MySQL索引总结
索引
索引的根本目的是减少磁盘 IO
索引原理
索引如果书的目录,如果没有目录,我们找一遍文章就只能一页一页的翻,直到翻完整本书才能找到所有自己需要的文章。有了索引就相当于有了目录,我们找一篇文章只需要在所有的标题中找到自己想要的数据,然后再根据目录(索引)指向的页码(ID)找到对应的文章。
上述只是一个简单的比喻,帮助我们理解为什么需要索引。其实有了索引不仅仅是查询目录方便,如果建立联合索引,还能避免再翻到书中寻找相关数据。
介绍索引原理前,我们先说下没有索引的查询流程。比如数据库a,有三个字段,id,name,age,我们需要查询name=张三的数据。开始查询name=张三 =》加载磁盘数据 =》 一条一条数据查询name=张三的数据 =》 查询整个表 =》 查询完毕。
在看下有了索引之后的流程,其实索引是一种数据结构,这里我们先简单认为是按照索引字段排序的二叉树。开始查询name=张三 =》 根据二分法定位到张三 =》根据这条数据ID回到磁盘查询整条数据 =》 顺序查找下个数据,直到name != 张三 =》 查询完毕。通过对比发现:
1、无索引的查询,需要读取整个表
2、有索引的查询只需读取所需数据,但是可能需要多一步根据ID到磁盘读数据的操作
由此可见,如果数据量很大,而需要的数据又占比整个数据库很少,有索引是会快很多的。如果需要查询的字段值在数据库中占比很大,可能没有索引会更好一点
索引结构
Hash 索引
Hash 索引虽然是常见的索引结构,但是比较少使用,适用用精确查询,不适用范围查询和模糊查询,因此实际使用中并不多
二叉树
* 二叉树是最经典的数据结构之一,也是很多结构,很多数据结构都是有二叉树引申出来的。二叉树顾名思义,每个节点有两个子节点,很像分叉的树枝。
* 二叉树有节点和子节点组成,一个子节点最多只能有两个子节点。左子节点比本节点小,右子节点比本节点大,时间复杂度为 O(n)
* 二叉树根节点会跟随数据变动而变动,因此数据量越大,变更数据时越复杂,查询时磁盘IO越多
B 树
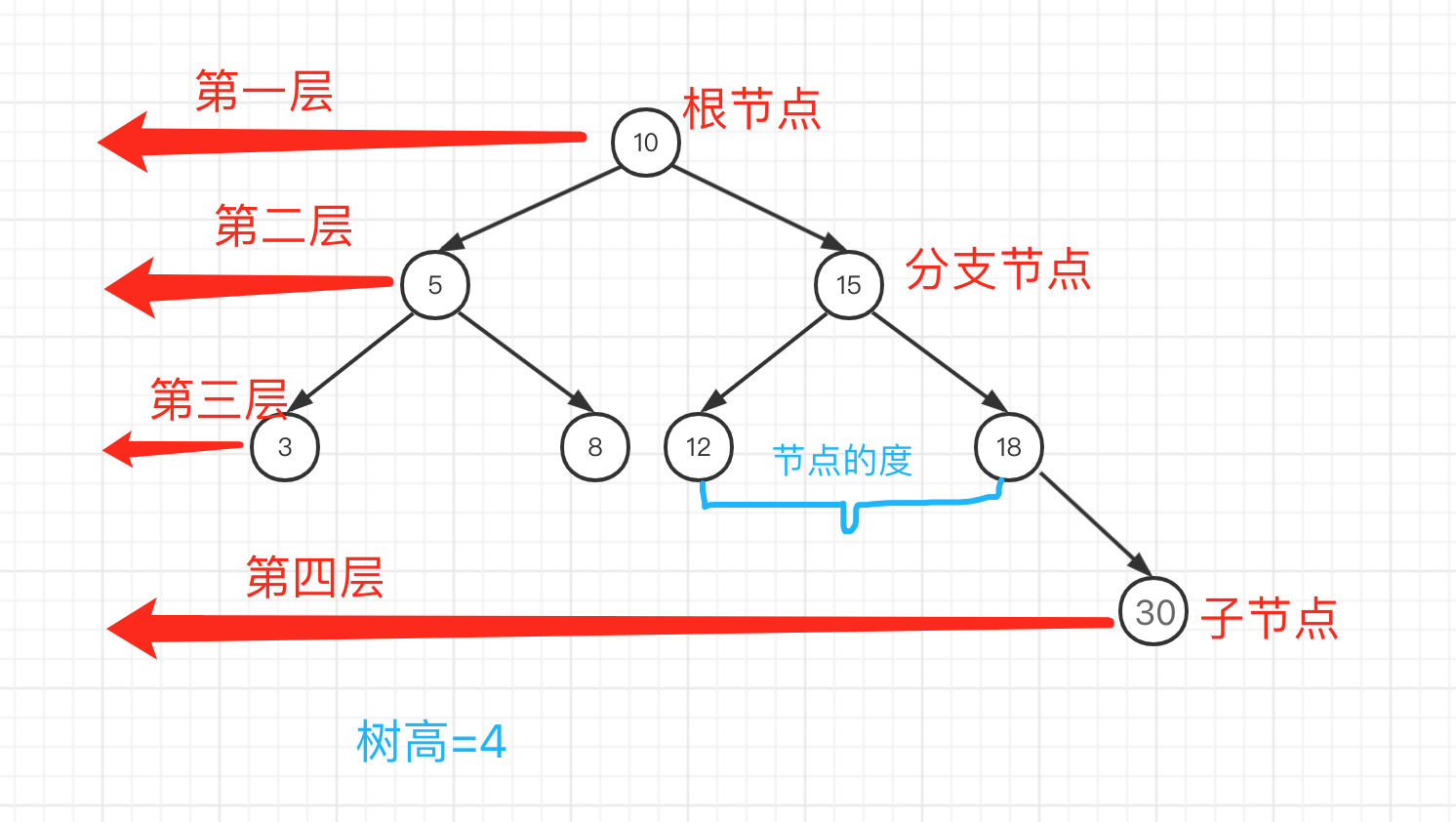
B 树和二叉树最大的不同是所有的叶子节点都在同一层,一个 m 阶的 B 树有一下特征
* 根节点至少有两个子节点
* 每个中间节点都包含 k-1 个元素和 k 个孩子,m/2 <= k <= m
* 所有的叶子节点都在同一层
* 每个节点中的元素从小到大排列
B+ 树
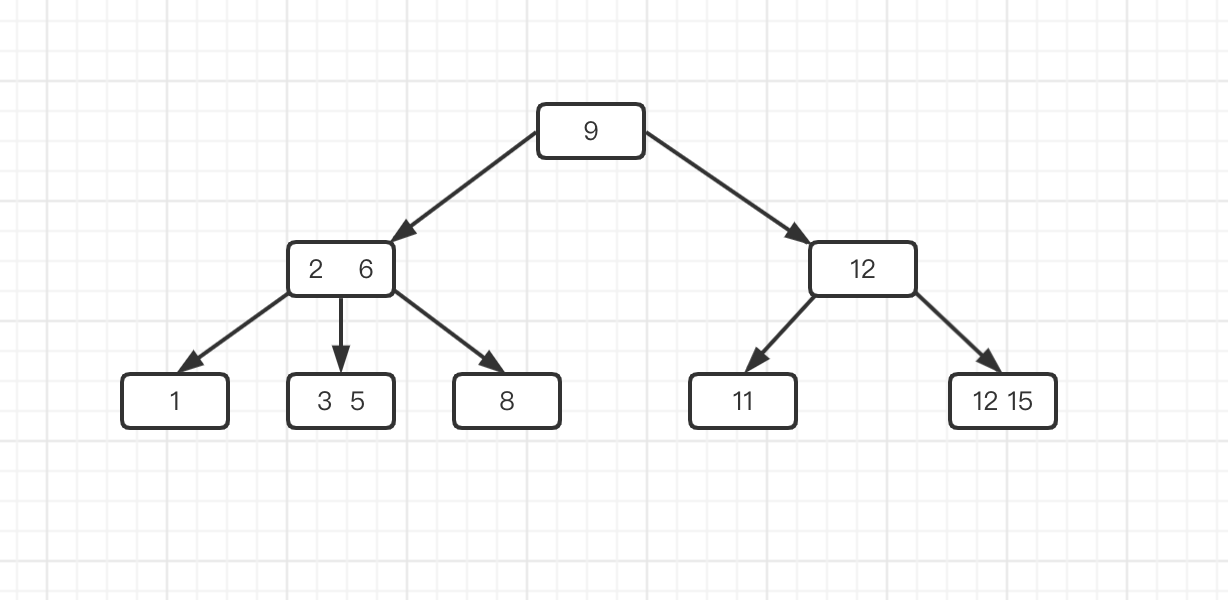
B+ 树和 B 树最大的不同是叶子节点包含中间节点的元素,子节点是顺序链接。MySQL 中,B+ 树的数据存放在叶子节点中,B 树的数据存放在每个节点中。一个 m 阶的 B+ 树有一下特征
* 每个中间节点都包含 k 个元素和 k 个孩子,每个元素不保存数据
* 所有的叶子节点包含全部的元素信息,以及指向这些元素记录的指针,且叶子节点依关键词的大小从小到大顺序链接。叶子节点元素包含数据
* 所有的中间元素都存在与叶子节点中,在叶子节点元素中属于最大(或最小)
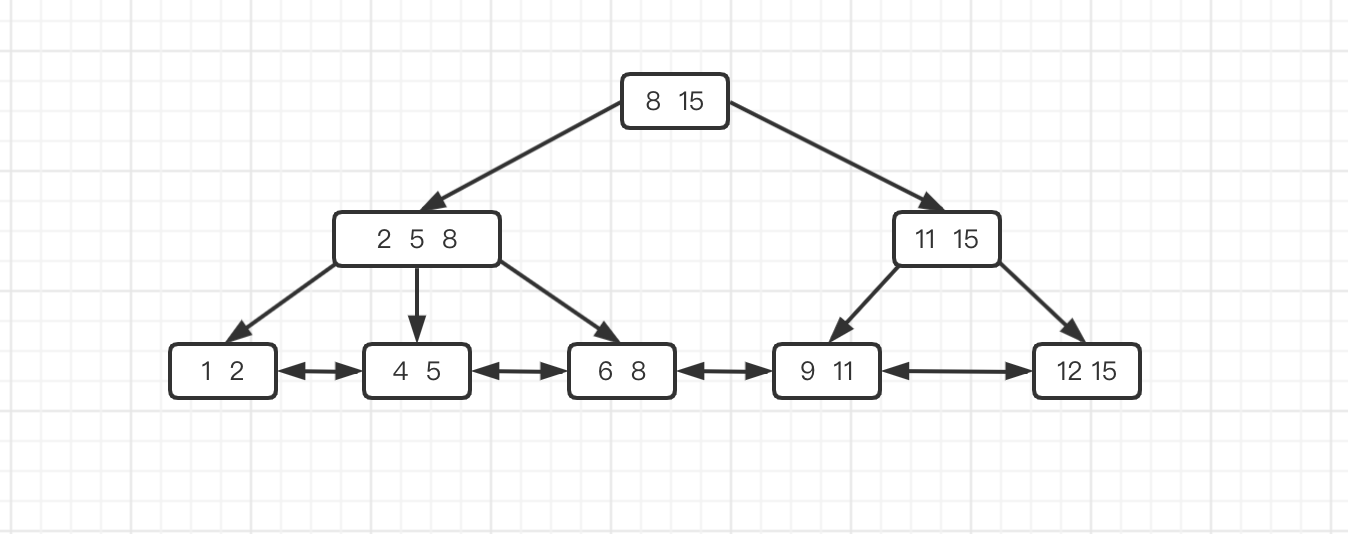
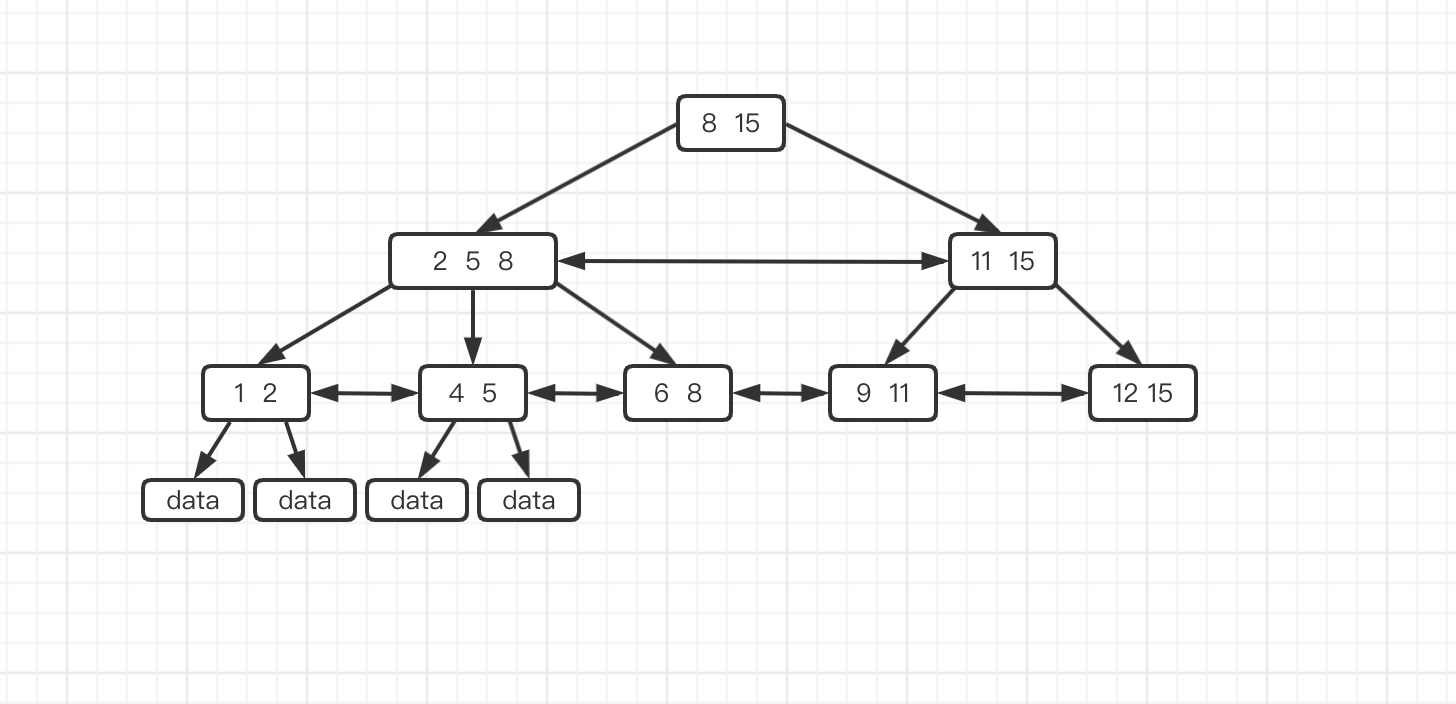
数据存储
* B+ 树中每个节点也叫索引页,叶子节点中数据的存储叫做数据页,叶子节点元素保存的是数据页的地址。索引页和数据页默认大小是16K,因为 B+ 树除了叶子节点其余节点中的元素都不包含数据,因此每个页中存储的元素页更多,也因此 B+ 树比 B 树查询 IO 次数更少
* 磁盘每次按照 4 k 读取,相当于每次至少读取4块(页)数据
* 当一条新记录被插入到InnoDB clustered index中时,InnoDB预留page的1/16的空间以备将来插入或者更新索引记录。
* 索引页中保存了两个指针,分别指向前一个索引页和后一个索引页
索引类型
根据字段特性区分,索引分为:主键索引、唯一索引、普通索引、前缀索引
* 主键索引:不能为空且唯一,一般创建表的时候创建,InnoDB 中,主键索引是聚簇索引,一个表只能有一个主键
* 唯一索引:一个表可以有多个唯一索引,值可以为空,多个空值不会触发冲突
* 普通索引:可以重复,可以为空值
* 前缀索引:是指对字符类型字段的前几个字符或对二进制类型字段的前几个bytes建立的索引,而不是在整个字段上建索引。前缀索引可以建立在类型为char、varchar、binary、varbinary的列上,可以大大减少索引占用的存储空间,也能提升索引的查询效率
优化索引
索引的优化不仅限于索引创建、SQL的优化,思想也要灵活多变,不要执着于一种方式,目的是减少程序执行时间
无效的索引
* 索引值重复率过高,比如a字段的一个值占总数的3分之2,根据这个值搜索表中所有字段值,MySQL流程是:普通索引找到ID-》根据ID走主键索引找到所有数据-》返回。如果不走索引,就是全盘扫描,虽然扫描的行数比较多,但是少了根据普通索引找ID的这步,因此不使用索引可能会更快些
* 模糊查询,MySQL 索引查询原则是从左向右匹配,所以 like "test%" 可以走索引,但是 like "%test" 或者 like "%test% 都不会走索引。如果建立的组合索引,第一个字段是范围查询或者模糊查询,则后续字段不会再走索引
* 已经建立了组合索引的第一个字段,又单独建立索引。比如建立组合索引 a、b两个字段,a 字段不需要重新再建立索引字段的,因为组合索引优先匹配左边的字段也就是a字段
索引优化及使用
* 覆盖索引,查询的字段都在索引中叫做覆盖索引(注意:每个索引都包含主键的)。覆盖索引不是一种索引方式,也不是靠特殊创建,而是使用索引的一种方式。比如创建索引a,查询语句为 select a,id from test where a=1; 查询的字段 a、id都在索引中,那么这个查询就使用了覆盖索引。因为查询的字段都在索引中,不需要额外回表操作,因此能够有效减少磁盘 IO
* 合适的场景 order by字段也可以做索引,或者放在组合索引中。索引是有排序的,因此即不需要重新排序,也不需要回表查询。没有索引流程:普通索引查询-》根据ID主键索引查询-》放到内存中排序-》(如果内存不足,利用临时文件辅助排序-》)排序-》完成。如果单行数据很大,上边这个排序效率不够好,会分太多临时文件。因此会有新的算法排序,路程:普通索引查询-》根据ID主键索引查询需要排序的字段和ID->放入缓存-》排序-》根据ID主键索引查询所需字段-》完成
* 索引字段尽量小,最好是数字。因为索引页大小是固定的,因此字段越小,索引页存储数据越多,磁盘IO越少。如果是字符串类型,可以适当使用前缀索引
* 更新频繁的字段不易创建索引,因为更新操作会重建索引,增加消耗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号