【kafka】kafka内核原理
基础概念
kafka基础构成
producer
消息生产者,发布消息到kafka集群的终端或服务。
broker
kafaka集群中包含的服务器
topic
每条发布到kafka集群的消息属于的类别,即kafka是面向topic的。
partition
partition是物理上的概念,每个topic包含一个或多个partition,kafka分配的单位是partition。
Consumer
消费者,从kafka集群中消费消息的终端或服务。
consumer group
hig-level consumer api中,每个consumeer都属于一个consumer group,每条消息只能被consumer
group 中的一个consumer消费,但可以被多个consumer group 消费
replica
partition的副本,保障partition的高可用
leader
replica中的一个角色,producer和consumer只跟leader交互
follower
replica中的一个角色,从leader中复制数据
controller
不知道大家有没有思考过一个问题,就是kafka集群中某个broker宕机之后,是谁负责感知到他的宕机,以及
负责进行leader partition的选举?如果您在kafka集群中新加入一些机器,此时谁来负责把集群中的数据
尽心负载均衡的迁移,包括你的kafka集群的各种元数据,比如说每台机器有哪些partition,谁是leader,谁
是follower,是谁来管理呢?比如你要删除一个topic,那么背后的各种partition如何删除,是谁来控制?
还有就是比如kafka集群扩容加入一个新的broker,是谁负责监听这个broker的加入?
kafka通过zookeeper来存贮集群中的meta信息。一旦controller所在broker宕机来,此时临时节点消失,集群中其他broker会一直监听这个临时节点,发现临时节点消失来,就争抢再次创建临时节点,保证有一台新的broker会成为controller角色。
从有controller这个事情来说,我们就知道kafka是一个主从架构的,只不过这个controller也做数据处理的同时,也管理者集群。
接下来,我说一下,这个过程。
刚开始集群启动的时候,每一个broker都会向zookeeper发起注册,一旦有其中某个节点注册成功,那么这个节点就是controller了。
下面这是kafka的架构图。
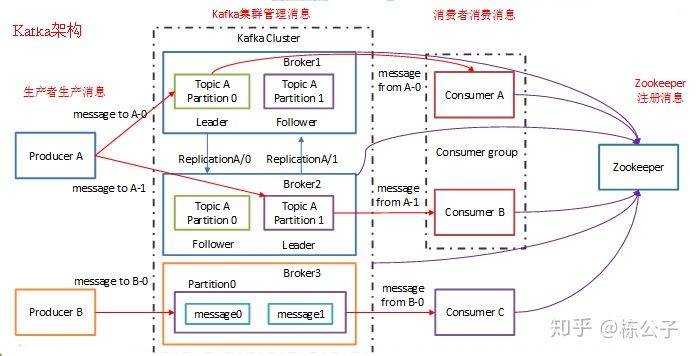
有了上面的基础知识,我们就可以真正的来说一下kafka的内核原理了。
内核原理
零拷贝
先来两张图片

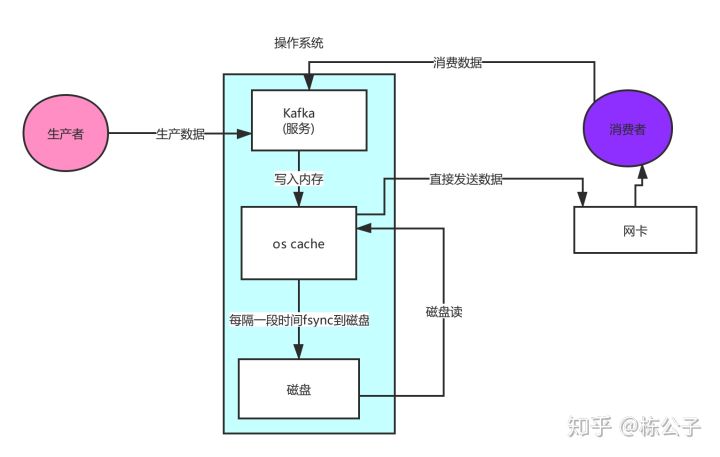
第一张图是非零拷贝,我们可以这样认为,生产者生产数据发送到kafka服务,然后kafka先写入内存,然后再写入磁盘,然后从磁盘中读数据到内存中,然后在读到kakfa服务。然后再通过socket发送到消费者,这个过程拷贝的次数有点过。
反观第二张图,就是零拷贝,他是直接从内存中读取数据,之际通过网卡发送数据到消费者,中间拷贝数据的次数一下子就少了好多,于是就提升了性能,kafka就是用了零拷贝这个机制。
日志分段存贮
不知道大家注意到一个事情没有,在搭建kafka集群的时候,我们会配置一个logs目录,这个目录就是存贮kafka数据的地方,我们来打开这个配置项看一下。
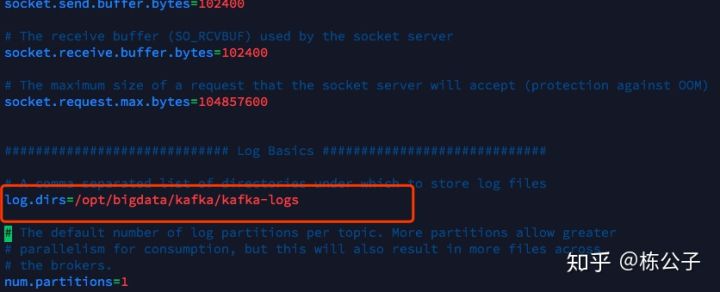
那么我们再来看一下这个目录真正的是什么样子的。
首先我通过创建topic命令,创建一个话题,命令如下
/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 3 --partitions 3 --topic new
我创建了一个topic叫new,然后给他了他三个分区,然后三个副本.这里需要说明一下参数
比如partition代表是分区,而replication-factor代表的是副本数。
创建完之后,我们就可以看到如下内容。
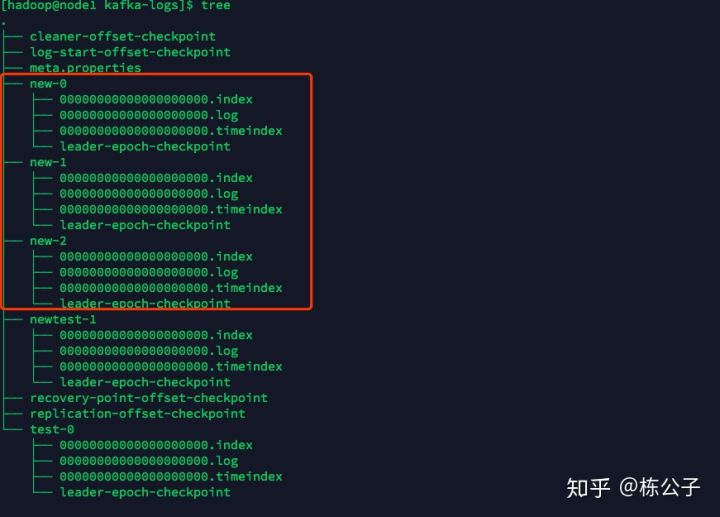
你可以看到,每一个分区以话题加上横杠后面加上从零开始的数字组成,然后在里面就是00000.log文件,这里面存贮的就是消息。
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindex
这个9936472之类的数字,就是代表了这个日志段文件中包含的起始offset,也就说明了这个分区里至少都写入了接近1000万条数据了,kafka broker有一个参数log.segment.bytes,限定了每个日志段文件的大小,最大就是1GB,一个日志段文件满了,就自动开一个新的日志文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做log rolling,正在被写入的那个日志段文件,叫做active log segment..
日志二分查找
上面我们说消息是记录在.log文件里面的,那么他是如何找到这条消息的呢?
日志文件段,.log文件会对应一个.index和.timeindex两个索引文件,kafaka在写入日志文件的时候,同时会写索引文件,就是,.index和.timeindex,一个是位移索引,一个是时间戳索引。
默认情况下,有个参数log.index.interval.bytes限定了在日志文件写入多少数据,就要在索引文件中写一条索引,默认是4kb,写4kb的数据先人后在索引里写一条索引,所以索引本身是稀疏格式的索引,不是每条数据对应一条索引,而且索引文件里的数据是按照位移和时间戳生序排序的,所以kafka在查找索引的时候,会用二分查找,时间复杂度是O(logN),找到索引,就可以在.log文件里定位到数据了。
.timeindex是时间戳索引文件,如果要查找某段时间范围内的时间,现在这个文件里二分查找到offset,然后再去.index里根据offset二分查找对应.log文件里的位置,最后就去.log文件里查找对应的数据。
索引文件映射到内存中,所以查询速度很快的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号