寒假第二次作业
寒假第二次作业
| 这个作业属于哪个课程 | 2021春软件工程实践 -W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业(2/2) |
| 这个作业的目标 | 阅读《构建之法》并提问 WordCount编程 |
| 其他参考文献 | 简书/博客园 |
目录:
-1. Github项目地址
-2. PSP表格
-3. 解题思路描述
-4. 代码规范制定链接
-5. 设计与实现过程
-6. 性能改进
-7. 单元测试
-8. 异常处理说明
-9. 心路历程与收获
一、 阅读《构建之法》
我看了这一段文字(MVP具体的做法是:把产品最核心的功能用最小的成本实现出来,然后快速征求用户的意见,(VIP服务的例子)……但它更强调更早获得用户反馈,为此可以在产品完成之前就发布。),有这个问题(为了征求用户意见,所给出的核心功能是一种假设(假设用户会使用)吗?假设和实际用户使用如果存在很多差别怎么办?)。根据我的实践,我得到这些经验(以选择不同颜色的衣服为例,“我”在有“被测试者”和真正的购买者两种身份时可能会做出不同的选择)。 但是我还是不太懂,我的困惑是(如何保证参与测试的用户所做出的的选择(程序员得到的假设)跟实际相差不大呢?)。
我看了这一段文字(4.5.3结对编程中,编码不再是私人的工作,而是一种公开的“表演”。程序员的代码、工作方式、技术水平都变得公开和透明。),有这个问题(虽然结对编程存在开发者之间可能就某一问题发生分歧,产生矛盾,造成不必要的内耗等缺点,但就效率来说依旧是一种高效的工作方式。那碰到沟通不合、不喜欢公开工作方式和技术水平的合作伙伴,选择什么样的方式会比较好呢?)。我查了资料,有这些说法(尽量在开始合作前先了解对方,并尽快确立项目的方向。),根据我的实践,我得到这些经验(如果遇到沟通不顺,双方可以先完成自己的部分,并尝试换位思考,有时候是不是自己太过于把东西强加给对方?)。但是我还是不太懂,我的困惑是(在双方的沟通中,如果是工作以外的内容的交流导致合作不顺,该怎么办呢?)。
我看了这一段文字( 敏捷对团队的要求很简单:自主管理、自我组织、多功能型,但这很难做的。),有这个问题(敏捷对团队的要求前两点皆为“自主”,若是有一个团队同时具备老手和新手,每个人能力不尽相同,此时应该用木桶原理去评判这个团队吗?)。我查了资料,有这些说法(任何一个组织,可能面临的一个共同问题,即构成组织的各个部分往往是优劣不齐的,而劣势部分往往决定整个组织的水平。),根据我的实践,我得到这些经验(如果团队中有一人水平与其他成员相差较大,整个团队完成工作的进度会被迫延长,因为要花许多的时间去帮助/等ta 完成他的部分)。 但是我还是不太懂,我的困惑是(如果团队中确实存在这样的“短板”,该怎么办呢?)。
我看了这一段文字( 软件开发不可能一次满足所有利益相关者的要求,但是我们一定要让相关角色在这个阶段有机会提出他们的需求和意见。),有这个问题(当项目的需求与软件的利益相对立的时候,团队该如何做选择呢?)。我查了资料,有这些说法(关于广告主的需求和利益:广告主的需求,根源在于宣传,无论是宣传产品,亦或是企业形象、服务;而广告主的利益,则在于其投入产出的比例及相应的渠道选择。),根据我的实践,我得到这些经验(在我使用一些软件的时候,并不想看跳出来的广告,这些广告会影响我对这个软件的使用感受)。但是我还是不太懂,我的困惑是(广告是一部分软件的收入来源,遇到这样广告主的利益与用户的需求产生矛盾的情况,软件团队该如何做选择呢?)。
我看了这一段文字( 在“现代软件工程”课程上,许多同学也提出了不少宏大的创新想法,但是到了课程结束时,什么也没做成,只剩下一个空的构想。 ),有这个问题(如何判断自己的想法是可行的呢?如何找到创新的方向呢? )。根据我的实践,我得到这些经验(在算法课程上,有时候会有和课本上不一样的想法,但是实际操作的时候经常发现这些想法行不通/方法不正确/计算机实现很麻烦 )。
但是我还是不太懂,我的困惑是(怎么能及时判断自己的想法是不是现实可行的呢? )。
二、WordCount编程
1、Github项目地址
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 25 |
| • Estimate | • 估计这个任务需要多少时间 | 15 | 25 |
| Development | 开发 | 440 | 491 |
| • Analysis | • 需求分析 (包括学习新技术) | 50 | 60 |
| • Design Spec | • 生成设计文档 | 30 | 33 |
| • Design Review | • 设计复审 | 10 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 18 |
| • Design | • 具体设计 | 40 | 30 |
| • Coding | • 具体编码 | 180 | 180 |
| • Code Review | • 代码复审 | 20 | 60 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 90 | 100 |
| Reporting | 报告 | 67 | 70 |
| • Test Repor | • 测试报告 | 45 | 40 |
| • Size Measurement | • 计算工作量 | 12 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 522 | 586 |
3、解题思路描述
多次阅读作业要求后,我分析出程序主要要完成的功能:
- 读取输入的文件
- 统计文件的行数
- 统计文件的字符总数
- 统计文件有效单词数
- 统计文件中出现频率最多的10个及以内的单词
- 将以上结果写入新的文件
- 从主函数的参数中获取输入输出文件的路径
于是我从1.6.内容开始,使用Fle、Filewriter完成对文件的读写。之后再次分析2、3、4、5,选择用Bufferreader的read()和readLine()方法对文件将进行读取。
为了存储单词以及单词出现的频率,我选用HashMap进行存储,对于排序,我在网上找到了使用TreeMap进行排序和利用Stream Collectors API进行排序的方法。
4、代码规范制定链接
5、设计与实现过程
1. 主要函数及类
WordCount:主函数
FileIO类:处理输入的文件和将内容写进输出的文件
DoCount类:处理文件,统计文件行数、统计文件字符数等
2. 主要功能的实现
//处理输入文件
public static String readFile(String file_path) throws IOException {……}
//将行数、字符数、单词数内容写进输出的文件
public static boolean writeFile(String file_path,String out_word) throws IOException{……}
//将其他内容写进输出文件
public static boolean writeFile(String file_path, Map<String, Integer>word_freq)throws IOException {……}
//统计行数
public static int countLine(String path) throws IOException{……}
//统计文件的字符数
public static Map<String, Integer> countCharacters (String path) throws IOException {……}
//统计单词
public static int wordNum(String path,String word_str,HashMap<String, Integer> word_freq)throws IOException{……}
//排序
public static Map<String, Integer> sortWords(HashMap<String, Integer>word_freq) {……}
3、函数关系
WordCount类对命令中输入的参数进行判断,若符合条件,将input文件交给FileIO处理,若符合要求则WordCount安排DoCount类的三个方法完成统计行数、字符数、单词数等功能,最终将结果返回给WordCount,WordCount再将内容交给FileIO把结果写入output文件。
4、主要代码
计算行数
while((string = bReader.readLine())!=null)
{
line++;
}
统计文件的单词总数:先将读到的内容全部转为小写再按空格分割,然后判断单词是否符合规则
while((string = bReader.readLine())!=null)
{
String[] str1 = string.toLowerCase().split("\\s+");// 按空格分割
array.add(str1);
}
Pattern p = Pattern.compile(rule);
Iterator iterator = array.iterator();
while (iterator.hasNext()) {
String[] s = (String[])iterator.next();
for(int y = 0;y<=s.length-1;y++) {
Matcher m = p.matcher(s[y]);
if(m.matches()) {
total++;
}
}
将符合规则的单词放入hashmap中比统计出现的频数
if(word_freq.get(s[y]) == null) {
word_freq.put(s[y], 1);
}
else {
int old_value = word_freq.get(s[y]);
old_value++;
word_freq.replace(s[y], old_value);
}
利用Stream Collectors API进行排序
Map<String,Integer>sort_mapMap=word_freq.entrySet()
.stream()
.sorted(Collections
.reverseOrder(……))
.collect(Collectors
.toMap(Map.Entry::getKey,
Map.Entry::getValue,(e1,e2)->e1,LinkedHashMap::new));
自定义排序方式,及先对单词出现的频率排序,若频率相同则根据字典排序。
new Comparator<Entry<String, Integer>>(){
@Override
public int compare(Map.Entry<String,Integer> o1, Map.Entry<String,Integer> o2) {
if (o1.getValue()<o2.getValue()) {
return -1;
}else if(o1.getValue() > o2.getValue()) {
return 1;
}else {
String a = o1.getKey();
String b = o2.getKey();
if(strcmp(a,b) > 0){
return -1;
}else if(strcmp(b, a) < 0) {
return 1;
}else {
return 0;
}
}
}
参照c当中的strcmp,在java中写了strcmp方法,对将字符串转为字符数组然后进行扫描,根据字典规则排序。
private int strcmp(String a, String b) {
char a_char[] = a.toCharArray();
char b_char[] = b.toCharArray();
int flag = 0;
int n = a_char.length;
if (a_char.length > b_char.length) {
n = b_char.length;
}
for (int i = 0; i < n; i++) {
if(a_char[i] == b_char[i]) {
continue;
}else if (a_char[i] < b_char[i]) {
flag = -1;
break;
}else {
flag = 1;
break;
}
}
return flag;
}
5、流程图
在WordCount中使用try-catch检测三个函数的执行,若发生错误,立即发送error内容并停止程序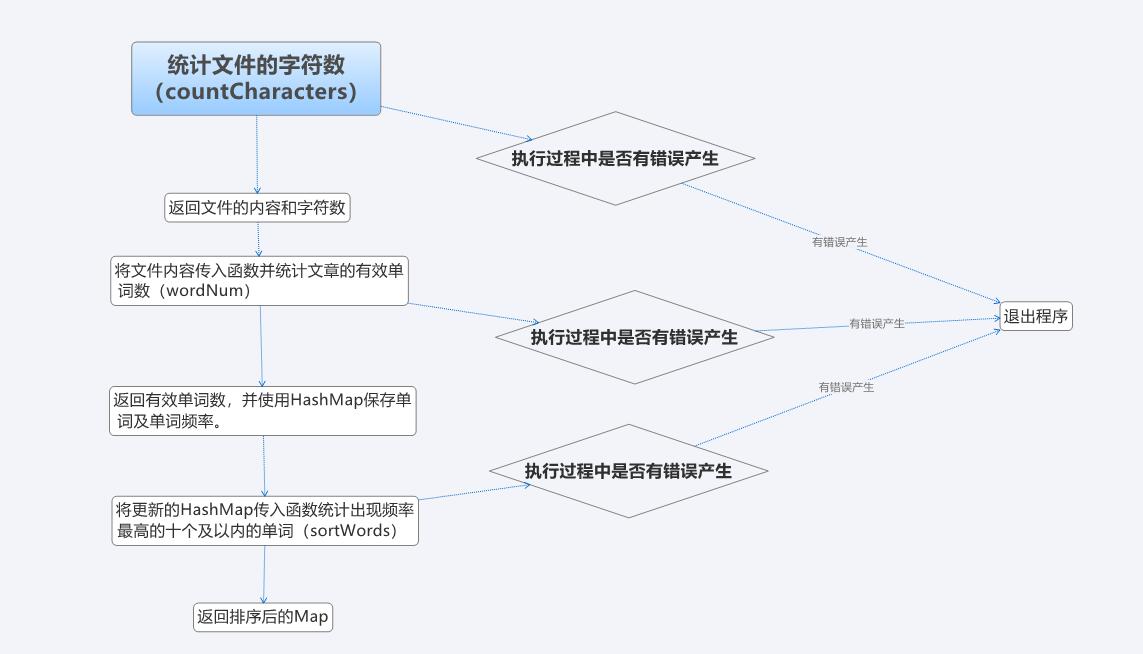
6、性能改进
改进前:
HashMap取得了关键字(key)后再取得关键值(value)
Set keys = word_freq.keySet();
int count = 0;
for(Object key:keys) {
writer.write("\n");
writer.write(key+":"+word_freq.get(key));
if(++count == 10)break;
}
改进后:
因为写入输出文件的时候是需要Map中存储的所有内容,所以使用Map.Entry可以直接得到所有内容,比上面的方法更加高效。
Set<Map.Entry<String, Integer>> mSet = word_freq.entrySet();
for(Map.Entry<String, Integer> entry :mSet) {
writer.write("\n");
writer.write(entry.getKey()+":"+entry.getValue());
if(++count == 10)break;
}
7、单元测试
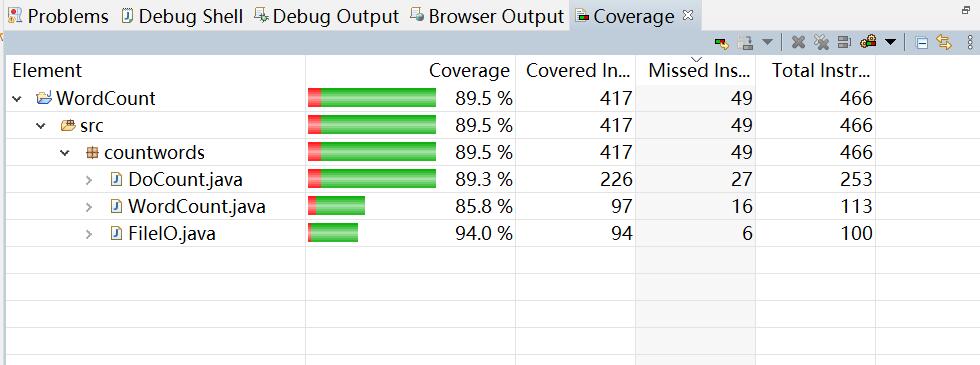
1、覆盖率
2、运行结果展示
结果展示:输出的单词统一为小写格式。- 统计文件的字符数
- 统计文件的单词总数
- 统计文件的有效行数
- 统计文件中各单词的出现次数
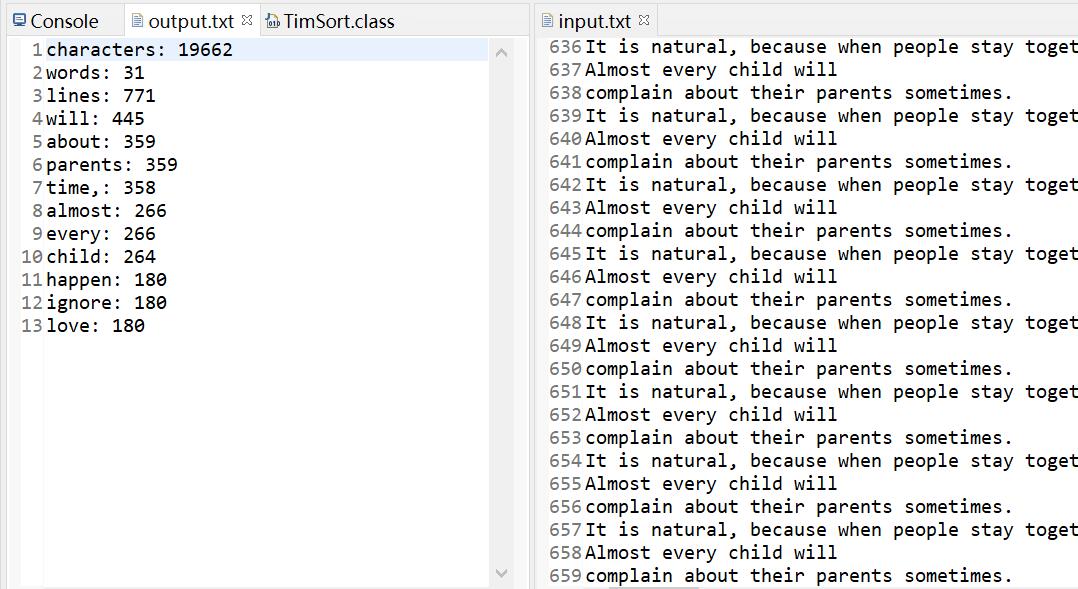
行数统计:任何包含非空白字符的行,都需要统计。
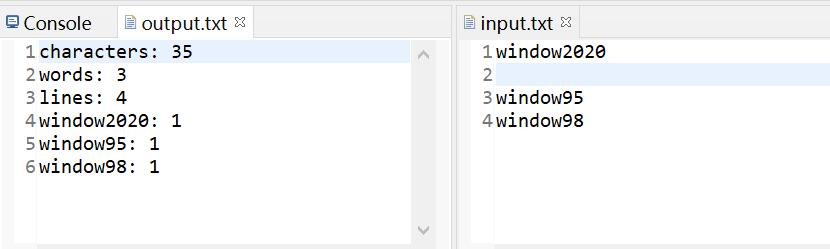
单词判断:至少以4个英文字母开头,跟上字母数字符号
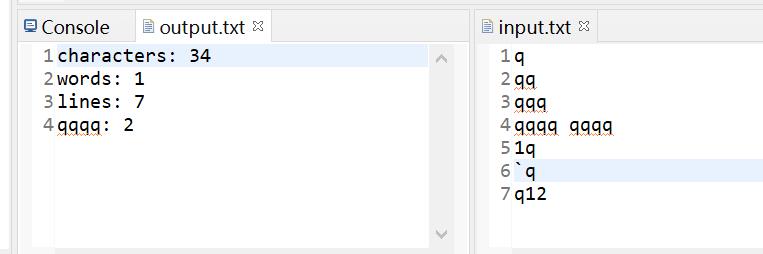
统计单词:不区分大小写
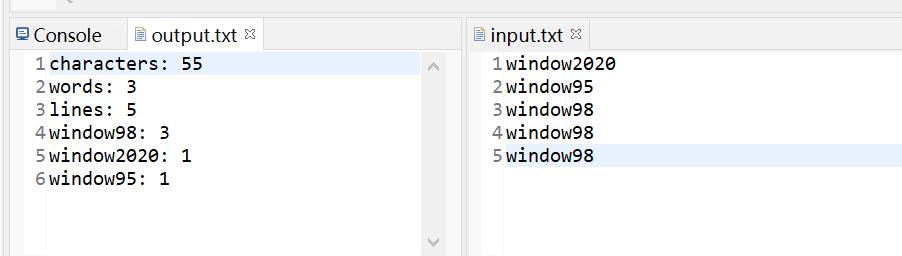
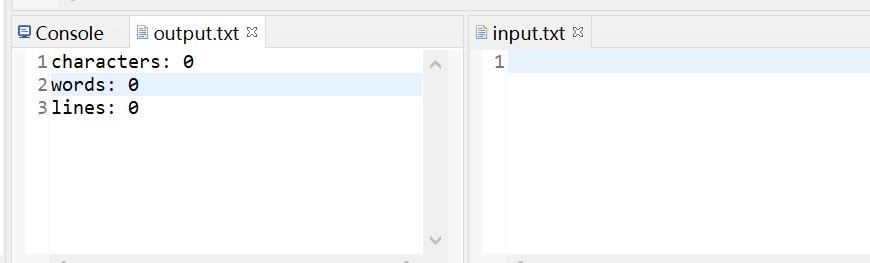
内容为空时:
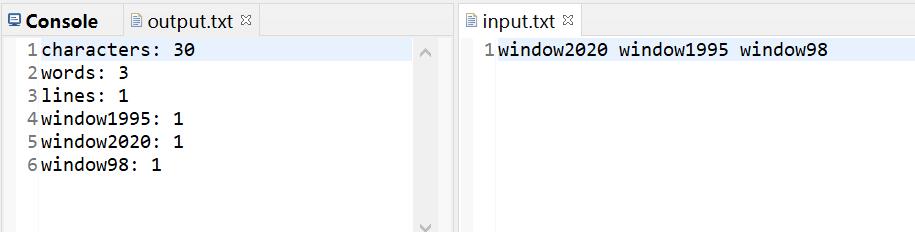
排序条件:频率相同的单词,优先输出字典序靠前的单词。
3、单元测试
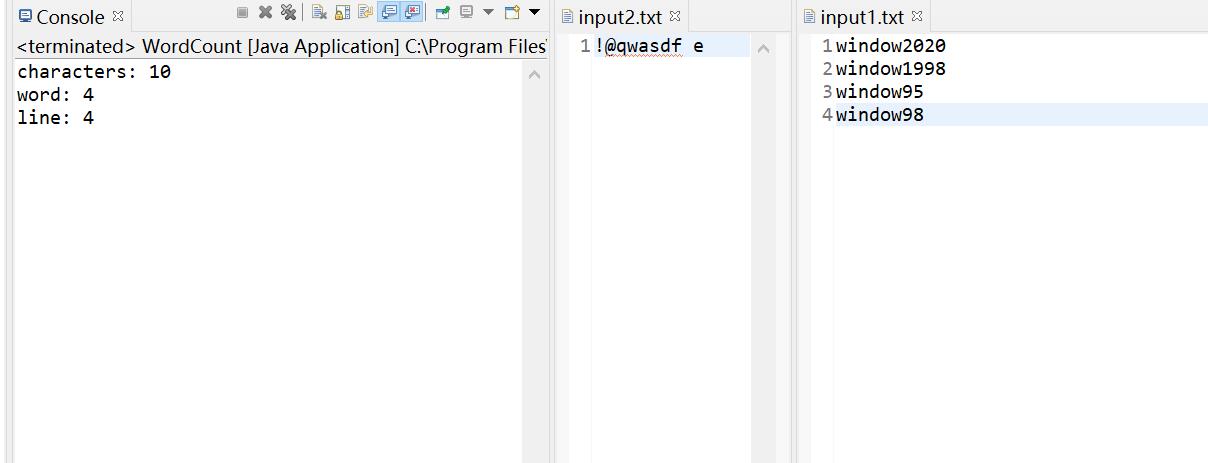
测试统计行数 public static void countLineTest() throws IOException{
String path = "input1.txt";
int line = 0;
String file_path = FileIO.readFile(path);
line = DoCount.countLine(file_path);
assert line == 4;
System.out.print("\nline"+":"+line);
}
测试统计字符数
public static void countCharactersTest() throws IOException{
String path = "input2.txt";
……
FileIO.readFile(path);
word_map = DoCount.countCharacters(file_path);
Set<String> keys = word_map.keySet();
for(Object key:keys) {
result = word_map.get(key);
}
assert result == 10;
System.out.print("characters"+":"+result);
}
测试统计单词数
public static void countWordsTest() throws IOException{
String path = "input1.txt";
FileIO.readFile(path);
int word = 0;
word_map = DoCount.countCharacters(file_path);
……
word = DoCount.wordNum(file_path,word_str,word_freq);
assert word == 4;
System.out.print("\nword"+":"+word);
}
测试结果
8、异常处理说明
在统计字符数、单词数、行数,统计词频时,若出现错误,则终止程序
try { ……
} catch (Exception e) {
System.out.print("error1");
return;
// TODO: handle exception
}
若输入的参数不是文件或者不存在
System.out.print("文件不存在或类型错误!");
return;
9、心路历程与收获
1、学习了Streams排序的方法。
2、复习了正则表达式
3、复习了Bufferreader的使用
4、学习了使用psp表格估计自己完成小任务的时间,虽然在这次完成作业的初期中没有很好地跟着流程走,但是在中期通过再次阅读《构建之法》更了解了PSP表格的作用,使得我有了明确的“将大任务细化,通过完成小任务,不断积累最终完成大任务”的想法,我还带着这样的思想运用到以后的课程学习中。
5、在性能改进方面,当时并不是很有头绪,在实际操作过程中,优化得并不是特别好,总是想着完成功能就可以了。因此,接下来要注重这方面的学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号