02_spark实操
运行案例程序
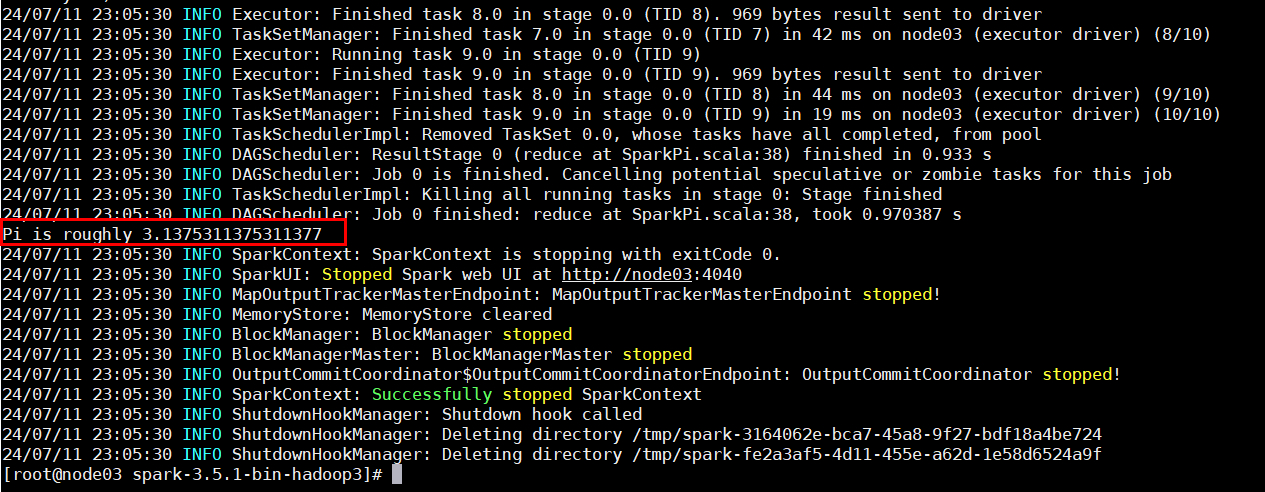
计算圆周率——Local
Local 模式下,解压安装 spark 后,运行 example 包下的案例程序:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ./examples/jars/spark-examples_2.12-3.5.1.jar 10
--class表示要执行程序的主类;--master lcoal[2]:本地模式,启动 k 个核心来计算;
查看 SparkSpi.scala 源代码:
package org.apache.spark.examples
import scala.math.random
import org.apache.spark.sql.SparkSession
/** Computes an approximation to pi */
object SparkPi {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}
实现 WordCount——Local
同理,我们可以自己用 Scala 实现简单的词频统计程序并且运行在 Spark 上。
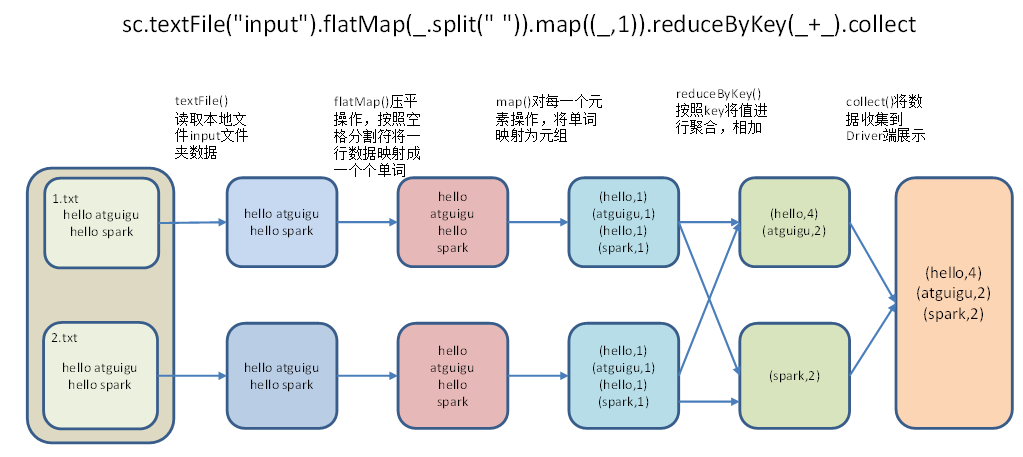
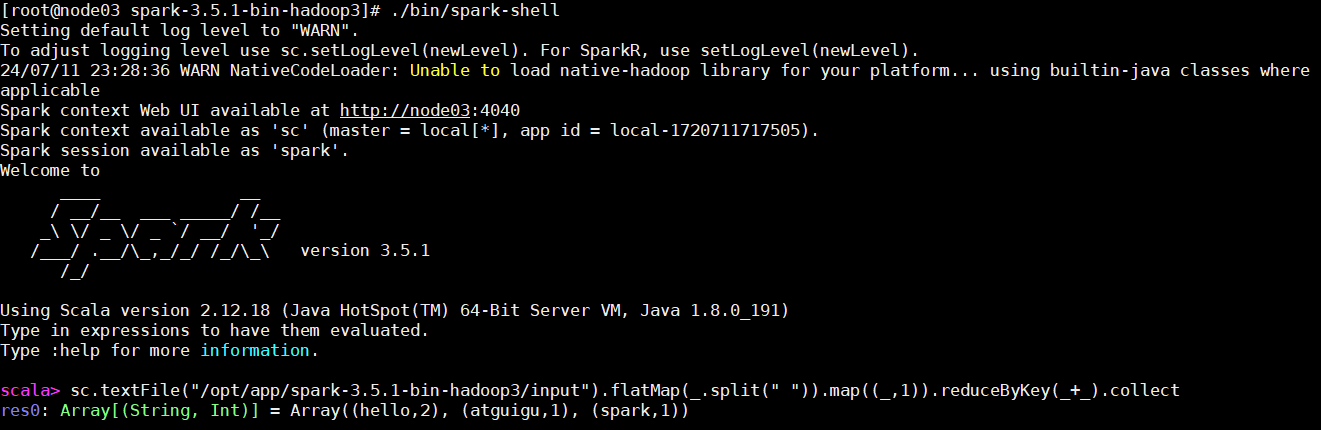
按如下步骤操作:
- 事先准备好词频文件
1.txt、2.txt; - 启动 spark 内置命令行解析器
spark-shell,编写 Scala 语句并执行。
Standalone 模式
Standalone 环境搭建
Standalone 模式不依赖于其他框架(Yarn、Mesos),完全由 Spark Master、Spark Worker 构建的高可用集群。
如何搭建 Standalone 模式:
- 进入 conf 目录,修改
slaves.template文件,为其中添加 worker 节点(节点名为对应主机名); - 修改
spark-env.sh文件,为其配置 Spark 主节点主机名和端口:
SPARK_MASTER_HOST=xxx
SPARK_MASTER_PORT=7077
- 分发 Spark 包到其他 Worker 节点上:
xsync spark.xxxx; - 启动集群:
sbin/start-all.sh;
standalone 模式下运行示例程序,注意 --master xxx 需要定义 主机IP+Port、--executor-memory Executor使用内存、--total-executor-cores CPU核数 需要指定额外参数。
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.5.1.jar \
Standalone 高可用
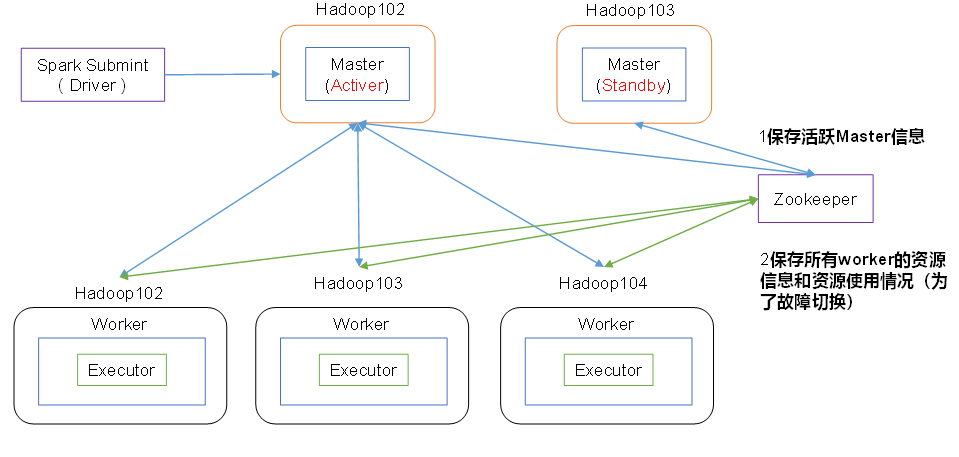
如何配置高可用:
- 安装 Zookeeper;
- 配置
spark-env.sh:
#注释掉如下内容:
#SPARK_MASTER_HOST=hadoop102
#SPARK_MASTER_PORT=7077
#添加上如下内容。配置由Zookeeper管理Master,在Zookeeper节点中自动创建/spark目录,用于管理:
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop102,hadoop103,hadoop104
-Dspark.deploy.zookeeper.dir=/spark"
#添加如下代码
#Zookeeper3.5的AdminServer默认端口是8080,和Spark的WebUI冲突
export SPARK_MASTER_WEBUI_PORT=8989
- 分发配置文件:
xsync spark-env.sh; - 分别启动主节点和工作节点;
- 上传数据文件到 hadoop 集群目录:
hadoop fs -put /xxx/input /input; - Spark 以集群方式启动计算任务:
bin/spark-shell \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2g \
--total-executor-cores 2
Standalone 运行原理
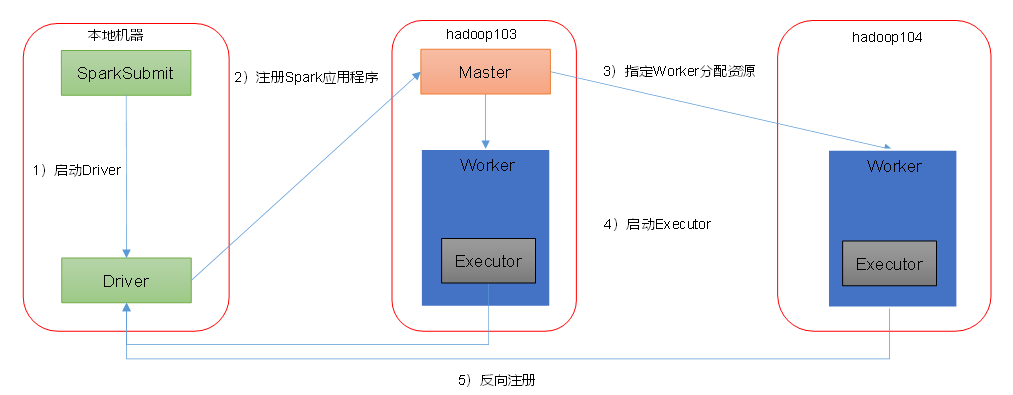
Spark 有 standalone-client、stanalone-cluster 两种模式,区别在于 Driver 程序的运行节点。
- 客户端模式,其中
--deploy-mode client表示运行在本地客户端:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
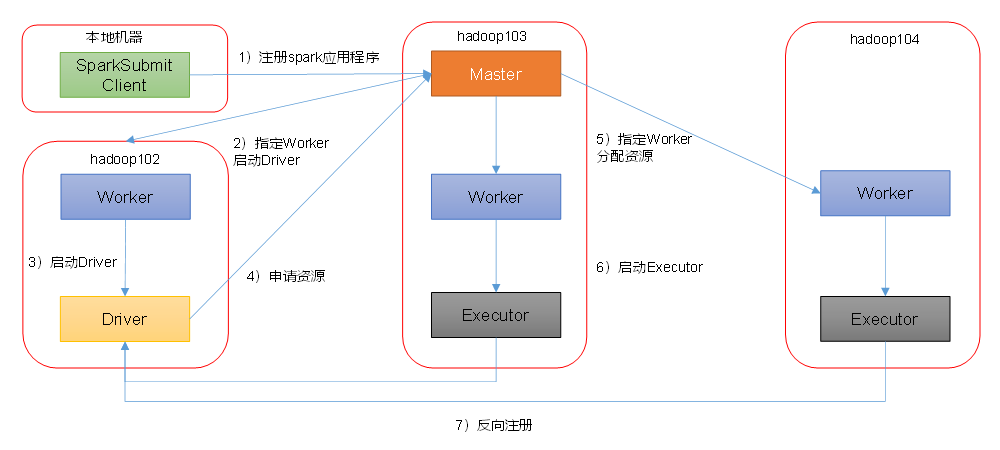
- 集群模式,其中
--deploy-mode cluster表示运行在集群:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
Yarn 模式
Spark 客户端直连 Yarn,不需要额外构建 Spark 集群。
Yarn 模式配置过程
- 修改 hadoop 配置文件
hadooop/yarn-site.xml:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 分发配置文件:
xsync hadoop/yarn-site.xml; - 修改
conf/spark-env.sh,添加YARN_CONF_DIR:
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
- 启动 HDFS、YARN 集群:
sbin/start-dfs.sh、sbin/start-yarn.sh; - 执行示例程序,其中
--master yarn指定了运行模式:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号