self-attention笔记
传统rnn模型
计算公式
\(h_{i} = tanh(W_{xh}x + W_{hh}h_{i-1} +b_{h})\)
\(y = sigmoid(W_{hy}h_{i}+b_{y})\)
其中W_{xh}和W_{hh}会合并成W_{h}:
\(h_{i} = tanh(W_{h}[x,h_{i-1}] +b_{h })\)
\([x,h_{i-1}]\)代表在列 的维度上进行拼接
缺点
在解决长序列之间的关联是,传统rnn模型变现很差,在进行反向传播时,过长的序列会导致误差反向传播,梯度计算异常,造成梯度爆炸或梯度消失。
m对n结构
(encoder/decoder结构)(seq2seq):
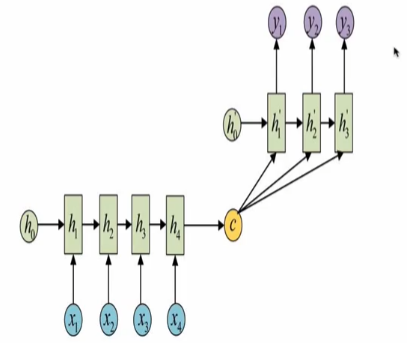
rnn代码实现
pytorch:
nn.RNN() 第一个参数:输入张量x的维度,input_size
第二个参数:隐含层特征h的维度,hidden_size
第三个参数:隐含层的数量,num_layers
input:
第一个参数:sequence的长度
第二个参数:batch_size
第三个参数:单个向量的长度,input_size
h0:
第一个参数:隐含层的数量,num_layers
第二个参数:batch_size
第三个个参数:隐含层的维度,hidden_size
rnn_layer = nn.RNN(5, 6, 1)
input = torch.randn(1, 3, 5)
h0 = torch.randn(1, 3, 6)
y, hn = rnn_layer(input, h0)
y.shape,hn.shape # torch.Size([1, 3, 6]))
for name, para in rnn_layer.named_parameters():
print(name, para.shape)
weight_ih_l0 torch.Size([6, 5])
weight_hh_l0 torch.Size([6, 6])
bias_ih_l0 torch.Size([6])
bias_hh_l0 torch.Size([6])
lstm模型(长短期记忆网络)
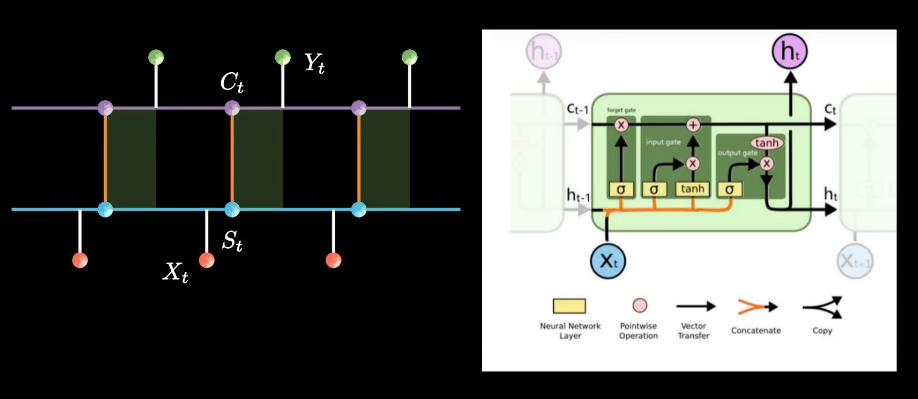
计算公式
遗忘门:\(f_{1} =sigmoid(W_{f_{1}}[x,h_{t-1}]+b)\)
记忆门:\(f_{2} =sigmoid(W_{f_{2}}[x,h_{t-1}]+b_{f_{2}})*tanh(\hat{W} _{f_{2}}[x,h_{t-1}]+\hat{b}_{f_{2}})\)
\(c_{t}=c_{t-1}*f_{1}+f_{2}\)
输出门:\(h_{t}=sigmoid(W_{h}[x,h_{t-1}]+b)*tanh(c_{t})\)
bi-lstm
双向lstm,并没有改变lstm的结构,只做了输出结果的拼接
lstm代码实现
nn.LSTM(5, 6, 2)
第一个参数:输入x的维度,input_size
第二个参数:隐藏层张量的维度,hidden_size
第三个参数:隐含层的数量,hidden_layer
第四个参数:是够使用双向lstm
x = torch.randn(1, 3, 5)
h0 = torch.randn(2, 3, 6)
c0 = torch.randn(2, 3, 6)
y, (hn, cn) = lstm(x,(h0,c0))
for name, para in lstm.named_parameters():
print(name, para.shape)
weight_ih_l0 torch.Size([24, 5])
weight_hh_l0 torch.Size([24, 6])
bias_ih_l0 torch.Size([24])
bias_hh_l0 torch.Size([24])
weight_ih_l1 torch.Size([24, 6])
weight_hh_l1 torch.Size([24, 6])
bias_ih_l1 torch.Size([24])
bias_hh_l1 torch.Size([24])
attention
rnn网络改进了传统神经网络,建立了网络隐层间的时序关联
与encoder-decoder结构只产生一个中间c,attention机制打破了只能形成单一向量的限制,每个时间输入不同的c。
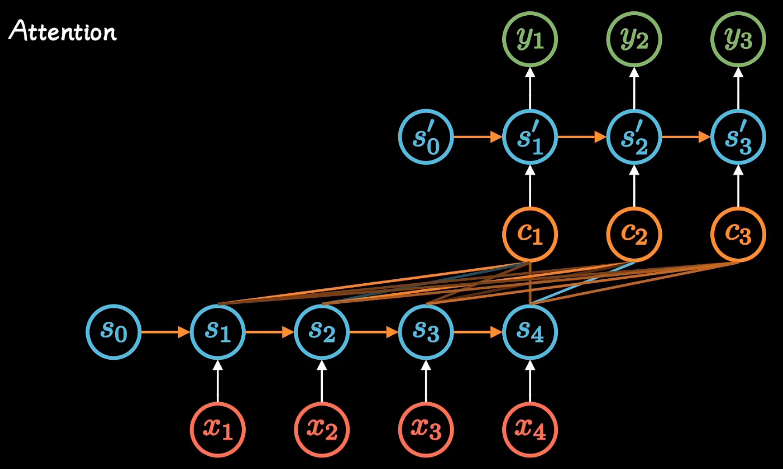
突破并行计算的限制,去掉了隐层间的时序关联,因为attention本身就已经对这些时序进行了打分。
由此产生了self-attention.。
attention就是权重,权重就是attention。
本质上就是通过加权求和,解决上下文的理解问题。在不同的上下文专注于不同的信息。
attention参数更少,速度更快,效果更好
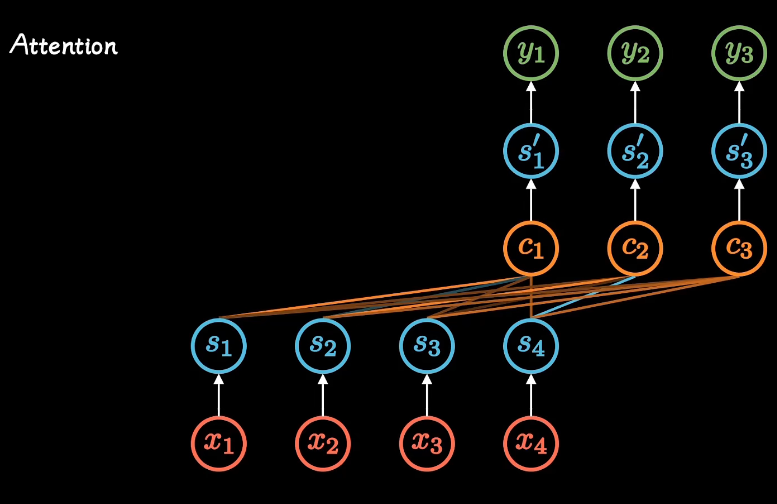
注意力层有很多实现方式,无外乎输入seq得到seq

 浙公网安备 33010602011771号
浙公网安备 33010602011771号