
深度学习面试题32:循环神经网络原理(RNN)
目录
单层神经网络
RNN原理
经典RNN结构
N VS 1 RNN结构
1 VS N RNN结构
Pytorch文本分类实践
参考资料
RNN 的英文全称是 Recurrent Neural Networks ,即循环神经网络,他是一种对序列型数据进行建模的深度模型。在学习之前,先来复习基本的单层神经网络。
|
单层神经网络 |
单层网络的输入是向量x,经过Wx+b和激活函数f得到输出y。
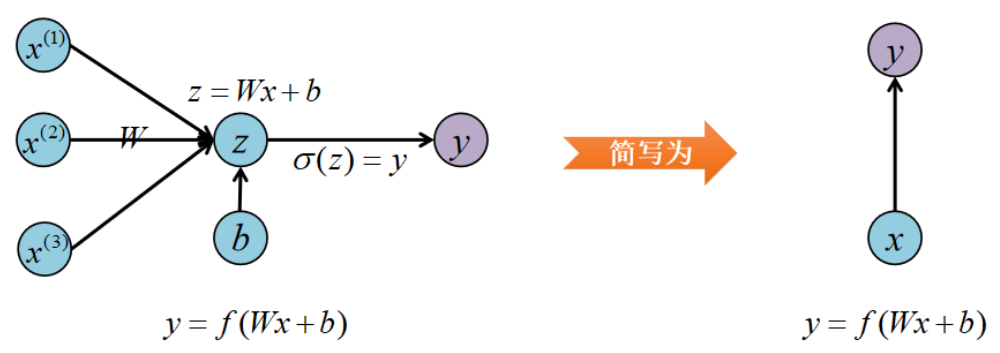
在实际应用中,我们会遇到很多序列形的数据:
例如:
自然语言处理问题中,x1可以看作是第1个单词的向量,x2可以看作是第2个单词的向量。
语音处理中,x1,x2,x3,......可以看作是每一帧声音信号的向量。
序列型的数据可以认为是一串信号,
比如一段文本“您吃了吗?”
x1可以表示“您”,x2表示“吃”,依次类推。
![]() 可以表示“您”的独热编码。
可以表示“您”的独热编码。
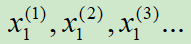 可以表示“您”的独热编码。
可以表示“您”的独热编码。序列形数据不好用传统的神经网络处理,因为传统神经网络不能考虑一串信号中每个信号顺序关系。这时候就能用RNN来处理。
|
RNN原理 |
以文本分类举例(分析用户对电影是积极评价还是消极评价),某一条训练数据为【“这个电影特效不差,推荐大家去看”,积极】
首先对文本分词:
这个/电影/特效/不/差/推荐/大家/去/看
这时候我们可以把分词结果按顺序依次输入神经网络,这也要求网络能够处理词汇的顺序信息(否则输入也能变成“这个电影特效差,不推荐大家去看”,恰好就变为消极类)
RNN引入了隐状态的概念,就可以达到一种效果:你输入模型的顺序为“这个电影特效不差”时,能理解为积极的;你输入“这个电影特效差”时,能理解为消极的。
也就是RNN借助隐状态,捕获到了输入数据顺序的信息
RNN的结构如下图所示:
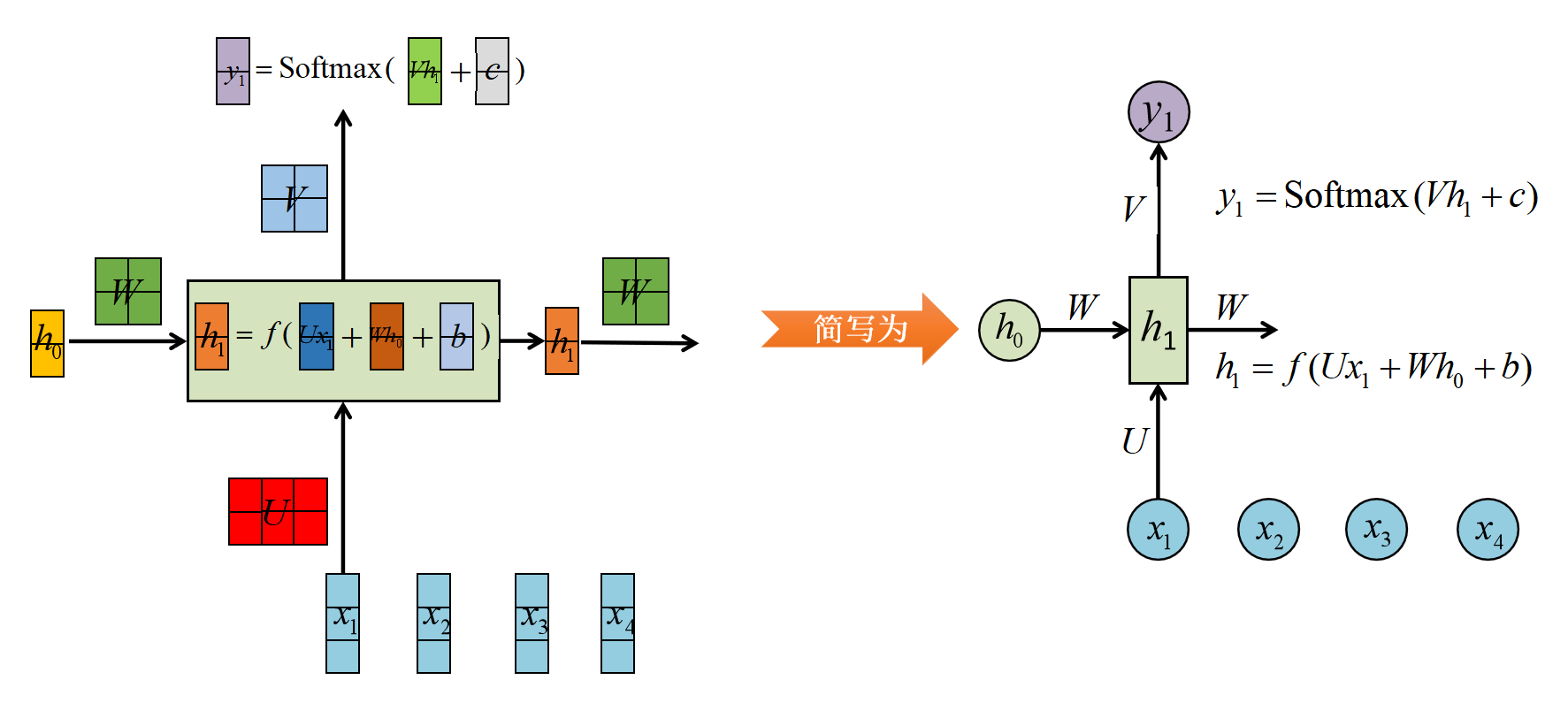
其中,
h0为初始的记忆单元,一般以0向量初始化;
x1为第1个词向量;
W、U、V、b、c为模型参数,他们在每一个时间步是共享的,也就是h1输出之后计算h2以及y2时,还是使用的W、U、V、b、c参数;
y1为第1个输出向量
|
经典RNN结构 |
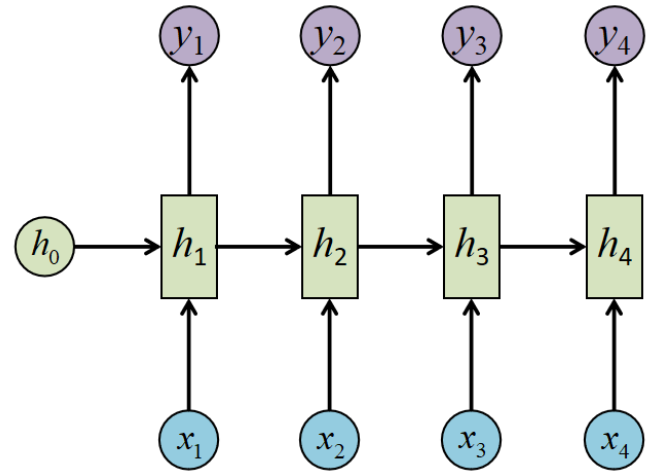
这就是最经典的RNN结构,他的输入是x1,x2,...,xn,输出为y1,y2,...,yn,也就是说输入序列和输出序列必须是等长的,由于这个限制,经典RNN的适用范围比较小,但也有一些问题上适用,比如:
计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。
输入为字符,输出为下一个字符的概率。这就是著名的CharRNN问题。
|
N VS 1 RNN结构 |
有的时候,问题的输入是一个序列,输出是一个单独的值,此时只需在最后一个h上进行输出变换就可以了
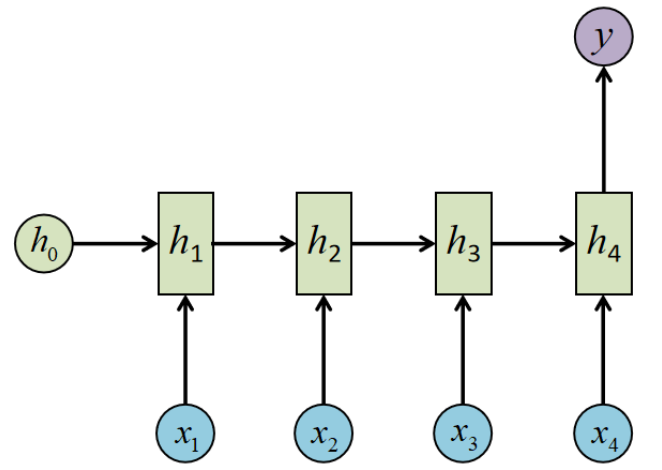
这种结构通常用来处理序列分类问题,比如:
输入一段文字判别它所属的类别;
输入一个句子判断其情感倾向;
输入一段视频判断他的类别
|
1 VS N RNN结构 |
输入不是序列,而输出是序列如何处理?结构改为下图即可
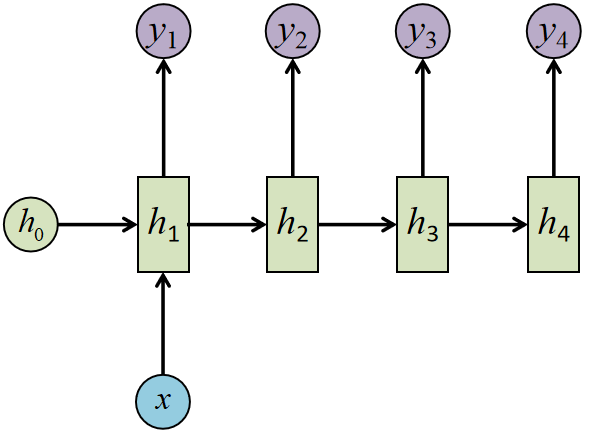
应用场景:
从图像生成文字(image caption)
从类别生成语音或音乐等
|
Pytorch文本分类实践 |
该项目为《NLP FROM SCRATCH: CLASSIFYING NAMES WITH A CHARACTER-LEVEL RNN》
项目地址https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial
项目介绍:该项目是一个18类的文本分类任务,18类表示18个国家,每个国家也就是一个标签。每个标签下的样本是一个姓氏文本(比如:“Abakumtsev”,这是一个俄国人的常用姓氏)。简言之:根据一个姓氏,判别这个姓氏属于哪个国家。
PS:个人感觉本项目的代码里存在一些问题,经过修正后,准确率得到了提升(主要调整了一个网络架构以及加入了一个relu激活函数),我也在和作者进行沟通,详情可以查看https://github.com/pytorch/tutorials/issues/1052
思路:
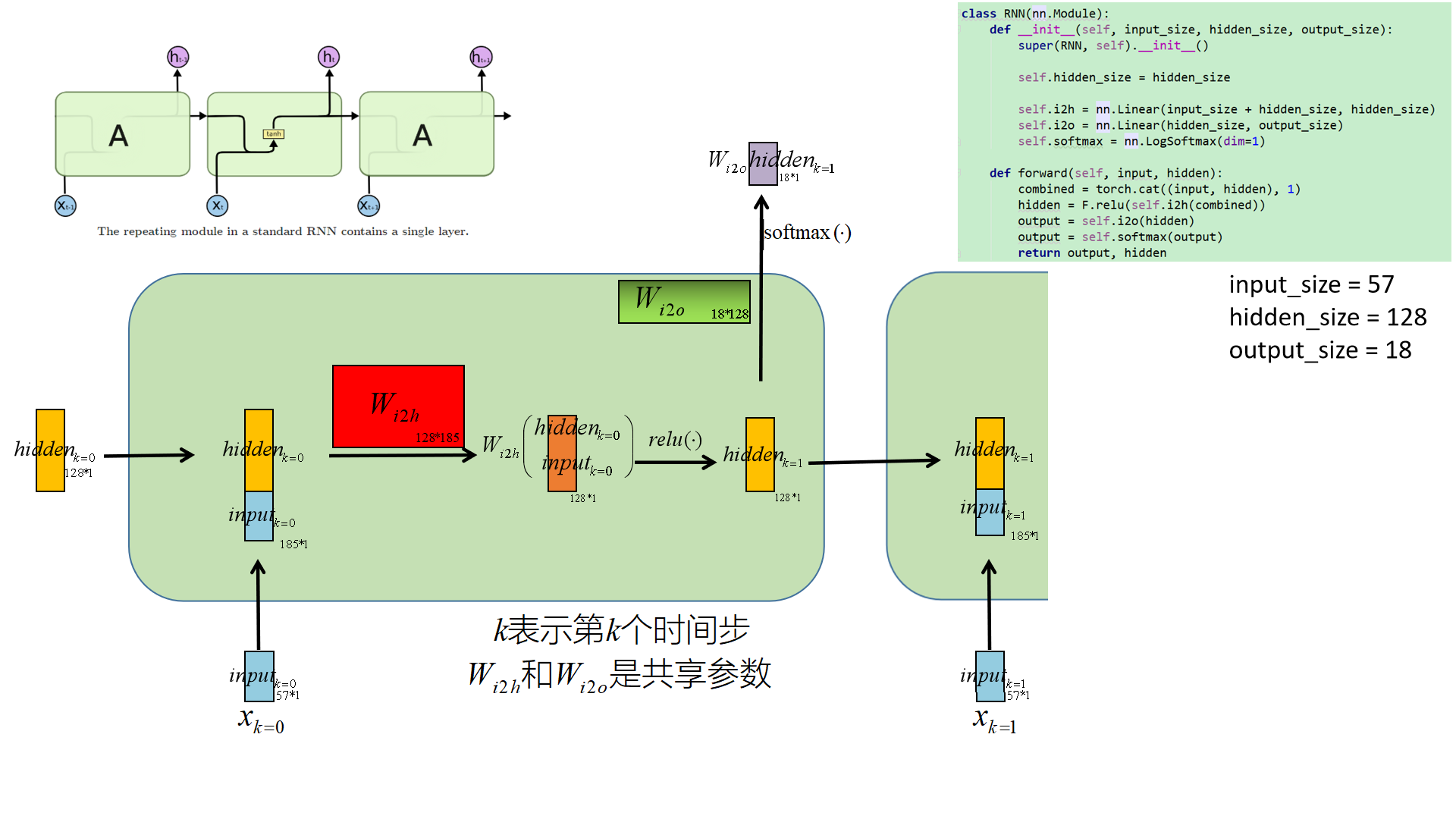
■ 对每个文本拆解为字符粒度,每个字符进行独热编码,本项目中一个字符由一个含57维向量表示。那么一个长度为5的单词,就可以用一个5*57的矩阵表示。实际就是CharRNN的做法。
■ 网络的初始隐藏层置为0向量,然后一个字符一个字符的传入网络,最终对最后一个时间步的隐藏层做Softmax转换,接着使用交叉熵构造损失函数。
■ 梯度反向传播,更新网络参数。
■ 预测的时候,同训练一致。不同点是在最后一个时间步,对隐藏层做Softmax转换后,输出概率最大的类别作为最终预测的标签。
下图描绘的是RNN的矩阵表示,与前面那张图大同小异。同时这幅图更细节的展示了本项目的架构、参数以及运行中间步骤各个张量的尺寸信息,相信这对大家深入理解RNN和本项目有很大帮助。
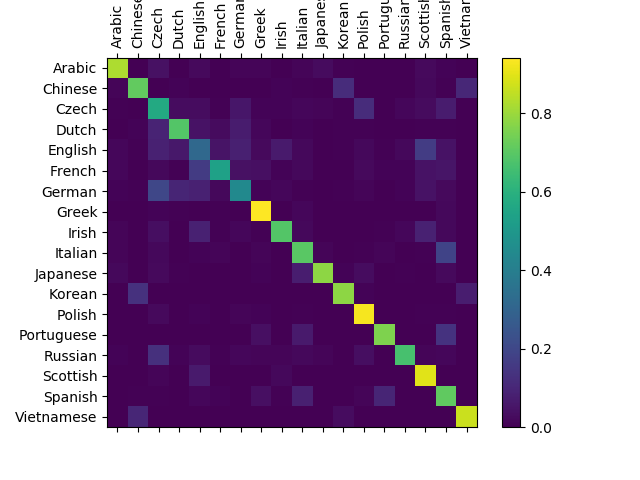
该项目的结果的混淆矩阵如下图所示,可以看到准确率还是不错的:
对应代码


from __future__ import unicode_literals, print_function, division from io import open import glob import os def findFiles(path): return glob.glob(path) print(findFiles('data/names/*.txt')) import unicodedata import string all_letters = string.ascii_letters + " .,;'" n_letters = len(all_letters) # Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427 def unicodeToAscii(s): return ''.join( c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn' and c in all_letters ) print(unicodeToAscii('Ślusàrski')) # Build the category_lines dictionary, a list of names per language category_lines = {} all_categories = [] # Read a file and split into lines def readLines(filename): lines = open(filename, encoding='utf-8').read().strip().split('\n') return [unicodeToAscii(line) for line in lines] for filename in findFiles('data/names/*.txt'): category = os.path.splitext(os.path.basename(filename))[0] all_categories.append(category) lines = readLines(filename) category_lines[category] = lines n_categories = len(all_categories) print(category_lines['Italian'][:5]) import torch # Find letter index from all_letters, e.g. "a" = 0 def letterToIndex(letter): return all_letters.find(letter) # Just for demonstration, turn a letter into a <1 x n_letters> Tensor def letterToTensor(letter): tensor = torch.zeros(1, n_letters) tensor[0][letterToIndex(letter)] = 1 return tensor # Turn a line into a <line_length x 1 x n_letters>, # or an array of one-hot letter vectors def lineToTensor(line): tensor = torch.zeros(len(line), 1, n_letters) for li, letter in enumerate(line): tensor[li][0][letterToIndex(letter)] = 1 return tensor print(letterToTensor('J')) print(lineToTensor('Jones').size()) import torch.nn as nn import torch.nn.functional as F class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.i2h = nn.Linear(input_size + hidden_size, hidden_size) self.i2o = nn.Linear(hidden_size, output_size) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): combined = torch.cat((input, hidden), 1) hidden = F.relu(self.i2h(combined)) output = self.i2o(hidden) output = self.softmax(output) return output, hidden def initHidden(self): return torch.zeros(1, self.hidden_size) n_hidden = 128 rnn = RNN(n_letters, n_hidden, n_categories) input = letterToTensor('A') hidden =torch.zeros(1, n_hidden) output, next_hidden = rnn(input, hidden) input = lineToTensor('Albert') hidden = torch.zeros(1, n_hidden) output, next_hidden = rnn(input[0], hidden) print(output) def categoryFromOutput(output): top_n, top_i = output.topk(1) category_i = top_i[0].item() return all_categories[category_i], category_i print(categoryFromOutput(output)) import random random.seed(66) def randomChoice(l): return l[random.randint(0, len(l) - 1)] def randomTrainingExample(): category = randomChoice(all_categories) line = randomChoice(category_lines[category]) category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long) line_tensor = lineToTensor(line) return category, line, category_tensor, line_tensor for i in range(10): category, line, category_tensor, line_tensor = randomTrainingExample() print('category =', category, '/ line =', line) criterion = nn.NLLLoss() learning_rate = 0.005 # If you set this too high, it might explode. If too low, it might not learn def train(category_tensor, line_tensor): hidden = rnn.initHidden() rnn.zero_grad() for i in range(line_tensor.size()[0]): output, hidden = rnn(line_tensor[i], hidden) loss = criterion(output, category_tensor) loss.backward() # Add parameters' gradients to their values, multiplied by learning rate for p in rnn.parameters(): p.data.add_(p.grad.data, alpha=-learning_rate) return output, loss.item() import time import math n_iters = 100000 print_every = 5000 plot_every = 1000 # Keep track of losses for plotting current_loss = 0 all_losses = [] def timeSince(since): now = time.time() s = now - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s) start = time.time() PATH = './char-rnn-classification.pth' for iter in range(1, n_iters + 1): category, line, category_tensor, line_tensor = randomTrainingExample() output, loss = train(category_tensor, line_tensor) current_loss += loss # Print iter number, loss, name and guess if iter % print_every == 0: guess, guess_i = categoryFromOutput(output) correct = '✓' if guess == category else '✗ (%s)' % category print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct)) # Add current loss avg to list of losses if iter % plot_every == 0: all_losses.append(current_loss / plot_every) current_loss = 0 torch.save(rnn.state_dict(), PATH) net = RNN(n_letters, n_hidden, n_categories) net.load_state_dict(torch.load(PATH)) import matplotlib.pyplot as plt import matplotlib.ticker as ticker plt.figure() plt.plot(all_losses) # Keep track of correct guesses in a confusion matrix confusion = torch.zeros(n_categories, n_categories) n_confusion = 100000 # Just return an output given a line def evaluate(line_tensor): hidden = rnn.initHidden() for i in range(line_tensor.size()[0]): output, hidden = rnn(line_tensor[i], hidden) return output # Go through a bunch of examples and record which are correctly guessed n_correct = 0 n_sum = 0 for i in range(n_confusion): category, line, category_tensor, line_tensor = randomTrainingExample() output = evaluate(line_tensor) guess, guess_i = categoryFromOutput(output) category_i = all_categories.index(category) confusion[category_i][guess_i] += 1 if category == guess: n_correct += 1 n_sum += 1 print("acc",n_correct/n_sum) # Normalize by dividing every row by its sum for i in range(n_categories): confusion[i] = confusion[i] / confusion[i].sum() # Set up plot fig = plt.figure() ax = fig.add_subplot(111) cax = ax.matshow(confusion.numpy()) fig.colorbar(cax) # Set up axes ax.set_xticklabels([''] + all_categories, rotation=90) ax.set_yticklabels([''] + all_categories) # Force label at every tick ax.xaxis.set_major_locator(ticker.MultipleLocator(1)) ax.yaxis.set_major_locator(ticker.MultipleLocator(1)) # sphinx_gallery_thumbnail_number = 2 plt.show()
|
参考资料 |
《21个项目玩转深度学习:基于Tensorflow的实践详解》
https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial

 浙公网安备 33010602011771号
浙公网安备 33010602011771号