Spark闭包
闭包的作用可以理解为:函数可以访问函数外部定义的变量,但是函数内部对该变量进行的修改,在函数外是不可见的,即对函数外源变量不会产生影响。

其实,在学习Spark时,一个比较难理解的点就是,在集群模式下,定义的变量和方法作用域的范围和生命周期。这在你操作RDD时,比如调用一些函数map、foreach时,访问其外部变量进行操作时,很容易产生疑惑。为什么我本地程序运行良好且结果正确,放到集群上却得不到想要的结果呢?
首先通过下边对RDD中的元素进行求和的示例,来看相同的代码本地模式和集群模式运行结果的区别:
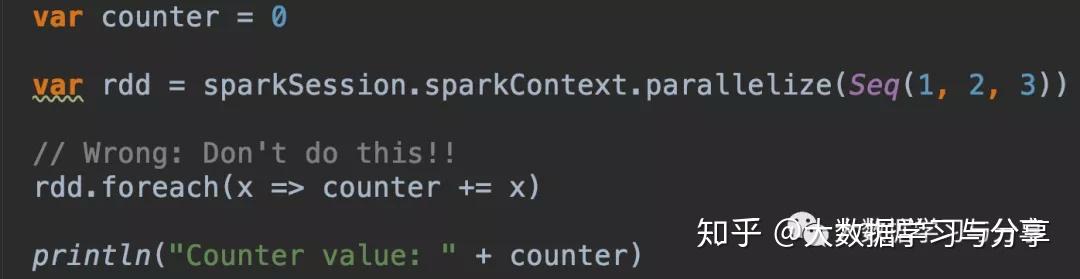
Spark为了执行任务,会将RDD的操作分解为多个task,并且这些task是由executor执行的。在执行之前,Spark会计算task的闭包即定义的一些变量和方法,比如例子中的counter变量和foreach方法,并且闭包必须对executor而言是可见的,这些闭包会被序列化发送到每个executor。在集群模式下,driver和executor运行在不同的JVM进程中,发送给每个executor的闭包中的变量是driver端变量的副本。因此,当foreach函数内引用counter时,其实处理的只是driver端变量的副本,与driver端本身的counter无关。driver节点的内存中仍有一个计数器,但该变量对executor是不可见的!executor只能看到序列化闭包的副本。因此,上述例子输出的counter最终值仍然为零,因为counter上的所有操作都只是引用了序列化闭包内的值。在本地模式下,往往driver和executor运行在同一JVM进程中。那么这些闭包将会被共享,executor操作的counter和driver持有的counter是同一个,那么counter在处理后最终值为6。
但是在生产中,我们的任务都是在集群模式下运行,如何能满足这种业务场景呢?
这就必须引出一个后续要重点讲解的概念:Accumulator即累加器。Spark中的累加器专门用于提供一种机制,用于在集群中的各个worker节点之间执行时安全地更新变量。

一般来说,closures - constructs比如循环或本地定义的方法,就不应该被用来改变一些全局状态,Spark并没有定义或保证对从闭包外引用的对象进行更新的行为。如果你这样操作只会导致一些代码在本地模式下能够达到预期的效果,但是在分布式环境下却事与愿违。如果需要某些全局聚合,请改用累加器。对于其他的业务场景,我们适时考虑引入外部存储系统、广播变量等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号