论文阅读 | GSDM
Diffusion-based | GSDM
SEU AAAI’24
一篇基于 Diffusion 的针对文本图像恢复(场景文本 STR + 手写文本 HTR)的文章。
Methodology
Overview
GSDM 由 SPM + RM 构成,如图所示
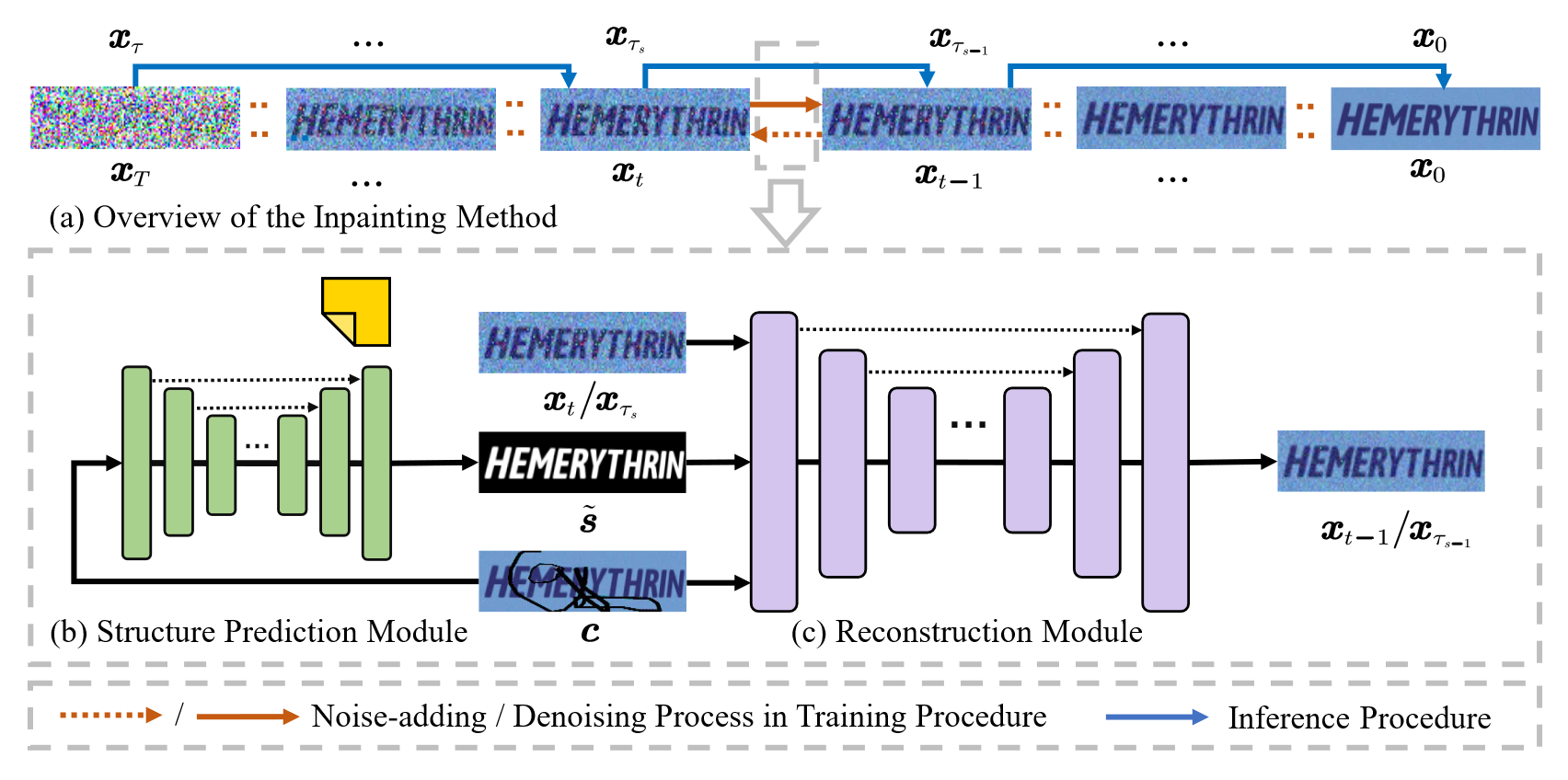
其中
- Input: \(c \in \mathbb{R}^{h \times w \times c}\)
- SPM: \(\tilde{s}\in\mathbb{R}^{h \times w}\)
- \(c + \tilde{s}\) → RM: \(\tilde{x} \in \mathbb{R}^{h \times w \times c}\)
SPM 由单个 U-Net[1] (denoted as \(g_\theta\)) 实现,用于从损坏图像预测完整图像的正确前景分割掩膜。为了增加 感受野,增强对周围损坏区域的感知,将 空洞卷积 (Yu et al. 2017) 引入网络。
Loss
损失函数共 4 个,其中两个用于评估掩膜预测:
- 像素 MAE (\(\ell_1\)?)
- BCE[2]
这里 \(s_i\) 和 \(\hat{s_i}\) 分别作为真实标签和预测概率。
另提出两个用于保持语义一致性 (p.s. 一说,\(\ell_2\) / \(\ell_1\) 用于保持一致性):
- 字符感知损失,即对比在特征空间的相似性
- 风格损失 (Gram 矩阵)
最终的 \(\mathcal{L}\) 是几个 loss 的加权。与开山作 Context Encoder 类似 (后者是 \(\ell_2\) + GAN),都是评估不同指标的损失函数线性叠加。部分用来维持一致性,部分用来维持风格 / 分布 / 语义明确等 (总之是这种意思)。
重建模块
也相当于一个解码器,基于 DDPM 的重参数化技巧,并参考了 DALL-E 2 的训练过程。
推理阶段使用一个非马尔可夫过程来加速。
优化目标
提到,用作 baseline 的是 \(\mathcal{L}_{pix}\) 和 \(\mathcal{L}_{rm}\)
Summary
总结如下
- 消融实验很完整,首先是模块,其次是模块内 (RM 使用 markov vs. non-markov),最后是损失函数。
- 贡献了一个数据集。其他就是射箭再画靶了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号