
ZooKeeper入门
ZooKeeper入门。
作者:IT王小二
博客:https://itwxe.com
一、ZooKeeper简介
ZooKeeper 致力于提供一个高性能、高可用,且具备严格的顺序访问控制能力的分布式协调服务,是雅虎公司创建,是 Google 的 Chubby 一个开源的实现,也是 Hadoop 和 Hbase 的重要组件。
1. ZooKeeper优点
- 简单的数据结构:共享的树形结构,类似文件系统,存储于内存。
- 可以构建集群:避免单点故障,3-5 台机器就可以组成集群,超过半数正常工作就能对外提供服务。
- 顺序访问:对于每个读请求,ZooKeeper 会分配一个全局唯一的递增编号,利用这个特性可以实现高级协调服务。
- 高性能:基于内存操作,服务于非事务请求,适用于读操作为主的业务场景,3 台 ZooKeeper 集群能达到 13w QPS。
2. 那些场景可以使用
- 数据发布订阅
- 负载均衡
- 命名服务
- Master 选举
- 集群管理
- 配置管理
- 分布式队列
- 分布式锁
二、ZooKeeper安装
ZooKeeper的安装配置不论是单机安装还是集群(或者集群伪分布)都是非常的简单。
首先准备工作
- Linux 需要安装配置jdk环境。
- 从 ZooKeeper官网 下载 ZooKeeper 安装包,然后上传至Linux,我上传在
/usr/local目录下。
下面的内容都是基于 CentOS7 安装ZooKeeper(3.4.12)。
1. 单机安装
1、解压压缩包。
tar -zxvf zookeeper-3.4.12.tar.gz
2、进入解压的目录,将配置文件zoo_sample.cfg复制一份为zoo.cfg,因为 ZooKeeper 启动时默认配置文件为zoo.cfg,当然你也可以指定配置文件 zoo_sample.cfg 启动(命令:./zkServer.sh start ../conf/zoo_sample.cfg)。
cd zookeeper-3.4.12/conf
cp zoo_sample.cfg zoo.cfg
3、修改 zoo_sample.cfg 配置文件的 dataDir 属性,这里存放了 ZooKeeper 的快照文件,根据自己的需求修改,如果定义的目录不存在需要先创建出来。
vim zoo.cfg
dataDir=/usr/local/zookeeper-3.4.12/data
4、进入解压目录 zookeeper-3.4.12 下的 bin 目录,启动 ZooKeeper,相关命令如下:
启动命令:./zkServer.sh start
停止命令:./zkServer.sh stop
重启命令:./zkServer.sh restart
状态查看命令:./zkServer.sh status
5、启动后,可以查看一下状态是否启动成功,然后使用命令行进行登录操作,之后就可以尝试使用 ZooKeeper 的命令行了,命令操作再后面介绍。
./zkCli.sh -server 192.168.182.130:2181
2. 集群安装
集群伪分布就是在一台服务器上面部署多个ZooKeeper,这里就不使用 集群伪分布 来示例了,之前 Redis 有使用过集群伪分布,集群伪分布就是通过配置文件端口号区别多个ZooKeeper,集群最好以奇数个为佳。
过程如下
1、不使用集群伪分布,那么首先准备好三台Linux服务器,我这里使用了三个虚拟机CentOS7,ip分别为:192.168.182.130、192.168.182.131、192.168.182.132,同时开放 2888 和 3888 这两个端口访问,不然集群无法相互通信,查看状态一直为 ERROR。
2、然后还是和单机安装一样,解压安装文件,复制配置文件,修改配置文件,不过配置文件还需要增加一个集群配置,贴出我的配置,其中:2888:集群内机器通讯使用(Leader监听此端口);3888:选举leader使用。
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper-3.4.12/data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# 增加的集群配置
server.0=192.168.182.130:2888:3888
server.1=192.168.182.131:2888:3888
server.2=192.168.182.132:2888:3888
3、配置好 192.168.182.130 这台服务器的配置文件之后,还需要做一件事情,在配置的 dataDir=/usr/local/zookeeper-3.4.12/data 目录下生成一个myid文件,分别对应上面配置中的server.0、server.1、server.2,例如 192.168.182.130 对应的就是 0 。
echo 0 > myid
4、将 zookeeper-3.4.12 这个目录使用 scp 命令远程复制到 192.168.182.131 和 192.168.182.132这两个服务器的 /usr/local 目录下,远程复制碰到登录密码输入即可,当然,你也可以使用其他工具复制。
scp -r /usr/local/zookeeper-3.4.12 root@192.168.182.131:/usr/local
scp -r /usr/local/zookeeper-3.4.12 root@192.168.182.132:/usr/local
5、前面提到 192.168.182.130 对应配置文件中的 0,那么 192.168.182.131 对应的就是 1,192.168.182.132 对应的就是2,所以还需要在这两台服务器上 分别更改 myid 文件内容。
echo 1 > myid
echo 2 > myid
6、最后分别启动每个服务器上的 ZooKeeper 就可以了,分别启动后可以查看一下三台服务器节点的状态,如果显示 Mode: follower 或者 Mode: leader 则代表集群成功,可以使用以下命令行工具查看效果。
3. ZooKeeper安装目录结构
- bin:存放系统脚本
- conf:存放配置文件
- contrib:附加功能支持
- dist-maven:maven 仓库文件
- docs:文档
- lib:依赖的第三方库
- recipes:经典场景样例代码
- src:源码
其中 bin 和 conf 是非常重要的两个目录,平时也是经常使用的。
bin目录
常用的两个:zkServer.sh 为服务端,zkCli 为命令行客户端。
conf目录
主要是配置文件的参数,其中几个比较重要的如下:
- clientPort:访问端口,即应用对外服务的端口。
- dataDir:用于存放内存数据库快照的文件夹,同时用于集群的 myid 文件也存在这个文件夹里(注意:一个配置文件只能包含一个 dataDir 字样,即使它被注释掉了),新安装这文件夹里面是没有文件的,可以通过 snapCount 参数配置产生快照的时机。
- snapCount:每进行 snapCount 次事务日志输出后,触发一次快照(snapshot), 此时,ZooKeeper 会生成一个
snapshot.*文件,同时创建一个新的事务日志文件log.*,默认是100000(真正的代码实现中,会进行一定的随机数处理,以避免所有服务器在同一时间进行快照而影响性能)(Java system property:zookeeper.snapCount )。 - dataLogDir:用于单独设置 transaction log 的目录,transaction log 分离可以避免和普通 log 还有快照的竞争。
- tickTime:心跳时间,为了确保连接存在的,以毫秒为单位,最小超时时间为两个心跳时间。
- initLimit:多少个心跳时间内,允许其他 server 连接并初始化数据,如果 ZooKeeper 管理的数据较大,则应相应增大这个值。
- syncLimit:多少个 tickTime 内,允许 follower 同步,如果 follower 落后太多,则会被丢弃。
三、ZooKeeper特性
1. 会话
客户端与服务端的一次会话连接,本质是 TCP 长连接,通过会话可以进行心跳检测和数据传输。
会话状态
ZooKeeper 客户端和服务端成功连接后,就创建了一次会话,ZooKeeper 会话在整个运行期间的生命周期中,会在不同的会话状态之间切换,这些状态包括:CONNECTING、CONNECTED、RECONNECTING、RECONNECTED、CLOSE。
一旦客户端开始创建 Zookeeper 对象,那么客户端状态就会变成 CONNECTING 状态,同时客户端开始尝试连接服务端,连接成功后,客户端状态变为 CONNECTED,通常情况下,由于断网或其他原因,客户端与服务端之间会出现断开情况,一旦碰到这种情况,Zookeeper 客户端会自动进行重连服务,同时客户端状态再次变成 CONNCTING,直到重新连上服务端后,状态又变为 CONNECTED,在通常情况下,客户端的状态总是介于 CONNECTING 和 CONNECTED 之间。但是,如果出现诸如会话超时、权限检查或是客户端主动退出程序等情况,客户端的状态就会直接变更为 CLOSE 状态。
2. 数据模型
ZooKeeper 的视图结构和 Unix 文件系统类似,其中每个节点称为“数据节点”或 ZNode, 每个 znode 可以存储数据,还可以挂载子节点,因此可以称之为“树”,需要注意的是,每一个 znode 都必须有值,如果没有值,节点是不能创建成功的。
- 在 Zookeeper 中,znode 是一个跟 Unix 文件系统路径相似的节点,可以往这个节点存储或获取数据。
- 通过客户端可对 znode 进行增删改查的操作,还可以注册 watcher 监控 znode 的变化。
3. 节点类型
zNode有两种节点类型:持久节点(persistent)、临时节点(ephemeral)
第一种:持久节点创建:不须其他参数,value可以为任意值,持久节点客户端断开连接后不会删除。
create /SunnyBear value
第二种:临时节点创建:加上 -e 参数即代表创建临时节点,客户端断开连接后会删除。
create -e /testSunnyBear ephemeralNodeTest
zNode节点有四种形式的目录节点:持节节点、持久顺序节点、临时节点、临时顺序节点
持久节点 和 临时节点 前面已经说了,那么来看下 持久顺序节点 和 临时顺序节点,创建时加上参数 -s 则代表加上了顺序,例如分别创建 持久顺序节点 和 临时顺序节点。
create -s /SunnyBear2 tests
# 返回了Created /SunnyBear20000000008
create -e -s /testSunnyBear ephemeralNodeTest
# 返回了Created /testSunnyBear0000000009
从上面的结果可以看到,顺就节点即在创建的节点名称后面加上了序号,并且同时需要注意的是,create 命令如果不是创建顺序节点,如果节点名称已经存在是无法创建的,会报错Node already exists: /SunnyBear,还有临时节点不允许有子节点。
4. ZooKeeper节点状态属性
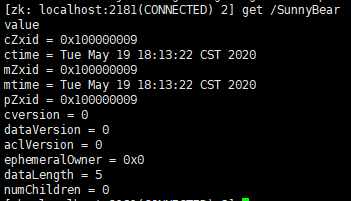
| 属性 | 数据结构 | 描述 |
|---|---|---|
| cZxid | long | 节点被创建的Zxid值 |
| ctime | long | 节点被创建的时间 |
| mZxid | long | 节点被修改的Zxid值 |
| mtime | long | 节点被修改的时间 |
| pZxid | long | 子节点最后一次被修改时的Zxid值 |
| cversion | long | 子节点的版本号 |
| dataVersion | long | 节点修改的版本号 |
| aclVersion | long | 节点的ACL被修改的版本号 |
| ephemeralOwner | long | 如果此节点为临时节点,那么它的值为这个节点持有者的会话ID,否则,它的值为0 |
| dataLength | int | 节点数据域的长度 |
| numChildren | int | 节点拥有的子节点的长度 |
- 其中 Zxid 为 事务id,可以识别出请求的全局顺序。
- 基于 CAS 理论保证分布式数据原子性操作。
5. ACL保障数据的安全
ACL 机制,表示为 scheme🆔permissions 格式,第一个字段表示采用哪一种机制,第二个 id 表示用户,permissions 表示相关权限(如只读,读写,管理等),详细的命令使用在后面介绍。
四、命令行
1. 服务端常用命令
启动命令:./zkServer.sh start
停止命令:./zkServer.sh stop
重启命令:./zkServer.sh restart
状态查看命令:./zkServer.sh status
2. 客户端常用命令
使用 ./zkCli.sh ip:端口 命令连接到 ZooKeeper,连接成功之后就可以使用下面的命令了,前面也提到了一些命令。
# 查看当前 ZooKeeper 中根目录下的子节点信息
ls /
# 查看当前 ZooKeeper 中根目录下子节点信息,并能看到更新次数等数据
ls2 /
# 创建节点,这个之前已经提到过了,其中-e代表临时节点,-s代表为顺序节点
create [-e] [-s] zNodeName zNodeValue
# 获取创建节点的信息
get /zNodeName
# 修改节点内容,这个和redis不同,如果key不存在,那么会报错
set /zNodeName zNodeValue
# 删除节点,如果存在子节点删除失败
delte /zNodeName
# 递归删除,子节点同时删除
rmr /zNodeName
# 退出客户端
quit
# 帮助命令
help
3. ACL命令常用命令
之前提到了ACL命令为 scheme🆔permissions 格式,那么分别看下这三段代表什么。
- schema:代表授权策略
- id:代表用户
- permission:代表权限
scheme
scheme有四种方式:
- world:默认方式,所有人都可以访问
- auth:代表已经认证通过的用户
- digest:即用户名:密码这种方式认证,这也是业务系统中最常用的
- ip:使用ip地址认证
id
和 scheme 一一对应,他也有四种:其中 auth 为明文,digest 为密文
- world -> anyone
- auth -> username:password
- digest -> username:BASE64(SHA1(password))
- ip -> 客户端ip地址
permission
c(CREATE)、d(DELETE)、r(READ)、w(WRITE)、a(ADMIN)这几个权限,对应增,删,查,改,管理权限,简称cdrwa
- c:创建子节点的权限
- d:删除子节点的权限
- r:读取节点数据的权限
- w:修改节点数据的权限
- a: 给子节点授权的管理权限
具体命令
# 获取子节点的ACL信息
getAcl /zNodeName
# 设置子界面ACL信息,例如:
# 设置所有人都可以访问testDir节点,但是却没有删除权限
setAcl /testDir world:anyone:crwa
# 设置auth方式,先增加用户再赋予权限,例如对/testDir目录下的/testAcl1进行操作
create /testDir/testAcl1 testAcl1
addauth digest user1:123456
setAcl /testDir/testAcl1 auth:user1:123456:crwa
# 设置digest方式,这个和auth的区别就是明文密码和密文密码的区别,不适用密文密码会设置失败,所以需要获取密文密码
# 通过shell命令获取密文密码
java -Djava.ext.dirs=/usr/local/zookeeper-3.4.12/lib -cp /usr/local/zookeeper-3.4.12/zookeeper-3.4.12.jar org.apache.zookeeper.server.auth.DigestAuthenticationProvider user2:123456
# 得到结果
user2:123456->user2:hZG2W+NR7DCvADzOkGR6JGLqoTY=
# 接下来就是基本操作了,使用zkCli客户端登录
create /testDir/testAcl2 testAcl2
addauth digest user2:123456
setAcl /testDir/testAcl2 digest:user2:hZG2W+NR7DCvADzOkGR6JGLqoTY=:crw
# 设置ip方式
create /testDir/testAcl3 testAcl3
set /testDir/testAcl3 ip:192.168.31.6:cdrwa
设置之后就可以使用命令来测试以下权限是否设置成功了,如果是 auth 和 digest的那么需要登录来获取权限,quit退出连接重新连接ZooKeeper,然后执行下面命令就可测试了。
addauth digest user1:123456
五、ZooKeeper日志
前面 conf 配置中提交到 dataDir 和 dataLogDir
- dataDir:ZooKeeper 的数据目录,主要目的是存储内存数据库序列化后的快照路径,可以通过 snapCount 参数配置产生快照的时机,默认是100000,但是实际源码中会使用 50000 + random(50000) 作为实际产生快照的操作次数,避免多个节点同时产生快照,影响性能。如果没有配置事务日志(即dataLogDir配置项)的路径,那么 ZooKeeper 的事务日志也存放在数据目录中。
- dataLogDir:指定事务日志的存放目录。事务日志对ZooKeeper的影响非常大,强烈建议事务日志目录和数据目录分开,不要将事务日志记录在数据目录(主要用来存放内存数据库快照)下。
快照即类似于 Redis 中的RDB,每 50000 + random(50000) 次记录操作就生成快照;
事务日志则类似于 Redis 中的AOF,记录着每一条操作命令。
查看快照和事务日志文件内容命令
需要注意的是,下面命令的分隔符在window上是;,在Linux上面是:,同时还需要注意 jar版本号 和 文件目录位置,修改为自己的。
查看快照:
java -cp ../../zookeeper-3.4.12.jar:../../lib/slf4j-api-1.7.25.jar org.apache.zookeeper.server.SnapshotFormatter snapshot.xxx
查看事务日志:
java -cp ../../zookeeper-3.4.12.jar:../../lib/slf4j-api-1.7.25.jar org.apache.zookeeper.server.LogFormatter log.xxx
都读到这里了,来个 点赞、评论、关注、收藏 吧!
