论文阅读 | LIR
网络结构优化 | LIR
UESTC MM’24
针对现有 IR 网络喜欢堆叠基本块、导致参数冗余和不必要计算等问题,提出轻量化的 LIR Baseline 网络。
Basis
一些关键词。
- 图像评价常用指标
- PSNR (峰值信噪比)
- SSIM (结构相似性)
- LAA (Lightweight Adaptive Att)
- patch embedding
- adaptive spatial aggregation
- PCA; contrastive learning paradigm
- multi-task learning
- U-Net
- ViT
Introduction
- local and global residual connetcions (局部和全局的残差连接) 可能会将输入图片的 degradation 传播到整个网络,包括 RM (重建网络) 一侧。
- 用可视化方式展示,现有方法都把原始输入的退化 (degradation) 传递到了整个网络,甚至输出。
- 另一个问题。当前工作的特征图,轮廓模糊,噪声明显,并且存在高频信息丢失。
- 针对 (1) 提出去掉一些残差连接。针对 (2) 提出自适应滤波器 (a component of LAA),用于在各种任务中自适应提取高频信息,和增强物体轮廓。
- 谈及 Transformer 时代 MLP 和 CNN 的重要性。有文章认为给 CNN 添加注意力和 patch embedding 后,达到与 Transformer 相似的性能。
- 针对 (5) 提出 patch embedding + MLP 构造一个 Patch Att,捕获全局信息同时减少计算量。
Related Works
- IPT 是首个将 ViT 引入 low-level IR tasks
- 关于 ViT self-att 的计算复杂度。"The computational complexity of the self-attention part in ViT is \(O(𝑁^2𝐷)\), where \(𝑁=𝐻×𝑊\) represents the length of the patch sequence and \(𝐷\) represents the dimension of the sequence."
- Vision Transformer 捕获长期依赖 (long-range dependencies)
Section 2.2 主要讨论 att 的计算复杂性问题,并引出本文工作 Patch Att 用于近似自注意力,并降低计算量。
Methodology
Overview
有大量跳跃连接,用于与不同阶段的特征图做差,并进一步提取高频,用于补强特征提取过程中的细节损失。
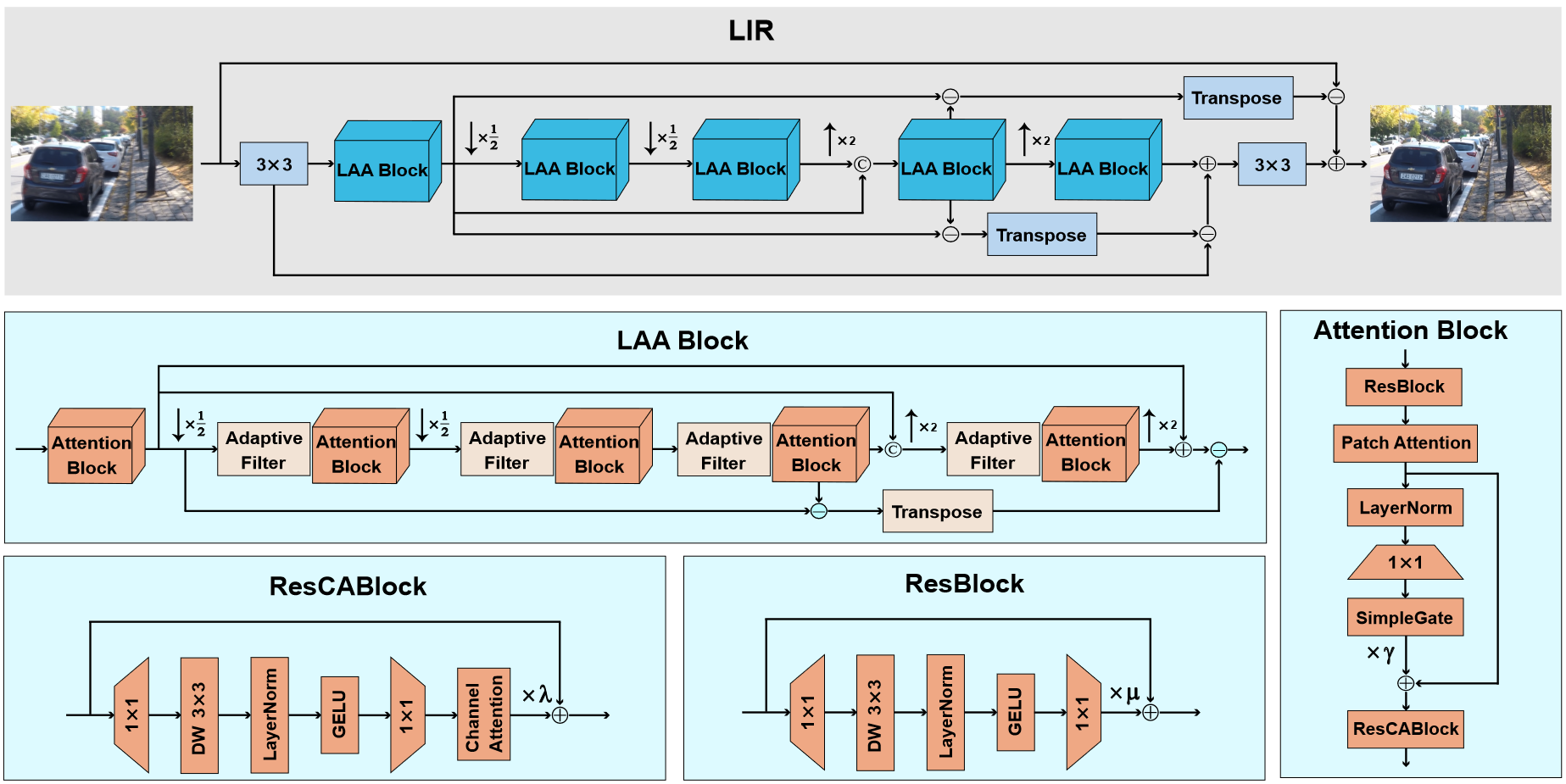
down-up style, that is, downsizing the feature map in the beginning and upsizing at the end. (后面还有提到 up-down style)
2 个全局残差连接和 1 个局部残差连接用于保留低频信息并保证训练稳定性。这里说 residual connection 能够保留低频信息,gpt-4o 给出的解释是,促进信息流动、减少梯度消失、允许特征重用和提高模型的平滑性等。不是很理解。
总之认为 “the feature map of the shallow layer contains more degradation compared to a deep layer” ,于是在第 1 和第 4 个 LAA 块间做差获得退化量,并放大用于最终的退化修正。
Adaptive Filter
这个滤波器想法来自 ECB,用于增强轮廓、消除图像退化和强化 (有用的) 高频信息。结构上是 9 个基本算子 (Laplation Sobel Roberts) + 1 个原始输入的加权,如图所示。
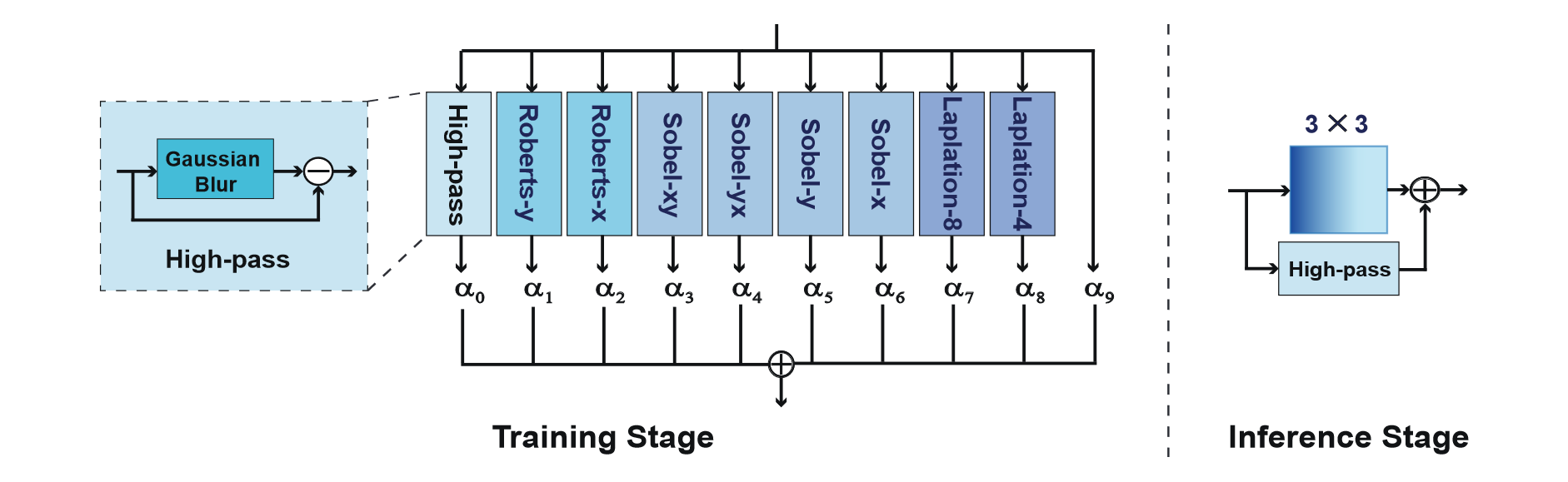
相较于 ECB 有如下优势
- 参数量小,训练简单
- 灵活 (调整参数)
- 鲁棒性好
感觉是把平均改成加权,然后丰富了滤波器的种类。
Att Block
自适应滤波器采集到的信息在 Att 加以利用。本工作的 Att 块包含以下部分
- ResBlock: 输入特征预处理
- PatchAttention: 提取全局信息
- SimpleGate: 门控,进一步提取特征间的依赖关系
- ResCABlock: 利用通道注意力 (CA) 模块,提取通道级 (channel-wise) 信息
其中,ResCABlock 含有 Channel Attention Module,在提取通道级信息方面表现良好。
为使 Att 块能够捕获全局信息,引入 Patch Attention 相较于 Transformer 中注意力计算的矩阵乘法开销和 q, k, v 之间的 softmax 计算,本工作使用元素级乘法和 MLP 来简化注意力计算。
Summary
提出一种轻量级的用于 IR 任务的网络。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号