面向对象第三单元总结博客
面向对象第三单元总结博客
homework9
设计策略-实现相关
本次作业主要要求实现两个类以及一些异常类。异常类几乎都是同质的,都需要支持计数功能,我实现了一个 Counter 类,主要用于实现计数异常总数以及查询单个 id 的异常总数。主要需要实现的类有两个,Network,Person,本次作业中这两次作业中需要实现的方法都比较的简单,基本的查询信息都可以直接将 JML 中描述的操作复现一遍就好了,没有什么架构可言,唯一值得注意的就是 Network 类中的 queryBlockSum 和 isCircle 方法,这两个方法如果用比较暴力的方式实现的话,复杂度是很高的。这两个方法的实现方式(并查集)分析复杂度时再说。
设计策略-架构分析
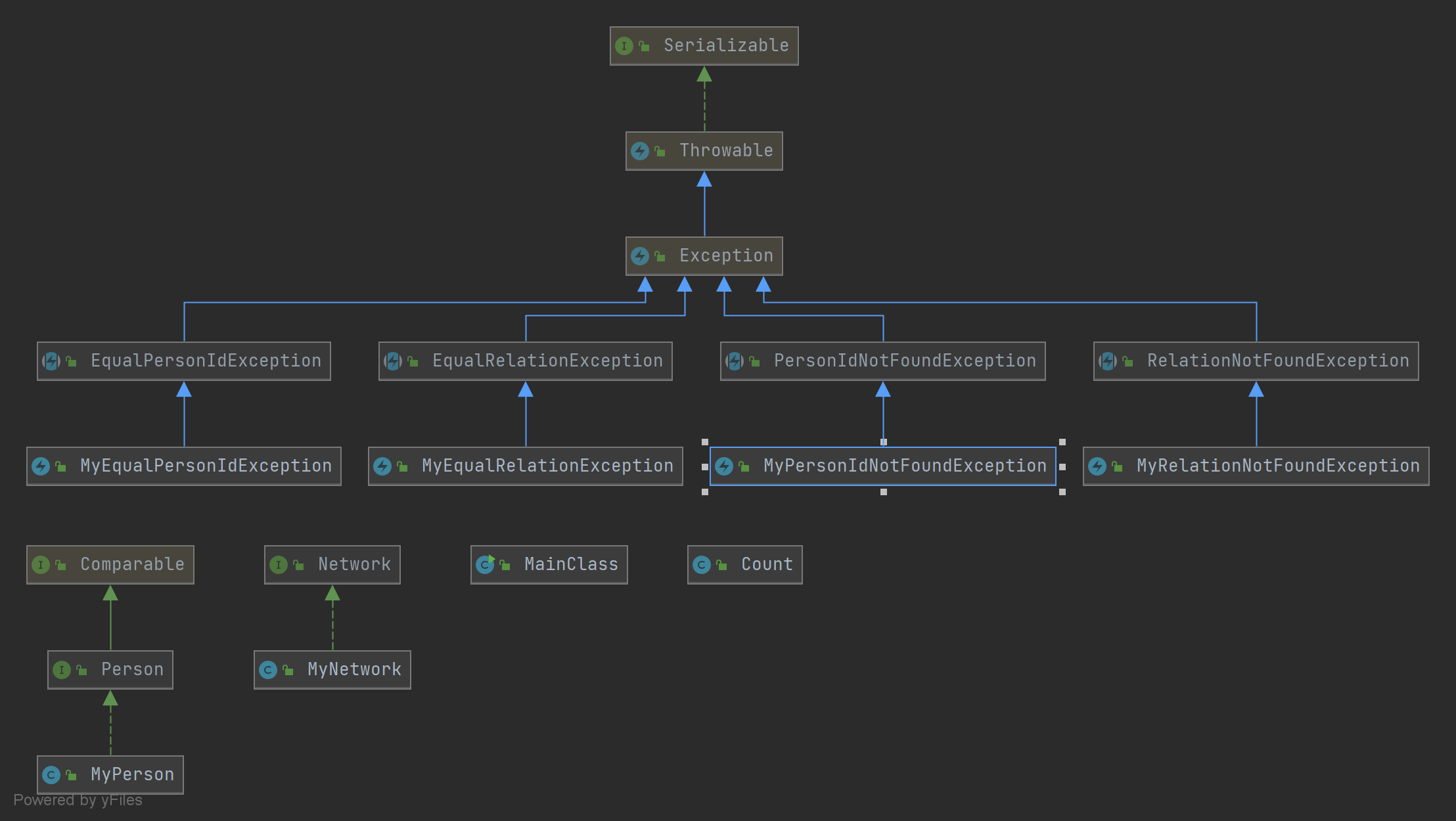
这个架构 emmm……,我敢保证这是我在整个 OO 课程中写的层次最分明的的架构了。从以上架构可以看出,其实我这次作业采用的整体架构与课程组给出的接口架构几乎是完全一致的,而且除了维护并查集以外,其它操作就是将JML 的代码用 java 复现了一遍。所以关于架构实在没啥好说的。
基于JML规格设计测试方法
虽然课程组有推荐使用JUnit,不过看了几个往届学长的介绍,听说这玩意并不好用,所以我也没有用它,而且实话实说,对于简单逻辑,我认为实际上并不需要耗费时间和精力去测试,对于全局代码的随机测试完全可以解决问题。而对于复杂逻辑的分析,就目前技术力来说,基本上不太可能 “给出一个JML 规格,就能严格测出你对于规格的实现到底对不对”,如果真的能够实现,那不是直接让机器人写代码不就好了,反正多复杂的逻辑它都能理解,我失业了。
本单元的测试我主要还是通过海量随机测试和一些性能测试,判断结果是否正确主要基于和室友的代码一同对拍的方式。其实这样测确实不是很科学,但是由于本次作业比较简单,也确实没有出什么问题。
容器选择和使用经验
之前我写 c++ 比较多,所以对于每一种容器的作用以及使用方式有比较熟悉。但是让我比较惊喜的是 java 中的容器真的很多,而且实现的方式也比较的高效。对于这次作业而言,需要的容器需要满足的功能 是十分清晰的,即能 够实现给出 id 属性,找到对应的人即可。这样的操作使用哈希表或者平衡树这样的数据结构即可完成,我本次作业中使用的容器是完全基于平衡树(红黑树)实现的 TreeMap,其实效率最高的容器应该是 HashMap ,java8 中,如果哈希表单个索引对应的列表太长,会将这个列表变成红黑树,这样其实查询复杂度 O(1) 会比完全的红黑树 O(logn) 优秀。但是TreeMap 本身就拥有十分优秀的复杂度,所以在本单元的作业中,TreeMap 已经足够用了。
性能分析
本次作业并没有出现性能问题。本次作业中大部分查询都是可以按照给出的 JML 规格在 O(n) 复杂度下完成的,对于单次的查询,O(n) 的复杂度完全是可以接受的。正如我上面所说,只需要特别处理两个询问即可,一个是询问两个点是否联通,另一个是询问连通块的个数,其实这两个操作就是并查集的模板。
并查集,是一种能够以一种简单的方式处理出图中各个点联通性的算法。算法的核心思想是将每一个图中联通块的点都合并到一颗树上,每新生成一条边,判断这条边连接的两个点是否在同一个连通块内,如果不在同一个联通块内,则将这两个点所在的树合并,具体操作就是将一棵树根节点的父亲指定为另一颗树的根节点,对于每个点我们记录它的父亲,之后每次向上寻找父亲即可确定每一棵树的根节点。如果两个点拥有相同的根节点,那么这两个节点一定是联通的。
并查集有两个优化,不过这里其实并不需要,一个是为了减少查询根节点的复杂度(原本应该是 O(n) ),可以采取路径压缩的方式,也就是在找根节点的时候将遍历到的每一个点的父节点设置为父节点。由于我们只关心树的根节点,而不关注树的结构,所以这样做对答案正确性不会产生影响。这样降低了树的高度,以后查询的复杂度因此而减少。可以证明路径合并优化后并查集复杂度为 O(logn) 。另一个优化是按秩合并,也就是每次都将较小的树合并到较大的树上,这样也能将复杂度优化到 O(logn),如果两个都加的话,复杂度会变成反阿克曼函数,近似O(1),当然,几乎不用做到这一步。
homework10
设计策略-实现相关
这次作业相较于上一次,区别是加了一个对于 Message 类和 Group 类的维护以及增加了一些新的异常,操作变得比较复杂,对于新加的 Group 类,需要维护它的人数,人的平均年龄和年龄的方差。Message 类大致的作用是维护这个"信息"的类型(分为两种,人发向人,以及人发向 Group)以及查询与之相关的信息。NetWork 中新增对于 Group 类型以及 Message 类型相关方法结果的查询。大半部分操作和上一次操作一样,直接按照 JML 给出的逻辑写即可。对于一些直接实现复杂度比较高的查询,如查询一个 Group 中所有关系的 value 和,我将这些查询拆分为两部,一部分在加边的时候维护,一部分在减边的时候维护。除此之外,这次作业还存在一些“小坑”,比如 addtoGroup 中的判断总人数是否超过 1111,如果没有好好阅读 JML 很难发现这一点。对于一些比较复杂的操作,可以分解操作,不一定要将所有的操作都写在一个地方,可以在 Group 类中加一些方法辅助查询。
设计策略-架构分析
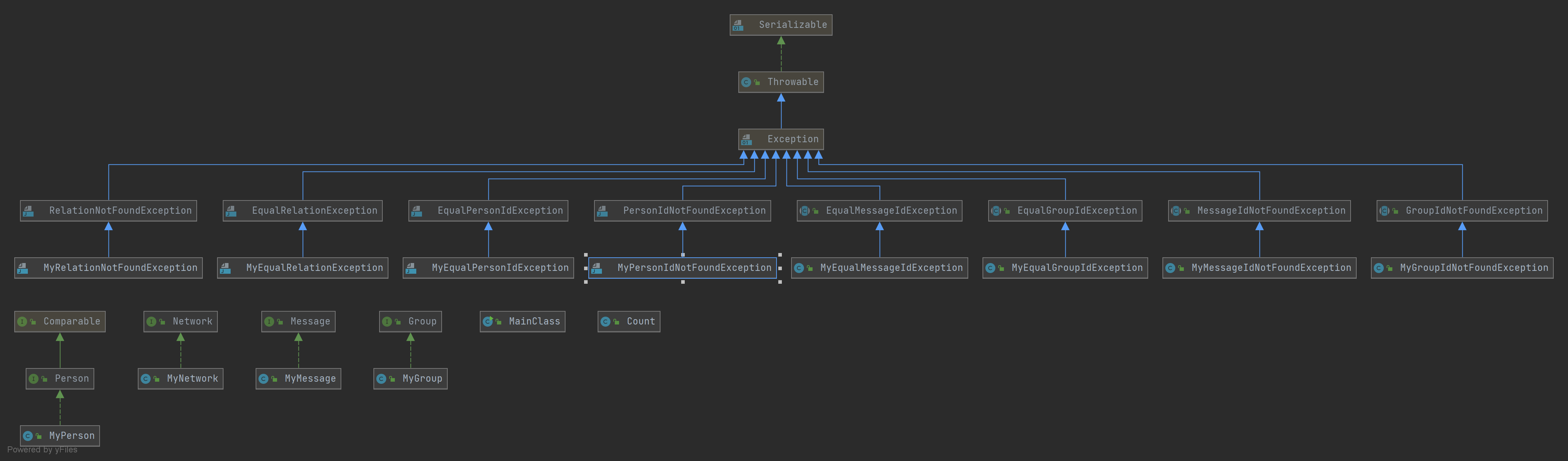
整体类的架构图如上,估计全年级统一架构,除了新加了一个用于计数异常的类,其余完全与课程组要求相同。关于图模型的构建,这次作业与上次作业相同,采用了一种类似于临界表的形式。即在每一个 Person 类中设置一个 HashMap ,用于存储与这个人存在一条边的人的 id 以及他对应的边的权值,此外,我还补充了相关的建边方法。这样的话,每次加边的时候,只需要调用边连接的两人的加边方法即可。
基于JML规格设计测试方法
本次作业的测试方法与上次作业相同,通过一个自动生成数据的 C++ 程序生成随机的数据,通过与室友对拍来判断正确性。只是针对几个特殊的易错点,比如一个group 不能超过 1111 个人做了一些测试,以及基于生成涵盖大量 qgvs指令来测试程序的性能 。
容器选择和使用经验
本次作业中,对于数据维护的基本要求还是要求根据 id ,做到数据的增删改查,除了 Person 类中存储每个人接收到的 message 用的是 Arraylist 之外,全部都是用的 TreeMap 使用这种容器的优势我上面已经说过,这里不再赘述。注意到在方法 sendMessage 中,一个人发给另一个人的 Message 是插入到 Message 集合的前部的,所以这里相对次序也是很重要的,所以这就要求容器也满足能够保存插入顺序的功能,所以这里使用 Arraylist 容器来存储每个人接收到的 Message,每次向后插入,插入的时候从后往前遍历即可。
性能分析
本次作业中除了上次就已经实现了的并查集外,可能影响复杂度的几个新增方法只有查询年龄平均值,查询年龄方差和查询 Group 中关系网的总权值。其中,查询年龄的平均值,直接去求复杂度是 O(n) 的,这样的复杂度本身是足够接受的,考虑到,测试的时候一定是询问比较多,所以考虑可以将其优化成均摊 O(1) 的复杂度,即在每次向 Group 加人和删人的时候都维护 Group 中人的总年龄。对于方差的处理,应该也可以这样,但是这样做就会改变方差原本的公式,考虑到所有结果必须要和 JML 的结果相一致,所以,求方差的时候还是老老实实的按照规格中描述的那样 O(n) 去求。本次作业中 JML 描述的复杂度最高的询问是 qgvs,如果完全按照 JML 描述实现这个方法的话,复杂度高达O(n^2),但是看懂描述后就会发现,其实这就是一个询问一个 group 中所有边之和然后乘 2 的操作,可以通过在加 group 和将人从 group 中去掉的时候动态维护一个答案,这样复杂度就被均摊成了 O(n),每次 qgvs 的查询的复杂度都是 O(1) 的。这样子维护还存在着一个坑点,即如果加边操作是在一个 group 中加的话,也需要维护边权和的值,而且需要注意不是一个人只能在一个 group 中,一个人可能在多个group 中,所有可能的情况都需要查询。
homework11
设计策略-实现相关
JML最后一次作业,相较于前几次的改动基本是换汤不换药的,新加了对于 message 类型的分类,给人增加了一个属性:钱的数量,钱的数量可以通过 send_message message (类型是红包型)改变。NetWork 中新增对于表情 emoji 以及每一种 emoji 的数量的维护。这些都和之前一样,按照 JML 规格规定的去维护即可,没有什么特别的地方。比较有意思的地方,就是新增了一个求最短路的操作,可以用 dijsktra 算法解决。
设计策略-架构分析
本次作业中关于图的建立和维护与前两次作业差别无二,整体架构继续延续官方架构,只是在其中加上了一些方法实现了一些算法,比如 dijsktra ,并查集等。
基于JML规格设计测试方法
本次测试我方法沿用了上几次的方法,但是增加了参与互测的人数,加强了对于性能方面的测试,主要测试最短路算法的正确性以及删除表情操作是否做的正确。
容器选择和使用经验
在本次作业的 JML 代码中,用了两个容易来维护 emoji ,我将其整合成了一个容器,HashMap ,同时起到维护emoji 的 id 和 emoji 的数量的作用。其余容器基本沿用前几次作业的。值得注意的是,这次作业中有一个删除 emoji 以及包含该emoji 的 message 的操作。对于容器中内容的删除不能一遍遍历一遍删除,这会触发 CurrentModification 错误。对于从一个容器中删去满足一定条件的值的元素的方法,可以使用 removeIf 方法,这样不会触发报错,或者直接使用一种暴力的方式,先将所有需要删去的元素放入一个容器中,再遍历容器进行删除。
性能分析
本次作业主要会出现性能问题的还是 sim 这个指令,这个指令需要我们去求图中两个点之间的最短路。对于最短路算法有很多,弗洛伊德,spfa,dijsktra 等,鉴于这里是求单源最短路而且保证了边权为正数,所以这里采用复杂度最优秀的 dijsktra 算法,采用堆优化的 dijsktra 算法可以达到单次 O(mlogm) 的复杂度,其中 \(m\) 是边的总数,在这次作业下这样的复杂度已经足以承受了。至于实现细节,数据结构课上讲过,应该也没啥难得,就是将普通的 bfs 算法改了一下而已,这里不赘述。
结语
本单元还真是凭一己之力拉低了 OO 课的难度,感觉白嫖了一个单元的分,孩子做了很开心,正好临近期末可以缓解一些其他课程的负担。
本单元的核心是代码规范,具体体现就是用 JML 语言来描述和限制代码的行为。首先,抛开 JML 本身不谈,我认为这样的一个想法是很好的,有对于每行代码的严格规范,程序猿也更容易写出更有针对性,层次更清晰的代码。并且如果对于一个现有的软件系统,如果能够分析出代码中每一个类 or 方法 or 函数的规格,在对代码进行分析时会更加方便很多,结果也更加可信。尽管想法很好,但我感觉这种方法最终耗费的最大资源是人力,这些行为目前只能支持人类来完成,可能根据现有的代码生成相应的规格可以由计算机完成,但是,根据规格来对代码进行进行准确的评审,我觉得几乎是不可能交由机器来完成,只能通过一些十分精通逻辑推导(也就是离散数学那一套)的人来完成。如果能够实现依据规格就能够进行自动评测的系统,那所谓的 “自动debug机” 不就出现了?全世界的程序猿狂喜。所以我认为验证代码的王道还是实际的测试,所谓的形式证明,在真正由机器实现之前,消耗的成本还是巨大的。当然,我也期望未来真的能够自动debug(x)。
最后吐槽一下 JML,这么复杂的机制应用于实际真的可以嘛,如果复杂点的逻辑怕是规格需要用 JML 写本书?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号