【VLMEvalKit】使用VLMEvalKit进行多模态大语言模型的评测
项目快速启动
1.运行环境
首先,确保你的开发环境已安装 Git 和 Python 3.7 及以上版本。接下来,通过以下命令克隆安装项目:
- 建议Python使用3.7及以上,这里用的是3.11;
- 建议预先安装Pytorch、Transformers、flash-attn等基础Python库,避免冲突;
- 注意:默认vlmeval库依赖较低版本的Torch,需要重新升级Torch库;
git clone https://github.com/open-compass/VLMEvalKit
cd VLMEvalKit
conda create -n vlm_eval_kit python=3.11
conda activate vlm_eval_kit
# 预先安装
pip install torch torchvision torchaudio # 最新版本
pip install transformers==4.45.0
# pip install flash-attn (建议手动安装)
# 其次安装
pip install -r requirements.txt
pip install -e .
# 重新升级 torch 库
pip uninstall torch
pip install torch torchvision torchaudio # 最新版本
# 最后安装
pip install ipdb
pip install einops transformers_stream_generator
pip install validators
pip install sty
pip install timeout_decorator
pip install nltk
安装flash-attention:https://blog.csdn.net/caroline_wendy/article/details/142567622
MME
MME是由腾讯优图实验室和厦门大学联合开发的多模态大语言模型评估基准,包含14个字任务,覆盖从粗粒度到细粒度的对象识别、常识推理、数值计算、文本翻译和代码推理等多个方面,全面评估模型等感知和认知能力。
python3 run.py --data MME --model Qwen2-VL-7B-Instruct --verbose
python3 run.py --data MME --model Llama-3.2-11B-Vision-Instruct --verbose
# python3 run.py --data MME --model LLaVA-CoT --verbose
torchrun --nproc-per-node=8 run.py --data MME --model LLaVA-CoT --verbose
评估结果:

MMStar
2.工程配置
2.1 环境变量(Env)
构建环境变量,在VLMEvalKit目录中,编写.env格式文件,指定模型下载路径(HF_HOME),和数据集下载路径(LMUDATA),也即如下:
HF_HOME="[your path]/huggingface/"
LMUData="[your path]/huggingface/LMUData/"
2.2 评估模型(Env)
VLMEvalKit的模型,参考vlmeval/config.py,包括现有的主流模型,位置默认是Huggingface的下载路径$HF_HOME,也即
model_groups = [
ungrouped, api_models,
xtuner_series, qwen_series, llava_series, internvl_series, yivl_series,
xcomposer_series, minigpt4_series, idefics_series, instructblip_series,
deepseekvl_series, janus_series, minicpm_series, cogvlm_series, wemm_series,
cambrian_series, chameleon_series, video_models, ovis_series, vila_series,
mantis_series, mmalaya_series, phi3_series, xgen_mm_series, qwen2vl_series,
slime_series, eagle_series, moondream_series, llama_series, molmo_series,
kosmos_series, points_series, nvlm_series, vintern_series, h2ovl_series, aria_series,
smolvlm_series
]
如果因为网络连接的问题无法洗在,例如Llama-3.2-11B-Vision-Instruct,可以在模型路径路径vlmeval/config.py中进行修改,
# vlmeval/config.py
llama_series={
# meta-llama/Llama-3.2-11B-Vision-Instruct 替换 [your path]/huggingface/meta-llama/Llama-3.2-11B-Vision-Instruct
'Llama-3.2-11B-Vision-Instruct': partial(llama_vision, model_path='[your path]/huggingface/meta-llama/Llama-3.2-11B-Vision-Instruct'),
'LLaVA-CoT': partial(llama_vision, model_path='[your path]/huggingface/Xkev/Llama-3.2V-11B-cot'),
'Llama-3.2-90B-Vision-Instruct': partial(llama_vision, model_path='meta-llama/Llama-3.2-90B-Vision-Instruct'),
}
# vlmeval/vlm/llama_vision.py
class llama_vision(BaseModel):
INSTALL_REQ = False
INTERLEAVE = False
# This function is used to split Llama-3.2-90B
def split_model(self):
# ...
# meta-llama/Llama-3.2-11B-Vision-Instruct 替换 [your path]/huggingface/meta-llama/Llama-3.2-11B-Vision-Instruct
def __init__(self, model_path='meta-llama/Llama-3.2-11B-Vision-Instruct', **kwargs):
- 默认与Huggingface下载路径一致,需要指定,则修改
vlmeval/config.py配置
2.3 评估集
VLMEvalKit的数据,参考vlmeval/dataset/__init__.py,主要支持IMAGE_DATASET、VIDEO_DATASET、TEXT_DATASET、CUSTOM_DATASET、DATASET_COLLECTION,也即:
# run.py
dataset = build_dataset(dataset_name, **dataset_kwargs)
# vlmeval/dataset/__init__.py
DATASET_CLASSES = IMAGE_DATASET + VIDEO_DATASET + TEXT_DATASET + CUSTOM_DATASET + DATASET_COLLECTION
def build_dataset(dataset_name, **kwargs):
for cls in DATASET_CLASSES:
if dataset_name in cls.supported_datasets():
return cls(dataset=dataset_name, **kwargs)
以MME为例,调用的是vlmeval/dataset/image_yorn.py数据集,也即:
DATASET_URL = {
'MME': 'https://opencompass.openxlab.space/utils/VLMEval/MME.tsv',
'HallusionBench': 'https://opencompass.openxlab.space/utils/VLMEval/HallusionBench.tsv',
'POPE': 'https://opencompass.openxlab.space/utils/VLMEval/POPE.tsv',
'AMBER': 'https://huggingface.co/datasets/yifanzhang114/AMBER_base64/resolve/main/AMBER.tsv',
}
基类ImageBaseDataset负责处理逻辑:
# Return a list of dataset names that are supported by this class, can override
@classmethod
def supported_datasets(cls):
return list(cls.DATASET_URL)
具体位置参考,位于LMUData变量之中,默认位置~/LMUDATA/images/MME,也即:
def LMUDataRoot():
if 'LMUData' in os.environ and osp.exists(os.environ['LMUData']):
return os.environ['LMUData']
home = osp.expanduser('~')
root = osp.join(home, 'LMUData')
os.makedirs(root, exist_ok=True)
return root
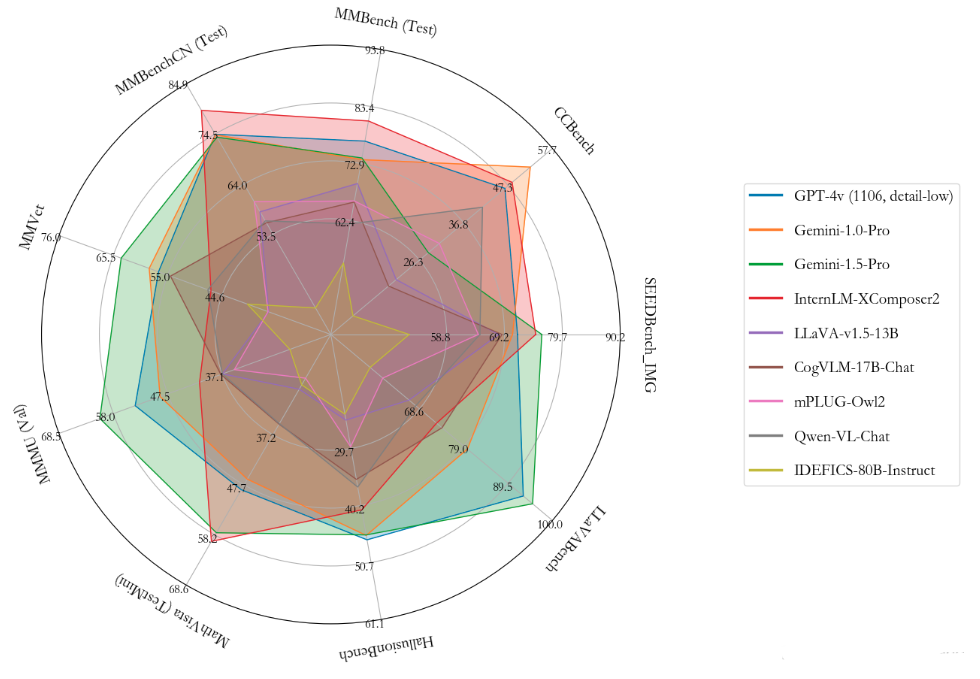
3.雷达图绘制
绘制雷达图,参考scripts/visualize.ipynb,使用OpenVLM.json全量的MLLM评估结果,进行绘制,效果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号