Redis底层原理是什么
Redis 的高性能源于其精妙的底层设计,主要包括以下几个方面:
1. 内存存储 (In-Memory Data Store)
-
核心原理: 所有数据主要存储在 RAM 中。这是 Redis 速度快的最根本原因,避免了传统磁盘数据库的 I/O 瓶颈。
-
优势: 内存访问速度比磁盘快几个数量级。
-
代价: 数据量受限于内存大小,成本较高,且需要持久化机制防止断电丢失。
2. 高效的数据结构 (Rich & Optimized Data Structures)
Redis 不仅仅是简单的 Key-Value 存储,其 value 支持多种数据结构,且每种结构都针对特定操作进行了高度优化:
- 简单动态字符串(string)、 整数集合(整数 set)
- 压缩列表 (小规模 List, Hash, Sorted Set/zset)
- 快速列表(list) 、字典(Key-Value 映射) (set,Hash)、跳跃表(zset)
-
简单动态字符串 (SDS - Simple Dynamic String):
-
相比 C 原生字符串,SDS 存储了长度信息,获取字符串长度复杂度为 O(1)。
-
预留空间 (预分配 & 惰性释放),减少修改字符串时内存重分配次数。
-
二进制安全,可以存储任意二进制数据(如图片)。
-
-
字典 (Hash Table / Dict): Redis 的基石。(set,Hash)
-
用于实现 Redis 数据库本身 (Key-Value 映射) 和 Hash 类型。
-
使用 MurmurHash2 等高效哈希算法。
-
采用 渐进式 rehash:当哈希表需要扩容或缩容时,不是一次性完成,而是分多次、渐进式地将旧桶中的数据迁移到新桶,避免单次操作耗时过长阻塞服务。
-
使用 链地址法 解决哈希冲突。
-
-
跳跃表 (Skip List):
-
用于实现 有序集合 (Sorted Set)。
-
在链表基础上添加多级索引,使得范围查询 (如
ZRANGE)、按排名访问的平均时间复杂度达到 O(logN)。 -
实现比平衡树(如红黑树)简单,且范围查询更高效。
-
-
压缩列表
-
ziplist(Redis7.0前):连续内存块存储节点,每个节点记录前驱长度和自身数据,支持快速头尾操作,但存在级联更新风险。
-
用于在小规模数据时实现 List, Hash, Sorted Set,以节省内存。
-
是一块连续的内存空间,紧凑存储多个元素及其长度信息。
-
当元素数量或大小超过阈值时,会自动转换为更高效(但内存占用稍大)的结构(如双向链表、哈希表、跳表)。
listpack(Redis7.0后):改进节点编码方式,消除级联更新问题,进一步提升性能。
-
-
-
快速列表 (QuickList - Redis 3.2+):
-
用于实现 List 类型。
-
是 ZipList 和双向链表的结合体。一个 QuickList 是由多个 ZipList 节点组成的双向链表。
-
平衡了内存效率和操作 (插入/删除) 性能。
-
-
整数集合 (IntSet):
-
当 Set 中所有元素都是整数且数量较少时使用。
-
是一块连续内存,按整数大小有序存储。
-
节省内存,查找效率高 (二分查找)。
-
-
Stream (Redis 5.0+): 用于实现消息队列,底层主要使用基数树 (Rax Tree / Radix Tree) 来高效存储消息 ID 和内容。
- 外部数据类型:
- String类型:每个字段单独存储为一个键值对,例如用户信息可能分散存储为user:123:name、user:123:age等键
-
- 为了节省空间,进行了空间预分配。底层通过sds5/8来,用一个len标记长度
![]()
-
- Hash类型:将多个字段存储为一个结构化对象(类似HashMap),例如user:123对应{name: "Alice", age: 30}
- list
- set
- 小数据量且全为整数时,用 整数集合 节省内存;
- 大数据量或包含字符串时,用 哈希表 保证高效操作。
- zset
- String类型:每个字段单独存储为一个键值对,例如用户信息可能分散存储为user:123:name、user:123:age等键

3. 单线程模型 (核心处理逻辑 - Event Loop)
-
核心原理: Redis 在处理客户端命令、执行操作、返回结果的核心逻辑是单线程的 (在 6.0 之前是完全单线程,6.0 后引入多线程 I/O,但命令执行本身仍是单线程)。
-
优势:
-
避免锁竞争: 无需复杂的锁机制(如互斥锁、读写锁),极大地简化了实现,提高了性能。
-
无上下文切换: 单线程无需在多个线程间切换,减少了 CPU 开销。
-
操作的原子性: 所有命令执行都是原子的,不存在并发修改问题。
-
-
如何高效? 依赖其 非阻塞 I/O 多路复用模型 (I/O Multiplexing):
-
使用
epoll(Linux)、kqueue(BSD/macOS)、select(跨平台但效率低) 等系统调用。 -
单线程的 事件循环 (Event Loop) 可以同时监听和管理大量的客户端套接字连接。
-
当某个连接有可读 (请求到达) 或可写 (可以发送响应) 事件发生时,事件循环会通知 Redis 主线程进行处理。
-
这使得单线程能够高效处理高并发连接。
-
-
瓶颈: 单个命令的执行时间不能过长,否则会阻塞后续所有命令。因此 Redis 命令通常设计得非常快,且避免使用慢查询。
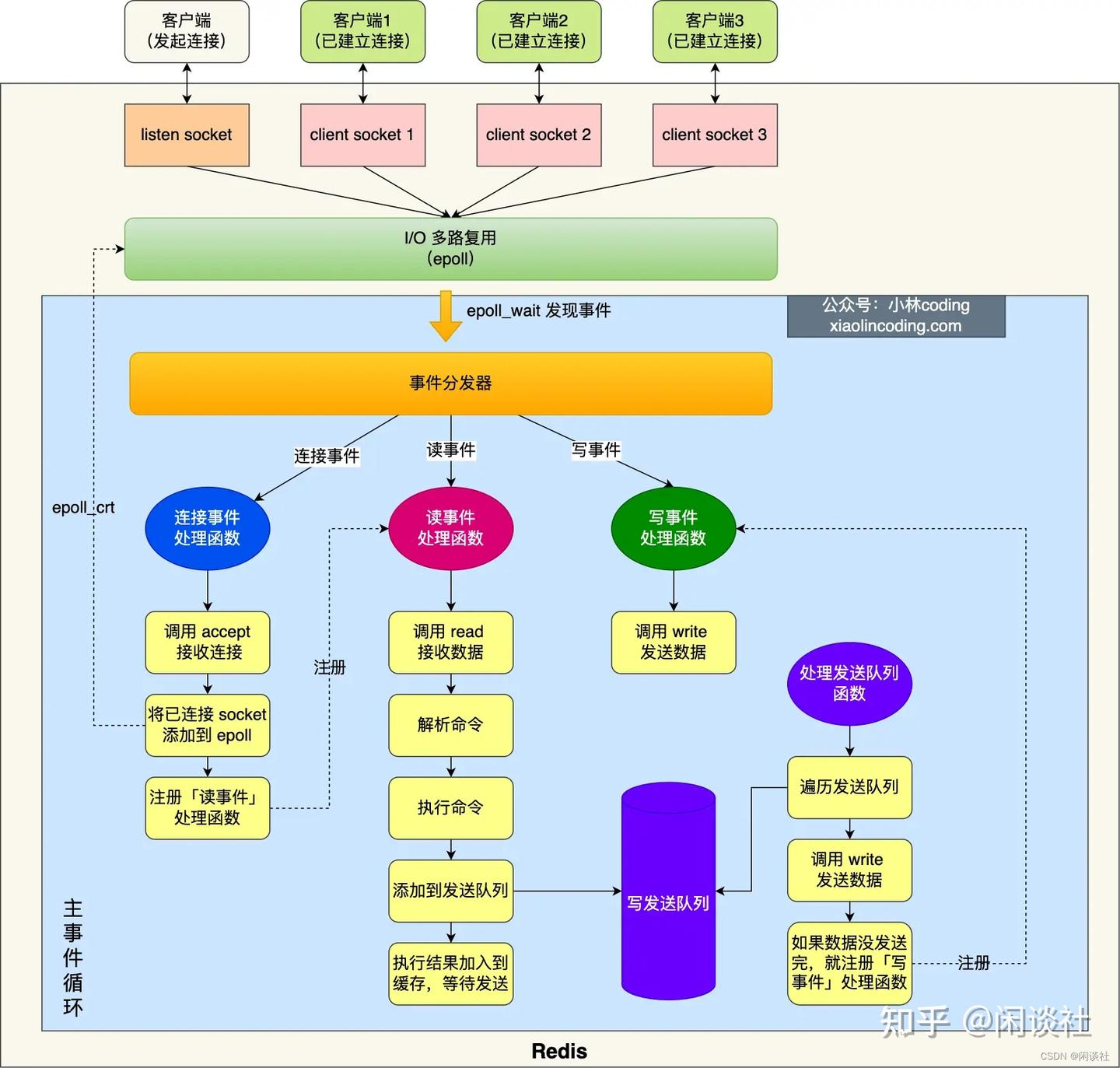
4. 多线程 I/O (Redis 6.0+)
-
背景: 随着网络带宽增加,单线程处理网络 I/O (读取请求、写回响应) 可能成为瓶颈。
-
原理:
-
主线程 仍然负责:事件循环、命令解析、命令执行、响应结果的组织。
-
多线程 (I/O Threads) 负责:读取客户端请求数据 (socket read) 和 写回 响应数据给客户端 (socket write)。
-
命令执行本身仍然是单线程的,保持了原子性。
-
-
优势: 显著提升了网络吞吐量,尤其在需要返回大量数据(如
LRANGE,HGETALL,KEYS*- 慎用)或客户端数量极多时。
5. 持久化 (Persistence)
为了解决内存数据易失性问题,Redis 提供两种主要持久化方式:
-
RDB (Redis Database):
-
原理: 在指定时间间隔内,生成内存数据的快照 (Snapshot) 保存到磁盘上的
.rdb文件。 -
触发方式: 手动 (
SAVE/BGSAVE) 或自动配置 (如save 900 1)。 -
过程 (
BGSAVE): Fork 一个子进程,由子进程负责将数据写入临时 RDB 文件,写入完成后替换旧文件。父进程继续处理请求。SAVE会阻塞主线程。 -
优点: 文件紧凑,恢复速度快。适合备份和灾难恢复。
-
缺点: 可能丢失最后一次快照之后的数据。
fork()操作在数据量大时可能阻塞主线程(虽然时间通常很短)。
-
-
AOF (Append Only File):
-
原理: 记录服务器收到的每一个写操作命令(以 Redis 协议格式),追加写入到文件末尾。
-
写回策略:
-
always: 每个命令都同步写磁盘,最安全,性能最低。 -
everysec(默认): 每秒同步一次(由后台线程完成),最多丢失 1 秒数据,是安全与性能的折衷。 -
no: 由操作系统决定何时同步,性能最好,但丢失数据风险最高。
-
-
重写 (Rewrite): AOF 文件会越来越大。Redis 会
fork子进程,根据当前内存数据生成一个新的、更小的 AOF 文件(包含重建数据集所需的最少命令序列),替换旧文件。 -
优点: 数据安全性更高(取决于
fsync策略),最多丢失 1 秒数据(默认策略)。文件可读性较好(便于人工修复)。 -
缺点: 文件通常比 RDB 大。恢复速度通常比 RDB 慢。在写入负载高时可能影响性能。
-
-
混合持久化 (AOF + RDB - Redis 4.0+):
-
原理: 在 AOF 重写时,子进程将当前内存数据快照以 RDB 格式写入新的 AOF 文件的开头,然后将重写缓冲区中的增量写命令(AOF 格式)追加到文件末尾。生成的文件包含
[RDB Head] + [AOF Tail]。 -
优点: 结合了 RDB 快速恢复和 AOF 丢失数据少的优点。恢复时先加载 RDB 快照,再重放增量 AOF 命令,速度更快。
-
6. 高可用与扩展 (High Availability & Scalability)
-
主从复制 (Replication):
-
原理: 一个 主节点 (Master) 处理写操作,将写命令异步复制给一个或多个 从节点 (Slave/Replica)。从节点处理读操作。
-
作用: 数据冗余备份、读写分离提高读吞吐量、故障恢复基础。
-
过程: 首次全量同步 (RDB 快照传输) + 后续增量同步 (命令传播)。
-
-
哨兵 (Sentinel):
-
原理: 分布式系统,由多个 Sentinel 进程组成,用于监控主节点和从节点的健康状态。
-
功能: 自动故障转移 (主节点宕机时,选举新主节点并通知客户端)、配置提供者、监控通知。
-
作用: 实现 Redis 的高可用 (HA)。
-
-
Redis 集群 (Cluster - Redis 3.0+):
-
原理: 分布式数据分片方案。将数据自动分割到 16384 个哈希槽 (slot) 中。集群由多个节点 (Node) 组成,每个节点负责一部分槽。
-
数据路由: 客户端根据 Key 计算 CRC16 校验和再取模 16384 得到所属槽,然后连接到负责该槽的节点。客户端或代理 (如 Redis 集群模式的客户端库) 处理重定向 (
MOVED,ASK)。 -
高可用: 每个分片通常是主从结构(主节点 + 一个或多个从节点)。主节点故障时,其从节点会被提升为新主节点。
-
作用: 实现水平扩展(分摊数据存储和访问压力)和高可用。
-
7. 其他关键机制
-
虚拟内存 (VM - 已废弃): 早期版本尝试将不常用数据交换到磁盘,但实现复杂且效果不佳,已被废弃。现在主要依赖内存和淘汰策略。
-
事务 (Transactions): 通过
MULTI,EXEC,WATCH等命令实现。它只是将多个命令打包、顺序执行,不保证严格意义上的 ACID 隔离性 (没有回滚,只有乐观锁WATCH)。满足原子性和隔离性(串行执行)。 -
管道 (Pipelining): 客户端一次性发送多个命令而无需等待每个命令的回复,服务器依次执行并一次性返回所有结果。大幅减少网络往返时间 (RTT),是提高批量操作性能的关键手段。
-
发布/订阅 (Pub/Sub): 消息通信模式,生产者 (Publisher) 发送消息到频道 (Channel),消费者 (Subscriber) 订阅频道接收消息。是轻量级的消息队列方案。
-
Lua 脚本: Redis 内置 Lua 解释器。客户端可以发送 Lua 脚本在服务器端原子性地执行多个操作。避免了事务的限制,功能更强大。
-
内存管理:
-
使用自己的内存分配器 (如
jemalloc) 替代默认的libc malloc,减少内存碎片,提高分配效率。 -
内存淘汰策略 (Eviction Policies): 当内存不足时,根据配置的策略 (
maxmemory-policy) 删除 Key 来腾出空间。常见策略有:-
noeviction: 不淘汰,写操作报错 (默认)。 -
allkeys-lru/volatile-lru: 基于 LRU (最近最少使用) 淘汰所有键 / 只淘汰设置了过期时间的键。 -
allkeys-lfu/volatile-lfu(4.0+): 基于 LFU (最不经常使用) 淘汰。 -
allkeys-random/volatile-random: 随机淘汰。 -
volatile-ttl: 淘汰即将过期 (TTL 最小) 的键。
-
-
-
超时键删除:在 Redis 里面,有三种过期策略分别是:定时过期、惰性过期、定期过期。而 Redis 中同时使用了惰性过期和定期过期两种过期策略。
定时过期,是指每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即对 key 进行清 除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的 CPU 资源去处理过期的数据,从 而影响缓存的响应时间和吞吐量
惰性过期:是指被动访问某个 key 的时候,才会判断 key 是否已过期,过期则清除。该策略可以最大 化地节省 CPU 资源,却对内存非常不友好。极端情况可能出现大量的过期 key 没有再次被访问,从 而不会被清除,占用大量内存。
但是这两种方案都有点极端,Redis 里面还有另外一种折中的方案.就是定期过期。(Redis 时间轮算法) 这种方案会周期性轮询 redis 库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制 删除频率。
这种方式可以通过调整定时扫描的时间间隔和每次扫描耗时,实现在不同情况下使得 CPU 和内存资源 达到最优的平衡效果。
总结
Redis 的卓越性能是其底层多个精妙设计协同作用的结果:内存存储提供了基础速度,精心优化的数据结构保障了各种操作的效率,单线程事件循环 (结合 I/O 多路复用) 避免了并发开销并简化了实现,渐进式 rehash 等机制保证了平滑操作,持久化机制 (RDB/AOF/混合) 解决了数据可靠性问题,而主从复制、哨兵、集群则提供了高可用和扩展能力。理解这些底层原理对于高效使用、调优和运维 Redis 至关重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号