实验记录 | Qwen2 文本分类/命名实体识别
Qwen-2 微调实战
Intro
指令微调
指令微调(Instruction Tuning)是一种针对大型预训练语言模型的微调技术,其核心目的是增强模型理解和执行特定指令的能力,使模型能够根据用户提供的自然语言指令准确、恰当地生成相应的输出或执行相关任务。
指令微调特别关注于提升模型在遵循指令方面的一致性和准确性,从而拓宽模型在各种应用场景中的泛化能力和实用性。
命名实体识别 (NER)
命名实体识别 (NER) 是一种NLP技术,主要用于识别和分类文本中提到的重要信息(关键词)。这些实体可以是人名、地名、机构名、日期、时间、货币值等等。 NER 的目标是将文本中的非结构化信息转换为结构化信息,以便计算机能够更容易地理解和处理。
Experimental Setup
参考 [1] [2] [3] 进行实验。加速卡为 3080 Ti。
- nproc = 64
- Core(s) per socket = 16
- Intel Xeon Silver4314@2.40 GHz
- NVIDIA Corporation GA102 [GeForce RTX 3080 Ti]
- CUDA Version = v11.8.89
- Python 3.11.2
Train
使用 Qwen2-1.5b-Instruct 模型在复旦中文新闻数据集上做指令微调训练,同时使用 SwanLab 监控训练过程、评估模型效果。采用了 Lora 微调,所以显存要求不高,10GB 左右就可以跑。因此使用了 3080Ti (12G)。
文本识别任务。根据教程说明,应该是跑了 2 个 epoch,算上下载,耗时半小时左右。
Results
文本分类
| train/loss | train/grad_norm | train_learning_rate | train_epoch |
|---|---|---|---|
 |
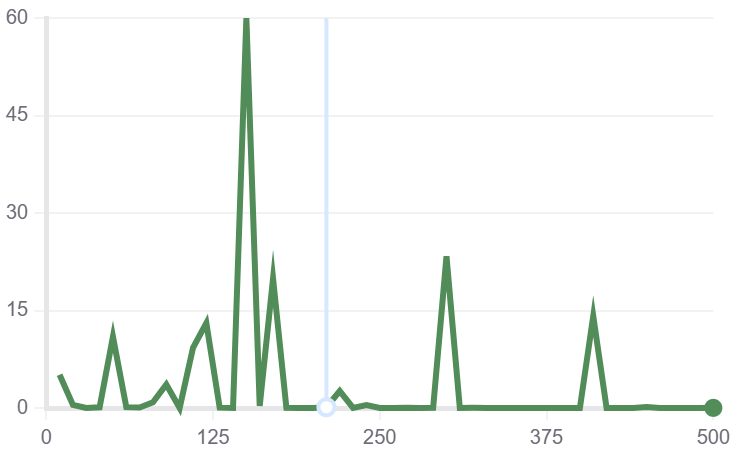 |
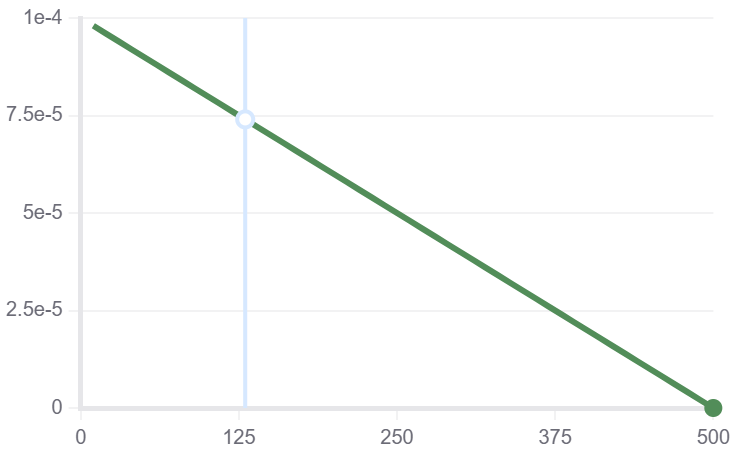 |
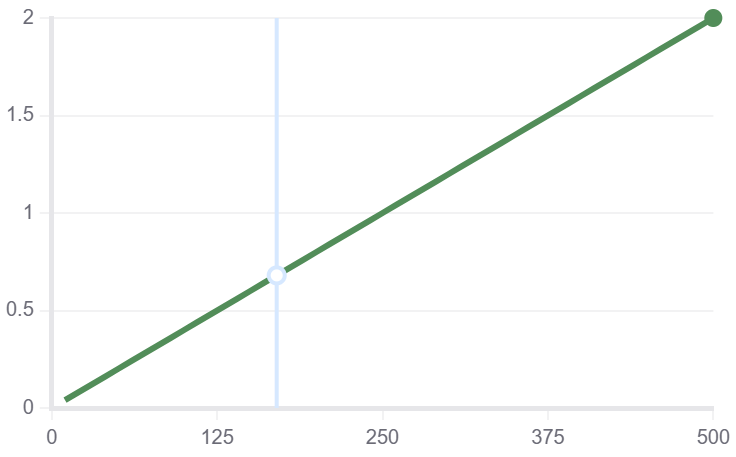 |
root@pve:~/share/projects/LLM-Finetune-main/train-qwen2-text# python predict_qwen2.py
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Space
NER
| train/loss | train/grad_norm | train_learning_rate | train_epoch |
|---|---|---|---|
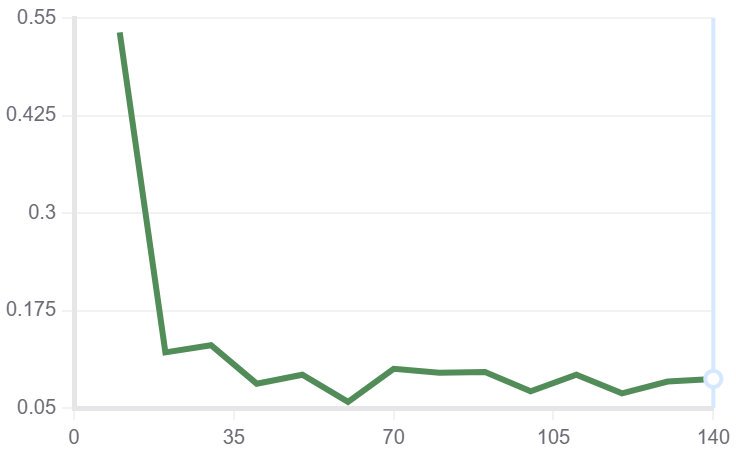 |
 |
 |
 |
需要根据 Tutors 修改 predict_qwen2.py
root@pve:~/share/projects/LLM-Finetune-main/train-qwen2-ner# python predict_qwen2.py
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
{"entity_text": "西安电子科技大学", "entity_label": "组织"}{"entity_text": "陈志明", "entity_label": "人名"}{"entity_text": "西北工业大学", "entity_label": "组织"}{"entity_text": "苏春红", "entity_label": "人名"}{"entity_text": "中国", "entity_label": "地理实体"}{"entity_text": "苏州", "entity_label": "地理实体"}
root@pve:~/share/projects/LLM-Finetune-main/train-qwen2-ner#
Summary
顺利把实验跑完了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号