【vLLM】使用vLLM部署Qwen3-VL-30B-A3B-Instruct
- 环境与设备配置:H20*8(96G)
MODEL_ID=Qwen/Qwen3-VL-30B-A3B-Instruct
MODEL_NAME=Qwen3-VL-30B-A3B-Instruct
python3 -m vllm.entrypoints.openai.api_server \
--model $MODEL_ID \
--served-model-name $MODEL_NAME \
--tensor-parallel-size 8 \
--mm-encoder-tp-mode data \
--limit-mm-per-prompt.video 0 \
--mm-processor-cache-type shm \
--enable-expert-parallel \
--host 0.0.0.0 \
--port 22002 \
--dtype bfloat16 \
--gpu-memory-utilization 0.75 \
--quantization fp8 \
--distributed-executor-backend mp
请求推理
import time
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
#base_url="http://127.0.0.1:22002/v1",
base_url="http://10.0.128.211:22002/v1",
timeout=3600
)
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://ofasys-multimodal-wlcb-3-toshanghai.oss-accelerate.aliyuncs.com/wpf272043/keepme/image/receipt.png"
}
},
{
"type": "text",
"text": "Describe the image."
}
]
}
]
start = time.time()
response = client.chat.completions.create(
#model="Qwen3-VL-235B-A22B-Thinking",
#model="Qwen3-30B-A3B-Instruct-2507",
#model="/mnt/data/projects/GLM_4.5v/ckpts/Qwen/Qwen3-30B-A3B-Instruct-2507",
model="Qwen3-VL-30B-A3B-Instruct",
messages=messages,
max_tokens=2048
)
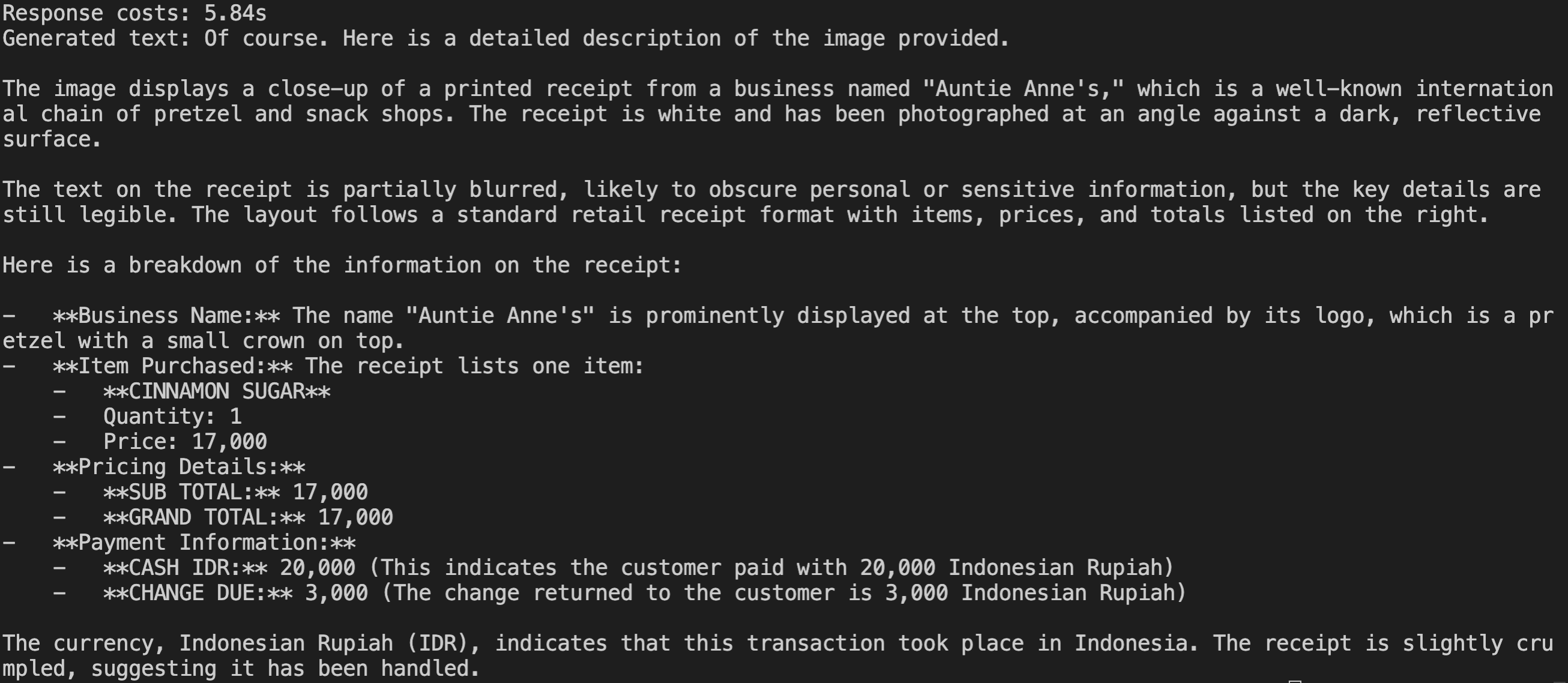
print(f"Response costs: {time.time() - start:.2f}s")
print(f"Generated text: {response.choices[0].message.content}")
Talk is cheap. Show me the code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号