03_spark_RDD算子
Transformation 转换算子
RDD 整体上分为 Value、双Value、Key-Value 三种类型。
Value 类型
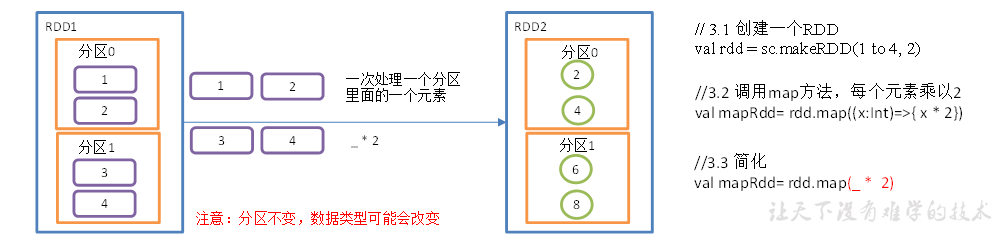
Map算子
函数签名
def map[U:ClassTag](f:T=>U):RDD[U],它通过接受一个参数,并且遍历该 RDD 中每一个数据项,依次应用函数 f 并得到新的 RDD;
object Value01_map {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
val sc = new SparkContext(conf)
// 创建RDD
val rdd:RDD[Int] = sc.makeRDD(1 to 4, 2)
// 执行 map 算子
val rdd2 = rdd.map(_ * 2)
rdd2.collect().foreach(println)
sc.stop()
}
}
mapPartitions()以分区为单位执行 Map 算子,将一个分区的数据放入迭代器中,批处理一次处理一个分区的数据。
def mapPartitionsFunc(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd:RDD[Int] = sc.makeRDD(1 to 4, 2)
val rdd1 = rdd.mapPartitions(x=>x.map(_*2))
rdd1.collect().foreach(println)
// 将RDD的一个分区作为几个集合进行结构转换,只需要保证最后一个分区输出一个集合即可
val value:RDD[Int] = rdd.mapPartitions(list => {
println("mapPartitoins调用")
list.filter(i => i%2 == 0)
})
value.collect().foreach(println)
sc.stop()
}
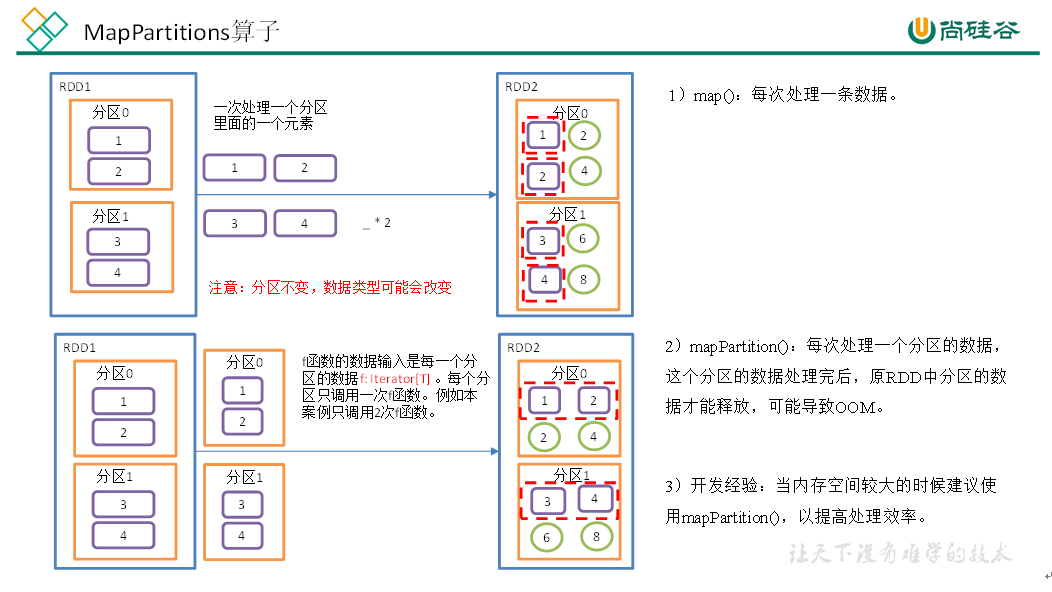
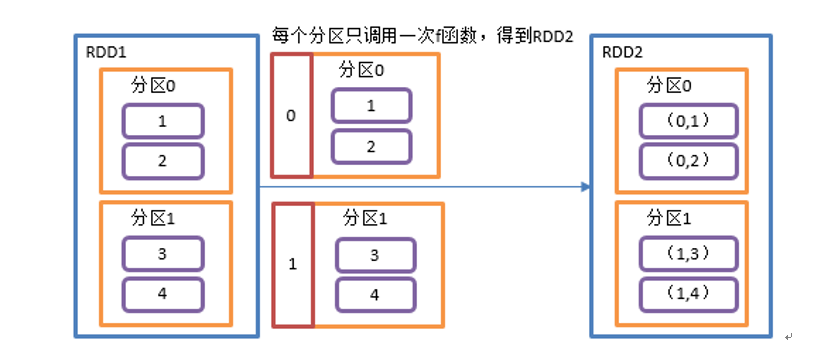
mapPartitionsWithIndex(),将分区号、分区数据作为一个元组进行处理。
def mapPartitionsWithIndexFunc(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd:RDD[Int] = sc.makeRDD(1 to 4, 2)
val rdd1 = rdd.mapPartitionsWithIndex((index, items) => {items.map(item=>{(index, item*2)})})
rdd1.collect().foreach(println)
sc.stop()
}
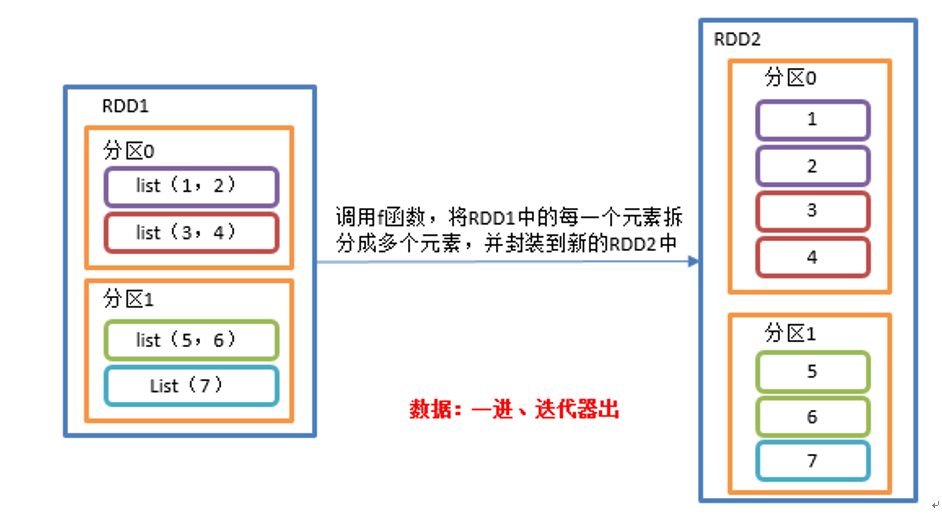
flatMap(),与 map 类似将 RDD 中每个元素通过 f 函数转换为新元素并封装到 RDD 中,区别在于 f 函数的返回值是一个集合,并将每一个该集合中的元素拆分出来放到新的 RDD中。
def flatMapTest(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val listRDD=sc.makeRDD(List(List(1,2),List(3,4),List(5,6),List(7)), 2)
listRDD.flatMap(x=>x).collect.foreach(println)
sc.stop()
}
三种 Map 方式对比:
map()每次处理分区中的一个数据;mapPartitions()每次处理一个分区的数据,并且只有当前分区数据处理完毕后才能处理下一个分区数据,所以可能导致 OOM;mapPartitionsWithIndex()处理的是分区号和数据组成的元组;
GroupBy算子
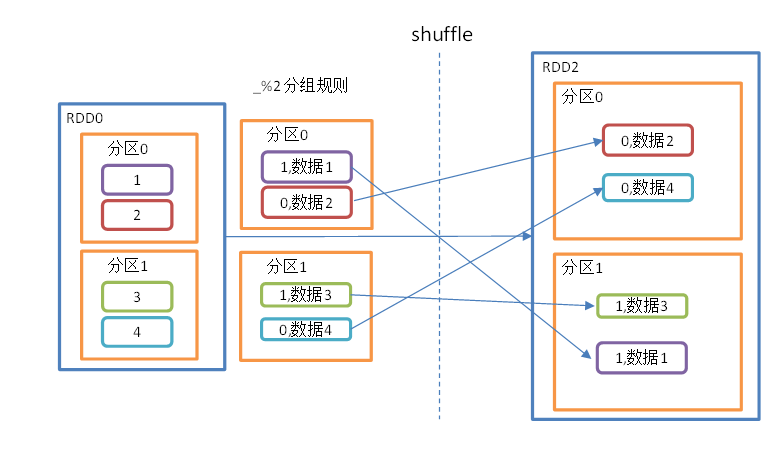
将RDD 中不同分区数据按照指定函数进行分组,然后将相同 key 的数据放入到新的分区中。
这个过程中会涉及到 shuffle,shuffle 会存盘并且改变数据分布,但是不会改变分区数量(部分分区有数据,部分没有,而每个分区对应一个 Executor,所以可能导致资源浪费)。
shuffle 后通过 GroupBy 再分区能够减少不必要的分区,减少资源浪费。
def groupByTest(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(1 to 4, 2)
rdd.groupBy(_%2).collect().foreach(println)
val rdd1 = sc.makeRDD(List("hello", "hive", "hadoop", "spark", "scala"))
rdd1.groupBy(str=>str.substring(0,1)).collect().foreach(println)
sc.stop()
}
filter/distinct 算子
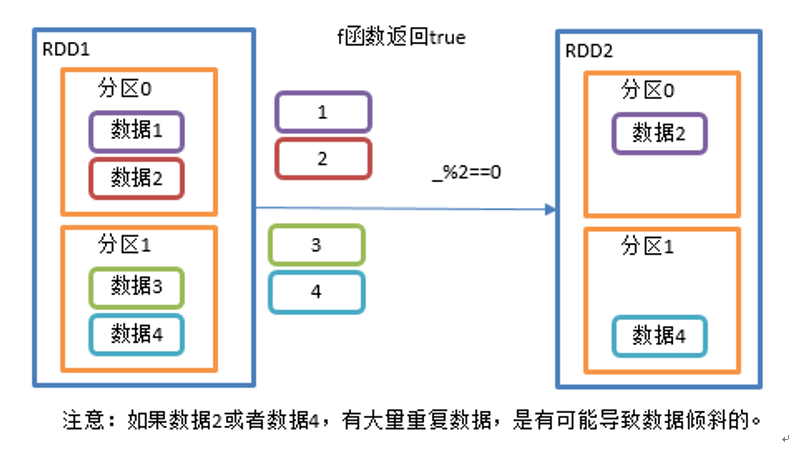
filter 算子会对每个分区的数据执行指定函数过滤,并将结果输出到新的 RDD 分区中。
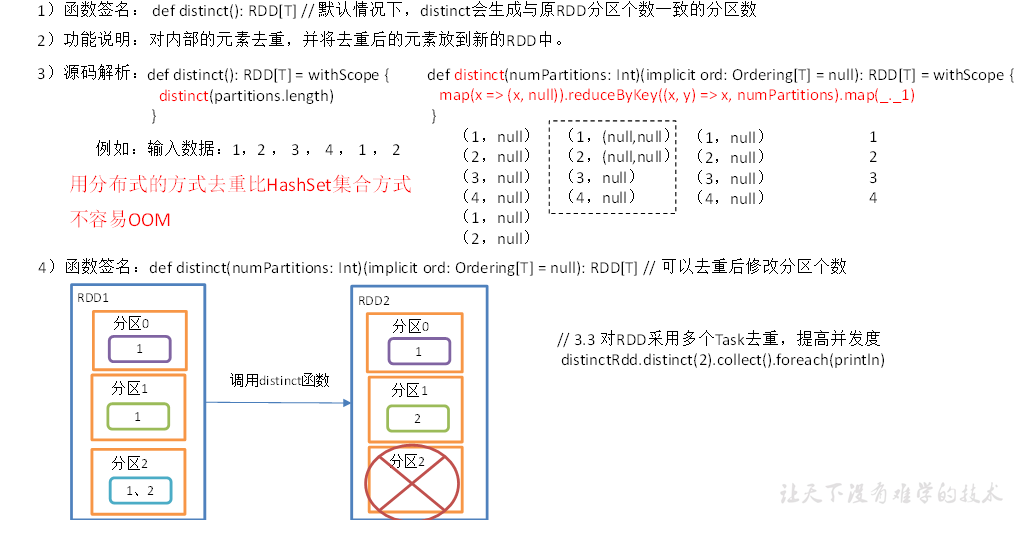
distinct 算子主要用于对内部元素的去重,是一种分布式去重方式,相比单机去重 Hash Set 效率更高,并且避免了 OOM 问题。
由于 shuffle 并没有改变分区的能力,所以 distinct 还可以额外指定去重后新的分区的个数。
def filterTest(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(1 to 4, 2)
rdd.filter(_%2==0).collect().foreach(println)
sc.stop()
}
def distinct(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(1,2,1,5,2,9,6,1))
rdd.distinct().collect().foreach(println)
rdd.distinct(2)
sc.stop()
}
filter 过滤算子:
distinct 去重算子:
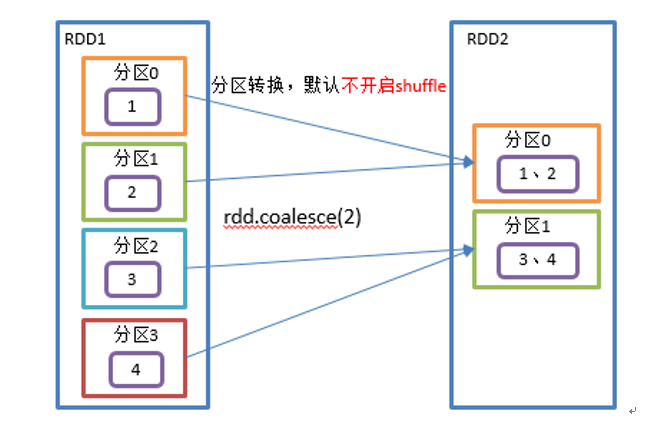
coalesce 分区合并算子
coalescs 用于大数据集过滤后,多个分区进行合并从而提高小数据集的执行效率。
coalescs 同样可以指定 shuffle 或者不 shuffle。
def coalesce(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(1 to 4, 4)
val coalesceRdd = rdd.coalesce(2)
val rdd1 = sc.makeRDD(Array(1,2,3,4,5,6), 3)
val coalesce1 = rdd1.coalesce(2)
val indexRdd = coalesce1.mapPartitionsWithIndex(
(index, datas) => {
datas.map((index, _))
}
)
indexRdd.collect().foreach(println)
println("***********************")
val indexRdd2 = rdd1.coalesce(2, true)
val indexRdd3 = indexRdd2.mapPartitionsWithIndex(
(index, datas) => {
datas.map((index, _))
}
)
indexRdd3.foreach(println)
sc.stop()
}
repartition 重新分区算子
repartition 内部实际上是执行 coalesce 操作,参数 shuffle 默认为 true,一般是对分区后的数据不满意,shuffle 重新分区。
def repartition(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array(1,2,3,4,5,6), 3)
val coalesceRdd = rdd.coalesce(2, true)
val repartRdd = coalesceRdd.repartition(2)
val indexRdd = repartRdd.mapPartitionsWithIndex((index, datas)=> {
datas.map((index, _))
})
indexRdd.collect().foreach(println)
sc.stop()
}
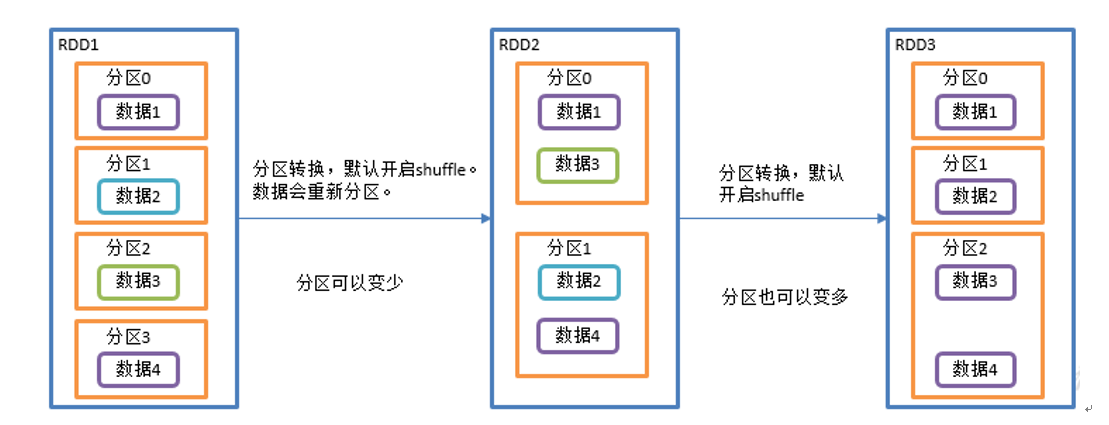
coalesce 和 repartition 的区别:
- coalesce 目的是合并分区使分区变少,可以选择是否执行 shuffle;
- repartition 底层是 coalesce 并且一定执行 shuffle;
def repartition(numPartitions: Int)(implicit ord: Ordering[T]=null): RDD[T] = withScope {
coalesce(numPartitions, shuffle=true)
}
- coalesce 一般为缩小分区,如果扩大分区不使用 shuffle 是没有意义的,repartition 扩大分区并执行 shuffle。
sortBy 排序算子
sortBy 算子用于排序数据,在排序之前可以先按照指定函数处理,然后对处理的结果排序,默认为正序;
def sortedBy(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(2,1,3,6,5))
val sortRdd = rdd.sortBy(num=> num)
sortRdd.collect().foreach(println)
val sortRdd2 = rdd.sortBy(num=>num, false)
sortRdd2.collect().foreach(println)
val strRdd = sc.makeRDD(List("1", "22", "12", "2", "3"))
strRdd.sortBy(_.toInt).collect().foreach(println)
val rdd3 = sc.makeRDD(List((2,1), (1,2), (1,1), (2,2)))
rdd3.sortBy(t=>t).collect().foreach(println)
sc.stop()
}
双 Value 类型
intersection 交集算子
intersection 交集,取两个 RDD 的交集并返回;
def value_intersection(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(1 to 4)
val rdd2 = sc.makeRDD(4 to 8)
rdd.intersection(rdd2).foreach(println)
sc.stop()
}
union 并集算子
union 取两个 RDD并集但是不去重;
def value_union(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(1 to 4)
val rdd2 = sc.makeRDD(4 to 8)
rdd.union(rdd2).foreach(println)
sc.stop()
}
substract 差集算子
def substract(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(1 to 4)
val rdd2 = sc.makeRDD(4 to 8)
rdd.subtract(rdd2).foreach(println)
sc.stop()
}
zip 拉链算子
将两个 RDD 中的数据合并,结果中 Key为第一个 RDD元素,Value为第二个 RDD元素。
注意默认两个 RDD 的分区数量以及元素数量都必须相同,否则会抛出异常。
def zip(): Unit = {
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(1 to 3, 3)
val rdd2 = sc.makeRDD(Array("a", "b", "c"), 3)
rdd.zip(rdd2).foreach(println)
val rdd3 = sc.makeRDD(Array("a", "b"), 3)
rdd.zip(rdd3).foreach(println)
val rdd4 = sc.makeRDD(Array("a", "b", "c"), 3)
rdd.zip(rdd4).collect().foreach(println)
sc.stop()
}
Key-Value 类型
partitionBy 算子
def partitionBy(partitioner: Partitioner): RDD[(K, V)]:将RDD[K,V]中的 K 按照指定的 Partitioner 分区器重新进行分区
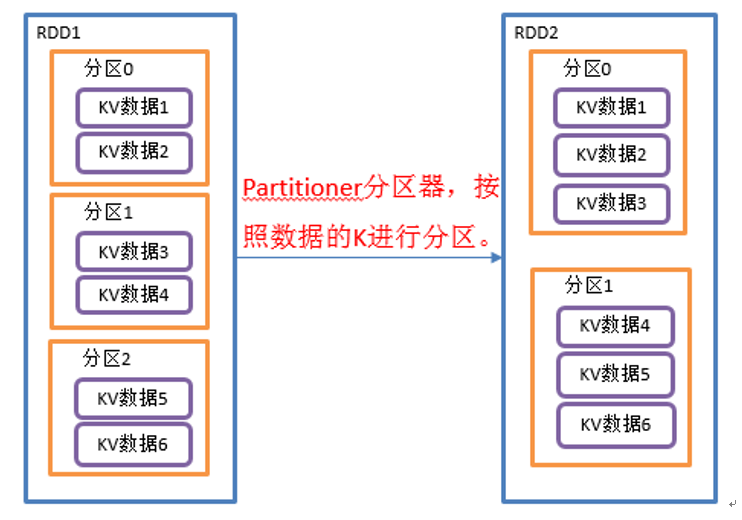
def partitionByKey_1(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd:RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")), 3)
// 重新分区
val rdd2 = rdd.partitionBy(new HashPartitioner(2))
val partRdd2 = rdd2.mapPartitionsWithIndex((index, iter) => iter.map((index, _)))
partRdd2.collect().foreach(println)
sc.stop()
}
def partitionByKey_2(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd:RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")), 3)
// 自定义分区器
val rdd2 = rdd.partitionBy(new MyPartitioner(2))
val partRdd2 = rdd2.mapPartitionsWithIndex((index, iter) => iter.map((index, _)))
partRdd2.collect().foreach(println)
sc.stop()
}
// 自定义分区器
class MyPartitioner(num:Int) extends Partitioner {
/**
* 分区数
* @return
*/
override def numPartitions: Int = num
/**
* 具体分区执行逻辑
* @param key
* @return
*/
override def getPartition(key: Any): Int = {
key match {
case s: String => 0
case i: Int => i % numPartitions
case _ => 0
}
}
}
partitionBy() 可以指定自定义分区器,分区器 Partitioner 为抽象类待实现:
abstract class Partitioner extends Serializable {
// 返回分区数
def numPartitions: Int
// 根据 Key 进行分区
def getPartition(key: Any): Int
}
Spark 已经实现的类包括 HashPartitioner,按照 Key 的哈希值进行分区,其中重新实现了 equals(xxx) 方法用于检查分区器对象是否和其他分区器实例相同。
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
groupByKey 算子
groupByKey 对每个 Key 进行分组,各个 RDD 中相同 Key 对应的 Value 合并为一个序列,但是不进行聚合操作。
def groupByKey(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a", 1),("b", 5),("b", 2)), 2)
// 合并各个 RDD 中相同 Key 的 Value
val group = rdd.groupByKey()
group.collect().foreach(println)
group.foreach {case (key, values) => println(s"key: $key, values: $values")}
// 分别计算各个分区的value之和
val sumGroupRdd = group.mapValues(values => values.sum)
sumGroupRdd.collect().foreach(println)
sc.stop()
}
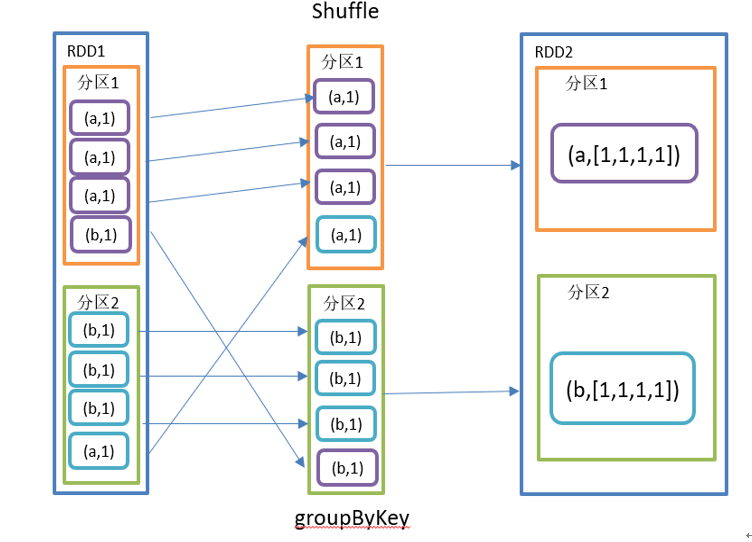
reduceByKey 算子
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
将 RDD[K,V] 中的元素按照相同的 K 对 V 进行聚合。各个分区先对自己分区进行 Combiner(预聚合),然后再执行各个分区 间的 shuffle,最周聚合每个分区的 Value。
def reduceByKey(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a", 1), ("b", 5), ("a", 5), ("b", 2)))
// 对相同 Key 的 Value 执行聚合操作
val reduceRdd = rdd.reduceByKey((v1, v2)=>v1+v2)
reduceRdd.collect().foreach(println)
sc.stop()
}
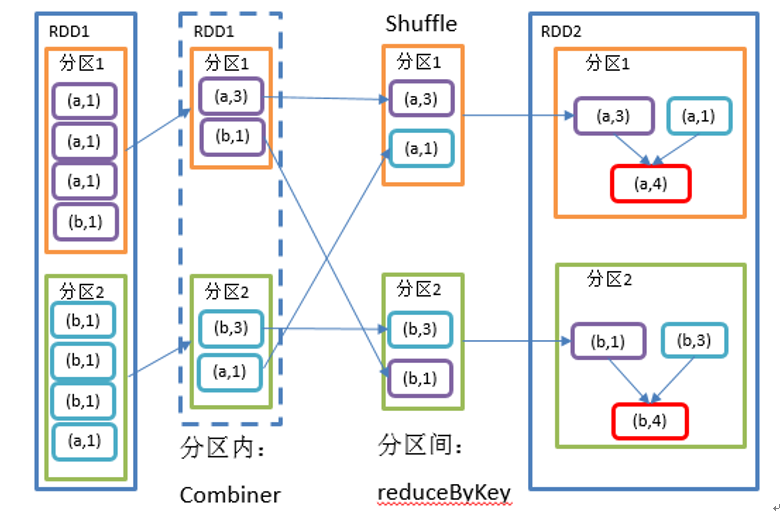
reduceByKey 和 groupByKey 区别:
reduceByKey在按照 Key 聚合前先执行单个分区的预聚合操作,最终返回结果是RDD[K,V];groupByKey按照 Key 进行分组,然后直接进行 shuffle;
aggregateByKey 算子
分区内和分区间不同逻辑的规约处理,先对每个分区数据执行
seqOp处理,然后执行combOp合并各个分区中的结果。
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {}
函数传递了 zeroValue(默认零值)、partitioner(分区器)、seqOp(在每一个分区中用初始值替代Value)、combOp(用于合并每个分区中结果的函数) 四个参数。
def aggregateByKey(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(List(("a",1),("a",3),("a",5),("b",7),("b",2),("b",4),("b",6),("a",7)), 2)
// 取每个分区 Key 相同的最大值,然后相加
rdd.aggregateByKey(0)(math.max(_, _), _ + _).collect().foreach(println)
sc.stop()
}
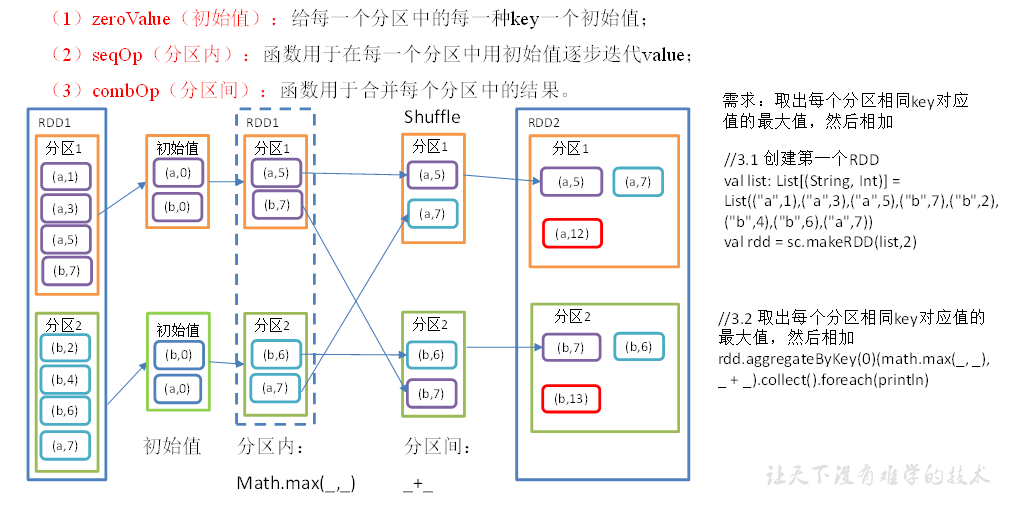
sortByKey 算子
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]
按照 Key 对 RDD[K,V] 排序,其中 Key 必须实现 Ordered 接口。
def sortByKey(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
// 按照 Key 正序排列
rdd.sortByKey(true).collect().foreach(println)
// 按照 Key 倒序排列
rdd.sortByKey(false).collect().foreach(println)
sc.stop()
}
mapValues 算子
只对 Value 执行相关操作
def mapValues(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
val mapRdd = rdd.mapValues(_+"_map")
mapRdd.collect().foreach(println)
sc.stop()
}
join 算子
类似于 SQL 中的内连接,用于在类型为 (K,V) 和 (K,W) 的RDD上调用,返回一个相同 Key 对应的所有元素对在一起的 (K,(V,W)) 的 RDD
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
def join(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array(("k1","v1"),("k1","v3"),("k4","v2"), ("k3", "v4")))
val rdd1 = sc.makeRDD(Array(("k1","v5"),("k1","v6"),("k3","v7"), ("k4", "v8"), ("k5", "v9")))
rdd.join(rdd1).collect().foreach(println)
sc.stop()
}
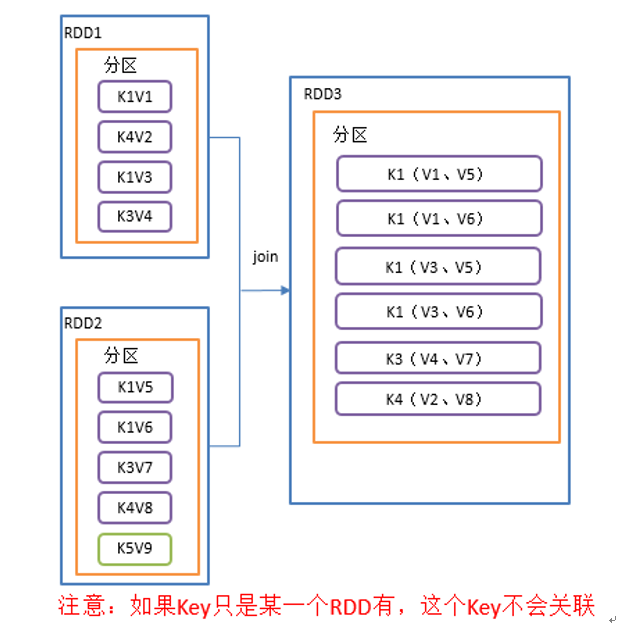
cogroup 算子
类似于 SQL 全连接,但是在同一个 RDD 中对 Key 执行聚合操作。
在类型为 (K,V) 和 (K,W) 的 RDD上调用,返回一个 (K,(Iterable, Iterable )) 类型的 RDD。
操作两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。
def cogroup(): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array(("k1","v1"), ("k1","v2"), ("k2","v3"), ("k2", "v4")))
val rdd1 = sc.makeRDD(Array(("k1","v5"),("k1","v6"),("k2","v7"),("k3", "v8")))
rdd.cogroup(rdd1).collect().foreach(println)
sc.stop()
}
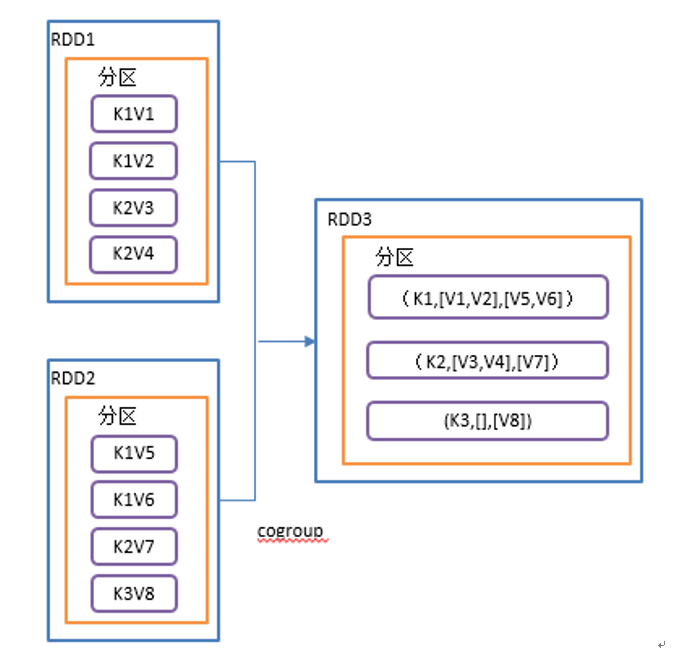
Demo实践
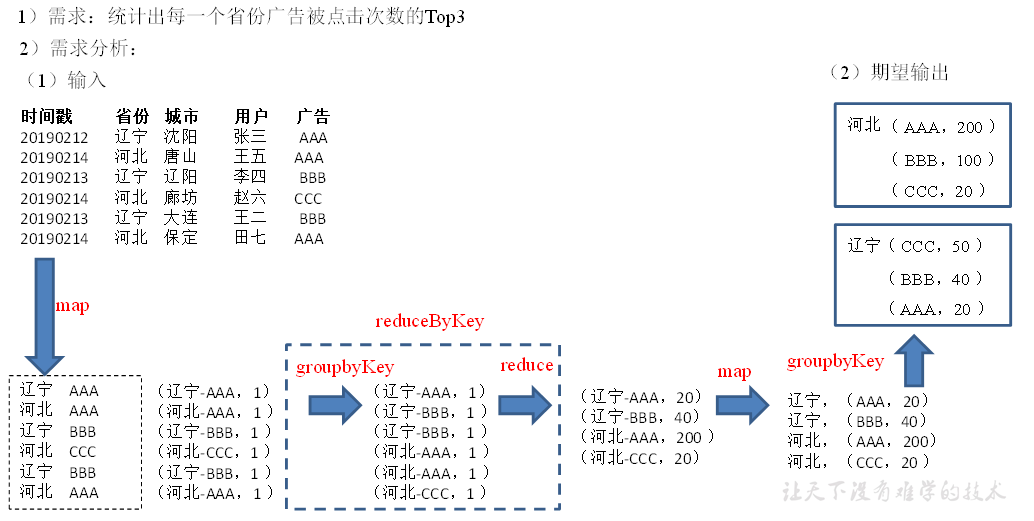
思路:
- 先对数据 map 转换处理,获取 (省份,广告) 二元组;
- 按照 key 执行
reduceByKey操作统计同一个省份下广告的次数,得到 RDD 格式为((省份,广告),次数); - 为了方便排序,需要转换RDD格式为
(省份,(广告,次数)),可以通过map()操作结合 Scala 偏函数写法实现; - 通过
mapValues()对 Values 进行处理,排序得到 TOP3 的数据。
object City_demo {
def main(args: Array[String]): Unit = {
// 初始化操作
val conf = new SparkConf().setAppName("SparkCoresTest").setMaster("local[*]")
val sc = new SparkContext(conf)
val lineRdd = sc.textFile("input/agent.log")
// 1.数据过滤
val tupleRdd = lineRdd.map(line => {
val arrays = line.split(" ")
(arrays(1), arrays(4))
})
// 2.同一个省份按照广告类型分组聚合 ((省份,广告ID),次数)
tupleRdd.collect().foreach(println)
val provinceCountRdd = tupleRdd.map((_, 1)).reduceByKey(_+_)
// provinceCountRdd.mapPartitionsWithIndex((index, iter)=> {iter.map(item=>{(index, item)})}).collect().foreach(println)
// 3.分省份对数据执行聚合
// groupBy 后省份会冗余
// val partRdd1 = provinceCountRdd.groupBy(tuple => tuple._1._1)
// partRdd1.mapPartitionsWithIndex((index, iter)=> {iter.map(item=>{(index, item)})}).collect().foreach(println)
val rdd1 = provinceCountRdd.map({
case ((province,id),count) => (province,(id,count))
})
// groupByKey 处理 ((省份,广告ID),次数) = (省份,(广告ID,次数))
val rdd2 = provinceCountRdd.map(tuple => (tuple._1._1, (tuple._1._2, tuple._2)))
// (省份,((广告ID1,次数1),(广告ID2,次数2),(广告ID3,次数3)))
val rdd3 = rdd2.groupByKey()
// rdd3.mapPartitionsWithIndex((index, iter)=> {iter.map(item=>{(index, item)})}).collect().foreach(println)
// 4.对二元组中Value排序,取TOP3
val resultRdd = rdd3.mapValues(iter => {
val list = iter.toList
list.sortWith(_._2 > _._2).take(3)
})
resultRdd.collect().foreach(println)
Thread.sleep(60000)
sc.stop()
}
}
Action 行动算子
上面介绍的转换算子都是懒加载不会立刻执行,而行动算子是触发了整个作业的执行。
collect 算子
以数组的格式返回数据集的所有元素
object action01_collect {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 收集数据到Driver
rdd.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
count 算子
返回RDD中元素的个数
object action02_count {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中元素的个数
val countResult: Long = rdd.count()
println(countResult)
//4.关闭连接
sc.stop()
}
}
first 算子
返回RDD中第一个元素
object action03_first {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中元素的个数
val firstResult: Int = rdd.first()
println(firstResult)
//4.关闭连接
sc.stop()
}
}
take、taskOrdered 算子
获取RDD(排序)的前 N 个数据
object action04_take {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
//3.2 返回RDD中前2个元素
val takeResult: Array[Int] = rdd.take(2)
println(takeResult.mkString(","))
//4.关闭连接
sc.stop()
}
}
// 获取排序后的前N个元素
object action05_takeOrdered{
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
//3.2 返回RDD中排完序后的前两个元素
val result: Array[Int] = rdd.takeOrdered(2)
println(result.mkString(","))
//4.关闭连接
sc.stop()
}
}
countByKey 算子
统计每种Key的出现次数
object action06_countByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))
//3.2 统计每种key的个数
val result: collection.Map[Int, Long] = rdd.countByKey()
println(result)
//4.关闭连接
sc.stop()
}
}
save 算子
- saveAsTextFile:将RDD数据集的元素以 textfile 格式保存到 HDFS 等文件系统;
- saveAsSequenceFile(path):将数据集中的元素以
Hadoop Sequencefile格式保存到指定目录下;注意只有 KV 类型 RDD 有该操作,单值没有; - saveAsObjectFile(path):序列化数据集为对象然后保存到文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号