hadoop-3.0.0-beta1分布式安装
楼主是从Hadoop2.x版本过来的,在工作之余自己搭建了一套3.0的版本来耍一耍,此文章的前置环境准备工作省略。主要介绍一些和Hadoop2.x版本不同的安装之处
Hadoop版本:hadoop-3.0.0-beta1
JDK版本:jdk1.8.0_121
虚拟机版本:Centos6.5
一、前置环境准备
1.1 jdk安装
1.2 免密钥登录
二、 hadoop3.0需要配置的文件有core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、hadoop-env.sh、workers
1.core-site.xml配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop3:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///hadoopv3/tmp</value> //此目录不配置的话,默认是在/temp目录下。Linux系统重启的话此目录会被清空
</property>
</configuration>
2.hdfs-site.xml配置文件
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///hadoopv3/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///hadoopv3/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop2:9001</value> </property> </configuration>
3.workers中设置slave节点,将slave机器的名称写入
hadoop1
hadoop2
hadoop3
4.mapred-site配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/software/hadoop-3.0.0-beta1/etc/hadoop,
/home/software/hadoop-3.0.0-beta1/share/hadoop/common/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/common/lib/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/hdfs/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/hdfs/lib/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/mapreduce/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/mapreduce/lib/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/yarn/*,
/home/software/hadoop-3.0.0-beta1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
5.yarn-site.xml配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>
</configuration>
6.hadoop-env.sh中配置java_home
export JAVA_HOME=/usr/local/java/jdk1.8.0_121
以上配置完成后,将hadoop整个文件夹复制到其他二台机器。
四、启动hadoop
hdfs namenode -format
注意:格式化的时候只需要在namenode节点执行一次即可
若没有设置路径$HADOOP_HOME/bin为环境变量,则需在$HADOOP_HOME路径下执行
格式化之后三台机器上的目录的结构分别是:
hadoop1:
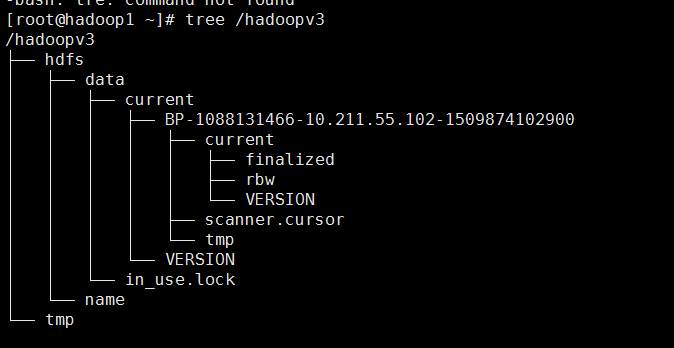
hadoop2:
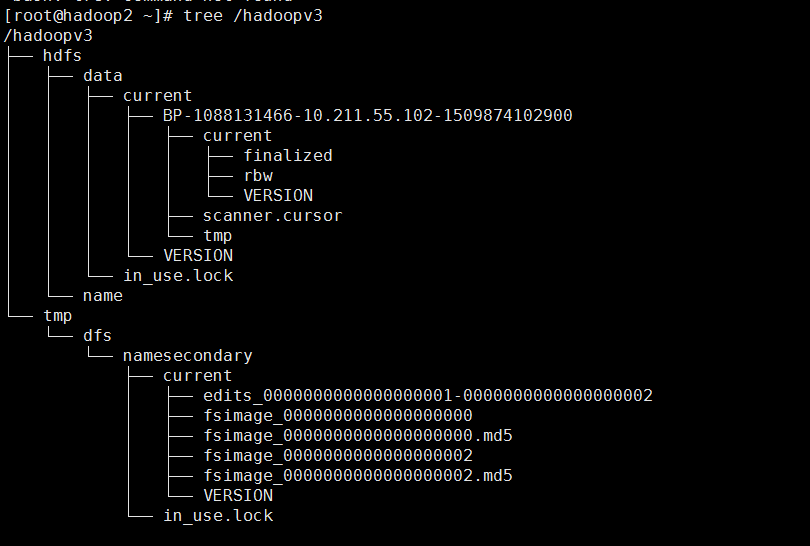
hadoop3:
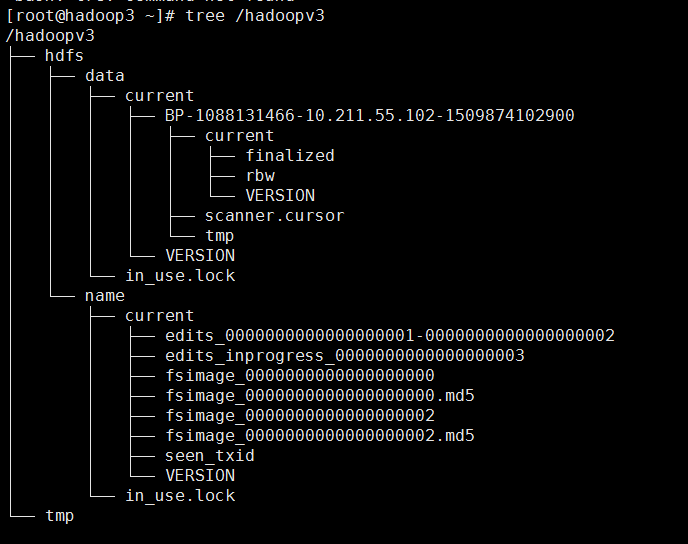
2.启动hdfs及yarn
start-dfs.sh
start-yarn.sh
若没有设置路径$HADOOP_HOME/sbin为环境变量,则需在$HADOOP_HOME路径下执行
现在便可以打开页面http://hadoop3:8088及http://hadoop3:9870;看到下面两个页面时说明安装成功。
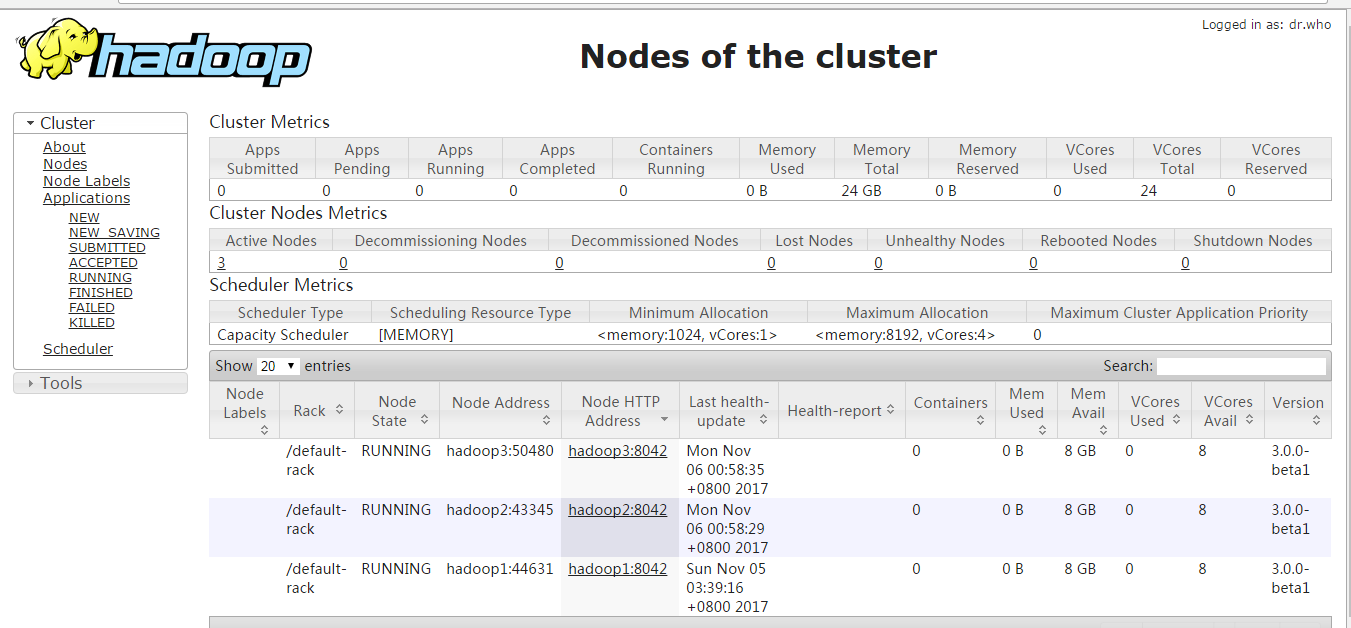

注意:启动的时候会遇到一些问题
问题1:Starting namenodes on [hadoop3]
ERROR: Attempting to launch hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.

解决1:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vi sbin/start-dfs.sh
$ vi sbin/stop-dfs.sh
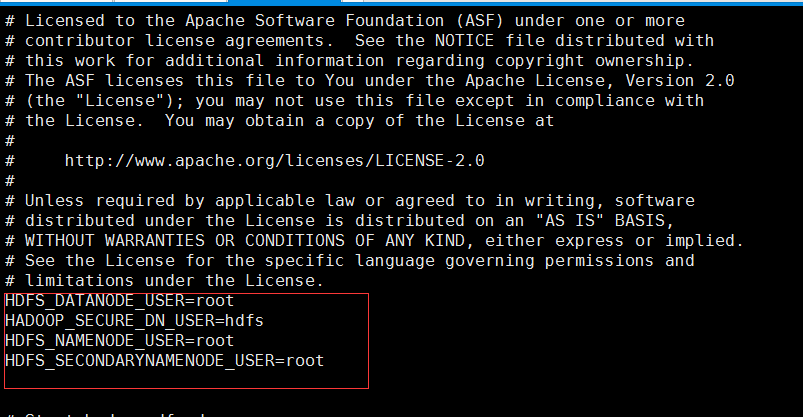
在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
问题2:
Starting resourcemanager
ERROR: Attempting to launch yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
Starting nodemanagers
ERROR: Attempting to launch yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting launch.
解决2:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vi sbin/start-yarn.sh
$ vi sbin/stop-yarn.sh


 浙公网安备 33010602011771号
浙公网安备 33010602011771号