论文阅读 | AMP-Net
AMP-Net
UESTC TIP 2021
Introduction
- 再次提到 “structureinducing regularizers” (结构诱导的正则化项) 如某些变换域的稀疏性、低秩等。
- 再次提到压缩感知重建是求解一个欠定的线性逆系统 (under-determined linear inverse system)
- NN-based methods. “no good interpretation and theoretical guarantee”
- deep unfolding. “a good balance between reconstruction speed and interpretation”
- It has been proved that combining multiple kinds of image prior knowledge can get better reconstruction results than single one. 最终的工作都落在使用 DNN 建模正则项以集成更多的先验信息。
- “data-driven end-to-end”
一些经典的非线性迭代算法,用于求解上述优化问题,包括
- fast iterative shrinkage-thresholding algorithm (ISTA) 迭代收缩阈值算法
- approximate message passing (AMP) 近似消息传递
- sparse Bayesian learning
- orthogonal matching pursuit (OMP) 正交匹配追踪
- iterative hard thresholding (IHT)
Preliminary
优化目标由下式给出
\(\mathcal{R}(\textbf{x})\) 为正则项。约束 \(\textbf{y}=\textbf{Ax}\) 的含义是,由于问题是欠定的 (数次提到 \(M \ll N\)),满足这个约束的重建有很多种。而正则项 \(\mathcal{R}(\cdot)\) 正是用于进行结构先验的约束 (类似 Inpainting 中利用正则项进行风格约束)
AMP Algorithm
The AMP algorithm interprets the classical linear operation as the sum of the original data and a noise term:
where \(\textbf{x}' \in \mathbb{R}^N\) is an estimate of \(\textbf{x}\). (前面看起来是 \(\frac{1}{2}\|\textbf{Ax}'-\textbf{y}\|_2^2\) 的梯度更新方向,整体就是 \(\textbf{x}'\) 的更新)
Backgrounds
AMP 分析了迭代非线性算法的一个经典方案
式中
- \(\textbf{A}\): 采样矩阵
- \(\mathcal{T}_k(\cdot)\): 非线性函数
这里求 \(\textbf{z}^{k-1}\) 并计算 \((\textbf{A}^T \textbf{z}^{k-1} + \textbf{x}^{k-1})\) 与 ISTA-Net 求 \(\textbf{r}^{(k)}\) 实际上做的是同一件事,第二步也是差不多的,都是在梯度更新后的 \(\textbf{x}'\) 上再进行一次非线性操作 (即此处的 \(\mathcal{T}_k\)),即:保真 (约束) 项和正则项交替计算。
这里 AMP 把 \(\textbf{x}^{k-1} \rightarrow \textbf{x}^{k}\) 过程解释为 \(\bar{\textbf{x}}+\textbf{e}\),后者是一个 Gaussian Noise. AMP 把迭代过程解释为 去噪视角 (denoising perspective).
是否可以由此引入 Diffusion
Architecture
Overview
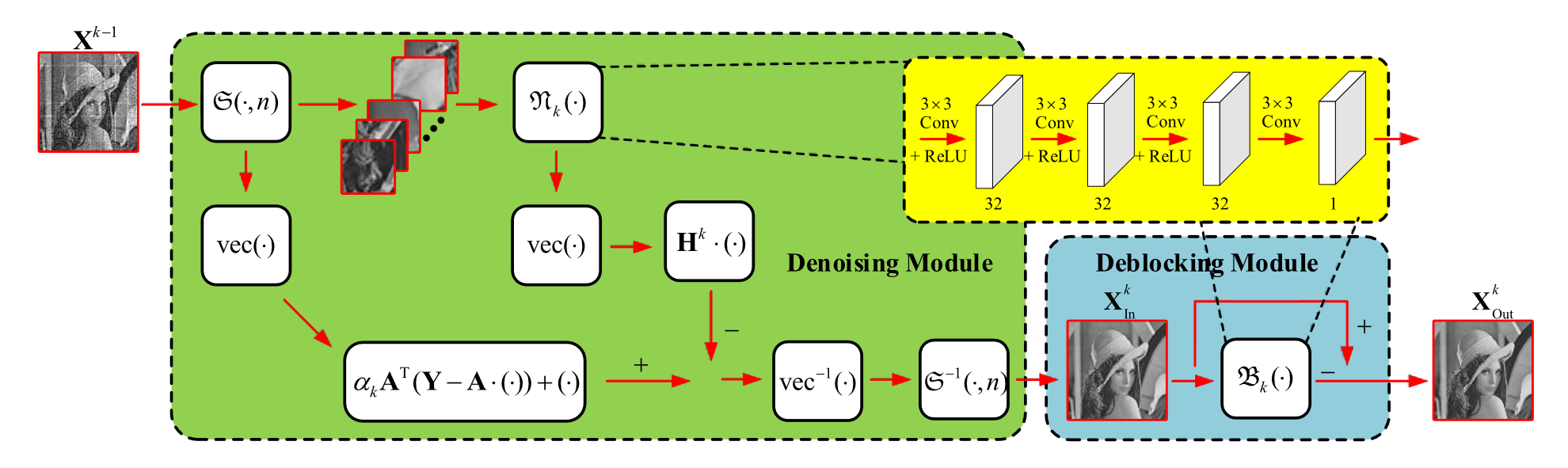
整体结构如图所示。
Sampling Model
ISTA-Net 没有详细讲述采样过程 (其采样矩阵是固定的),但 AMP-Net 是一个端到端网络,并进行了精讲。
式中 \(\mathbf{X}\in\mathbb{R}^{L \times P}\) 为原始输入的单通道图像,\(\mathbf{Y}\in\mathbb{R}^{M \times I}\) 为采样后的测量值。\(\mathbf{A}\) 是可学习的。从整个网络的顶层视角来看,\(\mathbf{X}\) 是网络的输入,输出 \(\mathbf{X}'\) ,像是训练了一个自编码器。
Reconstruction Model
由 Initialization Module 和 Reconstruction Module 组成。首先,Initialization Module 生成一个合理的初始化估计。后有多个 Reconstruction Module,又由 Denoising Module 和 Deblocking Module 组成。
Reconstruction Module 完成的任务如下。
注意 \(\textbf{X}^0\) 与 \(\textbf{X}\) 不同,是我们从 \(\textbf{Y}\) 重建出来的。
\(\mathbf{B}\) 是可学习的。区别于 ISTA-Net 直接用 \(\mathbf{X}\) 的先验对 \(\mathbf{X}^0\) 初始化
观察 ASP-Net 的更新过程
前两项是梯度下降。之后需要过一次非线性变换 (对应前文 \(\min_x \mathcal{R}(\textbf{x})\) 形式),这里是把 \(\mathcal{N}_k\) 用神经网络建模了。最后得到的是一个加性的非线性变换,可表述为 (省略了 \(\textbf{x}_i\) 经 \(\mathcal{S}^{-1}(\cdot, \textbf{x})\) 替换为 \(\mathbf{X}_i\) 的过程)
这里 \(\mathcal{D}(\cdot)\) 可以代表一个非线性的去噪过程,因为 AMP 把迭代过程中含 \(\bar{x}_i - x_{k-1}\) 的项视为一个噪声。区别于 ISTA-Net,其过程表述为
接下来是 Deblocking Module.
“Reconstructing images block-by-block without overlapping may lead to a situation that additional deblocking operations must be carried out.”
这里也是 ASP-Net 一直在强调的 block-by-block,即 \(\mathcal{S}(\cdot)\) 的主要任务。提到,这个操作可能需要一步额外的去噪,因而再次应用 denoising perspective 思想,即
从而
\(\mathcal{B}_k\) 也使用网络来建模。
(所以一开始为什么要进行分块)
Loss
只有一个 \(\ell_2\).
Experiments
比 ISTA-Net 效果更好,可能原因
- 采样过程也纳入可学习的范畴,从 \(\mathbf{X}\) 提取到更充分的先验
- 网络层数更多 (?)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号