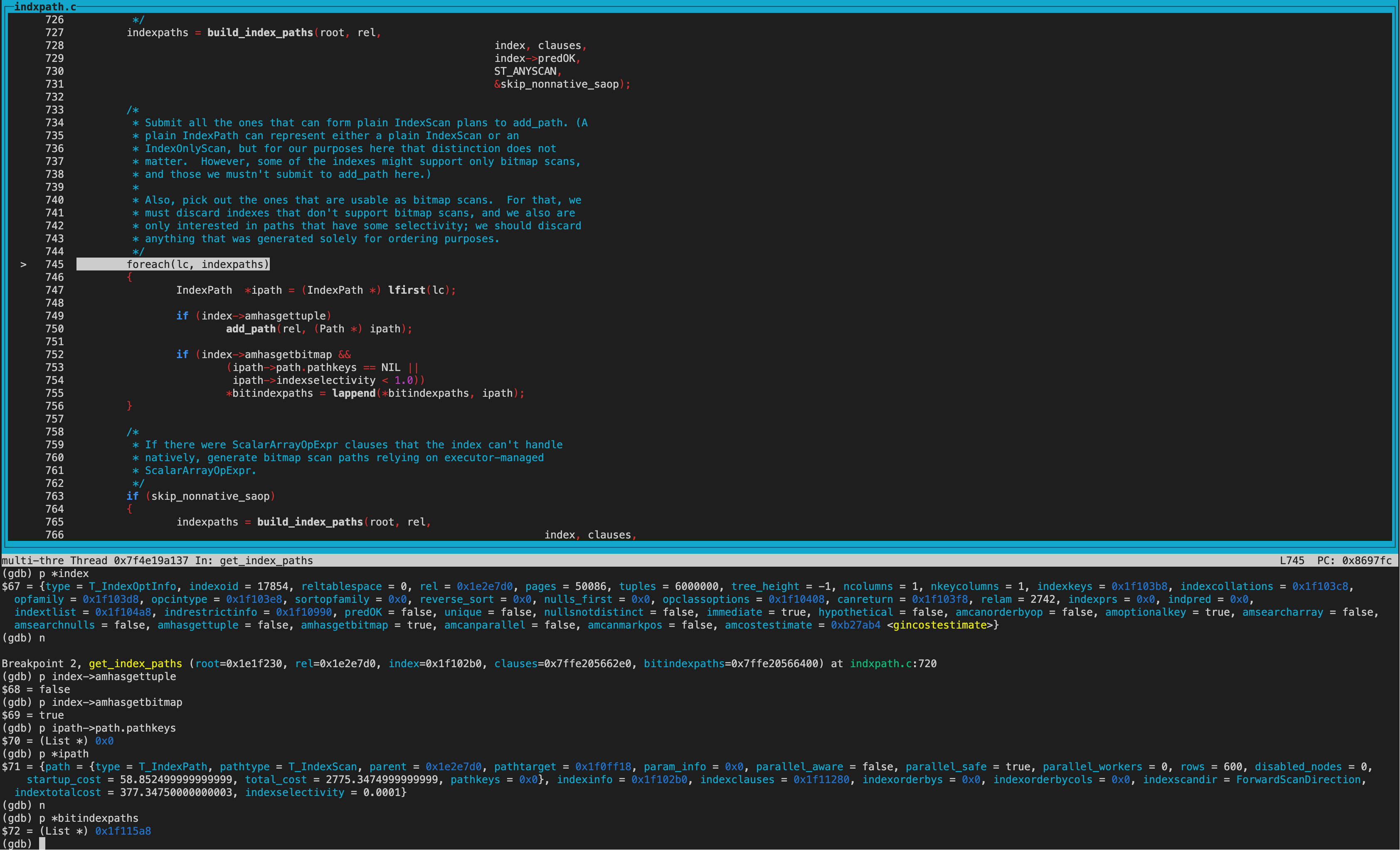
生成BitmapHeapScan path
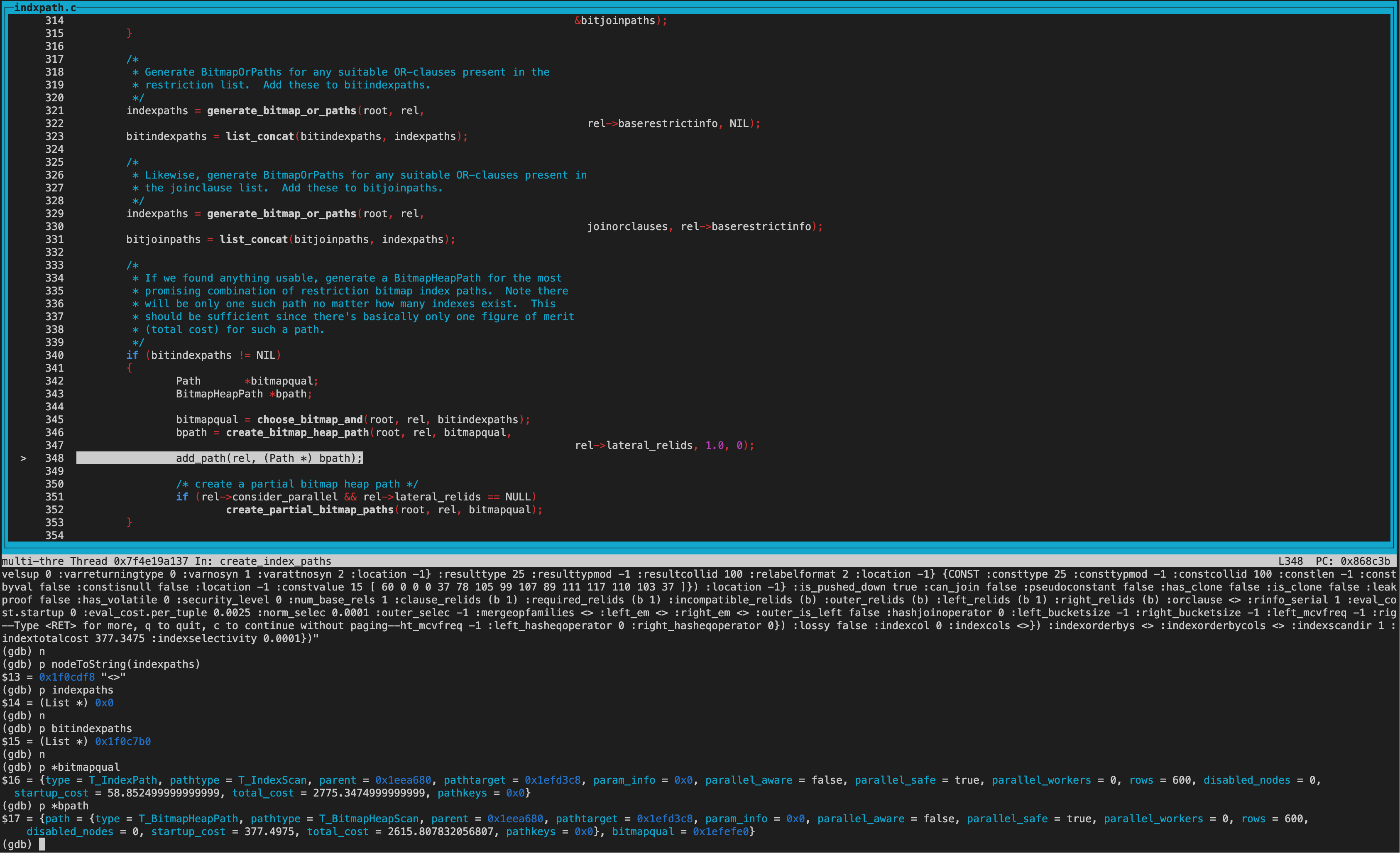
这里解释下pathkey:和索引的order属性相关,gin索引sortopfamily为NULL,amcanorderbyop为false,所以useful_pathkeys为null,即pathkey为NULL。
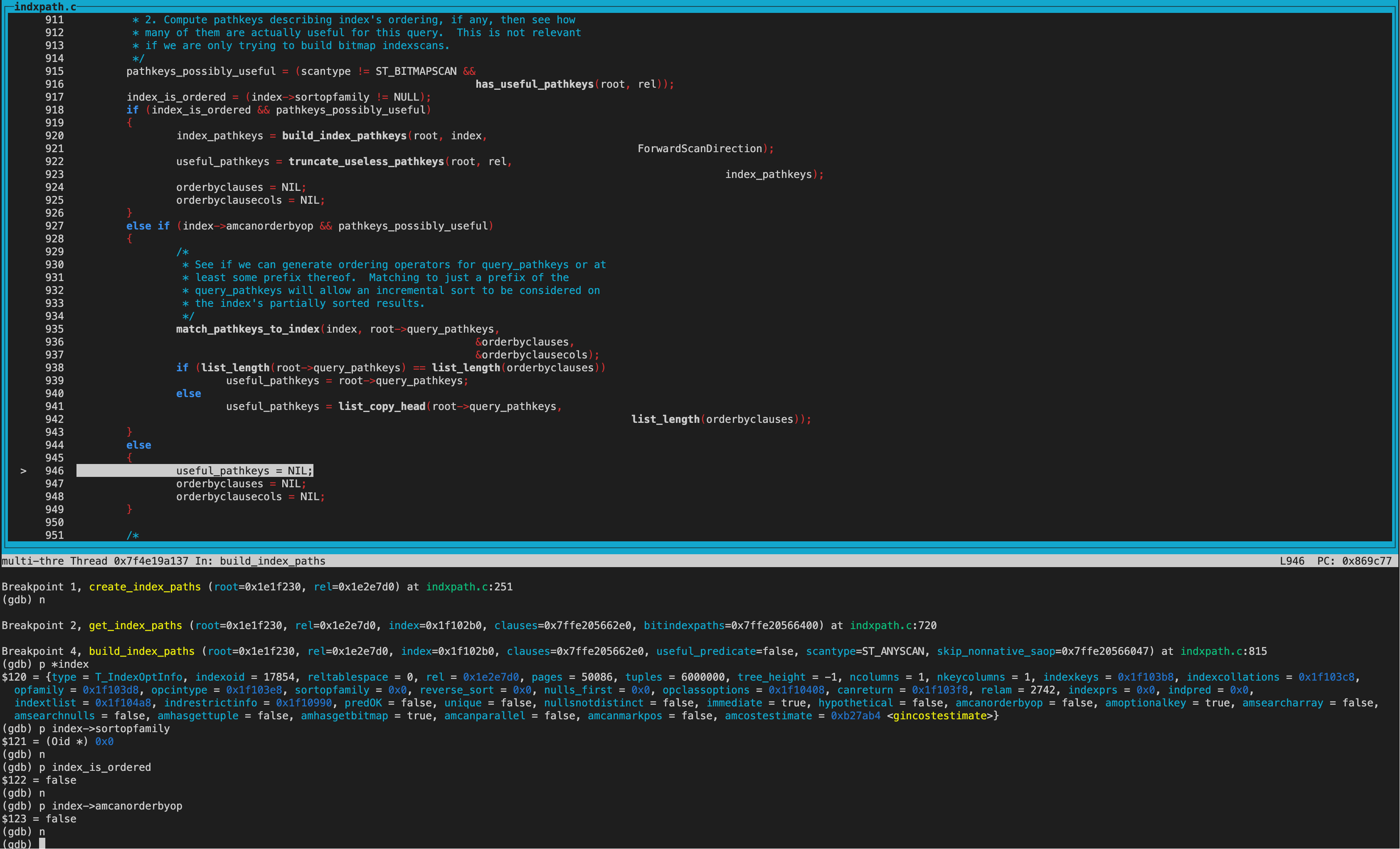
create_index_paths函数里,第二次遍历到的index为btree索引。
调用get_index_paths函数给btree索引生成路径。 btree索引amhasgettuple为true(bthandler中初始化),所以生成IndexScan path。 而amhasgetbitmap为true(bthandler中初始化),不过pathkey不为null,因此没有生成bitindexpaths,不生成BitmapIndexscan path。
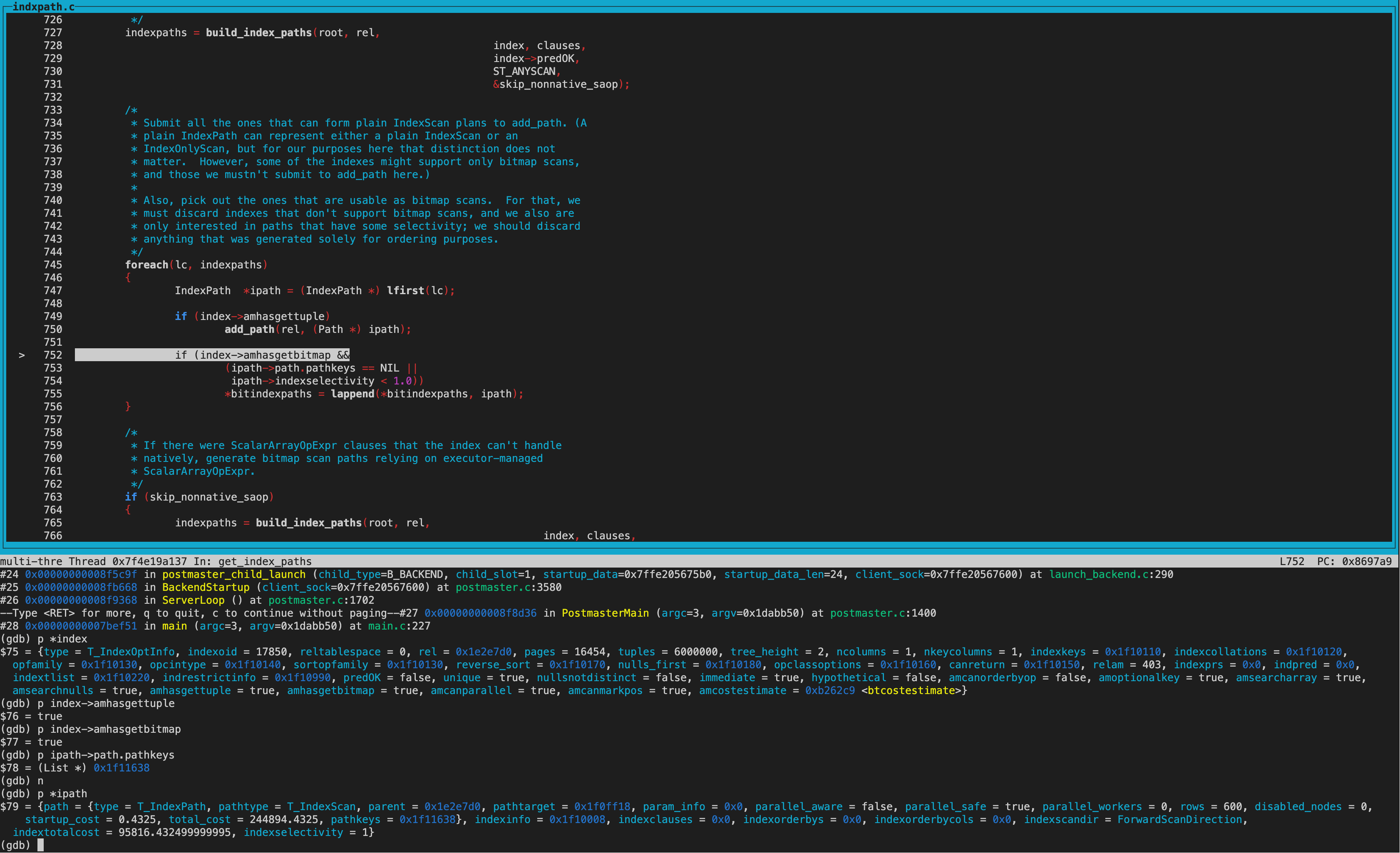
因为sortopfamily非NULL,所以生成useful_pathkeys,即pathkey非NULL。
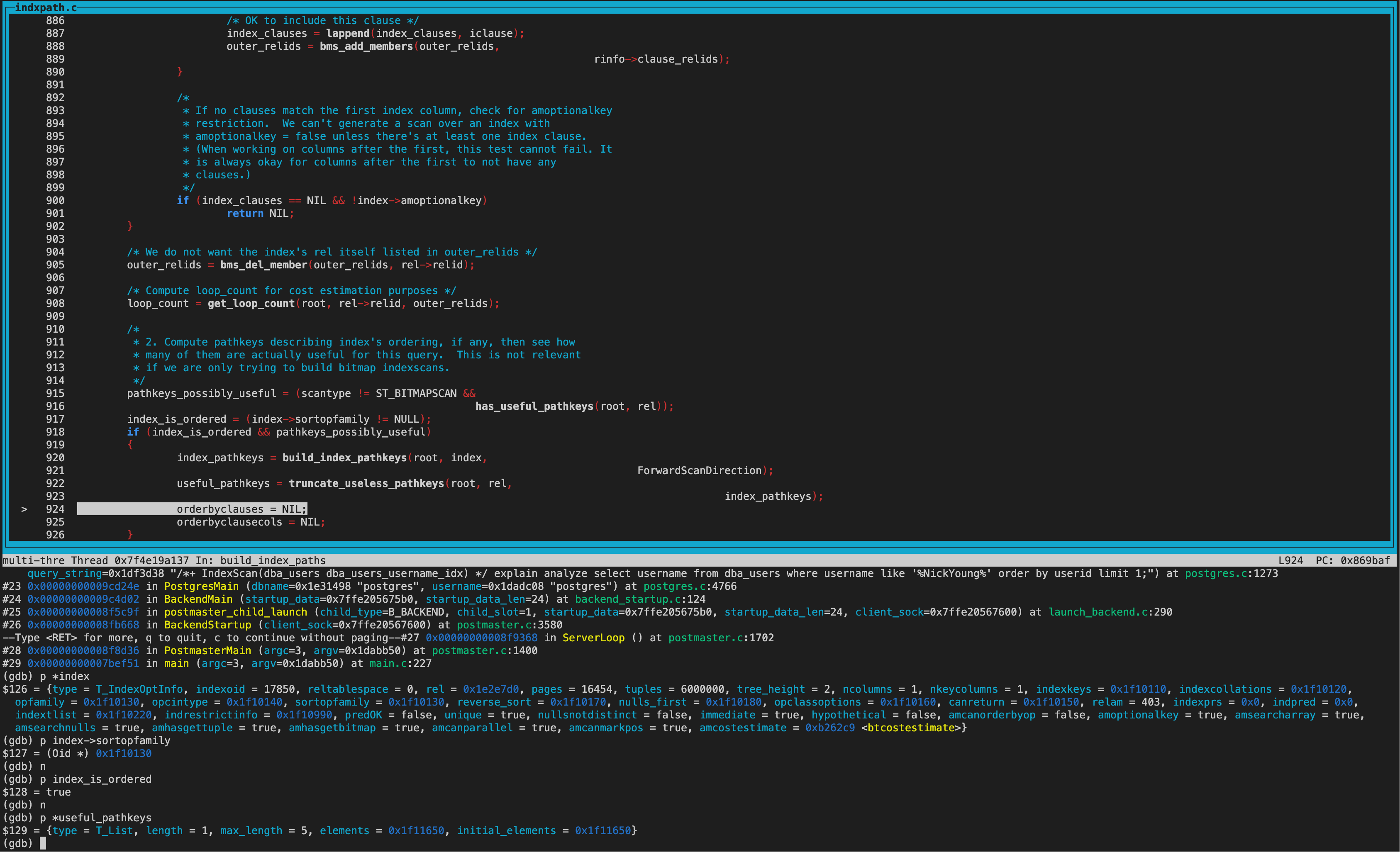
当然创建路径时都会比较cost,我们放到下一环节讨论。
至此,对于dba_users_pkey路径为Indexscan, 对于dba_users_username_idx路径为BitmapIndexscan。
2、来看rel_pathlist中的cost比较。
compare_path_costs_fuzzily(模糊比较)
首先比较的new_path为IndexScan,old_path为SeqScan。 因为目前还没走到hint阶段,当前guc参数都为on,因此两个path的disabled_nodes相同(都为0)。接着比较total_cost,old_path的total_cost和startup_cost都优于new_path,因此返回COST_BETTER2
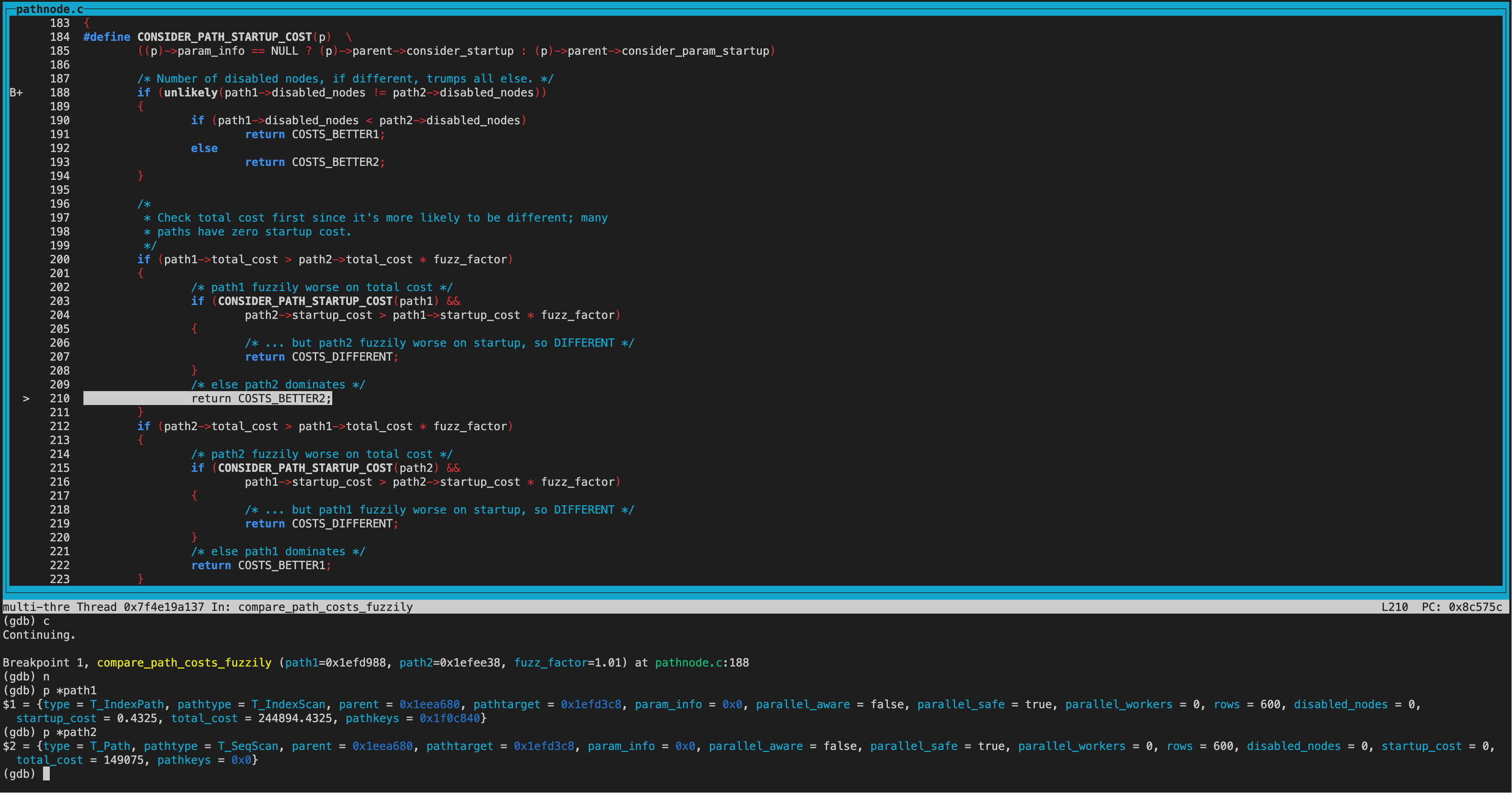
在add_path中costcmp为COST_BETTER2,keyscmp为PATHKRYS_BETTER1,所以没有标记accept_new为false。
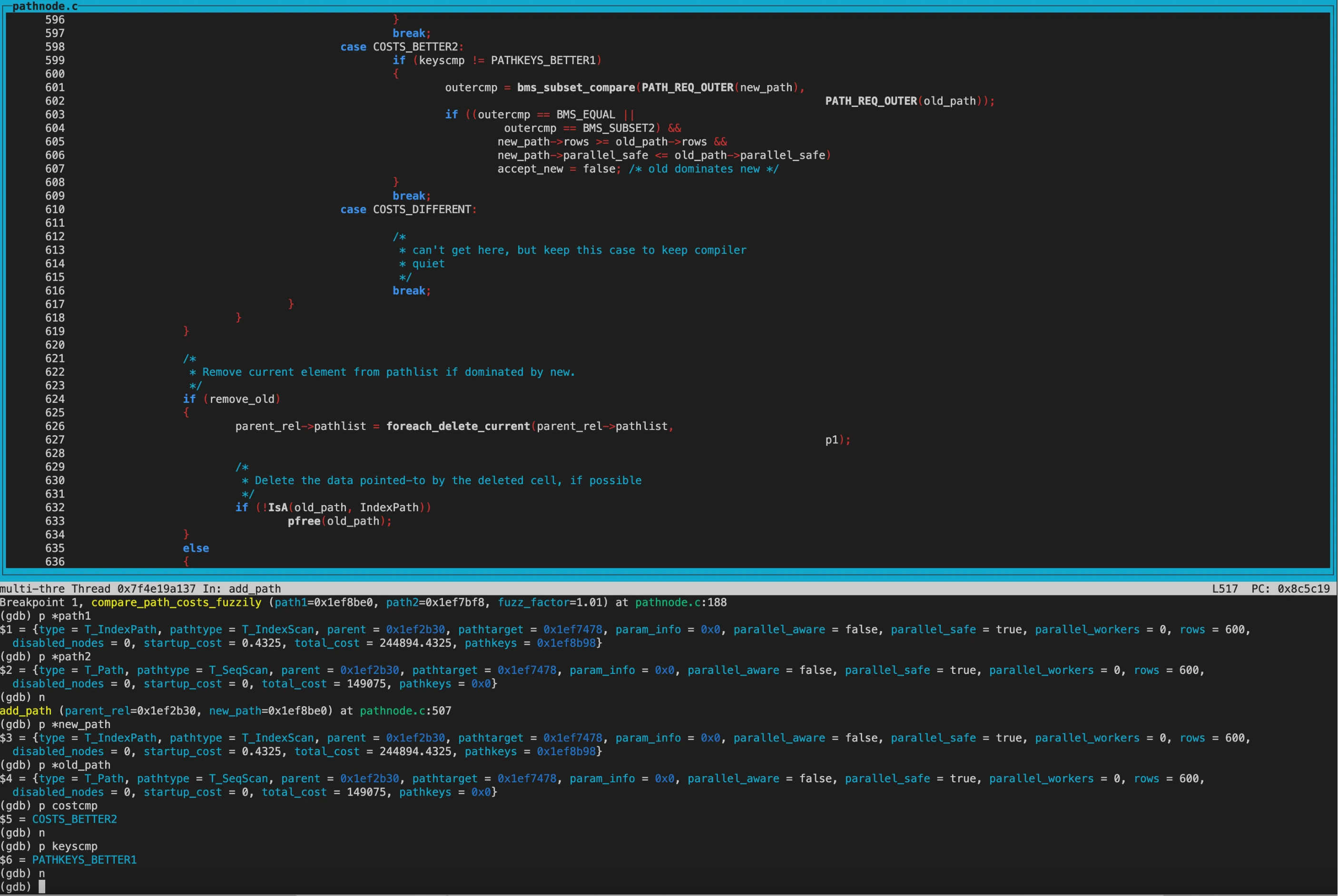
accept_new为true,因此将Indexscan加入pathlist。
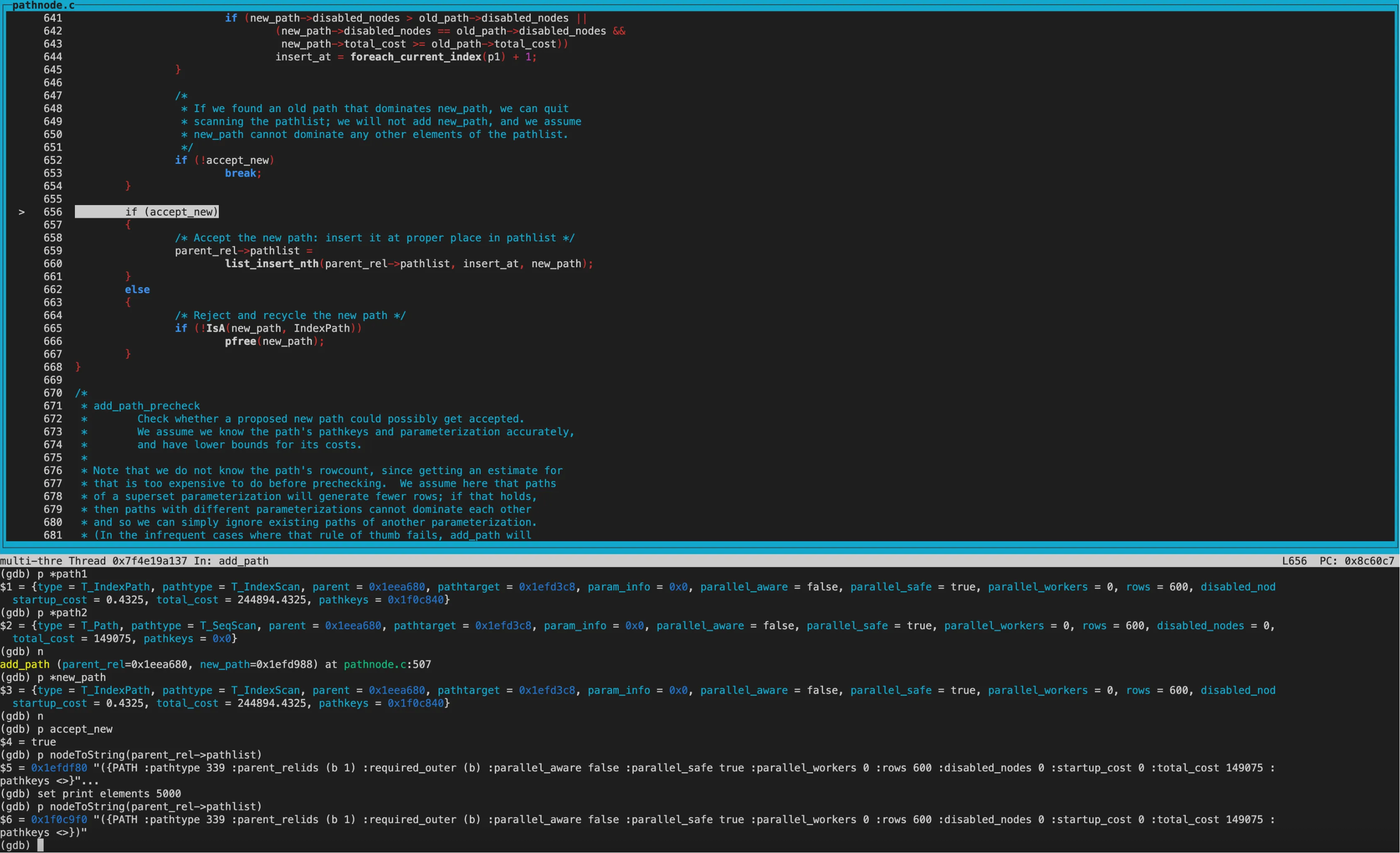
再来看new_path为BitmapHeapScan,old_path为IndexScan的cost模糊比较。
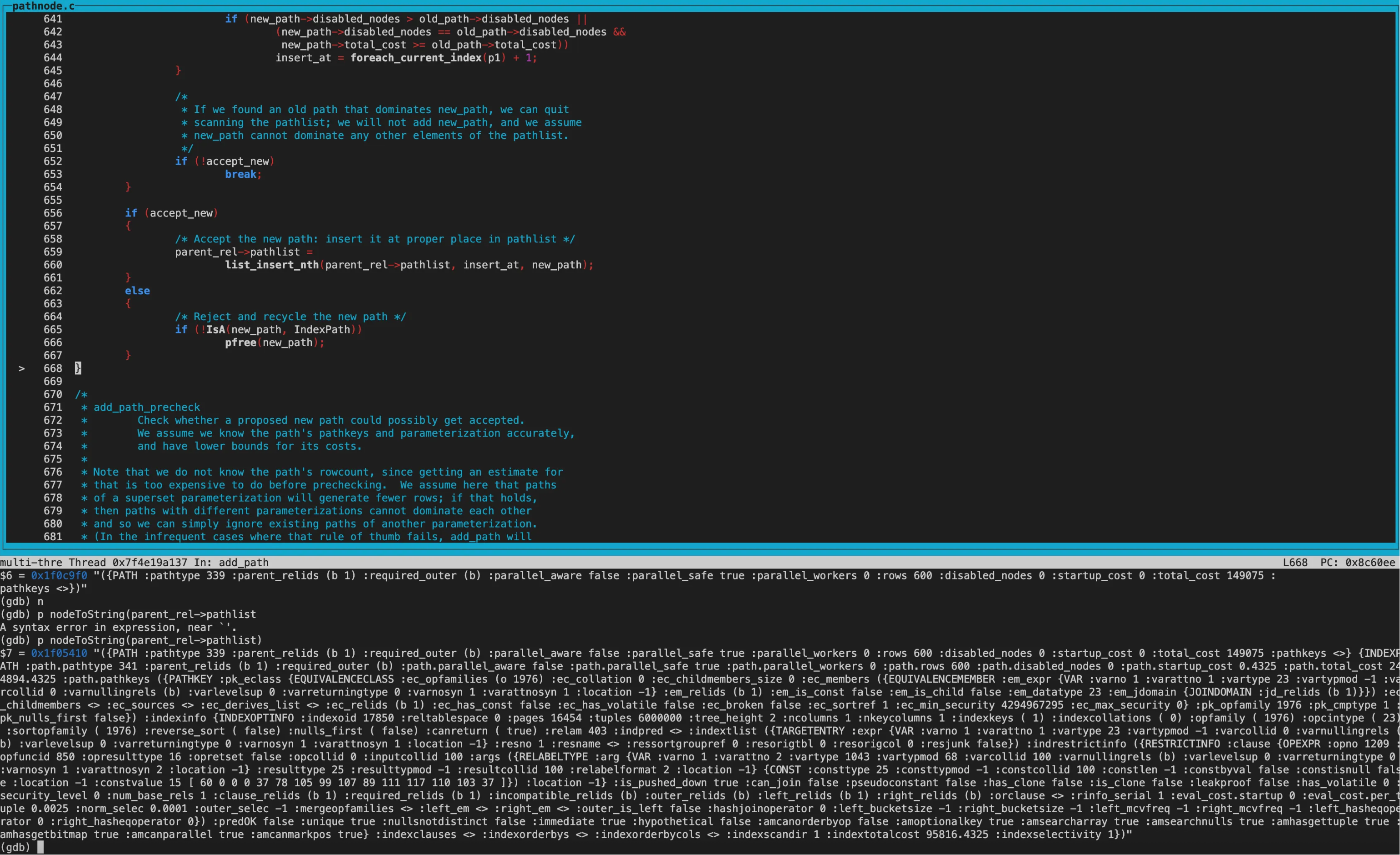
disabled_nodes相同,均为0。接着比较total_cost,new_path的total_cost优于old_path,但startup_cost更大。因此返回COST_DIFFERENT,两个path都保留。
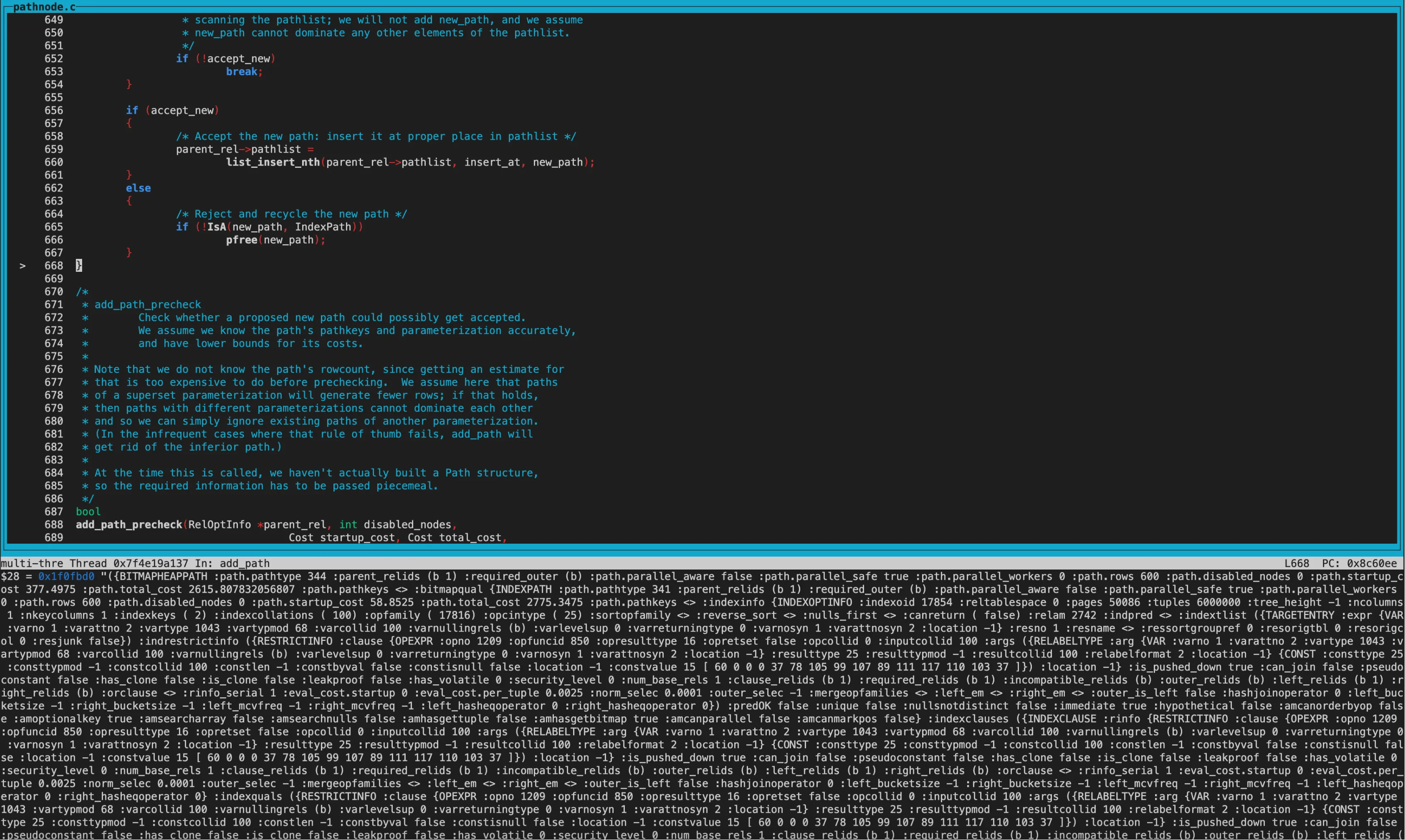
3、hint的处理
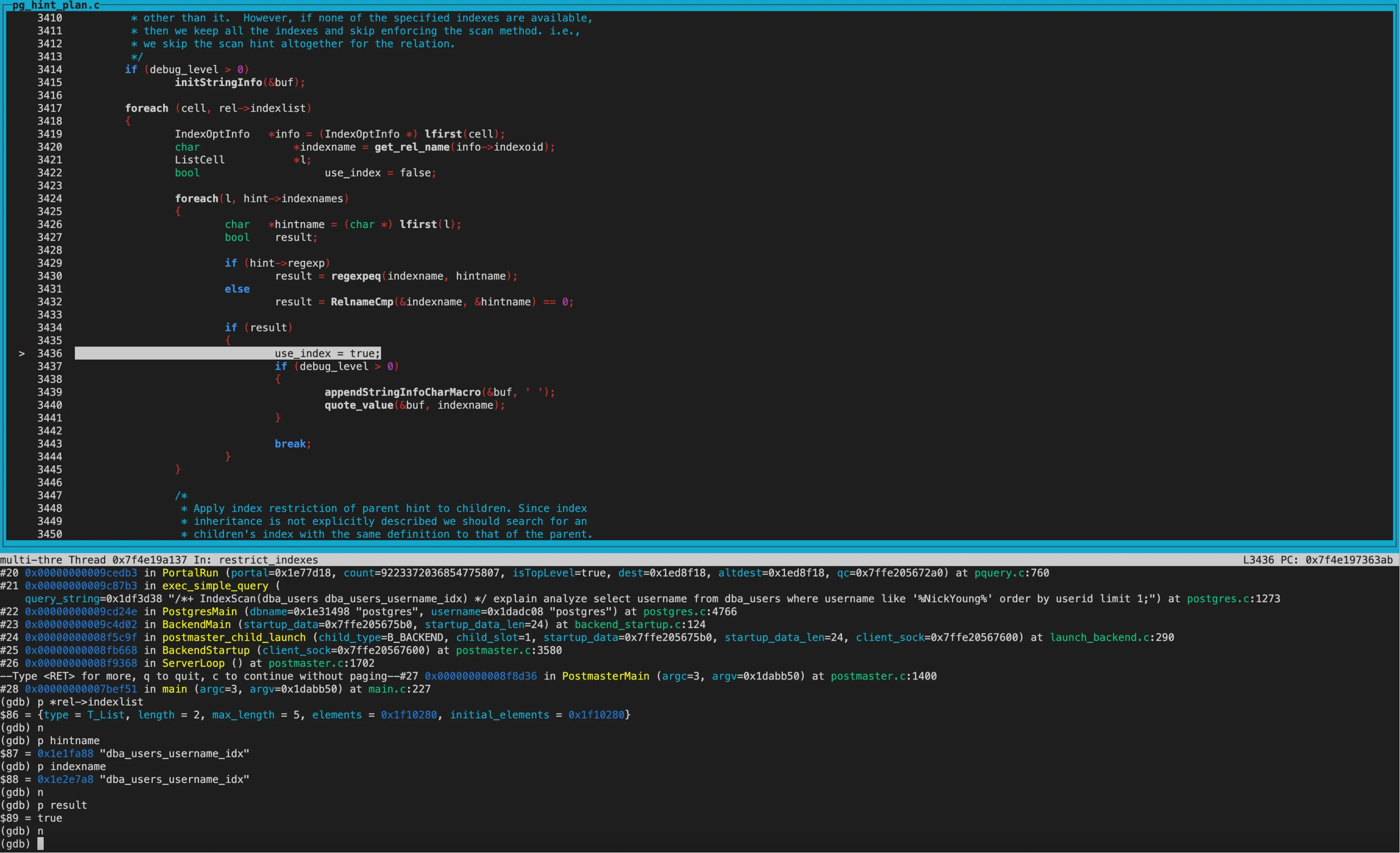
修改Indexlist:
hint为:/*+ IndexScan(dba_users dba_users_username_idx) */
在restrict_indexes函数中第一次遍历indexlist得到的indexname为dba_users_username_idx,和hintname一致,因此标记used_index=true;
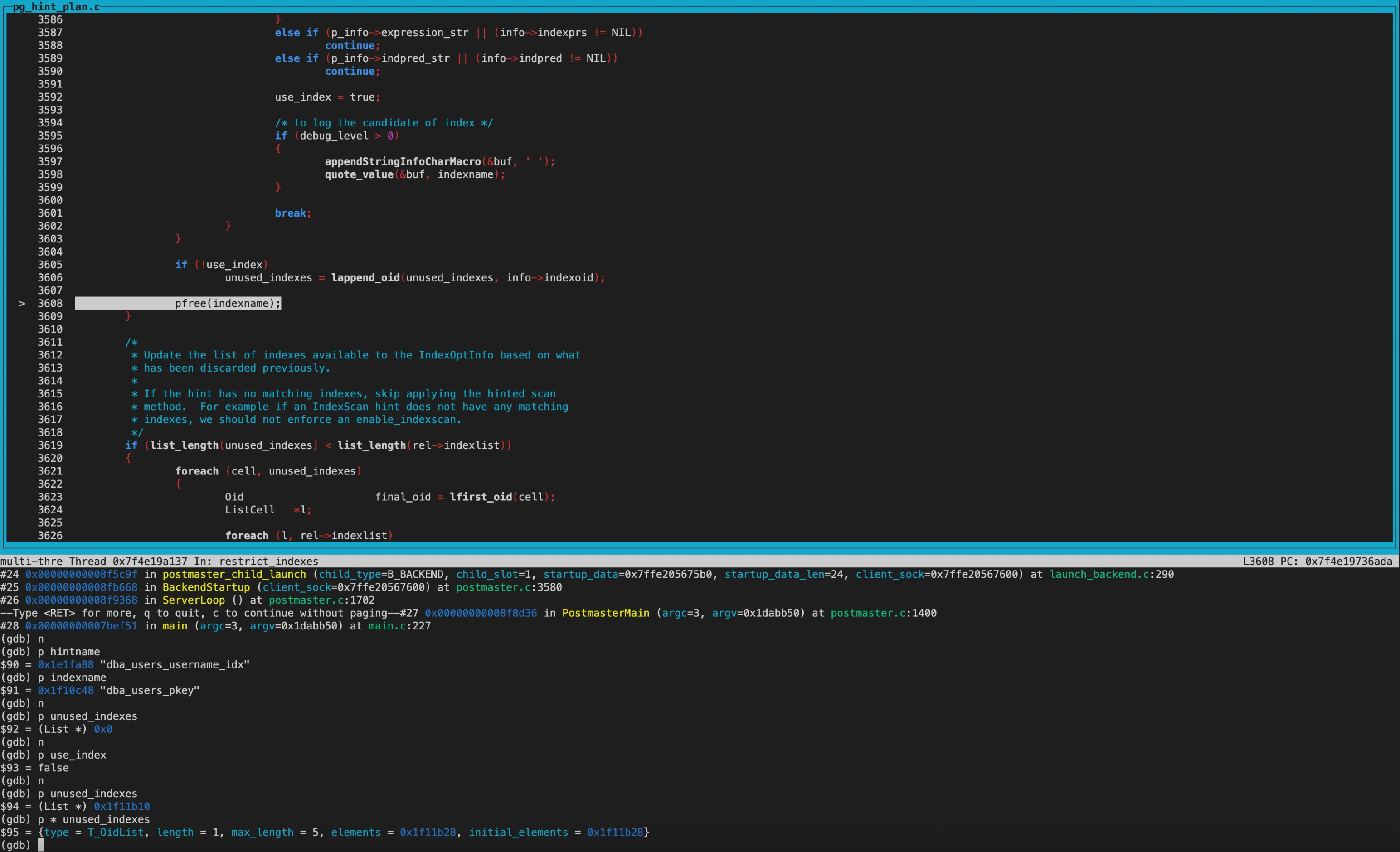
第二次遍历的indexname为dba_users_pkey和hintname不一致,则添加到unused_indexes列表。
然后使用foreach_delete_current函数将unused_indexes从rel->indexlist中剔除。 剔除后indexlist仅剩一个member,即dba_users_username_idx这个gin索引。
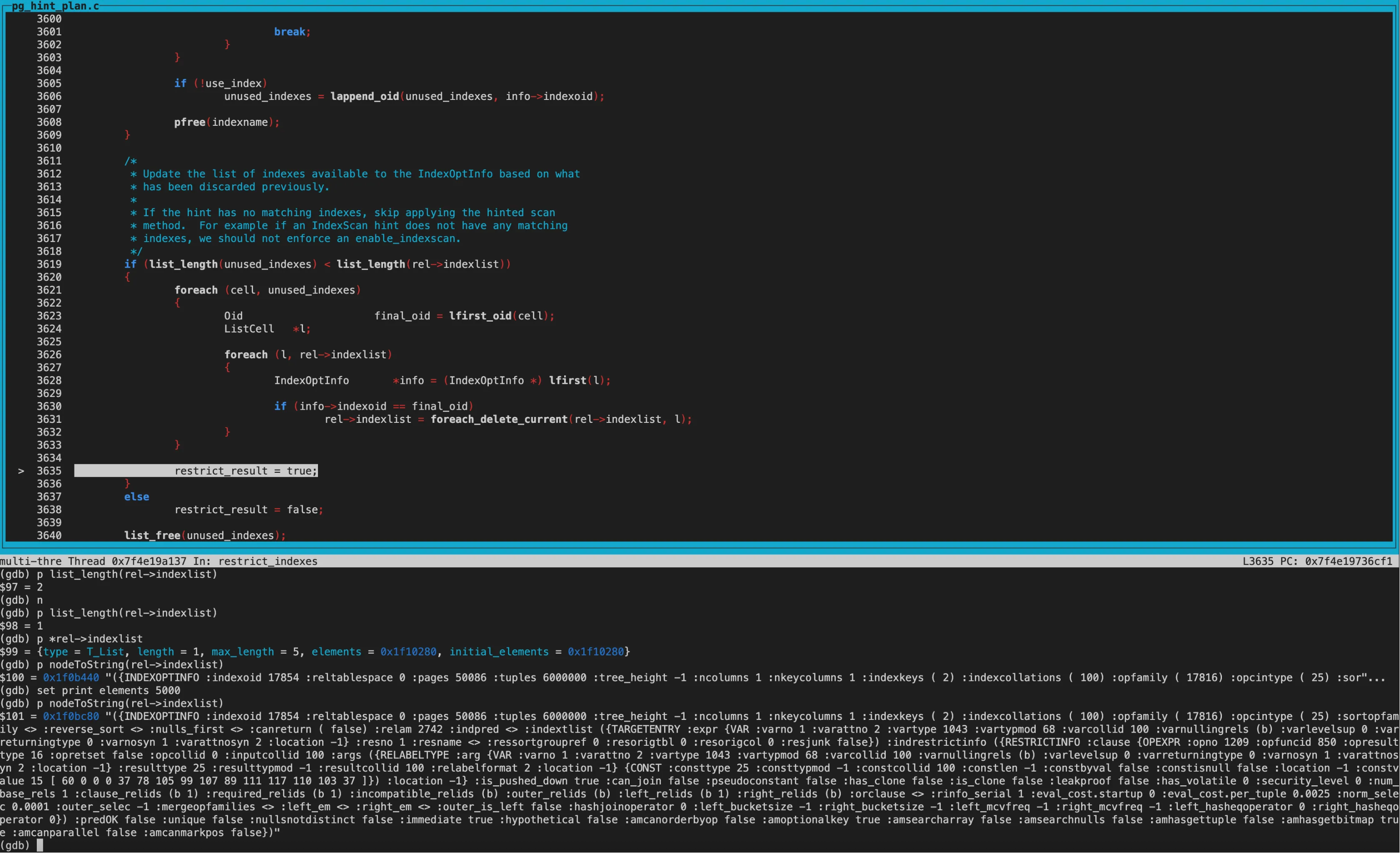
设置disabled_nodes:
除enable_indexscan外,其他方式设置为off,即为其他方式设置disabled_nodes。
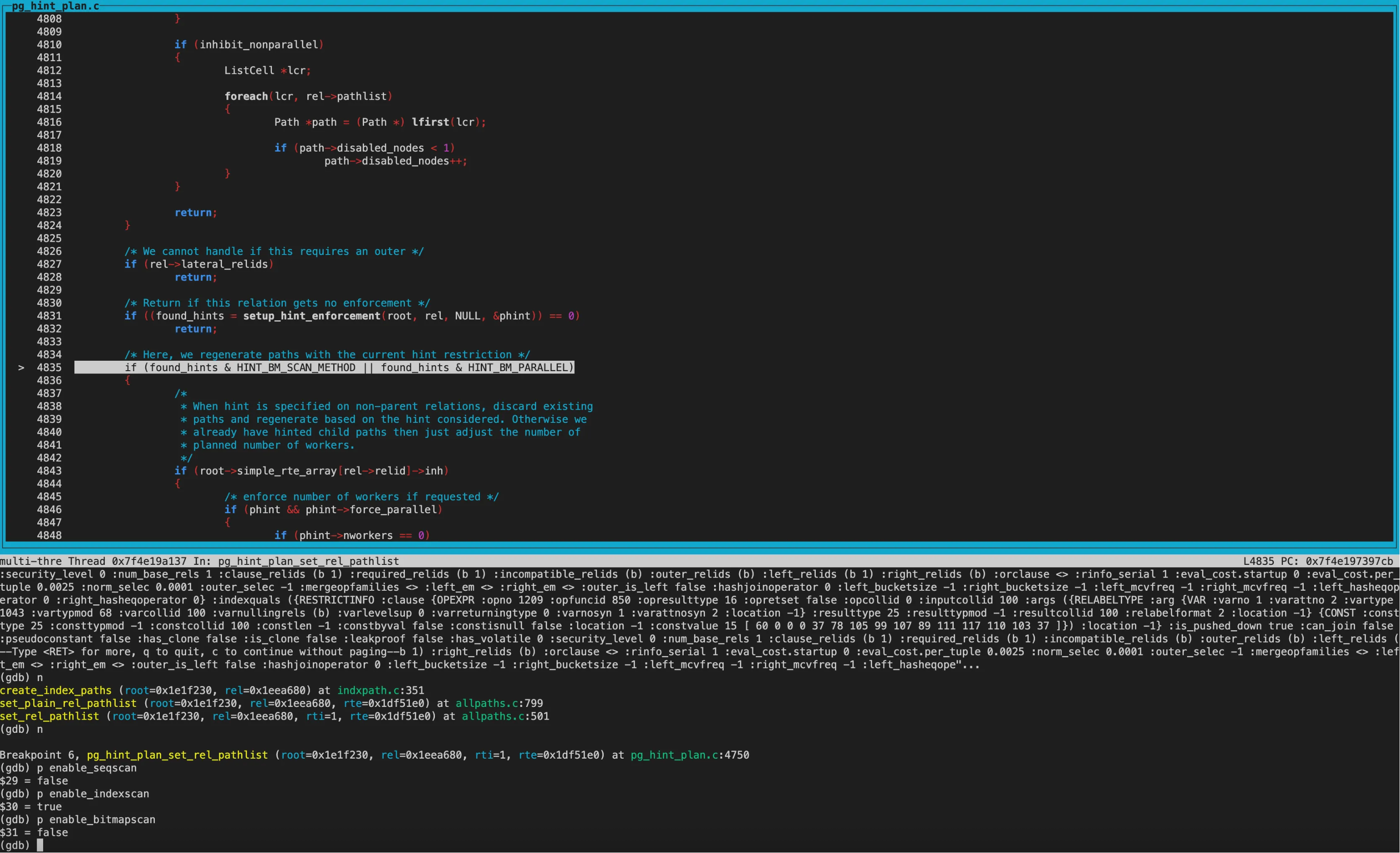
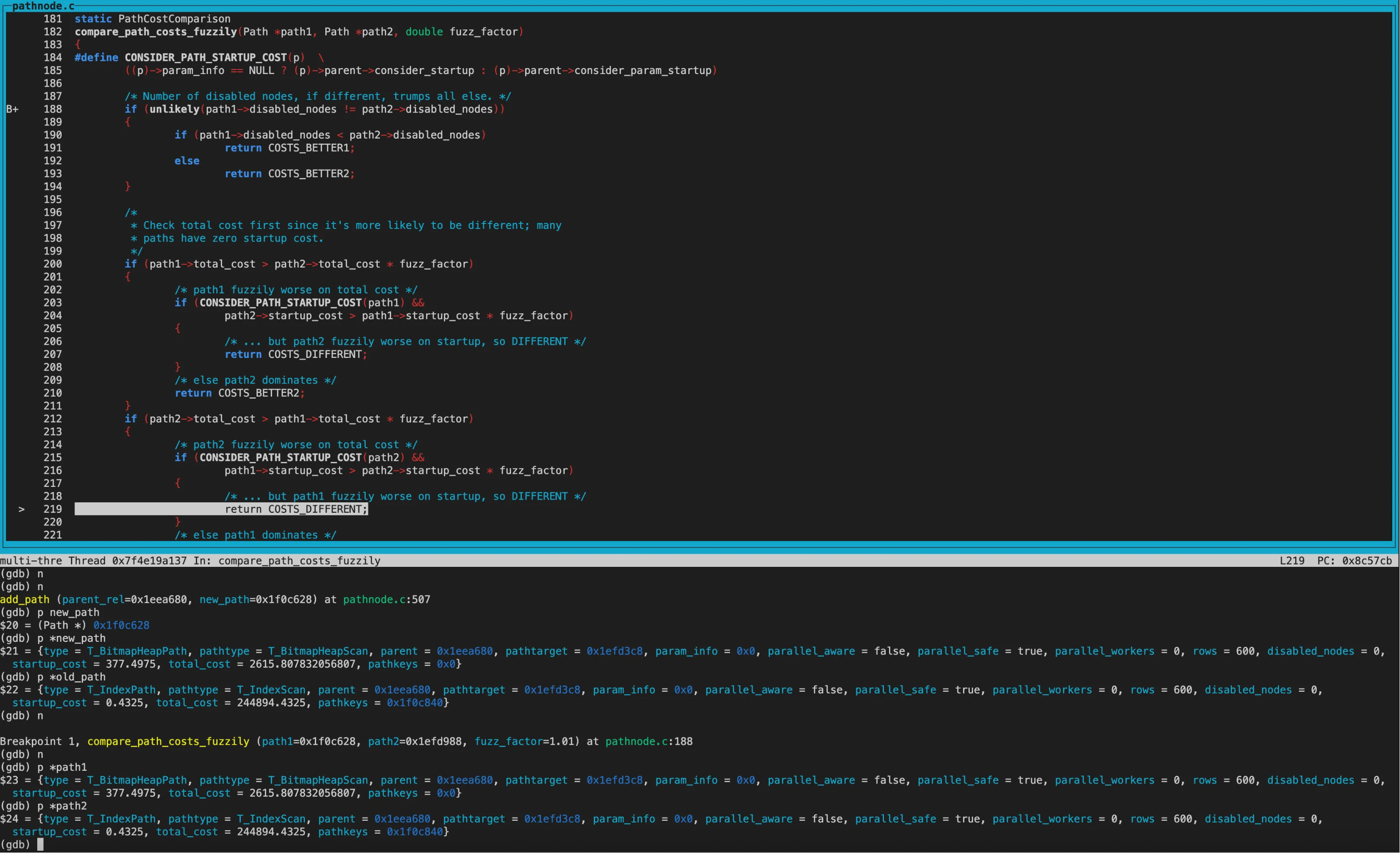
再次进行cost模糊比较,两个path的disabled_nodes相同,都为1。接着比较tocal_cost,两个path的total_cost及startup_cost的大小关系相反,因此返回COST_DIFFERENT,这两条path都保留。
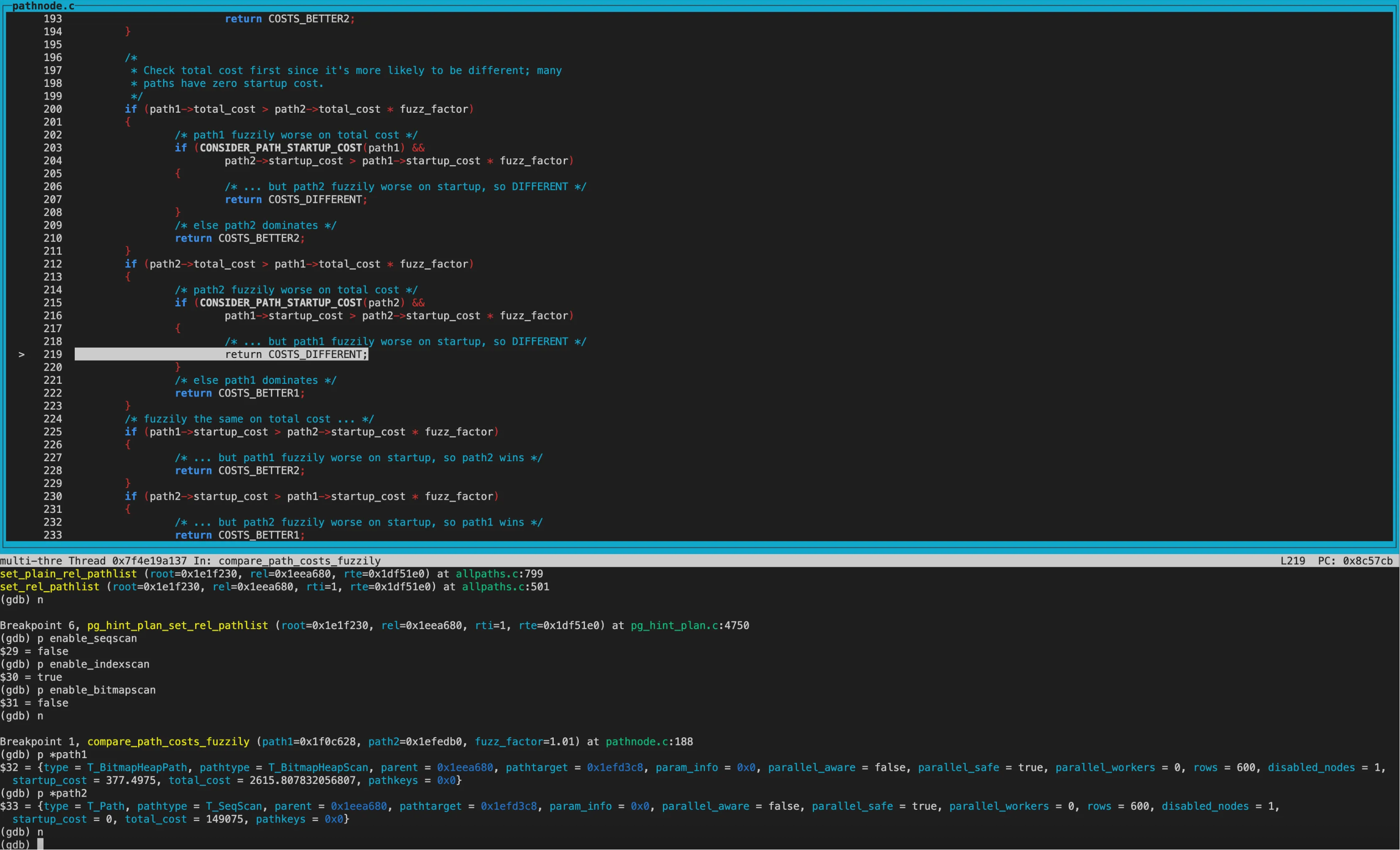
经过hint处理后,对于rel_pathlist就剩下SeqScan和BitmapHeapScan两个path。
4、最小代价选择
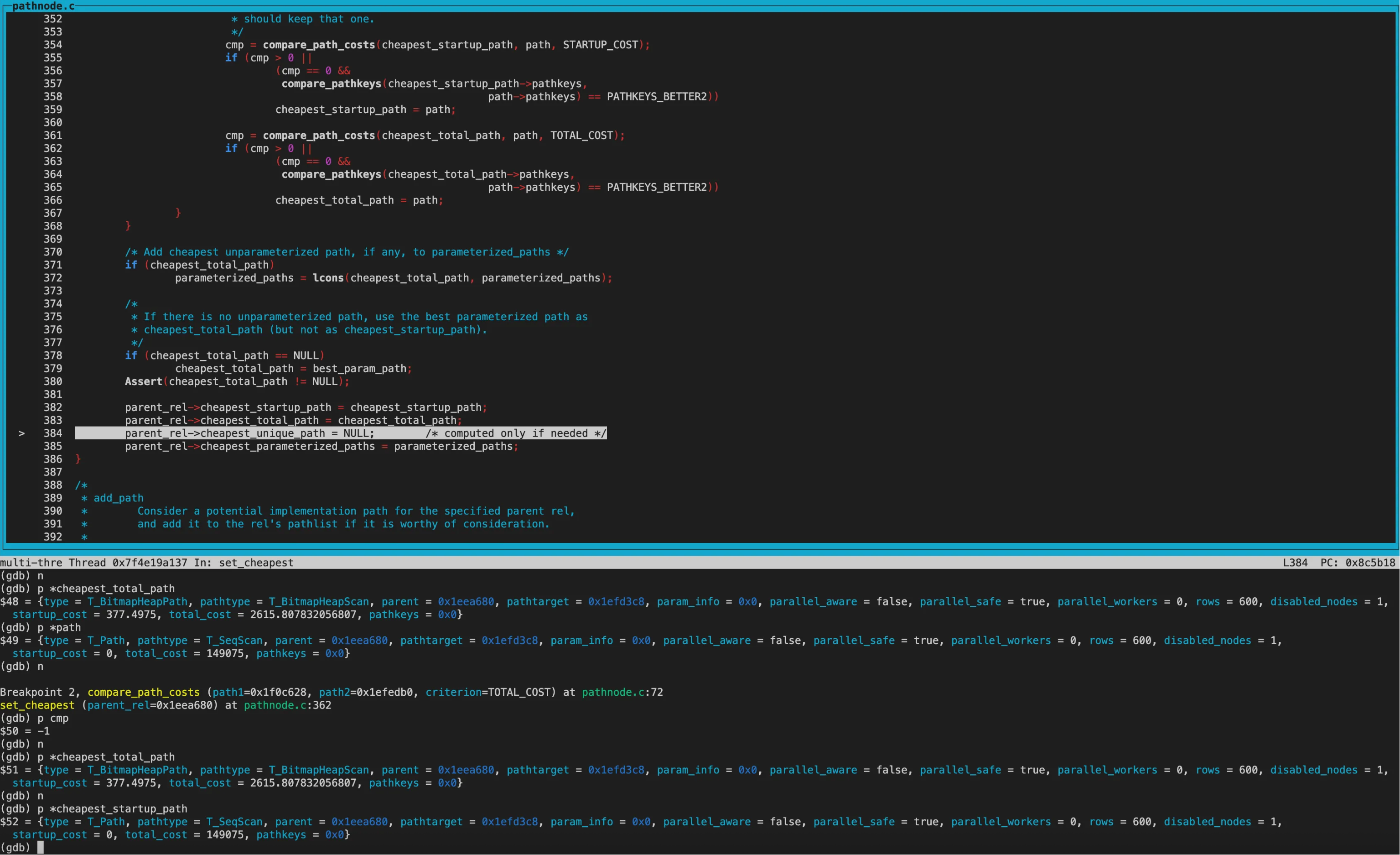
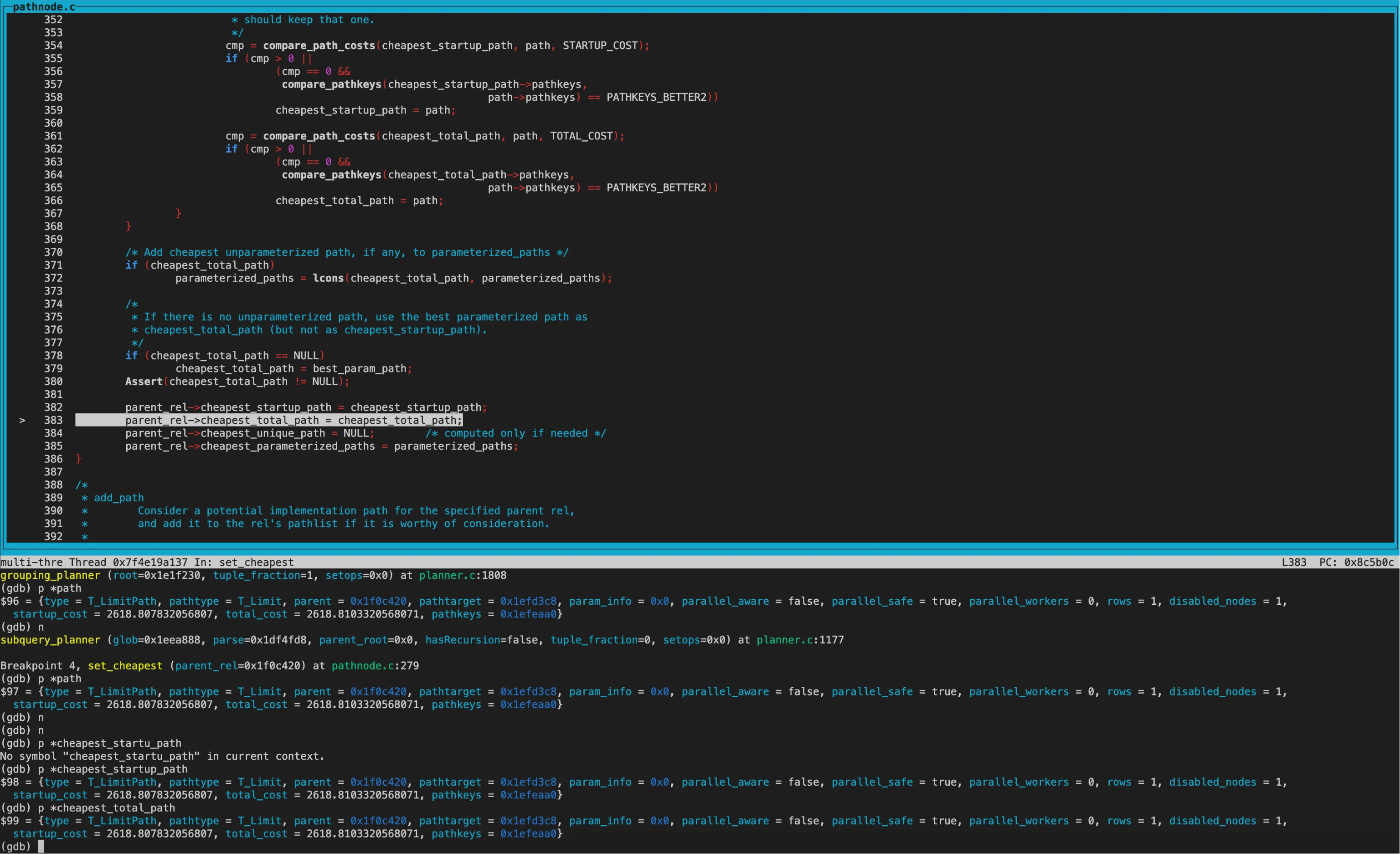
set_cheapest:
经过几轮调用compare_path_costs(精确比较)
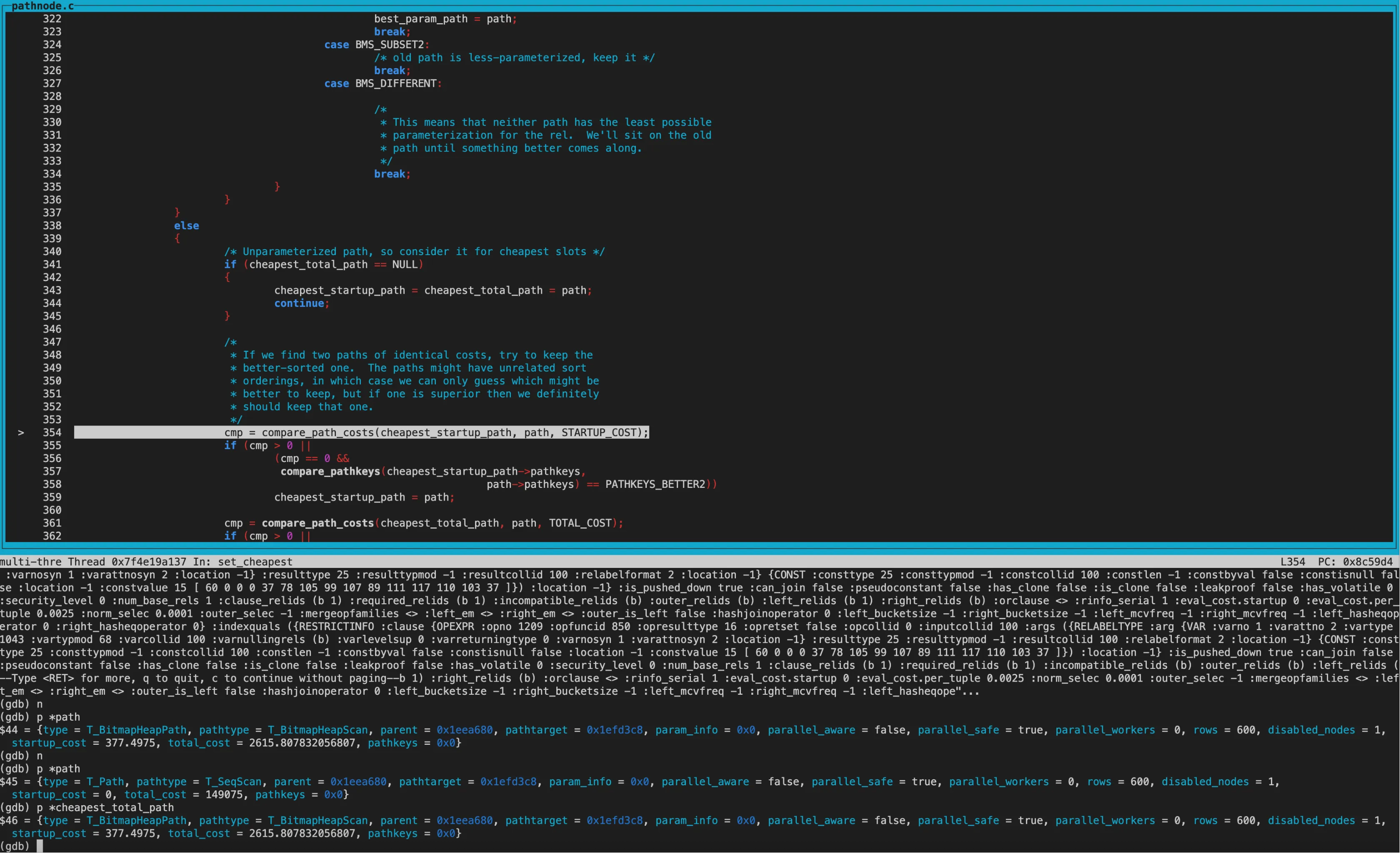
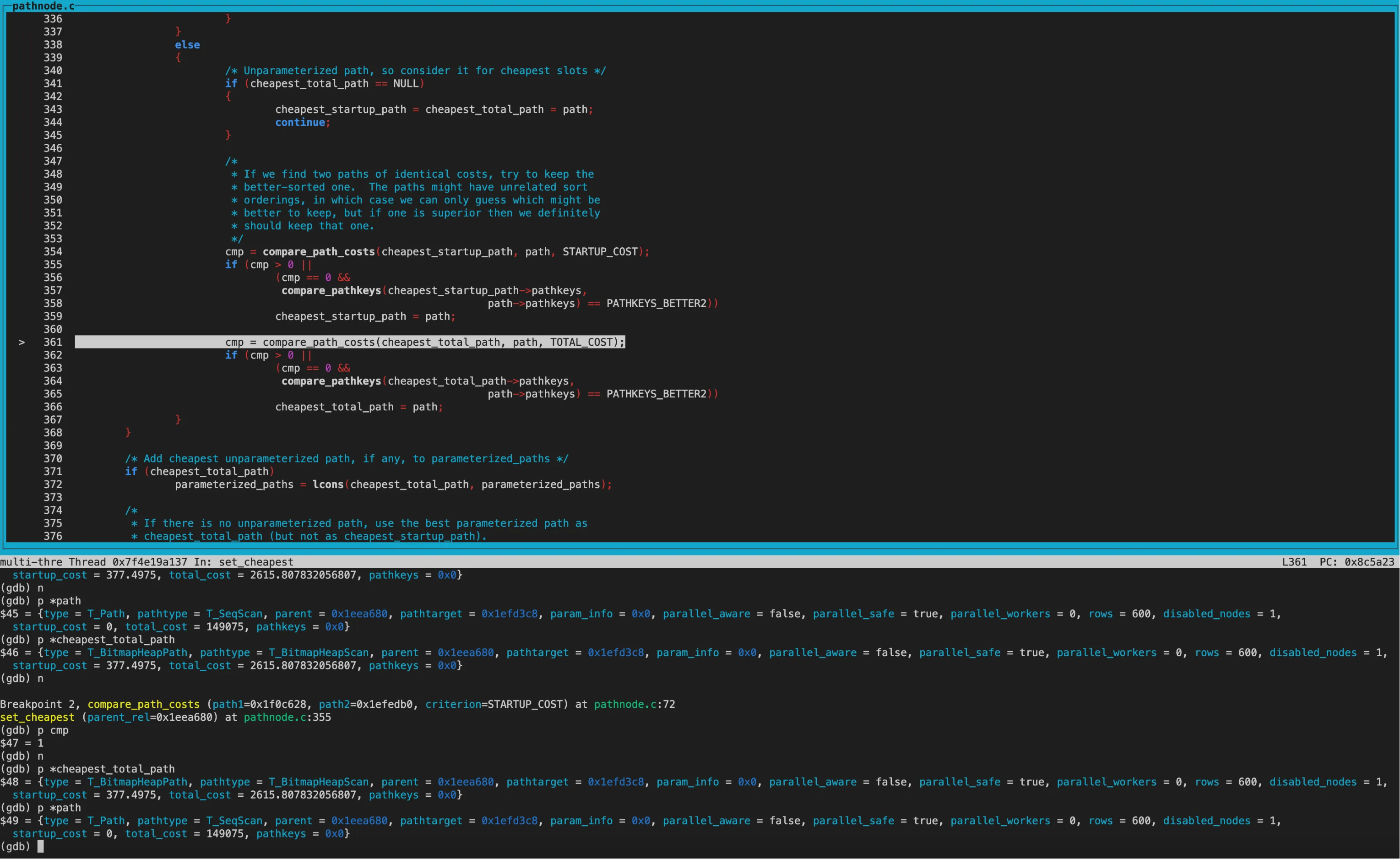
得到cheapest_startup_path为SeqScan,startup_cost为0; cheapest_total_path为BitmapHeapscan,total_cost为2615.81
后续还进行了Sort、GatherMerge等node的代价比较, 最终保留Sort并加入pathlist。
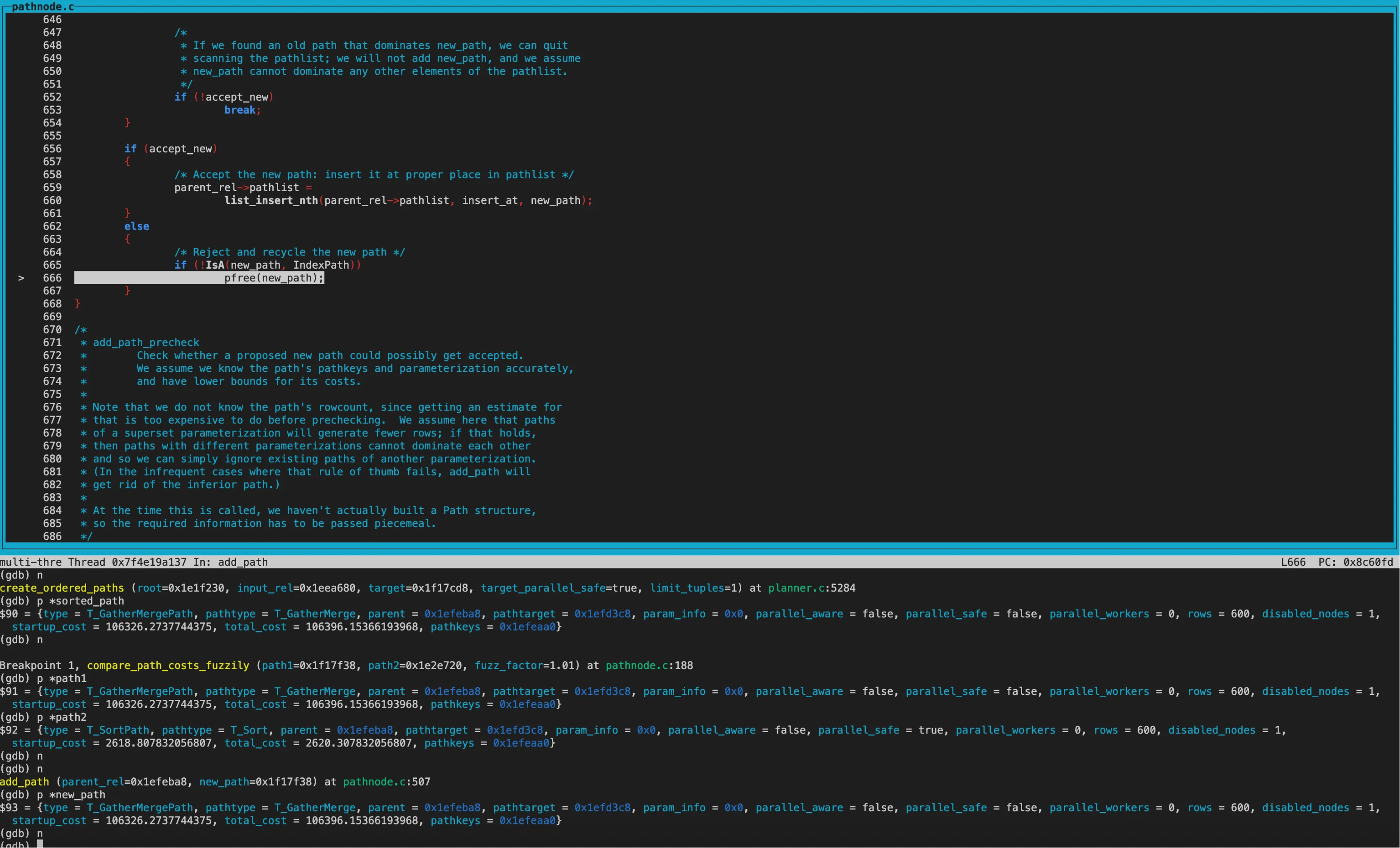
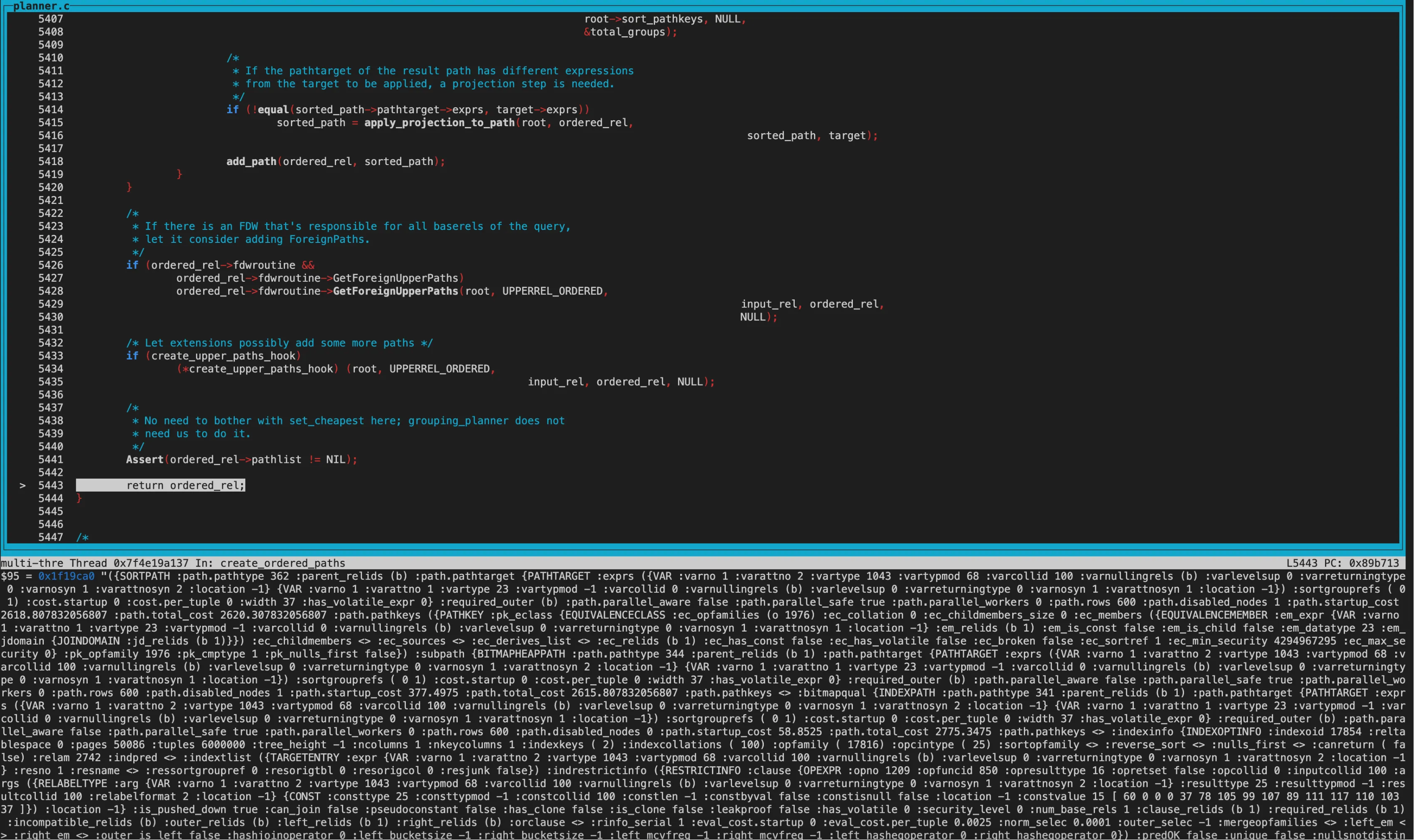
接下来就是创建limit节点了。
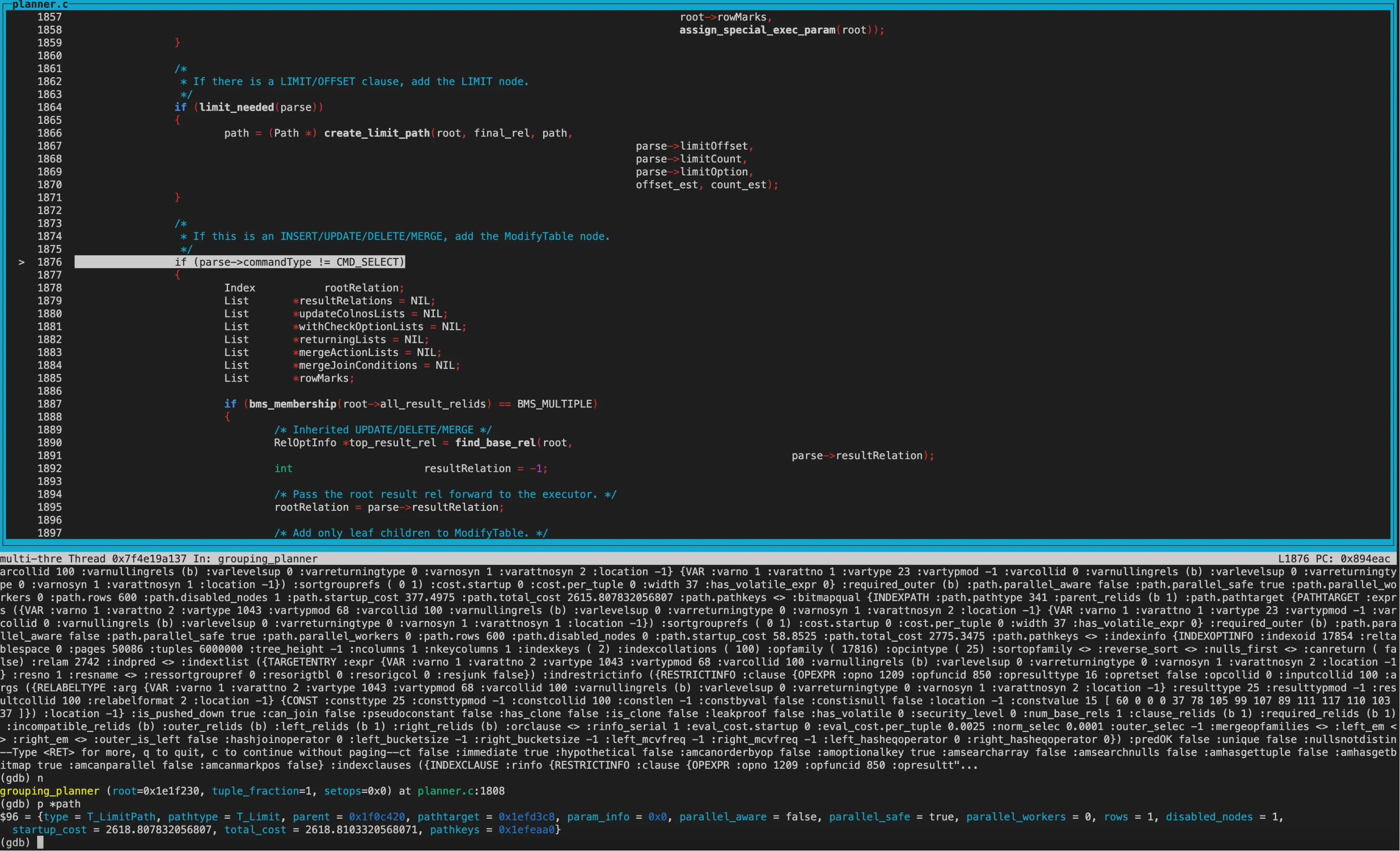
创建好Limit节点后,进行了几轮cost精确比较,cheapest_startup_path和cheapest_total_path均为Limit,startup_cost和total_cost均为2618.81
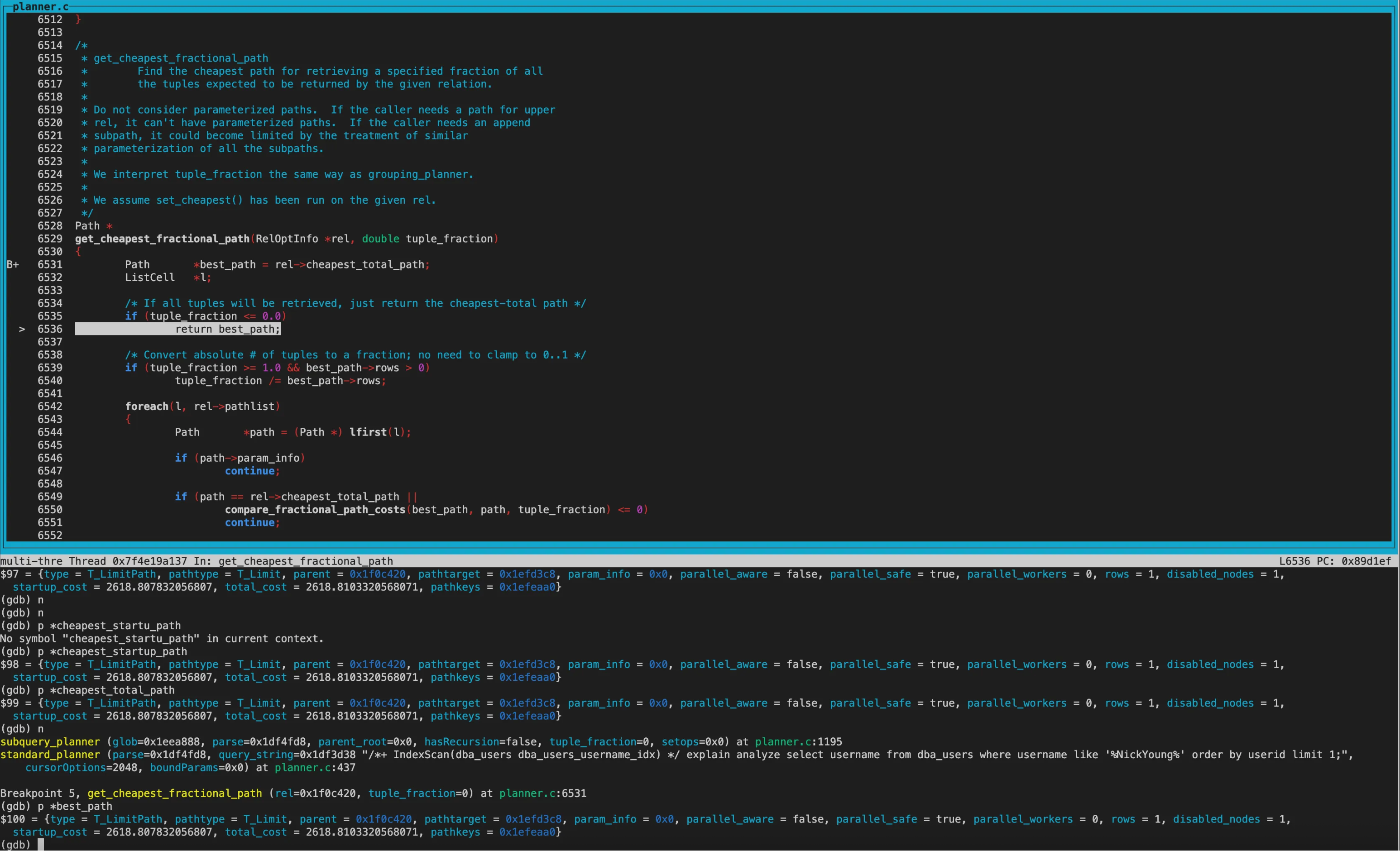
get_cheapest_fractional_path函数中获得best_path。
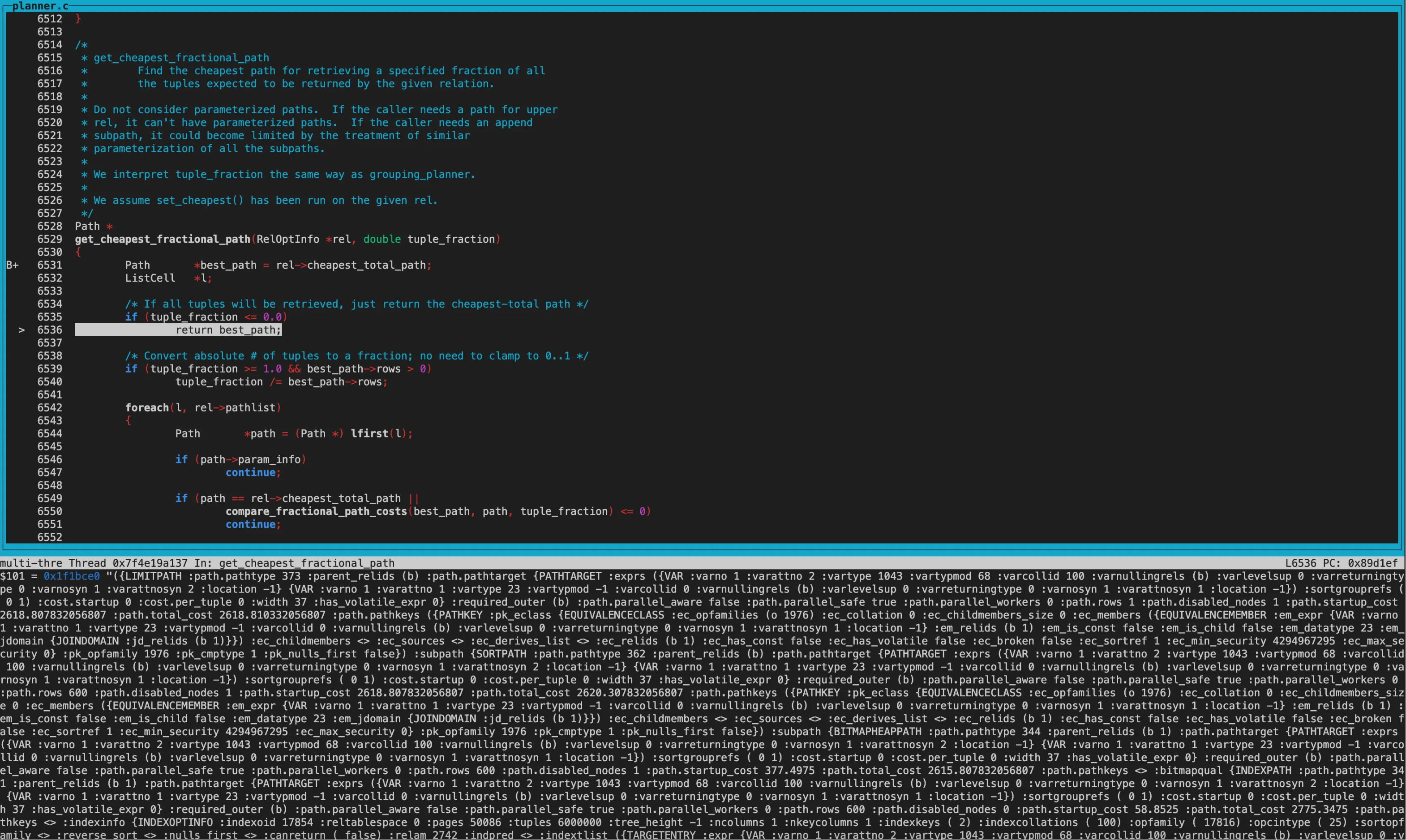
可以看到best_path结构为Limit -> Sort -> BitmapheapScan -> BitmapIndexScan。 并且从各自node的cost来看就是最终的执行计划。
5 总结
从disable_cost到disabled_nodes,给优化器最小代价预估带来了质的飞跃。感谢Robert Haas、Richard Guo、David Rowley几位巨佬,我相信PG会越来越好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号