网络随笔
云与IDC
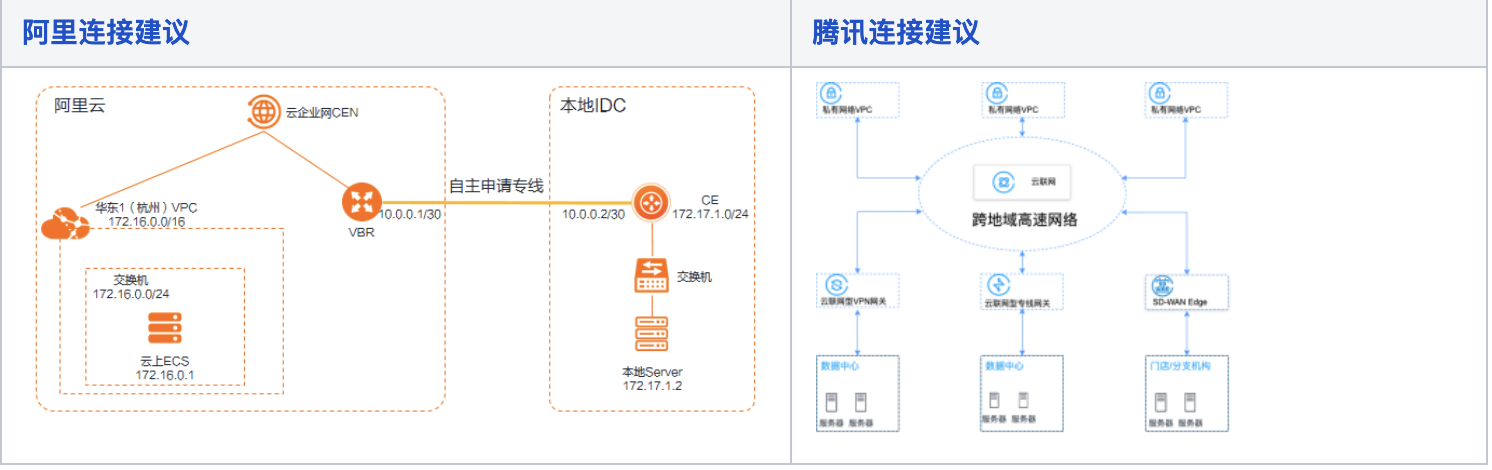
都是多个私网VPC组成云企网,再通过网关/边界路由经过专线到IDC
LB云厂商实现原理
| 阿里云 | 腾讯云 |
|
https://help.aliyun.com/document_detail/27544.html
|
https://cloud.tencent.com/document/product/214/530
|


kube-proxy
在kubernetes集群的每个节点上都运行着kube-proxy进程负责实现Kubernetes中Service组件的虚拟IP服务,常见的两种模型iptables和ipvs。
iptables
创建Service的时候会同时建立两个iptables规则,一个是给Service用,另一个是给Endpoints。给Service用的是为了转发流量给后端,给Endpoints用的是为了选择Pod。
kube-proxy创建Service的时候, 通过 Service 的 Informer 感知到API Server中service和endpoint的变化情况,在宿主机上同时建立两个iptables规则,一个是给Service用,另一个是给Endpoints。给Service用的是为了转发流量给后端,给Endpoints用的是为了选择Pod。集群越大,查询更新规则的性能损耗越大。
ipvs
IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。
当proxy启动的时候,proxy将验证节点是否安装ipvs模块,如果没有安装将退回iptables模式。IPVS模式也是基于Netfilter,对比iptables模式在大规模有更好的扩展性和性能。支持更复杂的均衡算法(最小复杂、最少连接、加权等),支持Service的健康检查和连接重试功能。IPVS依赖于iptables,使用iptables进行包过滤,SNAT,masuared。IPVS将使用ipset来存储需要DROP或MASQUARED的流量源地址和目标地址,这样可以保证iptables规则数量固定,不需要关心集群中有多少Service。
kube-Proxy会监视Kubernetes Service对象和Endpoints,调用Netlink接口以相应的创建IPVS规则并定期与Kubernets Service和Endpoints对象同步IPVS规则,以确保IPVS状态和期望状态一直。访问服务时,流量将会被重定向到一个Pod。
实例一
创建一个Service,系统会如何处理,测试针对ipvs类型集群创建一个ClusterIP类型的Service,两个后端Endpoints
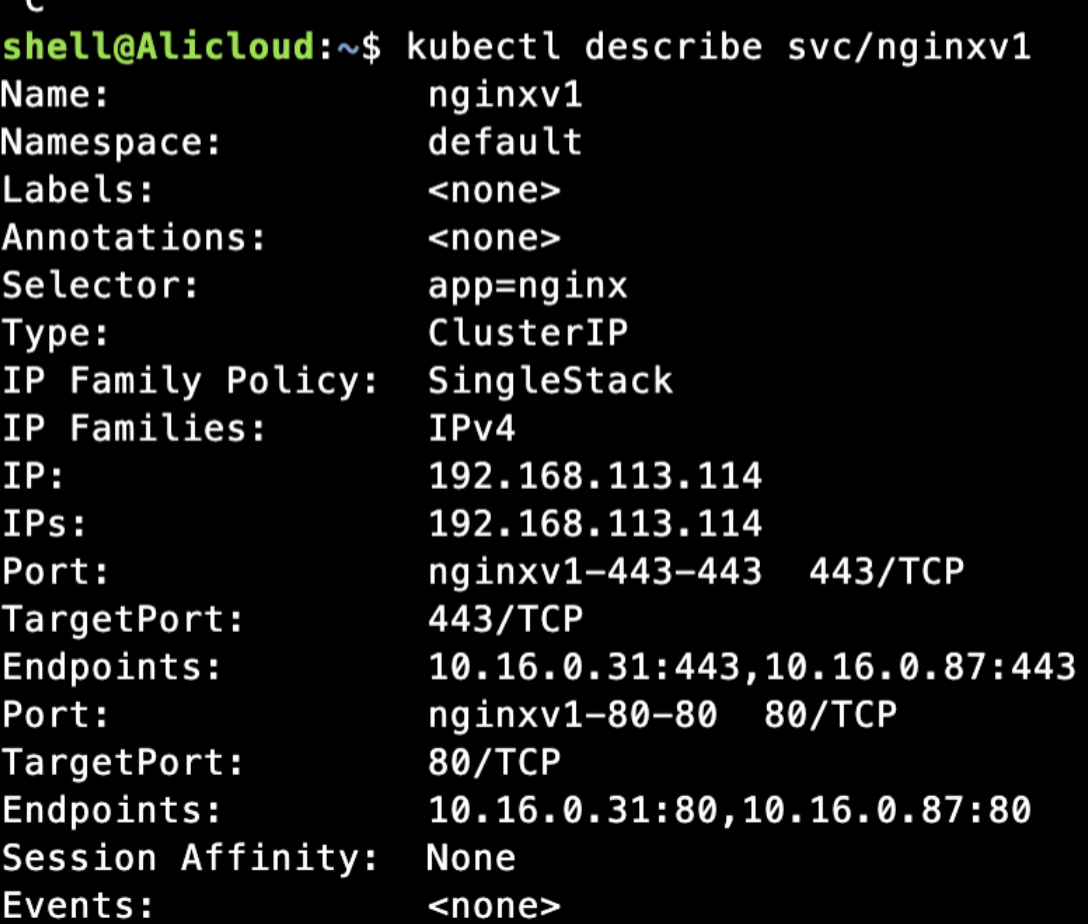
后端对应两个Pod
![]()
节点上会生成虚拟端口 kube-ipvs0
[root@iZuf634qce0653xtqgbxxmZ ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:16:3e:2b:7a:71 brd ff:ff:ff:ff:ff:ff inet 172.28.127.250/20 brd 172.28.127.255 scope global dynamic eth0 valid_lft 315090490sec preferred_lft 315090490sec inet6 fe80::216:3eff:fe2b:7a71/64 scope link valid_lft forever preferred_lft forever 3: dummy0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 0e:b1:67:c6:7f:3d brd ff:ff:ff:ff:ff:ff 4: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default link/ether b2:5a:5f:70:36:dd brd ff:ff:ff:ff:ff:ff inet 192.168.0.10/32 scope global kube-ipvs0 valid_lft forever preferred_lft forever ...... inet 192.168.113.114/32 scope global kube-ipvs0 valid_lft forever preferred_lft forever ...... 5: nodelocaldns: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default link/ether 0e:2c:1c:16:87:65 brd ff:ff:ff:ff:ff:ff inet 169.254.20.10/32 scope global nodelocaldns valid_lft forever preferred_lft forever 6: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 72:e9:91:28:05:5e brd ff:ff:ff:ff:ff:ff inet 10.16.0.1/26 brd 10.16.0.63 scope global cni0 valid_lft forever preferred_lft forever inet6 fe80::70e9:91ff:fe28:55e/64 scope link valid_lft forever preferred_lft forever 7: veth349c0776@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cni0 state UP group default link/ether 56:c8:2c:eb:e8:b1 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet6 fe80::54c8:2cff:feeb:e8b1/64 scope link valid_lft forever preferred_lft forever ......
搜索192.168.113.114,发现分别生成了虚拟服务,和通过rr轮询的后端地址
[root@iZuf634qce0653xtqgbxxmZ ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.113.114:80 rr
-> 10.16.0.31:80 Masq 1 0 0
-> 10.16.0.87:80 Masq 1 0 0
TCP 192.168.113.114:443 rr
-> 10.16.0.31:443 Masq 1 0 0
-> 10.16.0.87:443 Masq 1 0 0
.......
UDP 192.168.0.10:53 rr
-> 10.16.0.24:53 Masq 1 0 43
-> 10.16.0.85:53 Masq 1 0 44
实例二
新建Nodeport类型的服务,信息如下
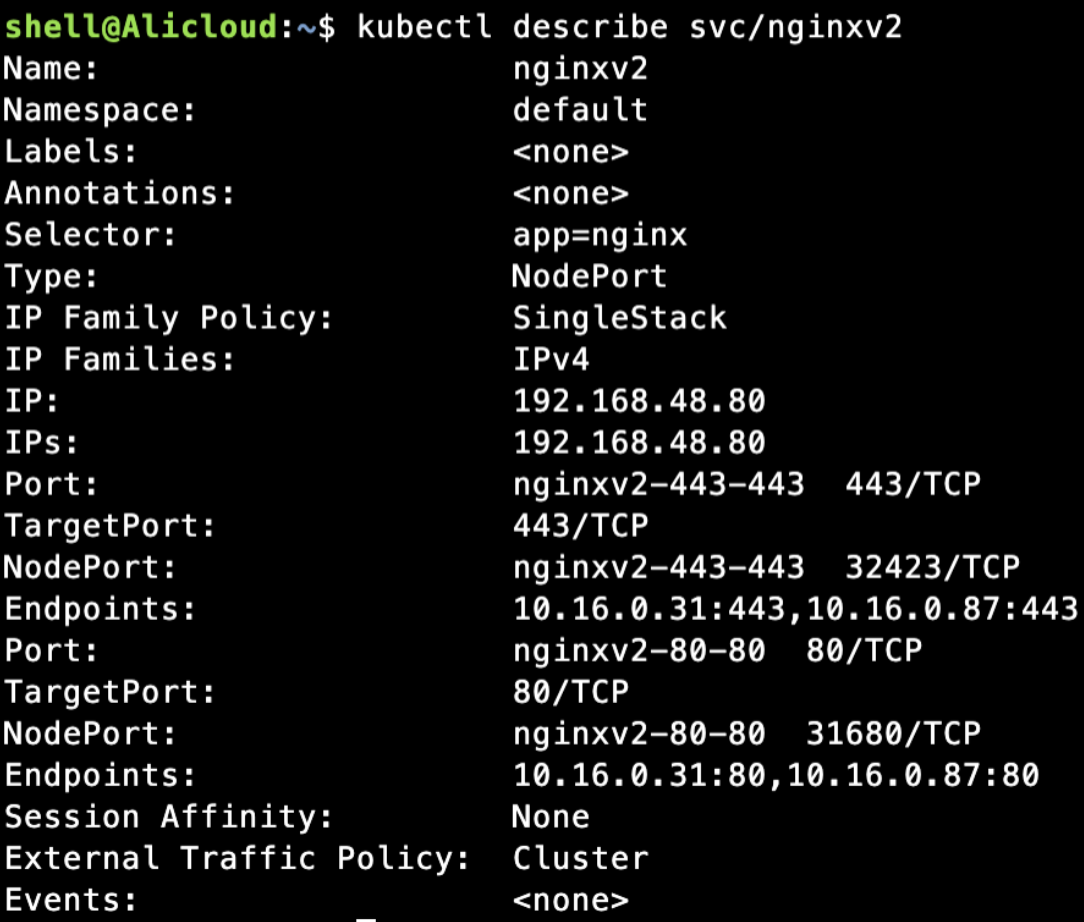
看下是否同样创建了虚拟映射,是的
[root@iZuf634qce0653xtqgbxxmZ net.d]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
......
TCP 192.168.48.80:80 rr
-> 10.16.0.31:80 Masq 1 0 0
-> 10.16.0.87:80 Masq 1 0 0
TCP 192.168.48.80:443 rr
-> 10.16.0.31:443 Masq 1 0 0
-> 10.16.0.87:443 Masq 1 0 0
......
CNI(Container Network Interface)插件
CNI的目的在于定义一个标准的接口规范,使得kubernetes在增删POD的时候,能够按照规范向CNI实例提供标准的输入并获取标准的输出,再将输出作为kubernetes管理这个POD的网络
- Kubelet 会首先从 ApiServer 监听到 Pod 的创建,会创建 Pod 的沙箱
- 然后通过 CNI 接口调用 CNI 的插件去配置容器的网络
- CNI 会配置 Pod 的网络空间,以及打通不同 Pod 之间的网络访问
CNI插件通过/etc/cni/net.d加载,当前云使用厂商提供默认插件,自建IDC使用Calico
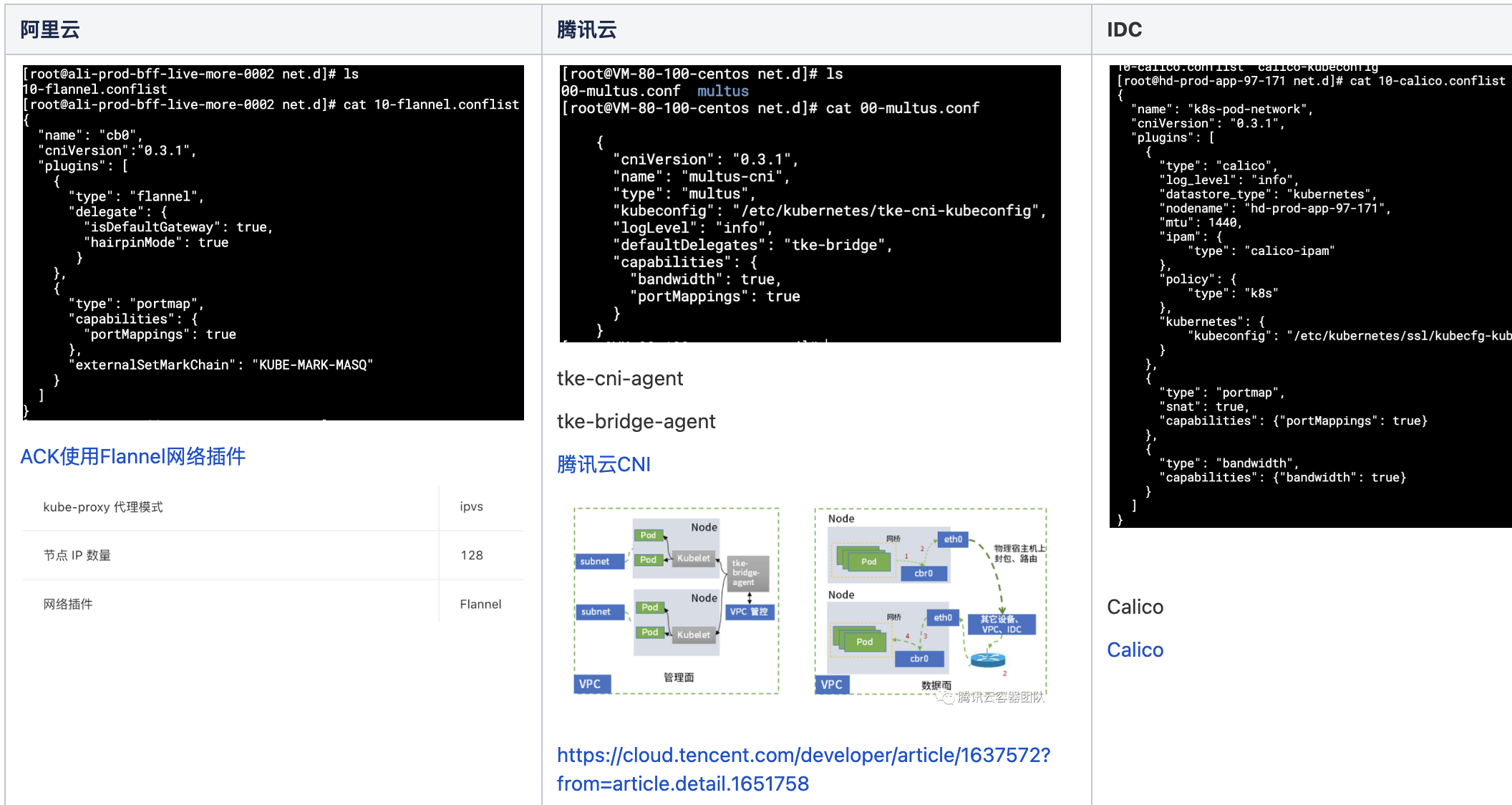
Flannel
Flannel是CoreOS公司开源的CNI网络插件,它的功能是让K8S集群中的不同节点创建的容器都具有全集群唯一的虚拟IP地址。它基于Linux TUN/TAP,使用UDP封装IP包来创建overlay网络,IP分配信息会存于ETCD中。
Flannel通用的Backend类型区分,主要区别是UDP经过用户态,性能低,VXlan不经过用户态,但还是需要隧道技术封包解包,hostgw设置下一跳地址为主机地址
etcd存储子网和宿主机之间的关系,于是flannel0等设备就可以掌握转发路由,现在都是直连apiserver
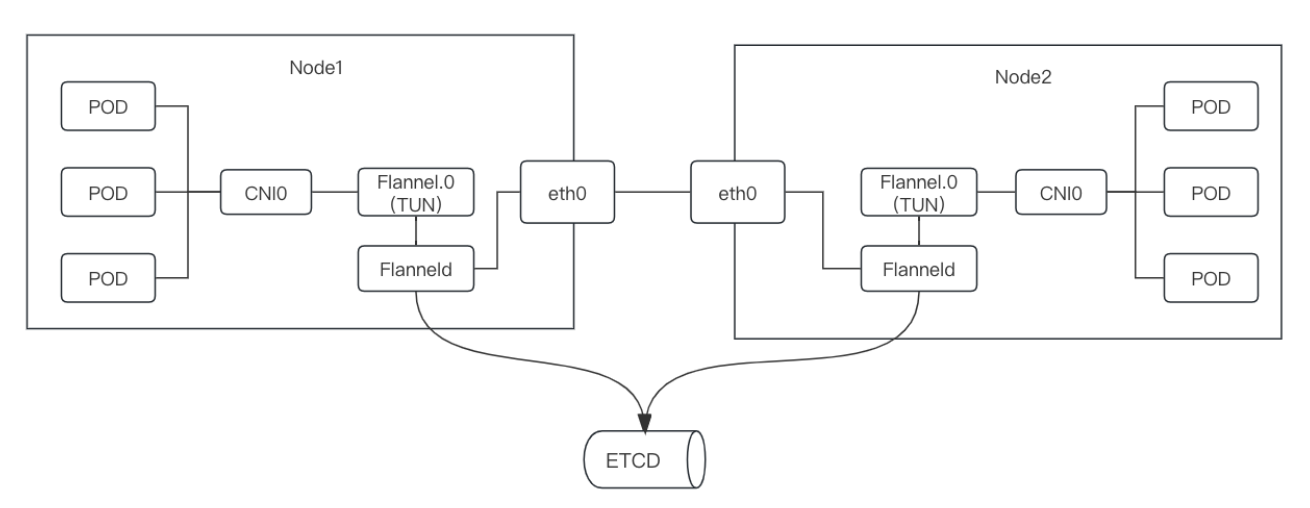
UDP
flannel0为TUN设备(TUN 在操作系统内核和用户应用程序之间传递 IP 包),收到IP包转发给用户态的flanneld进程,flannel进程通过UDP协议将包发到其他Node,其他flanneld收到解包再用,效率低,淘汰了
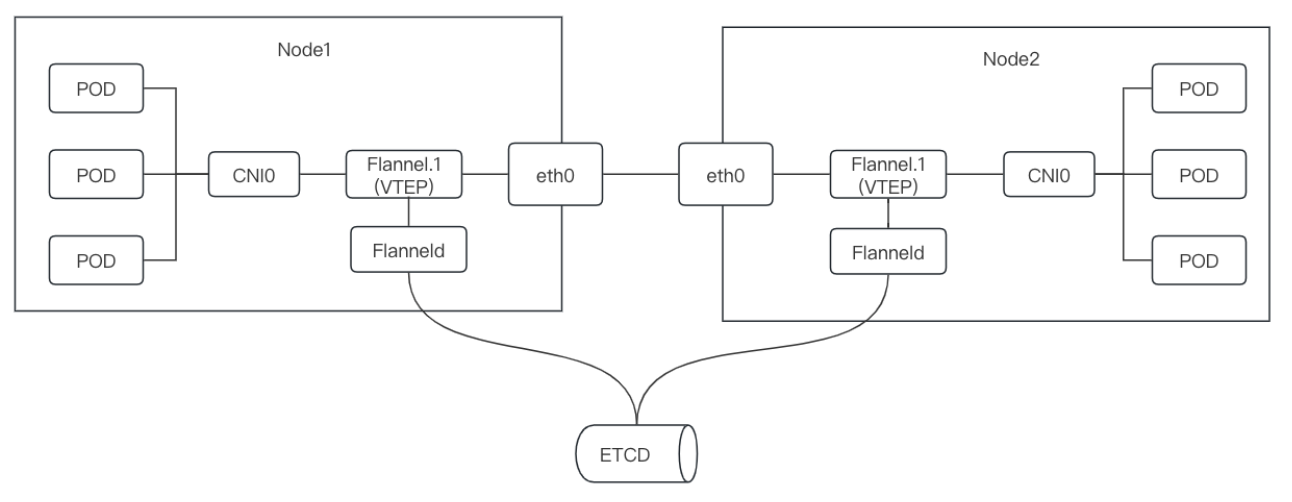
VXLAN
在内核态封装,无需TUN设备,通过netlink通知内核建立一个VTEP(VXLAN Tunnel End Point(虚拟隧道端点))的网卡flannel.1,在内核态完成封包解封,flanneld初始化ip->mac关系,维护fdb数据,二层mac通过ARP获取,再从mac到ip,从而完成跨主机通讯
Host-gw
通过主机路由的方式,将请求发送到容器外部的应用,但是有个约束就是宿主机要和其他物理机在同一个vlan或者局域网中,这种模式不需要封包和解包,因此更加高效。

阿里云
以阿里云为例,以下大部分内容来自阿里云文档
kubernates和云之间如何做到联动、优化的?
- 比如创建一个loadbalance类型的service,是如何创建对应的阿里云LB实例且关联的?
- 比如云厂商提供的CNI插件为啥宣称比开源的性能要好?优化在哪里?
创建阿里云ACK集群后,如果是托管模式,整个管理节点是被云托管的,所以看不到管理节点,但通过组件管理页面,可以看到默认安装了系统组件Cloud Controller Manager,文档功能描述也比较清晰了

Cloud Controller Manager提供Kubernetes与阿里云基础产品的对接能力,例如CLB(原SLB)、VPC等。CCM主要提供以下功能:
- 管理负载均衡
当Service的类型设置为
Type=LoadBalancer时,CCM组件会为该Service创建或配置阿里云负载均衡CLB,包括含CLB、监听、后端服务器组等资源。当Service对应的后端Endpoint或者集群节点发生变化时,CCM会自动更新CLB的后端虚拟服务器组。 - 实现跨节点通信
当集群网络组件为Flannel时,CCM组件负责打通容器与节点间网络,实现容器跨节点通信。CCM会将节点的Pod网段信息写入VPC的路由表中,从而实现跨节点的容器通信。该功能无需配置,安装即可使用。
ACK安装时,阿里云可选两种网络模式可选Flannel或Terway
ACK的Flannel插件采用的是阿里云VPC模式,报文经过阿里云VPC的路由表直接转发,不需要Vxlan等隧道封装技术封装报文,所以比Flannel默认的Vxlan模式具有更高的通信性能
每个节点需要对应一个VPC的路由表条目

实际配置
新增cni0网桥,目标为10.50.1.128/25的访问路由到cni0,再转到pod
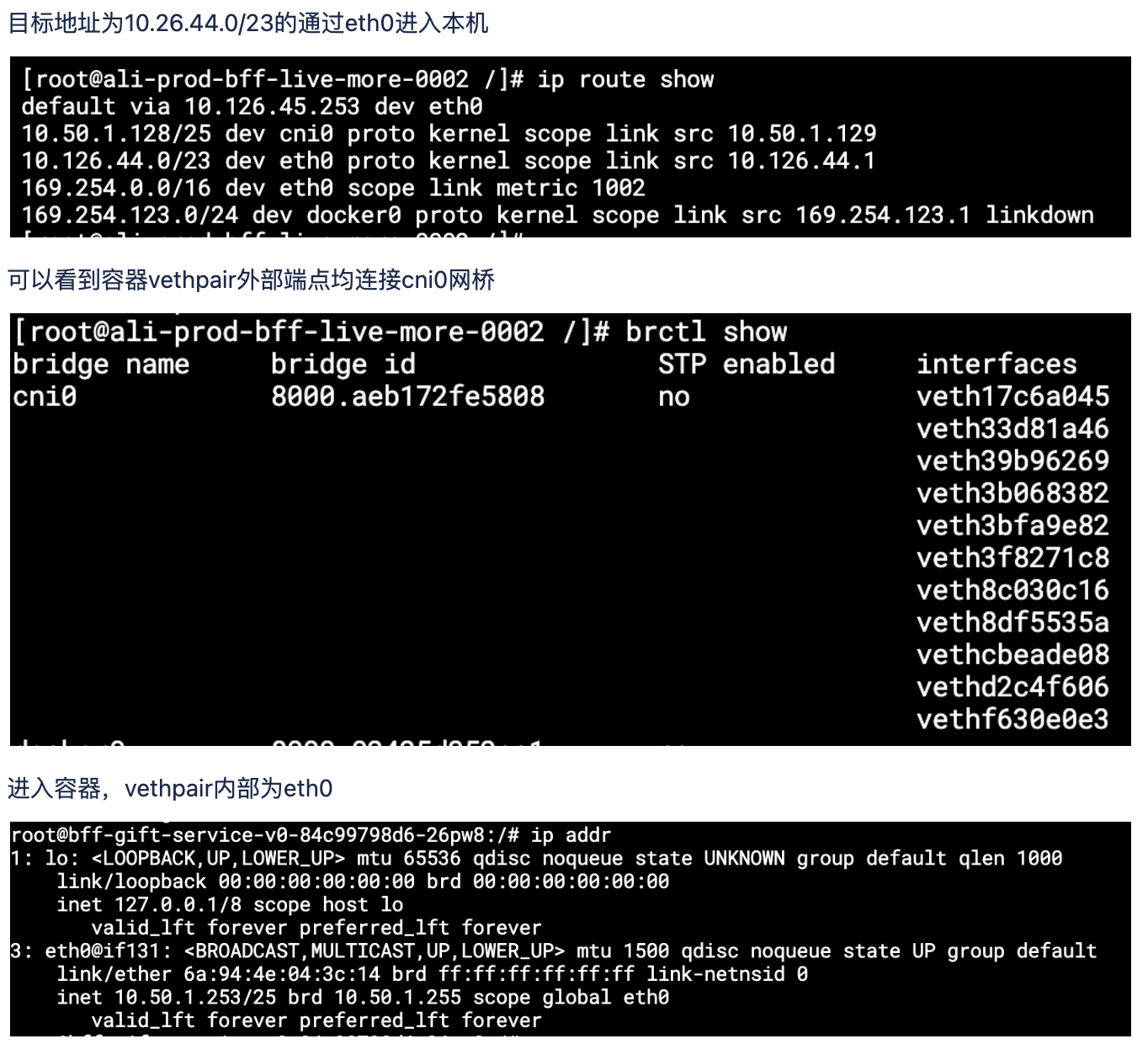
容器内对应的外部网卡为veth3b068382
root@bff-gift-service-v0-84c99798d6-26pw8:/# cat /sys/class/net/eth0/iflink 131 [root@ali-prod-bff-live-more-0002 /]# ip link | grep -A 1 131 131: veth3b068382@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cni0 state UP mode DEFAULT group default link/ether 26:30:6b:b1:7d:af brd ff:ff:ff:ff:ff:ff link-netnsid 6 [root@ali-prod-bff-live-more-0002 /]# ifconfig cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.50.1.129 netmask 255.255.255.128 broadcast 10.50.1.255 inet6 fe80::acb1:72ff:fefe:5808 prefixlen 64 scopeid 0x20<link> ether ae:b1:72:fe:58:08 txqueuelen 1000 (Ethernet) RX packets 15855360759 bytes 28152973539857 (25.6 TiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 18662545884 bytes 50106349648702 (45.5 TiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 169.254.123.1 netmask 255.255.255.0 broadcast 169.254.123.255 ether 02:42:5d:35:2c:a1 txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.126.44.1 netmask 255.255.254.0 broadcast 10.126.45.255 inet6 fe80::216:3eff:fe04:f044 prefixlen 64 scopeid 0x20<link> ether 00:16:3e:04:f0:44 txqueuelen 1000 (Ethernet) RX packets 47299822878 bytes 52009596870995 (47.3 TiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 15870629225 bytes 28473012734415 (25.8 TiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 206578406 bytes 41531785821 (38.6 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 206578406 bytes 41531785821 (38.6 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth17c6a045: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::c852:a7ff:feea:db79 prefixlen 64 scopeid 0x20<link> ether ca:52:a7:ea:db:79 txqueuelen 0 (Ethernet) RX packets 1649108222 bytes 1061560042794 (988.6 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 2408831694 bytes 1559058233935 (1.4 TiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth33d81a46: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::a00a:79ff:fef6:4580 prefixlen 64 scopeid 0x20<link> ether a2:0a:79:f6:45:80 txqueuelen 0 (Ethernet) RX packets 30004746 bytes 5482022016 (5.1 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 32532180 bytes 7542843349 (7.0 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth39b96269: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::4870:6bff:fe77:31af prefixlen 64 scopeid 0x20<link> ether 4a:70:6b:77:31:af txqueuelen 0 (Ethernet) RX packets 64426153 bytes 133130314688 (123.9 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 72122493 bytes 30702560591 (28.5 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth3b068382: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet6 fe80::2430:6bff:feb1:7daf prefixlen 64 scopeid 0x20<link> ether 26:30:6b:b1:7d:af txqueuelen 0 (Ethernet) RX packets 27844048 bytes 175916392954 (163.8 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 29608187 bytes 7968825461 (7.4 GiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth3bfa9e82: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 ......
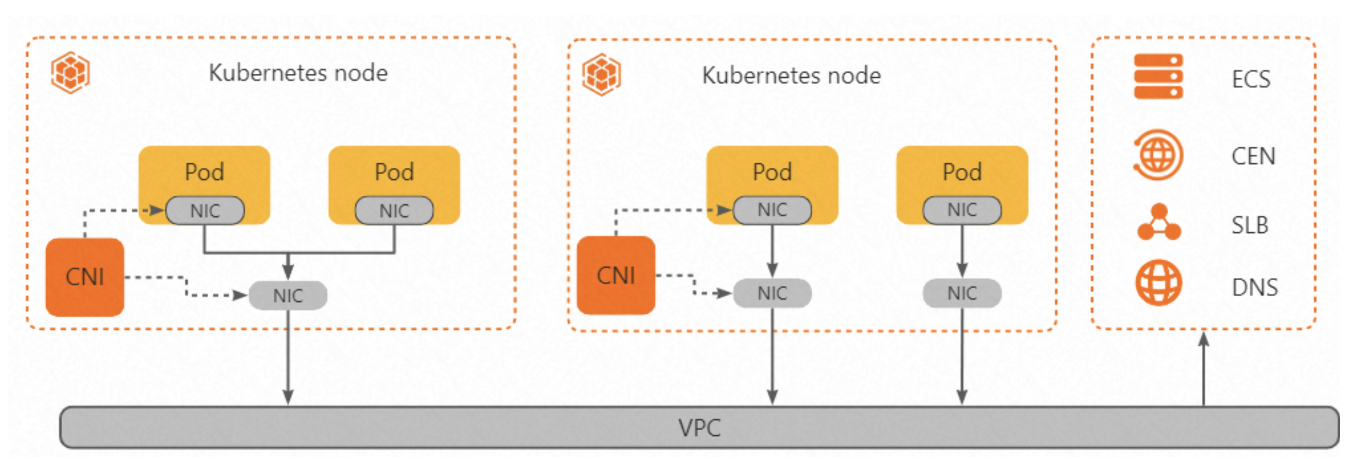
Terway
- Terway网络插件是ACK自研的容器网络接口(CNI)插件,基于阿里云的弹性网卡(ENI)构建网络,可以充分使用云上资源。Terway支持eBPF对网络流量进行加速,降低延迟,支持基于Kubernetes标准的网络策略(Network Policy)来定义容器间的访问策略。
- 在Terway网络插件中,每个Pod都拥有自己网络栈和IP地址。同一台ECS内的Pod之间通信,直接通过机器内部的转发,跨ECS的Pod通信、报文通过VPC的弹性网卡直接转发。由于不需要使用VxLAN等的隧道技术封装报文,因此Terway模式网络具有较高的通信性能。
Calico
https://www.projectcalico.org/

主要组件
- Felix:运行在每个需要运行workload的节点上的agent进程。主要负责配置路由及 ACLs(访问控制列表) 等信息来确保 endpoint 的连通状态,保证跨主机容器的网络互通;
- BGP Client(BIRD):读取Felix设置的内核路由状态,在数据中心分发状态。
- BGP Route Reflector(BIRD):BGP路由反射器,在较大规模部署时使用。如果仅使用BGP Client形成mesh全网互联就会导致规模限制,因为所有BGP client节点之间两两互联,需要建立N^2个连接,拓扑也会变得复杂。因此使用reflector来负责client之间的连接,防止节点两两相连。
查看calico-node相关组件,启动组件BIRD、Felix
其他信息忽略,通过命令行或CRD可见
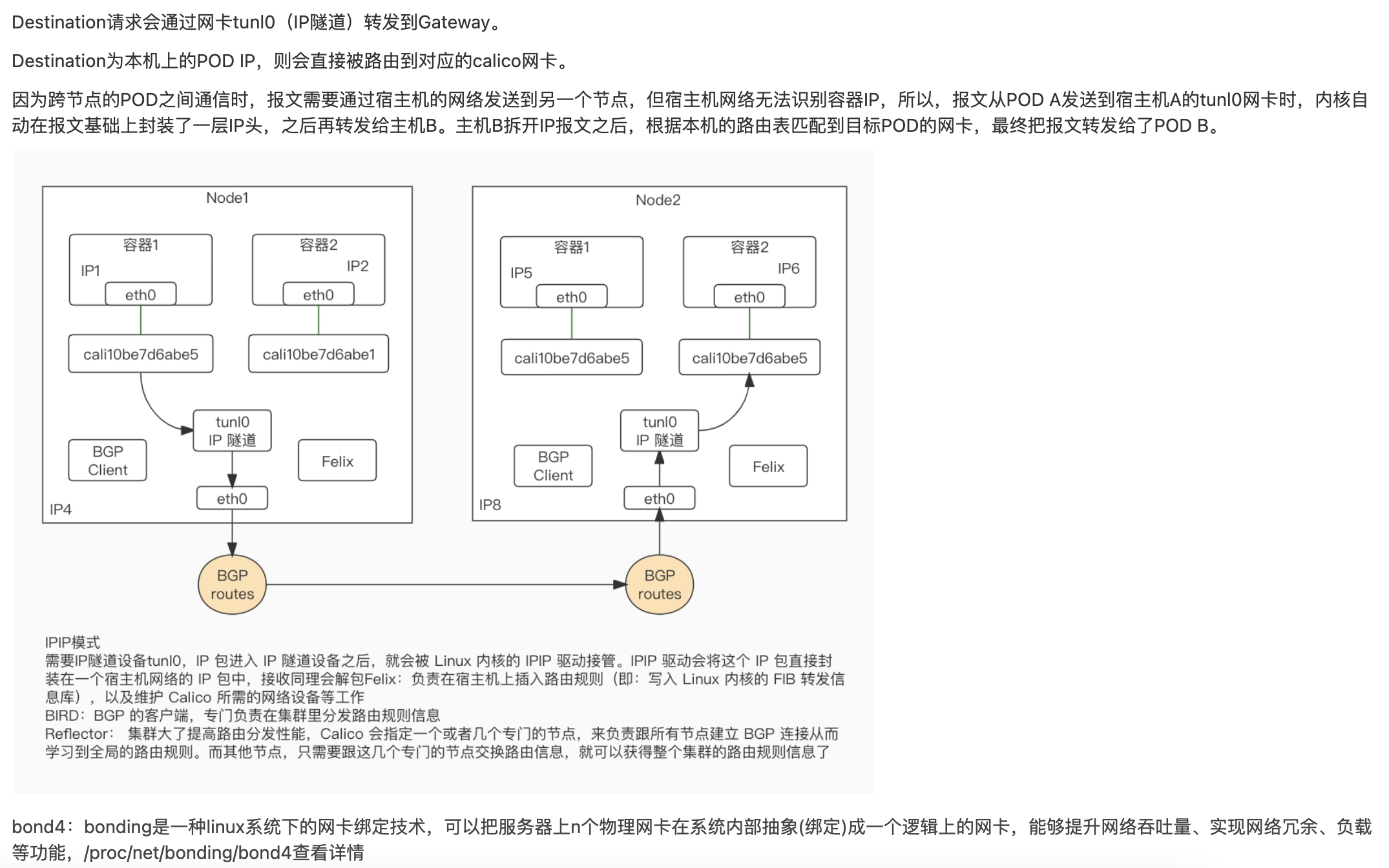
其他基础概念
| 二层网络 | OSI网络模型的数据链路层,处理网络上两个相邻节点的帧传递,mac地址为子层。宿主机之间二层不连通的情况比如宿主机分布在了不同的子网(VLAN)里。但是,在一个 Kubernetes 集群里,宿主机之间必须可以通过 IP 地址进行通信,也就是说至少三层可达 |
| 三层网络 | OSI网络模型中的网络层,主要关注在二层网络主机之间路由的数据包,ipv4\ipv6\ICMP是第三层网络协议的示例 |
| 隧道技术 |
网络基础设置在网络之间传递数据的方式,使用隧道技术传递可以是不同协议的数据包,隧道协议将这些其他协议的数据包重新封装在新的包头中发送。被封装的数据包在隧道的两个端点之间通过网络进行路由,被封装数据包在网络上传递时所经历的逻辑路径称为隧道 IP隧道是指一种可在两网络间进行通信的通道。在该通道里,会先封装其他网络协议的数据包,之后再传输信息 |
| IPIP |
普通的IPIP隧道,就是在报文的基础上再封装成一个IPv4报文 |
| VXLAN | 用于将二层以太网帧封装在UDP数据包中帮助云部署扩展,VXLAN虚拟化类似于VLAN,但比VLAN提供了更强大灵活性和功能 |
| 网桥 | 它是一个工作在数据链路层的设备,主要功能是根据 MAC 地址学习来将数据包转发到网桥的不同端口(Port)上 |
| NAT | Network Address Translation,网络地址转换 是将IP 数据包头中的IP 地址转换为另一个IP 地址的过程。在实际应用中,NAT 主要用于实现私有网络访问公共网络的功能 |
| SNAT |
Source Network Address Translation,源地址转换 是Linux防火墙的一种地址转换操作,也是iptables命令中的一种数据包控制类型,其作用是根据特定的条件修改数据包的源IP地址 比如:内部地址要访问公网上的服务时(如web访问),内部地址会主动发起连接,由路由器或者防火墙上的网关对内部地址做个地址转换,将内部地址的私有IP转换为公网的公有IP,网关的这个地址转换称为SNAT,主要用于内部共享IP访问外部 |
| DNAT |
Destination Network Address Translation,目的网络地址转换在Internet中发布位于局域网内的服务器,修改数据包的目的地址 比如:当内部需要提供对外服务时(如对外发布web网站),外部地址发起主动连接,由路由器或者防火墙上的网关接收这个连接,然后将连接转换到内部,此过程是由带有公网IP的网关替代内部服务来接收外部的连接,然后在内部做地址转换,此转换称为DNAT,主要用于内部服务对外发布 |
| Underlay Network | 底层设施,硬件通讯基础; 在 kubernetes 中,underlay network 中比较典型的例子是通过将宿主机作为路由器设备,Pod 的网络则通过学习路由条目从而实现跨节点通讯 |
| Overlay | 是现有网络上构建的虚拟逻辑网络,通常用于提供现有网络的抽象,能够分离和保护不同逻辑网络 |
| BGP | 管理数据包在边缘路由器之间的路由方式,通过考虑可用路径、路由规则和特定网络策略,帮助确定如何将数据包从一个网络发到另一个网络域。它跟普通路由器的不同之处在于,它的路由表里拥有其他自治系统里的主机路由信息,在使用了 BGP 之后,在每个边界网关上都会运行着一个小程序,将各自的路由表信息,通过 TCP 传输给其他的边界网关。而其他边界网关上的这个小程序,则会对收到的这些数据进行分析,然后将需要的信息添加到自己的路由表里 |
| IPTables | Linux内核功能,将灵活的规则序列附加到内核的数据包处理管道中的各种钩子上 iptables |
| IPVS | IP Virtual Server是在 Netfilter 上层构建的,并作为 Linux 内核的一部分,实现传输层负载均衡。IPVS 集成在 LVS(Linux Virtual Server,Linux 虚拟服务器)中,它在主机上运行,并在物理服务器集群前作为负载均衡器。IPVS 可以将基于 TCP 和 UDP 服务的请求定向到真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。ipvs |
| CIDR |
表示一段灵活的IP地址范围,ip/n,n标识网络位,前n不变,比如下面/8,就是二进制前8位不动 比如 10.0.0.0/8->00001010.00000000.00000000.00000000~00001010.11111111.11111111.11111111→子网掩码为255.0.0.0,对应网段为10.0.0.0~10.255.255.255 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号