


如何将嵌套json转为DataFrame
前言:在使用请求返回的json数据中,经常会遇到嵌套的形式,如果想将数据保存到数据库有两种方式,要么直接保存为json格式,要么对数据进行扁平化处理后存储。前者虽然简单直接,但是会对后期数据使用或分析造成不便,每次都需要写sql去处理json数据;对于后者,在后期使用数据时就会方便很多。下面主要介绍第二种方法。
一、案例数据
{
"order": {
"order_id": 1001,
"customer": {"name": "Alice", "phone": "13800138000"},
"items": [
{"id": 1, "name": "商品A", "price": 99},
{"id": 2, "name": "商品B", "price": 199}
],
'msg': '成功',
'code':200
}
}
二、处理
2.1 直接使用pd.DataFrame()进行操作
import pandas as pd
data = {
"order": {
"order_id": 1001,
"customer": {"name": "Alice", "phone": "13800138000"},
"items": [
{"id": 1, "name": "商品A", "price": 99},
{"id": 2, "name": "商品B", "price": 199}
],
'msg': '成功',
'code':200
}
}
print(pd.DataFrame(data))
结果:
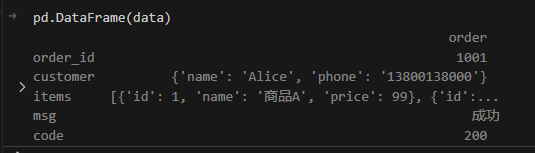
这个结果中只包含order列,意味着我们后期使用数据时还是很不方便,显然不是我们想要的效果。
2.2 使用pd.json_normalize()处理
import pandas as pd
data = {
"order": {
"order_id": 1001,
"customer": {"name": "Alice", "phone": "13800138000"},
"items": [
{"id": 1, "name": "商品A", "price": 99},
{"id": 2, "name": "商品B", "price": 199}
],
'msg': '成功',
'code':200
}
}
df = pd.json_normalize(data=data['order'])
结果:

这个结果中,pandas将data中的第一层的key当作列索引,相应的value当作值,仔细观察会发现最后两列"customer.name"和"customer.phone"被拆分为两列,但是"items"并未被拆分。如果想将items也拆开应该怎么办?
df = pd.json_normalize(
data=data["order"],
record_path="items",
meta=[
"order_id",
["customer", "name"],
["customer", "phone"],
],
record_prefix="problem_",
sep="_",
)
结果:

参数解释:
data:要处理的json对象
record_path:指定要展开的嵌套列表字段
meta:保留的外层字段(支持点路径或列表路径)
record_prefix:为展开的字段添加前缀(避免冲突)
meta_prefix:为保留的字段添加前缀(避免冲突)
sep:嵌套字段的分隔符(默认 .)
error:“ignore”: 如果meta中列出的键并非总是存在,将忽略 KeyError。“raise”: 如果meta中列出的键并非总是存在,则会引发 KeyError。
注:如果value直接是字典,不指定record_path时会自动将字典拆开,并默认以.分隔(可指定dep参数自定义);如果是列表需要指定record_path
以上可参考官方文档pandas.json_normalize


 浙公网安备 33010602011771号
浙公网安备 33010602011771号