
ConcurrentHashMap中的LongAdder思想
一、设计背景与核心目标
ConcurrentHashMap 在统计元素数量时(如 size() 方法),若直接使用 AtomicLong 会导致以下问题:
- CAS 竞争激烈:高并发下多个线程频繁竞争同一变量,导致大量 CAS 失败和重试,性能急剧下降
- 伪共享(False Sharing):多线程操作同一缓存行的不同变量时,缓存一致性协议会引发无效同步,降低性能
为解决这些问题,ConcurrentHashMap 采用类似 LongAdder 的分段计数机制,将全局计数拆分为多个独立单元,分散线程竞争。
二、分段计数实现原理
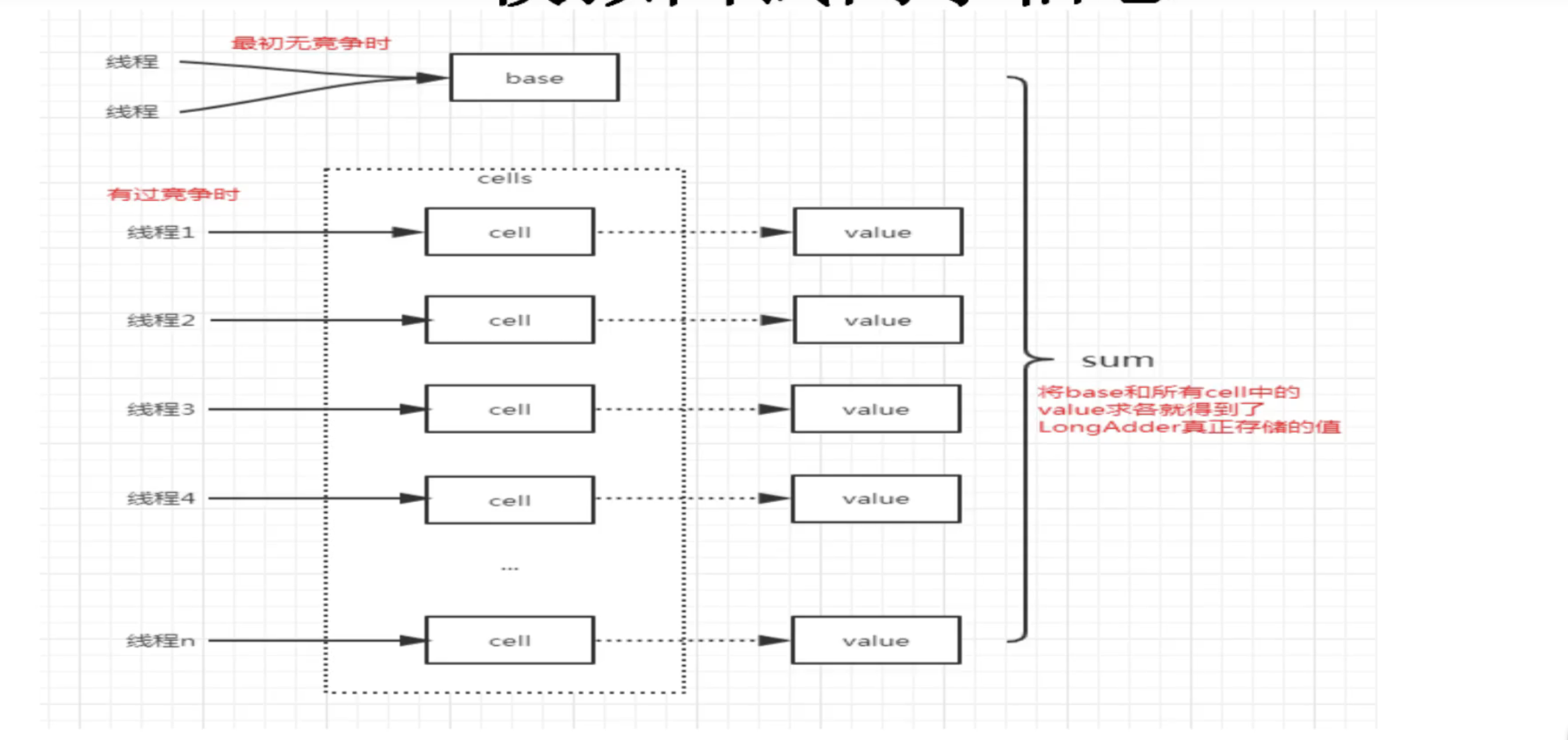
1. 核心数据结构
-
baseCount:基础计数器,用于低并发场景下的原子累加。 -
CounterCell[]:分段计数器数组,当检测到baseCount竞争激烈时,动态扩展并分配给不同线程使用
2. 关键方法逻辑
-
addCount(long x, int check):- 尝试更新
baseCount:通过 CAS 操作直接更新基础值。 - 竞争失败时切换分段:若 CAS 失败,初始化
CounterCell数组,并根据线程哈希值选择特定分段进行更新。 - 动态扩容:若某分段竞争激烈,自动扩容数组并重新哈希,进一步分散冲突
- 尝试更新
-
size():最终一致性统计,累加baseCount和所有CounterCell的值。由于不阻塞写操作,可能读到中间状态,但多次调用结果一致
3. 伪代码示例
// 伪代码简化版
private void addCount(long x, int check) {
if (CAS(baseCount, x)) { // 低竞争直接更新
return;
}
// 高竞争时使用分段
int hash = ThreadLocalRandom.getProbe();
CounterCell cell = cells[hash & cells.length];
if (cell == null) {
// 初始化分段
cells = new CounterCell[INITIAL_CAPACITY];
}
CAS(cell.value, x); // 分段内 CAS 更新
}
LongAdder 的核心思想
-
分散热点:
-
传统
AtomicLong:所有线程通过 CAS 竞争更新同一个value变量。在高并发下,大量 CAS 失败重试导致性能急剧下降。 -
LongAdder:引入一个base变量和一个Cell[]数组(初始为空或很小)。-
低竞争时: 直接通过 CAS 更新
base变量(类似AtomicLong)。 -
高竞争时: 当线程在更新
base时遇到 CAS 失败(表示有竞争),它会尝试“分散”:-
根据当前线程的某种哈希(如
ThreadLocalRandom)计算一个索引,定位到Cell[]数组中的一个Cell槽位。 -
每个
Cell是一个独立的、填充过的(避免伪共享)、用volatile修饰的简单long值。 -
线程优先尝试通过 CAS 更新自己“命中”的那个
Cell的值。
-
-
-
核心优势: 将原本针对单个变量的全局竞争,分散到了多个
Cell变量上。只要线程能够相对均匀地映射到不同的Cell,竞争就大大减少。冲突只在映射到同一个Cell的线程间发生,范围大大缩小。
-
-
最终一致求和:
-
要获取
LongAdder的当前总和 (sum()),并不是一个简单的读操作。 -
它需要将
base的值加上Cell[]数组中所有非空Cell的值。 -
这个求和过程在并发进行时,读到的
base和各个Cell的值可能不是严格意义上同一时刻的快照(即不是原子的),因此sum()的结果是一个最终一致的近似值。 -
核心优势: 牺牲了读取时绝对的原子性和实时一致性,换取了极高的写入(更新)性能。这对于像统计计数器这样读少写多且对瞬时绝对精确性要求不高的场景是完美的权衡。
-
ConcurrentHashMap 中的借鉴(主要在 addCount 方法)
ConcurrentHashMap 使用 sizeCtl 和一些辅助字段管理容量控制,并使用 baseCount 和一个 CounterCell[] 数组(LongAdder 中的 Cell[] 的变体)来统计元素数量。
-
baseCount(类比LongAdder.base):-
一个普通的
volatile long变量。 -
尝试路径: 当需要增加计数(例如在
putVal成功插入后调用addCount(1L, binCount)),ConcurrentHashMap首先尝试用 CAS 直接更新baseCount(U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x))。如果 CAS 成功,更新就完成了,非常高效。
-
-
CounterCell[](类比LongAdder.cells):-
一个延迟初始化的数组,元素类型是
CounterCell(通常就是一个简单的volatile long包装)。 -
分散路径: 如果步骤 1 中对
baseCount的 CAS 失败了(表明存在竞争),ConcurrentHashMap就会进入分散更新模式:-
检查
CounterCell[]是否已初始化。如果没有,尝试初始化一个较小的大小(通常是 2)。 -
使用线程相关的哈希值(如
ThreadLocalRandom.getProbe())计算一个索引i。 -
尝试获取对应索引
i处的CounterCell。-
如果该位置为空,尝试新建一个
CounterCell并放入数组(需要 CAS 保证线程安全)。 -
如果该位置不为空,尝试用 CAS 更新这个
CounterCell的值 (U.compareAndSwapLong(c, CELLVALUE, v = c.value, v + x))。
-
-
如果在更新选定的
CounterCell时也遇到 CAS 失败,说明该槽位竞争也激烈,可能会尝试重新计算哈希(ThreadLocalRandom.advanceProbe)映射到另一个槽位,或者尝试扩容CounterCell[]数组(如果竞争持续激烈且数组未达上限)。
-
-
核心思想体现: 将对单一
baseCount的竞争分散到多个CounterCell上,显著减少线程间的冲突。
-
-
获取元素数量 (
size(),mappingCount()):-
类似于
LongAdder.sum(),ConcurrentHashMap的size()或更推荐的mappingCount()方法并不是简单地返回baseCount。 -
它们需要遍历整个
CounterCell[]数组(如果已初始化),将所有非空CounterCell的值累加到baseCount上。 -
核心思想体现: 这个求和过程是非原子的。在并发修改时,返回的值是一个估计值,可能略微偏高或偏低(因为可能漏掉某个
CounterCell刚更新的值,或者包含某个CounterCell刚被加但尚未合并的值)。这就是为了换取高性能更新而接受的最终一致性。
-
总结:ConcurrentHashMap 中的 LongAdder 思想
-
优先尝试 CAS 更新基础值 (
baseCount)。 -
遇到基础值更新竞争失败时,将更新操作分散到一组
CounterCell槽位上。 -
获取总和 (
size()) 需要遍历求和所有分散的值 (baseCount + ΣCounterCell[i].value)。 -
读取总和 (
size()) 的结果是最终一致性的,不是绝对精确的瞬时值,但写入/更新 (addCount) 的性能在高并发下远优于基于单一原子变量的方案。
这种设计完美契合了 ConcurrentHashMap 的需求:更新计数(put, remove)操作极其频繁且要求高性能,而读取计数(size())操作相对较少且可以容忍一定的延迟和不精确性。LongAdder 的思想是解决高并发计数器性能问题的经典模式,并被 ConcurrentHashMap 成功采纳用于其内部计数机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号