一次 SQL 优化经历
背景
货架系统1期实现了收口各系统的售前售卖配置和治理,2期希望能统一对货架售卖商品提供实时的风控、监控、报表功能。
难点
要求对近 7 天的售卖数据进行聚合,时间跨度大,数据量大,且要保证实时性,单纯 SQL 语句无法达到目标。
数据报表
需求: 统计每个货架一周内的下单量和支付量,货架表总数量为 700w+。翻译一下需求就是对于 create_time 在一周内的数据,按照 shelf_id 分组,分别统计各个分组的记录总数和支付总数。
建表语句如下:
CREATE TABLE `tbl_sale_product_info` (
`id` bigint(20) AUTO_INCREMENT COMMENT '主键自增',
`order_id` varchar(20) DEFAULT '0' COMMENT '订单号', // 唯一索引
`hotel_id` varchar(20) DEFAULT '0' COMMENT '酒店id',
`product_id` varchar(20) DEFAULT '' COMMENT '产品id',
`number` int(11) DEFAULT '1' COMMENT '数量',
`product_state` int(11) DEFAULT '0' COMMENT '产品状态', // 状态为 2 表示已支付状态
`shelf_id` varchar(20) DEFAULT '' COMMENT '货架id',
`user_id` varchar(50) DEFAULT '' COMMENT '用户id',
`client_id` varchar(50) DEFAULT '' COMMENT '客户端id',
`client_ip` varchar(50) DEFAULT '' COMMENT '客户端ip',
`ext_info` varchar(500) DEFAULT '' COMMENT '理赔种类、金额',
`change_last_time` timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `idx_change_lasttime` (`change_last_time`),
KEY `idx_createTime` (`create_time`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='产品售卖信息'
简单实现
上述需求对应的 SQL 语句为:
SELECT
shelf_id,
count(1) order_count,
IFNULL(SUM(number * IF(product_state=2, 1, 0))) pay_count
FROM
tbl_sale_product_info
WHERE
create_time BETWEEN "2024-08-08 15:53:00" AND "2024-08-15 15:53:00"
GROUP BY
shelf_id;

执行可得预期结果,但是速度慢,达到 10s 以上,因此执行 explain 分析查询计划情况,重点关注如下字段信息:
possible_keys:对应 idx_createTime,但是实际的key为空,说明计划使用idx_createTime索引,但是实际没使用索引,出现了索引失效;rows:扫描的数据行数为 700ww+,几乎是全表扫描,且 type 为 ALL;filtered:实际使用行数占总查询行数的比例,较低,有较多无效扫描。
第一次改进
针对上述情况,可能 Innodb 引擎认为全表扫描比使用索引更快,但是 SQL 语句中必须出现聚合函数、条件语句,所以我们尝试降低 where 条件的跨度值,我们将跨度调整为1重新尝试。
SELECT
shelf_id,
count(1) order_count,
IFNULL(SUM(number * IF(product_state=2, 1, 0))) pay_count
FROM
tbl_sale_product_info
WHERE
create_time BETWEEN "2024-08-08 15:53:00" AND "2024-08-09 15:53:00"
GROUP BY
shelf_id;
经过 explain 分析后得出:
key为idx_createTime,使用了索引;rows为 5w+,如果乘以7 也仅为 35w+,为全表扫描的 25% 左右,大大减少了扫描行数;filtered为 100%,说明扫描到的行全部用上了。
所以我们可以采用多线程,分成7个线程,将总时间段拆为 7 份,每个线程查询 1 天,最后合并 7 天数据,具体步骤如下:
- 从 QConfig 中获取 批次处理线程数(
batchThreadCounts)、每批次处理数量(perBatchCounts) 相关配置,结合当前截止时间endTime,将时间段按照批次处理线程数划分为多个线程; - 每个线程处理时再按照每批处理数量拆分为多个批次循环处理,处理的结果存放到 ConcurrentHashMap 中(Key=shelf_id, value=DataVo);
- 由于每个线程在合并数据到 ConcurrentHashMap 时,会执行
containsKey、put操作,为保证原子性,使用synchronized关键字保证。
// 伪代码
public Response getShelfData(Request request) {
// 1.获取配置中心配置的批次线程数、每批次处理数量
BatchConfig batchConfig = getConfigFromQConfig(KEY, BatchConfig.class);
// 2.多线程处理
ConcurrentHashMap<String, DataVo> res = new ConcurrentHashMap();
ExecutorService threadPools = Executors.newFixedThreadPool(batchConfig.getBatchThreadCounts());
Date origin = request.getOriginTime();
for (int start = 0; start < batchConfig.getBatchThreadCounts(); start++) {
Date current = origin + start*DAY;
threadPools.submit(() -> {
getDailyShelfData(current, batchConfig.getPerBatchCounts(), res);
})
}
// 3.资源释放,异常处理,日志埋点
threadPools.shutdown();
}
// 每个线程处理操作
private void getDailyShelfData(Date time, int perBatchCounts, ConcurrentHashMap<String, DataVo> res) {
for (int i = 0; i < perBatchCounts; i++) {
synchronized (res) {
if (res.containsKey(shelfId)) {
res.get(shelfId).add(dataVo);
} else {
res.put(shelfId, dataVo);
}
}
}
}
但是经过上述优化,发布到堡垒机测试,接口响应时间接近 2s,仍然较慢。
第二次改进
针对上述结果思考进一步优化空间,首先我们的 SQL 语句 where 子句使用非主键索引,涉及到回表,如果使用主键索引速度可能会更快一些。
因此我们尝试查询一天时间段内最小id值、最大id值,耗时约 0.16s,不分片查询耗时 0.55s,以上如果用单线程完成总耗时 0.81s,有第一次改进的 70%,初步判断改进有效。
操作步骤:
- 查询一周内最早下单时间、最晚下单时间,以及对应时间最小订单id、最大订单id;
- 对id 分片查询,每个分片作为一个 Task 提交到线程池执行,查询后线程安全地合并到 Map 集合。
// 伪代码
public Response getShelfData(Request request) {
// 1.获取配置中心配置的批次线程数、每批次处理数量
BatchConfig batchConfig = getConfigFromQConfig(KEY, BatchConfig.class);
int batchThreadCounts = batchConfig.getBatchThreadCounts();
int batchPerCounts = batchConfig.getPerBatchCounts();
// 2.查询一周内产品id的最小值、最大值
ExecutorService threadPools = Executors.newFixedThreadPool(batchConfig.getBatchThreadCounts());
NumberRange idRange = getIdRangeByTime(CurrentTime, CurrentTime + 7*DAY, threadPools);
// 3.id分批次查询
ConcurrentHashMap<String, DataVo> res = new ConcurrentHashMap();
for (int start = 0; idRange.minId() + batchPerCounts*start < idRange.maxId(); start++) {
int startId = idRange.minId() + batchPerCounts*start;
int endId = idRange.minId() + batchPerCounts*(start+1);
threadPools.submit(() -> {
getDailyShelfData(startId, endId, res);
})
}
// 3.资源释放,异常处理,日志埋点
threadPools.shutdown();
}
// 获取指定时间范围内id最小值、最大值
private NumberRange getIdRangeByTime(Date startTime, Date endTime, ExecutorService threadPools) {
NumberRange range = new NumberRange();
Future<Long> minIdFuture = threadPools.submit(() -> {
//....
});
Future<Long> maxIdFuture = threadPools.submit(() -> {
//....
});
range.setMinId(minIdFuture.get());
range.setMaxId(maxIdFuture.get());
return range;
}
二次优化后,发布到堡垒机测试,接口响应时间为 0.57s,比第一次提升了近 70%。第一次查询接近 1.2s,后续查询会走 query_cache。
第三次改进
分析第二次操作,每次查询都需要查库,并发量高时给数据库带来太大压力。
分析需求可知,需求中对售卖情况的统计没有很强的实时性,提供给开发人员而非客户,因此考虑引入 Redis 缓存已查询数据。
具体设计 Key-Value 对缓存结果,查询时若 Key 未过期,则查询缓存返回,否则查库并更新缓存。
假设多个服务同时调用该接口,如果 Redis 不加分布式锁,那么每个服务都会访问一次数据库,而如果使用 Redis锁+自旋,没抢到锁的线程自旋,抢到锁的查询数据库并刷新缓存,这样只会查询一次数据库,其余服务会从缓存获取最新值。
public Response getData(Date time, int tries) {
// 先从 Redis 获取数据
String list = getDataFromRedis(buildKey(time));
if (!StringUtils.isEmpty(list)) {
return list;
}
// SET NX 抢锁,这里为了避免单点故障可以使用 Redission 分布式锁
if (!TryLock(REDIS_LOCK_KEY)) {
// 加锁失败自旋
if (tries > 0) {
Thread.sleep(1000);
getData(time, tries-1);
} else {
return null;
}
}
// 抢到锁查询数据库并刷新缓存
// 第二次改进的逻辑....
}
优化后再次堡垒测试,除了懒加载查询耗时外,其余响应时间接近 0.005s。
数据库缓存一致性
缓存数据结构:
- 数据报表:每个酒店的每种套餐下单量、支付量;——————对下单量、支付量没有很高的实时性要求(懒更新);
- 类型:zset
- 内容:酒店维度划分,
- 类型:zset
- 内容:按照上述维度划分,
- 售卖风控:用户id风控、客户端id风控、ip风控;——————对风险控制/恶意刷单等场景比较敏感,对数据有很强的实时性要求;
- 类型:list(可能存在大 Key 问题)
- 内容:
方案设计:
- Canal+MQ:监听售卖信息表 binlog,利用平台 otter 方案,同步数据到 MQ;
- 设计消费者组消费 MQ 消息,解析 binlog 变更信息内容(变更表、变更列、变更前数据、变更后数据)
- 查询 redis 中酒店维度下是否存在对应套餐id 的打标记录。若结果为空,则添加一条当前时间的打标记录到 zset;
- 若存在,则跳过。
- 客户端缓存查询某个酒店套餐下单量/支付量时,判断 Key 更新时间和当前时间差值,采取不同策略:
- 新鲜度范围内:查缓存返回;
- 较新鲜:返回缓存,并异步查库刷新缓存并删除打标;
- 不新鲜:同步更新缓存并删除打标记录;
风控
风控维度:基于 uid、clientId、ip 三个维度
风控指标配置:
- 日理赔数量;
- 周理赔数量;
- 周理赔金额;
- 日理赔产品下单数量;
- 周理赔产品下单数量;
- 风控 uid/cid/ip 白名单;
风控逻辑
- 通过 canal 监听 binlog 变化。当产品销售详情表发生变化时,更新数据库,同时记录 binlog,并向 MQ 发送数据变动消息;
- 消费端监听数据变动消息,调用缓存服务对 Redis 缓存插入/更新;
- 如果是支付/理赔类操作,则分别针对 uid、clientid、ip 相关的产品信息 RedisKey 执行缓存更新操作;
- 更新完毕后调用风控服务,检测 uid、clientId、ip 维度下风险控制指标。
基于 uid 风控
- 获取本次更新产品的信息,判断 uid 是否属于白名单,如是则结束;
- 从缓存中获取当前用户对产品操作记录的集合(List 类型,uid 相关 RedisKey);
- 就理赔维度、下单维度、订单维度判断风险类型、风险指数:
- 理赔维度:日理赔数量、周理赔数量、周理赔金额;
- 下单维度:日理赔产品下单数量、周理赔产品下单数量;
- 针对上述风控结果,实现对内部平台通知、黑名单同步
- 内部平台通知:封装请求,http请求调用;
- 以
riskType + riskValue(uid)为分布式锁 RedisKey,尝试加锁,加锁失败则退出,确保数据一致性; - 加锁成功后调用黑名单同步模块完成数据更新。
基于 clientId 风控
类似于上述基于 uid 风控
基于 ip 风控
类似于上述基于 uid 风控逻辑
黑名单
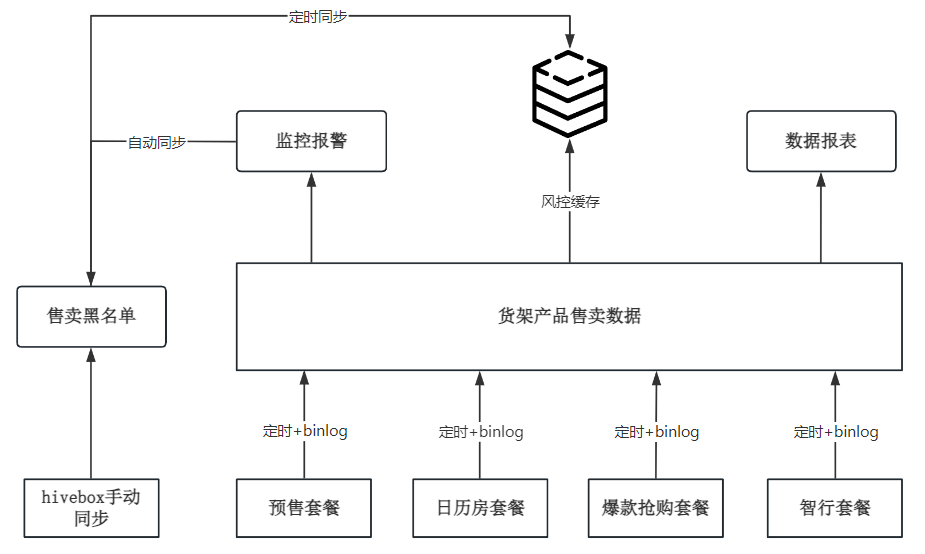
数据信息
黑名单表:
CREATE TABLE `tbl_blacklist` (
`id` bigint(20) AUTO_INCREMENT COMMENT '主键自增',
`key_name` varchar(20) DEFAULT '0' COMMENT '黑名单类型名 uid/cid/ip',
`key_type` tinyint(4) DEFAULT '0' COMMENT '类型值枚举',
`key_value` varchar(20) DEFAULT '1' COMMENT '值',
`key_json` varchar(120) DEFAULT '0' COMMENT 'json信息',
`shelf_id` varchar(20) DEFAULT '' COMMENT '货架id',
`change_last_time` timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '数据更新时间',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`effect_state` tinyint(4) DEFAULT '1' COMMENT '黑名单状态 1 有效 0 无效',
PRIMARY KEY (`id`),
KEY `idx_change_lasttime` (`change_last_time`),
KEY `idx_createTime` (`create_time`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='产品售卖信息'
黑名单服务中:每条记录都有唯一 id 对应,在逻辑上 keyType——keyValue——goods 三个字段是唯一约束关系,和唯一主键 id 对应。
黑名单同步接口
根据请求体分为是否包含唯一 id 两种方式:
- 包含唯一 id(这种方式只能更新货物列表、是否生效):
- 1.根据唯一主键 id 查库获取黑名单记录;
- 2.若存在记录,则根据 Key_type、key_value 检查待更新货物列表是否与表内已有其他记录冲突;若存在冲突则报错,否则更新相应数据条目。
- 若不包含唯一 id,则请求需要指定 key_type、key_value 字段:
- 1.根据 key_type、key_value 查库获取黑名单记录列表;
- 2.根据查询结果,判断是执行新增一条记录还是更新一条记录。
黑名单查询接口
关于分页:如果不给pageNo或者pageNo是-1,则代表全量查询。如果给了,则必须也要给pageSize,来进行分页查询。注:全量查询最多只返1000个。
关于条件:idList、keyTypeList、keyValueList均用“且”链接。如果不想限定某个字段的条件就让该字段List为NULL。对于每个List,若对应字段值在该List内则命中,也就是List内是“或”的关系。
黑名单删除接口
删除很简单
黑名单同步 Redis
- 通过定时任务平台指定任务执行的参数:批次处理数量、批次处理线程数、每个批次分片总数、分片索引;
- 先根据批次处理数量划分 batch,再对每个 batch 划分 shard,针对每个 shard 创建固定大小线程数的线程池并行执行多线程任务;
- 执行 Redis 数据更新操作时,redis-key 配置为
key_name+key_value组合,同时操作前需要通过分布式锁lock+key_name+key_value确保数据更新一致性; - 加锁成功则查询缓存黑名单数据,并判断是更新还是新增;加锁失败自旋,超过5次结束退出。
延申问题
查询时间段不固定,怎么设计 Redis 缓存结构
现有的逻辑:
- 请求时间间隔固定为 7d;
- 如果请求体指定了截止时间,则不走缓存,直接查数据库;
- 如果未指定截止时间,默认从缓存拿结果(缓存超时时间 1h);
若需要请求任意时间段:
- 查询起始时间不会很久,假设需要对 7d 以内的数据实时查询报表;
- 将时间切分为 7 天,每天对应一个 hash-key,hash-value 存储当天不同时间段的数据(比如0-6点、6-12点、12-18点、18-24点);
- 若用户查询时间范围在目标分片内/时间可拼接,直接从 Redis 取数据;否则查询 DB 获取最新数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号