Spark、flink、hive、Hadoop、Yarn、Hbase、Kylin区别,用更加让人容易理解的方式来阐述(DS)
好的!我们把 Hadoop 生态系统想象成一个现代化的大数据加工厂,用更生动的方式解释这些核心部件的区别和关系:
🏭 工厂核心架构与基础设施
-
🏗️ Hadoop (HDFS + MapReduce):
-
角色:工厂的「地基」与「原始仓库+初级加工线」
-
HDFS (Hadoop Distributed File System): 巨大的分布式原料仓库。它把海量原始数据(日志、文档、图片等)切块后,分散存放在工厂里成百上千台机器上。核心能力:存得多、不怕机器坏(冗余备份)。 就像把钢材、木材分区域、多备份地存储在巨大仓库里。
-
MapReduce (早期): 一条原始、笨重的初级加工流水线。它能处理超大批量的原料(比如统计全仓库螺丝钉数量),方法是将任务拆分(Map)给大量工人并行做简单处理,再把结果汇总(Reduce)。特点:能处理海量但慢。 就像让大量工人手工数螺丝钉,最后汇总。
-
-
👮♂️ YARN (Yet Another Resource Negotiator):
-
角色:工厂的「中央调度中心」
-
职责: 管理和调度整个工厂的资源(CPU、内存、机器)。当 Spark、Flink、MapReduce、Hive 等“车间”需要资源来运行任务时,都要向 YARN 申请资源(集装箱卡车、工人)。YARN 负责分配资源、监控任务运行、回收资源。核心能力:让工厂资源高效共享,避免混乱。 就像总控台,Spark 车间主任喊:“我要10台卡车和50个工人!” YARN 调度员安排:“3号区卡车5台,工人20个给你;5号区卡车5台,工人30个给你。”
-
🏗️ 数据加工与处理车间
-
📊 Hive:
-
角色:「SQL 报表车间」
-
职责: 主要处理堆积如山的历史原料(数据)。它让熟悉 SQL(数据库语言)的分析师,用写报表的方式(SQL) 就能操作仓库(HDFS)里的海量数据。它把 SQL 翻译成 MapReduce 或 Spark 任务(需要YARN调度资源),在后台默默运行。核心能力:用SQL做离线批量分析、生成报表。 就像报表员用标准报表模板语言,让调度中心(YARN)安排工人(MapReduce/Spark)去仓库(HDFS)里数数、汇总,最后生成月度销售报告。
-
-
⚡ Spark:
-
角色:「全能高速加工中心」
-
职责: 一个速度快、功能多的现代化车间。它利用内存计算(把中间结果放高速缓存),速度比原始的 MapReduce 流水线快非常多!它能做:
-
批量加工: 高效处理历史数据(替代MapReduce,比Hive快)。
-
准实时流水线: 处理源源不断送来的新原料(数据流),有几分钟延迟(微批处理)。
-
机器学习/图计算: 有专门的高级加工区。
-
-
核心能力:速度快、通用性强、适合多种加工任务。 就像一个全自动数控机床中心,能批量切割钢材(批处理),也能处理传送带上陆续送来的小零件(准实时流),还能做精密建模(ML)。它需要调度中心(YARN)分配资源,原料来自仓库(HDFS)。
-
-
🚨 Flink:
-
角色:「超高速实时流水线」
-
职责: 专门设计来处理永不停止、高速流动的原料(实时数据流)。它的目标是毫秒/秒级超低延迟!对数据流中每一个事件(比如一笔交易、一次点击)都立刻处理。
-
核心能力:真正实时处理、事件驱动、状态管理精准。 就像一条超精密激光流水线,零件(数据事件)一过来就瞬间打标、检测、分类。比Spark的准实时流水线更快更灵敏。它也找调度中心(YARN)要资源,原料可能来自仓库(HDFS)或直接来自外部传送带(Kafka等)。
-
📦 存储与查询优化区
-
📈 Kylin:
-
角色:「预包装速查超市」,大数据查询的 “超级索引员”
- 通俗解读:
- 如果你想在仓库里找 “红色苹果在 2025 年 6 月的销量”,直接查 Hadoop 可能要翻遍所有抽屉,很慢。
- Kylin 就像提前把苹果按颜色、时间、产地等维度分好类(建 “数据立方体 Cube”),查询时直接找对应分类,秒出结果。
特点:专门优化复杂查询(比如多维度报表),适合企业级数据分析(领导想看各地区销售额排名,Kylin 能瞬间搞定)。
-
职责: 解决海量历史数据查询慢的问题。它不现场计算,而是提前把分析师可能问的各种复杂问题(基于维度模型/Cube)的答案算好、打包好,存放在一个高速货架(HBase/云存储) 上。当老板或分析师来问问题时,Kylin 直接拿出现成的答案包,响应飞快(秒级甚至毫秒级)。
-
核心能力:预计算、空间换时间、交互式查询极快(OLAP)。 就像提前把“上个月各区域各产品销售总额”、“本周用户活跃度排行榜”等报表打印好挂在墙上,老板一问秒答。它依赖报表车间(Hive)提供数据定义,常找高速加工中心(Spark)做预计算,成品存到高速货架(HBase)。
-
🚀 HBase:
-
角色:「高速随机存取货架」
-
职责: 一个分布式、可伸缩的NoSQL数据库。它不像HDFS仓库那样适合存原始大文件,而是像一个巨大的、智能的、可按行快速查找的货架系统。适合存储需要快速随机读写(按Key查) 的结构化/半结构化数据。
-
核心能力:低延迟随机读写、海量KV存储、强伸缩性。 就像工厂里的智能立体仓库,输入一个零件编号(Key),机械臂立刻把对应的零件(Value)取出来。它底层通常使用HDFS仓库做持久化存储。Kylin的预计算结果就常存在这里供快速查询。
🎯 总结与关系图
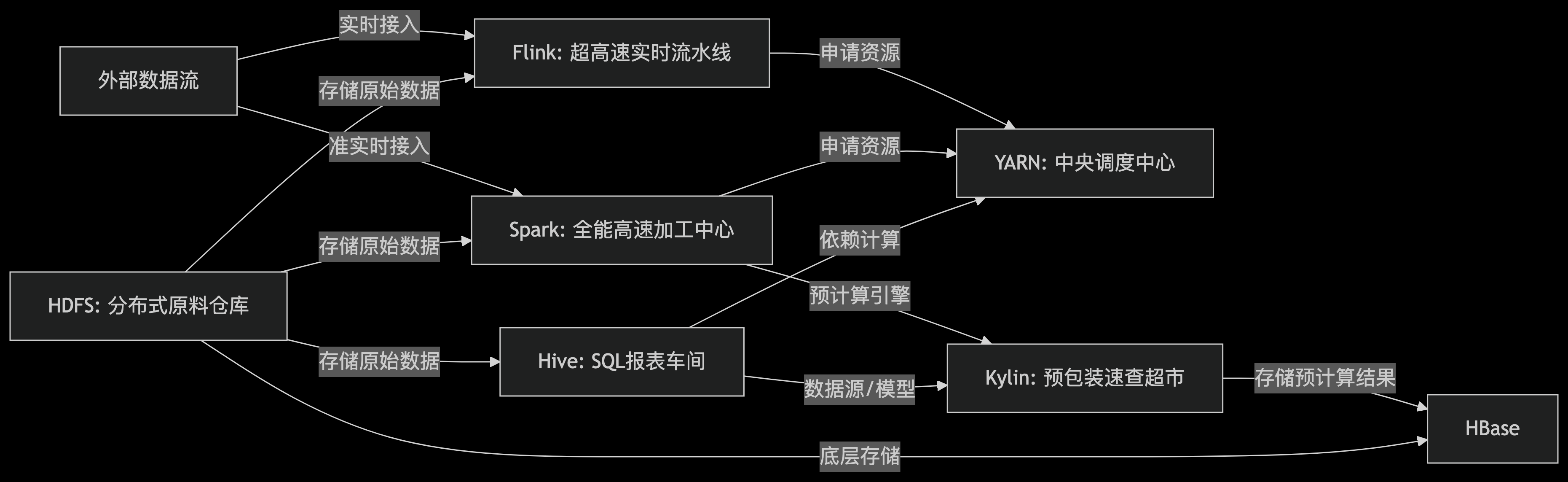
📌 关键区别与场景一句话指南
| 工具 | 核心角色 | 何时选用? | 关键特点 |
|---|---|---|---|
| HDFS | 海量原始仓库 | 需要可靠存储巨量原始文件(日志/视频等) | 存得多、不怕坏、顺序访问好,随机访问差 |
| YARN | 中央调度中心 | 所有计算任务(Spark/Flink/MapReduce/Hive)需要资源时 | 资源管理、调度、共享 |
| Hive | SQL报表车间 | 想用SQL分析历史数据,生成离线报表,不追求速度 | SQL on Hadoop, 慢但简单 |
| Spark | 全能高速加工中心 | 需要快速处理批量数据,或准实时流(分钟级),或做机器学习/图计算 | 内存计算、速度快、通用性强 |
| Flink | 超高速实时流水线 | 需要处理严格实时数据流(毫秒/秒级),如实时风控、监控 | 真正流处理、超低延迟、状态精准 |
| Kylin | 预包装速查超市 | 海量历史数据上需要秒级交互式查询、复杂多维分析 | 预聚合、用空间换时间、查询极快(OLAP) |
| HBase | 高速随机存取货架 | 需要快速按Key查询/更新海量结构化数据(如用户画像、实时订单状态) | NoSQL、低延迟随机读写、强伸缩性 |
| 技术 | 核心功能 | 速度特点 | 典型场景 | 类比对象 |
|---|---|---|---|---|
| Hadoop | 分布式存储与批处理 | 慢(硬盘处理) | 海量数据归档、离线统计 | 超级仓库管理员 |
| Hive | 将 SQL 转为 Hadoop 任务 | 中等 | 分析师用 SQL 做报表、统计 | SQL 翻译官 |
| Spark | 快速批处理 + 实时处理 | 快(内存处理) | 实时推荐、机器学习、复杂计算 | 高速公路跑车 |
| Flink | 流式实时处理 | 极快(实时响应) | 股票监控、用户行为实时分析 | 实时流水线 |
| Kylin | 预计算加速多维查询 | 极快(秒级响应) | 企业报表、多维度数据分析 | 超级索引员 |
工厂协作流举例:
实时订单监控: 订单数据流 -> Flink (实时处理,秒级欺诈检测) -> 结果存 HBase (供实时查询) / HDFS (供后续分析)
每日销售报表: 原始订单在 HDFS -> Hive (用SQL跑T+1报表) / Spark (更快地跑T+1报表)
高管交互式分析: Hive 定义数据模型 -> Spark 为 Kylin 预计算Cube -> 结果存 HBase -> 高管通过 Kylin 秒级查询任意维度组合的销售数据。
用户画像查询: 用户特征数据存 HBase -> 应用程序按UserID毫秒级查询。
记住: HDFS 是地基仓库,YARN 是调度大脑。
Hive/Spark/Flink 是主力加工车间 (Hive慢批,Spark快批+准实时,Flink真实时)。
HBase 是高速存取货架,Kylin 是预包装的速查超市(依赖加工车间和货架)。
它们各司其职,共同构建起强大的大数据处理工厂!根据你的业务需求(要存什么?离线分析?实时处理?快速查询?)选择合适的工具组合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号