

sharding在永辉导致所有广播表XA事务批量提交导致出现数据异常
-
-
![image]()
![]()
![]()
![]()
-
java.sql.Statement#clearBatch作用是什么?
-
1. 核心功能
- 清空批处理队列:当通过
addBatch()方法将多个 SQL 语句添加到批处理队列后,调用clearBatch()会立即移除所有已缓存的 SQL 命令,释放相关内存资源 - 避免重复执行:在批量执行(
executeBatch())后,若未清空队列,后续的addBatch()可能会继续向同一队列添加新命令,导致意外执行旧命令。clearBatch()可确保队列的“干净”状态
2. 使用场景
- 分批次处理:在需要分批提交 SQL 时(例如每 1000 条执行一次),通常会在
executeBatch()后调用clearBatch(),以便下一批次的 SQL 可以重新添加 - 异常恢复:若批处理过程中发生异常,可能需要回滚事务并清空队列,避免残留命令干扰后续操作
3. 示例代码
- 说明:每 1000 条执行一次批处理,执行后立即清空队列,避免内存占用过高
4. 注意事项
- 与
executeBatch()配合使用:clearBatch()通常在executeBatch()之后调用,但也可单独用于提前终止未执行的批处理 - 资源管理:清空队列不会自动关闭
Statement对象,仍需手动调用close()释放数据库连接资源 - 性能优化:合理使用
clearBatch()可减少内存压力,尤其在处理大规模数据时
5. 与
PreparedStatement的区别Statement的clearBatch()仅清空 SQL 命令列表,而PreparedStatement的clearBatch()还会重置参数绑定状态(通过clearParameters())
- 清空批处理队列:当通过
-
-
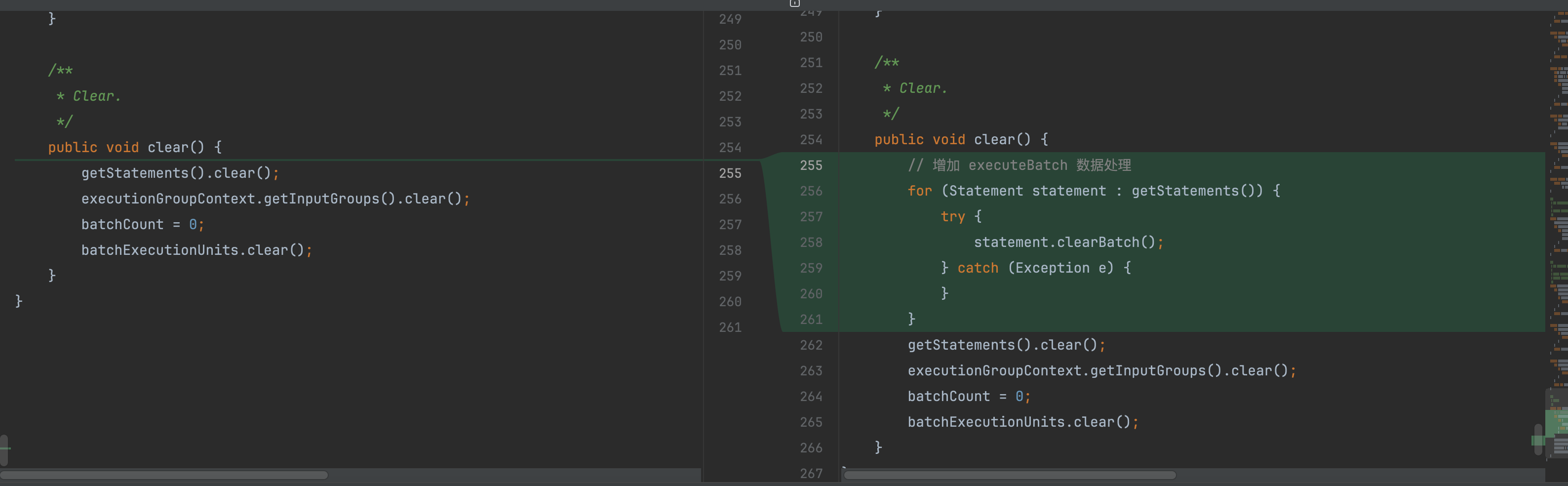
修改描述:原来只有LinkedList.clear,现在添加了对每一个LinkedList中的每个java.sql.Statement进行clearBatch删除
-
LinkedList.clear会删除每一个元素么:只会删除引用
-
在 Java 中,
LinkedList.clear()方法会移除链表中的所有元素,但其具体行为需要从内存管理的角度理解:核心行为
-
移除所有引用
clear()会遍历链表中的每个节点,将节点中存储的元素引用(item)置为null,断开链表对元素对象的引用。 -
断开节点链接
将每个节点的prev(前驱)和next(后继)指针置为null,使节点之间断开连接。 -
重置头尾指针
将链表的first(头节点)和last(尾节点)引用置为null。 -
大小归零
将链表的size属性设置为 0。
-
-
关键注意事项
-
元素对象不会被立即销毁
-
clear()只移除了链表对元素的引用,并非销毁元素对象本身。 -
如果元素对象仍被其他代码引用(如其他变量或集合),则不会被垃圾回收(GC)。
-
若元素对象未被其他代码引用,GC 会在后续回收它们。
-
-
节点对象会被回收
链表节点(Node对象)在断开引用后会被 GC 回收,因为链表不再持有它们的引用。
-
-
-
在上述代码中,如果没有及时通过clearBatch清除掉result中每一个元素的sql,那么下一次批次化sql提交会出现什么问题么?(ds)
-
在您提供的代码中,
getStatements()方法负责收集并返回一个Statement对象列表(具体为JDBCExecutionUnit的StorageResource)。这些Statement对象可能被用于 JDBC 批处理操作(即通过addBatch()添加 SQL 语句,然后通过executeBatch()提交执行)。如果没有在每次批处理操作后及时调用clearBatch()来清除每个Statement的批处理队列,那么在下一次批次化 SQL 提交时,可能会出现以下问题:1. 批处理队列残留导致重复执行 SQL(逻辑错误和数据不一致)
-
问题描述:JDBC
Statement对象内部维护一个批处理队列(batch queue),用于存储通过addBatch()添加的 SQL 语句。当调用executeBatch()时,队列中的所有语句会被执行。正常情况下,executeBatch()方法在执行成功后会自动清除队列(即队列被置空)。然而,如果executeBatch()未被调用、调用失败(如抛出异常)、或仅调用了addBatch()而未执行,那么队列中的 SQL 语句会残留。 -
风险场景:如果
result列表中的某个Statement对象在返回前已经用于批处理(例如,添加了 SQL 语句但未执行或未完全清除),那么当下一次使用同一个Statement进行批次化提交时(即再次调用addBatch()和executeBatch()),残留的 SQL 语句会与新添加的语句一起被执行。-
例如:
-
第一次使用:
statement.addBatch("INSERT INTO table1 ...");(但未执行executeBatch()或执行失败)。 -
第二次使用:
statement.addBatch("UPDATE table2 ...");然后statement.executeBatch()。 -
结果:
INSERT和UPDATE语句都会被意外执行,可能导致数据重复插入、更新错误或业务逻辑混乱。
-
-
-
后果:数据不一致(如重复记录、错误更新)、业务逻辑错误,甚至违反数据完整性约束(如主键冲突)。这类问题可能难以调试,因为错误是隐式的。
2. 执行异常或失败(稳定性问题)
-
问题描述:残留的 SQL 语句可能已失效(例如,表结构已变更、事务状态改变或 SQL 语法错误)。当
executeBatch()被调用时,这些无效语句会与新语句一起执行,导致整个批处理失败。-
例如:残留的 SQL 引用了一个已被删除的列,而新 SQL 是有效的。执行时,JDBC 可能抛出
BatchUpdateException或SQLException,导致整个批处理回滚(取决于事务设置)。
-
-
后果:应用程序抛出异常,批次化操作中断,需要额外的错误处理。在高并发或事务性场景中,这可能引起事务回滚、资源锁定或系统不稳定。
3. 性能下降(资源浪费)
-
问题描述:批处理队列中残留的 SQL 语句会增加
executeBatch()的执行负担。JDBC 需要解析和执行更多语句,消耗额外的数据库资源(CPU、I/O)。-
例如:如果残留了 100 条无效 SQL,新批次添加 50 条 SQL,则
executeBatch()会实际执行 150 条语句,而预期只有 50 条。
-
-
后果:数据库负载增加、响应时间变长、吞吐量下降,尤其在高频批处理场景(如数据导入或批量更新)中影响显著。
4. 资源泄露(长期风险)
-
问题描述:未清除的批处理队列可能导致
Statement对象持有不必要的资源(如数据库游标或内存缓存)。如果Statement被长期重用而未重置,这些资源可能无法及时释放。 -
后果:内存泄漏或数据库连接资源耗尽,最终导致
OutOfMemoryError或连接池枯竭,影响应用程序的健壮性。
为什么在您的代码中可能发生?
-
您的
getStatements()方法只是收集Statement对象,并不负责管理其内部状态(如批处理队列)。如果上游代码(调用者)在使用这些Statement时没有正确执行和清除批处理队列,残留问题会延续到下一次使用。 -
具体风险点:
-
如果
executionGroupContext中的JDBCExecutionUnit在getStorageResource()之前已经用于批处理(例如,添加了 SQL 但未调用executeBatch()或未处理异常),那么返回的result列表中的Statement对象就可能带有未清除的批处理队列。 -
当这些
Statement被用于“下一次批次化 SQL 提交”时(如通过addBatch()添加新 SQL 并调用executeBatch()),上述问题就会暴露。
-
解决方案建议
-
最佳实践:在批处理逻辑中,始终确保在
executeBatch()后调用clearBatch(),以显式清除队列(即使规范中executeBatch()成功后会清除队列,显式调用可增强健壮性)。示例:for (Statement stmt : statements) { stmt.addBatch("SQL1"); // 添加新 SQL stmt.addBatch("SQL2"); try { int[] counts = stmt.executeBatch(); // 执行批处理 } catch (BatchUpdateException e) { // 处理异常 stmt.clearBatch(); // 异常时手动清除 } finally { stmt.clearBatch(); // 确保清除 } } -
资源管理:考虑在不再需要
Statement时显式关闭(close()),或使用 try-with-resources 语句。避免长期重用Statement对象,尤其是在批处理场景中。 -
代码改进:在您的
getStatements()方法中,不建议直接清除Statement的队列(因为职责分离),但可以在上游逻辑中添加状态检查。例如:// 在调用 getStatements() 前确保清除 for (ExecutionGroup<JDBCExecutionUnit> group : executionGroupContext.getInputGroups()) { for (JDBCExecutionUnit unit : group.getInputs()) { Statement stmt = unit.getStorageResource(); if (stmt != null) { stmt.clearBatch(); // 显式清除 } } } List<Statement> statements = getStatements(); // 现在获取的 Statement 队列为空 -
框架选择:如果使用类似 ShardingSphere 等中间件(从您的代码风格推断),确保其批处理模块已正确处理队列清除。或考虑使用
PreparedStatement代替Statement,它更适合批处理且更易管理。
总之,未清除批处理队列的主要风险是残留 SQL 的意外执行,导致数据、异常或性能问题。通过严格在批处理生命周期中调用
clearBatch(),可以避免这些问题。如果您的上下文有更多细节(如框架或批处理逻辑),我可以提供更针对性的建议。 -
-
-
-
添加了隐式事务的处理
-
//判断是否使用隐式事务
protected final boolean isNeedImplicitCommitTransaction(ShardingSphereConnection connection, ExecutionContext executionContext) {
return this.isInDistributedTransaction(connection) && this.isModifiedSQL(executionContext) && executionContext.getExecutionUnits().size() > 1;
}
//isInDistributedTransaction 判断是否是分布式事务 ,isModifiedSQL判断事务是否是DML和新增和修改,判断是否是批量化执行//isDistributedTransaction判断是否是XA ,判断是否开启本地事务 isStartLocalTransaction ,判断当前不能在事务中,在事务中就说明是显式事务isInTransaction
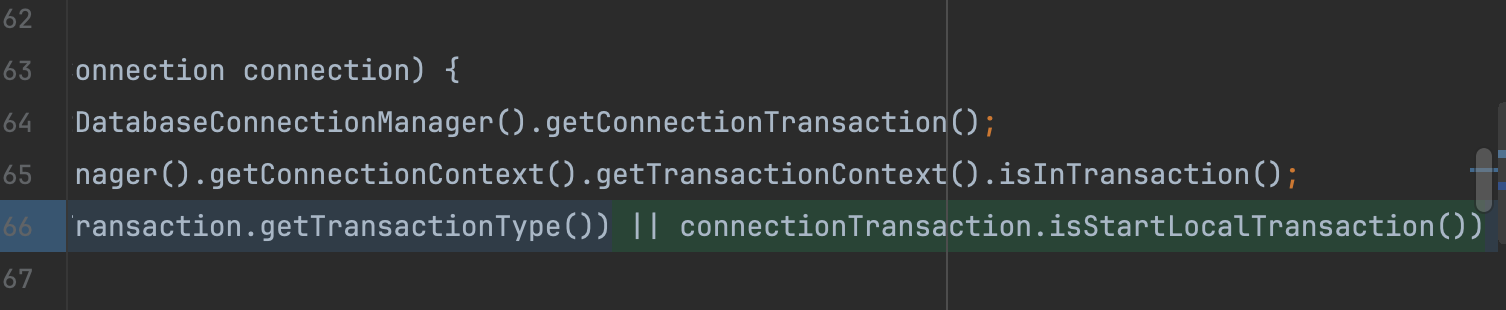
private boolean isInDistributedTransaction(final ShardingSphereConnection connection) { ConnectionTransaction connectionTransaction = connection.getDatabaseConnectionManager().getConnectionTransaction(); boolean isInTransaction = connection.getDatabaseConnectionManager().getConnectionContext().getTransactionContext().isInTransaction(); return (TransactionType.isDistributedTransaction(connectionTransaction.getTransactionType()) || connectionTransaction.isStartLocalTransaction()) && !isInTransaction; }//isInDistributedTransaction 判断是否是分布式事务 ,isModifiedSQL判断事务是否是DML和新增和修改,判断是否是批量化执行
//isDistributedTransaction判断是否是XA ,判断是否开启本地事务 isStartLocalTransaction ,判断当前不能在事务中,在事务中就说明是显式事务isInTransaction
判断是否处于分布式事务中,新增代码了判断isStartLocalTransaction代表是否开启了本地事务 -
![]()
-
![]()
![]()
-
![]()
-
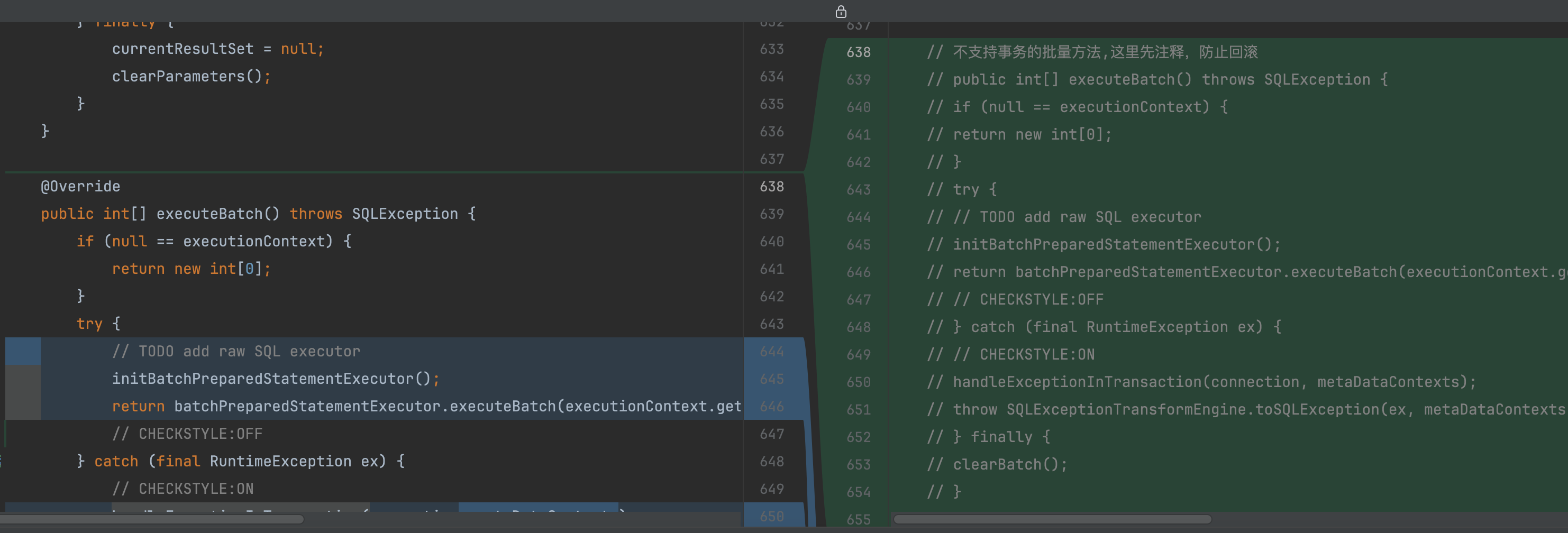
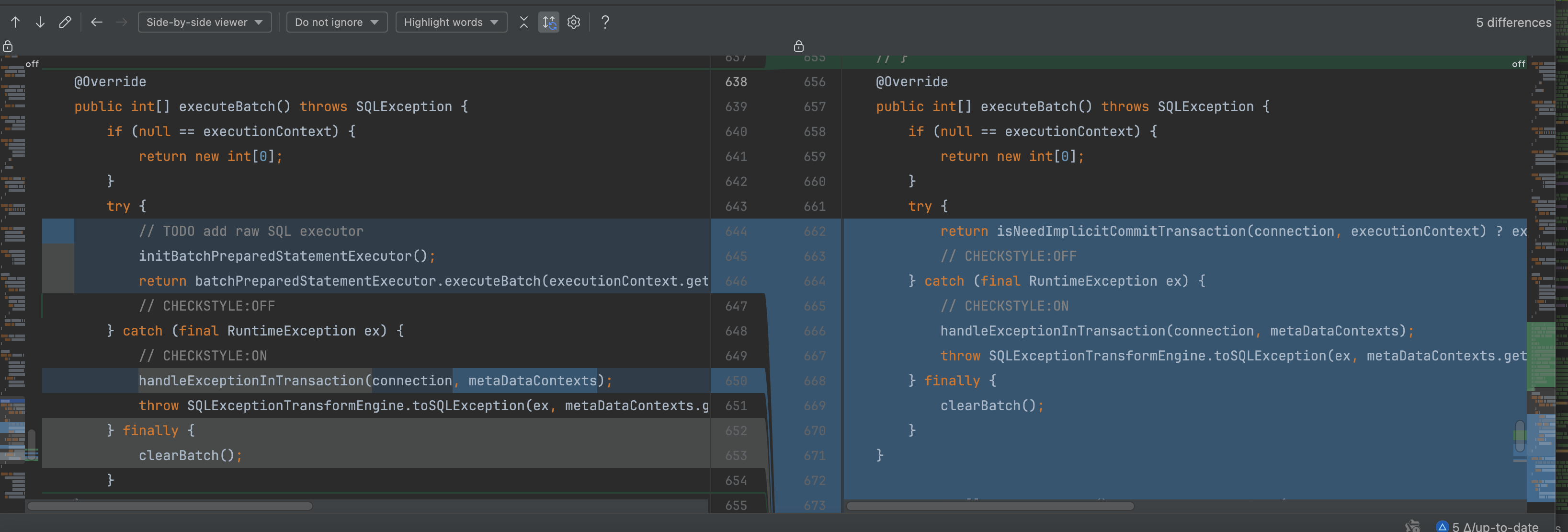
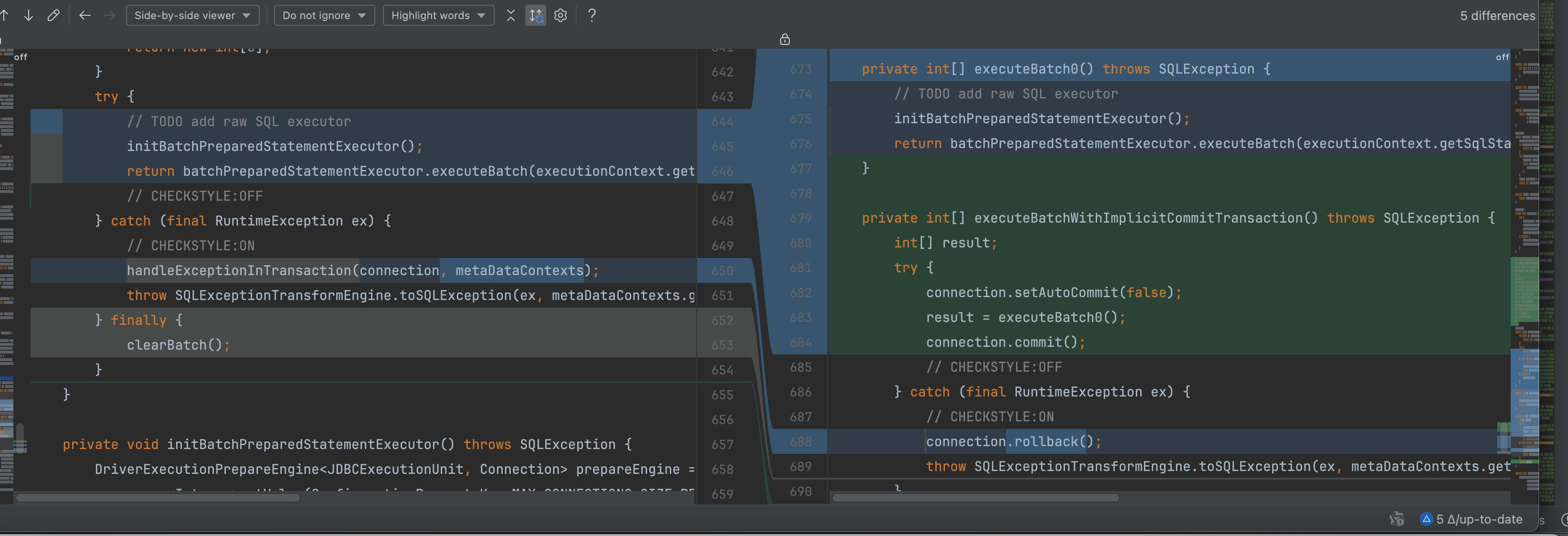
private int[] executeBatchWithImplicitCommitTransaction() throws SQLException { int[] result; try { connection.setAutoCommit(false); result = executeBatch0(); connection.commit(); // CHECKSTYLE:OFF } catch (final RuntimeException ex) { // CHECKSTYLE:ON connection.rollback(); throw SQLExceptionTransformEngine.toSQLException(ex, metaDataContexts.getMetaData().getDatabase(connection.getDatabaseName()).getProtocolType().getType()); } return result; } 和 public int[] executeBatch() throws SQLException { if (null == executionContext) { return new int[0]; } try { // TODO add raw SQL executor initBatchPreparedStatementExecutor(); return batchPreparedStatementExecutor.executeBatch(executionContext.getSqlStatementContext()); // CHECKSTYLE:OFF } catch (final RuntimeException ex) { // CHECKSTYLE:ON handleExceptionInTransaction(connection, metaDataContexts); throw SQLExceptionTransformEngine.toSQLException(ex, metaDataContexts.getMetaData().getDatabase(connection.getDatabaseName()).getProtocolType().getType()); } finally { clearBatch(); } }
-
-
上述这两块代码隐式批量提交事务,和显示批量提交事务,区别在哪里,核心原理是什么?
-
区别与核心原理分析
这两段代码分别实现了 隐式批量提交事务 和 显式批量提交事务,核心区别在于 事务边界的控制方式 和 异常处理逻辑。以下是详细对比:
1. 隐式批量提交事务 (
executeBatchWithImplicitCommitTransaction)private int[] executeBatchWithImplicitCommitTransaction() throws SQLException { int[] result; try { connection.setAutoCommit(false); // 显式关闭自动提交 result = executeBatch0(); // 执行批量操作 connection.commit(); // 显式提交事务 } catch (final RuntimeException ex) { connection.rollback(); // 显式回滚事务 throw convertToSQLException(ex); } return result; }核心原理:
-
事务边界由方法内部控制:
-
通过
connection.setAutoCommit(false)显式开启事务。 -
批量操作成功后调用
connection.commit()显式提交。 -
发生异常时调用
connection.rollback()显式回滚。
-
-
“隐式”的含义:
-
对调用者透明:调用方无需手动管理事务(如提前设置
autoCommit=false)。 -
方法内部封装了完整的事务生命周期(开启→提交/回滚)。
-
-
适用场景:
-
需要确保批量操作作为一个原子性事务执行(全成功或全失败)。
-
适合独立批量任务,不依赖外部事务上下文。
-
关键点:
-
直接控制
autoCommit状态和事务的提交/回滚。 -
异常处理仅针对
RuntimeException,回滚后转换异常类型。
2. 显式批量提交事务 (
executeBatch)public int[] executeBatch() throws SQLException { if (null == executionContext) return new int[0]; try { initBatchPreparedStatementExecutor(); return batchPreparedStatementExecutor.executeBatch(...); // 执行批量操作 } catch (final RuntimeException ex) { handleExceptionInTransaction(...); // 在事务中处理异常(可能回滚) throw convertToSQLException(ex); } finally { clearBatch(); // 清理资源 } }核心原理:
-
事务边界由调用方控制:
-
方法内部不管理事务(未设置
autoCommit或调用commit()/rollback())。 -
依赖外部已存在的事务环境(如调用方提前设置
autoCommit=false)。
-
-
“显式”的含义:
-
调用方需显式管理事务(如通过
beginTransaction()和commit())。 -
方法仅关注批量操作本身,事务控制交给外部。
-
-
异常处理:
-
通过
handleExceptionInTransaction处理异常(内部可能调用rollback,取决于事务状态)。 -
无论成功与否,
finally块确保清理资源(clearBatch)。
-
关键点:
-
不显式控制事务,而是依赖外部事务上下文。
-
通过
handleExceptionInTransaction实现异常时的回滚(需外部事务支持)。 -
必须清理资源(
finally块中的clearBatch)。
对比总结
特性 隐式批量提交事务 显式批量提交事务 事务控制方 方法内部管理(开启/提交/回滚) 调用方管理(依赖外部事务) autoCommit 设置 强制设为 false不修改,依赖外部状态 资源清理 未显式清理(可能由外部处理) 通过 finally块确保清理 (clearBatch)异常处理 直接回滚并转换异常 调用 handleExceptionInTransaction处理异常适用场景 独立原子性操作 作为大事务的一部分 事务边界 方法即完整事务 事务跨多个方法调用
核心原理总结
-
隐式事务:
-
封装性:将事务生命周期封装在方法内部,确保批量操作的原子性。
-
简化调用:调用方无需关心事务管理,适合单一逻辑单元。
-
-
显式事务:
-
灵活性:允许批量操作作为更大事务的一部分(如跨多个DAO操作)。
-
责任分离:事务控制权交给调用方,方法仅专注执行批量操作。
-
资源安全:严格通过
finally清理资源,避免内存泄漏。
-
使用建议
-
选择 隐式事务 当:需要确保批量操作的独立原子性,且不涉及外部事务。
-
选择 显式事务 当:批量操作是复杂业务逻辑的一部分(如跨多个数据库操作),需与其他操作共享事务。
-
-
-
结论:
- 因为在在批量化batch执行sql中,没有进行区分隐式事务和显示事务,导致用的都是显示事务,进而导致,只有编程式事务的情况才会被回滚,隐式的声明式事务不会回滚
- 所以我们加了判断隐式事务,相当于独立做回滚提交判断,


 浙公网安备 33010602011771号
浙公网安备 33010602011771号