Java SE面试整理
Java基础常见面试题总结
Lambda表达式
基本语法
- 参数部分
-
无参数:
() -> System.out.println("Hello, world!"); -
一个参数:
-
无需括号:
s -> System.out.println(s); -
带括号(特别是需要显式声明类型时):
(String s) -> System.out.println(s);
-
-
多个参数:
(a, b) -> a + b; -
带类型的多个参数:
(int a, int b) -> a + b;
- 箭头符号
->
箭头符号 -> 将Lambda表达式的参数部分与主体部分分开。
- 主体部分
-
单个表达式:
-
当主体部分是单个表达式时,可以省略大括号 {}和return 语句:
(a, b) -> a + b;
-
-
代码块:
-
当主体部分是一个代码块时,需要用大括号 {}包围,并且可以使用多个语句:
(a, b) -> { int sum = a + b; return sum; };
-
基础概念与常识
Java语言特点:
- 面向对象(封装、继承、多态)
- 平台无关性(Java虚拟机实现平台无关性,不同版本的操作系统中安装有不同版本的Java虚拟机,Java程序的运行只依赖于Java虚拟机)Write Once, Run Anywhere(一次编写,随处运行)
- 支持多线程
- 可靠性(具备异常处理和自动内存管理机制)
- 安全性(Java 语言本身的设计就提供了多重安全防护机制如访问权限修饰符、限制程序直接访问操作系统资源);
- 支持网络编程并且很方便;
- 编译与解释并存;
Java SE vs Java EE
Java SE 是 Java 的基础版本,Java EE 是 Java 的高级版本。
JVM vs JDK vs JRE
JDK(Java Development Kit)由JVM、核心类库、开发工具(java,javac...)组成。
JRE(Java Runtime Enviroment),Java的运行环境,由JVM和核心类库组成的。
JVM(Java Virtual Machine),运行 Java 字节码的虚拟机。
JDK、JRE的关系用一句话总结就是:用JDK开发程序,交给JRE运行。
字节码及其好处
字节码(扩展名为 .class 的文件)
.java --> javac编译 --> .class -->解释器&JIT--> 机器理解的代码
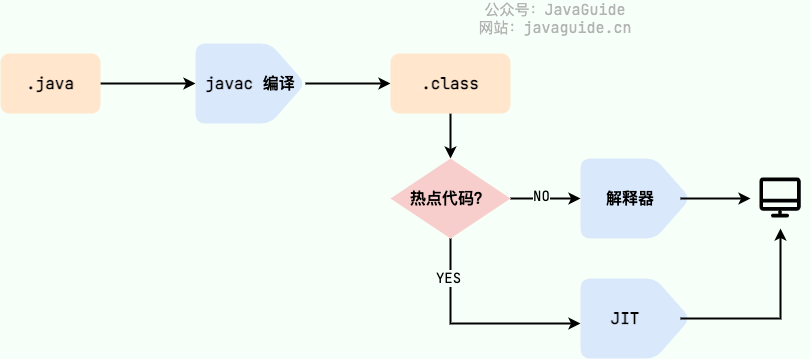
注意:.class->机器码 这一步,若是热点代码,使用 JIT(Just in Time Compilation) 编译器, JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用;否则通过Java解释器逐行解释执行,这种方式的执行速度会相对比较慢。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言 。
Java为了便于虚拟机执行Java程序,将虚拟机的内存划分为 方法区、栈、堆、本地方法栈、寄存器这5块区域。同学们需要重点关注的是 方法区、栈、堆。
-
方法区:字节码文件先加载到这里
-
栈:方法运行时所进入的内存区域,由于变量在方法中,所以变量也在这一块区域中
-
堆:存储new出来的东西,并分配地址。由于数组是new 出来的,所以数组也在这块区域。
Java 语言为什么“编译与解释并存”?
高级编程语言分为两种:
编译型:编译型语言会通过编译器将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
解释型:解释型语言会通过解释器一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行。
Java和C++的区别
Java 和 C++ 都是面向对象的语言,都支持封装、继承和多态,但是,它们还是有挺多不相同的地方:
- Java 不提供指针来直接访问内存,程序内存更加安全
- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
- Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
- C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
基本语法
标识符和关键字的区别
标识符:程序、类、变量、方法的名字,是我们自己取的名字;
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
类名:首字母大写(大驼峰命名)
变量名:第二个单词开始首字母大写(小驼峰命名)
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
关键字:被赋予特殊含义的标识符
Tips:所有的关键字都是小写的。
continue、break 和 return 的区别
continue:指跳出当前的这一次循环,继续下一次循环。break:指跳出整个循环体,继续执行循环下面的语句。return用于跳出所在方法,结束该方法的运行。
基本数据类型
Java的基本数据类型
Java一共有8种数据类型
6种数字类型。
-
4种整数型:
byte1、short2、int4、long8 -
2 种浮点型:
float4、double8
1种字符类型:char2
1种布尔型:boolean1
注意:
- Java 里使用
long类型的数据一定要在数值后面加上 L,否则将作为整型解析。- 比如23,它默认就为int类型;如果加上后缀L,则为long类型;
- 比如23.8,它默认为double类型;如果加上后缀F,则为float类型;
char a = 'h'char :单引号,String a = "hello":双引号。
八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean 。
基本类型和包装类型的区别
- 用途:除了定义一些常量和局部变量之外,我们在其他地方比如 方法参数、对象属性 中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
- 存储方式:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被
static修饰 )存放在 Java 虚拟机的堆中;包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。 - 占用空间:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
- 默认值:成员变量包装类型不赋值就是
null,而基本类型有默认值且不是null。 - 比较方式:对于基本数据类型来说,
==比较的是值。对于包装数据类型来说,==比较的是对象的内存地址。所有整型包装类对象之间值的比较,全部使用equals()方法。
⚠️ 注意:基本数据类型的存储位置取决于它们的作用域和声明方式。如果它们是局部变量,那么它们会存放在栈中;如果它们是成员变量,那么它们会存放在堆中。(被 static 修饰,也存放在堆中,但属于类,不属于对象)
public class Test {
// 成员变量,存放在堆中
int a = 10;
// 被 static 修饰,也存放在堆中,但属于类,不属于对象
// JDK1.7 静态变量从永久代移动了 Java 堆中
static int b = 20;
public void method() {
// 局部变量,存放在栈中
int c = 30;
static int d = 40; // 编译错误,不能在方法中使用 static 修饰局部变量
}
}
包装类型的缓存机制
包装类型的大部分都用到了缓存机制来提升性能。
Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or False。
Integer 缓存源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static {
// high value may be configured by property
int h = 127;
}
}
如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
两种浮点数类型的包装类 Float,Double 并没有实现缓存机制。
Integer i1 = 33;
Integer i2 = 33;
System.out.println(i1 == i2);// 输出 true
Float i11 = 333f;
Float i22 = 333f;
System.out.println(i11 == i22);// 输出 false
Double i3 = 1.2;
Double i4 = 1.2;
System.out.println(i3 == i4);// 输出 false
即使两个 float 字面量的值看起来相同,由于浮点数的精度问题,它们可能并不完全相等。
比较两个浮点数的数值是否相等,通常应该使用一个小的容差值来比较它们,而不是直接使用 == 操作符。
Integer i1 = 40; // 自动装箱,等价于Integer i1=Integer.valueOf(40)
Integer i2 = new Integer(40); // 显式地创建一个新的Integer对象
System.out.println(i1==i2);
Integer i1=40这一行代码会发生装箱,也就是说这行代码等价于Integer i1=Integer.valueOf(40)。
因此,i1直接使用的是常量池中的对象。
而Integer i2 = new Integer(40)会直接创建新的对象。
因此,答案是false。
记住:所有整型包装类对象之间值的比较,全部使用 equals 方法比较。

自动装箱与拆箱原理
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
Integer i = 10; //装箱
int n = i; //拆箱
因此,
装箱调用包装类的valueOf()方法,拆箱调用 xxxValue()方法。
Integer i = 10等价于Integer i = Integer.valueOf(10)int n = i等价于int n = i.intValue();
注意:如果频繁拆装箱的话,也会严重影响系统的性能。我们应该尽量避免不必要的拆装箱操作。
自动拆箱引发的NPE问题
浮点数运算精度丢失及其解决方法
计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以导致小数精度发生损失的情况。
BigDecimal 实现对浮点数的运算,不会造成精度丢失。
通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
超过 long 整型的数据如何表示?
当数据超过 long 整型的范围时,可以考虑使用BigInteger 类型来表示大整数。
BigInteger 内部使用 int[] 数组来存储任意大小的整形数据,但相对于常规整数类型的运算来说,BigInteger 运算的效率会相对较低。
import java.math.BigInteger;
public class LargeIntegerExample {
public static void main(String[] args) {
// 创建两个大整数
BigInteger num1 = new BigInteger("1234567890123456789012345678901234567890");
BigInteger num2 = new BigInteger("9876543210987654321098765432109876543210");
// 进行加法操作
BigInteger sum = num1.add(num2);
// 打印结果
System.out.println("Sum: " + sum);
}
}
变量
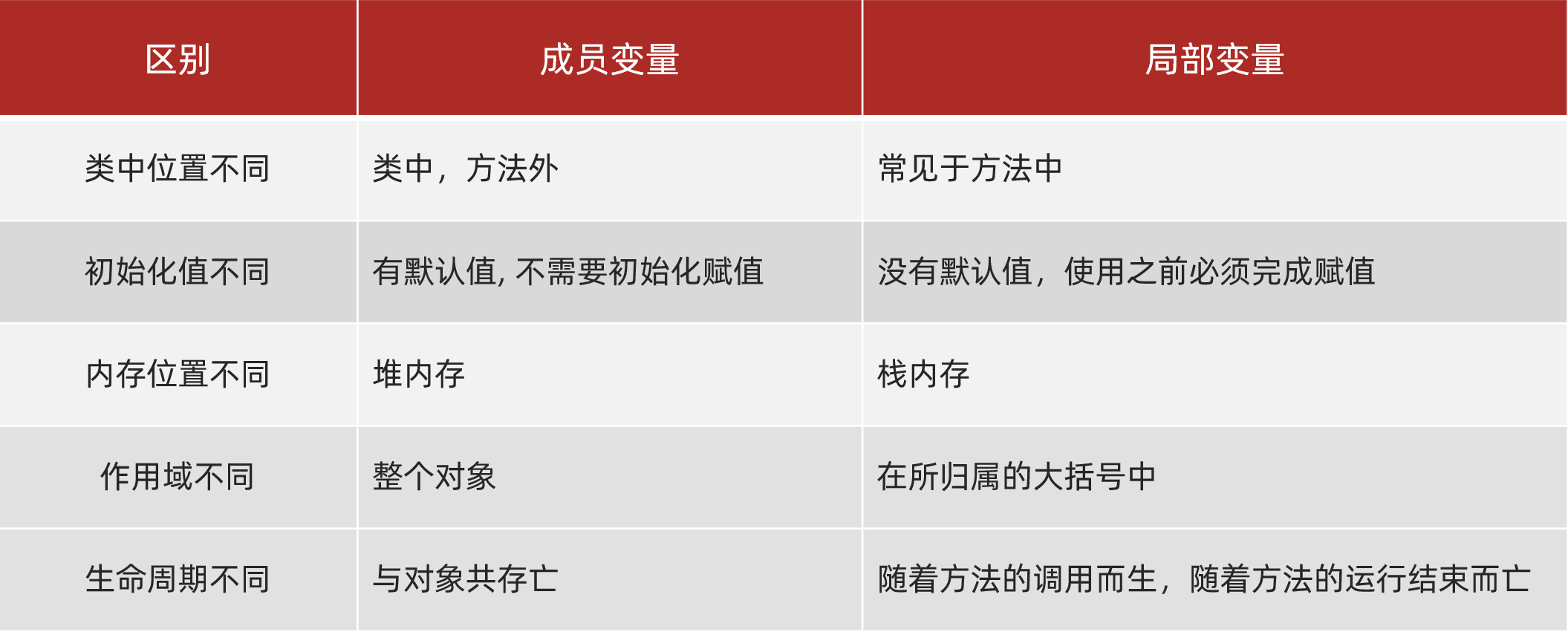
成员变量和局部变量的区别
语法形式:成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;
成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
存储方式:
如果成员变量是使用 static 修饰的,那么这个成员变量是属于类的(存放在堆中)
如果没有使用 static 修饰,成员变量是属于实例的,而对象存在于堆内存,局部变量则存在于栈内存。
被 static 修饰,也存放在堆中,但属于类,不属于对象。
生存时间:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
默认值:成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
静态变量作用
静态变量:是被 static 关键字修饰的变量。
可以被类的所有实例共享,无论一个类创建了多少个对象,都共享同一份静态变量,即静态变量只会被分配一次内存,即使创建多个对象,这样可以节省内存。
静态变量是通过类名来访问的,例如StaticVariableExample.staticVar(如果被 private关键字修饰就无法这样访问)。
public class StaticVariableExample {
// 静态变量
public static int staticVar = 0;
}
通常情况下,静态变量会被 final 关键字修饰成为常量。
public class ConstantVariableExample {
// 常量
public static final int constantVar = 0;
}
字符型常量和字符串常量的区别
- 形式 : 字符常量是单引号引起的一个字符,字符串常量是双引号引起的 0 个或若干个字符。
- 含义 : 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)。
- 占内存大小:字符常量只占 2 个字节; 字符串常量占若干个字节。
方法
方法返回值及方法的几种类型
方法的返回值 :获取到的某个方法体中的代码执行后产生的结果!
静态方法为什么不能调用非静态成员
静态方法属于类,而不属于类的具体实例。可以直接通过类名调用静态方法,而不需要创建类的实例。
非静态成员:类的实例成员,包括非静态字段(成员变量)和非静态方法。
public class StaticMethodExample {
// 静态方法
public static void staticMethod() {
System.out.println("This is a static method.");
}
// 非静态方法
public void nonStaticMethod() {
System.out.println("This is a non-static method.");
}
public static void main(String[] args) {
// 调用静态方法
StaticMethodExample.staticMethod();// 通过类名调用静态方法
// 创建类的实例
StaticMethodExample instance = new StaticMethodExample();
// 调用非静态方法
instance.nonStaticMethod();
}
}
- 静态方法是属于类的,可以通过类名直接访问,而非静态成员属于实例对象,只有在对象实例化之后才存在,需要通过类的实例对象去访问。
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中还不存在的非静态成员,属于非法操作。
静态方法和实例方法的区别
-
调用方式
调用静态方法无需创建对象 ,调用实例方法必须先创建对象,使用
对象.方法名调用。public class Person { public void method() { //...... } public static void staicMethod(){ //...... } public static void main(String[] args) { Person person = new Person(); // 调用实例方法 person.method(); // 调用静态方法 Person.staicMethod() } } -
访问类成员是否存在限制
静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),不允许访问实例成员(即实例成员变量和实例方法),而实例方法不存在这个限制。
重载和重写的区别
重载Overloading:同样的一个方法能够根据输入数据的不同,做出不同的处理。
方法名必须相同
如果多个方法(比如 StringBuilder 的构造方法)有相同的名字、不同的参数, 便产生了重载。
StringBuilder sb = new StringBuilder();
StringBuilder sb2 = new StringBuilder("HelloWorld");
综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。
一般在开发中,我们经常需要为处理一类业务,提供多种解决方案,此时用方法重载来设计是很专业的。
==============================================================================================================================================================================================================================================================================================================================================================================================================================================
重写Overriding:当子类继承自父类的相同方法,方法名、参数列表必须相同,返回类型应该和父类相同也可以是其子类。
- 如果父类方法访问修饰符为
private/final/static则子类就不能重写该方法,但是被static修饰的方法能够被再次声明。 - 构造方法无法被重写
class Animal {
public void makeSound() {
System.out.println("Animal makes a sound");
}
}
class Dog extends Animal {
// 重写父类方法
@Override
public void makeSound() {
System.out.println("Dog barks");
}
}
public class Example {
public static void main(String[] args) {
Animal animal = new Dog(); // 向上转型
animal.makeSound(); // 调用的是 Dog 类的 makeSound 方法
}
}
综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。
方法的重写要遵循“两同两小一大”:
-
“两同”即方法名相同、形参列表相同;
-
“两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
如果一个对象是父类的实例,那么调用父类方法得到的返回值,一定可以赋值给子类类型的变量。
如果一个方法抛出某个异常,那么子类方法可以抛出该异常的子类,这不会破坏异常的处理逻辑。
-
“一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。
访问权限有四个等级:
public(最大权限)、protected(可以被同一包内的类和不同包中的子类访问)、默认(只能被同一包内的类访问,默认不写修饰符)和private(最小权限)。class Animal { protected void eat() { System.out.println("Animal is eating"); } } class Dog extends Animal { // 这里尝试将访问权限缩小为默认(包内可见)只有在同一个包内的其他类才能访问 Dog 类的 eat() 方法。 void eat() { System.out.println("Dog is eating"); } } public class Main { public static void main(String[] args) { Animal myDog = new Dog(); myDog.eat(); // 使用父类引用调用 } }
知道什么是方法重写之后,还有一些注意事项,需要和大家分享一下。
- 1.重写的方法上面,可以加一个注解@Override,用于标注这个方法是复写的父类方法
- 2.子类复写父类方法时,访问权限必须大于或者等于父类方法的权限
public > protected > 缺省
- 3. 重写的方法返回值类型,必须与被重写的方法返回值类型一样,或者范围更小
- 4. 私有方法、静态方法不能被重写,如果重写会报错。
关于这些注意事项,同学们其实只需要了解一下就可以了。实际上我们实际写代码时,只要和父类写的一样就可以( 总结起来就8个字:声明不变,重新实现)
方法重写的应用场景
方法重写的应用场景之一就是:子类重写Object的toString()方法,以便返回对象的内容。
比如:有一个Student类,这个类会默认继承Object类。
比如:有一个Student类,这个类会默认继承Object类。
public class Student extends Object{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
其实Object类中有一个toString()方法,直接通过Student对象调用Object的toString()方法,会得到对象的地址值。
public class Test {
public static void main(String[] args) {
Student s = new Student("播妞", 19);
// System.out.println(s.toString());
System.out.println(s);
}
}
但是,此时不想调用父类Object的toString()方法,那就可以在Student类中重新写一个toSting()方法,用于返回对象的属性值。
package com.itheima.d12_extends_override;
public class Student extends Object{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
重新运行测试类,结果如下
Student{name=播妞,age=19}
子类中访问成员的特点
继承至少涉及到两个类,而每一个类中都可能有各自的成员(成员变量、成员方法),就有可能出现子类和父类有相同成员的情况,那么在子类中访问其他成员有什么特点呢?
- 原则:在子类中访问其他成员(成员变量、成员方法),是依据就近原则的
定义一个父类,代码如下
public class F {
String name = "父类名字";
public void print1(){
System.out.println("==父类的print1方法执行==");
}
}
再定义一个子类,代码如下。有一个同名的name成员变量,有一个同名的print1成员方法;
public class Z extends F {
String name = "子类名称";
public void showName(){
String name = "局部名称";
System.out.println(name); // 局部名称
}
@Override
public void print1(){
System.out.println("==子类的print1方法执行了=");
}
public void showMethod(){
print1(); // 子类的
}
}
接下来写一个测试类,观察运行结果,我们发现都是调用的子类变量、子类方法。
public class Test {
public static void main(String[] args) {
// 目标:掌握子类中访问其他成员的特点:就近原则。
Z z = new Z();
z.showName();
z.showMethod();
}
}
- 如果子类和父类出现同名变量或者方法,优先使用子类的;此时如果一定要在子类中使用父类的成员,可以加this或者super进行区分。
public class Z extends F {
String name = "子类名称";
public void showName(){
String name = "局部名称";
System.out.println(name); // 局部名称
System.out.println(this.name); // 子类成员变量
System.out.println(super.name); // 父类的成员变量
}
@Override
public void print1(){
System.out.println("==子类的print1方法执行了=");
}
public void showMethod(){
print1(); // 子类的
super.print1(); // 父类的
}
}
子类中访问构造器的特点
可变长参数
可变长参数:允许在调用方法时传入不定长度的参数
可变参数只能作为函数的最后一个参数,但其前面可以有也可以没有任何其他参数,Java 的可变参数编译后实际会被转换成一个数组。
面向对象基础
对象
所谓编写对象编程,就是把要处理的数据交给对象,让对象来处理。**
Java的祖师爷,詹姆斯高斯林认为,在这个世界中 万物皆对象!任何一个对象都可以包含一些数据,数据属于哪个对象,就由哪个对象来处理。
对象实质上是一种特殊的数据结构,对象其实就是一张数据表,表当中记录什么数据,对象就处理什么数据。
而数据表中可以有哪些数据,是由类来设计的。
对象在计算机中的执行原理
Student s1 = new Student();这句话中的原理如下
-
Student s1表示的是在栈内存中,创建了一个Student类型的变量,变量名为s1 -
而
new Student()会在堆内存中创建一个对象,而对象中包含学生的属性名和属性值同时系统会为这个Student对象分配一个地址值0x4f3f5b24
-
接着把对象的地址赋值给栈内存中的变量s1,通过s1记录的地址就可以找到这个对象
-
当执行
s1.name=“播妞”时,其实就是通过s1找到对象的地址,再通过对象找到对象的name属性,再给对象的name属性赋值为播妞;
面向对象编程好处
面向对象的开发更符合人类的思维习惯,让编程变得更加简单、更加直观。
类和对象的注意事项
第一条:一个代码文件中,可以写多个class类,但是只能有一个是public修饰,且public修饰的类必须和文件名相同。
//public修饰的类Demo1,和文件名Demo1相同
public class Demo1{
}
class Student{
}
第二条:对象与对象之间的数据不会相互影响,但是多个变量指向同一个对象会相互影响。
s1和s2两个变量分别记录的是两个对象的地址值,各自修改各自属性值,是互不影响的。
静态
static读作静态,可以用来修饰成员变量,也能修饰成员方法。
static修饰成员变量
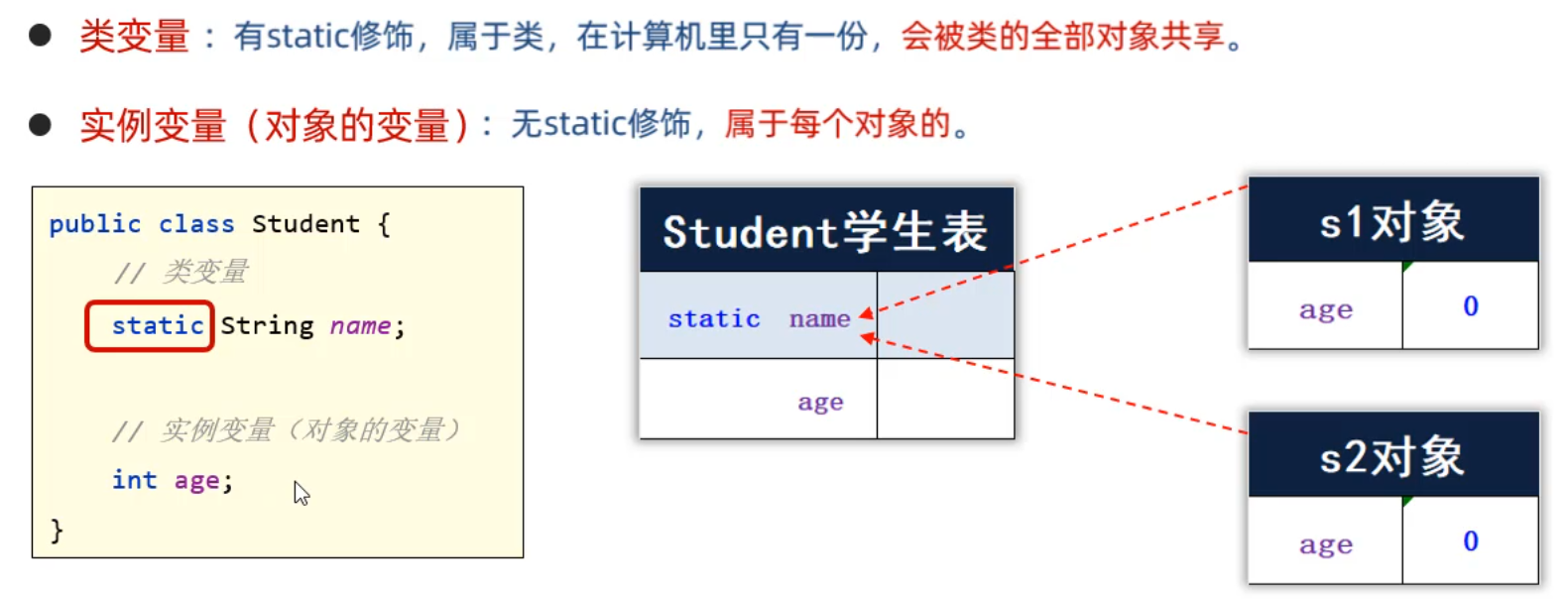
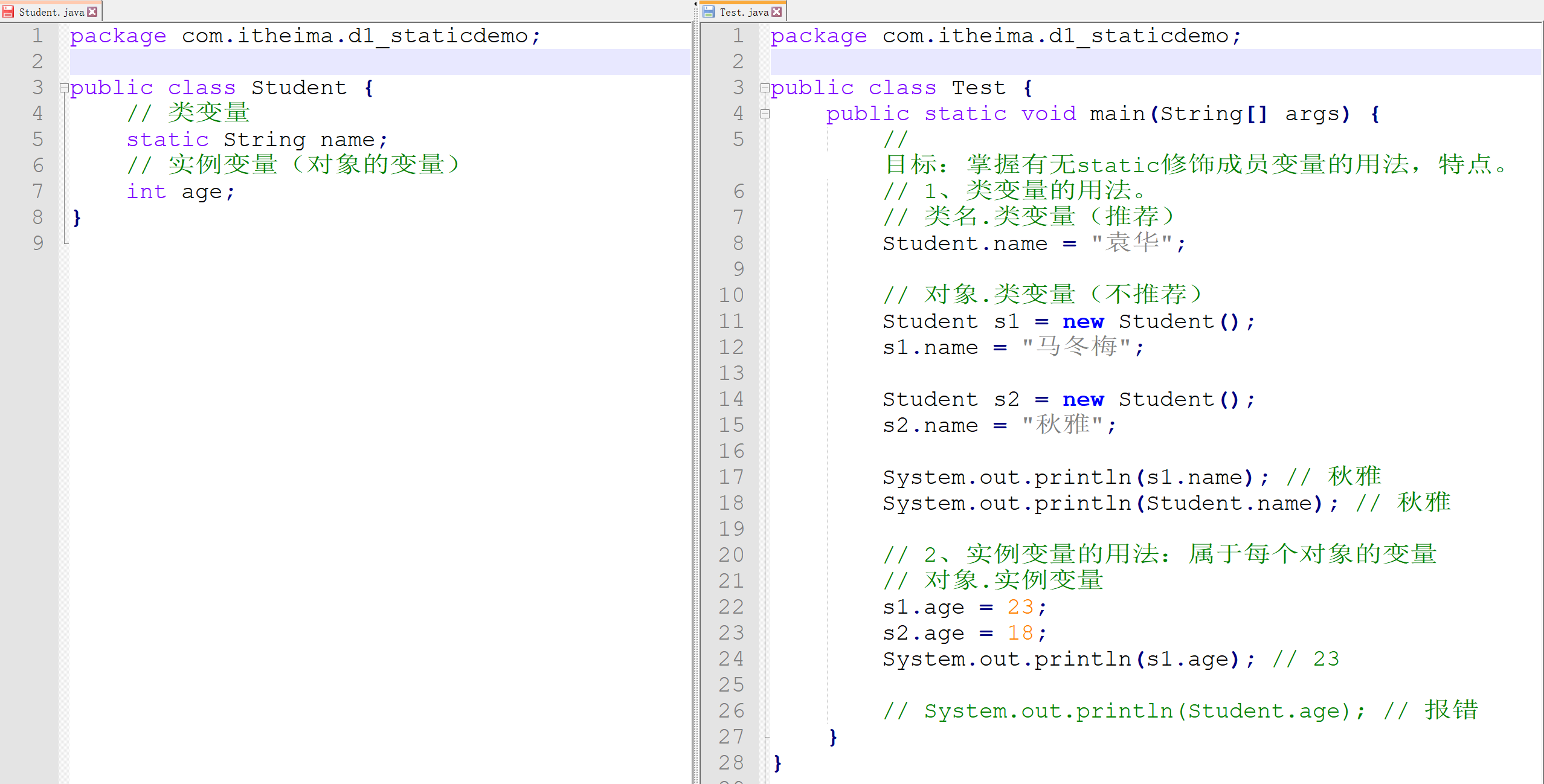
Java中的成员变量按照有无static修饰分为两种:类变量、实例变量。
- 类变量:有static修饰,属于类,在内存中只有一份,会被类的全部对象共享。
类名.类变量(推荐)类直接访问
对象.类变量(不推荐)也可以被类的对象访问
- 实例变量:属于对象,每一个对象都有一份,用对象调用
对象.类变量
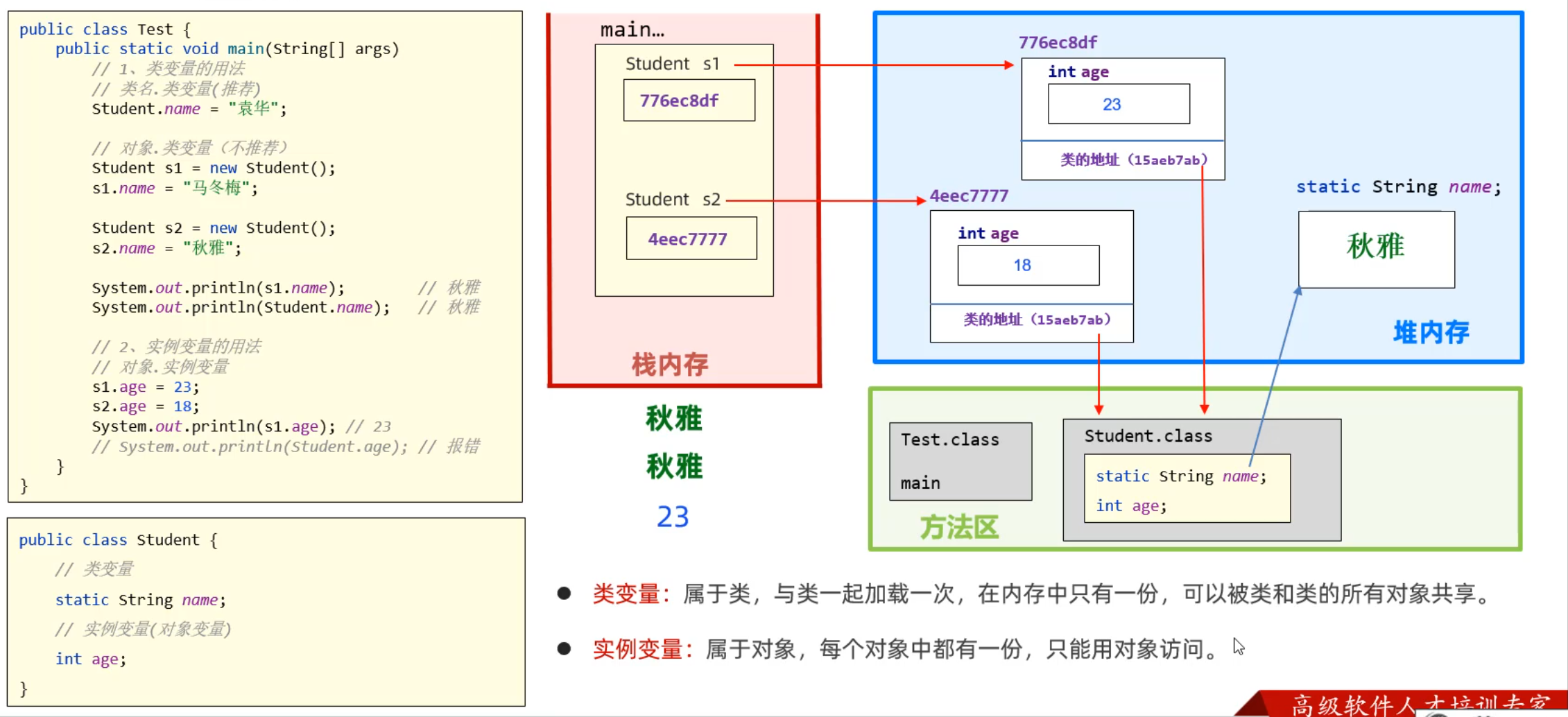
static修饰成员变量的应用场景
在实际开发中,如果某个数据只需要一份,且希望能够被共享(访问、修改),则该数据可以定义成类变量来记住。
需求:系统启动后,要求用于类可以记住自己创建了多少个用户对象。**
- 第一步:先定义一个
User类,在用户类中定义一个static修饰的变量,用来表示在线人数;
public class User{
public static int number;
//每次创建对象时,number自增一下
public User(){
User.number++;
}
}
- 第二步:再写一个测试类,再测试类中创建4个User对象,再打印number的值,观察number的值是否再自增。
public class Test{
public static void main(String[] args){
//创建4个对象
new User();
new User();
new User();
new User();
//查看系统创建了多少个User对象
System.out.println("系统创建的User对象个数:"+User.number);
}
}
运行上面的代码,查看执行结果是:系统创建的User对象个数:4
static修饰成员方法
成员方法根据有无static也分为两类:类方法、实例方法
有static修饰的方法,是属于类的,称为类方法;调用时直接用类名调用即可。
无static修饰的方法,是属于对象的,称为实例方法;调用时,需要使用对象调用。

我们看一个案例,演示类方法、实例方法的基本使用
- 先定义一个Student类,在类中定义一个类方法、定义一个实例方法
public class Student{
double score;
//类方法:
public static void printHelloWorld{
System.out.println("Hello World!");
System.out.println("Hello World!");
}
//实例方法(对象的方法)
public void printPass(){
//打印成绩是否合格
System.out.println(score>=60?"成绩合格":"成绩不合格");
}
}
- 在定义一个测试类,注意类方法、对象方法调用的区别
public class Test2{
public static void main(String[] args){
//1.调用Student类中的类方法
Student.printHelloWorld();
//2.调用Student类中的实例方法
Student s = new Student();
s.printPass();
//使用对象也能调用类方法【不推荐,IDEA连提示都不给你,你就别这么用了】
s.printHelloWorld();
}
}
搞清楚类方法和实例方法如何调用之后,接下来再啰嗦几句,和同学们聊一聊static修饰成员方法的内存原理。
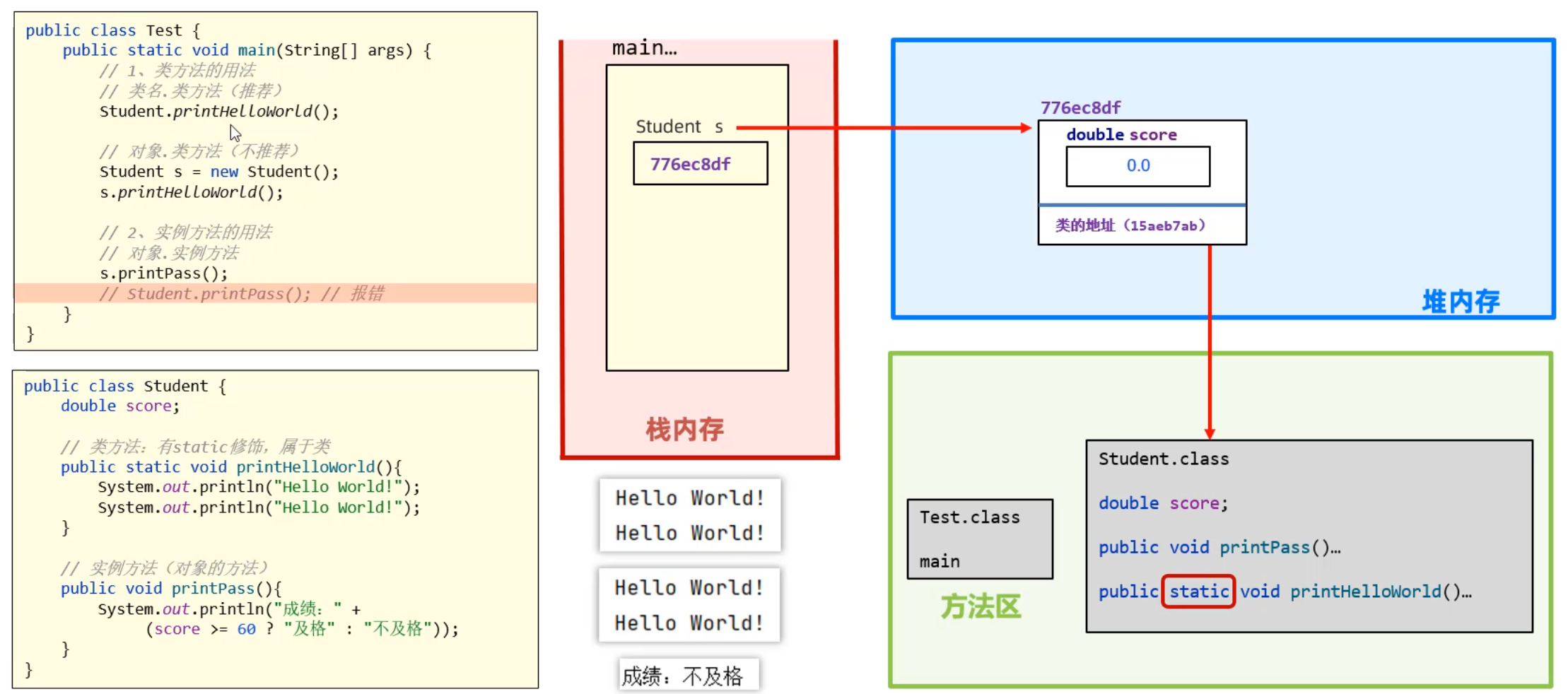
工具类
如果一个类中的方法全都是静态的,那么这个类中的方法就全都可以被类名直接调用,由于调用起来非常方便,就像一个工具一下,所以把这样的类就叫做工具类。
在补充一点,工具类里的方法全都是静态的,推荐用类名调用为了防止使用者用对象调用。我们可以把工具类的构造方法私有化。
static的注意事项
// 1、类方法中可以直接访问类的成员,不可以直接访问实例成员。
因为实例成员是属于对象的,肯定要用对象去访问的。
// 2、实例方法中既可以直接访问类成员,也可以直接访问实例成员。
// 3、实例方法中可以出现this关键字,类方法中不可以出现this关键字的
类方法是可以是用类名调用的,而this是要拿到当前对象的,所以没有对象调用类方法,所以this拿不到对象。
public class Student {
static String schoolName; // 类变量
double score; // 实例变量
// 1、类方法中可以直接访问类的成员,不可以直接访问实例成员。
public static void printHelloWorld(){
// 注意:同一个类中,访问类成员,可以省略类名不写。
// Student.schoolName = "黑马";
// Student.printHelloWorld2();
schoolName = "黑马";
printHelloWorld2();
System.out.println(score); // 报错的
printPass(); // 报错的
System.out.println(this); // 报错的
}
// 类方法
public static void printHelloWorld2(){
}
// 实例方法
public void printPass2(){
}
// 实例方法
// 2、实例方法中既可以直接访问类成员,也可以直接访问实例成员。
// 3、实例方法中可以出现this关键字,类方法中不可以出现this关键字的
public void printPass(){
schoolName = "黑马2"; //对的
printHelloWorld2(); //对的
System.out.println(score); //对的
printPass2(); //对的
System.out.println(this); //对的
}
}
static应用(代码块)
代码块根据有无static修饰分为两种:静态代码块、实例代码块


This关键字
this就是一个变量,用在方法中,可以拿到当前类的对象。
哪一个对象调用方法 方法中的this就是哪一个对象
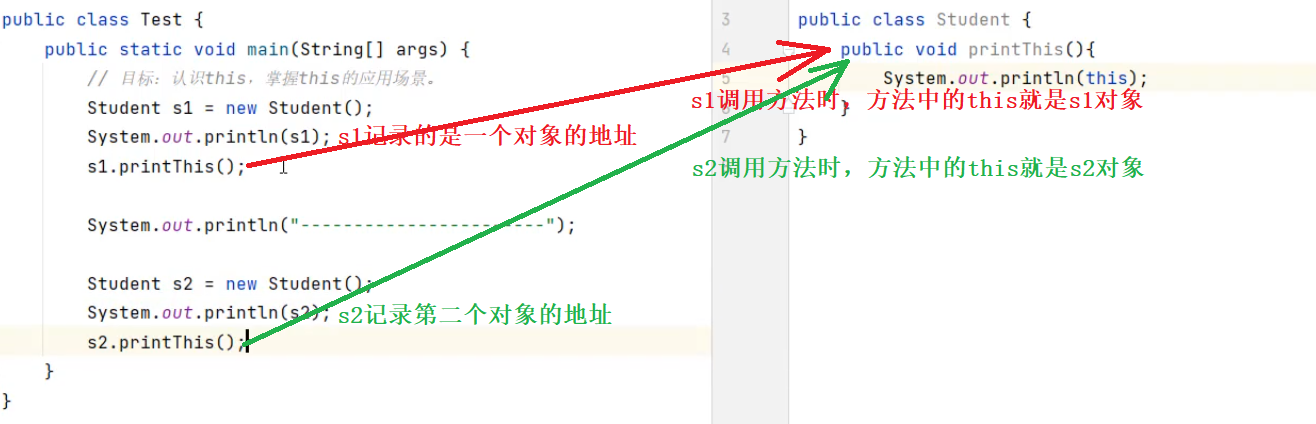
上面代码运行结果如下

this有什么用呢?
通过this在方法中可以访问本类对象的成员变量
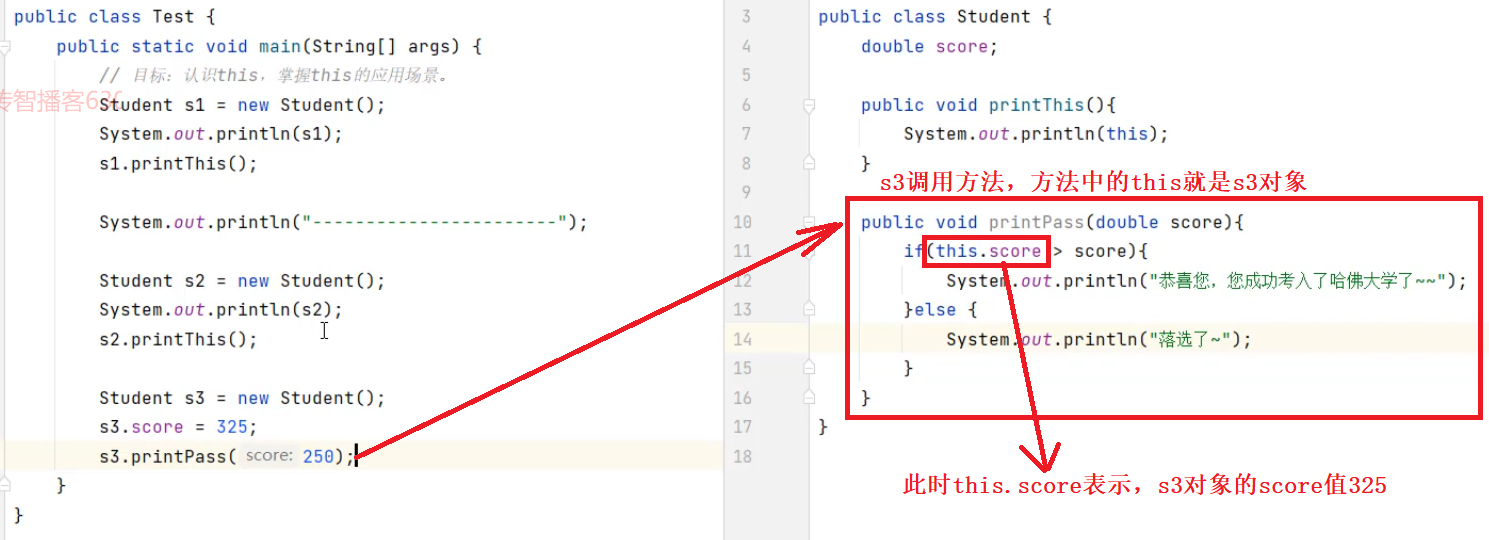
分析上面的代码s3.score=325,调用方法printPass方法时,方法中的this.score也是325; 而方法中的参数score接收的是250。执行结果是

Final关键字
- final修饰类:该类称为最终类,特点是不能被继承
- final修饰方法:该方法称之为最终方法,特点是不能被重写。
- final修饰变量:该变量只能被赋值一次。
常量
- 被 static final 修饰的成员变量,称之为常量。
- 通常用于记录系统的配置信息
构造器
构造器其实是一种特殊的方法,但是这个方法没有返回值类型,方法名必须和类名相同。
构造器的特点
在创建对象时,会调用构造器。
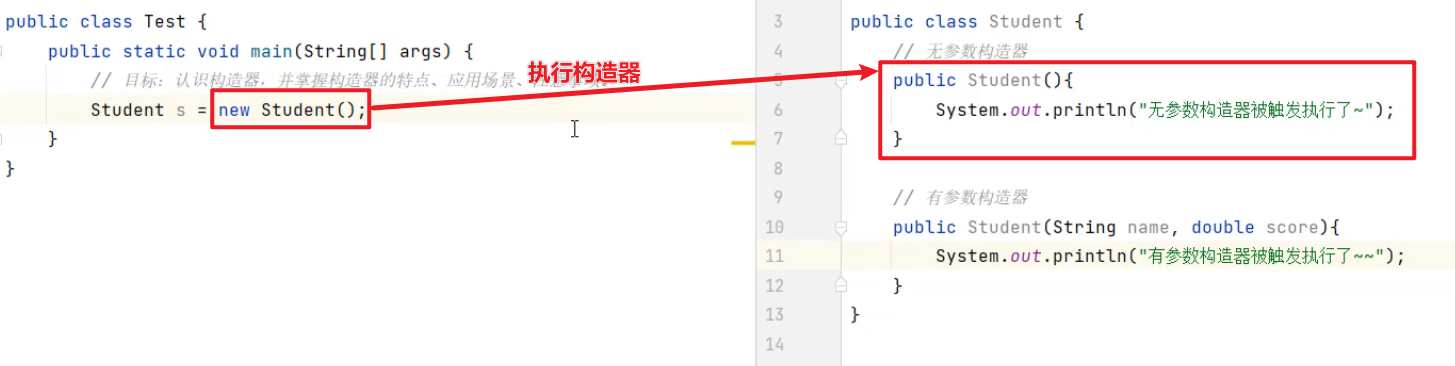
也就是说 new Student()就是在执行构造器,当构造器执行完了,也就意味着对象创建成功。
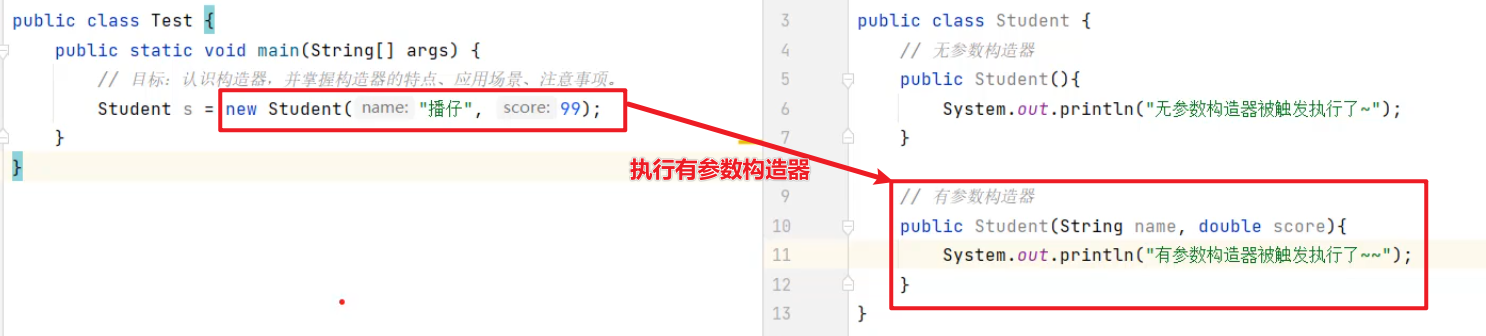
当执行new Student("播仔",99)创建对象时,就是在执行有参数构造器,当有参数构造器执行完,就意味着对象创建完毕了。
new 对象就是在执行构造方法。
构造器注意事项
1.在设计一个类时,如果不写构造器,Java会自动生成一个无参数构造器。
2.一定定义了有参数构造器,Java就不再提供空参数构造器,此时建议自己加一个无参数构造器。
JavaBean
实体类:
- 类中的成员变量都是私有的,并且对外提供相应的getXXX,setXXX方法
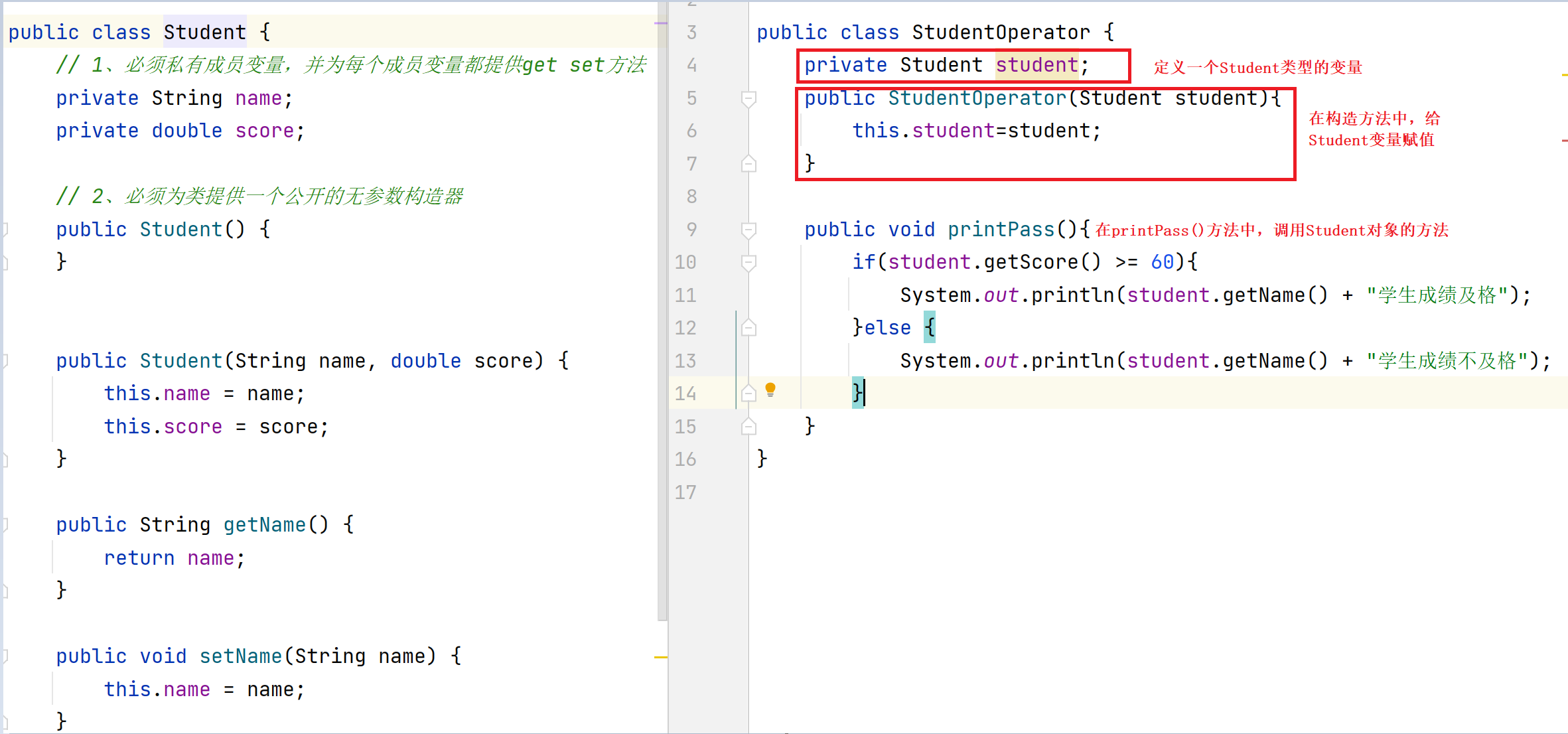
- 类中必须有一个公共的无参的构造器。
被private修饰的变量或者方法,只能在本类中被访问。
实体类中除了有给对象存、取值的方法就没有提供其他方法了。所以实体类仅仅只是用来封装数据用的。
在实际开发中,实体类仅仅只用来封装数据,而对数据的处理交给其他类来完成,以实现数据和数据业务处理相分离。
1. 想要展示系统中全部的电影信息(每部电影:编号、名称、价格)
2. 允许用户根据电影的编号(id),查询出某个电影的详细信息。
为了去描述每一部电影,可以设计一个电影类(Movie),电影类仅仅只是为了封装电影的信息,所以按照JavaBean类的标准写法来写就行。
public class Movie {
// 必须私有成员变量,并为每个成员变量提供get set方法
private int id;
private String name;
private double price;
private double score;
private String director;
private String actor;
private String info;
//必须为类提供一个公开的无参数构造类
public Movie() {
}
public Movie(int id, String name, double price, double score, String director, String actor, String info) {
this.id = id;
this.name = name;
this.price = price;
this.score = score;
this.director = director;
this.actor = actor;
this.info = info;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public String getDirector() {
return director;
}
public void setDirector(String director) {
this.director = director;
}
public String getActor() {
return actor;
}
public void setActor(String actor) {
this.actor = actor;
}
public String getInfo() {
return info;
}
public void setInfo(String info) {
this.info = info;
}
}
前面我们定义的Movie类,仅仅只是用来封装每一部电影的信息。为了让电影数据和电影数据的操作相分离,我们还得有一个电影操作类(MovieOperator)。因为系统中有多部电影,所以电影操作类中MovieOperator,需要有一个Movie[] movies; 用来存储多部电影对象;
同时在MovieOperator类中,提供对外提供,对电影数组进行操作的方法。
注意: new是操作类名的,建立新的 Movie 对象
public class MovieOperator {
//因为系统中有多部电影,所以电影操作类中,需要有一个Movie的数组
private Movie[] movies; // 定义一个Movie数组类型的变量
//在构造方法中,给Movie[]变量赋值
public MovieOperator(Movie[] movies){
this.movies = movies;
}
/** 1、展示系统全部电影信息 movies = [m1, m2, m3, ...]*/
public void printAllMovies(){
System.out.println("-----系统全部电影信息如下:-------");
for (int i = 0; i < movies.length; i++) {
// 数组中第 i 个元素的地址引用赋值给变量 m。m 和 movies[i] 都指向同一个 Movie 对象。
// 即获取一个已存在的 Movie 对象的引用
Movie m = movies[i];
System.out.println("编号:" + m.getId());
System.out.println("名称:" + m.getName());
System.out.println("价格:" + m.getPrice());
System.out.println("------------------------");
}
}
/** 2、根据电影的编号查询出该电影的详细信息并展示 */
public void searchMovieById(int id){
for (int i = 0; i < movies.length; i++) {
Movie m = movies[i];
if(m.getId() == id){
System.out.println("该电影详情如下:");
System.out.println("编号:" + m.getId());
System.out.println("名称:" + m.getName());
System.out.println("价格:" + m.getPrice());
System.out.println("得分:" + m.getScore());
System.out.println("导演:" + m.getDirector());
System.out.println("主演:" + m.getActor());
System.out.println("其他信息:" + m.getInfo());
return; // 已经找到了电影信息,没有必要再执行了
}
}
System.out.println("没有该电影信息~");
}
}
最后,我们需要在测试类中,准备好所有的电影数据,并用一个数组保存起来。每一部电影的数据可以封装成一个对象。然后把对象用数组存起来即可。
public class Test {
public static void main(String[] args) {
//创建一个Movie类型的数组,数组的动态初始化
Movie[] movies = new Movie[4];
//创建4个电影对象,分别存储到movies数组中
movies[0] = new Movie(1,"水门桥", 38.9, 9.8, "徐克", "吴京","12万人想看");
movies[1] = new Movie(2, "出拳吧", 39, 7.8, "唐晓白", "田雨","3.5万人想看");
movies[2] = new Movie(3,"月球陨落", 42, 7.9, "罗兰", "贝瑞","17.9万人想看");
movies[3] = new Movie(4,"一点就到家", 35, 8.7, "许宏宇", "刘昊然","10.8万人想看");
// 4、创建一个电影操作类的对象,接收电影数据,并对其进行业务处理
MovieOperator operator = new MovieOperator(movies);
Scanner sc = new Scanner(System.in);
while (true) {
System.out.println("==电影信息系统==");
System.out.println("1、查询全部电影信息");
System.out.println("2、根据id查询某个电影的详细信息展示");
System.out.println("请您输入操作命令:");
int command = sc.nextInt();
switch (command) {
case 1:
// 展示全部电影信息
operator.printAllMovies();
break;
case 2:
// 根据id查询某个电影的详细信息展示
System.out.println("请您输入查询的电影id:");
int id = sc.nextInt();
operator.searchMovieById(id);
break;
default:
System.out.println("您输入的命令有问题~~");
}
}
}
}
抽象类
在Java中有一个关键字叫abstract,它就是抽象的意思,它可以修饰类也可以修饰方法。
// 抽象类
public abstract class A {
//成员变量
private String name;
static String schoolName;
//构造方法
public A(){
}
//抽象方法
public abstract void test();
//实例方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
- 抽象类虽然不能创建对象,但是它可以作为父类让子类继承。而且子类继承父类必须重写父类的所有抽象方法。
//B类继承A类,必须复写test方法
public class B extends A {
@Override
public void test() {
}
}
- 子类继承父类如果不复写父类的抽象方法,要想不出错,这个子类也必须是抽象类
//B类基础A类,此时B类也是抽象类,这个时候就可以不重写A类的抽象方法
public abstract class B extends A {
}
抽象类的好处

分析需求发现,该案例中猫和狗都有名字这个属性,也都有叫这个行为,所以我们可以将共性的内容抽取成一个父类,Animal类,但是由于猫和狗叫的声音不一样,于是我们在Animal类中将叫的行为写成抽象的。代码如下
public abstract class Animal {
private String name;
//动物叫的行为:不具体,是抽象的
public abstract void cry();
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
接着写一个Animal的子类,Dog类。代码如下
public class Dog extends Animal{
@Override
public void cry(){
System.out.println(getName() + "汪汪汪的叫~~");
}
}
然后,再写一个Animal的子类,Cat类。代码如下
public class Cat extends Animal{
@Override
public void cry(){
System.out.println(getName() + "喵喵喵的叫~~");
}
}
最后,再写一个测试类,Test类。
public class Test2 {
public static void main(String[] args) {
// 目标:掌握抽象类的使用场景和好处.
Animal a = new Dog();
a.cry(); //这时执行的是Dog类的cry方法
}
}
再学一招,假设现在系统有需要加一个Pig类,也有叫的行为,这时候也很容易原有功能扩展。只需要让Pig类继承Animal,复写cry方法就行。
public class Pig extends Animal{
@Override
public void cry() {
System.out.println(getName() + "嚯嚯嚯~~~");
}
}
此时,创建对象时,让Animal接收Pig,就可以执行Pig的cry方法
public class Test2 {
public static void main(String[] args) {
// 目标:掌握抽象类的使用场景和好处.
Animal a = new Pig();
a.cry(); //这时执行的是Pig类的cry方法
}
}
综上所述,我们总结一下抽象类的使用场景和好处
1.用抽象类可以把父类中相同的代码,包括方法声明都抽取到父类,这样能更好的支持多态,一提高代码的灵活性。
2.反过来用,我们不知道系统未来具体的业务实现时,我们可以先定义抽象类,将来让子类去实现,以方便系统的扩展。
模板方法模式
模板方法模式主要解决方法中存在重复代码的问题
比如A类和B类都有sing()方法,sing()方法的开头和结尾都是一样的,只是中间一段内容不一样。此时A类和B类的sing()方法中就存在一些相同的代码。
怎么解决上面的重复代码问题呢? 我们可以写一个抽象类C类,在C类中写一个doSing()的抽象方法。再写一个sing()方法,代码如下:
// 模板方法设计模式
public abstract class C {
// 模板方法
public final void sing(){
System.out.println("唱一首你喜欢的歌:");
doSing();
System.out.println("唱完了!");
}
public abstract void doSing();
}
然后,写一个A类继承C类,复写doSing()方法,代码如下
public class A extends C{
@Override
public void doSing() {
System.out.println("我是一只小小小小鸟,想要飞就能飞的高~~~");
}
}
接着,再写一个B类继承C类,也复写doSing()方法,代码如下
public class B extends C{
@Override
public void doSing() {
System.out.println("我们一起学猫叫,喵喵喵喵喵喵喵~~");
}
}
最后,再写一个测试类Test
public class Test {
public static void main(String[] args) {
// 目标:搞清楚模板方法设计模式能解决什么问题,以及怎么写。
B b = new B();
b.sing();
}
}
综上所述:模板方法模式解决了多个子类中有相同代码的问题。具体实现步骤如下
第1步:定义一个抽象类,把子类中相同的代码写成一个模板方法。
第2步:把模板方法中不能确定的代码写成抽象方法,并在模板方法中调用。
第3步:子类继承抽象类,只需要父类抽象方法就可以了。
接口
一个比抽象类抽象得更加彻底的一种特殊结构,叫做接口。
Java提供了一个关键字interface,用这个关键字来定义接口这种特殊结构。格式如下
public interface 接口名{
//成员变量(常量)
//成员方法(抽象方法)
}
在接口中成员变量默认是常量,成员方法默认是抽象方法
按照接口的格式,我们定义一个接口看看
public interface A{
//这里public static final可以加,可以不加。
public static final String SCHOOL_NAME = "黑马程序员";
//这里的public abstract可以加,可以不加。
public abstract void test();
}
写好A接口之后,在写一个测试类,用一下
public class Test{
public static void main(String[] args){
//打印A接口中的常量
System.out.println(A.SCHOOL_NAME);
//接口是不能创建对象的
A a = new A();
}
}
我们发现定义好接口之后,是不能创建对象的。那接口到底什么使用呢?需要我注意下面两点
- 接口是用来被类实现(implements)的,我们称之为实现类。
- 一个类是可以实现多个接口的(接口可以理解成干爹),类实现接口必须重写所有接口的全部抽象方法,否则这个类也必须是抽象类
比如,再定义一个B接口,里面有两个方法testb1(),testb2()
public interface B {
void testb1();
void testb2();
}
接着,再定义一个C接口,里面有两个方法testc1(), testc2()
public interface C {
void testc1();
void testc2();
}
然后,再写一个实现类D,同时实现B接口和C接口,此时就需要复写四个方法,如下代码
// 实现类
public class D implements B, C{
@Override
public void testb1() {
}
@Override
public void testb2() {
}
@Override
public void testc1() {
}
@Override
public void testc2() {
}
}
最后,定义一个测试类Test
public class Test {
public static void main(String[] args) {
// 目标:认识接口。
System.out.println(A.SCHOOL_NAME);
// A a = new A();
D d = new D();
}
}
接口好处
- 弥补了类单继承的不足,一个类同时可以实现多个接口。
- 让程序可以面向接口编程,这样程序员可以灵活方便的切换各种业务实现。
现在要写一个A类,想让他既是学生,偶然也是司机能够开车,偶尔也是歌手能够唱歌。那我们代码就可以这样设计,如下:
class Student{
}
interface Driver{
void drive();
}
interface Singer{
void sing();
}
//A类是Student的子类,同时也实现了Dirver接口和Singer接口
class A extends Student implements Driver, Singer{
@Override
public void drive() {
}
@Override
public void sing() {
}
}
public class Test {
public static void main(String[] args) {
//想唱歌的时候,A类对象就表现为Singer类型
Singer s = new A();
s.sing();
//想开车的时候,A类对象就表现为Driver类型
Driver d = new A();
d.drive();
}
}
综上所述:接口弥补了单继承的不足,同时可以轻松实现在多种业务场景之间的切换。
接口案列

首先我们写一个学生类,用来描述学生的相关信息
右键Generate,然后constructor或Getter and Setter
public class Student {
private String name;
private char sex;
private double score;
public Student() {
}
public Student(String name, char sex, double score) {
this.name = name;
this.sex = sex;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
}
接着,写一个StudentOperator接口,表示学生信息管理系统的两个功能。
public interface StudentOperator {
void printAllInfo(ArrayList<Student> students);
void printAverageScore(ArrayList<Student> students);
}
然后,写一个StudentOperator接口的实现类StudentOperatorImpl1,采用第1套方案对业务进行实现。
public class StudentOperatorImpl1 implements StudentOperator{
@Override
public void printAllInfo(ArrayList<Student> students) {
System.out.println("----------全班全部学生信息如下--------------");
//students.for i
for (int i = 0; i < students.size(); i++) {
Student s = students.get(i);
System.out.println("姓名:" + s.getName() + ", 性别:" + s.getSex() + ", 成绩:" + s.getScore());
}
System.out.println("-----------------------------------------");
}
@Override
public void printAverageScore(ArrayList<Student> students) {
double allScore = 0.0;
for (int i = 0; i < students.size(); i++) {
Student s = students.get(i);
allScore += s.getScore();
}
System.out.println("平均分:" + (allScore) / students.size());
}
}
接着,再写一个StudentOperator接口的实现类StudentOperatorImpl2,采用第2套方案对业务进行实现。
public class StudentOperatorImpl2 implements StudentOperator{
@Override
public void printAllInfo(ArrayList<Student> students) {
System.out.println("----------全班全部学生信息如下--------------");
int count1 = 0;
int count2 = 0;
for (int i = 0; i < students.size(); i++) {
Student s = students.get(i);
System.out.println("姓名:" + s.getName() + ", 性别:" + s.getSex() + ", 成绩:" + s.getScore());
if(s.getSex() == '男'){
count1++;
}else {
count2 ++;
}
}
System.out.println("男生人数是:" + count1 + ", 女士人数是:" + count2);
System.out.println("班级总人数是:" + students.size());
System.out.println("-----------------------------------------");
}
@Override
public void printAverageScore(ArrayList<Student> students) {
double allScore = 0.0;
double max = students.get(0).getScore();
double min = students.get(0).getScore();
for (int i = 0; i < students.size(); i++) {
Student s = students.get(i);
if(s.getScore() > max) max = s.getScore();
if(s.getScore() < min) min = s.getScore();
allScore += s.getScore();
}
System.out.println("学生的最高分是:" + max);
System.out.println("学生的最低分是:" + min);
System.out.println("平均分:" + (allScore - max - min) / (students.size() - 2));
}
}
再写一个班级管理类ClassManager,在班级管理类中使用StudentOperator的实现类StudentOperatorImpl1对学生进行操作
班级里面许多学生,ArrayList集合。
public class ClassManager {
private ArrayList<Student> students = new ArrayList<>();
private StudentOperator studentOperator = new StudentOperatorImpl1();
public ClassManager
//Student s1 = new Student("迪丽热巴", '女', 99);
//students.add(s1);可简化下面的语句
students.add(new Student("迪丽热巴", '女', 99));
students.add(new Student("古力娜扎", '女', 100));
students.add(new Student("马尔扎哈", '男', 80));
students.add(new Student("卡尔扎巴", '男', 60));
}
// 打印全班全部学生的信息
public void printInfo(){
studentOperator.printAllInfo(students);
}
// 打印全班全部学生的平均分
public void printScore(){
studentOperator.printAverageScore(students);
}
}
最后,再写一个测试类Test,在测试类中使用ClassMananger完成班级学生信息的管理。
public class Test {
public static void main(String[] args) {
// 目标:完成班级学生信息管理的案例。
ClassManager clazz = new ClassManager();
clazz.printInfo();
clazz.printScore();
}
}
注意:如果想切换班级管理系统的业务功能,随时可以将StudentOperatorImpl1切换为StudentOperatorImpl2。自己试试
接口JDK8的新特性
随着JDK版本的升级,在JDK8版本以后接口中能够定义的成员也做了一些更新,从JDK8开始,接口中新增的三种方法形式。
我们看一下这三种方法分别有什么特点?
public interface A {
/**
* 1、默认方法:必须使用default修饰,默认会被public修饰
* 实例方法:对象的方法,必须使用实现类的对象来访问。
*/
default void test1(){
System.out.println("===默认方法==");
test2();
}
/**
* 2、私有方法:必须使用private修饰。(JDK 9开始才支持的)
* 实例方法:对象的方法。
*/
private void test2(){
System.out.println("===私有方法==");
}
/**
* 3、静态方法:必须使用static修饰,默认会被public修饰
*/
static void test3(){
System.out.println("==静态方法==");
}
void test4();
void test5();
default void test6(){
}
}
接下来我们写一个B类,实现A接口。B类作为A接口的实现类,只需要重写抽象方法就尅了,对于默认方法不需要子类重写。代码如下:
public class B implements A{
@Override
public void test4() {
}
@Override
public void test5() {
}
}
最后,写一个测试类,观察接口中的三种方法,是如何调用的
public class Test {
public static void main(String[] args) {
// 目标:掌握接口新增的三种方法形式
B b = new B();
b.test1(); //默认方法使用对象调用
// b.test2(); //A接口中的私有方法,B类调用不了
A.test3(); //静态方法,使用接口名调用
}
}
综上所述:JDK8对接口新增的特性,有利于对程序进行扩展。
接口的其他细节
- 一个接口可以继承多个接口
public class Test {
public static void main(String[] args) {
// 目标:理解接口的多继承。
}
}
interface A{
void test1();
}
interface B{
void test2();
}
interface C{}
//比如:D接口继承C、B、A
interface D extends C, B, A{
}
//E类在实现D接口时,必须重写D接口、以及其父类中的所有抽象方法。
class E implements D{
@Override
public void test1() {
}
@Override
public void test2() {
}
}
接口除了上面的多继承特点之外,在多实现、继承和实现并存时,有可能出现方法名冲突的问题,需要了解怎么解决(仅仅只是了解一下,实际上工作中几乎不会出现这种情况)
1.一个接口继承多个接口,如果多个接口中存在相同的方法声明,则此时不支持多继承
2.一个类实现多个接口,如果多个接口中存在相同的方法声明,则此时不支持多实现
3.一个类继承了父类,又同时实现了接口,父类中和接口中有同名的默认方法,实现类会有限使用父类的方法
4.一个类实现类多个接口,多个接口中有同名的默认方法,则这个类必须重写该方法。
综上所述:一个接口可以继承多个接口,接口同时也可以被类实现。
泛型:
定义类、接口、方法时,同时声明了一个或者多个类型变量(如:
public class ArrayList<E>{
...
}
ArrayList<String> list1 = new ArrayList<>();
-
泛型的好处:在编译阶段可以避免出现一些非法的数据。
-
泛型的本质:把具体的数据类型传递给类型变量。
自定义泛类型
//这里的<T,W>其实指的就是类型变量,可以是一个,也可以是多个。
public class 类名<T,W>{
}
自己定义一个MyArrayList
//定义一个泛型类,用来表示一个容器
//容器中存储的数据,它的类型用<E>先代替用着,等调用者来确认<E>的具体类型。
public class MyArrayList<E>{
private Object[] array = new Object[10];
//定一个索引,方便对数组进行操作
private int index;
//添加元素
public void add(E e){
array[index]=e;
index++;
}
//获取元素
public E get(int index){
return (E)array[index];
}
}
接下来,我们写一个测试类,来测试自定义的泛型类MyArrayList是否能够正常使用
public class Test{
public static void main(String[] args){
//1.确定MyArrayList集合中,元素类型为String类型
MyArrayList<String> list = new MyArrayList<>();
//此时添加元素时,只能添加String类型
list.add("张三");
list.add("李四");
//2.确定MyArrayList集合中,元素类型为Integer类型
MyArrayList<Integer> list1 = new MyArrayList<>();
//此时添加元素时,只能添加String类型
list.add(100);
list.add(200);
}
}
自定义泛型接口
泛型接口其实指的是在接口中把不确定的数据类型用<类型变量>表示。定义格式如下:
//这里的类型变量,一般是一个字母,比如<E>
public interface 接口名<类型变量>{
}
比如,我们现在要做一个系统要处理学生和老师的数据,需要提供2个功能,保存对象数据、根据名称查询数据,要求:这两个功能处理的数据既能是老师对象,也能是学生对象。
首先我们得有一个学生类和老师类
public class Teacher{
}
public class Student{
}
我们定义一个Data<T>泛型接口,T表示接口中要处理数据的类型。
public interface Data<T>{
public void add(T t);
public ArrayList<T> getByName(String name);
}
接下来,我们写一个处理Teacher对象的接口实现类
//此时确定Data<E>中的E为Teacher类型,
//接口中add和getByName方法上的T也都会变成Teacher类型
public class TeacherData implements Data<Teacher>{
public void add(Teacher t){
}
public ArrayList<Teacher> getByName(String name){
}
}
接下来,我们写一个处理Student对象的接口实现类
//此时确定Data<E>中的E为Student类型,
//接口中add和getByName方法上的T也都会变成Student类型
public class StudentData implements Data<Student>{
public void add(Student t){
}
public ArrayList<Student> getByName(String name){
}
}
再啰嗦几句,在实际工作中,一般也都是框架底层源代码把泛型接口写好,我们实现泛型接口就可以了。
泛型方法
下面就是泛型方法的格式
public <泛型变量,泛型变量> 返回值类型 方法名(形参列表){
}
下图中在返回值类型和修饰符之间有

接下我们看一个泛型方法的案例
public class Test{
public static void main(String[] args){
//调用test方法,传递字符串数据,那么test方法的泛型就是String类型
String rs = test("test");
//调用test方法,传递Dog对象,那么test方法的泛型就是Dog类型
Dog d = test(new Dog());
}
//这是一个泛型方法<T>表示一个不确定的数据类型,由调用者确定
public static <T> test(T t){
return t;
}
}
泛型限定
泛型限定的意思是对泛型的数据类型进行范围的限制。有如下的三种格式
- 表示**任意类型**
- 表示指定类型或者指定类型的**子类**
- 表示指定类型或者指定类型的**父类**
泛型擦除
泛型只能编译阶段有效,一旦编译成字节码,字节码中是不包含泛型的。
泛型只支持引用数据类型,不支持基本数据类型。
常用API
API(Application Programming interface)意思是应用程序编程接口,说人话就是Java帮我们写好的一些程序,如:类、方法等,我们直接拿过来用就可以解决一些问题。

Object类
Object类是Java中所有类的祖宗类,因此,Java中所有类的对象都可以直接使用Object类中提供的一些方法。
toString()方法
public String toString()
调用toString()方法可以返回对象的字符串表示形式。
默认的格式是:“包名.类名@哈希值16进制”
假设有一个学生类如下
public class Student{
private String name;
private int age;
public Student(String name, int age){
this.name=name;
this.age=age;
}
}
再定义一个测试类
public class Test{
public static void main(String[] args){
Student s1 = new Student("赵敏",23);
System.out.println(s1.toString());
}
}
打印结果如下

在Student类重写toString()方法,那么我们可以返回对象的属性值,代码如下
public class Student{
private String name;
private int age;
public Student(String name, int age){
this.name=name;
this.age=age;
}
@Override
public String toString(){
return "Student{name=‘"+name+"’, age="+age+"}";
}
}
运行测试类,结果如下
equals(Object o)方法
接下来,我们学习一下Object类的equals方法
public boolean equals(Object o)
判断此对象与参数对象是否"相等"
我们写一个测试类,测试一下
public class Test{
public static void main(String[] args){
Student s1 = new Student("赵薇",23);
Student s2 = new Student("赵薇",23);
//equals本身也是比较对象的地址,和"=="没有区别
System.out.println(s1.equals(s2)); //false
//"=="比较对象的地址
System.out.println(s1==s2); //false
}
}
但是如果我们在Student类中,把equals方法重写了,就按照对象的属性值进行比较
public class Student{
private String name;
private int age;
public Student(String name, int age){
this.name=name;
this.age=age;
}
@Override
public String toString(){
return "Student{name=‘"+name+"’, age="+age+"}";
}
//重写equals方法,按照对象的属性值进行比较
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
}
再运行测试类,效果如下

clone() 方法
Object类的clone()方法,克隆。
意思就是某一个对象调用这个方法,这个方法会复制一个一模一样的新对象,并返回。
public Object clone()
克隆当前对象,返回一个新对象
想要调用clone()方法,必须让被克隆的类实现Cloneable接口。如我们准备克隆User类的对象,代码如下
public class User implements Cloneable{
private String id; //编号
private String username; //用户名
private String password; //密码
private double[] scores; //分数
public User() {
}
public User(String id, String username, String password, double[] scores) {
this.id = id;
this.username = username;
this.password = password;
this.scores = scores;
}
//...get和set...方法自己加上
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
接着,我们写一个测试类,克隆User类的对象。并观察打印的结果
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
User u1 = new User(1,"zhangsan","wo666",new double[]{99.0,99.5});
//调用方法克隆得到一个新对象
User u2 = (User) u1.clone();
System.out.println(u2.getId());
System.out.println(u2.getUsername());
System.out.println(u2.getPassword());
System.out.println(u2.getScores());
}
}
克隆得到的对象u2它的属性值和原来u1对象的属性值是一样的。


下面演示一下深拷贝User对象
public class User implements Cloneable{
private String id; //编号
private String username; //用户名
private String password; //密码
private double[] scores; //分数
public User() {
}
public User(String id, String username, String password, double[] scores) {
this.id = id;
this.username = username;
this.password = password;
this.scores = scores;
}
//...get和set...方法自己加上
@Override
protected Object clone() throws CloneNotSupportedException {
//先克隆得到一个新对象
User u = (User) super.clone();
//再将新对象中的引用类型数据,再次克隆
u.scores = u.scores.clone();
return u;
}
}

基本类型包装类
为什么要学习包装类呢?
因为在Java中有一句很经典的话,万物皆对象。Java中的8种基本数据类型还不是对象,所以要把它们变成对象,变成对象之后,可以提供一些方法对数据进行操作。
Java中的包装类型是为了解决基本数据类型不能直接使用对象特性的限制而引入的。
包装类型的引入主要是基于以下几个考虑:
- 对象特性:基本数据类型不是对象,因此无法直接调用方法或属性。包装类使得基本数据类型拥有对象的性质,例如可以调用方法来转换值或操作数据。
- 泛型支持:Java的集合框架(如
ArrayList、HashMap等)不支持基本数据类型。使用泛型时,需要使用对象类型。包装类允许将基本数据类型作为对象存储在集合中。 - 提供额外的方法和属性:包装类提供了一些有用的工具方法和属性,如最大值、最小值常量,以及类型转换、比较等静态方法。
- 空值处理:基本数据类型不能表示空值(
null),这在很多情况下是个限制。包装类允许变量为空,这在表达缺失或未初始化的数据时非常有用。 - 序列化:只有对象才能被序列化,这对于网络传输或文件存储等操作是必要的。包装类使得基本数据类型值可以被序列化。
学习包装类,主要学习两点:
-
- 创建包装类的对象方式、自动装箱和拆箱的特性;
-
- 利用包装类提供的方法对字符串和基本类型数据进行相互转换
创建包装类对象的方法,以及包装类的一个特性叫自动装箱和自动拆箱。
以Integer为例。
//1.创建Integer对象,封装基本类型数据10
Integer a = new Integer(10);// 过时方法
//2.使用Integer类的静态方法valueOf(数据)
Integer b = Integer.valueOf(10);
//3.还有一种自动装箱的写法(意思就是自动将基本类型转换为引用类型)
Integer c = 10;
//4.自动拆箱,有装箱肯定还有拆箱(意思就是自动将引用类型转换为基本类型)
int d = c;
//5.装箱和拆箱在使用集合时就有体现
// 泛型和集合不支持基本数据类型,只能支持引用数据类型。
ArrayList<Integer> list = new ArrayList<>();
//添加的元素是基本类型,实际上会自动装箱为Integer类型
list.add(100);//自动装箱
//获取元素时,会将Integer类型自动拆箱为int类型
int e = list.get(0);//自动拆箱
4.2.2 包装类数据类型转换
在开发中,经常使用包装类对字符串和基本类型数据进行相互转换。
- 把字符串转换为数值型数据:包装类.parseXxx(字符串)
public static int parseInt(String s)
把字符串转换为基本数据类型
- 将数值型数据转换为字符串:包装类.valueOf(数据);
public static String valueOf(int a)
把基本类型数据转换为
- 写一个测试类演示一下
//1.字符串转换为数值型数据
String ageStr = "29";
int age1 = Integer.parseInt(ageStr);
String scoreStr = 3.14;
double score = Double.prarseDouble(scoreStr);
//2.整数转换为字符串,以下几种方式都可以(挑中你喜欢的记一下)
Integer a = 23;
String s1 = Integer.toString(a);
String s2 = a.toString();
String s3 = a+"";
String s4 = String.valueOf(a);
StringBuilder类
- StringBuilder代表可变字符串对象,相当于是一个容器,它里面的字符串是可以改变的,就是用来操作字符串的。
- 好处:StringBuilder比String更合适做字符串的修改操作,效率更高,代码也更加简洁。
接下来我们用代码演示一下StringBuilder的用法
public class Test{
public static void main(String[] args){
StringBuilder sb = new StringBuilder("itehima");
//1.拼接内容
sb.append(12);
sb.append("黑马");
sb.append(true);
//2.append方法,支持临时编程
sb.append(666).append("黑马2").append(666);
System.out.println(sb); //打印:12黑马666黑马2666
//3.反转操作
sb.reverse();
System.out.println(sb); //打印:6662马黑666马黑21
//4.返回字符串的长度
System.out.println(sb.length());
//5.StringBuilder还可以转换为字符串
String s = sb.toString();
System.out.println(s); //打印:6662马黑666马黑21
}
}
为什么要用StringBuilder对字符串进行操作呢?因为它的效率比String更高,我们可以下面两段代码验证一下。

经过我的验证,直接使用Stirng拼接100万次,等了1分钟,还没结束,我等不下去了;但是使用StringBuilder做拼接,不到1秒钟出结果了。
接下来,我们通过一个案例把StringBuilder运用下,案例需求如下图所示
代码如下
public class Test{
public static void main(String[] args){
String str = getArrayData( new int[]{11,22,33});
System.out.println(str);
}
//方法作用:将int数组转换为指定格式的字符串
public static String getArrayData(int[] arr){
//1.判断数组是否为null
if(arr==null){
return null;
}
//2.如果数组不为null,再遍历,并拼接数组中的元素
StringBuilder sb = new StringBuilder("[");
for(int i=0; i<arr.length; i++){
if(i==arr.length-1){
sb.append(arr[i]).append("]");;
}else{
sb.append(arr[i]).append(",");
}
}
//3、把StirngBuilder转换为String,并返回。
return sb.toString();
}
}
StringJoiner类
因为我们前面使用StringBuilder拼接字符串的时,代码写起来还是有一点麻烦,而StringJoiner号称是拼接神器,不仅效率高,而且代码简洁。
下面演示一下StringJoiner的基本使用
public class Test{
public static void main(String[] args){
StringJoiner s = new StringJoiner(",");
s.add("java1");
s.add("java2");
s.add("java3");
System.out.println(s); //结果为: java1,java2,java3
//参数1:间隔符
//参数2:开头
//参数3:结尾
StringJoiner s1 = new StringJoiner(",","[","]");
s1.add("java1");
s1.add("java2");
s1.add("java3");
System.out.println(s1); //结果为: [java1,java2,java3]
}
}
使用StirngJoiner改写前面把数组转换为字符串的案例
public class Test{
public static void main(String[] args){
String str = getArrayData( new int[]{11,22,33});
System.out.println(str);
}
//方法作用:将int数组转换为指定格式的字符串
public static String getArrayData(int[] arr){
//1.判断数组是否为null
if(arr==null){
return null;
}
//2.如果数组不为null,再遍历,并拼接数组中的元素
StringJoiner s = new StringJoiner(", ","[","]");
for(int i=0; i<arr.length; i++){
//加""是因为add方法的参数要的是String类型
s.add(String.valueOf(arr[i]));
}
//3、把StringJoiner转换为String,并返回。
return s.toString();
}
}
面向对象和面向过程的区别
两者的主要区别在于解决问题的方式不同:
- 面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。
- 面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。
另外,面向对象开发的程序一般更易维护、易复用、易扩展。
面向对象:
public class Circle {
// 定义圆的半径
private double radius;
// 构造函数
public Circle(double radius) {
this.radius = radius;
}
// 计算圆的面积
public double getArea() {
return Math.PI * radius * radius;
}
public static void main(String[] args) {
// 创建一个半径为3的圆
Circle circle = new Circle(3.0);
// 输出圆的面积
System.out.println("圆的面积为:" + circle.getArea());
}
}
我们定义了一个 Circle 类来表示圆,该类包含了圆的半径属性和计算面积的方法。
面向过程:
public class Main {
public static void main(String[] args) {
// 定义圆的半径
double radius = 3.0;
// 计算圆的面积和周长
double area = Math.PI * radius * radius;
// 输出圆的面积和周长
System.out.println("圆的面积为:" + area);
}
}
创建对象运算符、对象实体与对象引用有何不同
new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。
class Car {
String model;
Car(String model) {
this.model = model;
}
}
public class Main {
public static void main(String[] args) {
// 对象实体
Car myCar = new Car("Toyota");
// 对象引用
Car anotherCar = myCar; // 将对象实体的引用赋给对象引用
// 修改对象实体的属性
myCar.model = "Honda";
// 输出对象引用和对象实体的属性值
System.out.println("Object Reference: " + anotherCar.model);
System.out.println("Object Entity: " + myCar.model);
}
}
myCar 是一个对象实体,它存储在堆内存中,然后我们将对象实体的引用赋给了 anotherCar。修改 myCar 的属性值后,通过 anotherCar 访问相同的对象实体,因此输出中两者的属性值都变为 "Honda"。
对象的相等和引用相等的区别
- 对象的相等一般比较的是内存中存放的内容是否相等。
equals比较的是内容 - 引用相等一般比较的是他们指向的内存地址是否相等。
==比较的是引用
String str1 = "hello";
String str2 = new String("hello");
String str3 = "hello";
// 使用 == 比较字符串的引用相等
System.out.println(str1 == str2);//== 运算符比较字符串的引用,这里 str1 和 str2 引用的是不同的对象,所以输出 false。
System.out.println(str1 == str3);//str1 和 str3 引用的是相同的对象(都指向 字符串常量池 中的 "hello" 对象 true)
// 使用 equals 方法比较字符串的相等
System.out.println(str1.equals(str2));// true
System.out.println(str1.equals(str3));// true
如果一个类没有声明构造方法,该程序能正确执行吗
构造方法:是一种特殊的方法,主要作用是完成对象的初始化工作。
如果一个类没有声明构造方法,也可以执行!因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
构造方法特点
- 名字与类名相同。
- 没有返回值,但不能用 void 声明构造函数。
- 生成类的对象时自动执行,无需调用。
构造方法不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
面向对象三大特征
封装
封装:用类设计对象处理某一个事物的数据时,应该把要处理的数据,以及处理数据的方法,都设计到一个对象中去。
比如:在设计学生类时,把学生对象的姓名、语文成绩、数学成绩三个属性,以及求学生总分、平均分的方法,都封装到学生对象中来。
封装的设计规范用8个字总结,就是:合理隐藏、合理暴露
一般我们在设计一个类时,会将成员变量隐藏,然后把操作成员变量的方法对外暴露。
继承

关于继承如下 3 点请记住:
- 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
- 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。
- 子类对象实际上是由子、父类两张设计图共同创建出来的。
接下来,我们演示一下使用继承来编写代码,注意观察继承的特点。
public class A{
//公开的成员
public int i;
public void print1(){
System.out.println("===print1===");
}
//私有的成员
private int j;
private void print2(){
System.out.println("===print2===");
}
}
然后,写一个B类,让B类继承A类。在继承A类的同时,B类中新增一个方法print3
public class B extends A{
public void print3(){
//由于i和print1是属于父类A的公有成员,在子类中可以直接被使用
System.out.println(i); //正确
print1(); //正确
//由于j和print2是属于父类A的私有成员,在子类中不可以被使用
System.out.println(j); //错误
print2();
}
}
再演示一下,创建B类对象,能否调用父类A的成员。再写一个测试类
public class Test{
public static void main(String[] args){
B b = new B();
//父类公有成员,子类对象是可以调用的
System.out.println(i); //正确
b.print1();
//父类私有成员,子类对象时不可以调用的
System.out.println(j); //错误
b.print2(); //错误
}
}
继承好处
使用继承,可以快速地创建新的类,提高代码的复用性,节省大量创建新类的时间 ,提高我们的开发效率。
权限修饰符
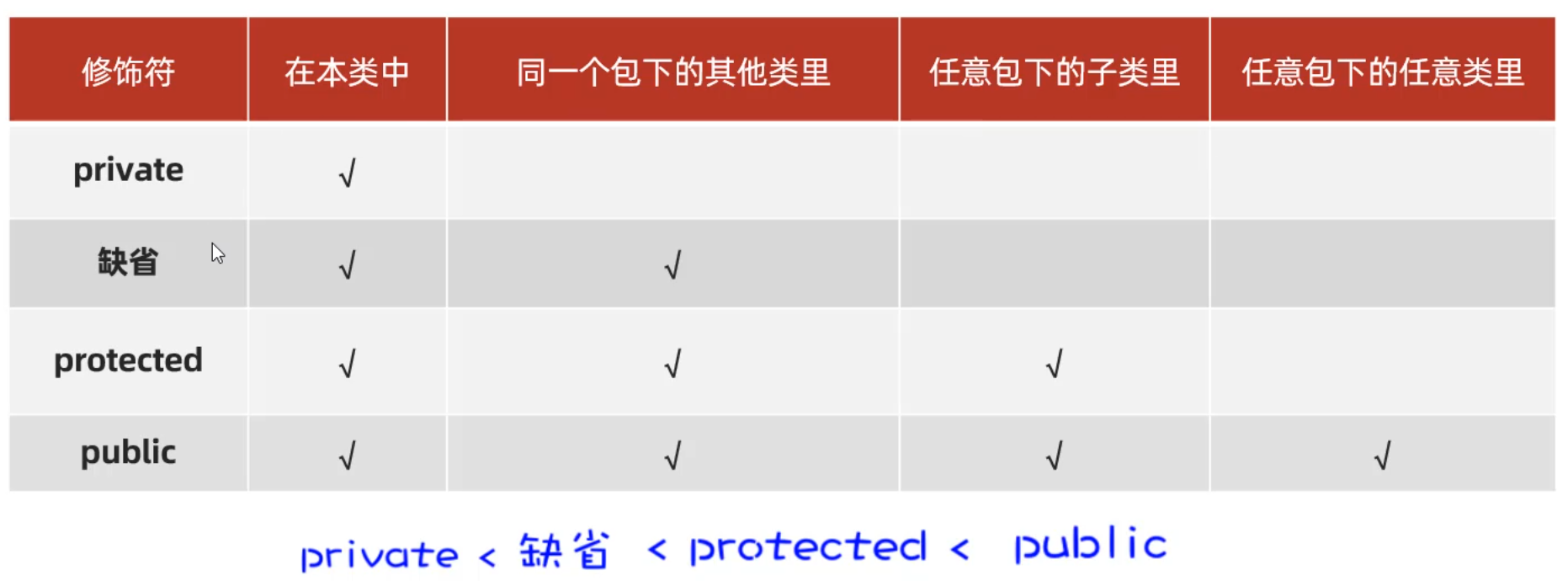
下面我们用代码演示一下,在本类中可以访问到哪些权限修饰的方法。
public class Fu {
// 1、私有:只能在本类中访问
private void privateMethod(){
System.out.println("==private==");
}
// 2、缺省:本类,同一个包下的类
void method(){
System.out.println("==缺省==");
}
// 3、protected: 本类,同一个包下的类,任意包下的子类
protected void protectedMethod(){
System.out.println("==protected==");
}
// 4、public: 本类,同一个包下的类,任意包下的子类,任意包下的任意类
public void publicMethod(){
System.out.println("==public==");
}
public void test(){
//在本类中,所有权限都可以被访问到
privateMethod(); //正确
method(); //正确
protectedMethod(); //正确
publicMethod(); //正确
}
}
接下来,在和Fu类同一个包下,创建一个测试类Demo,演示同一个包下可以访问到哪些权限修饰的方法。
public class Demo {
public static void main(String[] args) {
Fu f = new Fu();
// f.privateMethod(); //私有方法无法使用
f.method();
f.protectedMethod();
f.publicMethod();
}
}
接下来,在另一个包下创建一个Fu类的子类,演示不同包下的子类中可以访问哪些权限修饰的方法。
public class Zi extends Fu {
//在不同包下的子类中,只能访问到public、protected修饰的方法
public void test(){
// privateMethod(); // 报错
// method(); // 报错
protectedMethod(); //正确
publicMethod(); //正确
}
}
接下来,在和Fu类不同的包下,创建一个测试类Demo2,演示一下不同包的无关类,能访问到哪些权限修饰的方法;
public class Demo2 {
public static void main(String[] args) {
Fu f = new Fu();
// f.privateMethod(); // 报错
// f.method(); //报错
// f.protecedMethod();//报错
f.publicMethod(); //正确
Zi zi = new Zi();
// zi.protectedMethod(); //报错
}
}
单继承、Object
Java语言只支持单继承,不支持多继承,但是可以多层继承。
就像家族里儿子、爸爸和爷爷的关系一样:一个儿子只能有一个爸爸,不能有多个爸爸,但是爸爸也是有爸爸的。
public class Test {
public static void main(String[] args) {
// 目标:掌握继承的两个注意事项事项。
// 1、Java是单继承的:一个类只能继承一个直接父类;
// 2、Object类是Java中所有类的祖宗。
A a = new A();
B b = new B();
ArrayList list = new ArrayList();
list.add("java");
System.out.println(list.toString());
}
}
class A {} //extends Object{}
class B extends A{}
// class C extends B , A{} // 报错
class D extends B{}
子类中访问成员的特点
子类中访问构造器的特点
多态
方法名相同,但各自的参数不同,称为方法重载(Overload)。
在继承关系中,子类如果定义了一个与父类方法签名完全相同的方法,被称为覆写(Override)。
多态是指,针对某个类型的方法调用,其真正执行的方法取决于运行时期实际类型的方法。例如:
多态的特性就是,运行期才能动态决定调用的子类方法。对某个类型调用某个方法,执行的实际方法可能是某个子类的覆写方法。
比如:Teacher和Student都是People的子类,代码可以写成下面的样子

定义方法时,使用父类类型作为形参,可以接收一切子类对象,扩展行更强,更便利。
public class Test2 {
public static void main(String[] args) {
// 目标:掌握使用多态的好处
Teacher t = new Teacher();
go(t);
Student s = new Student();
go(s);
}
//参数People p既可以接收Student对象,也能接收Teacher对象。
public static void go(People p){
System.out.println("开始------------------------");
p.run();
System.out.println("结束------------------------");
}
}
调用super
在子类的覆写方法中,如果要调用父类的被覆写的方法,可以通过super来调用。
在 Java 中,super 关键字用于访问父类(超类)的方法和构造方法。它有两个主要用途:
- 调用父类的构造方法。
- 访问父类的被覆写方法或属性。
假设我们有一个父类 Animal,它有一个方法 make_sound。然后我们创建一个子类 Dog,并在子类中覆写 make_sound 方法,但我们仍然希望在子类的方法中调用父类的方法。
python复制代码class Animal:
def make_sound(self):
print("Animal makes a sound")
class Dog(Animal):
def make_sound(self):
super().make_sound() # 调用父类的make_sound方法
print("Dog barks")
# 创建一个Dog对象并调用make_sound方法
dog = Dog()
dog.make_sound()
在这个例子中,Dog 类覆写了 Animal 类的 make_sound 方法。在 Dog 类的 make_sound 方法中,我们使用 super().make_sound() 来调用父类 Animal 的 make_sound 方法。
运行上面的代码将输出:
Animal makes a sound
Dog barks
可以看到,调用 dog.make_sound() 时,首先执行了父类 Animal 的 make_sound 方法,输出 "Animal makes a sound",然后执行子类 Dog 的 make_sound 方法,输出 "Dog barks"。
final
继承可以允许子类覆写父类的方法。如果一个父类不允许子类对它的某个方法进行覆写,可以把该方法标记为final。用final修饰的方法不能被Override:
如果一个类不希望任何其他类继承自它,那么可以把这个类本身标记为final。用final修饰的类不能被继承:
对于一个类的实例字段,同样可以用final修饰。用final修饰的字段在初始化后不能被修改。例如:
public class Main {
public static void main(String[] args) {
// 给一个有普通收入、工资收入和享受国务院特殊津贴的小伙伴算税:
Income[] incomes = new Income[] {
new Income(3000),
new Salary(7500),
new StateCouncilSpecialAllowance(15000)
};
System.out.println(totalTax(incomes));
}
public static double totalTax(Income... incomes) {
double total = 0;
for (Income income: incomes) {
total = total + income.getTax();
}
return total;
}
}
class Income {
protected double income;
public Income(double income) {
this.income = income;
}
public double getTax() {
return income * 0.1; // 税率10%
}
}
class Salary extends Income {
public Salary(double income) {
super(income);
}
@Override
public double getTax() {
if (income <= 5000) {
return 0;
}
return (income - 5000) * 0.2;
}
}
class StateCouncilSpecialAllowance extends Income {
public StateCouncilSpecialAllowance(double income) {
super(income);
}
@Override
public double getTax() {
return 0;
}
}
super(income) 出现在 Salary 类和 StateCouncilSpecialAllowance 类的构造方法中。这个调用实际上是在调用父类 Income 的构造方法,并将参数 income 传递给它。可以确保在创建子类实例时,父类的构造方法也会被执行,从而正确初始化父类中的属性。
观察totalTax()方法:利用多态,totalTax()方法只需要和Income打交道,它完全不需要知道Salary和StateCouncilSpecialAllowance的存在,就可以正确计算出总的税。如果我们要新增一种稿费收入,只需要从Income派生,然后正确覆写getTax()方法就可以。把新的类型传入totalTax(),不需要修改任何代码。
多态允许添加更多类型的子类实现功能扩展,却不需要修改基于父类的代码。
类型转换
虽然多态形式下有一些好处,但是也有一些弊端。在多态形式下,不能调用子类特有的方法,比如在Teacher类中多了一个teach方法,在Student类中多了一个study方法,这两个方法在多态形式下是不能直接调用的。

多态形式下不能直接调用子类特有方法,但是转型后是可以调用的。这里所说的转型就是把父类变量转换为子类类型。格式如下:
//如果p接收的是子类对象
if(父类变量 instance 子类){
//则可以将p转换为子类类型
子类 变量名 = (子类)父类变量;
}

如果类型转换错了,就会出现类型转换异常ClassCastException,比如把Teacher类型转换成了Student类型.

关于多态转型问题,我们最终记住一句话:原本是什么类型,才能还原成什么类型
表示一个对象具有多种的状态,具体表现为父类的引用指向子类的实例。
- 多态不能调用“只在子类存在但在父类不存在”的方法;
- 如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。
接口和抽象类共同点和区别
共同点:
- 都不能被实例化。
- 都可以包含抽象方法。
- 都可以有默认实现的方法(Java 8 可以用
default关键字在接口中定义默认方法)。
区别:
- 接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
- 一个类只能继承一个类,但是可以实现多个接口。
- 接口中的成员变量只能是
public static final类型的,不能被修改且必须有初始值,而抽象类的成员变量默认 default,可在子类中被重新定义,也可被重新赋值。
// 接口
interface Shape {
// 接口中的方法默认是抽象的
double calculateArea();
void display();
}
// 抽象类
abstract class AbstractShape {
// 抽象类中可以包含抽象方法
abstract double calculateArea();
// 抽象类中可以包含普通方法的实现
void display() {
System.out.println("Displaying shape");
}
}
// 具体实现类:圆形
class Circle implements Shape {
private double radius;
public Circle(double radius) {
this.radius = radius;
}
@Override
public double calculateArea() {
return Math.PI * radius * radius;
}
@Override
public void display() {
System.out.println("Displaying circle");
}
}
// 具体实现类:矩形
class Rectangle extends AbstractShape {
private double length;
private double width;
public Rectangle(double length, double width) {
this.length = length;
this.width = width;
}
@Override
public double calculateArea() {
return length * width;
}
}
public class Main {
public static void main(String[] args) {
// 使用接口
Shape circle = new Circle(5.0);
circle.display();
System.out.println("Area of circle: " + circle.calculateArea());
// 使用抽象类
AbstractShape rectangle = new Rectangle(4.0, 6.0);
rectangle.display();
System.out.println("Area of rectangle: " + rectangle.calculateArea());
}
}
在上面的例子中,Shape 接口和 AbstractShape 抽象类都定义了图形的形状,并约定了计算面积和显示的方法。Circle 类实现了 Shape 接口,提供了计算圆形面积和显示的具体实现。Rectangle 类继承了 AbstractShape 抽象类,提供了计算矩形面积的具体实现。这展示了接口和抽象类的用法和区别。
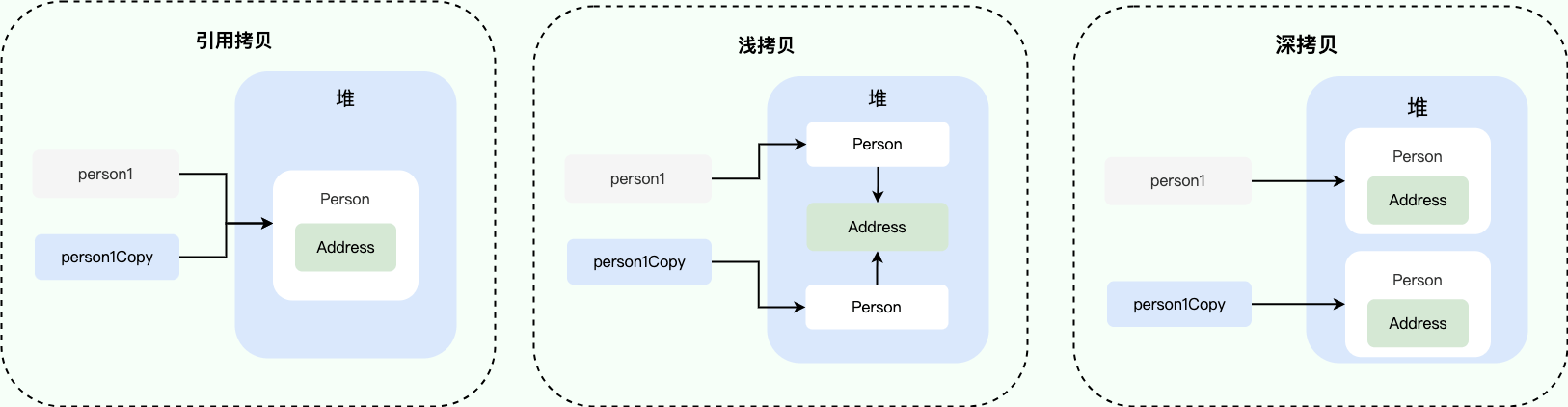
深拷贝、浅拷贝、引用拷贝
浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
引用拷贝:两个不同的引用指向同一个对象。
浅拷贝(Shallow Copy):
浅拷贝是指复制对象,但只复制对象本身和对象中的基本数据类型字段,而不复制对象中引用类型字段所引用的对象。因此,原对象和浅拷贝对象会共享同一个引用类型对象。
public class Address implements Cloneable{
private String name;
// 省略构造函数、Getter&Setter方法
@Override
public Address clone() {
try {
return (Address) super.clone();
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
public class Person implements Cloneable {
private Address address;
// 省略构造函数、Getter&Setter方法
@Override
public Person clone() {
try {
Person person = (Person) super.clone();
return person;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
}
实现了 Cloneable 接口,并重写了 clone() 方法。
clone() 方法的实现很简单,直接调用的是父类 Object 的 clone() 方法。
测试:
Person person1 = new Person(new Address("武汉"));
Person person1Copy = person1.clone();
// true
System.out.println(person1.getAddress() == person1Copy.getAddress());
从输出结构就可以看出, person1 的克隆对象和 person1 使用的仍然是同一个 Address 对象。
深拷贝(Deep Copy):
深拷贝是指复制对象,并且递归地复制对象中的所有引用类型字段所引用的对象,而不是共享引用类型对象。因此,原对象和深拷贝对象拥有各自独立的引用类型对象。
这里我们简单对 Person 类的 clone() 方法进行修改,连带着要把 Person 对象内部的 Address 对象一起复制。
@Override
public Person clone() {
try {
Person person = (Person) super.clone(); // 先调用父类的 clone() 方法进行浅拷贝
// 调用 person 对象的 getAddress() 方法获取获取 Person 对象的地址属性,即 Address 对象。
// 然后对Address 对象调用 clone() 方法,实现了 Address 对象的深拷贝
person.setAddress(person.getAddress().clone());
return person;
} catch (CloneNotSupportedException e) {
throw new AssertionError();
}
}
测试:
Person person1 = new Person(new Address("武汉"));
Person person1Copy = person1.clone();
// false
System.out.println(person1.getAddress() == person1Copy.getAddress());
从输出结构就可以看出,显然 person1 的克隆对象和 person1 包含的 Address 对象已经是不同的了。
引用拷贝:
引用拷贝实际上是指两个引用变量指向同一个对象,没有发生对象本身的拷贝。修改其中一个引用变量会影响另一个引用变量。
public class Main {
public static void main(String[] args) {
Address address1 = new Address("New York");
Address address2 = address1; // 引用拷贝
// 修改其中一个引用变量
address1.city = "San Francisco";
System.out.println(address1.city); // San Francisco
System.out.println(address2.city); // San Francisco (因为是引用拷贝,指向同一个 Address 对象)
}
}
在上述例子中,address2 实际上是 address1 的引用拷贝,它们指向同一个 Address 对象。因此,修改其中一个引用变量会影响另一个引用变量。
Object
Object 类的常见方法有哪些
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
/**
* native 方法,用于返回当前运行时对象的 Class 对象,使用了 final 关键字修饰,故不允许子类重写。
*/
public final native Class<?> getClass()
/**
* native 方法,用于返回对象的哈希码,主要使用在哈希表中,比如 JDK 中的HashMap。
*/
public native int hashCode()
/**
* 用于比较 2 个对象的内存地址是否相等,String 类对该方法进行了重写以用于比较字符串的值是否相等。
*/
public boolean equals(Object obj)
/**
* native 方法,用于创建并返回当前对象的一份拷贝。
*/
protected native Object clone() throws CloneNotSupportedException
/**
* 返回类的名字实例的哈希码的 16 进制的字符串。建议 Object 所有的子类都重写这个方法。
*/
public String toString()
/**
* native 方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
*/
public final native void notify()
/**
* native 方法,并且不能重写。跟 notify 一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
*/
public final native void notifyAll()
/**
* native方法,并且不能重写。暂停线程的执行。注意:sleep 方法没有释放锁,而 wait 方法释放了锁 ,timeout 是等待时间。
*/
public final native void wait(long timeout) throws InterruptedException
/**
* 多了 nanos 参数,这个参数表示额外时间(以纳秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 纳秒。。
*/
public final void wait(long timeout, int nanos) throws InterruptedException
/**
* 跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
*/
public final void wait() throws InterruptedException
/**
* 实例被垃圾回收器回收的时候触发的操作
*/
protected void finalize() throws Throwable { }
== 和 equals() 的区别
在Java中,引用类型主要包括以下几种:
- 类(Class): 用户自定义的类是引用类型的一种,它可以包含字段和方法。类的实例通过
new关键字创建。
class MyClass {
// 类的定义
}
MyClass obj = new MyClass(); // 创建 MyClass 类的实例
-
接口(Interface): 接口是一种抽象类型,可以包含方法的声明。类通过实现接口来提供接口中声明的具体实现。
interface MyInterface { // 接口的定义 } class MyClass implements MyInterface { // 实现 MyInterface 接口 } -
数组(Array): 数组是一种引用类型,可以存储相同类型的元素的集合。数组通过
new关键字创建。
int[] numbers = new int[5]; // 创建一个包含5个整数的数组
-
枚举(Enum): 枚举是一种特殊的引用类型,用于表示一组常量。枚举类型通过
enum关键字定义。enum Day { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY } Day today = Day.MONDAY; -
接口数组和类数组: 引用类型的数组可以包含接口类型或类类型的元素。
MyInterface[] interfaceArray = new MyInterface[3]; MyClass[] classArray = new MyClass[3]; -
集合类和泛型: Java提供了丰富的集合类,如
List、Set、Map等,以及泛型机制,用于处理引用类型的集合和容器。List<String> stringList = new ArrayList<>(); -
其他引用类型: 还有其他一些引用类型,如
String、StringBuilder、HashMap等,它们是Java中常用的引用类型。String str = "Hello"; // String 类型 StringBuilder builder = new StringBuilder(); // StringBuilder 类型==对于基本类型和引用类型的作用效果是不同的:- 对于基本数据类型来说,
==比较的是值。 - 对于引用数据类型来说,
==比较的是对象的内存地址。
equals()不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。 - 对于基本数据类型来说,
hashCode
hashCode作用:
hashCode() :获取哈希码(int 整数),也称为散列码,哈希码的作用是确定该对象在哈希表中的索引位置。

public native int hashCode();
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有hashCode:
hashCode() 和 equals()都是用于比较两个对象是否相等。
- 先计算对象的 hashCode 值
- 没有相符的 hashCode,HashSet 会假设对象没有重复出现
- 有相同 hashCode 值的对象,调用 equals() 方法来检查 hashCode 相等的对象是否真的相同
- 如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashCode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashCode 值作比较,如果没有相符的 hashCode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashCode 值的对象,这时会调用 equals() 方法来检查 hashCode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
那为什么 JDK 还要同时提供这两个方法呢?
因为在一些容器(比如 HashMap、HashSet)中,有了 hashCode() 之后,判断元素是否在对应容器中的效率会更高(参考添加元素进HashSet的过程)!
那为什么不只提供 hashCode() 方法呢?
这是因为两个对象的hashCode 值相等并不代表两个对象就相等。
那为什么两个对象有相同的 hashCode 值,它们也不一定是相等的?
因为 hashCode() 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的 hashCode )。
总结下来就是:
- 如果两个对象的
hashCode值相等,那这两个对象不一定相等(哈希碰撞)。 - 如果两个对象的
hashCode值相等并且equals()方法也返回true,我们才认为这两个对象相等。 - 如果两个对象的
hashCode值不相等,我们就可以直接认为这两个对象不相等。
重写 equals() 时为什么必须重写 hashCode() 方法
在Java中,当你重写一个类的 equals() 方法时,通常也需要重写 hashCode() 方法。
因为两个相等的对象的 hashCode 值必须是相等,即说如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
因此,一般来说,当你重写了 equals() 方法时,最好也一并重写 hashCode() 方法,以确保它们的一致性。
数组
数组有两种初始化的方式,一种是静态初始化、一种是动态初始化。
静态初始化
在定义数组时直接给数组中的数据赋值。
数据类型[] 变量名 = new 数据类型[]{元素1,元素2,元素3};
//定义数组,用来存储多个年龄
int[] ages = new int[]{12, 24, 36}
//定义数组,用来存储多个成绩
double[] scores = new double[]{89.9, 99.5, 59.5, 88.0};
静态初始化的一种简化写法:
数据类型[] 变量名 = {元素1,元素2,元素3};
//定义数组,用来存储多个年龄
int[] ages = {12, 24, 36}
//定义数组,用来存储多个成绩
double[] scores = {89.9, 99.5, 59.5, 88.0};
定义数组时, 数据类型[] 数组名也可写成数据类型 数组名[]`
//以下两种写法是等价的。但是建议大家用第一种,因为这种写法更加普遍
int[] ages = {12, 24, 36};
int ages[] = {12, 24, 36}
动态初始化
动态初始化不需要我们写出具体的元素,而是指定元素类型和长度就行。
//数据类型[] 数组名 = new 数据类型[长度];
int[] arr = new int[3];
String
String类创建对象
方式一: 直接使用双引号“...” 。
方式二:new String类,调用构造器初始化字符串对象。
String s1 = "abc"; //这里"abc"就是一个字符串对象,用s1变量接收
String rs2 = new String("itheima");
System.out.println(rs2);
char[] chars = {'a', '黑', '马'};
String rs3 = new String(chars);
System.out.println(rs3); //a黑马
String常用方法
public class StringDemo2 {
public static void main(String[] args) {
//目标:快速熟悉String提供的处理字符串的常用方法。
String s = "黑马Java";
// 1、获取字符串的长度
System.out.println(s.length());
// 2、提取字符串中某个索引位置处的字符
char c = s.charAt(1);
System.out.println(c);
// 字符串的遍历
for (int i = 0; i < s.length(); i++) {
// i = 0 1 2 3 4 5
char ch = s.charAt(i);
System.out.println(ch);
}
System.out.println("-------------------");
// 3、把字符串转换成字符数组,再进行遍历
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
System.out.println(chars[i]);
}
// 4、判断字符串内容,内容一样就返回true
// 总结:在Java中,如果你想比较两个字符串的内容是否相同,应该使用 equals() 方法。
// 如果你想比较两个字符串对象的引用地址是否相同,可以使用 == 运算符。
String s1 = new String("黑马");
String s2 = new String("黑马");
System.out.println(s1 == s2); // false
System.out.println(s1.equals(s2)); // true
// 5、忽略大小写比较字符串内容
String c1 = "34AeFG";
String c2 = "34aEfg";
System.out.println(c1.equals(c2)); // false
System.out.println(c1.equalsIgnoreCase(c2)); // true
// 6、截取字符串内容 (包前不包后的)
String s3 = "Java是最好的编程语言之一";
String rs = s3.substring(0, 8);
System.out.println(rs);
// 7、从当前索引位置一直截取到字符串的末尾
String rs2 = s3.substring(5);
System.out.println(rs2);
// 8、把字符串中的某个内容替换成新内容,并返回新的字符串对象给我们
String info = "这个电影简直是个垃圾,垃圾电影!!";
String rs3 = info.replace("垃圾", "**");
System.out.println(rs3);
// 9、判断字符串中是否包含某个关键字
String info2 = "Java是最好的编程语言之一,我爱Java,Java不爱我!";
System.out.println(info2.contains("Java"));
System.out.println(info2.contains("java"));
System.out.println(info2.contains("Java2"));
// 10、判断字符串是否以某个字符串开头。
String rs4 = "张三丰";
System.out.println(rs4.startsWith("张"));
System.out.println(rs4.startsWith("张三"));
System.out.println(rs4.startsWith("张三2"));
// 11、把字符串按照某个指定内容分割成多个字符串,放到一个字符串数组中返回给我们
String rs5 = "张无忌,周芷若,殷素素,赵敏";
String[] names = rs5.split(",");
for (int i = 0; i < names.length; i++) {
System.out.println(names[i]);
}
}
}
String、StringBuffer、StringBuilder 的区别
可变性
String 是不可变的,是只读字符串,即String引用的字符串内容是不能被改变的。
StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串,不过没有使用 final 和 private 关键字修饰,最关键的是这个 AbstractStringBuilder 类还提供了很多修改字符串的方法比如 append 方法。
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
//...
}
线程安全性
-
String中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder是StringBuilder与StringBuffer的公共父类,定义了一些字符串的基本操作,如expandCapacity、append、insert、indexOf等公共方法。 -
StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。 -
StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。
性能
-
对
String类型进行改变的时候,都会生成一个新的String对象,然后将指针指向新的String对象。 -
StringBuffer每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用。 -
StringBuilder相比使用StringBuffer仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
- 操作少量的数据: 适用
String - 单线程操作字符串缓冲区下操作大量数据: 适用
StringBuilder - 多线程操作字符串缓冲区下操作大量数据: 适用
StringBuffer
String s = new String("xyz")会创建几个对象?
- 首先在String池内寻找,若"xyz"字符串已存在,不创建"xyz"对应的String对象,否则创建一个对象。
- 然后,遇到new关键字,在内存上创建String对象,并将其返回给s,又一个对象。
所以,总共1个或2个对象。
String 为什么是不可变的
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
//...
}
🐛 修正:被 final 关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象。因此,final 关键字修饰的数组保存字符串并不是 String 不可变的根本原因,因为这个数组保存的字符串是可变的(final 修饰引用类型变量的情况)。
final修饰的value数组: 这确保了value数组一旦分配了内存空间并存储了字符串的字符,就不能再指向其他数组对象。这是对数组引用的不可变性。private修饰的value数组:private关键字使得value数组只能在String类的内部访问,外部类无法直接修改这个数组。final修饰的String类:final关键字确保了String类不能被继承。如果String类可以被继承,子类可能会修改其行为,破坏字符串的不可变性。
String 真正不可变有下面几点原因:
- 保存字符串的数组被
final修饰且为私有的,并且String类没有提供/暴露修改这个字符串的方法。 String类被final修饰导致其不能被继承,进而避免了子类破坏String不可变。
字符串字面量和new出来字符串的区别
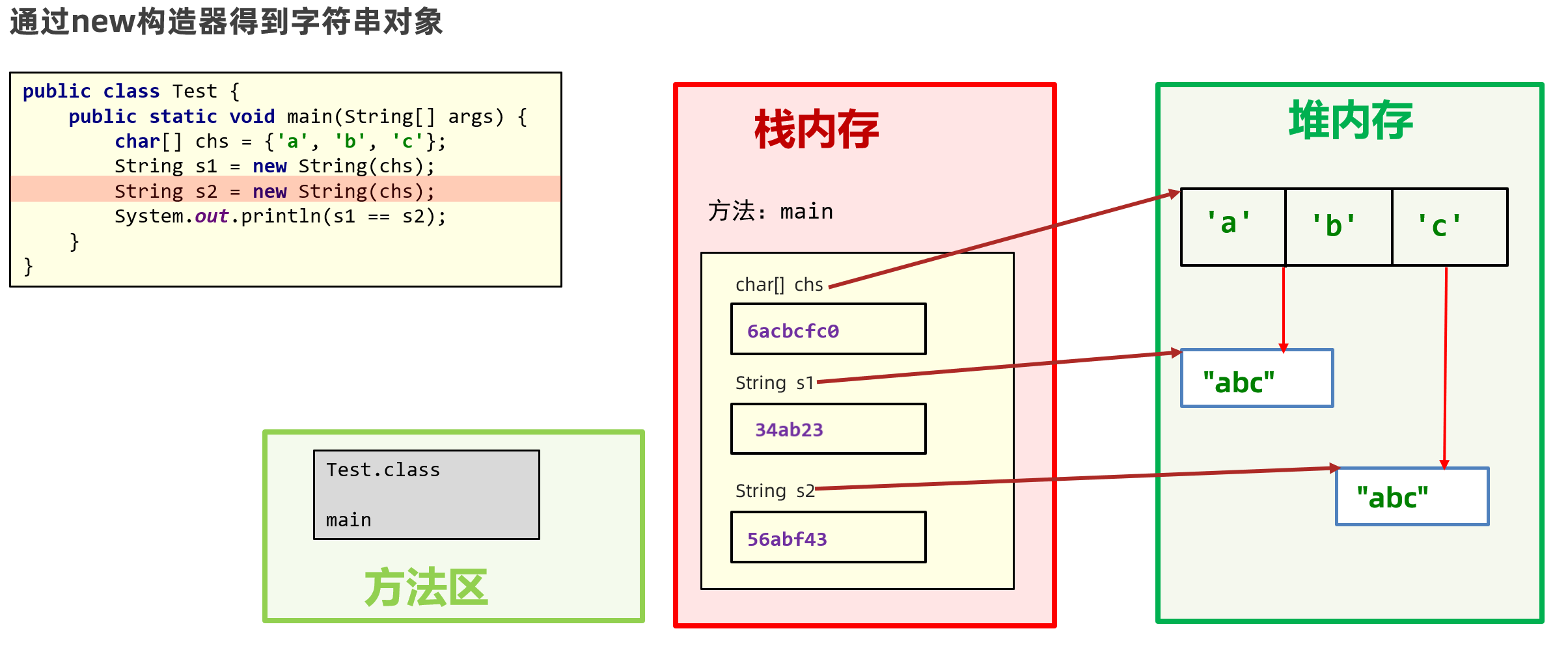
- 只要是以
“...”方式写出的字符串对象,会存储到字符串常量池,且相同内容的字符串只存储一份。 - 但通过
new方式创建字符串对象,每new一次都会产生一个新的对象放在堆内存中。
字符串拼接用“+” 还是 StringBuilder?
String#equals() 和 Object#equals() 有何区别?
String 中的 equals 方法是被重写过的,比较的是 String 字符串的值是否相等。 Object 的 equals 方法是比较的对象的内存地址。
字符串常量池的作用了解吗?
字符串常量池 : JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
// 在堆中创建字符串对象”ab“
// 将字符串对象”ab“的引用保存在字符串常量池中
String aa = "ab";
// 直接返回字符串常量池中字符串对象”ab“的引用
String bb = "ab";
System.out.println(aa==bb);// true 对于引用数据类型来说,`==` 比较的是对象的内存地址。
String s1 = new String("abc");这句话创建了几个字符串对象?
1、如果字符串常量池中不存在字符串对象“abc”的引用,那么它会在堆上创建两个字符串对象,其中一个字符串对象的引用会被保存在字符串常量池中。常量池中的字符串对象:"abc" 、堆中的字符串对象:s1
2、如果字符串常量池中已存在字符串对象“abc”的引用,则只会在堆中创建 1 个字符串对象“abc”。堆中的字符串对象:s1
String#intern 方法有什么作用?
String.intern() 是一个 native(本地)方法,其作用是将指定的字符串对象的引用保存在字符串常量池中,可以简单分为两种情况:
- 如果字符串常量池中保存了对应的字符串对象的引用,就直接返回该引用。
- 如果字符串常量池中没有保存了对应的字符串对象的引用,那就在常量池中创建一个指向该字符串对象的引用并返回。
// 在堆中创建字符串对象”Java“
// 将字符串对象”Java“的引用保存在字符串常量池中
// 将常量池中的引用赋给 s1
String s1 = "Java";
// 直接返回字符串常量池中字符串对象”Java“对应的引用.因此s2也指向了常量池中的"Java"字符串对象。
String s2 = s1.intern();
// 会在堆中在单独创建一个字符串对象
String s3 = new String("Java");
// 直接返回字符串常量池中字符串对象”Java“对应的引用
String s4 = s3.intern();
// s1 和 s2 指向的是堆中的同一个对象
System.out.println(s1 == s2); // true
// s3 和 s4 指向的是堆中不同的对象
System.out.println(s3 == s4); // false
// s1 和 s4 指向的是堆中的同一个对象
System.out.println(s1 == s4); //true
String 类型的变量和常量做“+”运算时发生了什么?
先来看字符串不加 final 关键字拼接的情况(JDK1.8):
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing"; //常量词中对象
String str4 = str1 + str2;//在堆上创建的新的对象
String str5 = "string"; //常量词中对象
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false
对于编译期可以确定值的字符串,也就是常量字符串 ,jvm 会将其存入字符串常量池。
常量折叠:会把常量表达式的值求出来作为常量嵌在最终生成的代码中.
字符串使用 final 关键字声明之后,可以让编译器当做常量来处理。对于 String str3 = "str" + "ing"; 编译器会给你优化成 String str3 = "string"; 。
示例代码:
final String str1 = "str";
final String str2 = "ing";
// 下面两个表达式其实是等价的
String c = "str" + "ing";// 常量池中的对象
String d = str1 + str2; // 常量池中的对象
System.out.println(c == d);// true
如果 ,编译器在运行时才能知道其确切值的话,就无法对其优化。
示例代码(str2 在运行时才能确定其值):
final String str1 = "str";
final String str2 = getStr();
String c = "str" + "ing";// 常量池中的对象
String d = str1 + str2; // 在堆上创建的新的对象
System.out.println(c == d);// false
public static String getStr() {
return "ing";
}
集合
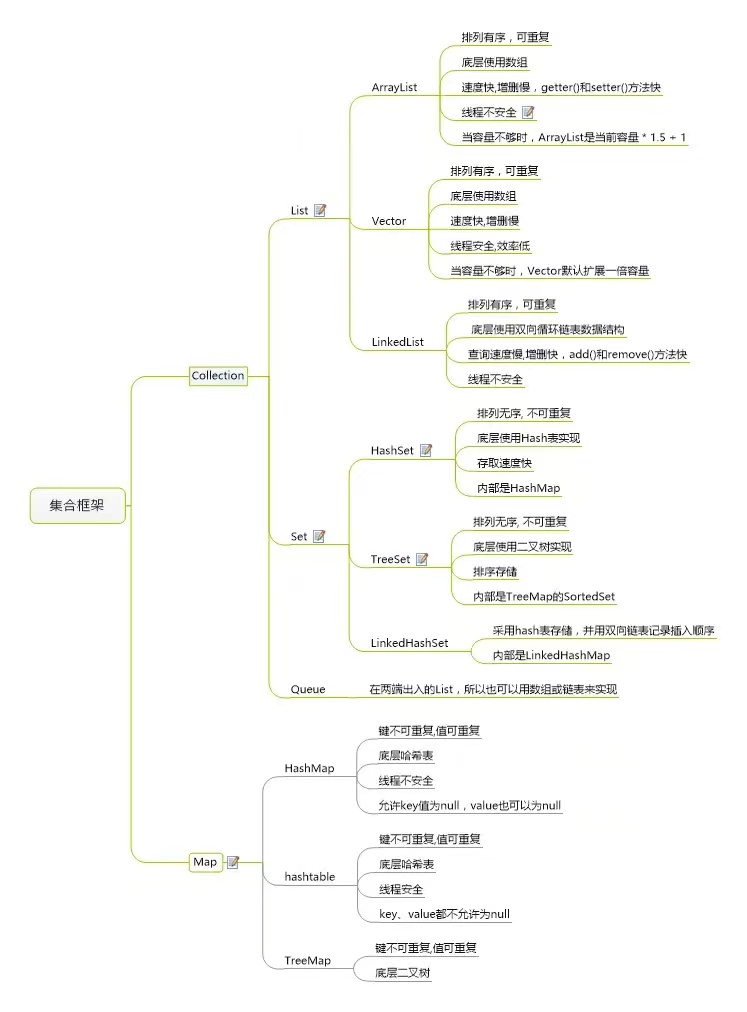
Java提供的常见集合?
- 在java中提供了量大类的集合框架,主要分为两类: 第一个是Collection 属于单列集合,第二个是Map 属于双列集合 。
- 在Collection中有两个子接口List和Set。在我们平常开发的过程中用的比较多,像list 接口中的实现类ArrarList和LinkedList。 在Set接口中有实现类HashSet和 TreeSet。
- 在map接口中有很多的实现类,平时比较常见的是HashMap、TreeMap,还有一个线程安全的map:ConcurrentHashMap
说说 List, Set, Queue, Map 四者的区别
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
Collection 接口下面的集合:
List
ArrayList:Object[]数组。Vector:Object[]数组。LinkedList:双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)。
Set
HashSet(无序,唯一): 基于HashMap实现的,底层采用HashMap来保存元素。LinkedHashSet:LinkedHashSet是HashSet的子类,并且其内部是通过LinkedHashMap来实现的。TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)。
Queue
PriorityQueue:Object[]数组来实现小顶堆。DelayQueue:PriorityQueue。ArrayDeque: 可扩容动态双向数组。
再来看看 Map 接口下面的集合。
Map
-
HashMap:JDK1.8 之前
HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
-
LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。) -
Hashtable:数组+链表组成的,数组是Hashtable的主体,链表则是主要为了解决哈希冲突而存在的。 -
TreeMap:红黑树(自平衡的排序二叉树)
为什么要使用集合?
当我们需要存储一组类型相同的数据时,数组是最常用且最基本的容器之一。但是,使用数组存储对象存在一些不足之处,因为在实际开发中,存储的数据类型多种多样且数量不确定。
这时,Java 集合就派上用场了。与数组相比,Java 集合提供了更灵活、更有效的方法来存储多个数据对象。
Java 集合框架中的各种集合类和接口可以存储不同类型和数量的对象,同时还具有多样化的操作方式。
相较于数组,Java 集合的优势在于它们的大小可变、支持泛型、具有内建算法等。总的来说,Java 集合提高了数据的存储和处理灵活性,可以更好地适应现代软件开发中多样化的数据需求,并支持高质量的代码编写。
如何选用集合?
我们主要根据集合的特点来选择合适的集合。比如:
- 我们需要根据键值获取到元素值时就选用
Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap。 - 我们只需要存放元素值时,就选择实现
Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。
ArrayList
ArrayList 和 Array(数组)的区别?
ArrayList 内部基于动态数组实现,比 Array(静态数组) 使用起来更加灵活:
ArrayList会根据实际存储的元素动态地扩容或缩容,而Array被创建之后就不能改变它的长度了。ArrayList允许你使用泛型来确保类型安全,Array则不可以。ArrayList中只能存储对象。对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)。Array可以直接存储基本类型数据,也可以存储对象。ArrayList支持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法,比如add()、remove()等。Array只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。ArrayList创建时不需要指定大小,而Array创建时必须指定大小。
下面是二者使用的简单对比:
Array:
// 初始化一个 String 类型的数组
String[] stringArr = new String[]{"hello", "world", "!"};
// 修改数组元素的值
stringArr[0] = "goodbye";
System.out.println(Arrays.toString(stringArr));// [goodbye, world, !]
// 删除数组中的元素,需要手动移动后面的元素
for (int i = 0; i < stringArr.length - 1; i++) {
stringArr[i] = stringArr[i + 1];
}
stringArr[stringArr.length - 1] = null;
System.out.println(Arrays.toString(stringArr));// [world, !, null]
ArrayList :
// 初始化一个 String 类型的 ArrayList
ArrayList<String> stringList = new ArrayList<>(Arrays.asList("hello", "world", "!"));
// 添加元素到 ArrayList 中
stringList.add("goodbye");
System.out.println(stringList);// [hello, world, !, goodbye]
// 修改 ArrayList 中的元素
stringList.set(0, "hi");
System.out.println(stringList);// [hi, world, !, goodbye]
// 删除 ArrayList 中的元素
stringList.remove(0);
System.out.println(stringList); // [world, !, goodbye]
ArrayList 插入和删除元素的时间复杂度?
对于插入:
- 头部插入:由于需要将所有元素都依次向后移动一个位置,因此时间复杂度是 O(n)。
- 尾部插入:当
ArrayList的容量未达到极限时,往列表末尾插入元素的时间复杂度是 O(1),因为它只需要在数组末尾添加一个元素即可;当容量已达到极限并且需要扩容时,则需要执行一次 O(n) 的操作将原数组复制到新的更大的数组中,然后再执行 O(1) 的操作添加元素。 - 指定位置插入:需要将目标位置之后的所有元素都向后移动一个位置,然后再把新元素放入指定位置。这个过程需要移动平均 n/2 个元素,因此时间复杂度为 O(n)。
对于删除:
- 头部删除:由于需要将所有元素依次向前移动一个位置,因此时间复杂度是 O(n)。
- 尾部删除:当删除的元素位于列表末尾时,时间复杂度为 O(1)。
- 指定位置删除:需要将目标元素之后的所有元素向前移动一个位置以填补被删除的空白位置,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
// ArrayList的底层数组大小为10,此时存储了7个元素
+---+---+---+---+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | | | |
+---+---+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8 9
// 在索引为1的位置插入一个元素8,该元素后面的所有元素都要向右移动一位
+---+---+---+---+---+---+---+---+---+---+
| 1 | 8 | 2 | 3 | 4 | 5 | 6 | 7 | | |
+---+---+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8 9
// 删除索引为1的位置的元素,该元素后面的所有元素都要向左移动一位
+---+---+---+---+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | | | |
+---+---+---+---+---+---+---+---+---+---+
0 1 2 3 4 5 6 7 8 9
LinkedList 插入和删除元素的时间复杂度?
- 头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,因此需要遍历平均 n/2 个元素,时间复杂度为 O(n)。
双向链表: 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
双向循环链表: 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
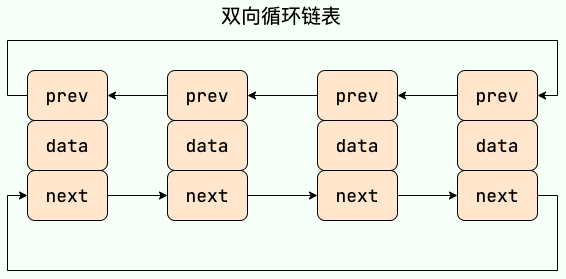
ArrayList表示一种集合,它是一个容器,用来装数据的,类似于数组。
因为数组一旦创建大小不变,比如创建一个长度为3的数组,就只能存储3个元素,想要存储第4个元素就不行。而集合是大小可变的,想要存储几个元素就存储几个元素。
ArrayList
/**
目标:要求同学们掌握如何创建ArrayList集合的对象,并熟悉ArrayList提供的常用方法。
*/
public class ArrayListDemo1 {
public static void main(String[] args) {
// 1、创建一个ArrayList的集合对象
// ArrayList<String> list = new ArrayList<String>();
// 从jdk 1.7开始才支持的
ArrayList<String> list = new ArrayList<>();
list.add("黑马");
list.add("黑马");
list.add("Java");
System.out.println(list);
// 2、往集合中的某个索引位置处添加一个数据
list.add(1, "MySQL");
System.out.println(list);
// 3、根据索引获取集合中某个索引位置处的值
String rs = list.get(1);
System.out.println(rs);
// 4、获取集合的大小(返回集合中存储的元素个数)
System.out.println(list.size());
// 5、根据索引删除集合中的某个元素值,会返回被删除的元素值给我们
System.out.println(list.remove(1));
System.out.println(list);
// 6、直接删除某个元素值,删除成功会返回true,反之
System.out.println(list.remove("Java"));
System.out.println(list);
list.add(1, "html");
System.out.println(list);
// 默认删除的是第一次出现的这个黑马的数据的
System.out.println(list.remove("黑马"));
System.out.println(list);
// 7、修改某个索引位置处的数据,修改后会返回原来的值给我们
System.out.println(list.set(1, "黑马程序员"));
System.out.println(list);
}
}
应用案例1
1.用户可以选购多个商品,可以创建一个ArrayList集合,存储这些商品
2.按照需求,如果用户选择了"枸杞"批量删除,应该删除包含"枸杞"的所有元素
1)这时应该遍历集合中每一个String类型的元素
2)使用String类的方法contains判断字符串中是否包含"枸杞"
3)包含就把元素删除
3.输出集合中的元素,看是否包含"枸杞"的元素全部删除
public class ArrayListTest2 {
public static void main(String[] args) {
// 1、创建一个ArrayList集合对象
ArrayList<String> list = new ArrayList<>();
list.add("枸杞");
list.add("Java入门");
list.add("宁夏枸杞");
list.add("黑枸杞");
list.add("人字拖");
list.add("特级枸杞");
list.add("枸杞子");
System.out.println(list);
//运行结果如下: [Java入门, 宁夏枸杞, 黑枸杞, 人字拖, 特级枸杞, 枸杞子]
// 2、开始完成需求:从集合中找出包含枸杞的数据并删除它
for (int i = 0; i < list.size(); i++) {
// i = 0 1 2 3 4 5
// 取出当前遍历到的数据
String ele = list.get(i);
// 判断这个数据中包含枸杞
if(ele.contains("枸杞")){
// 直接从集合中删除该数据
list.remove(ele);
}
}
System.out.println(list);
//删除后结果如下:[Java入门, 黑枸杞, 人字拖, 枸杞子]
}
}
运行完上面代码,我们会发现,删除后的集合中,竟然还有黑枸杞,枸杞子在集合中。这是为什么呢?
解决方法:
集合删除元素方式一:每次删除完元素后,让控制循环的变量i--就可以了;
// 方式一:每次删除一个数据后,就让i往左边退一步
for (int i = 0; i < list.size(); i++) {
// i = 0 1 2 3 4 5
// 取出当前遍历到的数据
String ele = list.get(i);
// 判断这个数据中包含枸杞
if(ele.contains("枸杞")){
// 直接从集合中删除该数据
list.remove(ele);
i--;
}
}
System.out.println(list);
- 集合删除元素方式二:倒着遍历集合,在遍历过程中删除元素就可以了
// 方式二:从集合的后面倒着遍历并删除
// [Java入门, 人字拖]
// i
for (int i = list.size() - 1; i >= 0; i--) {
// 取出当前遍历到的数据
String ele = list.get(i);
// 判断这个数据中包含枸杞
if(ele.contains("枸杞")){
// 直接从集合中删除该数据
list.remove(ele);
}
}
System.out.println(list);
应用案例2
上一个ArrayList应用案例中,我们往集合存储的元素是String类型的元素,实际上在工作中我们经常往集合中自定义存储对象。
分析需求发现:
- 在外卖系统中,每一份菜都包含,菜品的名称、菜品的原价、菜品的优惠价、菜品的其他信息。那我们就可以定义一个菜品类(Food类),用来描述每一个菜品对象要封装那些数据。
- 接着再写一个菜品管理类(FoodManager类),提供展示操作界面、上架菜品、浏览菜品的功能。
- 首先我们先定义一个菜品类(Food类),用来描述每一个菜品对象要封装那些数据。
public class Food {
private String name; //菜品名称
private double originalPrice; //菜品原价
private double specialPrice; //菜品优惠价
private String info; //菜品其他信息
public Food() {
}
public Food(String name, double originalPrice, double specialPrice, String info) {
this.name = name;
this.originalPrice = originalPrice;
this.specialPrice = specialPrice;
this.info = info;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getOriginalPrice() {
return originalPrice;
}
public void setOriginalPrice(double originalPrice) {
this.originalPrice = originalPrice;
}
public double getSpecialPrice() {
return specialPrice;
}
public void setSpecialPrice(double specialPrice) {
this.specialPrice = specialPrice;
}
public String getInfo() {
return info;
}
public void setInfo(String info) {
this.info = info;
}
}
- 接下来写一个菜品管理类,提供上架菜品的功能、浏览菜品的功能、展示操作界面的功能。
public class FoodManager{
//为了存储多个菜品,预先创建一个ArrayList集合;
//上架菜品时,其实就是往集合中添加菜品对象
//浏览菜品时,其实就是遍历集合中的菜品对象,并打印菜品对象的属性信息。
private ArrayList<Food> foods = new ArrayList<>();
//为了在下面的多个方法中,能够使用键盘录入,提前把Scanner对象创建好;
private Scanner sc = new Scanner(System.in);
/**
1、商家上架菜品
*/
public void add(){
System.out.println("===菜品上架==");
// 2、提前创建一个菜品对象,用于封装用户上架的菜品信息
Food food = new Food();
System.out.println("请您输入上架菜品的名称:");
String name = sc.next();
food.setName(name);
System.out.println("请您输入上架菜品的原价:");
double originalPrice = sc.nextDouble();
food.setOriginalPrice(originalPrice);
System.out.println("请您输入上架菜品的优惠价:");
double specialPrice = sc.nextDouble();
food.setSpecialPrice(specialPrice);
System.out.println("请您输入上架菜品的其他信息:");
String info = sc.next();
food.setInfo(info);
// 3、把菜品对象添加到集合容器中去
foods.add(food);
System.out.println("恭喜您,上架成功~~~");
}
/**
2、菜品;浏览功能
*/
public void printAllFoods(){
System.out.println("==当前菜品信息如下:==");
for (int i = 0; i < foods.size(); i++) {
Food food = foods.get(i);
System.out.println("菜品名称:" + food.getName());
System.out.println("菜品原价:" + food.getOriginalPrice());
System.out.println("菜品优惠价:" + food.getSpecialPrice());
System.out.println("其他描述信息:" + food.getInfo());
System.out.println("------------------------");
}
}
/**
3、专门负责展示系统界面的
*/
public void start(){
while (true) {
System.out.println("====欢迎进入商家后台管理系统=====");
System.out.println("1、上架菜品(add)");
System.out.println("2、浏览菜品(query)");
System.out.println("3、退出系统(exit)");
System.out.println("请您选择操作命令:");
String command = sc.next();
switch (command) {
case "add":
add();
break;
case "query":
printAllFoods();
break;
case "exit":
return; // 结束当前方法!
default:
System.out.println("您输入的操作命令有误~~");
}
}
}
}
- 最后在写一个测试类Test,在测试类中进行测试。其实测试类,只起到一个启动程序的作用。
public class Test {
public static void main(String[] args) {
FoodManager manager = new FoodManager();
manager.start();
}
}
ArrayList 源码
成员变量
构造函数
public ArrayList(int initialCapacity) 带初始化容量的构造函数
public ArrayList() 无参构造函数,默认创建空集合
public ArrayList(Collection<? extends E> c) 将collection对象转换成数组,然后将数组的地址的赋给elementData
关键方法
第1次:10-0 > 0 扩容
第2次-10次:10-10 = 0 扩容
第11次:11-10 > 0 扩容
size表示的是元素个数,elementdata是第一次扩容的长度为10的数组,length是数组长度
ArrayList 的扩容机制
Collection代表单列集合,每个元素(数据)只包含一个值。
Map代表双列集合,每个元素包含两个值(键值对)。

- List系列集合:添加的元素是有序、可重复、有索引。
- Set系列集合:添加的元素是无序、不重复、无索引。
ArrayList底层是如何实现的?
底层数据结构:ArrayList底层是用动态的数组实现的
初始容量:ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
扩容逻辑:ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
添加逻辑:
u确保数组已使用长度(size)加1之后足够存下下一个数据
u计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍)
u确保新增的数据有地方存储之后,则将新元素添加到位于size的位置上。
u返回添加成功布尔值。
ArrayList list=new ArrayList(10)中的list扩容几次
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
是new了一个ArrarList并且给了一个构造参数10,对吧?
好的,在ArrayList的源码中提供了一个带参数的构造方法,这个参数就是 指定的集合初始长度,所以给了一个10的参数,就是指定了集合的初始长度是10,这里面并没有扩容。
如何实现数组和List之间的转换
面试官:如何实现数组和List之间的转换
*//**数组转**List
\* public static void testArray2List(){
String[] strs = {"aaa","bbb","ccc"};
List<String> list = Arrays.*asList*(strs);
for (String s : list) {
System.*out*.println(s);
}
}
*//List**转数组
\* public static void testList2Array(){
List<String> list = new ArrayList<String>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
String[] array = list.toArray(new String[list.size()]);
for (String s : array) {
System.*out*.println(s);
}
}
- 数组转List ,使用JDK中java.util.Arrays工具类的asList方法
- List转数组,使用List的toArray方法。无参toArray方法返回 Object数组,传入初始化长度的数组对象,返回该对象数组
面试官:用Arrays.asList转List后,如果修改了数组内容,list受影响吗?
List 用toArray转数组后,如果修改了List内容,数组受影响吗
候选人: Arrays.asList转换list之后,如果修改了数组的内容,list会受影响,因为它的底层使用的Arrays类中的一个内部类ArrayList来构造的集合,在这个集合的构造器中,把我们传入的这个集合进行了包装而已,最终指向的都是同一个 内存地址
list用了toArray转数组后,如果修改了list内容,数组不会影响,当调用了 toArray以后,在底层是它是进行了数组的拷贝,跟原来的元素就没啥关系 了,所以即使list修改了以后,数组也不受影响
从线程安全来说,ArrayList和LinkedList都不是线程安全的
面试官:嗯,好的,刚才你说了ArrayList 和 LinkedList 不是线程安全的,你 们在项目中是如何解决这个的线程安全问题的?
候选人:主要有两种解决方案:
第一:我们使用这个集合,优先在方法内使用,定义为局部变量,这样的话,就不会出现线程安全问题。
第二:如果非要在成员变量中使用的话,可以使用线程安全的集合来替代,
ArrayList可以通过Collections 的 synchronizedList 方法将 ArrayList 转换成线程安全的容器后再使用。
LinkedList 换成ConcurrentLinkedQueue来使用
Collection集合的常用方法
这里我们以创建ArrayList为例,来演示
Collection<String> c = new ArrayList<>();
//1.public boolean add(E e): 添加元素到集合
c.add("java1");
c.add("java1");
c.add("java2");
c.add("java2");
c.add("java3");
System.out.println(c); //打印: [java1, java1, java2, java2, java3]
//2.public int size(): 获取集合的大小
System.out.println(c.size()); //5
//3.public boolean contains(Object obj): 判断集合中是否包含某个元素
System.out.println(c.contains("java1")); //true
System.out.println(c.contains("Java1")); //false
//4.pubilc boolean remove(E e): 删除某个元素,如果有多个重复元素只能删除第一个
System.out.println(c.remove("java1")); //true
System.out.println(c); //打印: [java1,java2, java2, java3]
//5.public void clear(): 清空集合的元素
c.clear();
System.out.println(c); //打印:[]
//6.public boolean isEmpty(): 判断集合是否为空 是空返回true 反之返回false
System.out.println(c.isEmpty()); //true
//7.public Object[] toArray(): 把集合转换为数组
Object[] array = c.toArray();
System.out.println(Arrays.toString(array)); //[java1,java2, java2, java3]
//8.如果想把集合转换为指定类型的数组,可以使用下面的代码
String[] array1 = c.toArray(new String[c.size()]);
System.out.println(Arrays.toString(array1)); //[java1,java2, java2, java3]
//9.还可以把一个集合中的元素,添加到另一个集合中
Collection<String> c1 = new ArrayList<>();
c1.add("java1");
c1.add("java2");
Collection<String> c2 = new ArrayList<>();
c2.add("java3");
c2.add("java4");
c1.addAll(c2); //把c2集合中的全部元素,添加到c1集合中去
System.out.println(c1); //[java1, java2, java3, java4]
Collection遍历方式
“集合的遍历之前不是学过吗?就用普通的for循环啊? “ 但是之前学习过的遍历方式,只能遍历List集合,不能遍历Set集合,因为以前的普通for循环遍历需要索引,只有List集合有索引,而Set集合没有索引。
所以我们需要有一种通用的遍历方式,能够遍历所有集合。
迭代器遍历集合
代码写法如下:
Collection<String> c = new ArrayList<>();
c.add("赵敏");
c.add("小昭");
c.add("素素");
c.add("灭绝");
System.out.println(c); //[赵敏, 小昭, 素素, 灭绝]
//第一步:先获取迭代器对象
//解释:Iterator就是迭代器对象,用于遍历集合的工具)
Iterator<String> it = c.iterator();
//第二步:用于判断当前位置是否有元素可以获取
//解释:hasNext()方法返回true,说明有元素可以获取;反之没有
while(it.hasNext()){
//第三步:获取当前位置的元素,然后自动指向下一个元素.
String e = it.next();
System.out.println(s);
}
增强for遍历集合
相比于迭代器遍历集合,增强for循环更为简洁。
格式
for(元素的数据类型 变量名:数组或者集合){
}
Collection<String> c = new ArrayList<>();
c.add("赵敏");
c.add("小昭");
c.add("素素");
c.add("灭绝");
//1.使用增强for遍历集合
for(String s: c){
System.out.println(s);
}
//2.再尝试使用增强for遍历数组
String[] arr = {"迪丽热巴", "古力娜扎", "稀奇哈哈"};
for(String name: arr){
System.out.println(name);
}
forEach遍历集合
在JDK8版本以后还提供了一个forEach方法也可以遍历集合。
遍历集合案例

首先,我们得写一个电影类,用来描述每一步电影应该有哪些信息。
public class Movie{
private String name; //电影名称
private double score; //评分
private String actor; //演员
//无参数构造方法
public Movie(){}
//全参数构造方法
public Movie(String name, double score, String actor){
this.name=name;
this.score=score;
this.actor=actor;
}
//...get、set、toString()方法自己补上..
}
再创建一个测试类
public class Test{
public static void main(String[] args){
Collection<Movie> movies = new ArrayList<>();
movies.add(new MOvie("《肖申克的救赎》", 9.7, "罗宾斯"));
movies.add(new MOvie("《霸王别姬》", 9.6, "张国荣、张丰毅"));
movies.add(new MOvie("《阿甘正传》", 9.5, "汤姆汉克斯"));
for(Movie movie : movies){
System.out.println("电影名:" + movie.getName());
System.out.println("评分:" + movie.getScore());
System.out.println("主演:" + movie.getActor());
}
}
}
以上代码的内存原理如下图所示:当往集合中存对象时,实际上存储的是对象的地址值
List系列集合
ArrayList和LinkedList区别:
List集合的常用方法
//1.创建一个ArrayList集合对象(有序、有索引、可以重复)
List<String> list = new ArrayList<>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("至尊宝");
list.add("牛夫人");
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]
//2.public void add(int index, E element): 在某个索引位置插入元素
list.add(2, "紫霞仙子");
System.out.println(list); //[蜘蛛精, 至尊宝, 紫霞仙子, 至尊宝, 牛夫人]
//3.public E remove(int index): 根据索引删除元素, 返回被删除的元素
System.out.println(list.remove(2)); //紫霞仙子
System.out.println(list);//[蜘蛛精, 至尊宝, 至尊宝, 牛夫人]
//4.public E get(int index): 返回集合中指定位置的元素
System.out.println(list.get(3));
//5.public E set(int index, E e): 修改索引位置处的元素,修改后,会返回原数据
System.out.println(list.set(3,"牛魔王")); //牛夫人
System.out.println(list); //[蜘蛛精, 至尊宝, 至尊宝, 牛魔王]
List集合的遍历方式
List集合相比于前面的Collection多了一种可以通过索引遍历的方式,所以List集合遍历方式一共有四种:
- 普通for循环(只因为List有索引)
- 迭代器
- 增强for
- Lambda表达式
List<String> list = new ArrayList<>();
list.add("蜘蛛精");
list.add("至尊宝");
list.add("糖宝宝");
//1.普通for循环
for(int i = 0; i< list.size(); i++){
//i = 0, 1, 2
String e = list.get(i);
System.out.println(e);
}
//2.增强for遍历
for(String s : list){
System.out.println(s);
}
//3.迭代器遍历
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
//4.lambda表达式遍历
list.forEach(s->System.out.println(s));
ArrayList底层的原理
ArrayList集合底层是基于数组结构实现的,也就是说当你往集合容器中存储元素时,底层本质上是往数组中存储元素。

我们知道数组的长度是固定的,但是集合的长度是可变的,这是怎么做到的呢?原理如下:

数组扩容,并不是在原数组上扩容(原数组是不可以扩容的),底层是创建一个新数组,然后把原数组中的元素全部复制到新数组中去。
LinkedList底层原理
LinkedList底层是链表结构,链表结构是由一个一个的节点组成,一个节点由数据值、下一个元素的地址组成。

LinkedList集合是基于双向链表实现了,所以相对于ArrayList新增了一些可以针对头尾进行操作的方法,如下图示所示:

LinkedList集合的应用场景
可以用它来设计栈结构、队列结构。
入队列可以调用LinkedList集合的addLast方法,出队列可以调用removeFirst()方法.
//1.创建一个队列:先进先出、后进后出
LinkedList<String> queue = new LinkedList<>();
//入对列
queue.addLast("第1号人");
queue.addLast("第2号人");
queue.addLast("第3号人");
queue.addLast("第4号人");
System.out.println(queue);
//出队列
System.out.println(queue.removeFirst()); //第4号人
System.out.println(queue.removeFirst()); //第3号人
System.out.println(queue.removeFirst()); //第2号人
System.out.println(queue.removeFirst()); //第1号人
我们再用LinkedList集合来模拟一下栈结构的效果。
接着,我们就用LinkedList来模拟下栈结构,代码如下:
//1.创建一个栈对象
LinkedList<String> stack = new ArrayList<>();
//压栈(push) 等价于 addFirst()
stack.push("第1颗子弹");
stack.push("第2颗子弹");
stack.push("第3颗子弹");
stack.push("第4颗子弹");
System.out.println(stack); //[第4颗子弹, 第3颗子弹, 第2颗子弹,第1颗子弹]
//弹栈(pop) 等价于 removeFirst()
System.out.println(statck.pop()); //第4颗子弹
System.out.println(statck.pop()); //第3颗子弹
System.out.println(statck.pop()); //第2颗子弹
System.out.println(statck.pop()); //第1颗子弹
//弹栈完了,集合中就没有元素了
System.out.println(list); //[]
Array和ArrayList有何区别?什么时候更适合用Array?
Array可以容纳基本类型和对象,而ArrayList只能容纳对象。
Array是指定大小的,而ArrayList大小可自动扩容。
Array可以通过索引访问元素,访问速度很快,是常数时间复杂度(O(1))。
尽管ArrayList明显是更好的选择,但也有些时候Array比较好用,比如下面的三种情况。
- 如果列表的大小已经指定,大部分情况下是存储和遍历它们
- 对于遍历基本数据类型,尽管Collections使用自动装箱来减轻编码任务,在指定大小的基本类型的列表上工作也会变得很慢。
- 如果你要使用多维数组,使用[][][] []List会方便。
- 如果需要频繁地进行插入、删除或者搜索元素,且不关心内存占用,使用 ArrayList 更加方便。
- 如果需要更高效地访问元素,并且元素数量是固定的,可以使用数组。数组的访问速度比 ArrayList 更快,因为数组中的元素是连续存储的,而 ArrayList 中的元素可能是分散存储的。
综上所述,Array 适用于固定大小的元素集合,需要高效访问元素的场景,而 ArrayList 适用于动态大小的元素集合,需要频繁进行插入、删除或搜索元素的场景。
ArrayList和LinkedList区别
底层数据结构:
- ArrayList 的底层实现是动态数组,它使用数组来存储元素。因此,ArrayList 对元素的随机访问速度很快,时间复杂度为 O(1)。
- LinkedList 的底层实现是双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别),每个节点都包含对前一个节点和后一个节点的引用。因此,LinkedList 在插入和删除操作上比较快,时间复杂度为 O(1),但是在随机访问时效率较低,时间复杂度为 O(n)。
内存占用:
- ArrayList 在内存中是连续存储的,因此它的内存占用相对较小。
- LinkedList 中的每个节点都需要额外的空间来存储对前一个节点和后一个节点的引用,因此它的内存占用相对较大。
ArrayList的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
性能特征:
-
ArrayList 适用于需要频繁访问列表元素的场景,因为它支持高效的随机访问。
LinkedList采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),时间复杂度为 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。 -
LinkedList 适用于需要频繁进行插入、删除操作的场景,因为它对插入和删除操作有较好的性能。
操作数据效率:
- ArrayList按照下标查询的时间复杂度O(1)【内存是连续的,根据寻址公 式】, LinkedList不支持下标查询
- 查找(未知索引): ArrayList需要遍历,链表也需要链表,时间复杂度都 是O(n)
- ArrayList尾部插入和删除,时间复杂度是O(1);其他部分增删需要挪动 数组,时间复杂度是O(n)
- LinkedList头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
线程安全
-
ArrayList和LinkedList都不是线程安全的
-
如果需要保证线程安全,有两种方案:‘
在方法内使用,局部变量则是线程安全的
使用线程安全的ArrayList和LinkedList
综上所述,如果需要频繁访问列表元素或者列表的大小是固定的,可以使用 ArrayList。如果需要频繁进行插入、删除操作,或者列表的大小不确定,可以考虑使用 LinkedList。
我们在项目中一般是不会使用到 LinkedList 的,需要用到 LinkedList 的场景几乎都可以使用 ArrayList 来代替,并且,性能通常会更好!就连 LinkedList 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 LinkedList 。
另外,不要下意识地认为 LinkedList 作为链表就最适合元素增删的场景。LinkedList 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的平均时间复杂度都是 O(n) 。
Set系列集合
//Set<Integer> set = new HashSet<>(); //无序、无索引、不重复
//Set<Integer> set = new LinkedHashSet<>(); //有序、无索引、不重复
Set<Integer> set = new TreeSet<>(); //可排序(升序)、无索引、不重复
set.add(666);
set.add(555);
set.add(555);
set.add(888);
set.add(888);
set.add(777);
set.add(777);
System.out.println(set); //[555, 666, 777, 888]
HashSet集合底层原理
HashSet集合底层是基于哈希表实现的,哈希表根据JDK版本的不同,也是有点区别的
- JDK8以前:哈希表 = 数组+链表
- JDK8以后:哈希表 = 数组+链表+红黑树

- 只有新添加元素的hashCode值和集合中以后元素的hashCode值相同、新添加的元素调用equals方法和集合中已有元素比较结果为true, 才认为元素重复。
- 如果hashCode值相同,equals比较不同,则以链表的形式连接在数组的同一个索引为位置(如上图所示)
在JDK8开始后,为了提高性能,当链表的长度超过8时,就会把链表转换为红黑树。
HashSet去重原理
要想保证在HashSet集合中没有重复元素,我们需要重写元素类的hashCode和equals方法。比如以下面的Student类为例,假设把Student类的对象作为HashSet集合的元素,想要让学生的姓名和年龄相同,就认为元素重复。
public class Student{
private String name; //姓名
private int age; //年龄
private double height; //身高
//无参数构造方法
public Student(){}
//全参数构造方法
public Student(String name, int age, double height){
this.name=name;
this.age=age;
this.height=height;
}
//...get、set、toString()方法自己补上..
//按快捷键生成hashCode和equals方法
//alt+insert 选择 hashCode and equals
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
if (age != student.age) return false;
if (Double.compare(student.height, height) != 0) return false;
return name != null ? name.equals(student.name) : student.name == null;
}
@Override
public int hashCode() {
int result;
long temp;
result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
temp = Double.doubleToLongBits(height);
result = 31 * result + (int) (temp ^ (temp >>> 32));
return result;
}
}
接着,写一个测试类,往HashSet集合中存储Student对象。
public class Test{
public static void main(String[] args){
Set<Student> students = new HashSet<>();
Student s1 = new Student("至尊宝",20, 169.6);
Student s2 = new Student("蜘蛛精",23, 169.6);
Student s3 = new Student("蜘蛛精",23, 169.6);
Student s4 = new Student("牛魔王",48, 169.6);
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
for(Student s : students){
System.out.println(s);
}
}
}
打印结果如下,我们发现存了两个蜘蛛精,当时实际打印出来只有一个,而且是无序的。
Student{name='牛魔王', age=48, height=169.6}
Student{name='至尊宝', age=20, height=169.6}
Student{name='蜘蛛精', age=23, height=169.6}
LinkedHashSet底层原理
LinkedHashSet它底层采用的是也是哈希表结构,只不过额外新增了一个双向链表来维护元素的存取顺序。

TreeSet集合
TreeSet集合的特点是可以对元素进行排序,但是必须指定元素的排序规则。
如果往集合中存储String类型的元素,或者Integer类型的元素,它们本身就具备排序规则,所以直接就可以排序。
Set<Integer> set1= new TreeSet<>();
set1.add(8);
set1.add(6);
set1.add(4);
set1.add(3);
set1.add(7);
set1.add(1);
set1.add(5);
set1.add(2);
System.out.println(set1); //[1,2,3,4,5,6,7,8]
Set<Integer> set2= new TreeSet<>();
set2.add("a");
set2.add("c");
set2.add("e");
set2.add("b");
set2.add("d");
set2.add("f");
set2.add("g");
System.out.println(set1); //[a,b,c,d,e,f,g]
如果往TreeSet集合中存储自定义类型的元素,比如说Student类型,则需要我们自己指定排序规则,否则会出现异常。
我们想要告诉TreeSet集合按照指定的规则排序,有两种办法:
第一种:让元素的类实现Comparable接口,重写compareTo方法
第二种:在创建TreeSet集合时,通过构造方法传递Compartor比较器对象
- 排序方式1:我们先来演示第一种排序方式
//第一步:先让Student类,实现Comparable接口
//注意:Student类的对象是作为TreeSet集合的元素的
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
//无参数构造方法
public Student(){}
//全参数构造方法
public Student(String name, int age, double height){
this.name=name;
this.age=age;
this.height=height;
}
//...get、set、toString()方法自己补上..
//第二步:重写compareTo方法
//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。
/*
原理:
在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的
结果是正数、负数、还是零,决定元素放在后面、前面还是不存。
*/
@Override
public int compareTo(Student o) {
//this:表示将要添加进去的Student对象
//o: 表示集合中已有的Student对象
return this.age-o.age;
}
}
此时,再运行测试类,结果如下
Student{name='至尊宝', age=20, height=169.6}
Student{name='紫霞', age=20, height=169.8}
Student{name='蜘蛛精', age=23, height=169.6}
Student{name='牛魔王', age=48, height=169.6}
- 排序方式2:接下来演示第二种排序方式
//创建TreeSet集合时,传递比较器对象排序
/*
原理:当调用add方法时,底层会先用比较器,根据Comparator的compare方是正数、负数、还是零,决定谁在后,谁在前,谁不存。
*/
//下面代码中是按照学生的年龄升序排序
Set<Student> students = new TreeSet<>(new Comparator<Student>{
@Override
public int compare(Student o1, Student o2){
//需求:按照学生的身高排序
return Double.compare(o1,o2);
}
});
//创建4个Student对象
Student s1 = new Student("至尊宝",20, 169.6);
Student s2 = new Student("紫霞",23, 169.8);
Student s3 = new Student("蜘蛛精",23, 169.6);
Student s4 = new Student("牛魔王",48, 169.6);
//添加Studnet对象到集合
students.add(s1);
students.add(s2);
students.add(s3);
students.add(s4);
System.out.println(students);
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
HashSet、LinkedHashSet和TreeSet都是Set接口的实现类,都能保证元素唯一,并且都不是线程安全的。HashSet、LinkedHashSet和TreeSet的主要区别在于底层数据结构不同。HashSet的底层数据结构是哈希表(基于HashMap实现)。LinkedHashSet的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。- 底层数据结构不同又导致这三者的应用场景不同。
HashSet用于不需要保证元素插入和取出顺序的场景,LinkedHashSet用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet用于支持对元素自定义排序规则的场景。
总结Collection集合

并发修改异常
我们先把这个异常用代码演示出来,再解释一下为什么会有这个异常产生
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
System.out.println(list); // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]
//需求:找出集合中带"李"字的姓名,并从集合中删除
Iterator<String> it = list.iterator();
while(it.hasNext()){
String name = it.next();
if(name.contains("李")){
list.remove(name);
}
}
System.out.println(list);
运行上面的代码,会出现下面的异常。这就是并发修改异常

为什么会出现这个异常呢?那是因为迭代器遍历机制,规定迭代器遍历集合的同时,不允许集合自己去增删元素,否则就会出现这个异常。
怎么解决这个问题呢?不使用集合的删除方法,而是使用迭代器的删除方法,代码如下:
List<String> list = new ArrayList<>();
list.add("王麻子");
list.add("小李子");
list.add("李爱花");
list.add("张全蛋");
list.add("晓李");
list.add("李玉刚");
System.out.println(list); // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]
//需求:找出集合中带"李"字的姓名,并从集合中删除
Iterator<String> it = list.iterator();
while(it.hasNext()){
String name = it.next();
if(name.contains("李")){
//list.remove(name);
it.remove(); //当前迭代器指向谁,就删除谁
}
}
System.out.println(list);
Collection的其他操作
可变参数
-
可变参数就算你学明白了。
-
可变参数是一种特殊的形式参数,定义在方法、构造器的形参列表处,它可以让方法接收多个同类型的实际参数。
-
可变参数在方法内部,本质上是一个数组。
-
public class ParamTest{
public static void main(String[] args){
//不传递参数,下面的nums长度则为0, 打印元素是[]
test();
//传递3个参数,下面的nums长度为3,打印元素是[10, 20, 30]
test(10,20,30);
//传递一个数组,下面数组长度为4,打印元素是[10,20,30,40]
int[] arr = new int[]{10,20,30,40}
test(arr);
}
public static void test(int...nums){
//可变参数在方法内部,本质上是一个数组
System.out.println(nums.length);
System.out.println(Arrays.toString(nums));
System.out.println("----------------");
}
}
最后还有一些错误写法:
一个形参列表中,只能有一个可变参数;否则会报错
一个形参列表中如果多个参数,可变参数需要写在最后;否则会报错

Collections工具类
注意Collections并不是集合,它比Collection多了一个s,一般后缀为s的类很多都是工具类。这里的Collections是用来操作Collection的工具类。
我们把这些方法用代码来演示一下:
public class CollectionsTest{
public static void main(String[] args){
//1.public static <T> boolean addAll(Collection<? super T> c, T...e)
List<String> names = new ArrayList<>();
Collections.addAll(names, "张三","王五","李四", "张麻子");
System.out.println(names);
//2.public static void shuffle(List<?> list):对集合打乱顺序
Collections.shuffle(names);
System.out.println(names);
//3.public static <T> void sort(List<T list): 对List集合排序
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(5);
list.add(2);
Collections.sort(list);
System.out.println(list);
}
}
上面我们往集合中存储的元素要么是Stirng类型,要么是Integer类型,他们本来就有一种自然顺序所以可以直接排序。但是如果我们往List集合中存储Student对象,这个时候想要对List集合进行排序自定义比较规则的。指定排序规则有两种方式,如下:
排序方式1:让元素实现Comparable接口,重写compareTo方法
比如现在想要往集合中存储Studdent对象,首先需要准备一个Student类,实现Comparable接口。
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
//排序时:底层会自动调用此方法,this和o表示需要比较的两个对象
@Override
public int compareTo(Student o){
//需求:按照年龄升序排序
//如果返回正数:说明左边对象的年龄>右边对象的年龄
//如果返回负数:说明左边对象的年龄<右边对象的年龄,
//如果返回0:说明左边对象的年龄和右边对象的年龄相同
return this.age - o.age;
}
//...getter、setter、constructor..
}
然后再使用Collections.sort(list集合)对List集合排序,如下:
//3.public static <T> void short(List<T list): 对List集合排序
List<Student> students = new ArrayList<>();
students.add(new Student("蜘蛛精",23,169.7));
students.add(new Student("紫霞",22,169.8));
students.add(new Student("紫霞",22,169.8));
students.add(new Student("至尊宝",26,169.5));
/*
原理:sort方法底层会遍历students集合中的每一个元素,采用排序算法,将任意两个元素两两比较;
每次比较时,会用一个Student对象调用compareTo方法和另一个Student对象进行比较;
根据compareTo方法返回的结果是正数、负数,零来决定谁大,谁小,谁相等,重新排序元素的位置
注意:这些都是sort方法底层自动完成的,想要完全理解,必须要懂排序算法才行;
*/
Collections.sort(students);
System.out.println(students);
排序方式2:使用调用sort方法是,传递比较器
/*
原理:sort方法底层会遍历students集合中的每一个元素,采用排序算法,将任意两个元素两两比较;
每次比较,会将比较的两个元素传递给Comparator比较器对象的compare方法的两个参数o1和o2,
根据compare方法的返回结果是正数,负数,或者0来决定谁大,谁小,谁相等,重新排序元素的位置
注意:这些都是sort方法底层自动完成的,不需要我们完全理解,想要理解它必须要懂排序算法才行.
*/
Collections.sort(students, new Comparator<Student>(){
@Override
public int compare(Student o1, Student o2){
return o1.getAge()-o2.getAge();
}
});
System.out.println(students);
Map集合
所有的Map集合有如下的特点:键不能重复,值可以重复,每一个键只能找到自己对应的值。
public class MapTest1 {
public static void main(String[] args) {
// Map<String, Integer> map = new HashMap<>(); // 一行经典代码。 按照键 无序,不重复,无索引。
Map<String, Integer> map = new LinkedHashMap<>(); // 有序,不重复,无索引。
map.put("手表", 100);
map.put("手表", 220); // 后面重复的数据会覆盖前面的数据(键)
map.put("手机", 2);
map.put("Java", 2);
map.put(null, null);
System.out.println(map);
Map<Integer, String> map1 = new TreeMap<>(); // 可排序,不重复,无索引
map1.put(23, "Java");
map1.put(23, "MySQL");
map1.put(19, "李四");
map1.put(20, "王五");
System.out.println(map1);
}
}
Map集合的常用方法
学习一下Map集合提供了那些方法供我们使用。由于Map是所有双列集合的父接口,所以我们只需要学习Map接口中每一个方法是什么含义,那么所有的Map集合方法你就都会用了。
public class MapTest2 {
public static void main(String[] args) {
// 1.添加元素: 无序,不重复,无索引。
Map<String, Integer> map = new HashMap<>();
map.put("手表", 100);
map.put("手表", 220);
map.put("手机", 2);
map.put("Java", 2);
map.put(null, null);
System.out.println(map);
// map = {null=null, 手表=220, Java=2, 手机=2}
// 2.public int size():获取集合的大小
System.out.println(map.size());
// 3、public void clear():清空集合
//map.clear();
//System.out.println(map);
// 4.public boolean isEmpty(): 判断集合是否为空,为空返回true ,反之!
System.out.println(map.isEmpty());
// 5.public V get(Object key):根据键获取对应值
int v1 = map.get("手表");
System.out.println(v1);
System.out.println(map.get("手机")); // 2
System.out.println(map.get("张三")); // null
// 6. public V remove(Object key):根据键删除整个元素(删除键会返回键的值)
System.out.println(map.remove("手表"));
System.out.println(map);
// 7.public boolean containsKey(Object key): 判断是否包含某个键 ,包含返回true ,反之
System.out.println(map.containsKey("手表")); // false
System.out.println(map.containsKey("手机")); // true
System.out.println(map.containsKey("java")); // false
System.out.println(map.containsKey("Java")); // true
// 8.public boolean containsValue(Object value): 判断是否包含某个值。
System.out.println(map.containsValue(2)); // true
System.out.println(map.containsValue("2")); // false
// 9.public Set<K> keySet(): 获取Map集合的全部键。
Set<String> keys = map.keySet();
System.out.println(keys);
// 10.public Collection<V> values(); 获取Map集合的全部值。
Collection<Integer> values = map.values();
System.out.println(values);
// 11.把其他Map集合的数据倒入到自己集合中来。(拓展)
Map<String, Integer> map1 = new HashMap<>();
map1.put("java1", 10);
map1.put("java2", 20);
Map<String, Integer> map2 = new HashMap<>();
map2.put("java3", 10);
map2.put("java2", 222);
map1.putAll(map2); // putAll:把map2集合中的元素全部倒入一份到map1集合中去。
System.out.println(map1);
System.out.println(map2);
}
}
Map集合遍历方式1
/**
* 目标:掌握Map集合的遍历方式1:键找值
*/
public class MapTest1 {
public static void main(String[] args) {
// 准备一个Map集合。
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 162.5);
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map);
// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
// 1、获取Map集合的全部键
Set<String> keys = map.keySet();
// System.out.println(keys);
// [蜘蛛精, 牛魔王, 至尊宝, 紫霞]
// key
// 2、遍历全部的键,根据键获取其对应的值
for (String key : keys) {
// 根据键获取对应的值
double value = map.get(key);
System.out.println(key + "=====>" + value);
}
}
}
Map集合遍历方式2
Map集合是用来存储键值对的,而每一个键值对实际上是一个Entry对象。
直接获取每一个Entry对象,把Entry存储扫Set集合中去,再通过Entry对象获取键和值。
/**
* 目标:掌握Map集合的第二种遍历方式:键值对。
*/
public class MapTest2 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map);
// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
// entries = [(蜘蛛精=169.8), (牛魔王=183.6), (至尊宝=169.5), (紫霞=165.8)]
// entry = (蜘蛛精=169.8)
// entry = (牛魔王=183.6)
// ...
// 1、调用Map集合提供entrySet方法,把Map集合转换成键值对类型的Set集合
Set<Map.Entry<String, Double>> entries = map.entrySet();
for (Map.Entry<String, Double> entry : entries) {
String key = entry.getKey();
double value = entry.getValue();
System.out.println(key + "---->" + value);
}
}
}
Map集合遍历方式3
Map集合的第三种遍历方式,需要用到下面的一个方法forEach,而这个方法是JDK8版本以后才有的。调用起来非常简单,最好是结合的lambda表达式一起使用。
/**
* 目标:掌握Map集合的第二种遍历方式:键值对。
*/
public class MapTest3 {
public static void main(String[] args) {
Map<String, Double> map = new HashMap<>();
map.put("蜘蛛精", 169.8);
map.put("紫霞", 165.8);
map.put("至尊宝", 169.5);
map.put("牛魔王", 183.6);
System.out.println(map);
// map = {蜘蛛精=169.8, 牛魔王=183.6, 至尊宝=169.5, 紫霞=165.8}
//遍历map集合,传递匿名内部类
map.forEach(new BiConsumer<String, Double>() {
@Override
public void accept(String k, Double v) {
System.out.println(k + "---->" + v);
}
});
//遍历map集合,传递Lambda表达式
map.forEach(( k, v) -> {
System.out.println(k + "---->" + v);
});
}
}
Map集合案例

先分析需求,再考虑怎么用代码实现
1.首先可以将80个学生选择的景点放到一个集合中去(也就是说,集合中的元素是80个任意的ABCD元素)
2.准备一个Map集合用来存储景点,以及景点被选择的次数
3.遍历80个学生选择景点的集合,得到每一个景点,判断Map集合中是否包含该景点
如果不包含,则存储"景点=1"
如果包含,则存获取该景点原先的值,再存储"景点=原来的值+1"; 此时新值会覆盖旧值
/**
* 目标:完成Map集合的案例:统计投票人数。
*/
public class MapDemo4 {
public static void main(String[] args) {
// 1、把80个学生选择的景点数据拿到程序中来。
List<String> data = new ArrayList<>();
String[] selects = {"A", "B", "C", "D"};
Random r = new Random();
for (int i = 1; i <= 80; i++) {
// 每次模拟一个学生选择一个景点,存入到集合中去。
int index = r.nextInt(4); // 0 1 2 3
data.add(selects[index]);
}
System.out.println(data);
// 2、开始统计每个景点的投票人数
// 准备一个Map集合用于统计最终的结果
Map<String, Integer> result = new HashMap<>();
// 3、开始遍历80个景点数据
for (String s : data) {
// 问问Map集合中是否存在该景点
if(result.containsKey(s)){
// 说明这个景点之前统计过。其值+1. 存入到Map集合中去
result.put(s, result.get(s) + 1);
}else {
// 说明这个景点是第一次统计,存入"景点=1"
result.put(s, 1);
}
}
System.out.println(result);
}
}
Map接口下面的是三个实现类HashMap、LinkedHashMap、TreeMap。
HashMap
往HashSet集合中添加元素时,实际上是把元素作为添加添加到了HashMap集合中。HashSet底层就是HashMap。
HashMap集合的特点是由键决定的: 它的键是无序、不能重复,而且没有索引的。
HashMap底层数据结构: 哈希表结构
JDK8之前的哈希表 = 数组+链表
JDK8之后的哈希表 = 数组+链表+红黑树
哈希表是一种增删改查数据,性能相对都较好的数据结构
往HashMap集合中键值对数据时,底层步骤如下
第1步:当你第一次往HashMap集合中存储键值对时,底层会创建一个长度为16的数组
第2步:把键然后将键和值封装成一个对象,叫做Entry对象
第3步:再根据Entry对象的键计算hashCode值(和值无关)
第4步:利用hashCode值和数组的长度做一个类似求余数的算法,会得到一个索引位置
第5步:判断这个索引的位置是否为null,如果为null,就直接将这个Entry对象存储到这个索引位置
如果不为null,则还需要进行第6步的判断
第6步:继续调用equals方法判断两个对象键是否相同
如果equals返回false,则以链表的形式往下挂
如果equals方法true,则认为键重复,此时新的键值对会替换就的键值对。
HashMap底层需要注意这几点:
1.底层数组默认长度为16,如果数组中有超过12个位置已经存储了元素,则会对数组进行扩容2倍
数组扩容的加载因子是0.75,意思是:16*0.75=12
2.数组的同一个索引位置有多个元素、并且在8个元素以内(包括8),则以链表的形式存储
JDK7版本:链表采用头插法(新元素往链表的头部添加)
JDK8版本:链表采用尾插法(新元素我那个链表的尾部添加)
3.数组的同一个索引位置有多个元素、并且超过了8个,则以红黑树形式存储
往Map集合中存储自定义对象作为键,为了保证键的唯一性,我们应该重写hashCode方法和equals方法。
HashMap 的底层实现/ 获取数据通过key的hash计算数组下标获取元素
JDK1.8之前采用的拉链法,数组+链表
JDK1.8之后采用数组+链表+红黑树,链表长度大于8且数组长度大于64则会从链表 转化为红黑树
将键(key)映射为数组下标的函数叫做散列函数。可以表示为:hashValue = hash(key)
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
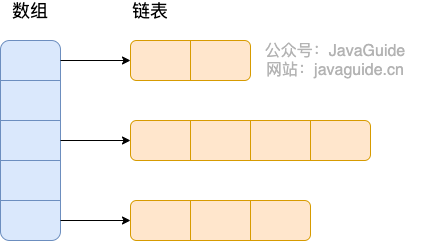
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
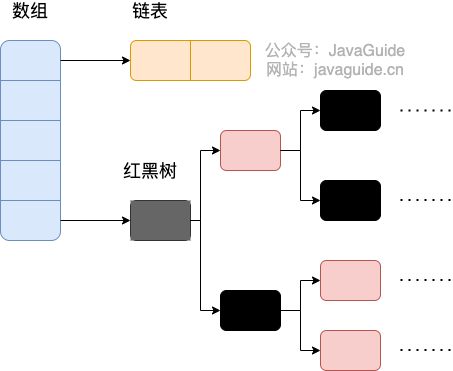
HashMap的jdk1.7和jdk1.8有什么区别
- JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建 一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的 值加到链表中即可。
- jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
我们来结合源码分析一下 HashMap 链表到红黑树的转换。
1、 putVal 方法中执行链表转红黑树的判断逻辑。
链表的长度大于 8 的时候,就执行 treeifyBin (转换红黑树)的逻辑。
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 遍历到链表最后一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表元素个数大于等于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 红黑树转换(并不会直接转换成红黑树)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
2、treeifyBin 方法中判断是否真的转换为红黑树。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 判断当前数组的长度是否小于 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 如果当前数组的长度小于 64,那么会选择先进行数组扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 否则才将列表转换为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树。
保证 HashMap 总是使用 2 的幂作为哈希表的大小
返回大于或等于给定目标容量 cap 的最小的2的幂
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
HashMap的put方法的具体流程
常见属性
static final int *DEFAULT_INITIAL_CAPACITY* = 1 << 4; *// aka 16 默认的初始容量
static final float *DEFAULT_LOAD_FACTOR* = 0.75f;// 默认的加载因子
transient HashMap.Node<K,V>[] table;
transient int size;
扩容阈值 == 数组容量 ***** 加载因子
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
HashMap是懒惰加载,在创建对象时并没有初始化数组
1. 判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
2. 根据键值key计算hash值得到数组索引
3. 判断table[i]==null,条件成立,直接新建节点添加
4. 如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
5. 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
HashMap的扩容机制
hashMap的寻址算法
hashmap在1.7情况下的多线程死循环问题
LinkedHashMap
LinkedHashMap集合的特点也是由键决定的:有序的、不重复、无索引。
/**
* 目标:掌握LinkedHashMap的底层原理。
*/
public class Test2LinkedHashMap {
public static void main(String[] args) {
// Map<String, Integer> map = new HashMap<>(); // 按照键 无序,不重复,无索引。
LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); // 按照键 有序,不重复,无索引。
map.put("手表", 100);
map.put("手表", 220);
map.put("手机", 2);
map.put("Java", 2);
map.put(null, null);
System.out.println(map);
}
}
- LinkedHashMap的底层原理,和LinkedHashSet底层原理是一样的。底层多个一个双向链表来维护键的存储顺序。
取元素时,先取头节点元素,然后再依次取下一个几点,一直到尾结点。所以是有序的。

TreeMap
- TreeMap集合的特点也是由键决定的,默认按照键的升序排列,键不重复,也是无索引的。
TreeMap集合的底层原理和TreeSet也是一样的,底层都是红黑树实现的。所以可以对键进行排序。
比如往TreeMap集合中存储Student对象作为键,排序方法有两种。
排序方式1:写一个Student类,让Student类实现Comparable接口
//第一步:先让Student类,实现Comparable接口
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
//无参数构造方法
public Student(){}
//全参数构造方法
public Student(String name, int age, double height){
this.name=name;
this.age=age;
this.height=height;
}
//...get、set、toString()方法自己补上..
//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。
/*
原理:
在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的
结果是正数、负数、还是零,决定元素放在后面、前面还是不存。
*/
@Override
public int compareTo(Student o) {
//this:表示将要添加进去的Student对象
//o: 表示集合中已有的Student对象
return this.age-o.age;
}
}
排序方式2:在创建TreeMap集合时,直接传递Comparator比较器对象。
/**
* 目标:掌握TreeMap集合的使用。
*/
public class Test3TreeMap {
public static void main(String[] args) {
Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return Double.compare(o1.getHeight(), o2.getHeight());
}
});
// Map<Student, String> map = new TreeMap<>(( o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()));
map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");
map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");
map.put(new Student("至尊宝", 23, 163.5), "水帘洞");
map.put(new Student("牛魔王", 28, 183.5), "牛头山");
System.out.println(map);
}
}
这种方式都可以对TreeMap集合中的键排序。注意:只有TreeMap的键才能排序,HashMap键不能排序。
集合嵌套
就是把一个集合当做元素,存储到另一个集合中去,我们把这种用法称之为集合嵌套。

- 案例分析
1.从需求中我们可以看到,有三个省份,每一个省份有多个城市
我们可以用一个Map集合的键表示省份名称,而值表示省份有哪些城市
2.而又因为一个身份有多个城市,同一个省份的多个城市可以再用一个List集合来存储。
所以Map集合的键是String类型,而指是List集合类型
HashMap<String, List<String>> map = new HashMap<>();
- 代码如下
/**
* 目标:理解集合的嵌套。
* 江苏省 = "南京市","扬州市","苏州市“,"无锡市","常州市"
* 湖北省 = "武汉市","孝感市","十堰市","宜昌市","鄂州市"
* 河北省 = "石家庄市","唐山市", "邢台市", "保定市", "张家口市"
*/
public class Test {
public static void main(String[] args) {
// 1、定义一个Map集合存储全部的省份信息,和其对应的城市信息。
Map<String, List<String>> map = new HashMap<>();
List<String> cities1 = new ArrayList<>();
Collections.addAll(cities1, "南京市","扬州市","苏州市" ,"无锡市","常州市");
map.put("江苏省", cities1);
List<String> cities2 = new ArrayList<>();
Collections.addAll(cities2, "武汉市","孝感市","十堰市","宜昌市","鄂州市");
map.put("湖北省", cities2);
List<String> cities3 = new ArrayList<>();
Collections.addAll(cities3, "石家庄市","唐山市", "邢台市", "保定市", "张家口市");
map.put("河北省", cities3);
System.out.println(map);
List<String> cities = map.get("湖北省");
for (String city : cities) {
System.out.println(city);
}
map.forEach((p, c) -> {
System.out.println(p + "----->" + c);
});
}
}
HahMap和Hashtable的区别
HashMap 和 HashTable 都是 Java 中用于存储键值对的数据结构,但它们有一些重要的区别。
- 数据结构不一样,hashtable是数组+链表,hashmap在1.8之后改为了 数组+链表+红黑树
- hash算法不同,hashtable是用本地修饰的hashcode值,而hashmap经 常了二次hash
- 扩容方式不同,hashtable是当前容量翻倍+1,hashmap是当前容量翻倍
- hashtable是线程安全的,操作数据的时候加了锁synchronized, hashmap不是线程安全的,效率更高一些
- 在实际开中不建议使用HashTable,在多线程环境下可以使用 ConcurrentHashMap类
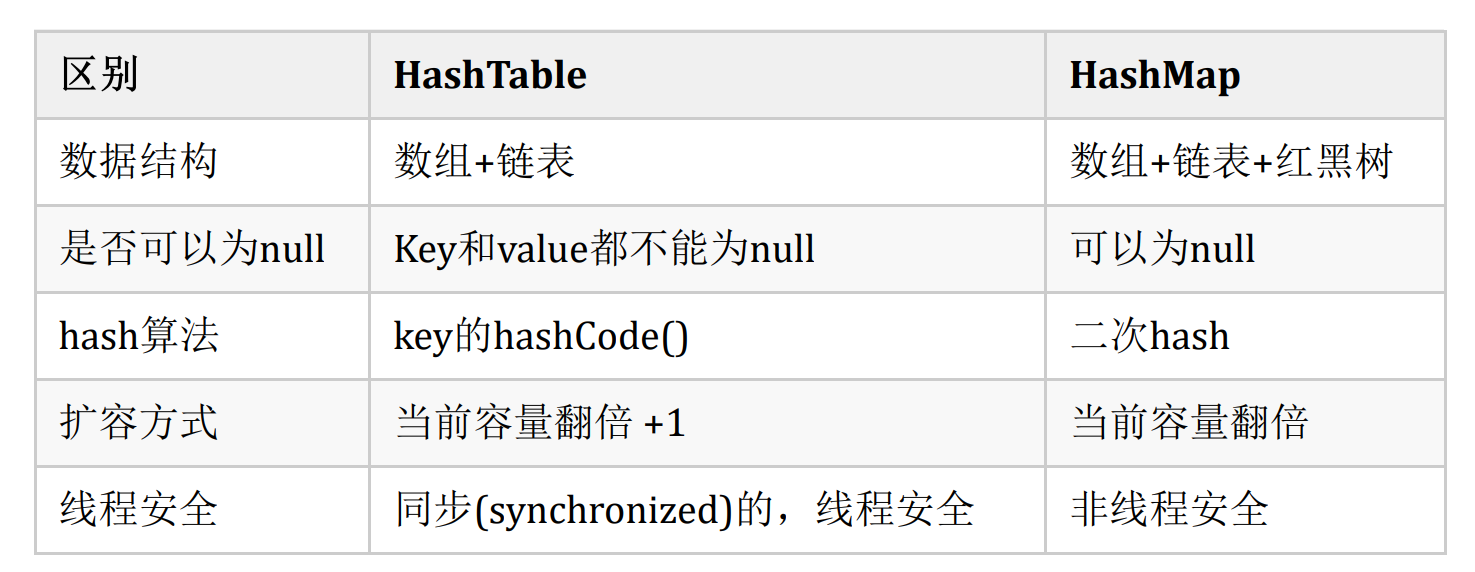
线程安全性:
- HashMap 是非线程安全的。多个线程可以同时访问和修改 HashMap,如果没有适当的同步措施,可能会导致数据不一致或竞争条件。如果多个线程同时访问一个
HashMap对象,并且至少有一个线程从结构上修改了映射,则它必须保持外部同步。 - HashTable 是线程安全的。多个线程可以共享同一个
Hashtable对象,而不会造成数据的不一致性。它的方法都被同步(synchronized)了,可以在多线程环境中使用,但这可能会降低性能。Hashtable是线程安全的,因为Hashtable内部的方法基本都经过synchronized修饰。 - (如果你要保证线程安全的话就使用
ConcurrentHashMap吧!)
允许空键和空值:
- HashMap 允许使用空(null)键和空(null)值。这意味着可以将 null 作为键或值存储在 HashMap 中。但 null 作为键只能有一个,null 作为值可以有多个.
- HashTable 不允许使用空(null)键或空(null)值。如果尝试存储空(null)键或空(null)值,会抛出 NullPointerException。
效率和性能:
- 由于 HashMap 不进行同步,适用于单线程环境,因此在性能上通常比 HashTable 更高效。
- HashTable 的同步操作可能导致性能下降,特别是在高并发环境下。
泛型支持:
- HashMap 支持泛型,可以指定键和值的类型。
- HashTable 不支持泛型,只能存储 Object 类型。
初始容量大小和每次扩充容量大小的不同:
① 创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的tableSizeFor()方法保证,下面给出了源代码)。也就是说 HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。Hashtable 没有这样的机制。
总的来说,如果在多线程环境下需要使用键值对存储,可以考虑使用 ConcurrentHashMap 来替代 HashTable,因为 ConcurrentHashMap 提供了更好的并发性能。在单线程环境下,通常首选使用 HashMap,因为它的性能更好。
HashMap和HashSet的区别
HashSet 底层就是基于 HashMap 实现的。
HashSet底层其实是用HashMap实现存储的, HashSet封装了一系列HashMap 的方法. 依靠HashMap来存储元素值,(利用hashMap的key键进行存储), 而 value值默认为Object对象. 所以HashSet也不允许出现重复值, 判断标准和 HashMap判断标准相同, 两个元素的hashCode相等并且通过equals()方法返回 true.
主要用途
- HashMap 是一个实现了
Map接口的集合,用于存储键值对(key-value pairs)。每个键映射到一个具体的值,键必须唯一。 - HashSet 是一个实现了
Set接口的集合,用于存储不重复的元素集合。它基本上使用HashMap实现,每个元素都作为键存储在底层的HashMap实例中,而值使用一个固定的对象标记(通常是PRESENT这个静态的Object对象)。

TreeSet和HashSet的区别
数据结构
- HashSet 基于哈希表实现,具体来说是通过一个
HashMap来实现的。它通过使用元素的哈希码来快速定位元素是否存在于集合中,从而优化了查找、添加和删除操作的速度。 - TreeSet 基于红黑树(一种自平衡的二叉查找树)实现,所有的元素都按照某种比较规则(自然排序或者根据
Comparator提供的排序规则)被排序存储。
性能
- HashSet 在添加、删除和查找元素时,提供了较为稳定的性能,理论上这些操作的时间复杂度是O(1),但实际性能取决于哈希函数的质量和集合的大小。
- TreeSet 添加、删除和查找操作的时间复杂度为O(log n),因为这些操作需要通过树结构进行。
用途
- HashSet 通常在不需要元素排序时使用,当你需要快速查找元素是否存在于集合中时,它是一个好选择。
- TreeSet 适用于需要有序集合的场景,例如,当你需要一个排序的唯一元素集合,或者需要频繁地进行有序操作(如查找范围内的元素)时。
ConcurrentHashMap
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的
ConcurrentHashMap底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable和 JDK1.8 之前的HashMap的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的; - 实现线程安全的方式(重要):
- 在 JDK1.7 的时候,
ConcurrentHashMap对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 - 到了 JDK1.8 的时候,
ConcurrentHashMap已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本; Hashtable(同一把锁) :使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
- 在 JDK1.7 的时候,
下面,我们再来看看两者底层数据结构的对比图。
Hashtable :
JDK1.7 的 ConcurrentHashMap :
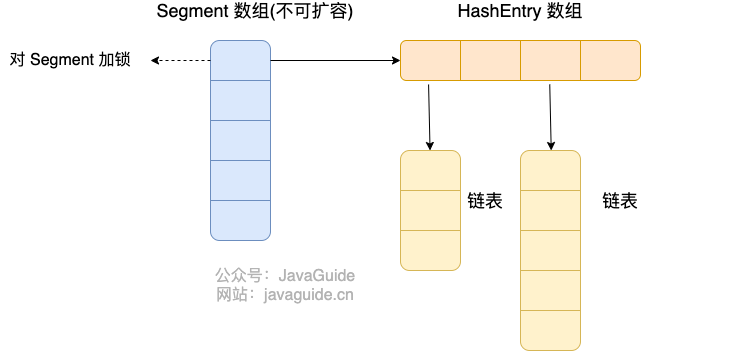
Java7 ConcurrentHashMap 存储结构
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 数组中的每个元素包含一个 HashEntry 数组,每个 HashEntry 数组属于链表结构。
JDK1.8 的 ConcurrentHashMap:
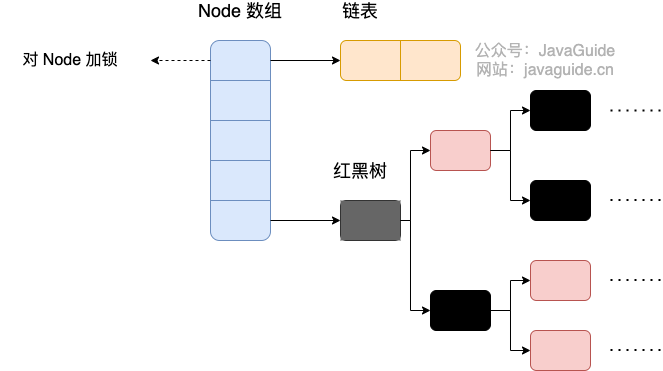
Java8 ConcurrentHashMap 存储结构
JDK1.8 的 ConcurrentHashMap 不再是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。
TreeNode是存储红黑树节点,被TreeBin包装。TreeBin通过root属性维护红黑树的根结点,因为红黑树在旋转的时候,根结点可能会被它原来的子节点替换掉,在这个时间点,如果有其他线程要写这棵红黑树就会发生线程不安全问题,所以在 ConcurrentHashMap 中TreeBin通过waiter属性维护当前使用这棵红黑树的线程,来防止其他线程的进入。
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
...
}
ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
JDK1.8 之前
数据结构:
Java7 ConcurrentHashMap 存储结构
首先将数据分为一段一段(这个“段”就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
-
一个
ConcurrentHashMap里包含一个Segment数组,Segment的个数一旦初始化就不能改变。Segment数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。 -
Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,当对HashEntry数组的数据进行修改时,必须首先获得对应的Segment的锁。
存储流程:
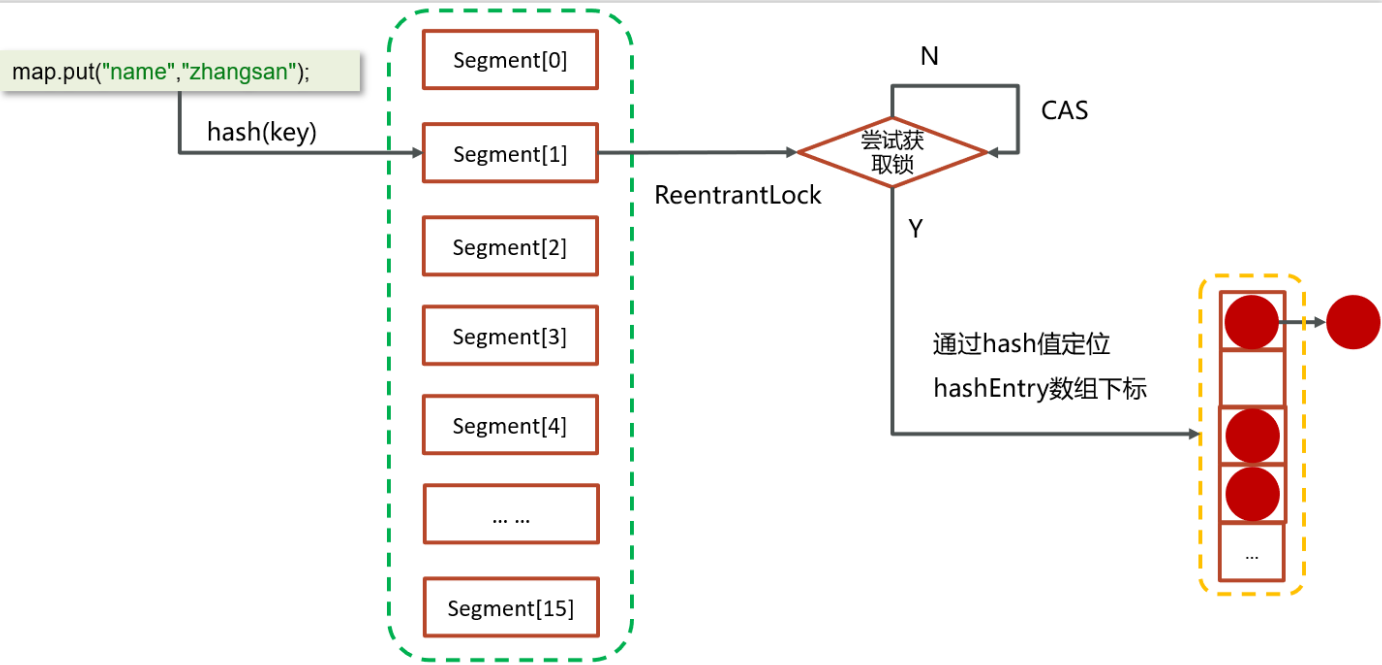
- 先去计算key的hash值,然后确定segment数组下标
- 再通过hash值确定hashEntry数组中的下标存储数据
- 在进行操作数据的之前,会先判断当前segment对应下标位置是否有线程进行操作,为了线程安全使用的是ReentrantLock进行加锁,如果获取锁是被会使用cas自旋锁进行尝试
JDK1.8 之后
Java8 ConcurrentHashMap 存储结构
放弃了Segment臃肿的设计,数据结构跟HashMap的数据结构是一 样的:数组+红黑树+链表
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。
数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
采用 CAS + Synchronized来保证并发安全进行实现
- CAS控制数组节点的添加
- 锁粒度更细,synchronized只锁定当前链表或红黑二叉树的首节点,只要hash不冲突,就不 会产生并发的问题 , 就不会影响其他 Node 的读写,效率得到提升
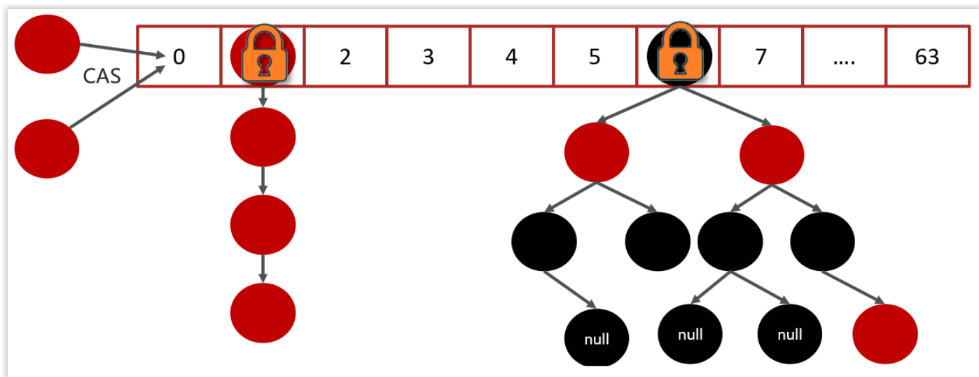
JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同
- 线程安全实现方式:JDK 1.7 采用
Segment分段锁来保证安全,Segment是继承自ReentrantLock。JDK1.8 放弃了Segment分段锁的设计,采用Node + CAS + synchronized保证线程安全,锁粒度更细,synchronized只锁定当前链表或红黑二叉树的首节点。 - Hash 碰撞解决方法 : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
- 并发度:JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
ConcurrentHashMap 是一种线程安全的高效Map集合
JDK1.7的底层采用是分段的数组+链表 实现
JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。
在jdk1.7中 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构 和HashMap类似,是一 种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构 的元素,每个 Segment 守 护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修 改 时,必须首先获得对应的 Segment的锁。
Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个 HashEntry 数组里得元 素,当对 HashEntry 数组的数据进行修改时,必须首 先获得对应的 Segment 锁
在jdk1.8中的ConcurrentHashMap 做了较大的优化,性能提升了不少。首先 是它的数据结构与jdk1.8的hashMap数据结构完全一致。其次是放弃了 Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保 证 并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点, 这样只要hash不冲 突,就不会产生并发 , 效率得到提升
ConcurrentHashMap 为什么 key 和 value 不能为 null
ConcurrentHashMap 能保证复合操作的原子性吗?
异常
Exception 和 Error 区别:
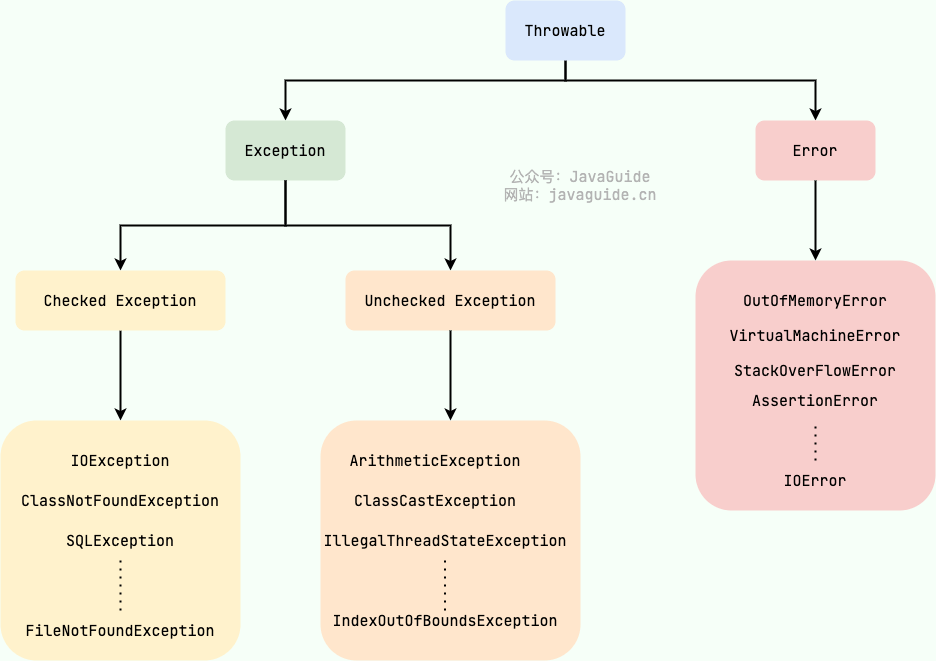
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。Error:Error属于程序无法处理的错误 ,不能通过catch来进行捕获不建议通过catch捕获 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
Checked Exception 和 Unchecked Exception 区别:
Checked Exception :Java 代码在编译过程中,如果受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译。
RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。
常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException...。
Unchecked Exception : Java 代码在编译过程中 ,即使不处理不受检查异常也可以正常通过编译。
RuntimeException 及其子类都统称为非受检查异常,常见的有(建议记下来,日常开发中会经常用到):
NullPointerException(空指针错误)IllegalArgumentException(参数错误比如方法入参类型错误)NumberFormatException(字符串转换为数字格式错误,IllegalArgumentException的子类)ArrayIndexOutOfBoundsException(数组越界错误)ClassCastException(类型转换错误)ArithmeticException(算术错误)SecurityException(安全错误比如权限不够)UnsupportedOperationException(不支持的操作错误比如重复创建同一用户)
Throwable 类常用方法
String getMessage(): 返回异常发生时的简要描述String toString(): 返回异常发生时的详细信息String getLocalizedMessage(): 返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同void printStackTrace(): 在控制台上打印Throwable对象封装的异常信息
try-catch-finally 如何使用
-
try块:用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。 -
catch块:用于处理 try 捕获到的异常。 -
finally块:无论是否捕获或处理异常,finally块里的语句都会被执行。当在
try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。
注意:不要在 finally 语句块中使用 return!
当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。
这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
public static void main(String[] args) {
System.out.println(f(2)); // 输出:0
}
public static int f(int value) {
try {
return value * value;
} finally {
if (value == 2) {
return 0;
}
}
}
Thows方法
使用throws在方法上声明,意思就是告诉下一个调用者,、这里面可能有异常啊,你调用时注意一下。
/**
* 目标:认识异常。
*/
public class ExceptionTest1 {
public static void main(String[] args) throws ParseException{
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = sdf.parse("2028-11-11 10:24");
System.out.println(d);
}
}
finally 中代码不会执行的情况
- 程序所在的线程死亡。
- 关闭 CPU。
如何使用 try-with-resources 代替try-catch-finally?
异常使用有哪些需要注意的地方?
- 不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
- 抛出的异常信息一定要有意义。
- 建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出
NumberFormatException而不是其父类IllegalArgumentException。 - 使用日志打印异常之后就不要再抛出异常了(两者不要同时存在一段代码逻辑中)。
泛型
什么是泛型?有什么作用
使用泛型参数,可以增强代码的可读性以及稳定性。
泛型的几种使用方式
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
项目中哪用到泛型
反射
除了int等基本类型外,Java的其他类型全部都是class(包括interface)。
JVM在第一次读取到一种class类型时,将其加载进内存。
每加载一种class,JVM就为其创建一个Class类型的实例,并关联起来。注意:这里的Class类型是一个名叫Class的class。它长这样:
public final class Class {
private Class() {}
}
以String类为例,当JVM加载String类时,它首先读取String.class文件到内存,然后,为String类创建一个Class实例并关联起来:
Class cls = new Class(String);
所以,JVM持有的每个Class实例都指向一个数据类型(class或interface):
一个Class实例包含了该class的所有完整信息:
由于JVM为每个加载的class创建了对应的Class实例,并在实例中保存了该class的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等,因此,如果获取了某个Class实例,我们就可以通过这个Class实例获取到该实例对应的class的所有信息。
通过Class实例获取class信息的方法称为反射(Reflection)。
加载类的字节码到内存,并以编程的方法解刨出类中的各个成分(成员变量、方法、构造器等)。
通过反射可以获取任意一个类的所有属性和方法,还可以调用这些方法和属性。
反射是用来写框架用的。
因为反射获取的是类的信息,反射的第一步首先获取到类才行。
由于Java的设计原则是万物皆对象,获取到的类其实也是以对象的形式体现的,叫字节码对象,用Class类来表示。
获取到字节码对象之后,再通过字节码对象就可以获取到类的组成成分了,这些组成成分其实也是对象,其中每一个成员变量用Field类的对象来表示、每一个成员方法用Method类的对象来表示,每一个构造器用Constructor类的对象来表示。
1.获取类的字节码
反射的第一步:是将字节码加载到内存,我们需要获取到的字节码对象。
2. 获取类的构造器
通过字节码对象获取构造器,并使用构造器创建对象。
想要快速记住这个方法的区别,给同学们说一下这些方法的命名规律,按照规律来记就很方便了。
get:获取
Declared: 有这个单词表示可以获取任意一个,没有这个单词表示只能获取一个public修饰的
Constructor: 构造方法的意思
后缀s: 表示可以获取多个,没有后缀s只能获取一个
2.1 反射获取构造器的作用
其实构造器的作用:初始化对象并返回。
3.反射获取成员变量&使用
这些方法的记忆规则,如下
get:获取
Declared: 有这个单词表示可以获取任意一个,没有这个单词表示只能获取一个public修饰的
Field: 成员变量的意思
后缀s: 表示可以获取多个,没有后缀s只能获取一个

4.反射获取成员方法
在Java中反射包中,每一个成员方法用Method对象来表示,通过Class类提供的方法可以获取类中的成员方法对象。如下下图所示

5.反射的应用
反射优缺点:
优点:可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
缺点:让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。
反射的应用场景:
因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。
像 Java 中的一大利器 注解 的实现也用到了反射。
为什么你使用 Spring 的时候 ,
一个@Component注解就声明了一个类为 Spring Bean 呢?
为什么你通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
注解
Annotation (注解) 是 Java5 开始引入的新特性,可以看作是一种特殊的注释,主要用于修饰类、方法或者变量,提供某些信息供程序在编译或者运行时使用。
我们说的@Test注解、@Overide注解是别人定义好给我们用的,将来如果需要自己去开发框架,就需要我们自己定义注解。
接着我们学习自定义注解
自定义注解的格式如下图所示

元注解
元注解是修饰注解的注解。
分别看一下@Target注解和@Retention注解有什么作用
@Target是用来声明注解只能用在那些位置,比如:类上、方法上、成员变量上等
@Retetion是用来声明注解保留周期,比如:源代码时期、字节码时期、运行时期
解析注解
通过反射技术把类上、方法上、变量上的注解对象获取出来,然后通过调用方法就可以获取注解上的属性值了。
我们把获取类上、方法上、变量上等位置注解及注解属性值的过程称为解析注解。
解析注解套路如下
1.如果注解在类上,先获取类的字节码对象,再获取类上的注解
2.如果注解在方法上,先获取方法对象,再获取方法上的注解
3.如果注解在成员变量上,先获取成员变量对象,再获取变量上的注解
总之:注解在谁身上,就先获取谁,再用谁获取谁身上的注解
注解的应用场景
注解是用来写框架的
注解的解析方法
注解只有被解析之后才会生效,常见的解析方法有两种:
- 编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用
@Override注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。 - 运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的
@Value、@Component)都是通过反射来进行处理的。
SPI
SPI Service Provider Interface
专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。
SPI 和 API 区别:
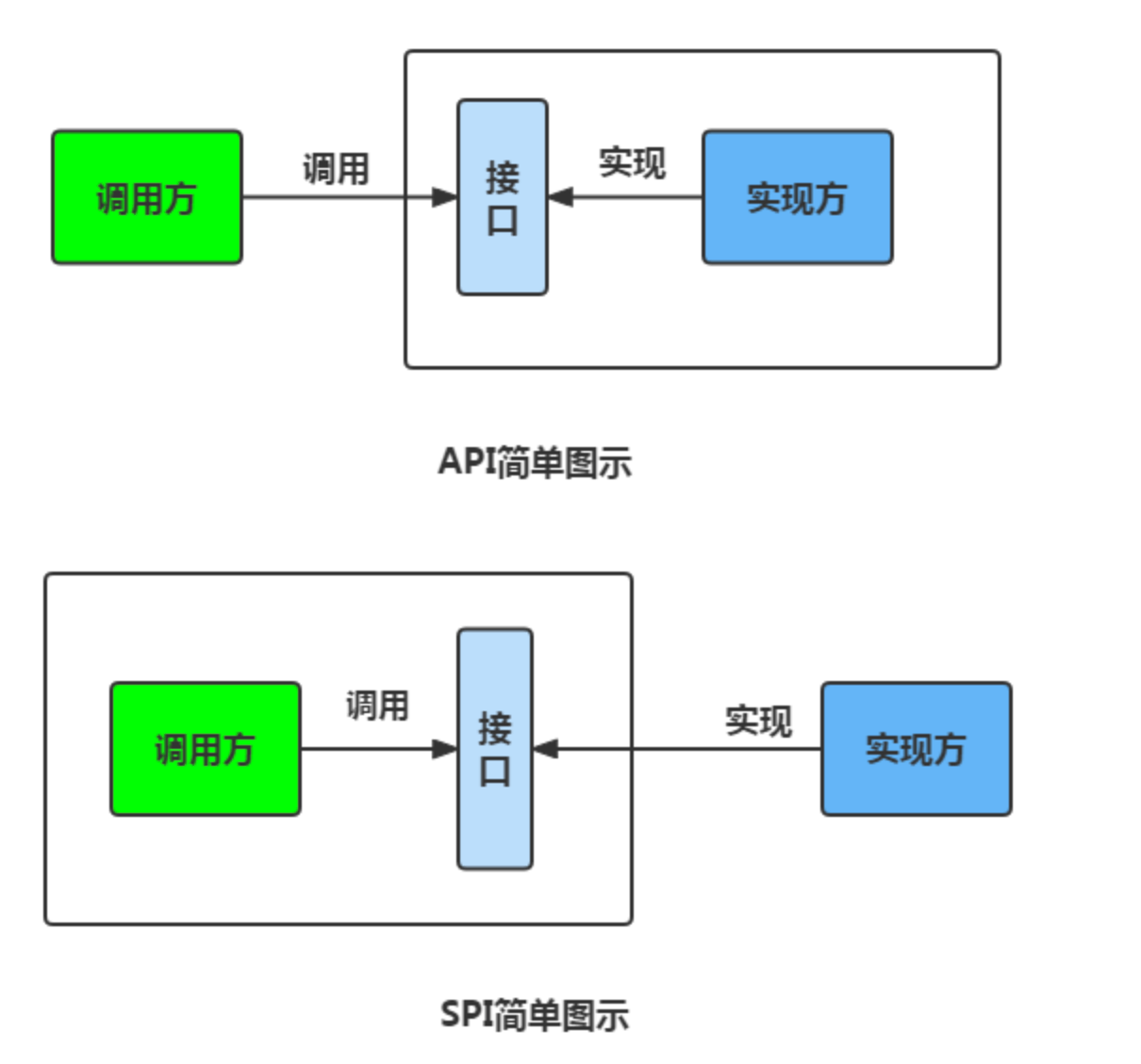
一般模块之间都是通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
- 当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
- 当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
SPI 的优缺点:
通过 SPI 机制能够大大地提高接口设计的灵活性,但是 SPI 机制也存在一些缺点,比如:
- 需要遍历加载所有的实现类,不能做到按需加载,这样效率还是相对较低的。
- 当多个
ServiceLoader同时load时,会有并发问题。
序列化和反序列化
- 序列化:将数据结构或对象转换成二进制字节流的过程。
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class)。
综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
序列化协议对应于 TCP/IP 4 层模型的哪一层?

TCP/IP 4 层模型:应用层、传输层、网络层、网络接口层。
OSI 七层协议模型的应用层、表示层和会话层对应的都是 TCP/IP 四层模型中的应用层,序列化协议属于 TCP/IP 协议应用层的一部分。
如果有些字段不想进行序列化怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
transient只能修饰变量,不能修饰类和方法。transient修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰int类型,那么反序列后结果就是0。static变量因为不属于任何对象(Object),所以无论有没有transient关键字修饰,均不会被序列化。
I/O
IO 即 Input/Output,输入和输出。
数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。
- 从计算机结构的视角来看的话:I/О描述了计算机系统与外部设备之间通信的过程。
- 从应用程序的角度来解读一下I/O:应用程序对操作系统的内核发起IO调用(系统调用),操作系统负责的内核执行具体的IO操作。也就是说,应用程序实际上只是发起了IO操作的调用而已,具体IO的执行是由操作系统的内核来完成的。
一个进程的地址空间划分为用户空间(User space)和内核空间(Kernel space ) 。
像我们平常运行的应用程序都是运行在用户空间,只有内核空间才能进行系统态级别的资源有关的操作,比如如文件管理、进程通信、内存管理等等。也就是说,我们想要进行IO操作,一定是要依赖内核空间的能力。
用户空间的程序不能直接访问内核空间。当想要执行IO操作时,只能发起系统调用****请求操作系统帮忙完成。
我们在平常开发过程中接触最多的就是磁盘IO(读写文件)和网络IO(网络请求和响应)。
当应用程序发起I/О调用后,会经历两个步骤:
- 内核等待I/О设备准备好数据
- 内核将数据从内核空间拷贝到用户空间。
Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
I/O 流为什么要分为字节流和字符流呢
不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
个人认为主要有两点原因:
-
字符流是由 Java 虚拟机将字节转换得到的,这个过程还算是比较耗时;
-
如果我们不知道编码类型的话,使用字节流的过程中很容易出现乱码问题。
-
文本数据处理:字符流更适用于处理文本数据,因为它们能够处理字符编码,确保正确的字符转换。
-
二进制数据处理:字节流更适用于处理二进制数据,如图像、音频、视频等文件,这些文件不受字符编码的影响。
-
性能:字节流在处理数据时更为底层,直接操作字节,因此在处理大量数据时可能更为高效。字符流则提供了更高级别的字符处理功能,但在处理二进制数据时可能效率较低。
总的来说,字节流主要用于处理原始的字节数据,而字符流更适用于处理文本数据。
Java 中的常见IO模型
BIO(Blocking I/O)
BIO属于同步阻塞IО模型。
同步阻塞IO模型中,应用程序发起read调用后,会一直阻塞,直到在内核把数据拷贝到用户空间。

在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。因此,我们需要一种更高效的I/O处理模型来应对更高的并发量。
NIO(Non-blocking I/O I/O)
NIO中的N可以理解为Non-blocking,对于高负载、高并发的(网络)应用,应使用NIO。
Java中的NIO可以看作是I/O多路复用模型。也有很多人认为,Java中的NIO属于同步非阻塞IО模型。

同步非阻塞IО模型中,应用程序会一直发起read调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。
相比于同步阻塞IO模型,同步非阻塞IO模型确实有了很大改进。通过轮询操作,避免了—直阻塞。
但是,这种IO模型同样存在问题:应用程序不断进行I/O系统调用轮询数据是否已经准备好的过程是十分消耗CPU资源的。
这个时候,I/O多路复用模型就上场了。

IO多路复用模型中,线程首先发起select调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起read调用。read调用的过程(数据从内核空间->用户空间)还是阻塞的。
Java 中的NIO,有一个非常重要的选择器( Selector )的概念,也可以被称为多路复用器。
通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。
IO多路复用模型,通过减少无效的系统调用,减少了对CPU 资源的消耗。
AIO(Asynchronous I/O)
异步IO是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。


语法糖
语法糖(Syntactic sugar) 代指的是编程语言为了方便程序员开发程序而设计的一种特殊语法,这种语法对编程语言的功能并没有影响。实现相同的功能,基于语法糖写出来的代码往往更简单简洁且更易阅读。
特殊文件
- 后缀为.properties的文件,称之为属性文件,它可以很方便的存储一些类似于键值对的数据。经常当做软件的配置文件使用。
- 每一行末尾不要习惯性加分号,以及空格等字符;不然会把分号,空格会当做值的一部分
- Properties是什么?
Properties是Map接口下面的一个实现类,所以Properties也是一种双列集合,用来存储键值对。 但是一般不会把它当做集合来使用。
Properties核心作用?
Properties类的对象,用来表示属性文件,可以用来读取属性文件中的键值对。
- 而xml文件能够表示更加复杂的数据关系,比如要表示多个用户的用户名、密码、家乡、性别等。在后面,也经常当做软件的配置文件使用。
XML是可扩展的标记语言,意思是它是由一些标签组成 的,而这些标签是自己定义的。本质上一种数据格式,可以用来表示复杂的数据关系。
XML文件有如下的特点:
-
XML中的
<标签名>称为一个标签或者一个元素,一般是成对出现的。 -
XML中的标签名可以自己定义(可扩展),但是必须要正确的嵌套
-
XML中只能有一个根标签。
-
XML标准中可以有属性
-
XML必须第一行有一个文档声明,格式是固定的
<?xml version="1.0" encoding="UTF-8"?> -
XML文件必须是以.xml为后缀结尾
-
像
<,>,&等这些符号不能出现在标签的文本中,因为标签格式本身就有<>,会和标签格式冲突。如果标签文本中有这些特殊字符,需要用一些占位符代替。
< 表示 < > 表示 > & 表示 & ' 表示 ' " 表示 "<data> 3 < 2 && 5 > 4 </data> -
如果在标签文本中,出现大量的特殊字符,不想使用特殊字符,此时可以用CDATA区,格式如下
<data1> <![CDATA[ 3 < 2 && 5 > 4 ]]> </data1>
日志
日志技术有如下好处
- 日志可以将系统执行的信息,方便的记录到指定位置,可以是控制台、可以是文件、可以是数据库中。
- 日志可以随时以开关的形式控制启停,无需侵入到源代码中去修改。
推荐同学们使用Logback日志框架,也在行业中最为广泛使用的。**
Logback日志分为哪几个模块
多线程
导致并发程序出现问题的根本原因
Java并发编程三大特性
- 原子性
一个线程在CPU中操作不可暂停,也不可中断,要不执行完成,要不不执行。
- 可见性
内存可见性:让一个线程对共享变量的修改对另一个线程可见
- 有序性
指令重排:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保 证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终 执行结果和代码顺序执行的结果是一致的。
线程
什么是线程和进程
-
进程是程序的一次执行过程,是系统运行程序的基本单位。系统运行一个程序即是一个进程从创建,运行到消亡的过程。不同的进程使用不同的内存空间,在当前进程下的所有线程可以共享内存空间。
-
线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,线程更轻量,线程上下文切换成本一般上要比进程上下文切换低(上下文切换指的 是从一个线程切换到另一个线程),线程也被称为轻量级进程。
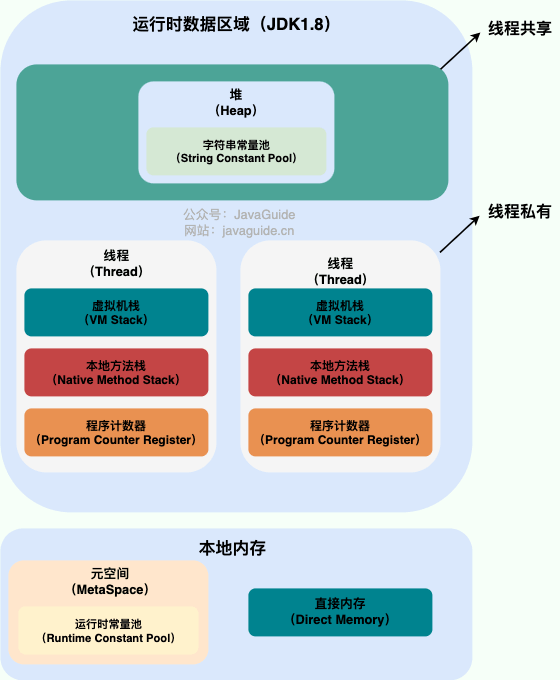
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)*资源,但是每个线程有自己的*程序计数器、虚拟机栈 和 本地方法栈。
总结:
- 线程是进程划分成的更小的运行单位。
- 线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。
- 线程执行开销小,但不利于资源的管理和保护;而进程正相反。
为什么程序计数器、虚拟机栈和本地方法栈是线程私有的呢?为什么堆和方法区是线程共享的呢?
程序计数器私有主要是为了线程切换后能恢复到正确的执行位置。
为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的。
一句话简单了解堆和方法区
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (几乎所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
如何创建线程
共有四种方式可以创建线程,分别是:
通常情况下,我们项目中都会采用线程池的方式创建线程。
1继承Thread类
public class MyThread extends Thread {
@Override
public void run() {
System.out.println("MyThread...run...");
}
public static void main(String[] args) {
// 创建MyThread对象
MyThread t1 = new MyThread() ;
MyThread t2 = new MyThread() ;
// 调用start方法启动线程
t1.start();
t2.start();
}
}
2实现runnable接口
public class MyRunnable implements Runnable{
@Override
public void run() {
System.out.println("MyRunnable...run...");
}
public static void main(String[] args) {
// 创建MyRunnable对象
MyRunnable mr = new MyRunnable() ;
// 创建Thread对象
Thread t1 = new Thread(mr) ;
Thread t2 = new Thread(mr) ;
// 调用start方法启动线程
t1.start();
t2.start();
}
}
3实现 Callable接口
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("MyCallable...call...");
return "OK";
}
public static void main(String[] args) throws
ExecutionException, InterruptedException {
// 创建MyCallable对象
MyCallable mc = new MyCallable() ;
// 创建F
FutureTask<String> ft = new FutureTask<String>(mc) ;
// 创建Thread对象
Thread t1 = new Thread(ft) ;
Thread t2 = new Thread(ft) ;
// 调用start方法启动线程
t1.start();
// 调用ft的get方法获取执行结果
String result = ft.get();
// 输出
System.out.println(result);
}
}
4线程池创建线程
public class MyExecutors implements Runnable{
@Override
public void run() {
System.out.println("MyRunnable...run...");
}
public static void main(String[] args) {
// 创建线程池对象
ExecutorService threadPool =
Executors.newFixedThreadPool(3);
threadPool.submit(new MyExecutors()) ;
// 关闭线程池
threadPool.shutdown();
}
}
runnable 和 callable 两个接口创建线程不同
- Runnable 接口run方法无返回值;Callable接口call方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
- 异常处理也不一样。Runnable接口run方法只能抛出运行时异常,也无法捕获处理;Callable接口call方法允许抛出异常,可以获取异常信息
- 在实际开发中,如果需要拿到执行的结果,需要使用Callalbe接口创建线程,调用FutureTask.get()得到可以得到返回值,此方法会阻塞主进程的继续 往下执行,如果不调用不会阻塞。
说说线程的生命周期和状态
Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态:
-
NEW: 初始状态,线程被创建出来但没有被调用
start()。 -
RUNNABLE: 运行状态,线程被调用了
start()等待运行的状态。 -
BLOCKED:阻塞状态,需要等待锁释放。
当线程进入
synchronized方法/块或者调用wait后(被notify)重新进入synchronized方法/块,但是锁被其它线程占有,这个时候线程就会进入 BLOCKED(阻塞) 状态。 -
WAITING:当线程执行
wait()方法之后,线程进入 WAITING(等待) 状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态。等待状态,表示该线程需要等待其他线程做出一些特定动作(通知或中断)。 -
TIME_WAITING:超时等待状态,可以在指定的时间后自行返回而不是像 WAITING 那样一直等待。
状态相当于在等待状态的基础上增加了超时限制,比如通过
sleep(long millis)方法或wait(long millis)方法可以将线程置于 TIMED_WAITING 状态。当超时时间结束后,线程将会返回到 RUNNABLE 状态。 -
TERMINATED:终止状态,表示该线程已经运行完毕。线程在执行完了
run()方法之后将会进入到 TERMINATED(终止) 状态。
线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。
当一个线程对象被创建,但还未调用 start 方法时处于新建状态,调用了 start 方法,就会由新建进入可运行状态。如果线程内代码已经执行完毕,由 可运行进入终结状态。当然这些是一个线程正常执行情况。 如果线程获取锁失败后,由可运行进入 Monitor 的阻塞队列阻塞,只有当持 锁线程释放锁时,会按照一定规则唤醒阻塞队列中的阻塞线程,唤醒后的线 程进入可运行状态 如果线程获取锁成功后,但由于条件不满足,调用了 wait() 方法,此时从可 运行状态释放锁等待状态,当其它持锁线程调用 notify() 或 notifyAll() 方 法,会恢复为可运行状态 还有一种情况是调用 sleep(long) 方法也会从可运行状态进入有时限等待状 态,不需要主动唤醒,超时时间到自然恢复为可运行状态
什么是线程上下文切换
线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用 CPU 状态中退出。
- 主动让出 CPU,比如调用了
sleep(),wait()等。 - 时间片用完,因为操作系统要防止一个线程或者进程长时间占用 CPU 导致其他线程或者进程饿死。
- 调用了阻塞类型的系统中断,比如请求 IO,线程被阻塞。
- 被终止或结束运行
这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用 CPU 的时候恢复现场。并加载下一个将要占用 CPU 的线程上下文。这就是所谓的 上下文切换。(上下文切换指的是从一个线程切换到另一个线程)
上下文切换是现代操作系统的基本功能,因其每次需要保存信息恢复信息,这将会占用 CPU,内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下。
sleep() 方法和 wait() 方法对比
共同点:都是让当前线程暂时放弃 CPU 的使用权,进入阻塞状态,两者都可以暂停线程的执行。
区别:
-
wait()通常被用于线程间交互/通信,sleep()通常被用于暂停执行。 -
方法归属不同:
wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者notifyAll()方法。sleep()方法执行完成后,线程会自动苏醒,或者也可以使用wait(long timeout)超时后线程会自动苏醒。 -
方法归属不同:
sleep()是Thread类的静态本地方法,wait()则是Object类的本地方法,每个对象都有。 -
sleep()方法没有释放锁,而wait()方法释放了锁 。 -
方法归属不同:wait 方法的调用必须先获取 wait 对象的锁,而 sleep 则无此限制
wait 方法执行后会释放对象锁,允许其它线程获得该对象锁(我放弃 cpu,但你们还可以用)
而 sleep 如果在 synchronized 代码块中执行,并不会释放对象锁(我放弃 cpu,你们也用不了)
为什么这样设计呢?下一个问题就会聊到。
为什么 wait() 方法不定义在 Thread 中?
wait() 是让获得对象锁的线程实现等待,会自动释放当前线程占有的对象锁。每个对象(Object)都拥有对象锁,既然要释放当前线程占有的对象锁并让其进入 WAITING 状态,自然是要操作对应的对象(Object)而非当前的线程(Thread)。
类似的问题:为什么 sleep() 方法定义在 Thread 中?
因为 sleep() 是让当前线程暂停执行,不涉及到对象类,也不需要获得对象锁。
可以直接调用 Thread 类的 run 方法吗
new 一个 Thread,线程进入了新建状态。调用 start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 但是,直接执行 run() 方法,会把 run() 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结:调用 start() 方法方可启动线程并使线程进入就绪状态,直接执行 run() 方法的话不会以多线程的方式执行。
线程的 run()和 start()有什么区别?
- start(): 用来启动线程,通过该线程调用run方法执行run方法中所定义的逻辑代 码。start方法只能被调用一次。
- run(): 封装了要被线程执行的代码,可以被调用多次。
如何停止一个正在运行的线程?
有三种方式可以停止线程
- 可以使用退出标志,使线程正常退出,也就是当run方法完成后线程 终止,一般我们加一个标记
- 可以使用线程的stop方法强行终止,不过一般不推荐,这个方法已作 废
- 可以使用线程的interrupt方法中断线程,内部其实也是使用中断标志 来中断线程
多线程
并发和并行
并发:两个及两个以上的作业在同一 时间段 内执行。并发就是多条线程交替执行。
并行:两个及两个以上的作业在同一 时刻 执行。多个CPU核心在执行多条线程。
举个不恰当的例子:
家庭主妇做饭、打扫卫生、给孩子喂奶,她一个人轮流交替做这多件事,这时就是并发
家庭主妇雇了个保姆,她们一起这些事,这时既有并发,也有并行(这时会产生竞争,例如锅只有一口,一个人用锅时,另一个人就得等待)
雇了3个保姆,一个专做饭、一个专打扫卫生、一个专喂奶,互不干扰,这时是并行

最关键的点是:是否是 同时 执行
最后一个问题,多线程到底是并发还是并行呢?
其实多个线程在我们的电脑上执行,并发和并行是同时存在的。
同步和异步的区别
- 同步:发出一个调用之后,在没有得到结果之前, 该调用就不可以返回,一直等待。
- 异步:调用在发出之后,不用等待返回结果,该调用直接返回。
使用多线程可能带来什么问题
并发编程的目的就是为了能提高程序的执行效率进而提高程序的运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
多线程常用方法
线程安全问题
线程安全问题指的是,多个线程同时操作同一个共享资源的时候,可能会出现业务安全问题。
线程安全问题的代码演示
先定义一个共享的账户类
public class Account {
private String cardId; // 卡号
private double money; // 余额。
public Account() {
}
public Account(String cardId, double money) {
this.cardId = cardId;
this.money = money;
}
// 小明 小红同时过来的
public void drawMoney(double money) {
// 先搞清楚是谁来取钱?
String name = Thread.currentThread().getName();
// 1、判断余额是否足够
if(this.money >= money){
System.out.println(name + "来取钱" + money + "成功!");
this.money -= money;
System.out.println(name + "来取钱后,余额剩余:" + this.money);
}else {
System.out.println(name + "来取钱:余额不足~");
}
}
public String getCardId() {
return cardId;
}
public void setCardId(String cardId) {
this.cardId = cardId;
}
public double getMoney() {
return money;
}
public void setMoney(double money) {
this.money = money;
}
}
在定义一个是取钱的线程类
public class DrawThread extends Thread{
private Account acc;
public DrawThread(Account acc, String name){
super(name);
this.acc = acc;
}
@Override
public void run() {
// 取钱(小明,小红)
acc.drawMoney(100000);
}
}
最后,再写一个测试类,在测试类中创建两个线程对象
public class ThreadTest {
public static void main(String[] args) {
// 1、创建一个账户对象,代表两个人的共享账户。
Account acc = new Account("ICBC-110", 100000);
// 2、创建两个线程,分别代表小明 小红,再去同一个账户对象中取钱10万。
new DrawThread(acc, "小明").start(); // 小明
new DrawThread(acc, "小红").start(); // 小红
}
}
运行程序,执行效果如下。你会发现两个人都取了10万块钱,余额为-10完了。

线程同步方案
为了解决前面的线程安全问题,我们可以使用线程同步思想。同步最常见的方案就是加锁,意思是每次只允许一个线程加锁,加锁后才能进入访问,访问完毕后自动释放锁,然后其他线程才能再加锁进来。
采用加锁的方案,就可以解决前面两个线程都取10万块钱的问题。怎么加锁呢?Java提供了三种方案
1.同步代码块
2.同步方法
3.Lock锁
同步代码块
我们先来学习同步代码块。它的作用就是把访问共享数据的代码锁起来,以此保证线程安全。
//锁对象:必须是一个唯一的对象(同一个地址)
synchronized(锁对象){
//...访问共享数据的代码...
}
使用同步代码块,来解决前面代码里面的线程安全问题。我们只需要修改DrawThread类中的代码即可。
// 小明 小红线程同时过来的
public void drawMoney(double money) {
// 先搞清楚是谁来取钱?
String name = Thread.currentThread().getName();
// 1、判断余额是否足够
// this正好代表共享资源!
synchronized (this) {
if(this.money >= money){
System.out.println(name + "来取钱" + money + "成功!");
this.money -= money;
System.out.println(name + "来取钱后,余额剩余:" + this.money);
}else {
System.out.println(name + "来取钱:余额不足~");
}
}
}
此时再运行测试类,观察是否会出现不合理的情况。
锁对象如何选择的问题
1.建议把共享资源作为锁对象, 不要将随便无关的对象当做锁对象
2.对于实例方法,建议使用this作为锁对象
3.对于静态方法,建议把类的字节码(类名.class)当做锁对象
同步方法
同步方法,就是把整个方法给锁住,一个线程调用这个方法,另一个线程调用的时候就执行不了,只有等上一个线程调用结束,下一个线程调用才能继续执行。
// 同步方法
public synchronized void drawMoney(double money) {
// 先搞清楚是谁来取钱?
String name = Thread.currentThread().getName();
// 1、判断余额是否足够
if(this.money >= money){
System.out.println(name + "来取钱" + money + "成功!");
this.money -= money;
System.out.println(name + "来取钱后,余额剩余:" + this.money);
}else {
System.out.println(name + "来取钱:余额不足~");
}
}
同步方法有没有锁对象?锁对象是谁?
同步方法也是有锁对象,只不过这个锁对象没有显示的写出来而已。
1.对于实例方法,锁对象其实是this(也就是方法的调用者)
2.对于静态方法,锁对象时类的字节码对象(类名.class)
总结一下同步代码块和同步方法有什么区别?
1.不存在哪个好与不好,只是一个锁住的范围大,一个范围小
2.同步方法是将方法中所有的代码锁住
3.同步代码块是将方法中的部分代码锁住
Lock锁
Lock锁是JDK5版本专门提供的一种锁对象,通过这个锁对象的方法来达到加锁,和释放锁的目的,使用起来更加灵活。格式如下
1.首先在成员变量位子,需要创建一个Lock接口的实现类对象(这个对象就是锁对象)
private final Lock lk = new ReentrantLock();
2.在需要上锁的地方加入下面的代码
lk.lock(); // 加锁
//...中间是被锁住的代码...
lk.unlock(); // 解锁
使用Lock锁改写前面DrawThread中取钱的方法,代码如下
// 创建了一个锁对象
private final Lock lk = new ReentrantLock();
public void drawMoney(double money) {
// 先搞清楚是谁来取钱?
String name = Thread.currentThread().getName();
try {
lk.lock(); // 加锁
// 1、判断余额是否足够
if(this.money >= money){
System.out.println(name + "来取钱" + money + "成功!");
this.money -= money;
System.out.println(name + "来取钱后,余额剩余:" + this.money);
}else {
System.out.println(name + "来取钱:余额不足~");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
lk.unlock(); // 解锁
}
}
}
线程的生命周期/线程包括哪些状态,状态之间是如何变化的
在Thread类中有一个嵌套的枚举类叫Thread.Status,这里面定义了线程的6中状态。
NEW: 当一个线程对象被创建,但还未调用 start 方法时处于新建状态, 此时未与操作系统底层线程关联
RUNNABLE: 可以运行状态,线程调用了start()方法后处于这个状态, 此时与底层线程关联,由操作系统调度执行
BLOCKED:
1. 当获取锁失败后,由可运行进入 Monitor 的阻塞队列阻塞,此时不占用cpu 时间
2. 当持锁线程释放锁时,会按照一定规则唤醒阻塞队列中的阻塞线程,唤醒后的线程进入可运行状态
WAITING:
1. 当获取锁成功后,但由于条件不满足,调用了 wait() 方法,此时从可运行状态释放锁进入 Monitor 等待集合等待,同样不占用 cpu 时间
2. 当其它持锁线程调用 notify() 或 notifyAll() 方法,会按照一定规则唤醒等待集合中的等待线程,恢复为可运行状态
TIMED_WAITING: 计时等待状态,线程执行时被调用了sleep(毫秒)或者wait(毫秒)方法处于这个状态
1. 当获取锁成功后,但由于条件不满足,调用了 wait(long) 方法,此时从可运行状态释放锁进入 Monitor 等待集合进行有时限等待,同样不占用 cpu时间
2. 当其它持锁线程调用 notify() 或 notifyAll() 方法,会按照一定规则唤醒等待集合中的有时限等待线程,恢复为可运行状态,并重新去竞争锁
3. 如果等待超时,也会从有时限等待状态恢复为可运行状态,并重新去竞争锁
4. 还有一种情况是调用 sleep(long) 方法也会从可运行状态进入有时限等待状态,但与 Monitor 无关,不需要主动唤醒,超时时间到自然恢复为可运行状态
TERMINATED: 终止状态, 线程执行完毕或者遇到异常时,处于这个状态。
线程内代码已经执行完毕,由可运行进入终结
此时会取消与底层线程关联
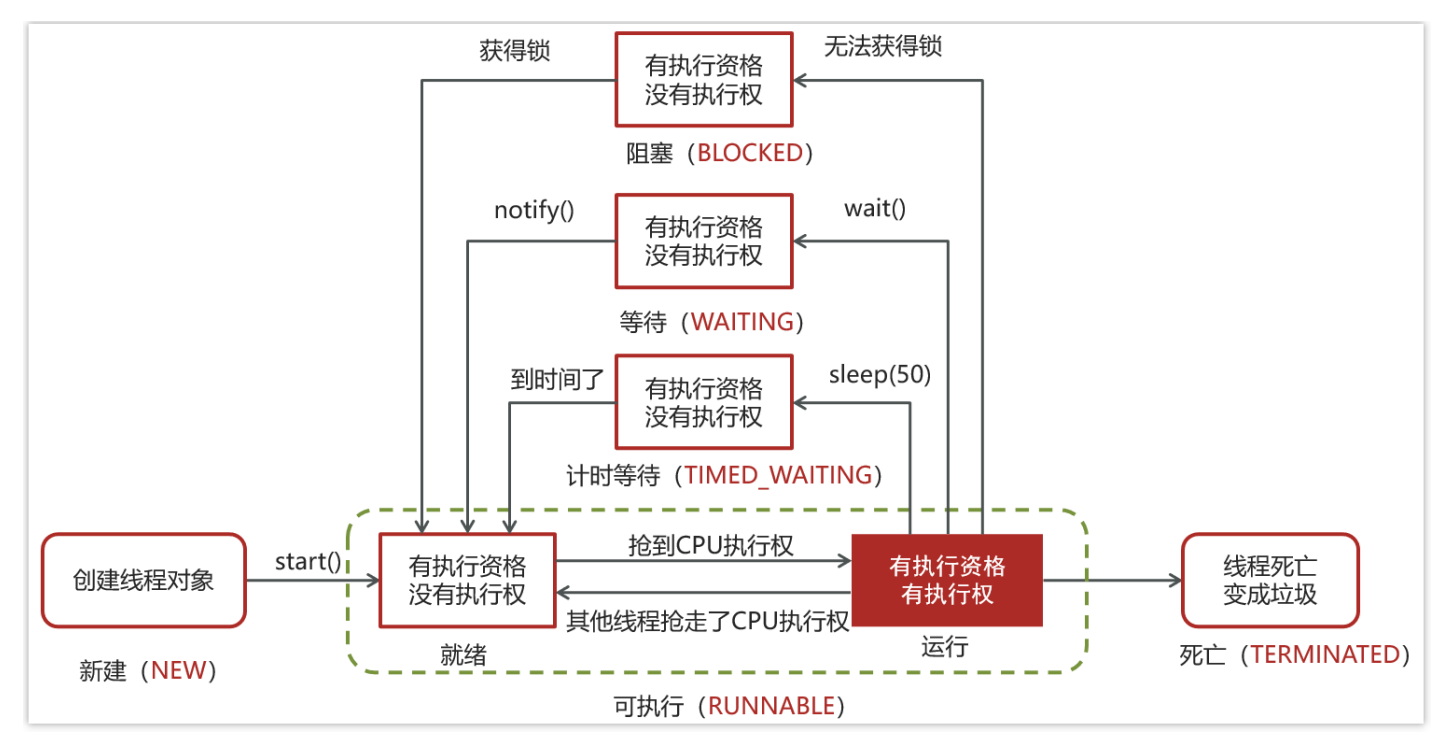
notify()和 notifyAll()区别?
- notifyAll:唤醒所有wait的线程
- notify:只随机唤醒一个 wait 线程
如何理解线程安全和不安全
线程安全和不安全是在多线程环境下对于同一份数据的访问是否能够保证其正确性和一致性的描述。
- 线程安全指的是在多线程环境下,对于同一份数据,不管有多少个线程同时访问,都能保证这份数据的正确性和一致性。
- 线程不安全则表示在多线程环境下,对于同一份数据,多个线程同时访问时可能会导致数据混乱、错误或者丢失。
导致并发程序出现问题的根本原因是什么
Java并发编程三大特性
- 原子性
一个线程在CPU中操作不可暂停,也不可中断,要不执行完成,要不不执行
- 可见性
让一个线程对共享变量的修改对另一个线程可见
- 有序性
指令重排:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的
死锁
什么是线程死锁
死锁:一个线程需要同时获取多把锁,这时就容易发生死锁
t1 线程获得A对象锁,接下来想获取B对象的锁
t2 线程获得B对象锁,接下来想获取A对象的锁
这个时候t1线程和t2线程都在互相等待对方的锁,就产生了死锁
线程死锁描述的是这样一种情况:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
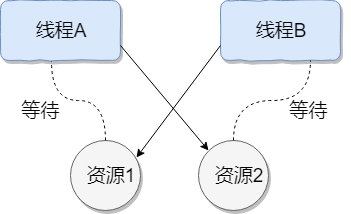
产生死锁的四个必要条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。
如何检测死锁
- 使用
jmap、jstack等命令查看 JVM 线程栈和堆内存的情况。如果有死锁,jstack的输出中通常会有Found one Java-level deadlock:的字样,后面会跟着死锁相关的线程信息。另外,实际项目中还可以搭配使用top、df、free等命令查看操作系统的基本情况,出现死锁可能会导致 CPU、内存等资源消耗过高。 - 采用 VisualVM、JConsole 等工具进行排查。
这个也很容易,我们只需要通过jdk自动的工具就能搞定
我们可以先通过jps来查看当前java程序运行的进程id
然后通过jstack来查看这个进程id,就能展示出来死锁的问题,并且,可以定 位代码的具体行号范围,我们再去找到对应的代码进行排查就行了。
如何预防和避免死锁
如何预防死锁? 破坏死锁的产生的必要条件即可:
- 破坏请求与保持条件:一次性申请所有的资源。
- 破坏不剥夺条件:占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件:靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
如何避免死锁?
JMM
JMM(Java Memory Model)Java内存模型,是java虚拟机规范中所定义的一种内存模型。
Java内存模型(Java Memory Model)描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
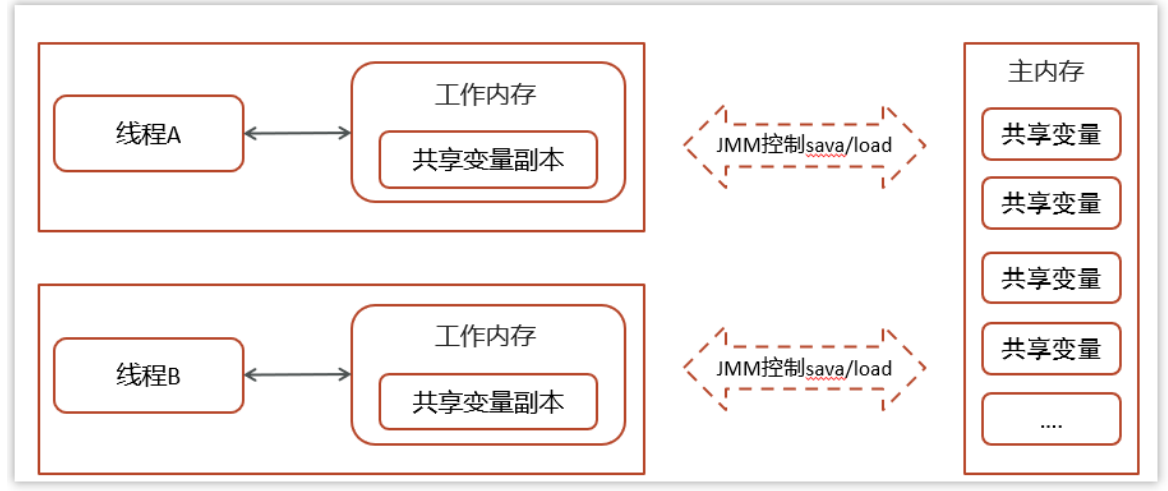
特点:
- 所有的共享变量都存储于主内存(计算机的RAM)这里所说的变量指的是实例变量和类变量。不包含局部变量,因为局部变量是线程私有的,因此不存在 竞争问题。
- 每一个线程还存在自己的工作内存,线程的工作内存,保留了被线程使用的 变量的工作副本。
- 线程对变量的所有的操作(读,写)都必须在工作内存中完成,而不能直接读写 主内存中的变量,不同线程之间也不能直接访问对方工作内存中的变量,线 程间变量的值的传递需要通过主内存完成。
volatile关键字
volatile 是一个关键字,可以修饰类的成员变量、类的静态成员变量,主要有两个功能
- 1.保证线程间的可见性
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的,volatile关键字会强制将修改的值立即 写入主存。
- 2.禁止进行指令重排序
用 volatile 修饰共享变量会在读、写共享变量时加入不同的屏障,阻止其他读写操作越过屏障,从而达到阻止重排序的效果
禁止进行指令重排序,可以保证代码执行有序性。底层实现原理是, 添加了一个内存屏障,通过插入内存屏障禁止在内存屏障前后的指令执行重 排序优化
如何保证变量的可见性
在 Java 中,volatile 关键字可以保证变量的可见性,如果我们将变量声明为 volatile ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。
如何禁止指令重排序
代码在实际运行时,代码指令可能不是严格按照代码语句的顺序执行的。
只要程序的最终运行结果与它顺序化执行的结果相等,那么指令的执行顺序可以与代码逻辑顺序不一致,整个过程叫:指令重排序。
在 Java 中,volatile 关键字除了可以保证变量的可见性,还有一个重要的作用就是防止 JVM 的指令重排序。 如果我们将变量声明为 volatile ,在对这个变量进行读写操作的时候,会通过插入特定的 内存屏障 的方式来禁止指令重排序。

注解@Actor保证方法内的代码在同一个线程下执行
- 情况一:先执行actor2获取结果--->0,0(正常)
- 情况二:先执行actor1中的第一行代码,然后执行actor2获取结果--->0,1(正常)
- 情况三:先执行actor1中所有代码,然后执行actor2获取结果--->1,1(正常)
- 情况四:先执行actor1中第二行代码,然后执行actor2获取结果--->1,0(发生了指 令重排序,影响结果)
解决方案
在变量上添加volatile,禁止指令重排序,则可以解决问题
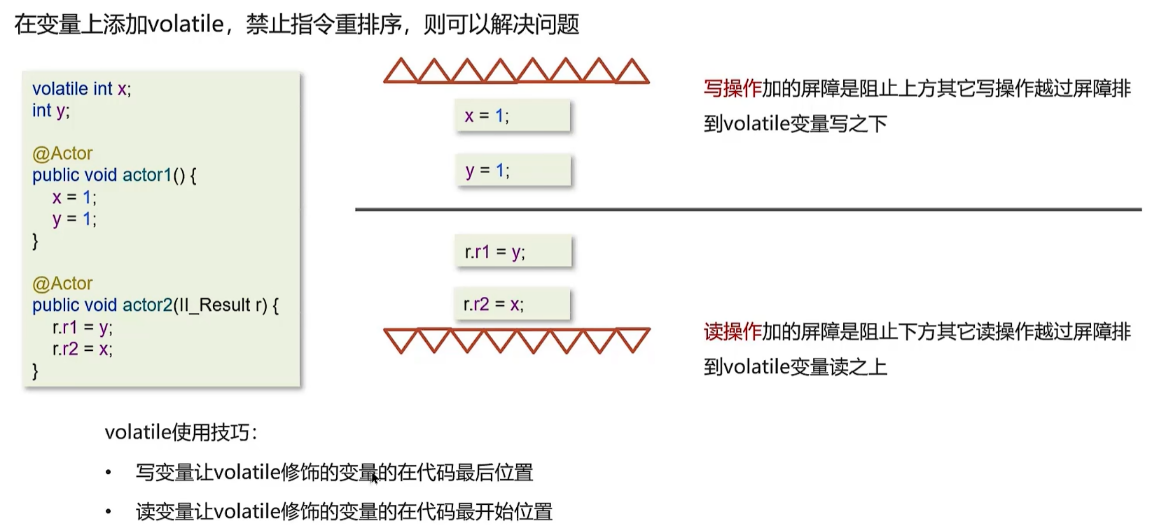
volatile 可以保证原子性么?
乐观锁和悲观锁
悲观锁
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
像 Java 中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行。
乐观锁
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法)。
高并发的场景下,乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹。但是,如果冲突频繁发生(写占比非常多的情况),会频繁失败和重试,这样同样会非常影响性能,导致 CPU 飙升。
不过,大量失败重试的问题也是可以解决的,像我们前面提到的 LongAdder以空间换时间的方式就解决了这个问题。
理论上来说:
- 悲观锁通常多用于写比较多的情况(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如
LongAdder),也是可以考虑使用乐观锁的,要视实际情况而定。 - 乐观锁通常多用于写比较少的情况(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考
java.util.concurrent.atomic包下面的原子变量类)。
如何实现乐观锁
乐观锁一般会使用版本号机制或 CAS 算法实现,CAS 算法相对来说更多一些。
版本号机制
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
举一个简单的例子:假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
- 操作员 A 此时将其读出(
version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。 - 在操作员 A 操作的过程中,操作员 B 也读入此用户信息(
version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。 - 操作员 A 完成了修改工作,将数据版本号(
version=1 ),连同帐户扣除后余额(balance=$50 ),提交至数据库更新,此时由于提交数据版本等于数据库记录当前版本,数据被更新,数据库记录version更新为 2 。 - 操作员 B 完成了操作,也将版本号(
version=1 )试图向数据库提交数据(balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 1 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须等于当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员 A 的操作结果的可能。
CAS算法
黑马视频
Compare And Swap(比较再交换),它体现的一种乐观锁的思想, 在无锁情况下保证线程操作共享数据的原子性。
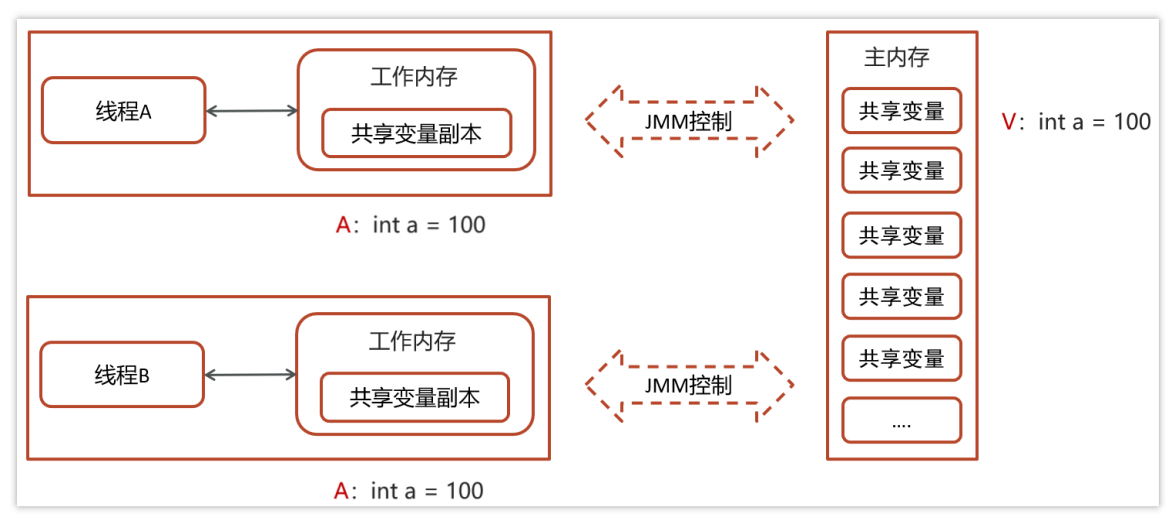
- 线程1与线程2都从主内存中获取变量int a = 100,同时放到各个线程的工作内存中
一个当前内存值V、旧的预期值A、即将更新的值B,当且仅当旧的预期值A 和内存值V相同时,将内存值修改为B并返回true,否则什么都不做,并返回 false。如果CAS操作失败,通过自旋的方式等待并再次尝试,直到成功。
-
线程1操作:V:int a = 100,A:int a = 100,B:修改后的值:int a = 101 (a++)
线程1拿A的值与主内存V的值进行比较,判断是否相等
如果相等,则把B的值101更新到主内存中
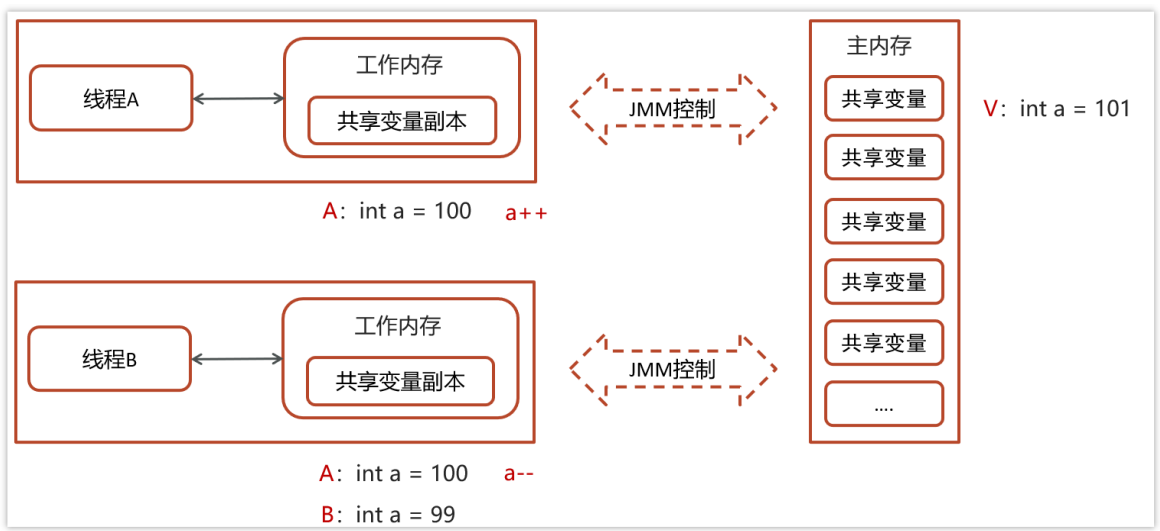
-
线程2操作:V:int a = 100,A:int a = 100,B:修改后的值:int a = 99(a--)
线程2拿A的值与主内存V的值进行比较,判断是否相等(目前不相等,因为 线程1已更新V的值99)
不相等,则线程2更新失败
- 自旋锁操作
因为没有加锁,所以线程不会陷入阻塞,效率较高
如果竞争激烈,重试频繁发生,效率会受影响

需要不断尝试获取共享内存V中最新的值,然后再在新的值的基础上进行更新操 作,如果失败就继续尝试获取新的值,直到更新成功。
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
举一个简单的例子:假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
- 操作员 A 此时将其读出(
version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。 - 在操作员 A 操作的过程中,操作员 B 也读入此用户信息(
version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。 - 操作员 A 完成了修改工作,将数据版本号(
version=1 ),连同帐户扣除后余额(balance=$50 ),提交至数据库更新,此时由于提交数据版本等于数据库记录当前版本,数据被更新,数据库记录version更新为 2 。 - 操作员 B 完成了操作,也将版本号(
version=1 )试图向数据库提交数据(balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 1 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须等于当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员 A 的操作结果的可能。
- CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量, 就算改了也没关系,我吃亏点再重试呗。
- synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改 共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。
CAS算法存在哪些问题
ABA 问题是 CAS 算法最常见的问题。
- ABA 问题
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 "ABA"问题。
ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。JDK 1.5 以后的 AtomicStampedReference 类就是用来解决 ABA 问题的,其中的 compareAndSet() 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
- 循环时间长开销大
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
如果 JVM 能支持处理器提供的 pause 指令那么效率会有一定的提升,pause 指令有两个作用:
- 可以延迟流水线执行指令,使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。
- 可以避免在退出循环的时候因内存顺序冲突而引起 CPU 流水线被清空,从而提高 CPU 的执行效率。
- 只能保证一个共享变量的原子操作
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5 开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作。
总结
- 高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行。乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹。不过,如果冲突频繁发生(写占比非常多的情况),会频繁失败和重试,这样同样会非常影响性能,导致 CPU 飙升。
- 乐观锁一般会使用版本号机制或 CAS 算法实现,CAS 算法相对来说更多一些,这里需要格外注意。
- CAS 的全称是 Compare And Swap(比较与交换) ,用于实现乐观锁,被广泛应用于各大框架中。CAS 的思想很简单,就是用一个预期值和要更新的变量值进行比较,两值相等才会进行更新。
- CAS 算法的问题:ABA 问题、循环时间长开销大、只能保证一个共享变量的原子操作。
synchronized关键字
原理
synchronized 是 Java 中的一个关键字,翻译成中文是同步的意思,主要解决的是多个线程之间访问资源的同步性,可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。synchronized 属于悲观锁。synchronized 底层使用的JVM级别中的Monitor 来决定当前线程是否获得了锁。
- Synchronized【对象锁】采用互斥的方式让同一时刻至多只有一个线程能持有 【对象锁】,其它线程再想获取这个【对象锁】时就会阻塞住
- 它的底层由monitor实现的,monitor是jvm级别的对象( C++实现),线程获得锁需要使用对象(锁)关联monitor,相对性能也比较低。
- 在monitor内部有三个属性,分别是owner、entrylist、waitset
- 其中owner是关联的获得锁的线程,并且只能关联一个线程;entrylist关联的 是处于阻塞状态的线程;waitset关联的是处于Waiting状态的线程
Monitor
monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因
monitor内部维护了三个变量
-
WaitSet:保存处于Waiting状态的线程
-
EntryList:保存处于Blocked状态的线程
-
Owner:持有锁的线程
只有一个线程获取到的标志就是在monitor中设置成功了Owner,一个 monitor中只能有一个Owner 在上锁的过程中,如果有其他线程也来抢锁,则进入EntryList 进行阻塞,当 获得锁的线程执行完了,释放了锁,就会唤醒EntryList 中等待的线程竞争锁,竞争的时候是非公平的。
- Synchronized【对象锁】采用互斥的方式让同一时刻至多只有一个线程能持 有【对象锁】
- 它的底层由monitor实现的,monitor是jvm级别的对象( C++实现),线程获 得锁需要使用对象(锁)关联monitor
- 在monitor内部有三个属性,分别是owner、entrylist、waitset
- 其中owner是关联的获得锁的线程,并且只能关联一个线程;entrylist关联的 是处于阻塞状态的线程;waitset关联的是处于Waiting状态的线程
如何使用 synchronized?
synchronized 关键字的使用方式主要有下面 3 种:
-
修饰实例方法
(锁当前对象实例)给当前对象实例加锁,进入同步代码前要获得 当前对象实例的锁 。
synchronized void method() { //业务代码 } -
修饰静态方法
(锁当前类)给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 当前 class 的锁。
这是因为静态成员不属于任何一个实例对象,归整个类所有,不依赖于类的特定实例,被类的所有实例共享。
synchronized static void method() { //业务代码 }静态
synchronized方法和非静态synchronized方法之间的调用互斥么?不互斥!如果一个线程 A 调用一个实例对象的非静态synchronized方法,而线程 B 需要调用这个实例对象所属类的静态synchronized方法,是允许的,不会发生互斥现象,因为访问静态synchronized方法占用的锁是当前类的锁,而访问非静态synchronized方法占用的锁是当前实例对象锁。 -
修饰代码块
(锁指定对象/类)
synchronized(object)表示进入同步代码库前要获得 给定对象的锁。synchronized(类.class)表示进入同步代码前要获得 给定 Class 的锁
synchronized(this) {
//业务代码
}
总结:
synchronized关键字加到static静态方法和synchronized(class)代码块上都是是给 Class 类上锁;synchronized关键字加到实例方法上是给对象实例上锁;- 尽量不要使用
synchronized(String a)因为 JVM 中,字符串常量池具有缓存功能。
synchronized在高并发量的情况下,性能不高,在项目该如何控制使用锁呢?
在高并发下,我们可以采用ReentrantLock来加锁。
synchronized 和 volatile 区别
synchronized 关键字和 volatile 关键字是两个互补的存在,而不是对立的存在!
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好 。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块 。volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。volatile关键字主要用于解决变量在多个线程之间的可见性,而synchronized关键字解决的是多个线程之间访问资源的同步性。
synchronized和Lock区别
- 语法层面
synchronized 是关键字,源码在 jvm 中,用 c++ 语言实现 ,使用 synchronized 时,退出同步代码块锁会自动释放,
Lock 是接口,源码由 jdk 提供,用 java 语言实现 而使用 Lock 时, 需要手动调用 unlock 方法释放锁
- 功能层面
二者均属于悲观锁、都具备基本的互斥、同步、锁重入功能
Lock 提供了许多 synchronized 不具备的功能,例如获取等待状态、公平锁、可打断、可超时、多条件变量
Lock 有适合不同场景的实现,如 ReentrantLock, ReentrantReadWriteLock
-
性能层面
在没有竞争时,synchronized 做了很多优化,如偏向锁、轻量级锁,性能不赖
在竞争激烈时,Lock 的实现通常会提供更好的性能
锁的形式/锁升级的形式
Java中的synchronized有偏向锁、轻量级锁、重量级锁三种形式,分别对应了锁 只被一个线程持有、不同线程交替持有锁、多线程竞争锁三种情况。
重量级锁:
底层使用的Monitor实现,里面涉及到了用户态和内核态的切换、进程的上下文切换,成本较高,性能比较低。
轻量级锁:
线程加锁的时间是错开的(也就是没有竞争),可以使用轻量级锁来优化。轻量级修改了对象头的锁标志,相对重量级锁性能提升很多。每次修改都是CAS操作,保证原子性
偏向锁:
一段很长的时间内都只被一个线程使用锁,可以使用了偏向锁,在第一次获得锁时,会有一个CAS操作,之后该线程再获取锁,只需要判
断 mark word中是否是自己的线程id即可,而不是开销相对较大的CAS命令。
一旦锁发生了竞争,都会升级为重量级锁
AQS
全称是 AbstractQueuedSynchronizer,是阻塞式锁和相关的同步器工具的框架, 它是构建锁或者其他同步组件的基础框架
比较典型的AQS实现类ReentrantLock,它默认就是非公平锁,新的线程与队列中的线程共同来抢资源。
内部有一个属性 state 属性来表示资源的状态,默认state等于0,表示没有获 取锁,state等于1的时候才标明获取到了锁。通过cas 机制设置 state 状态
在它的内部还提供了基于 FIFO 的等待队列,是一个双向列表,其中
- tail 指向队列最后一个元素
- head 指向队列中最久的一个元素
ReentrantLock底层的实现就是一个AQS。
AQS与Synchronized的区别
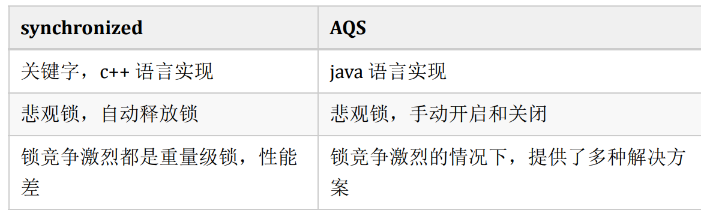
工作机制
- 在AQS中维护了一个使用了volatile修饰的state属性来表示资源的状态,0表示无锁,1表示有锁
- 提供了基于 FIFO 的等待队列,类似于 Monitor 的 EntryList
- 条件变量来实现等待、唤醒机制,支持多个条件变量,类似于 Monitor 的 WaitSet
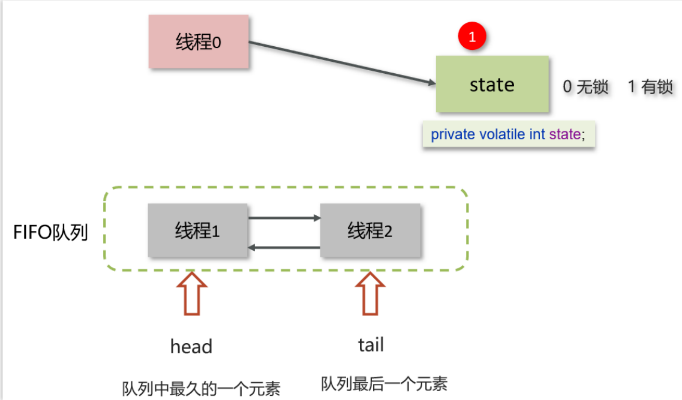
线程0来了以后,去尝试修改state属性,如果发现state属性是0,就修改state状态 为1,表示线程0抢锁成功
线程1和线程2也会先尝试修改state属性,发现state的值已经是1了,有其他线程持 有锁,它们都会到FIFO队列中进行等待,
FIFO是一个双向队列,head属性表示头结点,tail表示尾结点
如果多个线程共同去抢这个资源是如何保证原子性的呢?
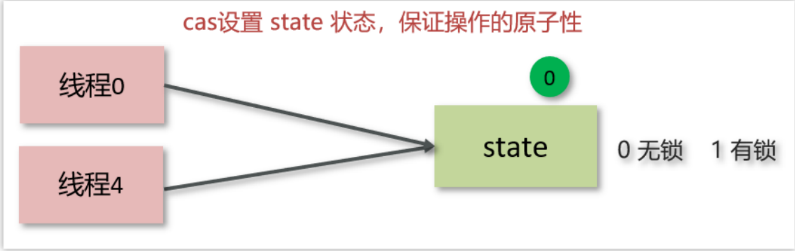
在去修改state状态的时候,使用的cas自旋锁来保证原子性,确保只能有一个线 程修改成功,修改失败的线程将会进入FIFO队列中等待。
AQS是公平锁吗,还是非公平锁?
- 新的线程与队列中的线程共同来抢资源,是非公平锁
- 新的线程到队列中等待,只让队列中的head线程获取锁,是公平锁
ReentrantLock
- ReentrantLock是一个可重入锁:,调用 lock 方 法获取了锁之后,再次调用 lock,是不会再阻塞,内部直接增加重入次数 就行了,标识这个线程已经重 复获取一把锁而不需要等待锁的释放。
- ReentrantLock是属于juc报下的类,属于api层面的锁,跟synchronized一 样,都是悲观锁。通过lock()用来获取锁,unlock()释放锁。
- 它的底层实现原理主要利用CAS+AQS队列来实现。它支持公平锁和非公平锁,两者的实现类似
- 构造方法接受一个可选的公平参数(默认非公平锁),当设置为true时,表 示公平锁,否则为非公平锁。公平锁的效率往往没有非公平锁的效率高。
公平锁和非公平锁有什么区别
公平锁按照请求的顺序来授予锁,确保所有线程都能公平地获取锁。这意味着锁的分配遵循“先到先得”的原则,不会出现线程“饥饿”的情况。公平锁的特点包括:
- 顺序性:公平锁会维护一个队列,当一个线程请求锁时,如果锁被占用,该线程会被添加到队列的尾部。当锁被释放时,队列头部的线程会首先获得锁。
- 避免线程饥饿:由于请求锁的线程按顺序获取锁,不会有线程一直得不到锁的情况,避免了线程饥饿问题。
- 性能开销:由于需要维护队列和顺序,公平锁在性能上可能会有一定的开销,相比非公平锁来说稍微慢一些。
非公平锁在授予锁时不考虑请求的顺序,这意味着任何线程在任何时候都有可能获取锁。非公平锁的特点包括:
- 随机性:非公平锁不会保证线程按照请求顺序获取锁,锁的授予可能是随机的或基于其他调度策略。
- 可能的线程饥饿:由于没有顺序保证,一些线程可能会长时间得不到锁,导致线程饥饿。
- 高性能:非公平锁不需要维护请求顺序,因此在性能上通常比公平锁更高效,特别是在竞争不激烈的情况下。
选择公平锁还是非公平锁
- 公平锁适用于需要严格控制线程访问顺序的场景,确保每个线程都能公平地获取锁,适用于需要避免线程饥饿的系统。
- 非公平锁适用于高性能需求的场景,特别是当锁的争用不激烈时,非公平锁能够提供更高的吞吐量。
可中断锁和不可中断锁有什么区别
ThreadLocal
ThreadLocal 有什么用
通常情况下,创建的变量是可以被任何一个线程访问并修改的。如果想实现每一个线程都有自己的专属本地变量该如何解决呢?
ThreadLocal是多线程中对于解决线程安全的一个操作类,它会为每个线程都分 配一个独立的线程副本从而解决了变量并发访问冲突的问题。ThreadLocal 同时 实现了线程内的资源共享。
JDK 中自带的ThreadLocal类正是为了解决这样的问题。 ThreadLocal类主要解决的就是让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。
如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是ThreadLocal变量名的由来。他们可以使用 get() 和 set() 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。
再举个简单的例子:两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
嗯,知道一些~ 在ThreadLocal内部维护了一个一个 ThreadLocalMap 类型的成员变量,用来 存储资源对象
调用 set 方法,就是以 ThreadLocal 自己作为 key,资源对象作为 value,放入当前线程的 ThreadLocalMap 集合中
调用 get 方法,就是以 ThreadLocal 自己作为 key,到当前线程中查找关联的资源值
调用 remove 方法,就是以 ThreadLocal 自己作为 key,移除当前线程关联的资源值
ThreadLocal基本使用
三个主要方法:
- set(value) 设置值
- get() 获取值
- remove() 清除值
ThreadLocal的实现原理&源码解析
ThreadLocal本质来说就是一个线程内部存储类,从而让多个线程只操作自己内部的值,从而实现线程数据隔离
在ThreadLocal中有一个内部类叫做ThreadLocalMap,类似于HashMap
ThreadLocalMap中有一个属性table数组,这个是真正存储数据的位置
ThreadLocal-内存泄露问题
是应为ThreadLocalMap 中的 key 被设计为弱引用,它是被动的被GC调用释 放key,不过关键的是只有key可以得到内存释放,而value不会,因为value 是一个强引用。
在使用ThreadLocal 时都把它作为静态变量(即强引用),因此无法被动依 靠 GC 回收,建议主动的remove 释放 key,这样就能避免内存溢出
线程池
线程池就是一个可以复用线程的技术。
不使用线程池会有什么问题:
假设:用户每次发起一个请求给后台,后台就创建一个新的线程来处理,下次新的任务过来肯定也会创建新的线程,如果用户量非常大,创建的线程也讲越来越多。然而,创建线程是开销很大的,并且请求过多时,会严重影响系统性能。
线程池内部会有一个容器,存储几个核心线程,假设有3个核心线程,这3个核心线程可以处理3个任务。
但是任务总有被执行完的时候,假设第1个线程的任务执行完了,那么第1个线程就空闲下来了,有新的任务时,空闲下来的第1个线程可以去执行其他任务。依此内推,这3个线程可以不断的复用,也可以执行很多个任务。
线程池就是一个线程复用技术,它可以提高线程的利用率。
提到的来说一下使用线程池的好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池的核心参数
线程池核心参数主要参考ThreadPoolExecutor这个类的7个参数的构造函数
- corePoolSize 核心线程数目 -核心线程数目是线程池中会保留的最多线程数,即使这些线程处于空闲状态也不会被终止。
- maximumPoolSize 最大线程数目 = (核心线程+救急线程的最大数目) 救急线程是临时的,当它们完成任务并在一定的生存时间内没有新任务到达时,这些线程会被终止。
- keepAliveTime 生存时间 - 救急线程的生存时间,生存时间内没有新任务,此线程资源会释放
- unit 时间单位 - 救急线程的生存时间单位,如秒、毫秒等
- workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- threadFactory 线程工厂 - 可以定制线程对象的创建,例如设置线程名字、是 否是守护线程等
- handler 拒绝策略 - 当所有线程都在繁忙,workQueue 也放满时,会触发拒绝 策略
在拒绝策略中又有4中拒绝策略 当线程数过多以后,
- 第一种是抛异常、
- 第二种是由调用者执行任务、
- 第三 是丢弃当前的任务,
- 第四是丢弃最早排队任务。默认是直接抛异常。
线程池的执行原理/工作流程
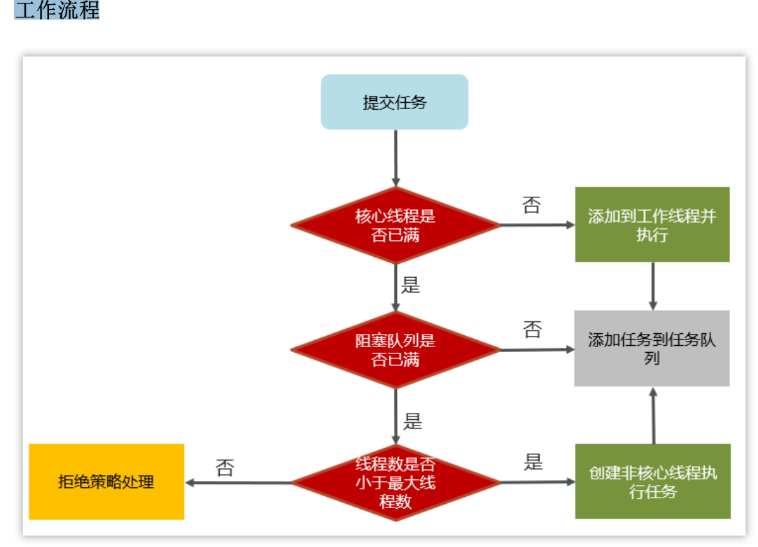
1,任务在提交的时候,首先判断核心线程数是否已满,如果没有满则直接 添加到工作线程执行
2,如果核心线程数满了,则判断阻塞队列是否已满,如果没有满,当前任务存入阻塞队列
3,如果阻塞队列也满了,则判断线程数是否小于最大线程数,如果满足条 件,则使用临时线程执行任务 如果核心或临时线程执行完成任务后会检查阻塞队列中是否有需要执行的线 程,如果有,则使用非核心线程执行任务
4,如果所有线程都在忙着(核心线程+临时线程),则走拒绝策略
线程池的种类
- 创建使用固定线程数的线程池
核心线程数与最大线程数一样,没有救急线程
适用场景:适用于任务量已知,相对耗时的任务
- 单线程化的线程池,它只会用唯一的工作线程来执行任 务,保证所有任务按 照指定顺序(FIFO)执行
核心线程数和最大线程数都是1
适用场景:适用于按照顺序执行的任务
- 可缓存线程池
核心线程数为0
适用场景:适合任务数比较密集,但每个任务执行时间较短的情况
- 提供了“延迟”和“周期执行”功能的ThreadPoolExecutor。
适用场景:有定时和延迟执行的任务
线程池中有哪些常见的阻塞队列
比较常见的有4个,用的最多是ArrayBlockingQueue和LinkedBlockingQueue
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO。
- LinkedBlockingQueue:基于链表结构的有界阻塞队列,FIFO。
- DelayedWorkQueue :是一个优先级队列,它可以保证每次出队的任务都是当 前队列中执行时间最靠前的
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
创建线程池方式
线程池执行的任务可以有两种,一种是Runnable任务;一种是callable任务。
线程池执行Runnable任务
execute方法可以用来执行Runnable任务。
线程池执行Callable任务
学习使用线程池执行Callable任务。callable任务相对于Runnable任务来说,就是多了一个返回值。
线程池工具类(Executors)
方式一:通过ThreadPoolExecutor构造函数来创建(推荐)。
方式二:通过 Executor 框架的工具类 Executors 来创建。
不建议用Executors创建线程池
主要原因是如果使用Executors创建线程池的话,它允许的请求队列默认长度/允许创建的线程数量 是Integer.MAX_VALUE,有可能导致堆积大量的请求/创建大量的线程,从而导致内存溢出。
所以,我们一般推荐使用ThreadPoolExecutor来创建线程池,这样可以明确规定线程池的参数,避免资源的耗尽。

线程池中线程异常后,销毁还是复用?
先说结论,需要分两种情况:
- 使用
execute()提交任务:当任务通过execute()提交到线程池并在执行过程中抛出异常时,如果这个异常没有在任务内被捕获,那么该异常会导致当前线程终止,并且异常会被打印到控制台或日志文件中。线程池会检测到这种线程终止,并创建一个新线程来替换它,从而保持配置的线程数不变。 - 使用
submit()提交任务:对于通过submit()提交的任务,如果在任务执行中发生异常,这个异常不会直接打印出来。相反,异常会被封装在由submit()返回的Future对象中。当调用Future.get()方法时,可以捕获到一个ExecutionException。在这种情况下,线程不会因为异常而终止,它会继续存在于线程池中,准备执行后续的任务。
简单来说:使用execute()时,未捕获异常导致线程终止,线程池创建新线程替代;使用submit()时,异常被封装在Future中,线程继续复用。
这种设计允许submit()提供更灵活的错误 处理机制,因为它允许调用者决定如何处理异常,而execute()则适用于那些不需要关注执行结果的场景。
设定线程池大小/核心线程数?
并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?
线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了上下文切换成本。
上下文切换:
多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。
- 如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的,CPU 根本没有得到充分利用。
- 如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
有一个简单并且适用面比较广的公式:
N为计算机的CPU核数
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
如何判断是 CPU 密集任务还是 IO 密集任务?
- CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序,例如计算型代码、Bitmap转换、Gson转换。
- 涉及到文件读写、DB读写、网络请求这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
Future 类
场景题
新建 T1、T2、T3 三个线程,如何保证按顺序执行?
嗯~~,我思考一下 (适当的思考或想一下属于正常情况,脱口而出反而太假[背诵痕迹])
你可以用线程类的join()方法在 一个线程中启动另一个线程,另外一个线程完成该线程继续执行。
代码举例: 为了确保三个线程的顺序你应该先启动最后一个(T3调用T2,T2调用T1),这样 T1就会先完成而T3最后完成
public class JoinTest {
public static void main(String[] args) {
// 创建线程对象
Thread t1 = new Thread(() -> {
System.out.println("t1");
}) ;
Thread t2 = new Thread(() -> {
try {
t1.join(); // 加入线程t1,只有t1线程执行完毕以后,再次执行该线程
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t2");
}) ;
Thread t3 = new Thread(() -> {
try {
t2.join(); // 加入线程t2,只有t2线程执行完毕以后,再次执行该线程 notifyAll:唤醒所有wait的线程notify:只随机唤醒一个 wait 线程
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("t3");
}) ;
// 启动线程
t1.start();
t2.start();
t3.start();
}
}
如果控制某一个方法允许并发访问线程的数量
嗯~~,我想一下 在jdk中提供了一个Semaphore[seməfɔːr]类(信号量) 它提供了两个方法,semaphore.acquire() 请求信号量,可以限制线程的个 数,是一个正数,如果信号量是-1,就代表已经用完了信号量,其他线程需要 阻塞了
第二个方法是semaphore.release(),代表是释放一个信号量,此时信号量的 个数+1
你在项目中哪里用了多线程?
嗯~~,我想一下当时的场景[根据自己简历上的模块设计多线程场景]
参考场景一: es数据批量导入 在我们项目上线之前,我们需要把数据量的数据一次性的同步到es索引库 中,但是当时的数据好像是1000万左右,一次性读取数据肯定不行(oom异 常),如果分批执行的话,耗时也太久了。所以,当时我就想到可以使用线 程池的方式导入,利用CountDownLatch+Future来控制,就能大大提升导入 的时间。
参考场景二: 在我做那个xx电商网站的时候,里面有一个数据汇总的功能,在用户下单之 后需要查询订单信息,也需要获得订单中的商品详细信息(可能是多个), 还需要查看物流发货信息。因为它们三个对应的分别三个微服务,如果一个 一个的操作的话,互相等待的时间比较长。所以,我当时就想到可以使用线 程池,让多个线程同时处理,最终再汇总结果就可以了,当然里面需要用到 Future来获取每个线程执行之后的结果才行
参考场景三: 《黑马头条》项目中使用的 我当时做了一个文章搜索的功能,用户输入关键字要搜索文章,同时需要保 存用户的搜索记录(搜索历史),这块我设计的时候,为了不影响用户的正 常搜索,我们采用的异步的方式进行保存的,为了提升性能,我们加入了线 程池,也就说在调用异步方法的时候,直接从线程池中获取线程使用
JVM
JVM组成
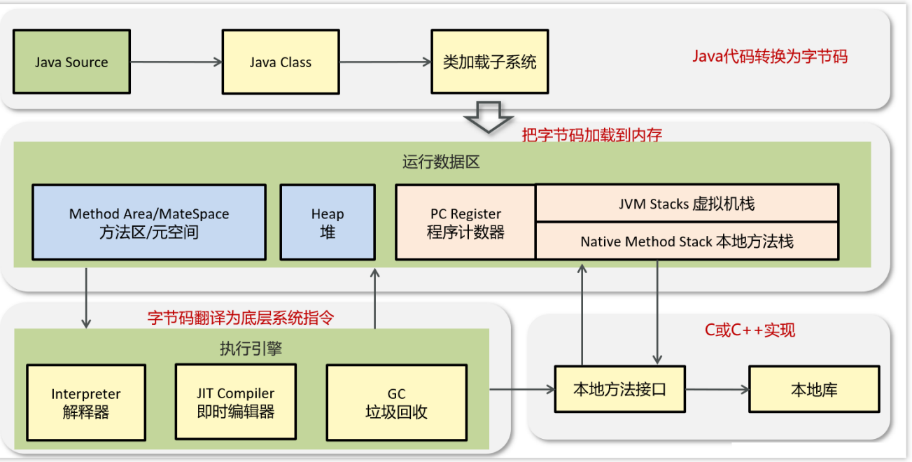
JVM 的主要组成部分
- ClassLoader(类加载器)
- Runtime Data Area(运行时数据区,内存分区)
- Execution Engine(执行引擎)
- Native Method Library(本地库接口)
运行流程:
- 类加载器:把Java代码转换为字节码
- 运行时数据区:把字节码加载到内存中,而字节码文 件只是JVM的一套指令集规范,并不能直接交给底层系统去执行,而是有执行引擎运行
- 执行引擎:将字节码翻译为底层系统指令,再交由CPU 执行去执行,此时需要调用其他语言的本地库接口来实现整个程序的功能。
Java内存区域详解
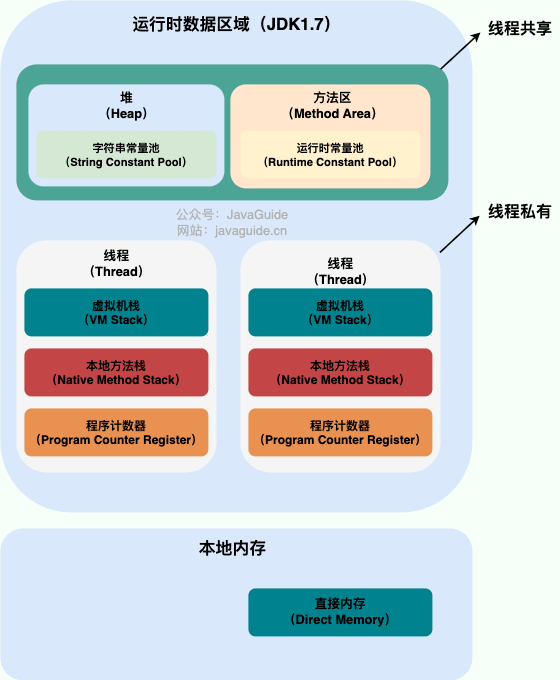
线程私有的:
- 程序计数器
- 虚拟机栈
- 本地方法栈
线程共享的:
- 堆
- 方法区
- 直接内存 (非运行时数据区的一部分)
运行时数据区域
程序计数器
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。
为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
注意:程序计数器是唯一一个不会出现 OutOfMemoryError 的内存区域,它的生命周期随着线程的创建而创建,随着线程的结束而死亡,所以程序计数器不会进行GC。
java虚拟机对于多线程是通过线程轮流切换并且分配线程执行时间。在任何的一个时间点上,一个处理器只会处理执行一个线程,如果当前被执行的这 个线程它所分配的执行时间用完了【挂起】。处理器会切换到另外的一个线 程上来进行执行。并且这个线程的执行时间用完了,接着处理器就会又来执行被挂起的这个线程。这时候程序计数器就起到了关键作用,程序计数器在来回切换的线程中记录他上一次执行的行号,然后接着继续向下执行。
堆
Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。
此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
Java 堆是垃圾收集器管理的主要区域,因此也被称作 GC 堆(Garbage Collected Heap)。从垃圾回收的角度,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆还可以细分为:新生代和老年代;再细致一点有:Eden、Survivor、Old 等空间。进一步划分的目的是更好地回收内存,或者更快地分配内存。
在 JDK 7 版本及 JDK 7 版本之前,堆内存被通常分为下面三部分:
- 新生代内存(Young Generation)
- 老生代(Old Generation)
- 永久代(Permanent Generation)
JDK 8 版本之后 PermGen(永久代) 已被 Metaspace(元空间) 取代,元空间使用的是本地内存。
为了避免方法区出现OOM,所以在java8中将堆上的方法区【永久代】给移动到了本地内存上,重新开辟了一块空间,叫做元空间。
在JAVA8中堆内会存在年轻代、老年代
- Young区被划分为三部分,Eden区和两个大小严格相同的Survivor区, 其中,Survivor区间中,某一时刻只有其中一个是被使用的,另外一个留做 垃圾收集时复制对象用。在Eden区变满的时候, GC就会将存活的对象移到 空闲的Survivor区间中,根据JVM的策略,在经过几次垃圾收集后,任然存 活于Survivor的对象将被移动到Tenured区间。
- Tenured区主要保存生命周期长的对象,一般是一些老的对象,当一些 对象在Young复制转移一定的次数以后,对象就会被转移到Tenured区。
方法区
方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。主要存储类的信息、运行时常量池。
方法区和永久代以及元空间的关系

方法区和永久代以及元空间的关系很像 Java 中接口和类的关系,类实现了接口,这里的类就可以看作是永久代和元空间,接口可以看作是方法区,也就是说永久代以及元空间是 HotSpot 虚拟机对虚拟机规范中方法区的两种实现方式。
永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。
为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?
1、整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整(也就是受到 JVM 内存的限制),而元空间使用的是本地内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
Java虚拟机栈
虚拟机栈是描述的是方法执行时的内存模型,是线程私有的,生命周期与线程 相同,每个方法被执行的同时会创建栈桢。保存执行方法时的局部变量、动 态连接信息、方法返回地址信息等等。方法开始执行的时候会进栈,方法执行完会出栈【相当于清空了数据】,所以这块区域不需要进行GC。
与程序计数器一样,Java 虚拟机栈(后文简称栈)也是线程私有的,它的生命周期和线程相同,随着线程的创建而创建,随着线程的死亡而死亡。
- 每个线程运行时所需要的内存,称为虚拟机栈,先进后出
- 每个栈由多个栈帧(frame)组成,对应着每次方法调用时所占用的内存
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
垃圾回收是否涉及栈内存?
垃圾回收主要指就是堆内存,当栈帧弹栈以后,内存就会释放
栈内存分配越大越好吗?
未必,默认的栈内存通常为1024k 栈帧过大会导致线程数变少,例如,机器总内存为512m,目前能活动的线程 数则为512个,如果把栈内存改为2048k,那么能活动的栈帧就会减半
本地方法栈
和虚拟机栈所发挥的作用非常相似,区别是:虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
运行时常量池
存放编译期生成的各种字面量(Literal)和符号引用(Symbolic Reference)的常量池表(Constant Pool Table) 。
常量池表会在类加载后存放到方法区的运行时常量池中。
字符串常量池
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
// 在堆中创建字符串对象”ab“
// 将字符串对象”ab“的引用保存在字符串常量池中
String aa = "ab";
// 直接返回字符串常量池中字符串对象”ab“的引用
String bb = "ab";
System.out.println(aa==bb);// true
直接内存
JDK1.4 中新加入的 NIO(Non-Blocking I/O,也被称为 New I/O),引入了一种基于通道(Channel)*与*缓存区(Buffer)*的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为*避免了在 Java 堆和 Native 堆之间来回复制数据。
不受 JVM 内存回收管理,是虚拟机的系统内存,常见于 NIO 操作时,用于数据缓冲区,分配回收成本较高,但读写性能高,不受 JVM 内存回收管理。
它又叫做堆外内存,线程共享的区域,在 Java 8 之前有个永久代的概念,实 际上指的是 HotSpot 虚拟机上的永久代,它用永久代实现了 JVM 规范定义的 方法区功能,主要存储类的信息,常量,静态变量,即时编译器编译后代码 等,这部分由于是在堆中实现的,受 GC 的管理,不过由于永久代有 - XX:MaxPermSize 的上限,所以如果大量动态生成类(将类信息放入永久 代),很容易造成 OOM,有人说可以把永久代设置得足够大,但很难确定 一个合适的大小,受类数量,常量数量的多少影响很大。 所以在 Java 8 中就把方法区的实现移到了本地内存中的元空间中,这样方法区就不受 JVM 的控制了,也就不会进行 GC,也因此提升了性能。
JVM 运行时数据区总结
组成部分:堆、方法区、栈、本地方法栈、程序计数器
- 堆解决的是对象实例存储的问题,垃圾回收器管理的主要区域。
- 方法区可以认为是堆的一部分,用于存储已被虚拟机加载的信息,常量、静 态变量、即时编译器编译后的代码。
- 栈解决的是程序运行的问题,栈里面存的是栈帧,栈帧里面存的是局部变量 表、操作数栈、动态链接、方法出口等信息。
- 本地方法栈与栈功能相同,本地方法栈执行的是本地方法,一个Java调用非 Java代码的接口。
- 程序计数器(PC寄存器)程序计数器中存放的是当前线程所执行的字节码的 行数。JVM工作时就是通过改变这个计数器的值来选取下一个需要执行的字节码 指令。
堆和栈的区别
- 栈内存一般会用来存储局部变量和方法调用,但堆内存是用来存储Java对象和数组的的。堆会GC垃圾回收,而栈不会。
- 栈内存是线程私有的,而堆内存是线程共有的。
- 两者异常错误不同,但如果栈内存或者堆内存不足都会抛出异常。
栈空间不足:java.lang.StackOverFlowError。 堆空间不足:java.lang.OutOfMemoryError。
JVM垃圾回收详解
为了让程序员更专注于代码的实现,而不用过多的考虑内存释放的问题,
在Java语言中,有了自动的垃圾回收机制,也就是我们熟悉的GC(Garbage Collection)。
有了垃圾回收机制后,程序员只需要关心内存的申请即可,内存的释放由系统自动识别完成。
在进行垃圾回收时,不同的对象引用类型,GC会采用不同的回收时机。
堆空间的基本结构
Java 的自动内存管理主要是针对对象内存的回收和对象内存的分配。同时,Java 自动内存管理最核心的功能是 堆 内存中对象的分配与回收。
Java 堆是垃圾收集器管理的主要区域,因此也被称作 GC 堆(Garbage Collected Heap)。
从垃圾回收的角度来说,由于现在收集器基本都采用分代垃圾收集算法,所以 Java 堆被划分为了几个不同的区域,这样我们就可以根据各个区域的特点选择合适的垃圾收集算法。
在 JDK 7 版本及 JDK 7 版本之前,堆内存被通常分为下面三部分:
- 新生代内存(Young Generation)
- 老生代(Old Generation)
- 永久代(Permanent Generation)
下图所示的 Eden 区、两个 Survivor 区 S0 和 S1 都属于新生代,中间一层属于老年代,最下面一层属于永久代。
JDK 8 版本之后 PermGen(永久) 已被 Metaspace(元空间) 取代,元空间使用的是直接内存 。
新生代、老年代、永久代的区别
- 新生代主要用来存放新生的对象。
- 老年代主要存放应用中生命周期长的内存对象。
- 永久代指的是永久保存区域。主要存放Class和Meta(元数据)的信息。在 Java8中,永久代已经被移除,取而代之的是一个称之为“元数据区”(元空 间)的区域。元空间和永久代类似,不过元空间与永久代之间最大的区别在 于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空 间的大小仅受本地内存的限制。
内存分配和回收原则
对象优先在 Eden 区分配
Minor GC是JVM中的一种垃圾收集机制,主要用于清理新生代(Young Generation)中的垃圾对象。
大多数情况下,对象在新生代中 Eden 区分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。
大对象直接进入老年代
大对象就是需要大量连续内存空间的对象(比如:字符串、数组)。
大对象直接进入老年代的行为是由虚拟机动态决定的,它与具体使用的垃圾回收器和相关参数有关。
大对象直接进入老年代是一种优化策略,旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本。
长期存活的对象将进入老年代
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。
为了做到这一点,虚拟机给每个对象一个对象年龄(Age)计数器。
大部分情况,对象都会首先在 Eden 区域分配。如果对象在 Eden 出生并经过第一次 Minor GC 后仍然能够存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间(s0 或者 s1)中,并将对象年龄设为 1(Eden 区->Survivor 区后对象的初始年龄变为 1)。
对象在 Survivor 中每熬过一次 MinorGC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。
主要进行 gc 的区域
针对 HotSpot VM 的实现,它里面的 GC 其实准确分类只有两大种:
部分收集 (Partial GC):
- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
- 混合收集(Mixed GC):对整个新生代和部分老年代进行垃圾收集。
整堆收集 (Full GC):收集整个 Java 堆和方法区。
空间分配担保
空间分配担保是为了确保在 Minor GC 之前老年代本身还有容纳新生代所有对象的剩余空间。
死亡对象判断方法
如果一个或多个对象没有任何的引用指向它了,那么这个对象现在就是垃圾,如果定位了垃圾,则有可能会被垃圾回收器回收。
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断哪些对象已经死亡(即不能再被任何途径使用的对象)。
引用计数法
给对象中添加一个引用计数器:
- 每当有一个地方引用它,计数器就加 1;
- 当引用失效,计数器就减 1;
- 任何时候计数器为 0 的对象就是不可能再被使用的。
这个方法实现简单,效率高。
但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间循环引用的问题。
所谓对象之间的相互引用问题:除了对象 objA 和 objB 相互引用着对方之外,这两个对象之间再无任何引用。但是他们因为互相引用对方,导致它们的引用计数器都不为 0,于是引用计数算法无法通知 GC 回收器回收他们。
优点:
- 实时性较高,无需等到内存不够的时候,才开始回收,运行时根据对象的计 数器是否为0,就可以直接回收。
- 在垃圾回收过程中,应用无需挂起。如果申请内存时,内存不足,则立刻报 OOM错误。
- 区域性,更新对象的计数器时,只是影响到该对象,不会扫描全部对象。
缺点:
- 每次对象被引用时,都需要去更新计数器,有一点时间开销。
- 浪费CPU资源,即使内存够用,仍然在运行时进行计数器的统计。
- 无法解决循环引用问题,会引发内存泄露。(最大的缺点)
可达性分析算法
通过一系列的称为 “GC Roots” 的对象作为起点,从这些节点开始向下搜索,引出它下面指向的下一个节点,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的,需要被回收。
哪些对象可以作为 GC Roots 呢?
根对象是那些肯定不能当做垃圾回收的对象,就可以当做根对象
- 虚拟机栈(栈帧中的局部变量表)中引用的对象
- 本地方法栈(Native 方法)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 所有被同步锁持有的对象
- JNI(Java Native Interface)引用的对象
对象可以被回收,就代表一定会被回收吗?
当对象被标记为可回收后,当发生GC时,首先会判断这个对象 是否执行了finalize方法,如果这个方法还没有被执行的话,那么就会先来执行 这个方法,接着在这个方法执行中,可以设置当前这个对象与GC ROOTS产生关联,那么这个方法执行完成之后,GC会再次判断对象是否可达,如果仍然不可 达,则会进行回收,如果可达了,则不会进行回收。
finalize方法对于每一个对象来说,只会执行一次。如果第一次执行这个方法的 时候,设置了当前对象与RC ROOTS关联,那么这一次不会进行回收。 那么等到 这个对象第二次被标记为可回收时,那么该对象的finalize方法就不会再次执行 了。
Object类中的finalize方法一直被认为是一个糟糕的设计,成为了 Java 语言的负担,影响了 Java 语言的安全和 GC 的性能。JDK9 版本及后续版本中各个类中的finalize方法会被逐渐弃用移除。忘掉它的存在吧!
引用类型总结
1.强引用(StrongReference)
如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2.软引用(SoftReference)
如果一个对象只具有软引用,那就类似于可有可无的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用适用于缓存等内存敏感的应用场景,可以在内存不足时自动清理。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。
3.弱引用(WeakReference)
如果一个对象只具有弱引用,那就类似于可有可无的生活用品。
弱引用与软引用的区别:弱引用是一种更弱的引用类型,只要垃圾回收器发现了它们,不论当前内存是否充足,都会被回收。弱引用对象的生命周期更短暂。
适用于避免内存泄漏,例如在实现某些数据结构(如映射表)时,通过弱引用确保不再使用的对象可以被及时回收。
在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
4.虚引用(PhantomReference)
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
虚引用主要用来跟踪对象被垃圾回收的活动。
虚引用与软引用和弱引用的一个区别在于: 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
如何判断一个常量是废弃常量
运行时常量池主要回收的是废弃的常量。
假如在字符串常量池中存在字符串 "abc",如果当前没有任何 String 对象引用该字符串常量的话,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"abc" 就会被系统清理出常量池了。
如何判断一个类是无用的类?
方法区主要回收的是无用的类,那么如何判断一个类是无用的类的呢?
类需要同时满足下面 3 个条件才能算是 “无用的类”:
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的
ClassLoader已经被回收。 - 该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
垃圾收集算法
标记-清除算法
标记-清除(Mark-and-Sweep)算法分为“标记(Mark)”和“清除(Sweep)”阶段:首先标记出所有不需要回收的对象,在标记完成后统一回收掉所有没有被标记的对象。
- 根据可达性分析算法得出的垃圾进行标记
- 对这些标记为可回收的内容进行垃圾回收
它是最基础的收集算法,后续的算法都是对其不足进行改进得到。这种垃圾收集算法会带来两个明显的问题:
- 效率问题:标记和清除两个过程效率都不高。标记和清除两个动作都需要遍历所有的对象,并且在GC时,需要停止应用程序,对于交互性要求比较高的应用而言这个体验是非常差的。
- 空间问题:标记清除后会产生大量不连续的内存碎片。因为被回收的对象可能存在于内存的各个角落,所以清理出来的内存是不连贯的。
复制算法
为了解决标记-清除算法的效率和内存碎片问题,复制(Copying)收集算法出现了。
它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉,交换两个内存的角色,完成垃圾的回收。这样就使每次的内存回收都是对内存区间的一半进行回收。
如果内存中的垃圾对象较多,需要复制的对象就较少,这种情况下适合使用该方式并且效率比较高,反之,则不适合。
虽然改进了标记-清除算法,但依然存在下面这些问题:
优点:
- 在垃圾对象多的情况下,效率较高
- 清理后,内存无碎片
缺点:
- 可用内存变小:分配的2块内存空间,在同一个时刻,只能使用一半
- 不适合老年代:如果存活对象数量比较大,复制性能会变得很差。
标记-整理算法
标记-整理(Mark-and-Compact)算法是根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是简单的直接对可回收对象回收,而是让所有存活的对象向内存一端移动,然后直接清理掉端边界以外的内存。从而解决了碎片化的问题
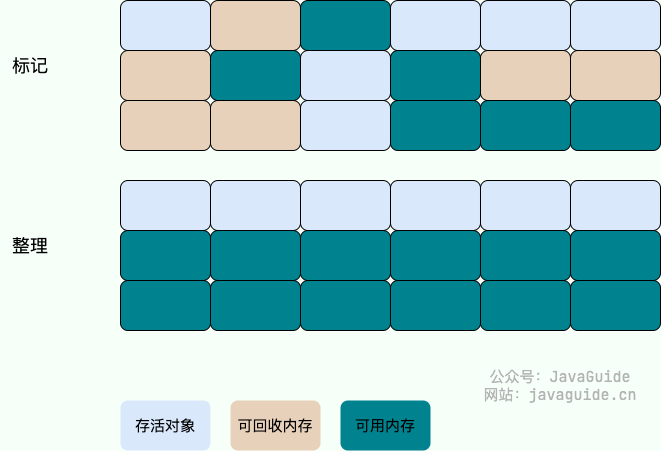
由于多了整理这一步,因此效率也不高,适合老年代这种垃圾回收频率不是很高的场景。
分代收集算法
当前虚拟机的垃圾收集都采用分代收集算法,
只是根据对象存活周期的不同将内存分为几块。一般将 Java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
- 比如在新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。
- 而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
在java8时,堆被分为了两份:新生代和老年代【1:2】,在java7时,还存在一 个永久代。
对于新生代,内部又被分为了三个区域。Eden区,S0区,S1区【8:1:1】
- 当对新生代产生GC:MinorGC【young GC】
- 当对老年代产生GC:Major GC
- 当对新生代和老年代产生FullGC: 新生代 + 老年代完整垃圾回收,暂停时间长, 应尽力避免

工作机制
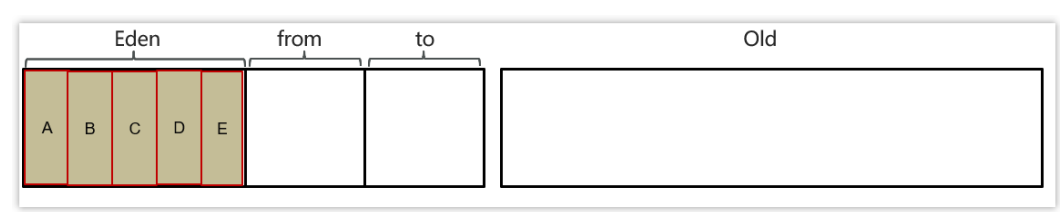
-
新创建的对象,都会先分配到eden区
-
当伊甸园内存不足,标记伊甸园与 from区域的存活对象
-
将存活对象采用复制算法复制到 to 中,复制完毕后,伊甸园和 from 内存都得到释放
-
经过一段时间后伊甸园的内存又出现不足,标记eden区域to区存活的对象, 将存活的对象复制到from区
-
当幸存区对象熬过几次回收(最多15次),晋升到老年代(幸存区内存不足 或大对象会导致提前晋升)
具体的工作机制是有些情况:
1)当创建一个对象的时候,那么这个对象会被分配在新生代的Eden区。当 Eden区要满了时候,触发YoungGC。
2)当进行YoungGC后,此时在Eden区存活的对象被移动到S0区,并且当前 对象的年龄会加1,清空Eden区。
3)当再一次触发YoungGC的时候,会把Eden区中存活下来的对象和S0中的 对象,移动到S1区中,这些对象的年龄会加1,清空Eden区和S0区。
4)当再一次触发YoungGC的时候,会把Eden区中存活下来的对象和S1中的 对象,移动到S0区中,这些对象的年龄会加1,清空Eden区和S1区。
5)对象的年龄达到了某一个限定的值(默认15岁 ),那么这个对象就会进 入到老年代中。
当然也有特殊情况,如果进入Eden区的是一个大对象,在触发YoungGC的时 候,会直接存放到老年代
当老年代满了之后,触发FullGC。FullGC同时回收新生代和老年代,当前只会存在一个FullGC的线程进行执行,其他的线程全部会被挂起。 我们在程序中要尽量避免FullGC的出现。
MinorGC、Major GC、Mixed GC、FullGC的区别
STW(Stop-The-World):暂停所有应用程序线程,等待垃圾回收的完成
- MinorGC【young GC】发生在新生代的垃圾回收,暂停时间短(STW)
- Major GC 老年代区域的垃圾回收,老年代空间不足时,会先尝试触发Minor GC。Minor GC之后空间还不足,则会触发Major GC,Major GC速度比较慢, 暂停时间长
- Mixed GC 新生代 + 老年代部分区域的垃圾回收,G1 收集器特有
- FullGC: 新生代 + 老年代完整垃圾回收,暂停时间长(STW),应尽力避免
垃圾收集/回收器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
串行垃圾收集器
Serial和Serial Old串行垃圾收集器,是指使用单线程进行垃圾回收,堆内存较小,适合个人电脑
- Serial 作用于新生代,采用复制算法
- Serial Old 作用于老年代,采用标记-整理算法
垃圾回收时,只有一个线程在工作,并且java应用中的所有线程都要暂停 (STW),等待垃圾回收的完成。
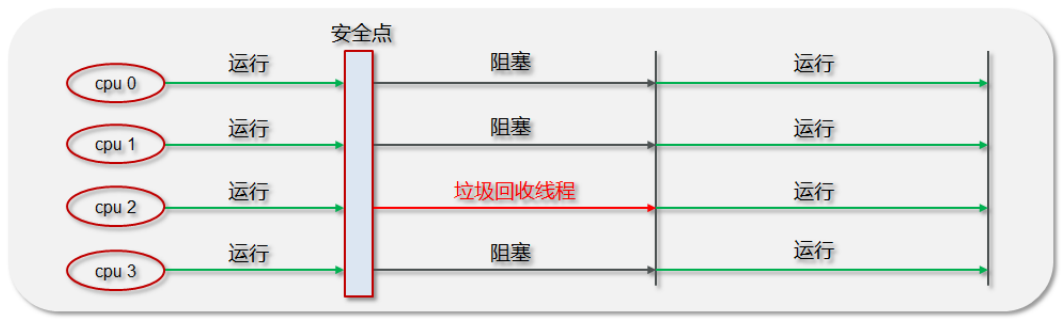
并行垃圾收集器
Parallel New和Parallel Old是一个并行垃圾回收器,JDK8默认使用此垃圾回收器
- Parallel New作用于新生代,采用复制算法
- Parallel Old作用于老年代,采用标记-整理算法
垃圾回收时,多个线程在工作,并且java应用中的所有线程都要暂停(STW), 等待垃圾回收的完成。
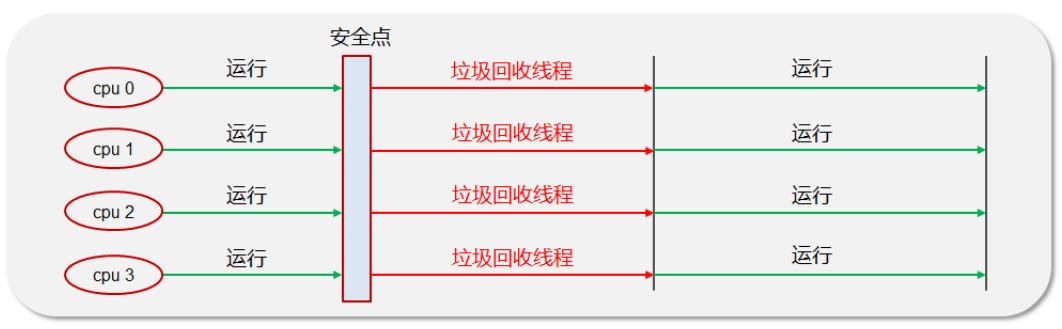
CMS(并发)垃圾收集器
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,该回收器是针对老年代垃圾回收的,是一款以获取最短回收停顿时间为目标的收集器,停顿时间短,用户体验就好。其最大特点是在进行垃圾回收时,应用仍然能正常运行
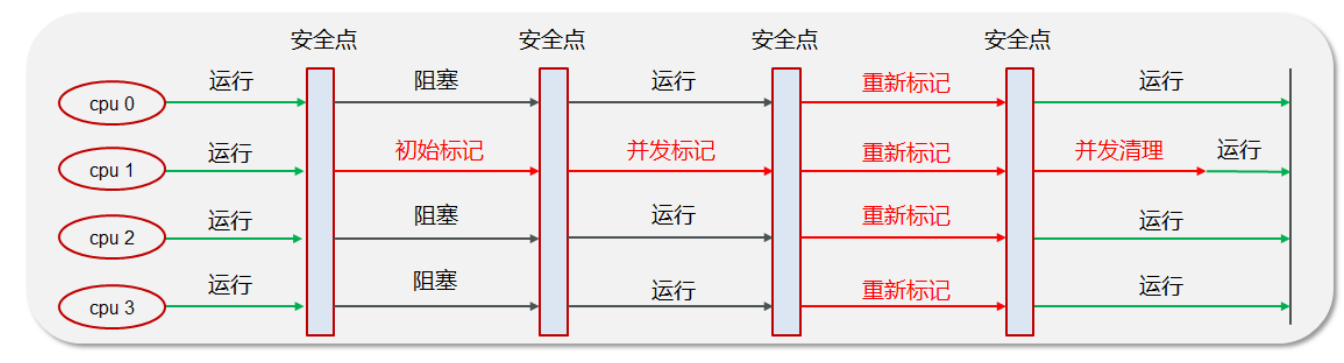
G1垃圾收集器
- 应用于新生代和老年代,在JDK9之后默认使用G1
- 划分成多个区域,每个区域都可以充当 eden,survivor,old, humongous, 其中 humongous 专为大对象准备
- 采用复制算法
- 响应时间与吞吐量兼顾
- 分成三个阶段:新生代回收、并发标记、混合收集
- 如果并发失败(即回收速度赶不上创建新对象速度),会触发 Full GC
年轻代垃圾回收
- 初始时,所有区域都处于空闲状态
- 创建了一些对象,挑出一些空闲区域作为伊甸园区存储这些对象
- 当伊甸园需要垃圾回收时,挑出一个空闲区域作为幸存区,用复制算法复制存活对象,需要暂停用户线程
- 随着时间流逝,伊甸园的内存又有不足
- 将伊甸园以及之前幸存区中的存活对象,采用复制算法,复制到新的幸存 区,其中较老对象晋升至老年代
年轻代垃圾回收+并发标记
- 当老年代占用内存超过阈值(默认是45%)后,触发并发标记,这时无需暂停用户线程
- 并发标记之后,会有重新标记阶段解决漏标问题,此时需要暂停用户线程。
- 这些都完成后就知道了老年代有哪些存活对象,随后进入混合收集阶段。此 时不会对所有老年代区域进行回收,而是根据暂停时间目标优先回收价值高 (存活对象少)的区域(这也是 Gabage First 名称的由来)。
混合垃圾回收
- 复制完成,内存得到释放。进入下一轮的新生代回收、并发标记、混合收集
- 其中H叫做巨型对象,如果对象非常大,会开辟一块连续的空间存储巨型对象
类加载过程详解
类从被加载到虚拟机内存中开始到卸载出内存为止,它的整个生命周期可以简单概括为 7 个阶段::加载(Loading)、**验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。其中,验证、准备和解析这三个阶段可以统称为连接(Linking)**。
类加载过程
加载
查找和导入class文件
类加载过程的第一步,主要完成下面 3 件事情:
- 通过全类名获取定义此类的二进制字节流。
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构。
- 在内存中生成一个代表该类的
Class对象,作为方法区这些数据的访问入口。
验证
验证类是否符合JVM规范,安全性检查
验证是连接阶段的第一步,这一阶段的目的是确保 Class 文件的字节流中包含的信息符合《Java 虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。
准备
准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中分配。
解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。也就是得到类或者字段、方法在内存中的指针或者偏移量。
初始化
对类的静态变量,静态代码块执行初始化操作
初始化阶段是执行初始化方法 <clinit> ()方法的过程,是类加载的最后一步,这一步 JVM 才开始真正执行类中定义的 Java 程序代码(字节码)。
对于<clinit> () 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 <clinit> () 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起多个线程阻塞,并且这种阻塞很难被发现。
使用
JVM 开始从入口方法开始执行用户的程序代码
类卸载
卸载类即该类的 Class 对象被 GC。
当用户程序代码执行完毕后,JVM 便开始销毁创建的 Class 对象,最后负责运行 的 JVM 也退出内存
卸载类需要满足 3 个要求:
- 该类的所有的实例对象都已被 GC,也就是说堆不存在该类的实例对象。
- 该类没有在其他任何地方被引用
- 该类的类加载器的实例已被 GC
所以,在 JVM 生命周期内,由 jvm 自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
类加载器详解
类加载过程。
- 类加载过程:加载->连接->初始化。
- 连接过程又可分为三步:验证->准备->解析。
加载是类加载过程的第一步,主要完成下面 3 件事情:
- 通过全类名获取定义此类的二进制字节流
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表该类的
Class对象,作为方法区这些数据的访问入口
类加载器
- 类加载器是一个负责加载类的对象,用于实现类加载过程中的加载这一步。
- 每个 Java 类都有一个引用指向加载它的
ClassLoader。 - 数组类不是通过
ClassLoader创建的(数组类没有对应的二进制字节流),是由 JVM 直接生成的。
JVM只会运行二进制文件,而类加载器的主要作用就是加载 Java 类的字节码( .class 文件)到 JVM 中(在内存中生成一个代表该类的 Class 对象),从而让Java程序能够启动起来。
字节码可以是 Java 源程序(.java文件)经过 javac 编译得来,也可以是通过工具动态生成或者通过网络下载得来。
双亲委派模型
双亲委派模型介绍
当我们想要加载一个类的时候,具体是哪个类加载器加载呢?这就需要提到双亲委派模型了。
下图展示的各种类加载器之间的层次关系被称为类加载器的“双亲委派模型(Parents Delegation Model)”。
双亲委派模型的执行流程
- 在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载(每个父类加载器都会走一遍这个流程)。
- 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器
loadClass()方法来加载类)。依次递归,所有的请求最终都会传送到顶层的启动类加载器BootstrapClassLoader中。 - 只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载(调用自己的
findClass()方法来加载类)。 - 如果子类加载器也无法加载这个类,那么它会抛出一个
ClassNotFoundException异常。
JVM为什么采用双亲委派机制/好处
- 双亲委派模型保证了 Java 程序的稳定运行,可以避免某一个类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类)当父类已经加载后则无需重复加载,保证唯一性。
- 为了安全,保证了 Java 的核心 API 不被篡改。
单元测试
Junit测试框架,用于对代码进行单元测试的工具(IDEA已经集成了junit框架)。相比于在main方法中测试有如下几个优点。

由于Junit是第三方提供的,所以我们需要把jar包导入到我们的项目中,才能使用。

单元测试断言
所谓断言:意思是程序员可以预测程序的运行结果,检查程序的运行结果是否与预期一致。
Junit框架的常用注解

前面的注解是基于Junit4版本的,再Junit5版本中对注解作了更新,但是作用是一样的。

设计模式
重点要说的是:在什么业务场景下使用了设计模式,什么设计模式?
开闭原则 对扩展开放,对修改关闭
public static Coffee orderCoffee(String type){
Coffee coffee = null;
if("american".equals(type)){
coffee = new AmericanCoffee();
}else if ("latte".equals(type)){
coffee = new LatteCoffee();
}
//添加配料
coffee.addMilk();
coffee.addSuqar();
return coffee;
}
在java中,万物皆对象,这些对象都需要创建,如果创建的时候直接new该对 象,就会对该对象耦合严重.
假如我们要更换对象,所有new对象的地方都需要 修改一遍,这显然违背了软件设计的开闭原则。
如果我们使用工厂来生产对象, 我们就只和工厂打交道就可以了,彻底和对象解耦,如果要更换对象,直接在工厂里更换该对象即可,达到了与对象解耦的目的;所以说,工厂模式最大的优点 就是:解耦
工厂方法模式
简单工厂
简单工厂模式指由一个工厂对象来创建实例,客户端不需要关注创建逻辑,只需提供传入工厂的参数。
适用于工厂类负责创建对象较少的情况,缺点是如果要增加新产品,就需要修改工厂类的判断逻辑,违背开闭原则,且产品多的话会使工厂类比较复杂。
例子:
- Calendar抽象类的getInstance方法,调用createCalendar方法根据不同的地区参数创建不同的日历对象。
- Spring 中的 BeanFactory使用简单工厂模式,根据传入一个唯一的标识来获得 Bean对象。
工厂方法
简单工厂模式只有一个工厂类,负责创建所有产品,如果要添加新的产品,通常需要修改工厂类的代码。
而工厂方法模式引入了抽象工厂和具体工厂的概念,每个具体工厂只负责创建一个具体产品,添加新的产品只需要添加新的工厂类而无需修改原来的代码,这样就使得产品的生产更加灵活,支持扩展,符合开闭原则。
也就是定义一个抽象工厂,其定义了产品的生产接口,但不负责具体的产品,将生产任务交给不同的派生类工厂。这样不用通过指定类型来创建对象了。
抽象工厂
简单工厂模式和工厂方法模式不管工厂怎么拆分抽象,都只是针对一类产品,如果要生成另一种产品,就比较难办了!
抽象工厂模式通过在AbstarctFactory中增加创建产品的接口,并在具体子工厂中实现新加产品的创建,当然前提是子工厂支持生产该产品。否则继承的这个接口可以什么也不干。
在工厂方法模式中,每个具体工厂只负责创建单一的产品。
但是如果有多类产品呢,比如说"手机",一个品牌的手机有高端机、中低端机之分,这些具体的产品都需要建立一个单独的工厂类。
但是它们都是相互关联的,都共同属于同一个品牌,这就可以使用到【抽象工厂模式】。
抽象工厂模式可以确保一系列相关的产品被一起创建,这些产品能够相互配合使用,再举个例子,有一些家具,比如沙发、茶几、椅子,都具有古典风格的和现代风格的,抽象工厂模式可以将生产现代风格的家具放在一个工厂类中,将生产古典风格的家具放在另一个工厂类中,这样每个工厂类就可以生产一系列的家具。
从上面类图结构中可以清楚的看到如何在工厂方法模式中通过增加新产品接口来实现产品的增加的。
抽象工厂模式包含多个抽象产品接口,多个具体产品类,一个抽象工厂接口和多个具体工厂,每个具体工厂负责创建一组相关的产品。
-
抽象工厂接口AbstractFactory:声明一组用于创建产品的方法,每个方法对应一个产品。
-
抽象产品接口AbstractProduct:定义产品的接口,可以定义多个抽象产品接口,比如说沙发、椅子、茶几都是抽象产品。
-
具体产品类ConcreteProduct:实现抽象产品接口,产品的具体实现,古典风格和沙发和现代风格的沙发都是具体产品。
-
具体工厂类ConcreteFactory:实现抽象工厂接口,负责创建一组具体产品的对象,在本例中,生产古典风格的工厂和生产现代风格的工厂都是具体实例。
单例模式
单例模式是一种创建型设计模式,它的核心思想是保证一个类只有一个实例,并提供一个全局访问点来访问这个实例。
- 只有一个实例的意思是,在整个应用程序中,只存在该类的一个实例对象,而不是创建多个相同类型的对象。
- 全局访问点的意思是,为了让其他类能够获取到这个唯一实例,该类提供了一个全局访问点(通常是一个静态方法),通过这个方法就能获得实例。
为什么使用单例模式
- 全局控制:保证只有一个实例,这样就可以严格的控制客户怎样访问它以及何时访问它,简单的说就是对唯一实例的受控访问
- 节省资源:也正是因为只有一个实例存在,就避免多次创建了相同的对象,从而节省了系统资源,而且多个模块还可以通过单例实例共享数据。
- 懒加载:单例模式可以实现懒加载,只有在需要时才进行实例化,这无疑会提高程序的性能。
想要实现一个单例设计模式,必须遵循以下规则:
- 私有的构造函数:防止外部代码直接创建类的实例
- 私有的静态实例变量:保存该类的唯一实例
- 公有的静态方法:通过公有的静态方法来获取类的实例
单例模式的实现方式有多种:
- 饿汉式指的是在类加载时就已经完成了实例的创建,不管后面创建的实例有没有使用,先创建再说,所以叫做“饿汉"。但是实例有可能没有使用而造成资源浪费。
优点:线程安全,没有加锁,执行效率较高
通过synchronized关键字加锁保证线程安全,synchronized可以添加在方法上面,也可以添加在代码块上面。
缺点:不是懒加载,类加载时就初始化,浪费内存空间
- 懒汉式指的是只有在请求实例时才会创建,如果在首次请求时还没有创建,就创建一个新的实例,如果已经创建,就返回已有的实例,意思就是需要使用了再创建,所以称为"懒汉"。
优点:懒加载
缺点:线程不安全
策略模式
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。
策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
一句话总结:只要代码中有冗长的if-else或switch分支判断都可以采用策略模式优化
责任链模式
为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;
当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
比较常见的springmvc中的拦截器,web开发中的filter过滤器。
内容审核(视频、文章、课程….)
订单创建
简易流程审批
Linux
inode
inode 是 Linux/Unix 文件系统的基础。
通过以下五点可以概括 inode 到底是什么:
- 硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 元信息 metadata:如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 存储文件元信息的区域就叫 inode,译为索引节点:i(index)+node。 每个文件都有一个唯一的 inode,存储文件的元信息。
- inode 是一种固定大小的数据结构,其大小在文件系统创建时就确定了,并且在文件的生命周期内保持不变。
- inode 的访问速度非常快,因为系统可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
- inode 的数量是有限的,每个文件系统只能包含固定数量的 inode。这意味着当文件系统中的 inode 用完时,无法再创建新的文件或目录,即使磁盘上还有可用空间。因此,在创建文件系统时,需要根据文件和目录的预期数量来合理分配 inode 的数量。
- 可以使用
stat命令可以查看文件的 inode 信息,包括文件的 inode 号、文件类型、权限、所有者、文件大小、修改时间。
简单来说:inode 就是用来维护某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等信息。
再总结一下 inode 和 block:
- inode:记录文件的属性信息,可以使用
stat命令查看 inode 信息。 - block:实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
Linux/Unix 操作系统使用 inode 区分不同的文件。这样做的好处是,即使文件名被修改或删除,文件的 inode 号码不会改变,从而可以避免一些因文件重命名、移动或删除导致的错误。同时,inode 也可以提供更高的文件系统性能,因为 inode 的访问速度非常快,可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
硬链接和软链接
在 Linux/类 Unix 系统上,文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。
常见的文件链接类型有两种:
1、硬链接(Hard Link)
- 在 Linux/类 Unix 文件系统中,每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的(可以看作是互为硬链接,源头是同一份文件),删除其中任何一个对另外一个没有影响,可以通过给文件设置硬链接文件来防止重要文件被误删。
- 只有删除了源文件和所有对应的硬链接文件,该文件才会被真正删除。
- 硬链接具有一些限制,不能对目录以及不存在的文件创建硬链接,并且,硬链接也不能跨越文件系统。
ln命令用于创建硬链接。
2、软链接(Symbolic Link 或 Symlink)
- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
- 软连接类似于 Windows 系统中的快捷方式。
- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
ln -s命令用于创建软链接。
硬链接为什么不能跨文件系统?
硬链接是通过 inode 节点号建立连接的,而硬链接和源文件共享相同的 inode 节点号。
然而,每个文件系统都有自己的独立 inode 表,且每个 inode 表只维护该文件系统内的 inode。如果在不同的文件系统之间创建硬链接,可能会导致 inode 节点号冲突的问题,即目标文件的 inode 节点号已经在该文件系统中被使用。
Linux 文件类型
- 普通文件(-):用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
- 目录文件(d,directory file):目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
- 符号链接文件(l,symbolic link):保留了指向文件的地址而不是文件本身。
- 字符设备(c,char):用来访问字符设备比如键盘。
- 设备文件(b,block):用来访问块设备比如硬盘、软盘。
- 管道文件(p,pipe) : 一种特殊类型的文件,用于进程之间的通信。
- 套接字文件(s,socket):用于进程间的网络通信,也可以用于本机之间的非网络通信。
Linux 目录树
Linux 使用一种称为目录树的层次结构来组织文件和目录。目录树由根目录(/)作为起始点,向下延伸,形成一系列的目录和子目录。每个目录可以包含文件和其他子目录。
常见目录说明:
- /bin: 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
- /etc: 存放系统管理和配置文件;
- /home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
- /usr: 用于存放系统应用程序;
- /opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
- /proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
- /root: 超级用户(系统管理员)的主目录(特权阶级o);
- /sbin: 存放二进制可执行文件,只有 root 才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如 ifconfig 等;
- /dev: 用于存放设备文件;
- /mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
- /boot: 存放用于系统引导时使用的各种文件;
- /lib 和/lib64: 存放着和系统运行相关的库文件 ;
- /tmp: 用于存放各种临时文件,是公用的临时文件存储点;
- /var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
- /lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
Linux 常用命令
目录切换
cd usr:切换到该目录下 usr 目录cd ..(或cd../):切换到上一层目录cd /:切换到系统根目录cd ~:切换到用户主目录cd -: 切换到上一个操作所在目录
目录操作
ls:显示目录中的文件和子目录的列表。例如:ls /home,显示/home目录下的文件和子目录列表。ll:ll是ls -l的别名,ll 命令可以看到该目录下的所有目录和文件的详细信息mkdir [选项] 目录名:创建新目录(增)。例如:mkdir -m 755 my_directory,创建一个名为my_directory的新目录,并将其权限设置为 755,即所有用户对该目录有读、写和执行的权限。find [路径] [表达式]:在指定目录及其子目录中搜索文件或目录(查),非常强大灵活。例如:① 列出当前目录及子目录下所有文件和文件夹:find .;② 在/home目录下查找以.txt结尾的文件名:find /home -name "*.txt",忽略大小写:find /home -i name "*.txt";③ 当前目录及子目录下查找所有以.txt和.pdf结尾的文件:find . \( -name "*.txt" -o -name "*.pdf" \)或find . -name "*.txt" -o -name "*.pdf"。pwd:显示当前工作目录的路径。rmdir [选项] 目录名:删除空目录(删)。例如:rmdir -p my_directory,删除名为my_directory的空目录,并且会递归删除my_directory的空父目录,直到遇到非空目录或根目录。rm [选项] 文件或目录名:删除文件/目录(删)。例如:rm -r my_directory,删除名为my_directory的目录,-r(recursive,递归) 表示会递归删除指定目录及其所有子目录和文件。cp [选项] 源文件/目录 目标文件/目录:复制文件或目录(移)。例如:cp file.txt /home/file.txt,将file.txt文件复制到/home目录下,并重命名为file.txt。cp -r source destination,将source目录及其下的所有子目录和文件复制到destination目录下,并保留源文件的属性和目录结构。mv [选项] 源文件/目录 目标文件/目录:移动文件或目录(移),也可以用于重命名文件或目录。例如:mv file.txt /home/file.txt,将file.txt文件移动到/home目录下,并重命名为file.txt。mv与cp的结果不同,mv好像文件“搬家”,文件个数并未增加。而cp对文件进行复制,文件个数增加了。
文件操作
像 mv、cp、rm 等文件和目录都适用的命令,这里就不重复列举了。
touch [选项] 文件名..:创建新文件或更新已存在文件(增)。例如:touch file1.txt file2.txt file3.txt,创建 3 个文件。ln [选项] <源文件> <硬链接/软链接文件>:创建硬链接/软链接。例如:ln -s file.txt file_link,创建名为file_link的软链接,指向file.txt文件。-s选项代表的就是创建软链接,s 即 symbolic(软链接又名符号链接) 。cat/more/less/tail 文件名:文件的查看(查) 。命令tail -f 文件可以对某个文件进行动态监控,例如 Tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log监控 文 件的变化 。vim 文件名:修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤:vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!(输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
文件压缩
1)打包并压缩文件:
Linux 中的打包文件一般是以 .tar 结尾的,压缩的命令一般是以 .gz 结尾的。而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般 .tar.gz。
命令:tar -zcvf 打包压缩后的文件名 要打包压缩的文件 ,其中:
- z:调用 gzip 压缩命令进行压缩
- c:打包文件
- v:显示运行过程
- f:指定文件名
比如:假如 test 目录下有三个文件分别是:aaa.txt、 bbb.txt、ccc.txt,如果我们要打包 test 目录并指定压缩后的压缩包名称为 test.tar.gz 可以使用命令:tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt 或 tar -zcvf test.tar.gz /test/ 。
2)解压压缩包:
命令:tar [-xvf] 压缩文件
其中 x 代表解压
示例:
- 将
/test下的test.tar.gz解压到当前目录下可以使用命令:tar -xvf test.tar.gz - 将 /test 下的 test.tar.gz 解压到根目录/usr 下:
tar -xvf test.tar.gz -C /usr(-C代表指定解压的位置)
文件传输
scp [选项] 源文件 远程文件(scp 即 secure copy,安全复制):用于通过 SSH 协议进行安全的文件传输,可以实现从本地到远程主机的上传和从远程主机到本地的下载。例如:scp -r my_directory user@remote:/home/user,将本地目录my_directory上传到远程服务器/home/user目录下。scp -r user@remote:/home/user/my_directory,将远程服务器的/home/user目录下的my_directory目录下载到本地。需要注意的是,scp命令需要在本地和远程系统之间建立 SSH 连接进行文件传输,因此需要确保远程服务器已经配置了 SSH 服务,并且具有正确的权限和认证方式。rsync [选项] 源文件 远程文件: 可以在本地和远程系统之间高效地进行文件复制,并且能够智能地处理增量复制,节省带宽和时间。例如:rsync -r my_directory user@remote:/home/user,将本地目录my_directory上传到远程服务器/home/user目录下。ftp(File Transfer Protocol):提供了一种简单的方式来连接到远程 FTP 服务器并进行文件上传、下载、删除等操作。使用之前需要先连接登录远程 FTP 服务器,进入 FTP 命令行界面后,可以使用put命令将本地文件上传到远程主机,可以使用get命令将远程主机的文件下载到本地,可以使用delete命令删除远程主机的文件。这里就不进行演示了。
文件权限
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(executable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
通过 ls -l 命令我们可以 查看某个目录下的文件或目录的权限
修改文件/目录的权限的命令:chmod
补充一个比较常用的东西:
假如我们装了一个 zookeeper,我们每次开机到要求其自动启动该怎么办?
- 新建一个脚本 zookeeper
- 为新建的脚本 zookeeper 添加可执行权限,命令是:
chmod +x zookeeper - 把 zookeeper 这个脚本添加到开机启动项里面,命令是:
chkconfig --add zookeeper - 如果想看看是否添加成功,命令是:
chkconfig --list
用户管理
Linux 系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
Linux 用户管理相关命令:
useradd [选项] 用户名:创建用户账号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。userdel [选项] 用户名:删除用户帐号。usermod [选项] 用户名:修改用户账号的属性和配置比如用户名、用户 ID、家目录。passwd [选项] 用户名: 设置用户的认证信息,包括用户密码、密码过期时间等。。例如:passwd -S 用户名,显示用户账号密码信息。passwd -d 用户名: 清除用户密码,会导致用户无法登录。passwd 用户名,修改用户密码,随后系统会提示输入新密码并确认密码。su [选项] 用户名(su 即 Switch User,切换用户):在当前登录的用户和其他用户之间切换身份。
用户组管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同 Linux 系统对用户组的规定有所不同,如 Linux 下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
Linux 系统用户组的管理相关命令:
groupadd [选项] 用户组:增加一个新的用户组。groupdel 用户组:要删除一个已有的用户组。groupmod [选项] 用户组: 修改用户组的属性。
系统状态
-
top [选项]:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。 -
htop [选项]:类似于top,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。 -
uptime [选项]:用于查看系统总共运行了多长时间、系统的平均负载等信息。 -
vmstat [间隔时间] [重复次数]:vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。 -
free [选项]:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。 -
df [选项] [文件系统]:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:df -a,查看全部文件系统。 -
du [选项] [文件]:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。 -
sar [选项] [时间间隔] [重复次数]:用于收集、报告和分析系统的性能统计信息,包括系统的 CPU 使用、内存使用、磁盘 I/O、网络活动等详细信息。它的特点是可以连续对系统取样,获得大量的取样数据。取样数据和分析的结果都可以存入文件,使用它时消耗的系统资源很小。 -
ps [选项]:用于查看系统中的进程信息,包括进程的 ID、状态、资源使用情况等。ps -ef/ps -aux:这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:ps aux|grep redis(查看包括 redis 字符串的进程),也可使用pgrep redis -a。 -
systemctl [命令] [服务名称]:用于管理系统的服务和单元,可以查看系统服务的状态、启动、停止、重启等。
网络通信
ping [选项] 目标主机:测试与目标主机的网络连接。ifconfig或ip:用于查看系统的网络接口信息,包括网络接口的 IP 地址、MAC 地址、状态等。netstat [选项]:用于查看系统的网络连接状态和网络统计信息,可以查看当前的网络连接情况、监听端口、网络协议等。ss [选项]:比netstat更好用,提供了更快速、更详细的网络连接信息。
其他
sudo + 其他命令:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。grep 要搜索的字符串 要搜索的文件 --color:搜索命令,--color 代表高亮显示。kill -9 进程的pid:杀死进程(-9 表示强制终止)先用 ps 查找进程,然后用 kill 杀掉。shutdown:shutdown -h now:指定现在立即关机;shutdown +5 "System will shutdown after 5 minutes":指定 5 分钟后关机,同时送出警告信息给登入用户。reboot:reboot:重开机。reboot -w:做个重开机的模拟(只有纪录并不会真的重开机)。
Linux 环境变量
在 Linux 系统中,环境变量是用来定义系统运行环境的一些参数,比如每个用户不同的主目录(HOME)。
Shell编程
目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 。
两者之间,Shell 几乎是 IT 企业必须使用的运维自动化编程语言,特别是在运维工作中的服务监控、业务快速部署、服务启动停止、数据备份及处理、日志分析等环节里,shell 是不可缺的。
Python 更适合处理复杂的业务逻辑,以及开发复杂的运维软件工具,实现通过 web 访问等。
Shell 是一个命令解释器,解释执行用户所输入的命令和程序。一输入命令,就立即回应的交互的对话方式。
Shell 编程就是对一堆 Linux 命令的逻辑化处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号